傅里叶变换处理音频c++_KWS-SoC——基于Wujian100的音频流关键词检测SoC拓展开发笔记之一...
Keyword Spotting(KWS, 关键词检测),目的是在一串连续的音频流中检测出预定义的词或者词组。在实际应用中,比如手机的智能助手,智能住宅里所支持的语音指令等,都需要用到关键词检测,当用户讲出预定义的关键词后,会触发相应的功能。一个明显的问题是,这种技术如果应用在移动终端,为了保持随时响应,需要连续不间断的运行来侦测用户的语音请求。因此,在满足准确性的前提下尽可能地做到低功耗设计..
Keyword Spotting(KWS, 关键词检测),目的是在一串连续的音频流中检测出预定义的词或者词组。在实际应用中,比如手机的智能助手,智能住宅里所支持的语音指令等,都需要用到关键词检测,当用户讲出预定义的关键词后,会触发相应的功能。
一个明显的问题是,这种技术如果应用在移动终端,为了保持随时响应,需要连续不间断的运行来侦测用户的语音请求。因此,在满足准确性的前提下尽可能地做到低功耗设计,就是移动端KWS技术的目标。
KWS的技术原理:简而言之,就是首先对音频信号进行逐帧预处理,通过短时傅里叶变换或者梅尔频谱等处理,将音频数据转换为二维的声谱图,其中声谱图横坐标就是时间轴,纵坐标是其频率特征信息。因此,KWS的语音识别问题实际上可以转换为图像处理问题。传统的基于神经网络的KWS,采用了DNN或者CNN,将分类输出与预先定义的声学模型label进行比较,看是否触发关键词。
为了提高时域上的感知强度,很多KWS系统采用了RNN或者dilated CNN。然而这些方式都需要考虑到低功耗、延迟等问题。本文采用的KWS IP核是IA&C Lab的郑日雍师兄基于Vivado的HLS流程开发的,该IP核是基于DS-RNN(深度可分离卷积-循环神经网络)算法实现,在保证准确率的同时,也大幅提高了能效比,减少了内存需求,非常适合在低功耗平台中使用。最终,把IP核集成在Wujian100这个低功耗MCU平台上,使得低功耗的优势更加彰显。限于篇幅,本文不展开论述算法与其硬件实现过程,本专栏会在后续的帖子里专门介绍。
Wujian100是平头哥开源的一个基于RISC-V架构的芯片设计平台。该平台是一款平头哥半导体开发的超低功耗的MCU平台,也是一款基于安全可信系统框架与CSI标准软件接口,支持从硬件到软件到系统的全栈敏捷开发,助力客户打造面向极低功耗的MCU产品。
在此平台基础上,可以快速地进行IP核拓展并进行系统前端仿真,并对拓展的硬件设计部分进行功能验证。在制作好FPGA以后,可以通过平台提供的CDK软件集成开发环境对系统进行软件功能开发,用户可进行代码的编辑、在线仿真调试、模拟器调试、在线编程、性能分析等工作。Wujian100平台也提供了DebugServer工具,用于连接调试器和CPU在线仿真器,实现对CPU进行在线调试控制。
笔者在本篇文章中将展示将KWS加速核集成到Wujian100平台上,并且进行功能仿真的例子。最终整个系统的实现已经在github上开源:KWS-SoC
本文将简要介绍开发的过程:
1. Wujian100仿真平台的获取
首先,需要准备Wujian100平台:wujian100_open
相关的开发工具可以在平头哥芯片开放社区(OCC)里下载,包括RISC-V工具链,CDK集成开发环境以及Debug工具。
关于仿真平台的使用,平头哥芯片开放社区的在线视频中都已经详细阐述。基本上就是先在tool目录下的setup.sh中配置RISC-V工具链环境和VCS环境,然后在workdir目录下,run在case中写的测试程序即可进行仿真。
2. KWS模块的集成
由于Vivado提供了丰富的IP核以及方便的用户界面,在集成IP核时,笔者采用了Vivado 2019.2进行。具体集成的步骤如下所示
• 新建vivado工程
由于笔者采用的KWS IP核是采用HLS综合得到的,且目前仅支持PYNQ-Z1 的开发板。如果需要在其他开发板移植,需要对HLS的源码重新综合,为了简便,笔者在新建工程时直接选用了PYNQ-Z1 芯片。
• 导入wujian100平台
接下来就是在项目工程中添加源码了。将soc文件夹导入到design files中,将tb文件夹导入到simulation files中。需要注意的是,soc文件夹中有些文件是verilog header文件,tb文件都是system verilog文件,需要手动设置。
• 添加IP核传输接口
笔者用到的KWS IP核,其结构如下图所示

可以看到,IP核需要四种数据的通道,分别是:
• data_in: 需要传输的预处理后的音频帧数据
• weight: KWS IP核中神经网络中所用到的已经训练好的权重数据
• control: 用于控制权重和数据输入的信号
• data_out: 输出的数据,用于和label比较得到识别结果
除了数据通道,每个通道还有握手信号,以及表示stream传输结束的握手信号。
首先,下图是Wujian100平台的系统结构图:
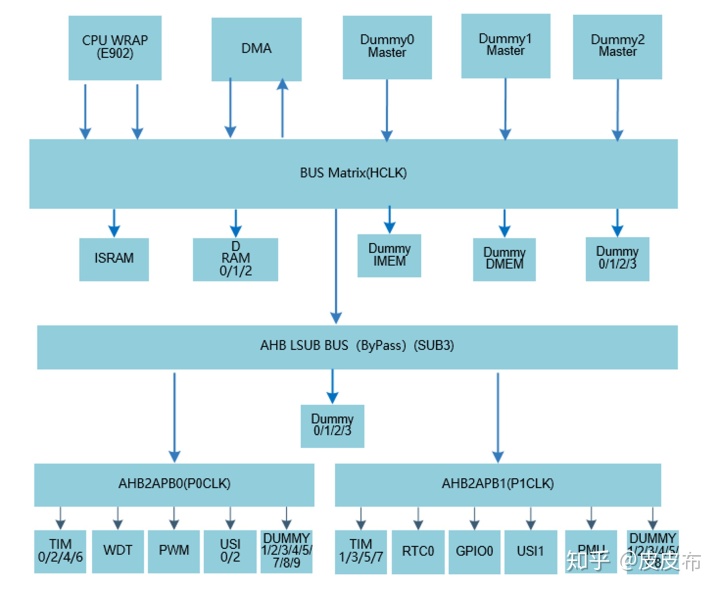
为了保证传输速度,以及方便集成,笔者直接采用了BUS Matrix(HCLK)上的Dummy0/1/2/3作为四种数据的传输通道。wujian100平台采用的是标准的AHB接口。为了能与KWS采用的axi-stream协议匹配,笔者对每个通道使用了vivado提供的ahb转axi的接口,如下图所示:

由于KWS实际没有用到完整的axi4协议,所以为了能使转换bridge正常使用,需要对其中一些没有用到的端口进行手动赋值,此处以data_in为例:
• ahb_hburst信号:该信号为ahb突发传输信号,由于wujian100暂时不支持突发传输,因此ahb的master端没有给出burst信号,因此,此处需要将值赋值3'b0,指明单次传输
• data_in_axi_awvalid信号:由于data in数据仅为写方向,所以将此信号赋值为1即可,表示写地址通道永远有效,而只将KWS的data_in_tvalid信号连接到wvalid,即写数据valid信号即可
• B通道相关信号,该通道为axi4的从设备响应通道,KWS里并没有对应的信号,因此需要对bvalid赋值恒为1,表示从设备始终响应
• 其他信号,比如和突发传输,传输错误信号等,KWS里都没有利用到,所以需要对其进行相关赋值,具体赋值可以参考开源代码。
最终集成好的IP核在SoC的层次位置,如下图所示
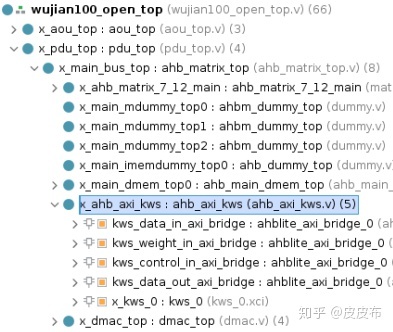
• 例化memory
实际使用中,KWS所需要载入的权重数据已经大于200k,原生的SoC提供的4块64kb的memory已经基本不能满足仿真所需的数据存储的要求。因此,笔者在ahb bus上的dmem接口例化了一个256kb的BRAM,用于存放权重数据 ,如下图所示
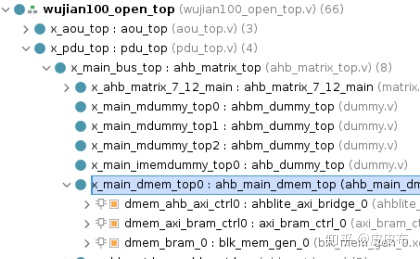
需要注意的是,vivado提供的bram controller只支持axi接口,因此,需要像上一节讲到的使用一个协议转换接口,将ahb协议转换为axi协议进行通讯。
3. 音频数据预处理
以上就是整个系统的集成过程。接下来,为了能将数据正确的存放到mem中进行仿真,需要对数据进行预处理。
由于在KWS系统中,需要首先将音频数据转换为声谱数据,这一过程可以用开源工程中的my_audio.py实现,通过调用my_mfcc将wav音频转换为梅尔频率倒谱。
为了能测试KWS的计算结果,开源工程中test_mymodel_myaudio.py 脚本实现了对40组数据进行预处理和软件模型计算的参考输出,其中346行
fingerprints = my_audio.my_mfcc(my_spectrogram) 将输入数据转化为单精度浮点数表示,350行中
prob = sess.run(net.probs[0], feed_dict = {net.fingerprint_input: fingerprints_3d}) 则是参考模型计算出的分类预测输出,也是单精度浮点表示。对于计算出的结果,其输出最大值所在的位置,对应预先模型训练好的ds_rnn_labels.txt中label的位置,则是KWS识别出的词汇。
4. KWS-SoC系统的仿真过程
• 编写仿真程序
首先在wujian100的case目录下新建仿真项目目录,新建main.c文件。然后参考doc文件夹下的user_guide对四个ahb端口的基地址端口定义:
#define DATA_IN_BADDR 0x40010000;
#define WEIGHT_IN_BADDR 0x40020000;
#define CONTROL_IN_BADDR 0x40100000;
#define DATA_OUT_BADDR 0x80000000; 然后之后就可以对端口进行读写数据了,由于笔者是计划weight放在第三步例化的bram中,data_in数据放在wujian100预留的sram1中,最终的data_out数据dump到sram0数据中,因此同样需要定义这三个地址,都可以在User_guide中查阅。
volatile uint32_t RESULT_MEM_ADDR = 0x20000000;
volatile uint32_t WEIGHT_MEM_ADDR = 0x30000000;
volatile uint32_t DATA_IN_MEM_ADDR = 0x20010000; 完成这个步骤后,就可以对对应地址进行读写,比如要将data_in的数据写到kws的ip中,就可以用这句实现
*(volatile uint32_t *) DATA_IN_BADDR = *(volatile uint32_t *) (DATA_IN_MEM_ADDR+4*j); 如果想读数据,方法同理。
在测试中,权重数据有57244个,data_in输入数据一组有490个,因此用两个for循环,就可以完成所有数据的传输。
整个数据的传输流程:参考所使用的KWS ip使用流程,依次是control写0,weight写入57244个数据,control写1,data_in写入490个数据,data_out读12个数据,control写1,然后之后可以继续写490个data_in,读12个data_out,control写1次1,以此重复...笔者测试了多组输入数据的情况,开源工程中默认的情况是只写一组数据,有需求的读者可以重写程序进行编译。
注:上述过程为CPU逐字读写数据的方式。wujian100提供了dmac可以实现将指定数量的数据从源地址搬运到目标地址,虽然也只是基于单次传输的形式,但是这种传输方式可以释放CPU的负载。本实验测试通过了DMA传输的方式,但是在开源工程中提供的程序是上述的CPU读写方式,如果有需求的读者可以参考case中的dmac示例进行重新编译程序。
程序写好以后,按照wujian100官方给出的教程对程序进行编译,笔者开发时,采用了官方提供的RISC-V工具链编译程序。但是在仿真这个步骤时,由于采用了vivado的ip,在用最新版本的vivado导出VCS仿真脚本时出现了问题,所以最终没有采用官方给出的VCS或者iverilog仿真脚本进行仿真。所以,只是采用了原版的SoC仿真平台以及官方的仿真脚本生成指令。
因此,此步骤最好直接用原版的wujian100开源平台进行编译,否则会在仿真步骤报错(对编译没有影响)。
编译完成后,会在workdir目录下生成仿真需要用到的16进制指令文件test.pat
• 在vivado中进行仿真
有了上述生成的16进制指令,就可以对整个KWS-SoC进行仿真了。在仿真之前,需要做一些准备工作:
首先需要将输入单精度浮点数据转换为16进制,此过程可以用到开源工程中的float2hex.py脚本,此脚本将40组数据转换为16进制数据,同样也对weight数据进行转换。
然后需要在testbench中,在SoC复位后,首先将上一步的程序写入wujian100的isram中,然后wujian100的core才能正常取值译码执行等。此过程wujian100平台在testbench中已经给出,读者只需要把path改为上一步workdir的路径。
接下来,把输入数据放到ram中
for(j=0;j<32'h490;j=j+1)
begin
data_one_word[31:0] = data_temp_mem_set1[j];
wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms1_top.x_sms_sram.x_fpga_spram.x_fpga_byte3_spram.mem[j][7:0] = data_one_word[31:24];
wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms1_top.x_sms_sram.x_fpga_spram.x_fpga_byte2_spram.mem[j][7:0] = data_one_word[23:16];
wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms1_top.x_sms_sram.x_fpga_spram.x_fpga_byte1_spram.mem[j][7:0] = data_one_word[15:8];
wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms1_top.x_sms_sram.x_fpga_spram.x_fpga_byte0_spram.mem[j][7:0] = data_one_word[7:0];
end
然后需要将权重数据放入BRAM中,由于权重数据太多,笔者直接通过在例化BRAM时,指定coe初始化文件的方式写入了权重数据
最后是输出结果写入到ram中,因此在busmnt.v中添加dumpmemory的部分
for(k=0;k<32'd12;k=k+1)
begin
$fwrite(DATA_FILE_1, "%x" , wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms0_top.x_sms_sram.x_fpga_spram.x_fpga_byte3_spram.mem[k]);
$fwrite(DATA_FILE_1, "%x" , wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms0_top.x_sms_sram.x_fpga_spram.x_fpga_byte2_spram.mem[k]);
$fwrite(DATA_FILE_1, "%x" , wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms0_top.x_sms_sram.x_fpga_spram.x_fpga_byte1_spram.mem[k]);
$fwrite(DATA_FILE_1, "%xn" , wujian100_open_tb.x_wujian100_open_top.x_retu_top.x_smu_top.x_sms_top.x_sms0_top.x_sms_sram.x_fpga_spram.x_fpga_byte0_spram.mem[k]);
end 最终结果会把ram中的结果输出到测试文件夹中,格式为16进制
接下来就可以Run simulation开始仿真,因为系统规模较大,因此仿真需要的时间比较久。
• 数据后处理
最终,在测试文件夹中可以得到输出结果。为了得到最终的数据,可以用hex2float.py脚本进行16进制到浮点数的转换,读者可以将转换后的结果与参考模型计算出的结果进行比对。同时,此脚本也会根据ds_rnn_label,最终print出预测的结果。
5. 总结
笔者在wujian100开源平台上进行了拓展,将已有的IP核集成到soc平台上并成功地进行了仿真验证。当然,此过程仍有可以改进的地方,第一是可以把之前提到的所有过程集成到一个脚本中,减少人力操作的成本。第二是可以继续生成bitstream,将SoC烧进板子中,继续用官方提供的CDK和debug工具进行开发,最终可以实现上位机和板子之间的自动传输通讯。第三点是可以优化SoC的结构,比如control端口,其实并用不到ahb的高传输速率的特性,可以用另外的方式简化接口,减少所用到的硬件资源。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)