基础模型定义视觉新时代:综述与展望
在本次综述中,我们对视觉基础模型进行了全面回顾,包括结合不同模态(视觉、文本、音频等)的典型架构设计、训练目标(对比、生成)、预训练数据集、微调机制,以及常见的提示模式。进NLP群—>加入NLP交流群论文:Foundational Models Defining a New Era in Vision: A Survey and Outlook地址:https://arxiv.org/pdf
在本次综述中,我们对视觉基础模型进行了全面回顾,包括结合不同模态(视觉、文本、音频等)的典型架构设计、训练目标(对比、生成)、预训练数据集、微调机制,以及常见的提示模式。
进NLP群—>加入NLP交流群

论文:Foundational Models Defining a New Era in Vision: A Survey and Outlook
地址:https://arxiv.org/pdf/2307.13721.pdf
项目:https://https://github.com/awaisrauf/Awesome-CV-Foundational-Modelsesome-CV-Foundational-Models
用于观察和推理视觉场景的组成性质的视觉系统是理解我们的世界的基础。现实世界环境中物体及其位置、模糊性和变化之间的复杂关系可以用人类语言更好地描述,自然地受到语法规则和其他模式(例如音频和深度)的控制。
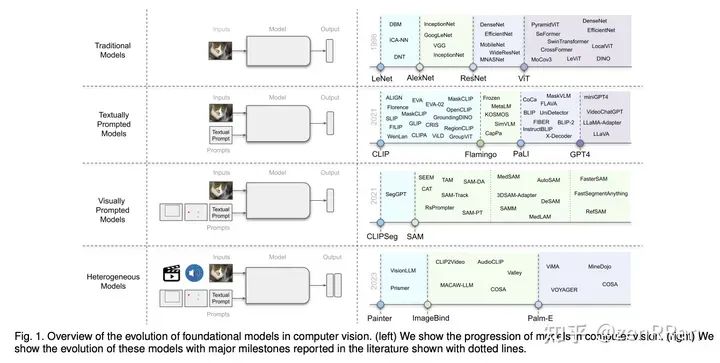
这些模型学会了弥合这些模式之间的差距,并与大规模训练数据相结合,促进测试时的上下文推理、泛化和提示能力。这些模型被称为基础模型。

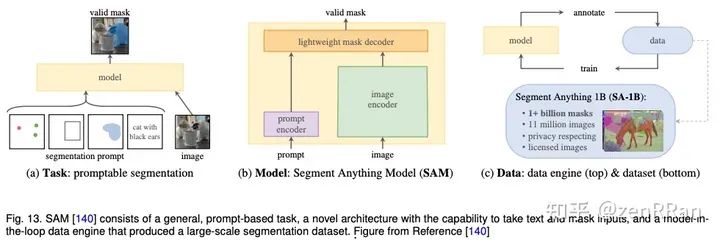
此类模型的输出可以通过人类提供的提示进行修改,而无需重新训练,例如,通过提供边界框来分割特定对象,通过询问有关图像或视频场景的问题来进行交互式对话,或者通过语言指令来操纵机器人的行为。
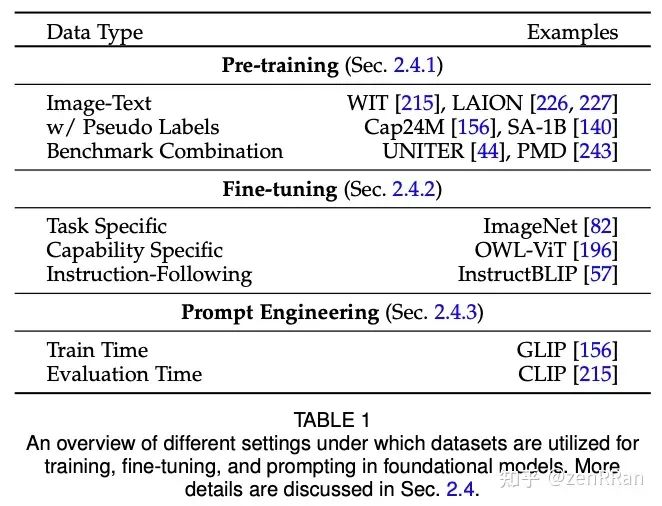
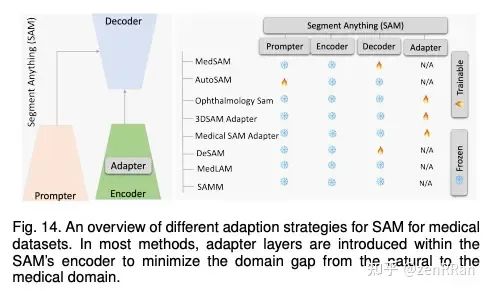
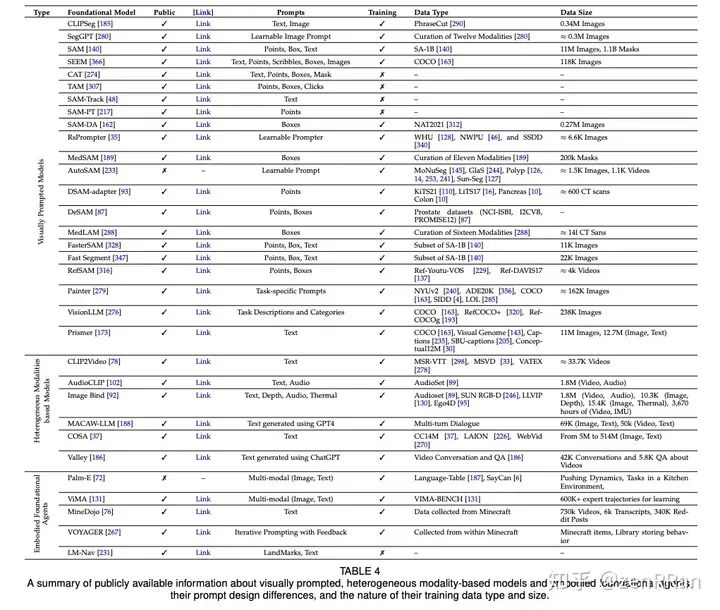
在本次调查中,我们对此类新兴基础模型进行了全面回顾,包括结合不同模态(视觉、文本、音频等)的典型架构设计、训练目标(对比、生成)、预训练数据集、微调机制 ,以及常见的提示模式;文本、视觉和异构。
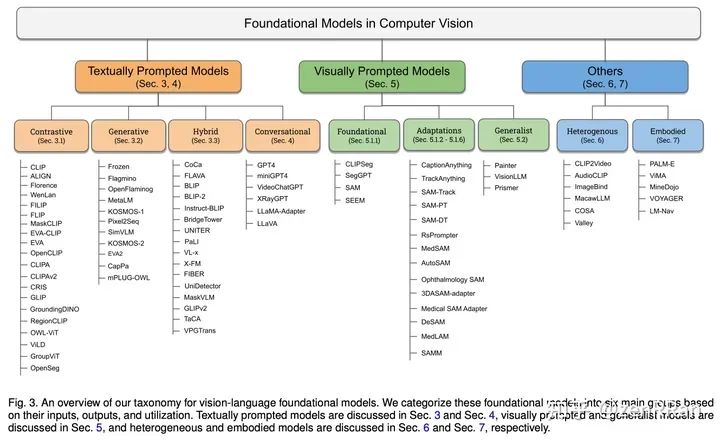
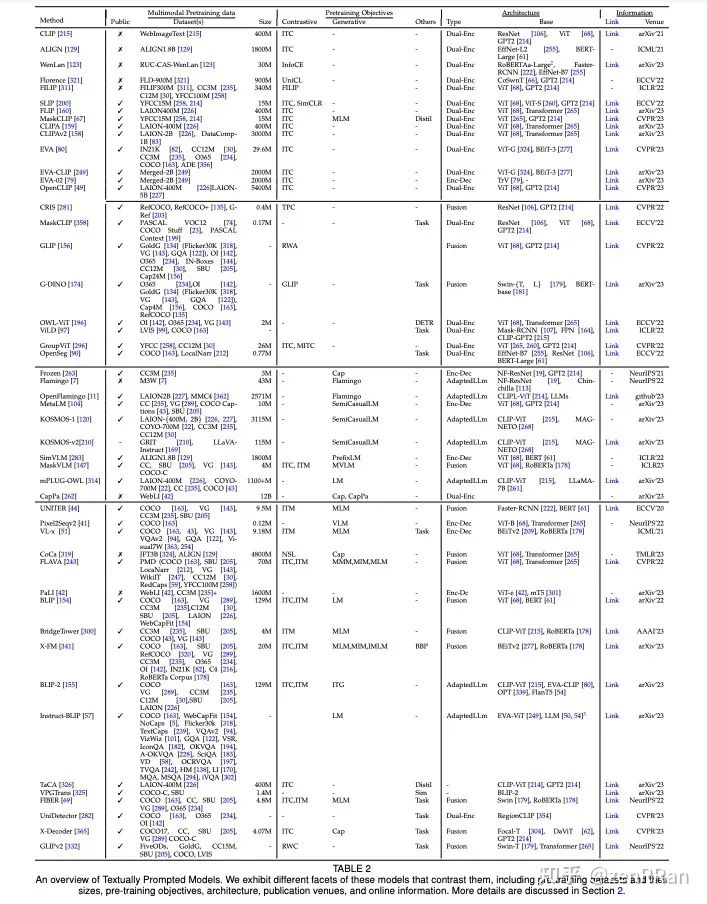
我们讨论计算机视觉基础模型的开放挑战和研究方向,包括评估和基准测试的困难、现实世界理解的差距、上下文理解的局限性、偏见、对抗性攻击的脆弱性和可解释性问题。

我们回顾了该领域的最新发展,系统、全面地涵盖了基础模型的广泛应用。

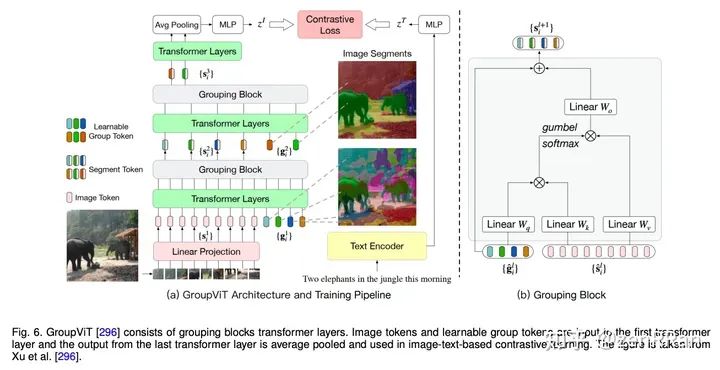


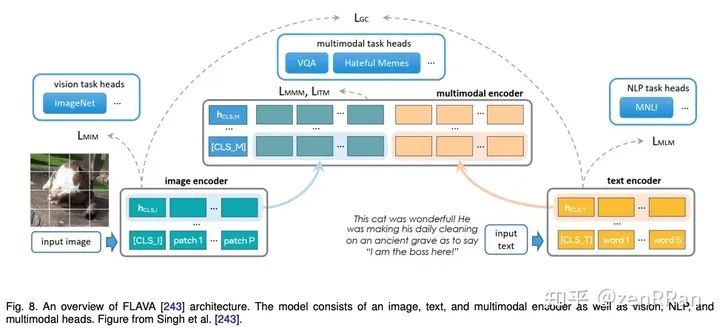
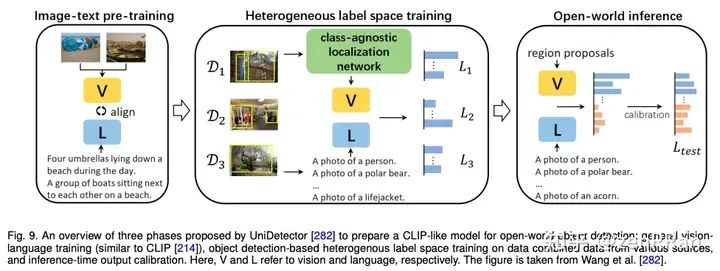
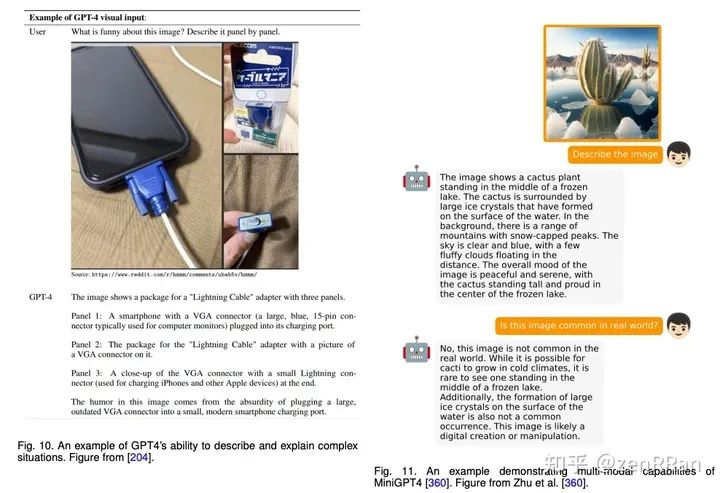


进NLP群—>加入NLP交流群

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献372条内容
已为社区贡献372条内容

所有评论(0)