(ICML-2022)BLIP:构建统一视觉-语言理解与生成模型的语言图像预训练方法
BLIP:统一的视觉-语言预训练框架 BLIP提出了一种新颖的视觉-语言预训练框架,通过多模态混合编码器-解码器(MED)结构和数据自举方法CapFilt,实现了视觉-语言理解与生成任务的统一优化。MED架构能够同时支持三种功能模式:单模态编码、图像引导文本编码和图像引导文本解码。框架采用图文对比、图文匹配和语言建模三种损失联合优化。CapFilt方法通过生成合成图像描述和过滤噪声数据,有效提升了
BLIP:构建统一视觉-语言理解与生成模型的语言图像预训练方法
paper是Salesforce Research发表在ICML 2022的工作
paper title:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
Code:链接
Abstract
视觉-语言预训练(Vision-Language Pre-training, VLP)提升了多种视觉-语言任务的性能。然而,现有的大多数预训练模型仅在基于理解的任务或基于生成的任务中表现出色。此外,性能的提升在很大程度上依赖于扩展数据集规模,这些数据集通常来自网络中嘈杂的图文对,这是一种次优的监督信号来源。本文提出了BLIP,一个新的VLP框架,能够灵活迁移到视觉-语言理解和生成任务。BLIP通过引导生成图像描述,有效利用了嘈杂的网络数据,其中一个描述器生成合成的图像描述,一个过滤器则去除其中嘈杂的部分。我们在多个视觉-语言任务上取得了当前最优的结果,例如图文检索(平均Recall@1提升 + 2.7 % +2.7\% +2.7%)、图像描述(CIDEr得分提升 + 2.8 % +2.8\% +2.8%)以及视觉问答(VQA得分提升 + 1.6 % +1.6\% +1.6%)。此外,BLIP在零样本迁移至视频-语言任务时也表现出强大的泛化能力。
1. Introduction
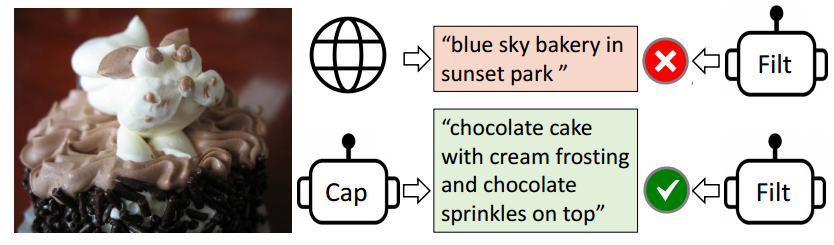
图1。我们使用一个生成器(Captioner,简称 Cap)为网络图像生成合成描述,同时使用一个过滤器(Filter,简称 Filt)去除噪声描述。
视觉-语言预训练近期在多种多模态下游任务中取得了巨大成功。然而,现有方法存在两个主要局限性:(1)从模型角度来看:大多数方法要么采用基于编码器的模型(Radford 等,2021;Li 等,2021a),要么采用编码器-解码器模型(Cho 等,2021;Wang 等,2021)。然而,基于编码器的模型在直接迁移到文本生成任务(如图像描述)时不够直接;而编码器-解码器模型尚未成功应用于图文检索任务。
(2)从数据角度来看:大多数最新的方法(如 CLIP(Radford 等,2021)、ALBEF(Li 等,2021a)、SimVLM(Wang 等,2021))是在从网络收集的图文对上进行预训练的。尽管通过扩大数据集规模获得了性能提升,但本文表明,噪声较大的网络文本并不是视觉-语言学习的最优选择。
为此,我们提出了 BLIP:用于统一视觉-语言理解与生成的语言-图像自举预训练(Bootstrapping Language-Image Pre-training)。BLIP 是一个新的视觉-语言预训练框架,相比现有方法能够支持更广泛的下游任务。该框架从模型和数据两个角度引入了两个创新点:
(a) 多模态混合编码器-解码器(Multimodal Mixture of Encoder-Decoder,MED):一种用于有效多任务预训练与灵活迁移学习的新型模型架构。MED 可以作为单模态编码器、以图像为条件的文本编码器,或以图像为条件的文本解码器工作。该模型通过三个视觉-语言目标进行联合预训练:图文对比学习、图文匹配和图像条件语言建模。
(b) 生成与筛选(Captioning and Filtering,CapFilt):一种用于从噪声图文对中学习的新型数据自举方法。我们将一个预训练的 MED 微调为两个模块:一个图像描述器,用于根据网络图像生成合成描述;另一个是筛选器,用于从原始网络文本和合成文本中剔除噪声描述。
我们进行了大量实验和分析,并得出以下关键观察结果:
• 我们证明,通过对图像描述的自举,描述器与筛选器协同工作,在多种下游任务上实现了显著的性能提升。我们还发现,生成的描述越多样,性能提升越明显。
• BLIP 在广泛的视觉-语言任务上达到了当前最先进的性能,包括图文检索、图像描述、视觉问答、视觉推理和视觉对话。在将我们的模型直接迁移到两个视频-语言任务(文本-视频检索和视频问答)时,也达到了最先进的零样本学习表现。
2. Related Work
2.1. Vision-language Pre-training
视觉-语言预训练(Vision-language pre-training, VLP)旨在通过在大规模图文对上进行预训练,以提升下游视觉与语言任务的性能。由于获取人工标注文本的成本过高,大多数方法(Chen et al., 2020;Li et al., 2020;2021a;Wang et al., 2021;Radford et al., 2021)采用从网络上抓取的图像与alt文本对(Sharma et al., 2018;Changpinyo et al., 2021;Jia et al., 2021)。尽管使用了基于规则的简单筛选器,网络文本中的噪声仍然普遍存在。然而,噪声的负面影响在很大程度上被忽视,因扩大数据集所带来的性能提升掩盖了这一问题。我们的论文表明,网络文本中的噪声并不利于视觉-语言学习,并提出了CapFilt方法,以更有效地利用网络数据集。
已有许多尝试试图将各种视觉与语言任务统一到一个框架中(Zhou et al., 2020;Cho et al., 2021;Wang et al., 2021)。其中最大的挑战是设计一种既能胜任理解类任务(如图文检索)又能胜任生成类任务(如图像描述)的模型架构。现有的编码器模型(Li et al., 2021a;2021b;Radford et al., 2021)和编码器-解码器模型(Cho et al., 2021;Wang et al., 2021)都难以同时在这两类任务上取得优异表现,而统一的单一编码器-解码器结构(Zhou et al., 2020)也限制了模型能力。我们提出的多模态编码器-解码器混合模型,在保持预训练过程简洁高效的同时,提供了更大的灵活性,并在多种下游任务上取得了更好的性能。
2.2. Knowledge Distillation
知识蒸馏(Knowledge Distillation, KD)(Hinton 等,2015)旨在通过从教师模型中提取知识来提升学生模型的性能。自蒸馏(Self-distillation)是知识蒸馏的一种特殊形式,其中教师模型与学生模型的规模相同。研究表明,该方法在图像分类(Xie 等,2020)以及近期的视觉-语言预训练(VLP)(Li 等,2021a)中均具有良好效果。与大多数现有的知识蒸馏方法仅仅要求学生模型复制教师模型的类别预测结果不同,我们提出的 CapFilt 可以被理解为在 VLP 背景下更有效的一种知识蒸馏方式,其中 Captioner 通过语义丰富的合成描述传递知识,而 Filter 则通过去除噪声描述来实现知识的提炼。
2.3. Data Augmentation
尽管数据增强(Data Augmentation, DA)已在计算机视觉领域广泛应用(Shorten & Khoshgoftaar,2019),但在语言任务中实施 DA 相对不那么直接。近年来,生成式语言模型被用于为各种自然语言处理(NLP)任务生成合成样本(Kumar 等,2020;Anaby-Tavor 等,2020;Puri 等,2020;Yang 等,2020)。与这些主要聚焦于低资源纯语言任务的方法不同,我们的方法在大规模视觉-语言预训练中展示了合成描述(synthetic captions)的显著优势。
3. Method
我们提出了BLIP,一个统一的视觉-语言预训练(VLP)框架,用于从带噪声的图文对中学习。本节首先介绍我们提出的新模型架构MED及其预训练目标,随后阐述用于数据集自举的CapFilt方法。
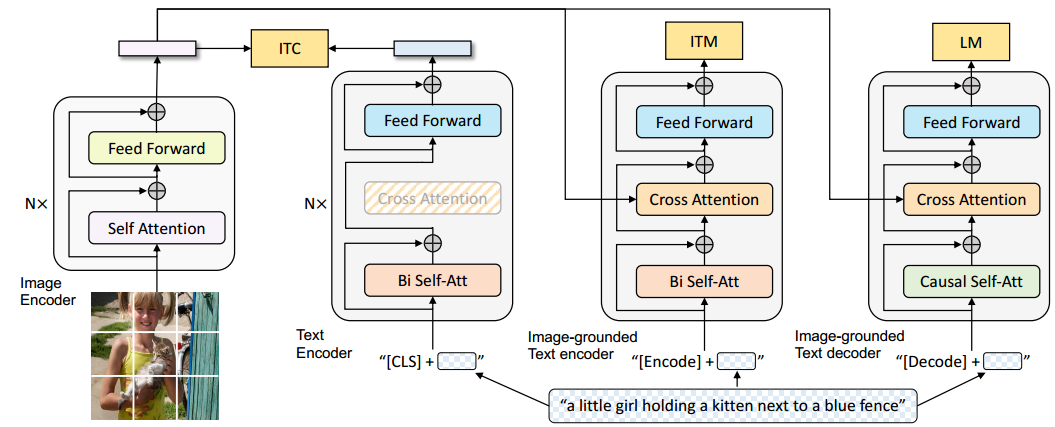
图2. BLIP的预训练模型结构与目标(相同颜色表示共享参数)。我们提出了多模态编码-解码混合结构(Multimodal Mixture of Encoder-Decoder),这是一种统一的视觉-语言模型,可在以下三种功能中运行:(1) 单模态编码器:通过图文对比损失(Image-Text Contrastive, ITC)进行训练,用于对齐视觉和语言表示;(2) 图像引导的文本编码器:通过引入额外的交叉注意力层(Cross-Attention)来建模视觉与语言的交互关系,并通过图文匹配损失(Image-Text Matching, ITM)进行训练,以区分正负图文对;(3) 图像引导的文本解码器:将双向自注意力层替换为因果自注意力层(Causal Self-Attention),并与编码器共享交叉注意力层和前馈网络。该解码器通过语言建模损失(Language Modeling, LM)进行训练,用于根据图像生成描述文本。
3.1. Model Architecture
我们采用视觉Transformer(Dosovitskiy等,2021)作为图像编码器,将输入图像划分为多个图像块,并将其编码为一系列嵌入表示,同时引入一个额外的[CLS]标记用于表示全局图像特征。与使用预训练的目标检测器提取视觉特征的方法(Chen等,2020)相比,使用ViT在计算上更高效,且已被近期方法广泛采用(Li等,2021a;Kim等,2021)。
为了预训练一个兼具理解与生成能力的统一模型,我们提出了多模态编码-解码混合结构(MED),这是一种多任务模型,可在三种功能模式下运行:
(1) 单模态编码器:分别对图像和文本进行编码。文本编码器结构与BERT(Devlin等,2019)相同,在文本输入前添加一个[CLS]标记以概括句子内容。
(2) 图像引导的文本编码器:通过在每个Transformer块中的自注意力(SA)层与前馈网络(FFN)之间插入一个跨模态注意力(CA)层,将视觉信息注入文本编码过程中。文本末尾添加一个任务特定的[Encode]标记,其输出嵌入表示作为图文对的多模态表示。
(3) 图像引导的文本解码器:将图像引导文本编码器中的双向自注意力层替换为因果自注意力层。使用[Decode]标记表示序列起始,使用一个结束标记表示序列终止。
3.2. Pre-training Objectives
我们在预训练阶段联合优化三个目标函数,其中包括两个基于理解的目标和一个基于生成的目标。每对图文样本仅需一次通过计算开销较大的视觉Transformer,以及三次通过文本Transformer,在每次前向传播中激活不同的功能模式,以计算如下所述的三个损失函数。
图文对比损失(Image-Text Contrastive Loss, ITC)激活单模态编码器,旨在对视觉Transformer和文本Transformer的特征空间进行对齐,通过鼓励正向图文对具有更相似的表示,从而区别于负向配对。该方法已被证明能有效提升视觉与语言理解能力(Radford等,2021;Li等,2021a)。我们采用Li等(2021a)提出的ITC损失,引入动量编码器(momentum encoder)来生成特征,并使用动量编码器生成的软标签作为训练目标,以捕捉负样本中可能存在的正样本。
图文匹配损失(Image-Text Matching Loss, ITM)激活图像引导的文本编码器,旨在学习能够捕捉图像与语言之间细粒度对齐关系的多模态表示。ITM是一个二分类任务,模型使用ITM预测头(一个线性层)来判断图文对是否匹配。为挖掘更具信息性的负样本,我们采用Li等(2021a)提出的困难负样本挖掘策略,即在一个batch中,具有较高对比相似度的负样本更有可能被选用于计算损失。
语言建模损失(Language Modeling Loss, LM)激活图像引导的文本解码器,目标是根据图像生成描述文本。该损失通过交叉熵优化模型,以自回归方式最大化文本的生成概率。我们在计算损失时应用0.1的标签平滑。相比于在VLP中广泛使用的MLM(掩码语言建模)损失,LM损失赋予模型将视觉信息转化为连贯文本的泛化能力。
为了在实现高效预训练的同时利用多任务学习优势,文本编码器与文本解码器共享除自注意力层(SA)外的所有参数。这是因为编码任务和解码任务的差异主要体现在SA层上。具体而言,编码器使用双向自注意力来构建当前输入token的表示,而解码器使用因果自注意力以预测下一个token。另一方面,嵌入层(embedding)、交叉注意力层(CA)与前馈网络(FFN)在编码与解码任务中功能相似,因此共享这些层不仅提升了训练效率,也增强了多任务学习的效果。
3.3. CapFilt
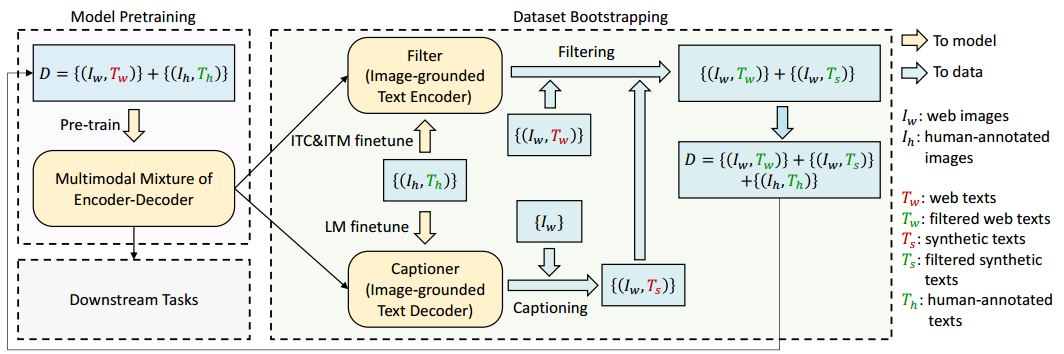
图3. BLIP的学习框架。我们引入一个captioner(生成器)为网页图像生成合成描述文本,并使用一个filter(过滤器)去除噪声图文对。captioner和filter均从同一个预训练模型初始化,并分别在小规模人工标注数据集上进行微调。经过数据增强(bootstrapping)得到的新数据集被用于预训练一个新的模型。
由于高质量人工标注的图文对 { ( I h , T h ) } \{(I_h, T_h)\} {(Ih,Th)}(如 COCO(Lin et al., 2014))标注成本高昂,现有数据量有限。近期的研究(Li 等,2021a;Wang 等,2021)则利用了大量从网页自动收集的图像及替代文本对 { ( I w , T w ) } \{(I_w, T_w)\} {(Iw,Tw)}。然而,这些网页上的替代文本往往无法准确描述图像的视觉内容,因而成为一种噪声较大的信号,不利于学习图文之间的对齐关系。
我们提出 Captioning and Filtering(CapFilt),一种提升文本语料质量的新方法。图 3 展示了 CapFilt 的结构。该方法引入两个模块:一个 captioner 用于根据网页图像生成描述文本,另一个 filter 用于剔除噪声图文对。这两个模块均以同一个预训练的 MED 模型初始化,并在 COCO 数据集上分别进行微调。微调过程是轻量级的。
具体来说,captioner 是一个图像引导的文本解码器。它通过语言建模(LM)目标进行微调,用于根据图像解码文本。对于网页图像 I w I_w Iw,captioner 生成合成描述 T s T_s Ts,每张图像生成一个描述。
filter 是一个图像引导的文本编码器。它通过图文对比(ITC)和图文匹配(ITM)目标进行微调,用于判断文本是否与图像匹配。filter 会从原始网页文本 T w T_w Tw 和合成文本 T s T_s Ts 中剔除噪声文本——即当 ITM 预测该文本与图像不匹配时,认为该文本为噪声。
最后,我们将过滤后的图文对与人工标注图文对进行整合,构建一个新的训练集,以预训练一个新的模型。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 25
25 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)