videoprism论文速读:从图像描述中学习音频视频模式
【摘要】本文提出了一种创新的视频挖掘方法,通过将图像描述数据集中的文本转移到相似视频片段,构建出千万级规模的VideoCC3M数据集(1030万视频-描述对),解决了视频音频领域标注数据匮乏的难题。该方法采用双流模型架构,在文本-视频检索、音频检索和视频描述三大任务上取得突破性表现:在MSR-VTT数据集上检索性能超越HowTo100M预训练模型,AudioCaps音频检索达到SOTA,视频描述任
一、论文介绍
本文提出了一种新的视频挖掘管道,旨在解决文本-视频和文本-音频检索领域大规模训练数据匮乏的问题。该方法通过将图像描述数据集中的描述转移至视频片段,构建了一个大规模、弱标注的音频-视频描述数据集。基于此数据集训练的多模态变换模型在视频检索和视频描述任务上表现优异,甚至超越了使用HowTo100M预训练的数据集。
二、研究背景与挑战
图像领域的成功与视频音频领域的困境
在图像领域,已有大量带有自然语言描述的数据集,推动了相关技术的飞速发展。然而,在视频和音频领域,手动标注视频既费时又昂贵,导致现有视频描述数据集规模较小(通常为10万级别),而音频描述数据集规模更小。
HowTo100M的局限性
HowTo100M数据集虽大规模,但存在诸多问题:(1)自动语音识别(ASR)转录存在噪声;(2)连续叙述可能包含不完整或语法错误的句子;(3)领域多局限于教学视频;(4)语音与视频内容可能不匹配或未对齐。
三、研究方法
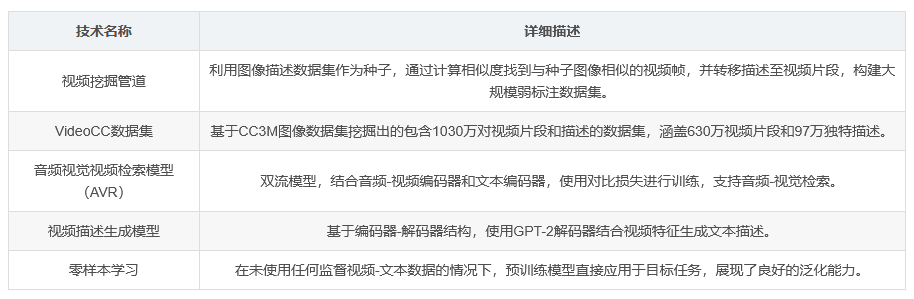
视频挖掘管道
核心思想是利用图像描述数据集作为种子,通过计算种子图像与视频帧的特征向量相似度,找到与种子图像相似的视频帧,并提取包含匹配帧的短暂视频片段,将图像描述转移到这些片段上。
VideoCC数据集构建
使用Conceptual Captions 3M(CC3M)图像数据集作为种子数据集,挖掘出1030万对视频片段和描述,涵盖630万视频片段和97万独特描述,构成VideoCC3M数据集。
四、模型架构
音频视觉视频检索(AVR)
采用双流模型,一个流为音频-视频编码器,另一个流为文本编码器。视频编码器基于RGB帧和音频频谱图提取特征,文本编码器使用BERT模型。最终,视频和文本编码被投影到共同维度,计算点积相似度。
视频描述生成
采用编码器-解码器结构,视频编码器与检索模型相同,解码器基于GPT-2,结合视频特征和先前生成的文本生成新文本。
五、实验
数据集与指标
实验使用了VideoCC3M、HowTo100M、MSR-VTT、AudioCaps和Clotho数据集,评估指标包括Recall@K和Bleu-4、CIDEr、Meteor等。
实验结果
-
文本-视频检索:在MSR-VTT数据集上,VideoCC3M预训练模型显著优于HowTo100M,尤其在零样本设置下,性能提升更为明显。
-
音频检索:在AudioCaps和Clotho数据集上,VideoCC3M预训练模型在文本-音频检索任务上取得了最佳性能。
-
视频描述:VideoCC3M预训练模型在MSR-VTT数据集的视频描述任务上超越了先前发表的工作。
六、关键结论
本文提出的视频挖掘方法能够有效利用现有图像描述数据集,挖掘出大规模弱标注的视频和音频数据。基于这些数据训练的多模态模型在多个任务上均取得了优异的性能,证明了该方法的有效性和优越性。
七、核心技术总结

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 6
6 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)