浅谈 audioContext 音频上下文(图解)
最近逛了逛 Github,发现些有意思的项目,主要和 小智AI 有关,起源于 "虾哥"。不过项目主要针对硬件设备,软件方面做的人不是很多,于是翻了翻,发现有搞头,可以顺手学点东西。
主要是对开源项目使用 Vue3 进行重构,在重构的过程中学习到了 audioContext 相关的概念。
可以帮忙点个小星星~
下面进入正题:
audioContext 初步了解
audioContext 是音频上下文,至于什么是上下文,打个比方:
A:“你快点”
B:“我快不了!”
这句话如果没有语境(也就是上下文),你可能完全不知道 A 希望 B 在做什么上快点
而在此处,你可以将 audioContext 想象成一个图:

此时 audioContext 是空白的,因为你还没有进行别的操作。
不过未来,所有音频操作都要在这个图上进行,因此 audioContext 是一切音频操作的基础。
如果你此时从后端获取到一段音频文件 audioBuffer,可以通过创建节点的方式进行播放:
const source = audioContext.createBufferSource();
source.buffer = audioBuffer;
source.connect(audioContext.destination);在上述代码中,我们通过 createBufferSource 方法在 audioContext 图中创建了一个节点 source,并将音频文件放在 source 节点中:

最后通过节点的 connect 方法将 source 节点链接到 audioContext.destination,也就是音频上下文的出口:
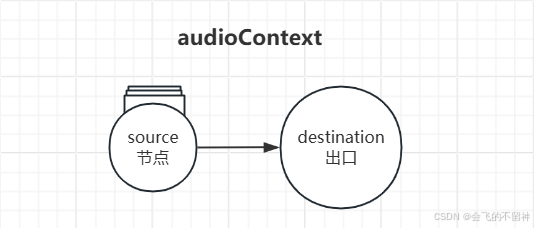
每个 audioContext 默认都会有个 destination 属性,就相当于水龙头的出口,音频要从水龙头的出口出来才能播放。
以上,创建节点可以看作创建了一处水源,而水源必须从水龙头流出才能顺利完成播放。
audioContext 解码音频
还记得上文提到的 audioBuffer 吗?从后端传来的 AudioBuffer 类型的文件。
其实后端传来的文件不一定是 AudioBuffer 类型,更多的可能是 Opus 或其他方式编码后的音频(因为编码后的音频文件体积较小,便于传输)。
不过此处我们不讲如何对编码后的音频文件进行解码,而是讲解码后的音频二进制文件 blob 如何转化为 AudioBuffer 类型:
const arrayBuffer = blob.arrayBuffer();
const audioBuffer = audioContext.decodeAudioData(arrayBuffer);此处我们通过将解码后的音频文件转化为 ArrayBuffer,再使用 audioContext 的 decodeAudioData 进行解码,最终拿到了 audioBuffer。
audioContext 进阶操作
该小节主要阐述 AudioContext API。
如果你有获取用户音频传输给后端的需求,下面有两个方法:
- 使用 MediaRecorder API 对用户音频进行录制,录制完成后上传至后端(一般使用 HTTPS 请求)
- 使用 AudioContext API 将实时获取到的用户音频流上传至后端(一般用于 WebSocket 通信)
当然,二者首先都需要浏览器提供的 Navigator.mediaDevices.getUserMedia 获取用户的麦克风权限和音频流。
先简单说说 MediaRecorder API 吧:
MediaRecorder 中有两个回调函数用于处理得到的音频,分别是 onstop 和 ondataavailable,通过 start 和 stop 方法对录音进行开始和停止。
在 AudioContext API 中,理解图和节点的概念非常重要。
首先我们需要将我们获取到的用户音频流封装为一个入口节点(水源):
// 获取用户音频流
const audioStream = navigator.mediaDevices.getUserMedia();
// 将音频流封装进 source 节点
const source = audioContext.createMediaStreamSource(audioStream);为了更便于理解,下面是等效的图:
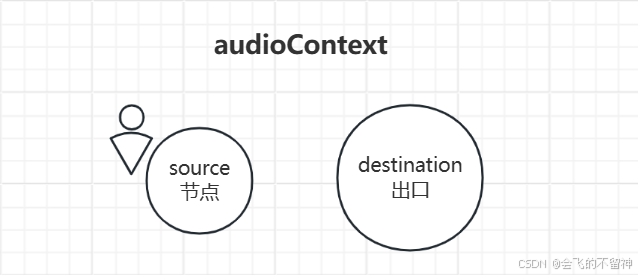
当用户允许了麦克风权限之后,source 节点会有源源不断的用户音频流产生。
此时,我们需要创建一个自定义节点,将 source 节点产生的流传入自定义节点,进行我们想要的处理。

自定义节点的创建比较复杂,不过可以概括为以下几步:
- 创建并注册自定义节点的类文件
- 在 audioContext 中添加这个自定义的节点类型
- 创建自定义节点
- 将需要的节点链接到自定义节点
1. 创建自定义节点的类文件
首先,创建一个文件夹 audioProcessor.js,写入下面的代码:
class AudioProcessor extends AudioWorkletProcessor {
constructor() {
super();
}
process(inputs) {
// 内部处理逻辑...
return true;
}
}
registerProcessor('audioProcessor', AudioProcessor);这是一个通用的自定义节点注册模板,先定义一个类、重写 process 方法、调用 registerProcessor 进行注册。
2. 在 audioContext 中注册这个自定义节点
const audioContext = new AudioContext();
audioContext.audioWorklet.addModule(
"/utils/audio/audioProcessor.js"
);3. 创建自定义节点
const processorNode = new AudioWorkletNode(audioContext, "audioProcessor")4. 将需要的节点链接到自定义节点
source.connect(processorNode);此时你可能会注意到,audioContext.destination 没有被连接。因为音频处理不需要播放,所以 processorNode 不用再链接到 destination 了,否则用户自己的音频流被播放出来,会比较奇怪
总结
如果你觉得本文对你有帮助,欢迎点赞和分享!
作图工具:Process on

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)