Llama 3-V:以100倍小的模型和500美元匹敌GPT4-V视觉模型
Llama3 的横空出世震惊了世界,它在几乎所有基准测试中都超越了 GPT-3.5,并在一些方面超越了 GPT-4。随后,GPT-4o 的出现凭借其多模态能力再次夺回了王座。今天,我们发布了一个改变现状的产品:Llama3-V,这是首个基于 Llama3 构建的多模态模型。而且,我们在不到 500 美元的成本下完成了整个训练。你问基准测试怎么样?让数据来说话吧。我们的性能比当前最先进且最受欢迎的多
概述
Llama3 的横空出世震惊了世界,它在几乎所有基准测试中都超越了 GPT-3.5,并在一些方面超越了 GPT-4。随后,GPT-4o 的出现凭借其多模态能力再次夺回了王座。今天,我们发布了一个改变现状的产品:Llama3-V,这是首个基于 Llama3 构建的多模态模型。而且,我们在不到 500 美元的成本下完成了整个训练。
你问基准测试怎么样?让数据来说话吧。我们的性能比当前最先进且最受欢迎的多模态理解模型 Llava 提高了 10-20%。此外,在所有指标上,我们与那些体积大 100 倍的闭源模型表现相当,除了 MMMU 指标。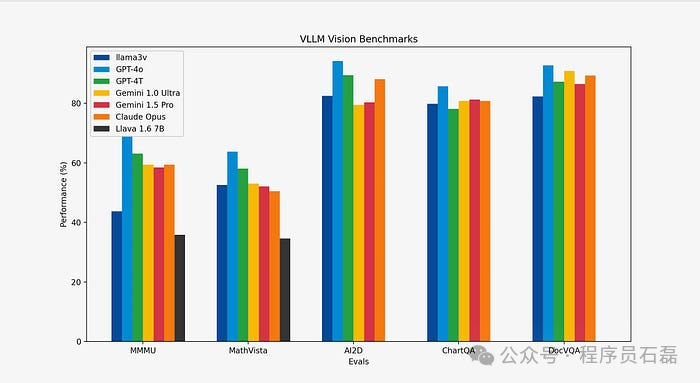 请查看以下链接:
请查看以下链接:
- Huanggface: https://huggingface.co/mustafaaljadery/llama3v/
- Github: https://github.com/mustafaaljadery/llama3v
模型架构
我们的工程工作主要集中在使 Llama3 理解视觉信息。为此,我们将输入图像嵌入到一系列补丁嵌入中,使用 SigLIP 模型。这些嵌入然后通过一个投影模块与文本标记对齐,该模块应用了两个自注意力块,将文本和视觉嵌入放在同一个平面上。最后,投影模块中的视觉标记被预先添加到文本标记之前,并将联合表示传递到 Llama3 中,就像通常那样。
Llama3-V 架构:我们使用 SigLIP 将输入图像嵌入到补丁中。然后,我们训练一个带有两个自注意力块的投影模块,以对齐我们的文本和视觉标记。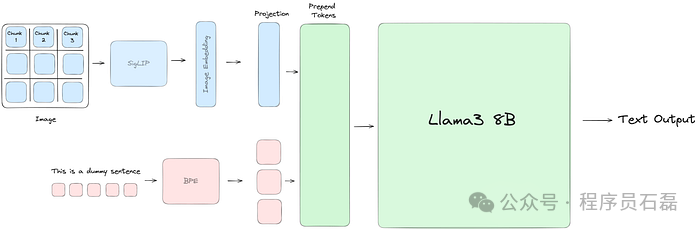 上图展示了整个工作的高层次视图。现在,让我们深入了解每个阶段的细节。
上图展示了整个工作的高层次视图。现在,让我们深入了解每个阶段的细节。
SigLIP
SigLIP(Sigmoid Loss for Language Image Pre-Training)是一种图像嵌入模型,与 CLIP 类似。不同之处在于,CLIP 使用对比损失和 softmax 归一化,而 SigLIP 使用成对 sigmoid 损失,这使得模型可以独立处理每个图像-文本对,而无需在批次中查看所有对。SigLIP 的视觉编码器将图像分割成一系列不重叠的图像补丁,并将它们投射到低维线性嵌入空间,生成一系列补丁嵌入。这些补丁嵌入然后通过一个视觉编码器,应用自注意力以捕捉长距离依赖关系并提取更高级别的视觉特征。对于我们的目的,我们直接使用 Google DeepMind 训练的原始 SigLIP 模型。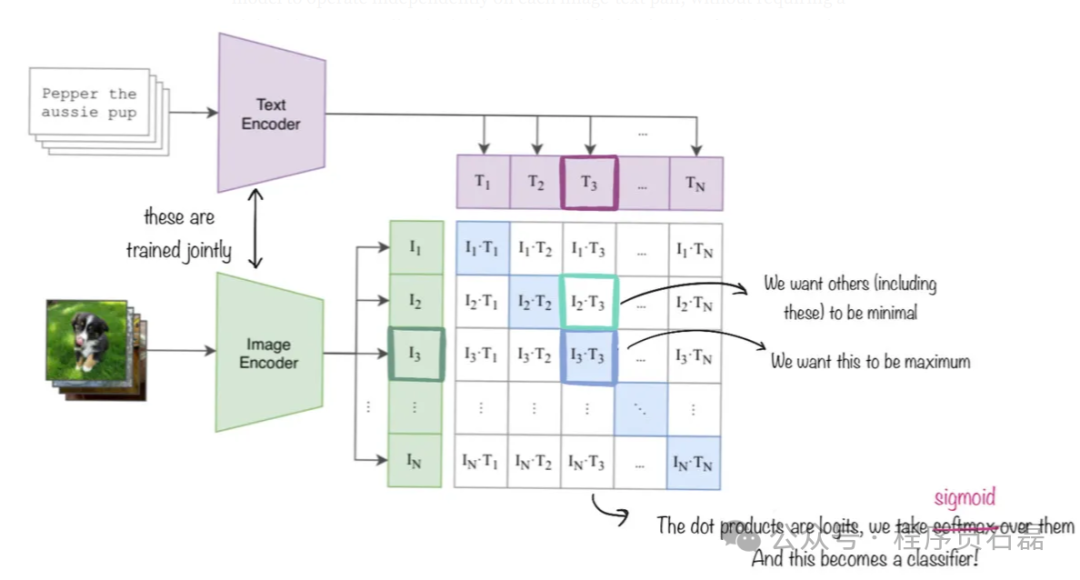 SigLIP嵌入工作原理的示意图。我们同时训练图像和文本解码器,但在我们的案例中,文本编码模块保持固定。不像CLIP,我们最小化的是sigmoid损失而不是softmax损失,但其他大部分东西保持不变。图片来自Merve的推特帖子。
SigLIP嵌入工作原理的示意图。我们同时训练图像和文本解码器,但在我们的案例中,文本编码模块保持固定。不像CLIP,我们最小化的是sigmoid损失而不是softmax损失,但其他大部分东西保持不变。图片来自Merve的推特帖子。
与文本嵌入对齐
为了节省计算资源,我们保持 SigLIP 固定。但是,为了将输出的图像嵌入与 Llama3 使用的文本嵌入对齐,我们使用了一个额外的投影模块。不同于 Llava,它对原始图像嵌入应用单个线性层,我们训练了两个自注意力块,以更好地捕捉输入嵌入中的模式,生成最终的图像嵌入向量。
预先添加图像标记
对于文本输入,我们首先使用 Byte Pair Encoding (BPE) 词汇表对文本进行标记,生成一系列文本标记。我们通过特殊的 和 标签来标记这些标记。对于来自投影模块的图像嵌入,我们将每个向量视为一个单独的“视觉标记”,并通过 和 标签对它们进行标记。最后,我们将视觉标记序列预先添加到文本标记序列之前,形成联合输入表示,然后传递到 Llama3 进行处理。
推理优化
训练这些模型成本高昂。为了优化计算资源,我们进行了两项主要优化。第一项是简单的缓存机制,第二项是在 MPS/MLX 前端的优化。
缓存
SigLIP 模型比 Llama3 小得多。因此,如果我们按顺序运行所有操作,当 SigLIP 运行时,我们的 GPU 利用率非常低。此外,我们不能通过增加 SigLIP 的批处理大小来提高利用率,因为这样 Llama 会遇到 OOM 错误。相反,我们观察到我们的 SigLIP 模型保持不变,因此预先计算图像嵌入。然后,对于预训练和 SFT,我们直接传递这些预先计算的图像嵌入,而不是重新运行 SigLIP 模块。这不仅允许我们增加批处理大小并最大限度地利用 GPU 运行 SigLIP 模块,还节省了训练/推理时间,因为流水线的两个部分可以分别进行。
MPS/MLX 优化
我们的第二个优化再次由 SigLIP 相对于 Llama 的较小体积驱动。具体来说,由于 SigLIP 适合我们的 Macbooks,我们在 MPS 优化的 SigLIP 模型上运行推理,使我们的吞吐量达到每秒 32 张图像——使我们的缓存步骤相对快速地进行。
训练过程
预计算来自 SigLIP 的嵌入
让我们深入了解预训练过程的第一步:通过 SigLIP 预计算图像嵌入。在这一步中,我们的目标是将图像传递到 SigLIP 嵌入模型中,以获得图像的向量表示或嵌入。一个技术细节:由于分辨率较高,我们遵循 LLaVA-UHD 采用的方法,进行图像拆分。图像拆分的目的是将图像划分为可变大小的补丁或片段,以便更高效地编码。这些拆分的图像在批处理中并发处理。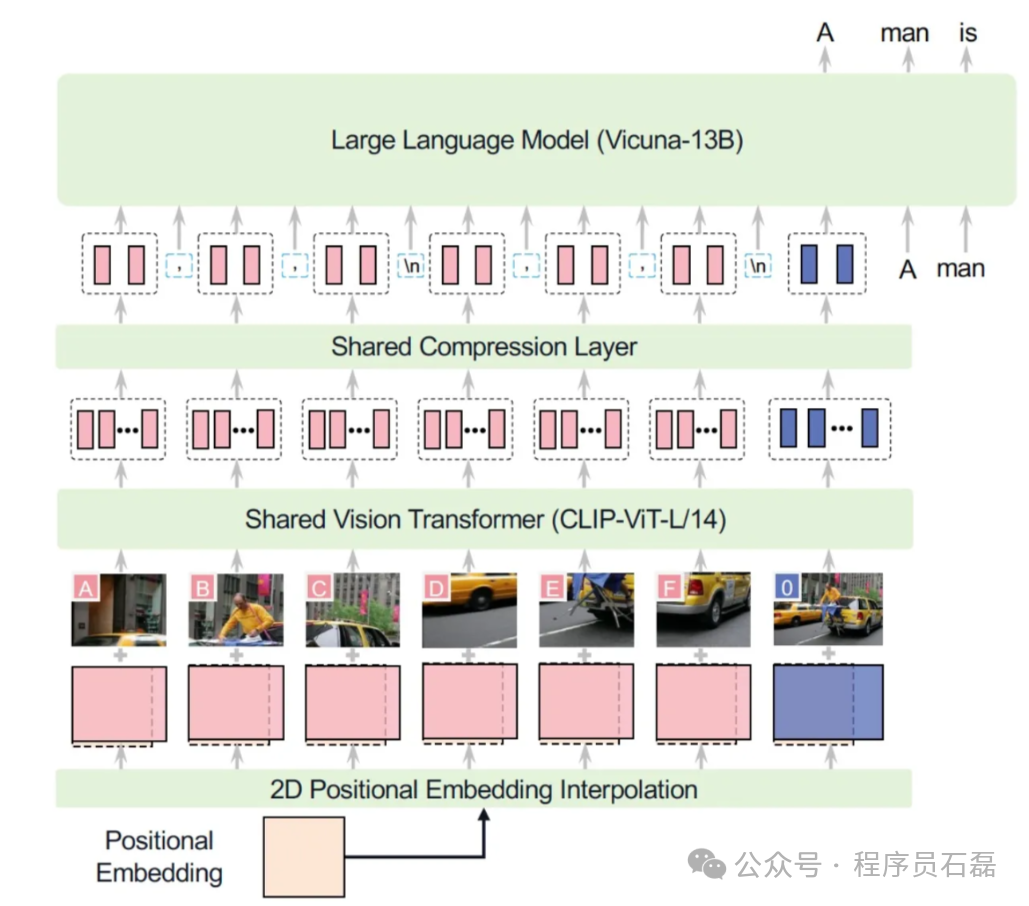
使用 SigLIP 嵌入
我们首先加载 SigLIP 模型和处理器/标记器。然后,我们使用处理器预处理提供的输入图像。接着,我们将预处理后的图像传递给模型。随后,模型输出图像-文本对的 logits。我们接着应用 sigmoid 激活函数到 logits 以获得概率。我们现在看到图像嵌入包含在这些概率中。到目前为止,这个嵌入捕捉了图像中的视觉信息。
学习投影矩阵
在计算了 SigLIP 的图像嵌入之后,我们接下来学习一个投影矩阵——你也可以将其视为投影层,通常是一个线性或前馈层。如上面成分部分所述,投影层将视觉嵌入从其原始空间映射到联合多模态嵌入空间。具体来说,投影层对视觉嵌入 v 应用一个学习到的权重矩阵 W_v,以获得投影的多模态视觉嵌入 W_v * v。因此,在这个投影步骤之后,视觉和文本嵌入本质上对齐到了一个共同的多模态嵌入空间,使得它们的表示可以相互交互并结合用于多模态建模任务,如视觉问答、图像字幕等。更具体地说,投影层的结果是生成的“潜在变量”。
一旦计算了潜在变量,我们接着在文本标记之前预先添加它们作为图像标记。预先添加的原因是,在预训练期间将图像放在文本之前使模型更容易学习。可以将其视为拥有代表实际图像的标记,然后是代表图像内容的文本标记:几乎像是带有图像的标题。我们的架构与 LLaVA-UHD 几乎相同(他们选择 CLIP-ViT,而我们使用 SigLIP,他们使用 Vicuna-13B),因此我们提供了他们的插图作为参考:
预训练
现在我们已经确定了预训练所需的数据,我们可以深入了解实际的预训练过程。在预训练中,我们使用了 60 万个图像预先添加到文本的例子。在这一步中,我们保持 Llama-3 架构的主要权重冻结。关键是我们只想更新投影矩阵的梯度。至关重要的是,我们保持其余权重冻结。至此,我们已经总结了预训练步骤的直觉和过程。关键在于将嵌入的图像(潜在变量)与其文本在一个联合表示中对齐,然后预训练 LLaMA-3 以专注于基于遇到的例子更新投影矩阵。
有监督的微调
在预训练之后,我们进行有监督的微调,以增强模型的性能。在这一步中,我们冻结了计算的嵌入(来自投影层),并保持
除了视觉和投影矩阵之外的所有内容冻结。换句话说,如果你看下面的图像,红色组件是解冻的,而蓝色组件是冻结的。这是为了进行“指令”微调——换句话说,使模型在多模态文本输出方面更强。在这个阶段,我们使用了 100 万个例子(700 万个拆分图像)。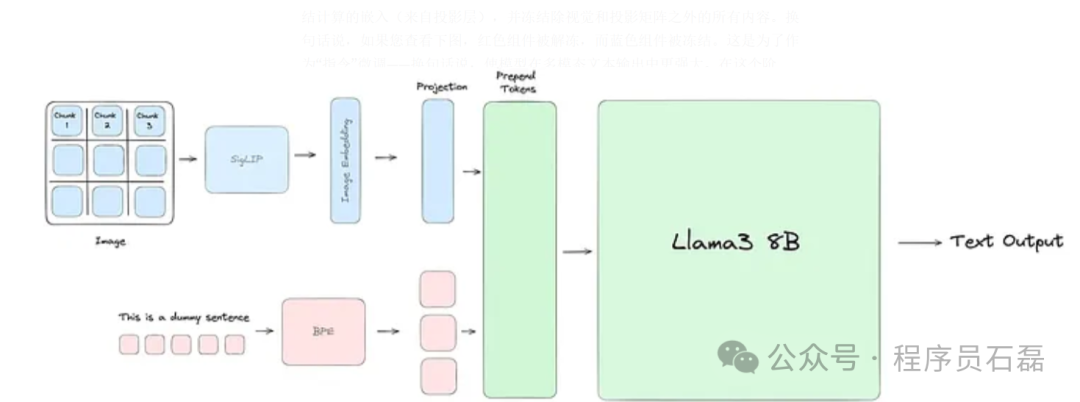
总结
-
我们为 Llama3 8B 添加了一个视觉编码器
-
我们的模型比当前开源最先进的视觉语言模型 Llava 提高了 10-20% 的性能。
-
我们提供了与 GPT4v、Gemini Ultra 和 Claude Opus 等体积接近 100 倍大的模型相当的视觉能力。
-
我们描述了一种在不到 500 美元的成本下进行预训练和指令微调模型的高效流程。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 21
21 0
0- 0



 已为社区贡献141条内容
已为社区贡献141条内容

所有评论(0)