视觉语言导航 相关工作速览之一
VLFM: Vision-Language Frontier Maps for Zero-Shot Semantic Navigation
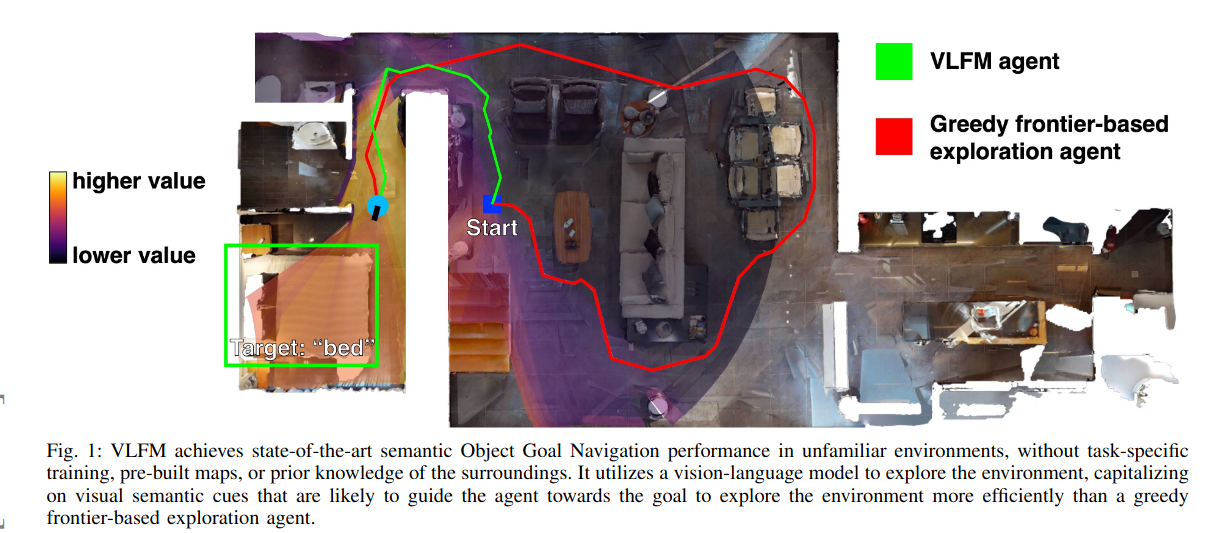
1. 研究背景与目标
人类在陌生环境中导航时,会结合语义知识(如物体空间分布规律)进行推理。受此启发,Yokoyama等(2023)[1]提出了一种零样本(zero-shot)语义导航方法VLFM,旨在让机器人在未知环境中高效寻找目标物体,无需任务特定训练、预建地图或环境先验知识。
2. 核心方法
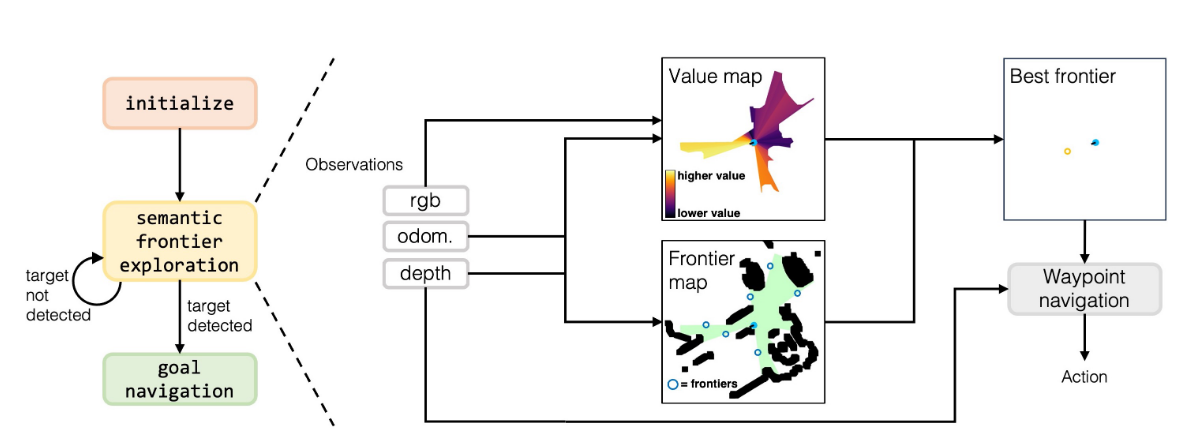
VLFM通过三阶段框架实现目标驱动导航:
- 前沿探索(Frontier Exploration):基于深度观测构建占据地图,识别已探索与未探索区域的边界(前沿)。根据已占据区域的边沿和未探索区域的边沿划分地图边界,将未探索边界的中点视为潜在探索点。
- 语义价值地图(Value Map):
- 利用预训练视觉语言模型BLIP-2[26],计算RGB图像与目标物体文本提示(如“前方可能有<目标物体>”)的余弦相似度,生成语义价值分数。

- 通过置信度加权融合历史与当前观测的语义信息(见图3),形成语言 grounded 的价值地图,指导机器人选择最可能通向目标的前沿。上图有沿着主光轴的权重衰减以及多帧权重融合策略
- 利用预训练视觉语言模型BLIP-2[26],计算RGB图像与目标物体文本提示(如“前方可能有<目标物体>”)的余弦相似度,生成语义价值分数。
- 目标导航(Goal Navigation):使用YOLOv7[27]或Grounding-DINO[29]检测目标物体后,通过PointNav策略[31]导航至目标。
3. 技术优势
- 零样本能力:直接利用预训练模型(BLIP-2、YOLOv7等),无需针对导航任务微调。
- 多模态融合:相比依赖文本中间表示的现有方法(如ESC[2]、SemUtil[3]),VLFM通过视觉-语言联合推理提升计算效率和语义理解能力。
- 模块化设计:各组件(如导航策略、目标检测)可替换,适配未来更优模型。
4. 实验结果
在Habitat模拟器的三个数据集上,VLFM在**成功路径加权长度(SPL)**指标上显著超越现有零样本方法:
- Gibson:SPL提升11.7%(52.2% vs SemUtil的40.5%)[1]
- HM3D:SPL提升8.1%(30.4% vs ESC的22.3%)[1]
- MP3D:SPL提升3.3%(17.5% vs ESC的14.2%)[1]
甚至优于部分需任务特定训练的方法(如Gibson上SPL比SemExp[16]高19.2%)。
5. 现实部署
在波士顿动力Spot机器人上的实际办公楼测试中,VLFM成功实现了真实场景下的零样本导航(视频见naoki.io/vlfm),验证了其跨仿真-现实的泛化能力。
6. 局限与未来方向
- 当前仅支持单楼层导航,未处理楼梯场景。
- 语义价值地图为任务专用,未保留多任务通用信息。
- 未来可探索主动交互(如操纵物体)和长程多任务规划。
7. 意义
VLFM通过视觉-语言模型的空间 grounded 语义推理,为零样本语义导航设立了新标杆,展现了基础模型在机器人领域的潜力。其模块化设计为后续研究提供了灵活框架。
参考文献:文中所有引用均以[数字]标注,对应论文末尾参考文献列表(如BLIP-2[26]、YOLOv7[27]等)。
ApexNav: An Adaptive Exploration Strategy for Zero-Shot Object Navigation with Target-centric Semantic Fusion
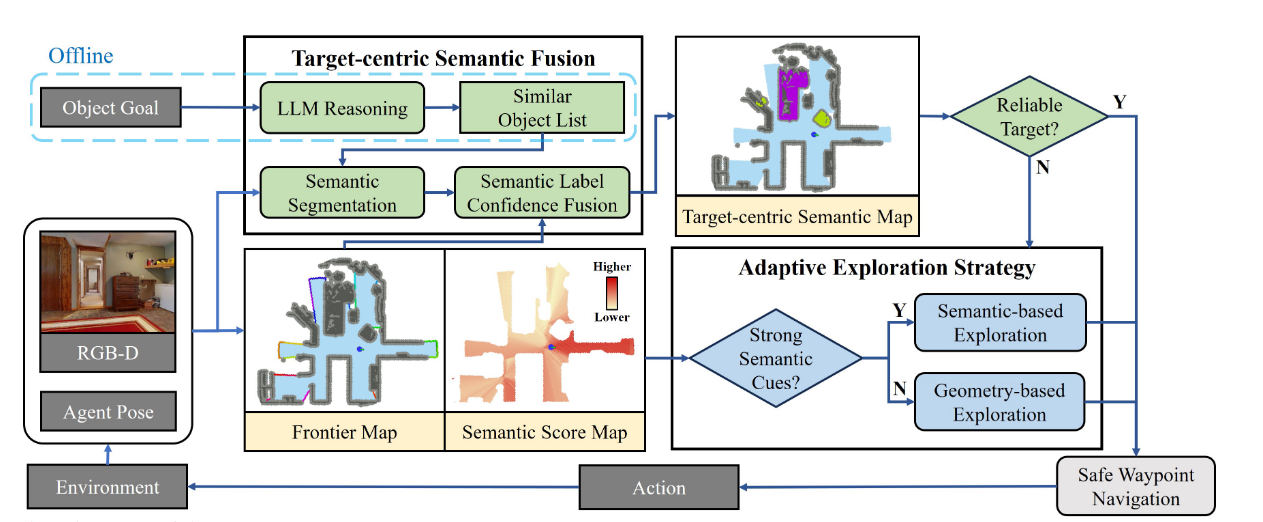
本文介绍了 ApexNav,一种用于零样本目标导航(Zero-Shot Object Navigation, ZSON)的高效且鲁棒的框架,主要贡献包括 自适应探索策略 和 目标中心语义融合方法。
1. 研究背景与问题
目标导航(ObjectNav)要求智能体在未知环境中导航至指定类别的目标物体,是机器人学和AI领域的基础挑战。尽管基于大语言模型(LLM)和视觉语言模型(VLM)的零样本方法展现出强大的泛化能力,但仍存在以下问题:
- 效率不足:现有方法过度依赖语义推理,但在语义线索较弱(如空白墙面或遮挡场景)时效率低下[24, 25]。
- 鲁棒性差:单帧检测或最大置信度融合易受误检影响,尤其在杂乱场景中[6, 8, 26]。
2. 核心方法
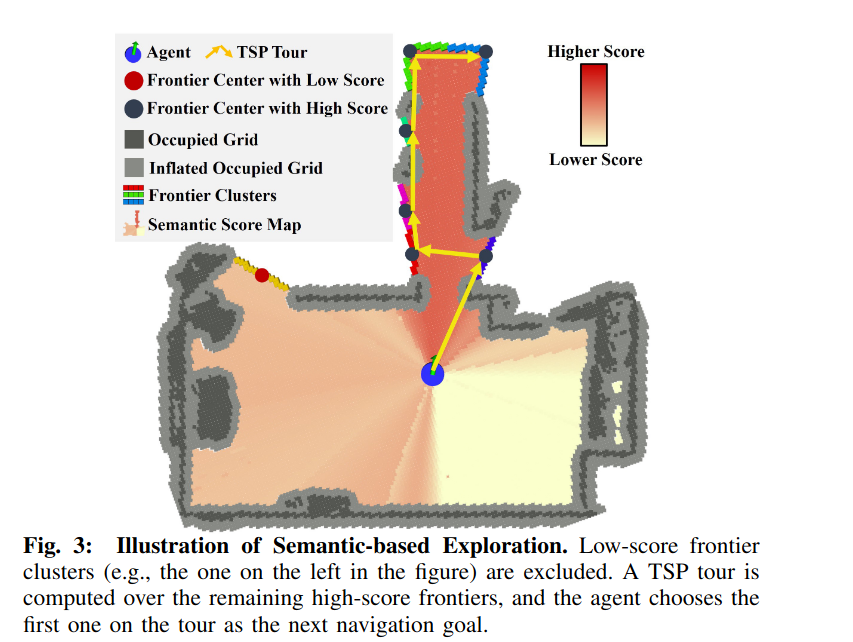
(1)自适应探索策略
- 模式切换机制:通过分析语义分数的分布(如最大值与均值比 $r$ 和标准差 $\sigma$ ),动态选择语义模式(强语义线索)或几何模式(弱语义线索)[IV-B]。
- 语义模式:将高分数边界点建模为旅行商问题(TSP),优化访问顺序以减少冗余路径[IV-B2]。
- 几何模式:采用最近边界点策略快速探索未知区域[IV-B3]。给每一个前沿点赋值一个语义得分如果前沿点的语义得分的方差小于给定阈值那么就切换成几何探索。
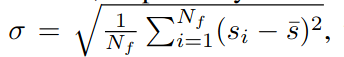
- 实验验证:在HM3Dv1和HM3Dv2数据集上,自适应策略的SPL比固定策略提升8.6%和16.9%[V-B]。
(2)目标中心语义融合
- 多帧融合:通过检测体积加权的置信度更新(式2),长期记忆目标及相似物体,减少误检[IV-C3]。
- LLM辅助推理:生成易混淆物体列表和自适应置信度阈值 $c_{th}$ [IV-C1]。

- 缺失检测惩罚:对当前未检测到的物体降低置信度,避免错误累积[图6]。
- 效果:在HM3Dv2上,融合模块使SR相对提升19.8%,显著优于最大置信度融合方法[V-E]。
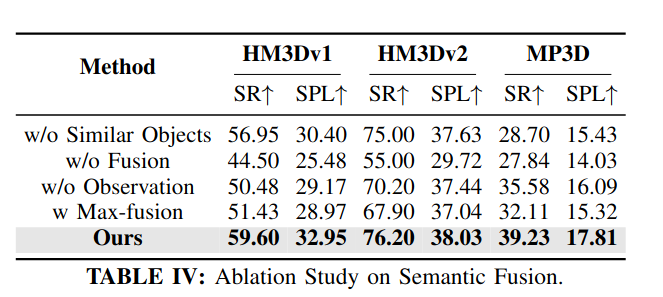
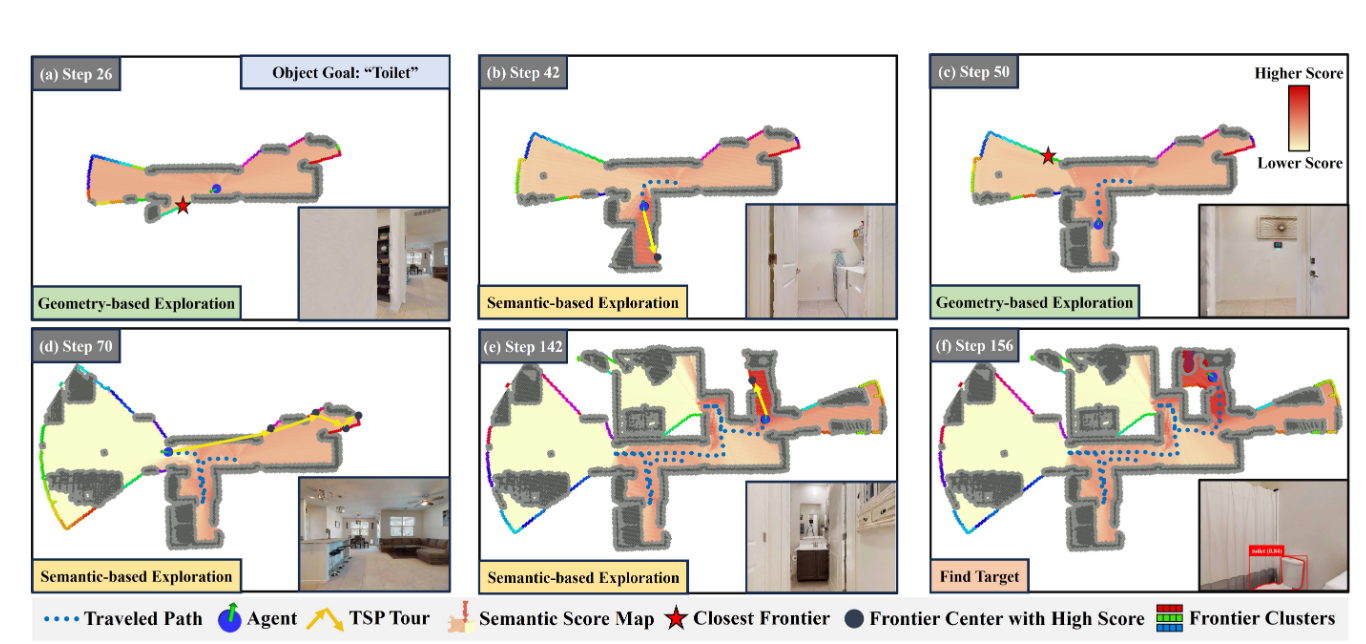
-
消融实验中,ABCD具体指代的是对目标中心语义融合模块(Target-centric Semantic Fusion)的四个关键组成部分进行的系统性测试。具体定义如下:
-
A. ApexNav w/o Similar Objects
移除相似物体辅助检测模块,仅保留目标物体的检测功能。实验表明这会降低系统对易混淆物体的辨别能力,在HM3Dv1数据集上SR下降4.45%,SPL降低2.55%[1]。 -
B. ApexNav w/o Fusion
完全移除语义融合机制,直接使用单帧检测结果覆盖置信度分数。这导致性能显著下降,在HM3Dv2数据集上SR暴跌21.2%,验证了多帧融合对纠错的重要性[1]。 -
C. ApexNav w/o Observation
禁用"未检测到物体时的置信度惩罚"机制。当先前检测到的物体在当前视野中消失时,不再降低其置信度。该缺陷使MP3D数据集的SR下降3.65%,证明动态置信度调整对避免误报至关重要[1]。 -
D. ApexNav w Max-fusion
将原有融合策略替换为传统max-confidence融合方法。结果显示在HM3Dv2上SR降低8.3%,说明简单的最大置信度融合容易积累错误(见图6案例),而作者提出的基于检测体积的加权融合更具鲁棒性[1]。 这些消融实验通过控制变量法验证了目标中心语义融合机制中每个子模块的贡献: -
相似物体列表扩展了检测范围(A组对比)
-
多帧融合提供错误修正能力(B组对比)
-
动态置信度调整避免误报固化(C组对比)
-
体积加权融合优于最大置信度融合(D组对比)作者通过这四组实验最终证明,完整的目标中心语义融合系统相比任何简化版本都能显著提升导航成功率(平均SR提升9.12%)和路径效率(平均SPL提升5.83%)[1]。
3. 实验与结果
- 数据集:在HM3Dv1、HM3Dv2和MP3D上,ApexNav的SR和SPL均达到SOTA(如HM3Dv2上SR=76.2%,SPL=38.0%)[表I]。
- 失败分析:主要失败原因包括跨楼层任务(13%)、误检(11%)和小物体漏检[图7]。
- 实物验证:基于AgileX LIMO机器人的实验成功定位目标,验证了框架的实用性[图1]。
4. 创新与意义
- 理论贡献:
- 首次提出基于语义分布的自适应探索策略,平衡语义与几何信息。
- 设计目标中心融合方法,通过多帧上下文增强鲁棒性。
- 应用价值:为搜索救援、家庭服务机器人等场景提供了无需训练的导航解决方案。
5. 局限与未来方向
- 局限:未解决跨楼层导航问题,依赖2D地图导致部分任务失败[V-C]。
- 展望:结合3D环境建模、更强大的检测模型(如改进YOLOv7[19])和实时轨迹规划(如MINCO[20])进一步提升性能。综上,ApexNav通过自适应探索和鲁棒融合机制,为零样本目标导航设立了新基准。
ZSON: Zero-Shot Object-Goal Navigation using Multimodal Goal Embeddings
Majumdar等(2023)[1]提出了一种名为ZSON的零样本开放世界目标导航方法,通过多模态目标嵌入实现了无需ObjectNav训练数据即可完成物体目标导航任务。以下是全文的核心要点:
- 研究背景与动机
- 传统ObjectNav方法受限于封闭词汇表(如"椅子"、"床"等预设类别)[1]
- 现有方法需要大量3D场景标注或人类演示数据[10]
- 提出零样本(无需ObjectNav训练)和开放世界(不限类别)的解决方案[1]
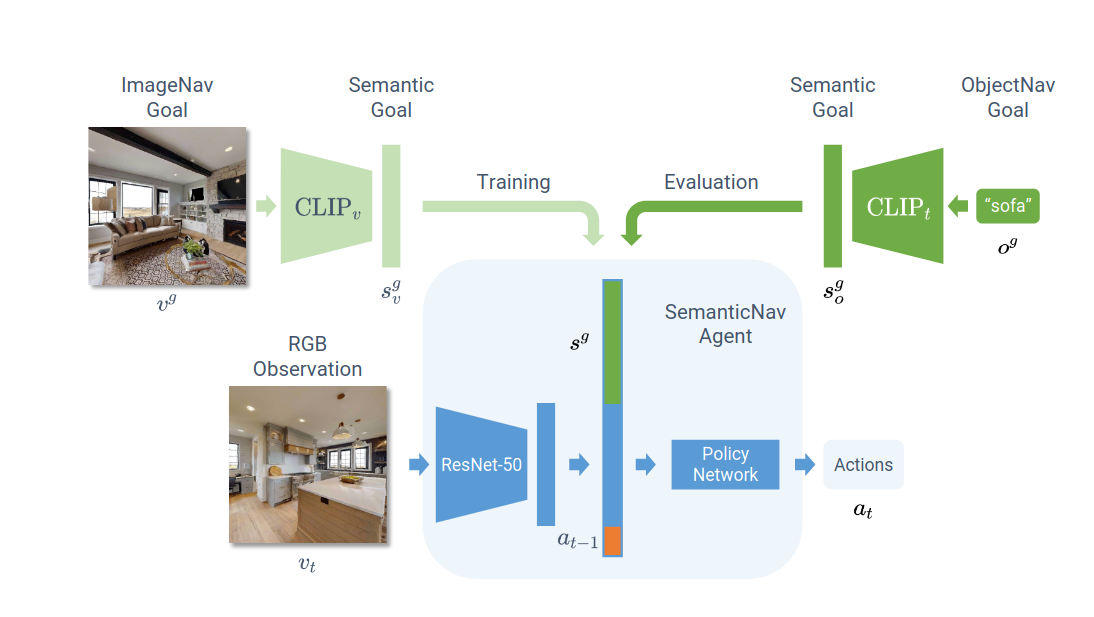
- 关键技术
- 利用CLIP[19]构建视觉-语言共享嵌入空间(图1)
- 将图像目标(ImageNav)和语言目标(ObjectNav)映射到统一语义空间[1]
- 训练流程:先在HM3D环境中用720万ImageNav样本训练,再零样本迁移到ObjectNav[6]
- 主要创新
- 语义目标导航(SemanticNav)框架(图2)
- 解耦目标表示(CLIP处理)与导航策略学习[2]
- 支持自然语言接口(如"浴室水槽"、"厨房水槽"等复合指令)[9]
- 实验结果
- 在Gibson数据集上零样本成功率31.3%,比ZER[18]提升20%绝对值[7]
- HM3D数据集SPL达12.6%,匹配监督方法OVRL[16]性能[7]
- 定性实验显示能理解隐含空间信息(如"水槽和炉灶"→厨房)[9]
- 关键发现
- 视觉编码器预训练使ObjectNav成功率提升9.4-10.4%[8]
- 训练环境多样性(72→800场景)提升6.6%成功率[8]
- 微调实验显示:100M步可使HM3D成功率提升至49.6%[14]
- 意义与局限
- 首次实现开放词汇的零样本ObjectNav(表4)[13]
- 可能受训练环境偏见影响(如非常规物体摆放)[9]
- 代码已开源:https://github.com/gunagg/zson[1]该方法通过语义空间对齐实现了跨模态导航,在保持零样本优势的同时突破了传统ObjectNav的封闭词汇限制,为开放世界 embodied AI 提供了新思路。
ESC: Exploration with Soft Commonsense Constraints for Zero-shot Object Navigation
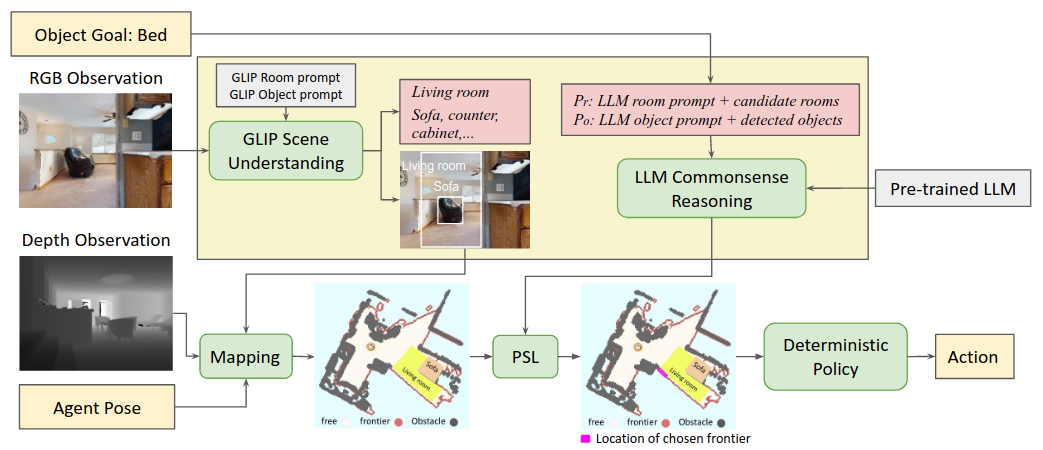
本文提出的 ESC(Exploration with Soft Commonsense Constraints)方法 是一种零样本(zero-shot)物体导航框架,通过结合预训练视觉语言模型和常识推理语言模型,无需在目标环境中进行训练即可实现开放世界的物体导航。以下是方法的详细分步说明:
1. 开放世界语义场景理解(Open-World Semantic Scene Understanding)
-
基于提示的语义 grounding
使用预训练的视觉语言模型 GLIP(Grounded Language-Image Pre-training)[1] 进行开放世界的物体和房间检测。-
物体提示(Object Prompt):将常见室内物体集合 $\{o_c\}$ 与目标物体 $\{o_g\}$ 合并,生成如
"cabinet. chair. table."的文本提示,输入 GLIP 检测当前视野中的物体及其边界框(Eq. 1)。 -
房间提示(Room Prompt):类似地,定义常见房间类别(如卧室、客厅)生成提示,检测当前场景的房间信息(Eq. 2)。
-
优势:GLIP 通过大规模图文预训练,支持通过提示泛化到新物体和场景。
-
-
语义地图构建
将深度图像 $D_t$ 与相机参数结合,投影到 3D 体素空间,并压缩为 2D 导航地图。检测到的物体和房间信息(如边界框中心点)被映射到语义地图中,用于后续导航决策。
2. 基于语言模型的常识推理(Commonsense Reasoning via LLM)
-
物体级与房间级推理
利用预训练语言模型(如 DeBERTa v3[1] 或 ChatGPT)预测目标物体 $G$ 与当前场景中物体 $o_i$ 或房间 $r_i$ 的关联概率:-
物体级:输入问题如 “What is a fireplace likely to be near?”,输出 $S(G|o_i) \in [0,1]$ 表示物体共现概率。
-
房间级:输入问题如 “Where should you go to find a fireplace?”,输出 $S(G|r_i)$ 表示目标物体在房间内的概率。
-
示例(图 1):检测到“沙发在客厅”后,推理“壁炉可能在客厅”,从而优先探索客厅未观测区域。
-
3. 基于软常识约束的探索(Commonsense-Guided Exploration)
-
前沿探索(Frontier-Based Exploration, FBE)
前沿(frontier)定义为已探索区域与未知区域的边界。传统 FBE 选择最近的前沿,而 ESC 结合语义和常识优化选择策略。 -
概率软逻辑(Probabilistic Soft Logic, PSL)
将常识知识转化为可执行的软逻辑规则,通过加权一阶逻辑约束导航决策:-
物体共现规则(Eq. 4):
-
若物体 $o_i$ 与目标 $G$ 共现概率高(如“床”与“床头柜”),则优先探索附近前沿。
-
-
房间关联规则:类似地,鼓励探索目标物体可能出现的房间内的前沿。
-
距离约束(Eq. 6):保留最短路径启发式,权重加倍以平衡探索效率。
-
总和约束(Eq. 7):确保仅选择一个前沿。
-
-
PSL 推理与动作生成
使用 ADMM 或独热约束求解器 优化目标变量 $Y$ (前沿选择概率),选择损失最小的前沿(表 5)。例如,若某前沿靠近“沙发”且 $S(\text{fireplace}|\text{sofa})=0.8$ ,则其被选中的概率显著提升。
4. 导航策略(Navigation Policy)
-
算法流程(Algorithm 1):
-
初始化语义地图和导航地图。
-
每步更新地图,若检测到目标物体则直接导航至目标。
-
否则通过 PSL 选择下一个前沿,重复直至成功或超时。
-
-
局部策略适配:针对不同数据集调整策略(如 RoboTHOR 无 GPS 时通过深度差异判断移动)。
方法优势与创新点
-
零样本泛化:无需导航数据训练,直接利用预训练模型的开放世界能力。
-
显式常识建模:通过 PSL 将语言模型的隐含知识转化为可解释的软逻辑规则,优于隐式学习的神经网络方法 [1]。
-
高效探索:在 MP3D 数据集上相对基线(CoW)提升 288% SR,在 HM3D 和 RoboTHOR 也显著优于需训练的零样本方法(如 ZSON)[1]。
示例与可视化
-
图 5 展示了导航过程中如何通过常识推理避开厨房(“厕所不可能在厨房”)和桌椅区域,最终找到目标“马桶”。
-
图 3 对比 ESC 与 CoW 在各物体类别上的成功率,显示 ESC 在语义关联强的物体(如“床”“厕所”)上优势显著。通过上述设计,ESC 实现了零样本条件下高效、可解释的物体导航,为具身智能的开放世界应用提供了新思路。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)