Swin Transformer:基于移动窗口的分层视觉Transformer
Transformer已被广泛应用于自然语言处理领域。但是由于语言和视觉之间存在巨大差异,如何将Transformer更好地应用到视觉领域成了一项挑战。为了解决这些差异,作者提出了基于移动窗口的分层视觉Transformer——Swin Transformer。移动窗口将Self-Attention计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而大幅提高了效率。分层结构在不同尺度建模上具有一
Transformer已被广泛应用于自然语言处理领域。但是由于语言和视觉之间存在巨大差异,如何将Transformer更好地应用到视觉领域成了一项挑战。为了解决这些差异,作者提出了基于移动窗口的分层视觉Transformer——Swin Transformer。移动窗口将Self-Attention计算限制在非重叠的局部窗口上,同时允许跨窗口连接,从而大幅提高了效率。分层结构在不同尺度建模上具有一定灵活性,并且具有与图像大小相关的线性计算复杂度。Swin Transformer的这些特性使其能够兼容广泛的视觉任务,包括图像分类、目标检测、语义分割等。Swin Transformer的性能大大超过了以前的最好方法,达到了SOTA水平。
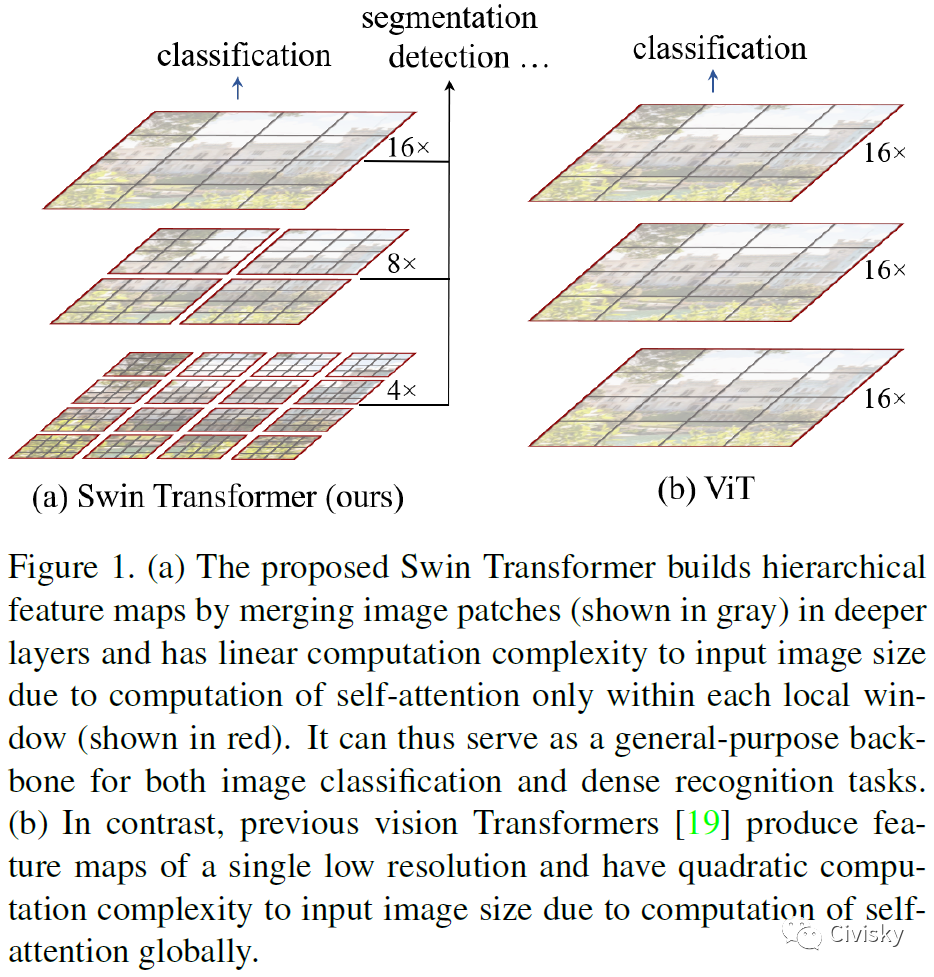
如图1所示,Swin Transformer构造了一个分层表示,从小型Patches(灰色轮廓)开始,在更深的Transformer层中逐渐合并相邻的Patches。
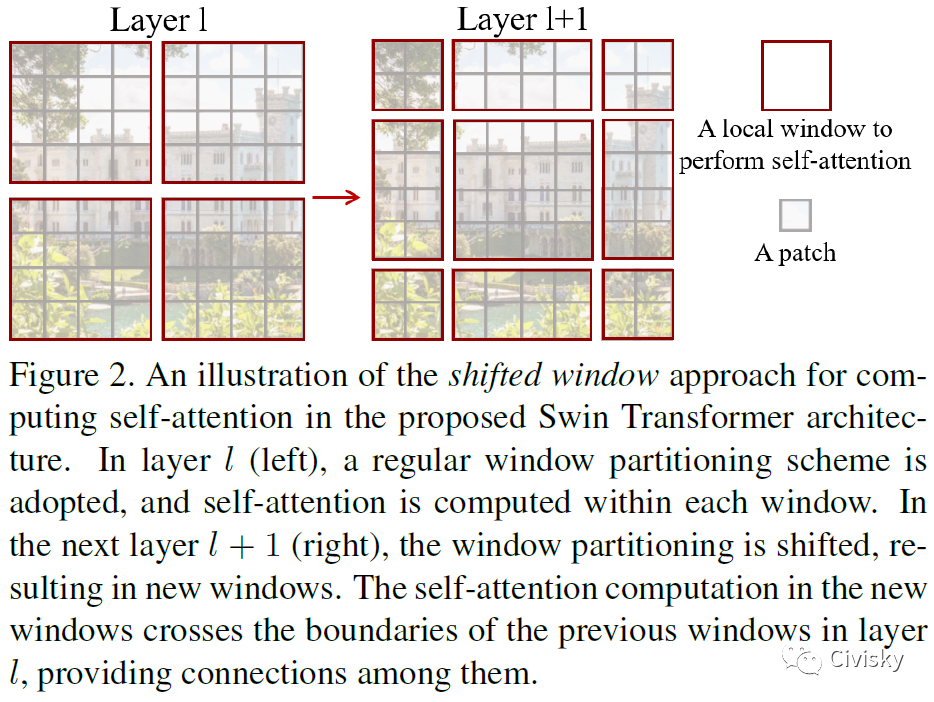
图2举例说明了Swin Transformer结构中计算Self-Attention的移动窗口方法。
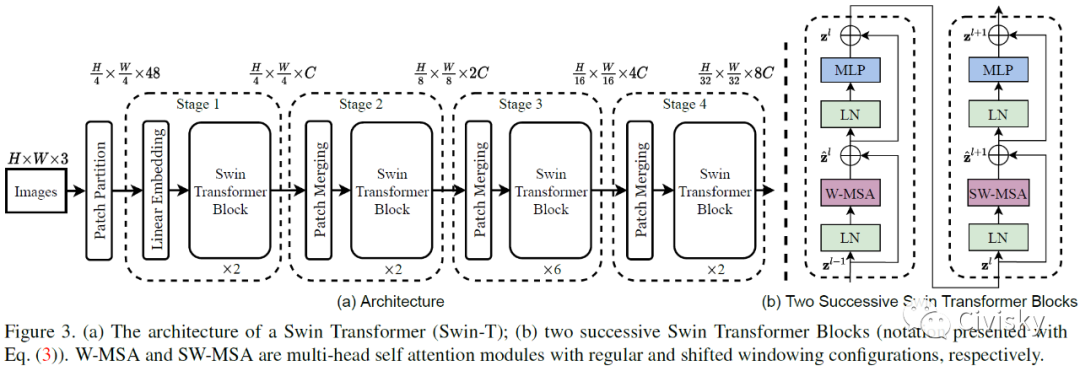
图3给出了Swin Transformer的体系架构图和两个连续的Swin Transformer块。
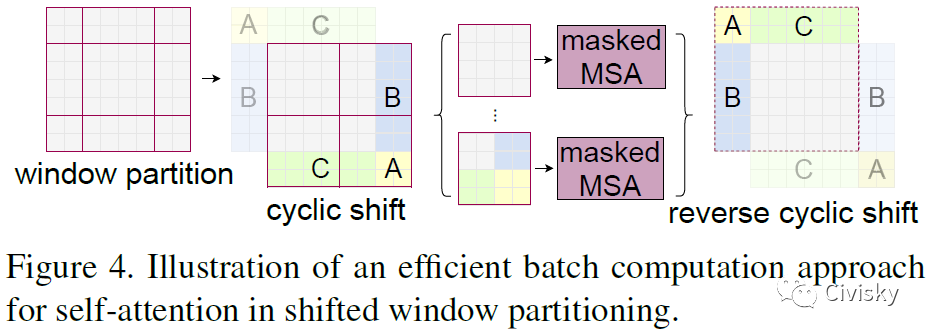
图4展示了在移动窗口分区中Self-Attention的高效批处理计算方法。
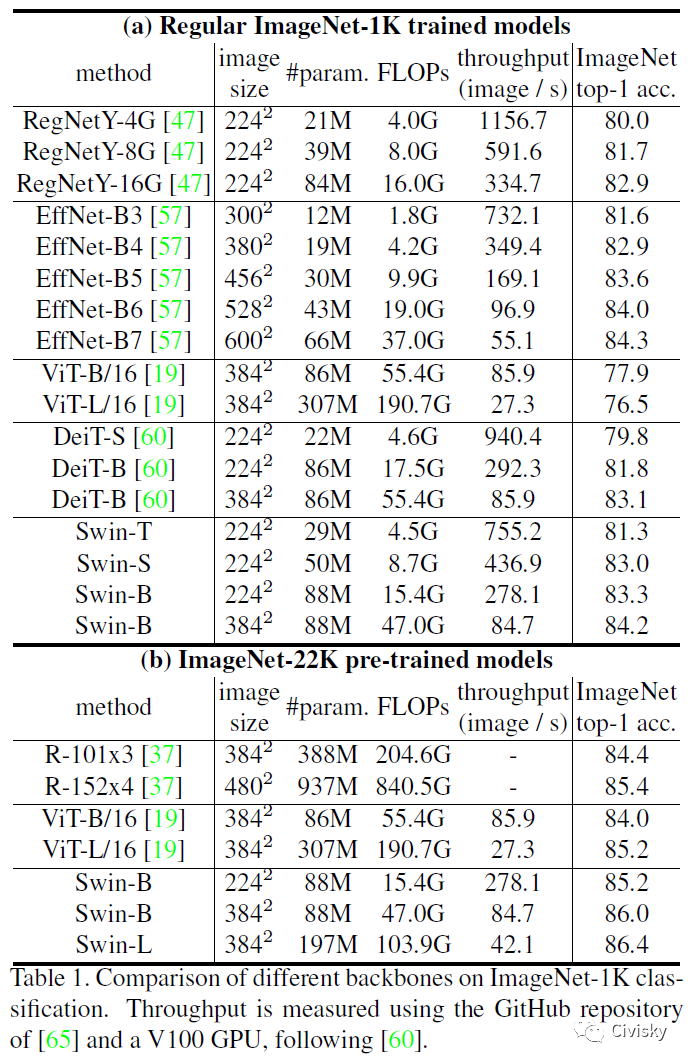
表1给出了不同Backbones在ImageNet-1K和ImageNet-22K分类任务上的实验结果。
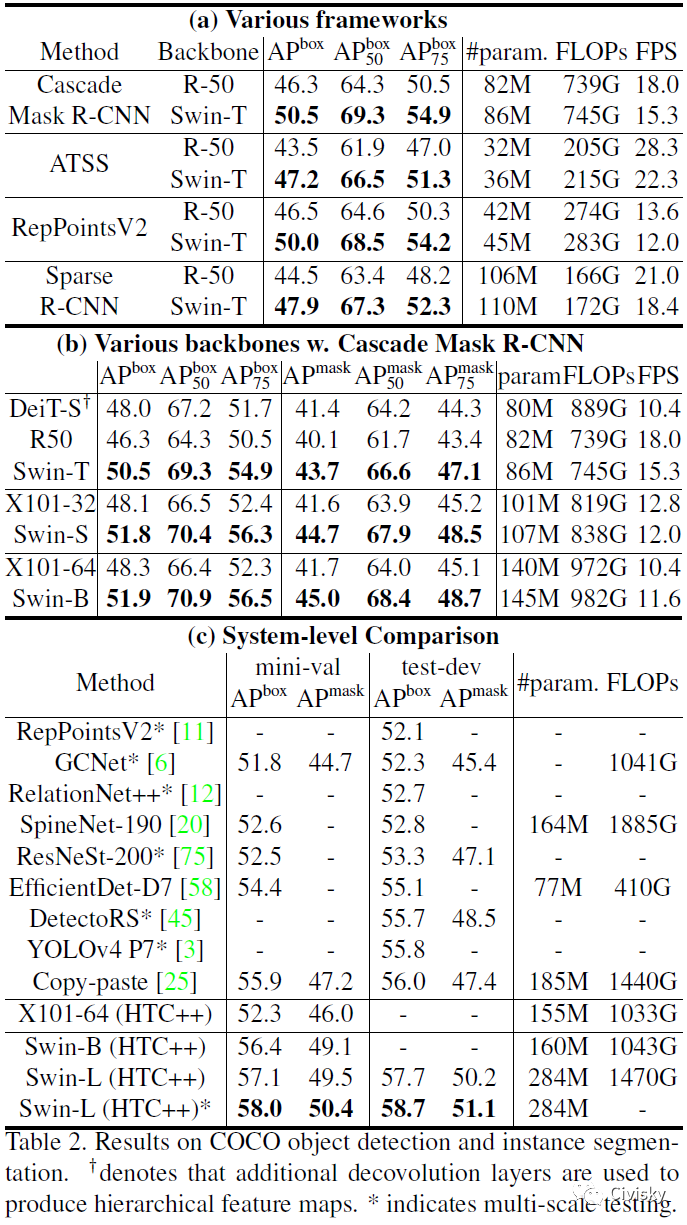
表2给出了不同模型在COCO目标检测任务上的实验结果。
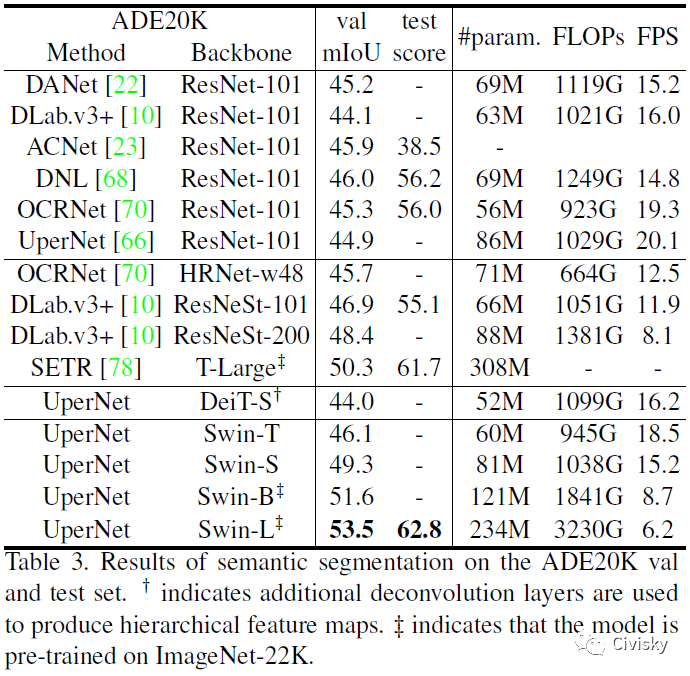
表3给出了不同方法在ADE20K语义分割任务上的实验结果。
总结
Swin Transformer可以产生层次化的特征表示,并具有与图像大小相关的线性计算复杂度。Swin Transformer在COCO目标检测和ADE20K语义分割任务上达到了SOTA水平,大大超过了以前的最好方法。Swin Transformer的强大性能有望促进视觉和语言信号的统一建模。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)