【深度视觉】第十一章:语义分隔
而Unet在医疗图像分隔领域之所以这么好,我感觉是:我们知道浅层卷积关注的是图像的纹理特征,就是关注的是图像的细节点,而深层卷积则关注的是高层语义信息,就是图像的轮廓等更大感受野的信息。因为通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回是非常有意义的。分
十三、语义分隔
前面讲的都是视觉识别中的图像分类任务以及图像分类的几个经典算法,下面我们开始语义分隔任务。
(一)什么是语义分隔、语义分隔的思路
1、视觉识别的四大任务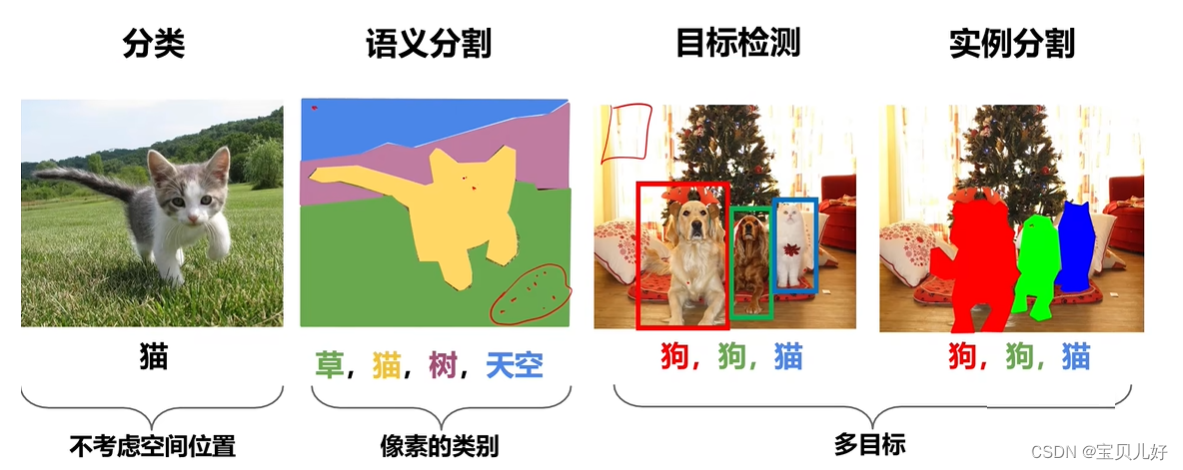
分类任务:就是用我们前面讲的经典架构和前沿网络来对图像进行分类,看图像是猫还是狗还是汽车还是青蛙的这种整图的分类任务,就是给一个整图打一个标就好了。
语义分隔:是像素级的分类任务,就是对图像中的每个像素都进行分类。就是对原图的每个像素都分是猫还是草还是树还是天空等这种分类任务。
目标检测:是在图像的区域中进行分类,就是滑窗滑动,判断滑窗图像的类别。相当于是区域级的分类问题。
实例分隔:也是像素级的分类任务,但比语义分隔更复杂。实例分隔是在语义分隔的基础上,还得分狗A狗B猫A猫B。就是不仅要区分一个像素是不是目标像素,还得区分这个像素是谁,是狗A还是猫B呀?
可见,分类、目标检测、语义分隔、实例分隔都是分类任务,只是对图片识别的程度不一样,所以它们对应的标签也是不一样的。
分类是对图像了解程度最浅的一个任务,分类模型得到的信息也是最少的,也就是标签只有"是"或"不是"这种简单的信息。
目标检测,模型得到的信息是一个区域级的信息,也就是训练数据的标签是图像某些区域的"是"或"不是"这种信息。
语义分隔,其训练数据的标签是一个像素级的标签。
实例分隔的标签就是基于实例的像素级,就是不仅要告诉你这个像素"是"或"不是",还得告诉你这个"是"的像素是谁。
也所以,目标检测模型、语义分隔模型、实例分隔模型都是基于前面我们学的googlenet、resnet或者VGG改进而来的。
2、语义分隔思想及原理
就是给每个像素分配类别标签,不区分实例,只考虑像素类别。
(1)语义分隔思路1: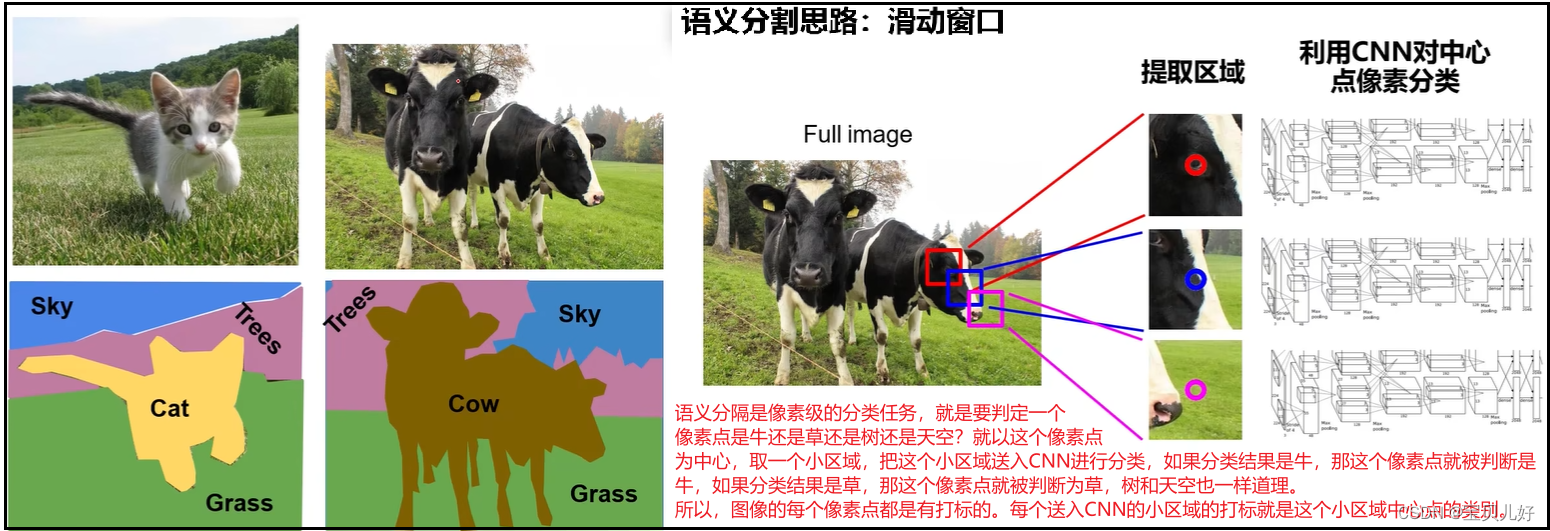
只要我们指定窗口的尺寸,上图的语义分隔思想就是可行的。但是这种操作效率太低!重叠区域的特征反复被计算,就是相邻很近的像素周围的区域不断被送入CNN被重复不断地进行特征计算,这样就非常低效。为了避免重复计算,就出现了全卷积神经网络。我们知道卷积层本来就是提取特征的,全卷积网络就可以一次性把一整张图的特征都计算出来,那所以最后只要一次性输出所有像素的类别即可:
(2)语义分隔思路2: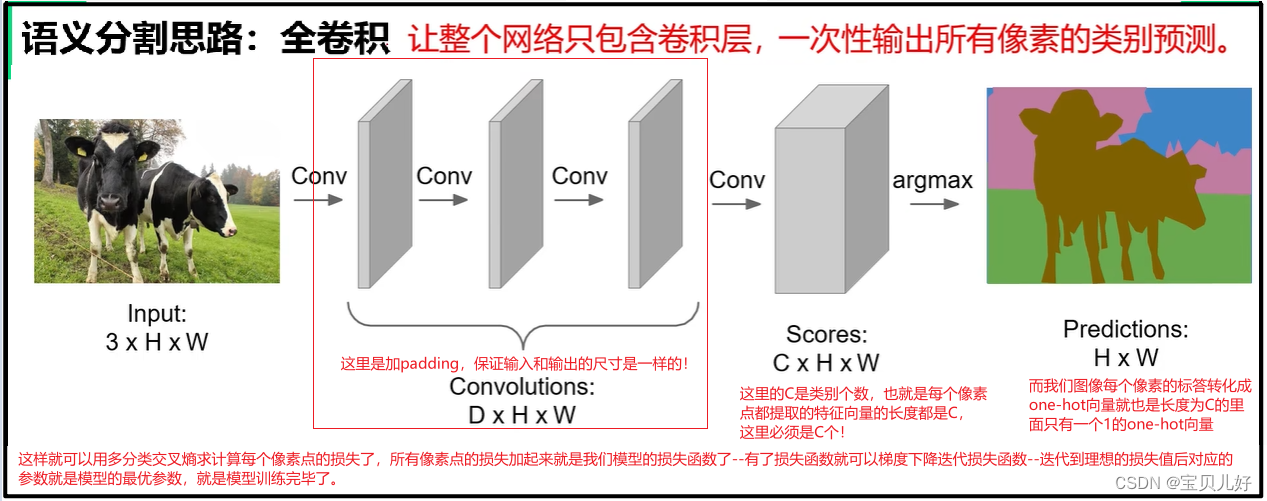
这种思路我们就基本不怎么care输入图像的尺寸了,只要我们只要padding保证上图红框部分的尺寸和原图一直保持一致就可以了。
上图我们的标答是一个四分类:牛、天空、草地、树,所以每张图片的每个像素的标答的one-hot形式就是长度为4,也就是上图的C就得是4。
思路2虽然比思路1的计算量小了,但也有很明显的弊端就是:处理过程中一直保持原始分辨率,对显存的需求就会非常庞大。我们知道要想提取更复杂的特征和语义就得加深网络,那特征图如果一直保持很大的尺寸,深度就必然要受到算力的制约!我们知道VGG加深网络是在不断减半特征图的基础上加深网络的,就这样vgg的参数都是天量的了。我们知道在CNN网络中,所有向前传播的参数和中间结果都是要保存的,用来反向传播计算梯度的,如果前向的变量实在是太多,硬件肯定是支撑不了的。所以对于大尺寸图片思路2也是无能为力的。
(3)语义分隔思路3: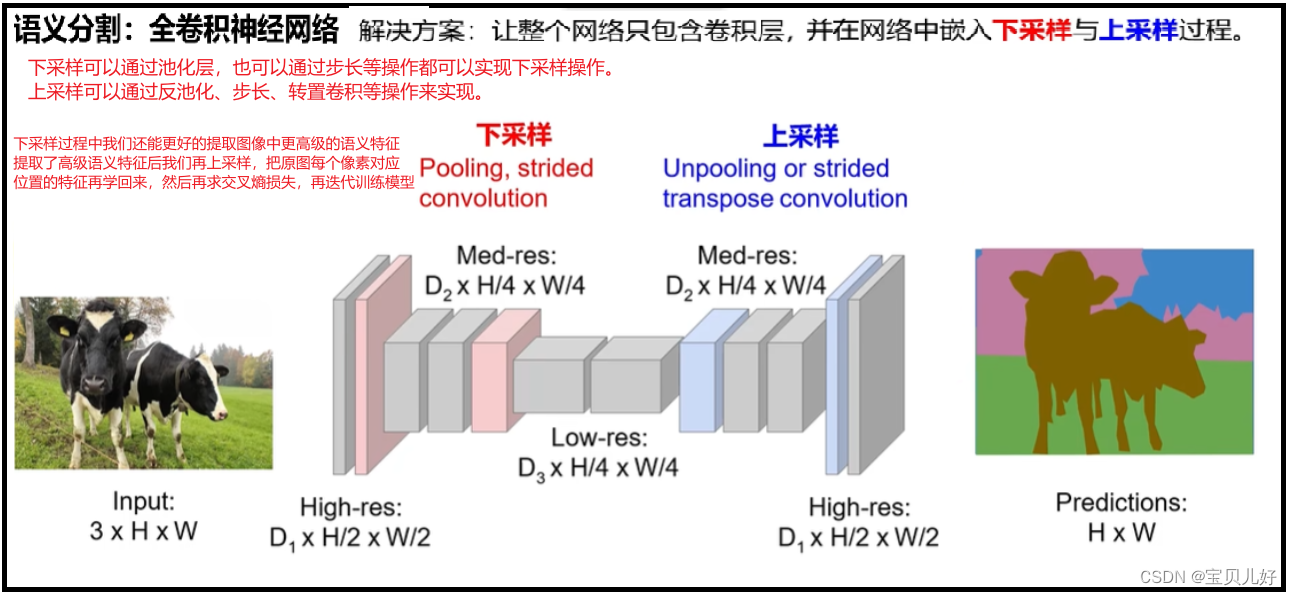
至于上下采样的具体实现方法,我们的【深度视觉】第五章:卷积网络的重要概念及花式卷积,中的转置卷积部分写的非常清楚,有相关实现的api,大家可以参考。
另外,上图中的D1是必须等于类别个数的,和上图的C的值是一样的!
(二)语义分隔经典模型:U-Net 及其代码实现
1、U-Net简介
U-Net可以说是最常用、最简单的一种分割模型了,简单、高效、易懂、易构建、可以从小数据集中训练,是2015年《U-Net: Convolutional Networks for Biomedical Image Segmentation》提出的模型。论文连接:https://arxiv.org/abs/1505.04597 大家可以自行下载原论文阅读。
2、U-Net和FCN、Autoencoder之间的渊源
首先,U-Net和FCN都是在Autoencoder(AE)之后提出的,也就是说U-Net和FCN都是借鉴了Autoencoder的思想框架。Autoencoder是自动编码器,也就是编码和解码(encoder-decoder),早在2006年就被Hinton大神提出来并发表在nature上了,此后,经过业界的魔改,现在已经形成自动编码器家族Autoencoders,这个家族是深度学习领域经典的无 监督网络一派,不仅用在语义分隔,在图像生成领域、图像降噪、图像压缩、风格迁移等领域也是有不可撼动的绝对地位的。下图是自动编码器的网络架构: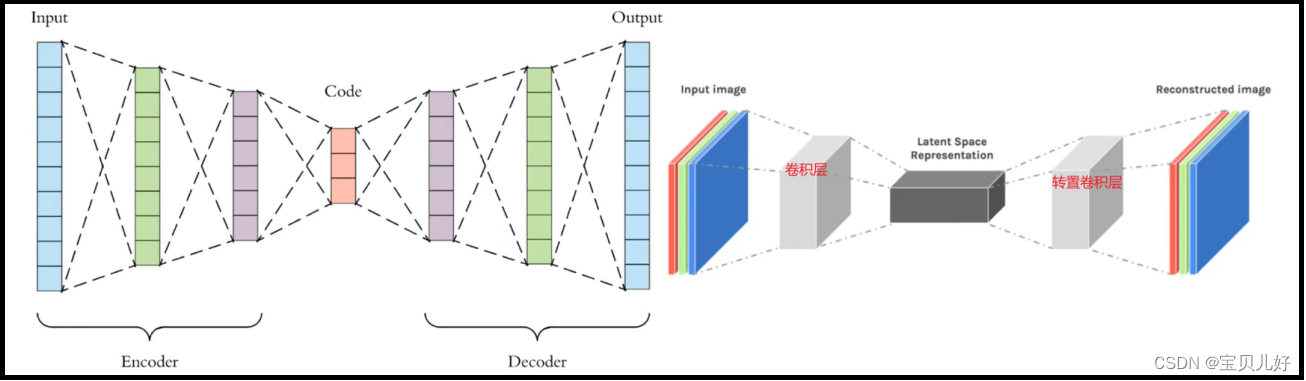
其次,U-Net比FCN(Fully Convolutional Netowkrs)稍晚提出来,但都发表在2015年。和FCN相比,U-Net的第一个特点是完全对称,也就是左边和右边是很类似的,而FCN的decoder相对简单,只用了一个deconvolution的操作,之后并没有跟上卷积结构。第二个区别就是skip connection,也就是特征图融合环节,FCN用的是加操作(summation),就是把特征图对应位置的特征值相加来融合特征;U-Net用的是叠操作(concatenation),就是通过通道数的拼接,形成更厚的特征,当然这样会更佳消耗显存。
再次,在U-Net和FCN被提出后的几年中,有很多很多的论文去讲如何改进U-Net或者FCN,不过这个分割网络的本质的拓扑结构是没有改动的。举例来说,在ICCV上何凯明大神提出的Mask RCNN,相当于一个检测,分类,分割的集大成者,我们仔细去看它的分割部分,其实使用的也就是这个简单的FCN结构。这说明了这种“U形”的编码解码结构确实非常的简洁,并且最关键的一点是好用。
最后,从论文中我们可以知道,Unet提出的初衷是为了解决医学图像分割问题,而且unet也确实在这个领域大放异彩,效果非常好,目前大多数医疗影像语义分割任务都会首先用Unet作为baseline。而Unet在医疗图像分隔领域之所以这么好,我感觉是:我们知道浅层卷积关注的是图像的纹理特征,就是关注的是图像的细节点,而深层卷积则关注的是高层语义信息,就是图像的轮廓等更大感受野的信息。但是不管是深层特征还是浅层特征都是有各自的意义的。而医疗影像语义较为简单、结构固定。因此语义信息相比自动驾驶等较为单一,因此并不需要去筛选过滤无用的信息。医疗影像的所有特征都很重要,因此低级特征和高级语义特征都很重要,所以U型结构的skip connection结构(特征拼接)就能更好的派上用场。因为通过反卷积得到的更大的尺寸的特征图的边缘,是缺少信息的,毕竟每一次下采样提炼特征的同时,也必然会损失一些边缘特征,而失去的特征并不能从上采样中找回,因此通过特征的拼接,来实现边缘特征的一个找回是非常有意义的。
3、U-Net架构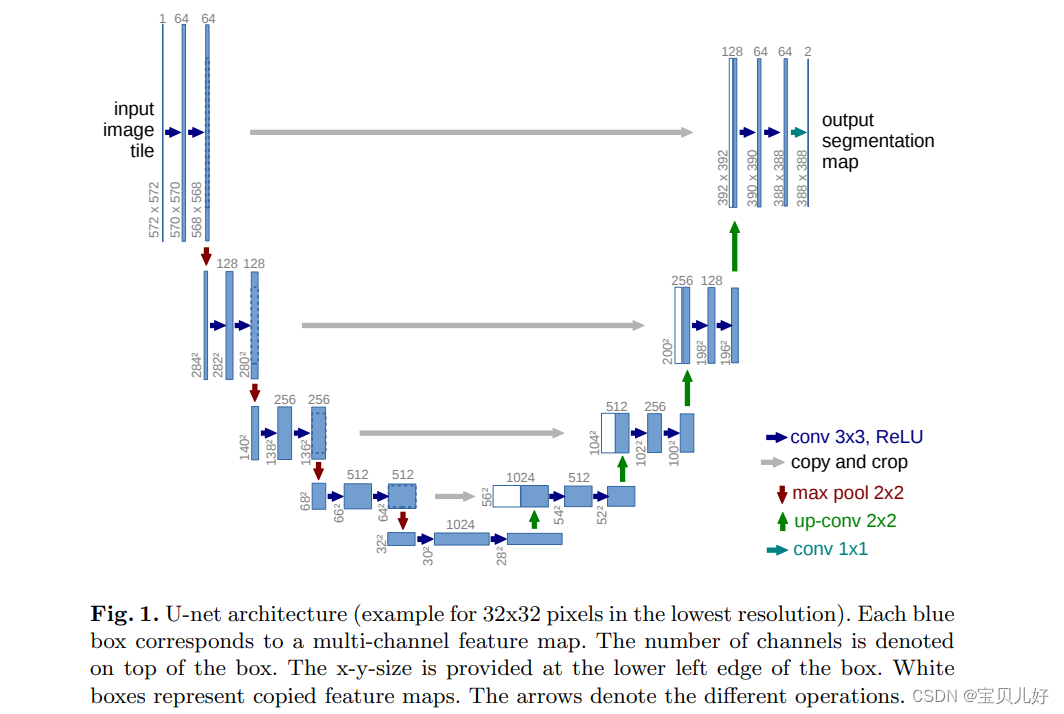
上图架构是U-Net原论文中的架构图,这个架构相对googlenet和resnet已经非常简单了,所以我也简单介绍一下:
这个架构呈现U型,左边部分就是用传统的卷积层不断实现下采样效果,不断提取图像特征,将图像信息进行压缩,或者说就是enconding的过程;右边部分就是用传统的转置卷积不断地对图像进行上采样,就是decoding的过程;中间的skip connection就是把对应左边的特征图进行crop and copy,就是先crop(因为从架构图上看,很明显左边的特征图尺寸和右边的不一样!所以必须得先crop),然后再concat。
下面的代码是我严格按照上面架构图写的架构代码,完全是我自己的风格写的,所以仅供参考:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms.functional as TF
class downsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.down = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, bias=False),nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)
)
def forward(self, x):
return self.down(x)
class upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.up(x)class Unet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.block1 = downsample(1,64) #in(1,572,572)-(64,570, 570)-(64,568,568)
self.maxpool1 = nn.MaxPool2d(2) #out(64, 284,284)
self.block2 = downsample(64, 128) #out(128, 282,282)-(128, 280,280)
self.maxpool2 = nn.MaxPool2d(2) #out(128, 140, 140)
self.block3 = downsample(128, 256) #out(256, 138, 138)-(256, 136, 136)
self.maxpool3 = nn.MaxPool2d(2) #out(256, 68, 68)
self.block4 = downsample(256, 512) #out(512, 66, 66)-(512, 64, 64)
self.maxpool4 = nn.MaxPool2d(2) #out(512,32,32)
self.block5 = downsample(512, 1024) #out(1024,30, 30)-(1024, 28, 28)
self.block6_1 = upsample(1024, 512) #out(512,56, 56)
self.block6_2 = downsample(1024, 512) #in(1024,56,56)-out(512,54, 54)-(512,52,52)
self.block7_1 = upsample(512, 256) #out(256,104, 104)
self.block7_2 = downsample(512, 256) #in(512,104, 104)-out(256,102,102)-(256,100,100)
self.block8_1 = upsample(256, 128) #out(128, 200,200)
self.block8_2 = downsample(256, 128) #in(256,200,200)-out(128,198,198)-(128,196,196)
self.block9_1 = upsample(128, 64) #out(64,392,392)
self.block9_2 = downsample(128, 64) #in(128,392,392)-out(64,390,390)-(64,388,388)
self.block9_3 = nn.Conv2d(64,num_classes,kernel_size=1, bias=False) #out(2,388,388)
def forward(self, x):
block1 = self.block1(x) #(64,568,568)
pool1 = self.maxpool1(block1) #(64, 284,284)
block2 = self.block2(pool1) #(128, 280,280)
pool2 = self.maxpool2(block2) #(128, 140, 140)
block3 = self.block3(pool2) #(256, 136, 136)
pool3 = self.maxpool3(block3) #(256, 68, 68)
block4 = self.block4(pool3) #(512, 64, 64)
pool4 = self.maxpool4(block4) #(512,32,32)
block5 = self.block5(pool4) #(1024, 28, 28)
block6_1 = self.block6_1(block5) #(512,56, 56)
block4_ = TF.crop(block4, 4,4, 56,56) #左上角的坐标、height、width
concat1 = torch.cat([block6_1,block4_], dim=1) #(1024,56,56)
block6_2 = self.block6_2(concat1) #(512,52,52)
block7_1 = self.block7_1(block6_2) #(256,104, 104)
block3_ = TF.crop(block3, 16,16, 104,104)
concat2 = torch.cat([block7_1,block3_], dim=1) #(512,104, 104)
block7_2 = self.block7_2(concat2) #(256,100,100)
block8_1 = self.block8_1(block7_2) #(128, 200,200)
block2_ = TF.crop(block2, 40,40, 200,200)
concat3 = torch.cat([block8_1,block2_], dim=1) #(256,200,200)
block8_2 = self.block8_2(concat3) #(128,196,196)
block9_1 = self.block9_1(block8_2) #(64,392,392)
block1_ = TF.crop(block1, 38,38, 392,392)
concat4 = torch.cat([block9_1,block1_], dim=1) #(128,392,392)
block9_2 = self.block9_2(concat4) #(64,388,388)
block9_3 = self.block9_3(block9_2) #(2,388,388)
return block9_3model = Unet(2)
input_data = torch.ones(10, 1, 572, 572)
output = model(input_data)
output.shape运行结果:
 看来从输入到输出是可以顺利跑通的,就也说明架构没问题。
看来从输入到输出是可以顺利跑通的,就也说明架构没问题。
(四)PASCAL VOC2012语义分隔案例展示
1、下载PASCAL VOC2012数据集
Download the training/validation data (2GB tar file),下载地址The PASCAL Visual Object Classes Challenge 2012 (VOC2012)
下载完毕后是一个压缩包,解压后的文件结构如下: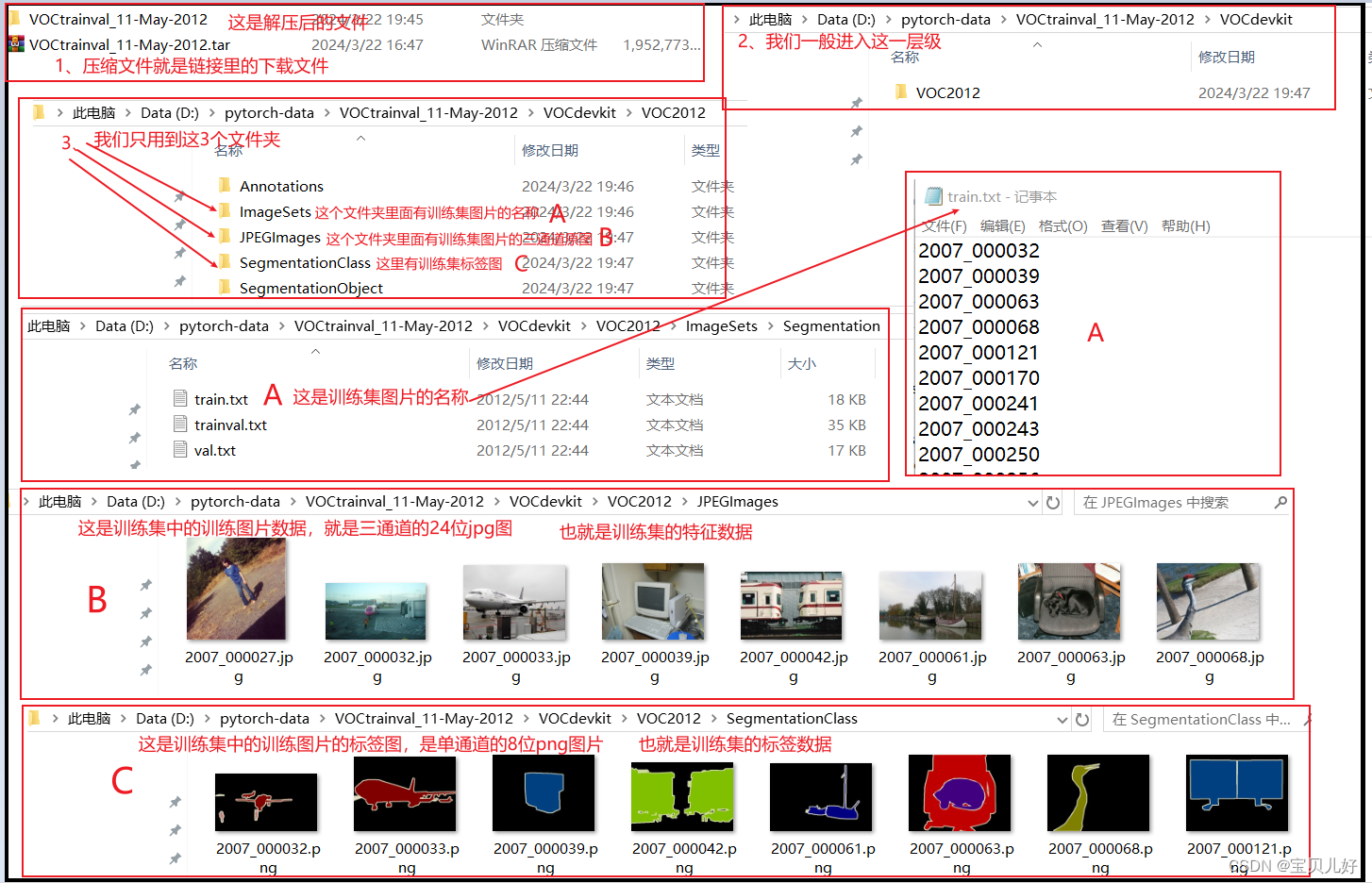
2、数据探索
我们前面说过语义分隔是像素级的分类任务,所以语义分隔任务的数据集中的标签(标答)也是细化到每个像素的。
对于Pascal VOC2012数据集上图的B就是训练集的特征数据,这个数据是24位jpg图,也就是我们常见的三通道图。
但是B对应的标答C,就非常难搞了。C在尺寸上肯定是和B对应图片的尺寸大小是相等的,但是C是一个8位的“伪彩色”图像(一般使用png格式,信息无损失),不同数字显示为不同颜色,让语义分割的结果一眼就能看出好坏。VOC2012标答C的标签类别一共有20类,分别是飞机、自行车、鸟等20种类别,再加上背景就是21个类别。使用“伪彩色”图像能让结果直观化,但是也极大的增加了数据处理的复杂度。下面我们开始数据探索,了解什么是“伪彩色”图像?什么是调色板?以及如何读取训练集的特征和标签。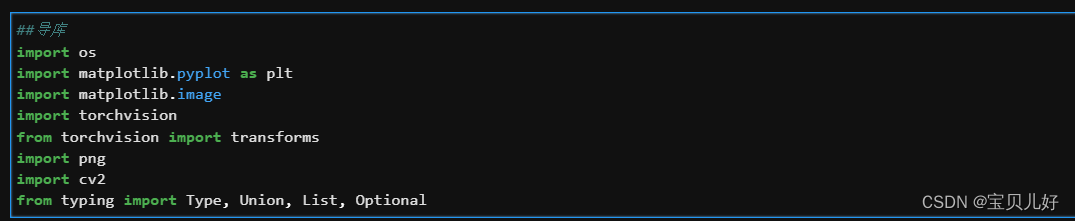
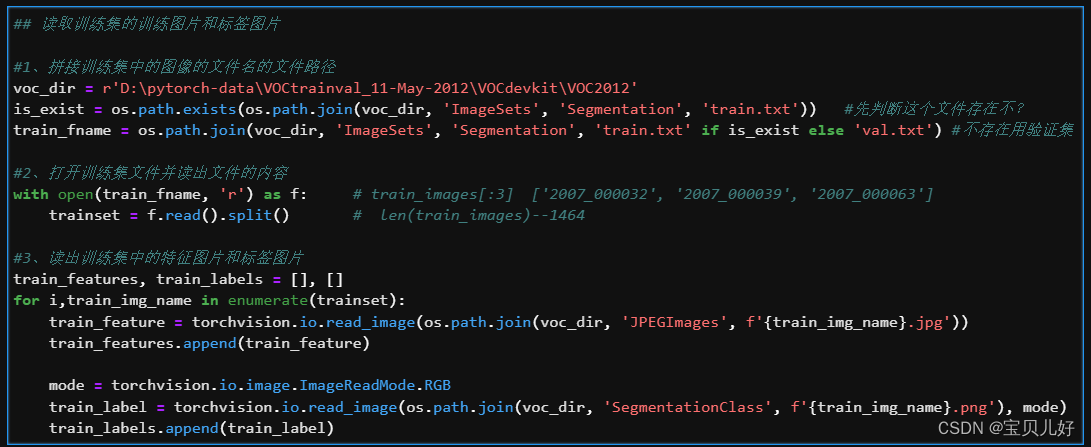
(1)特征图数据
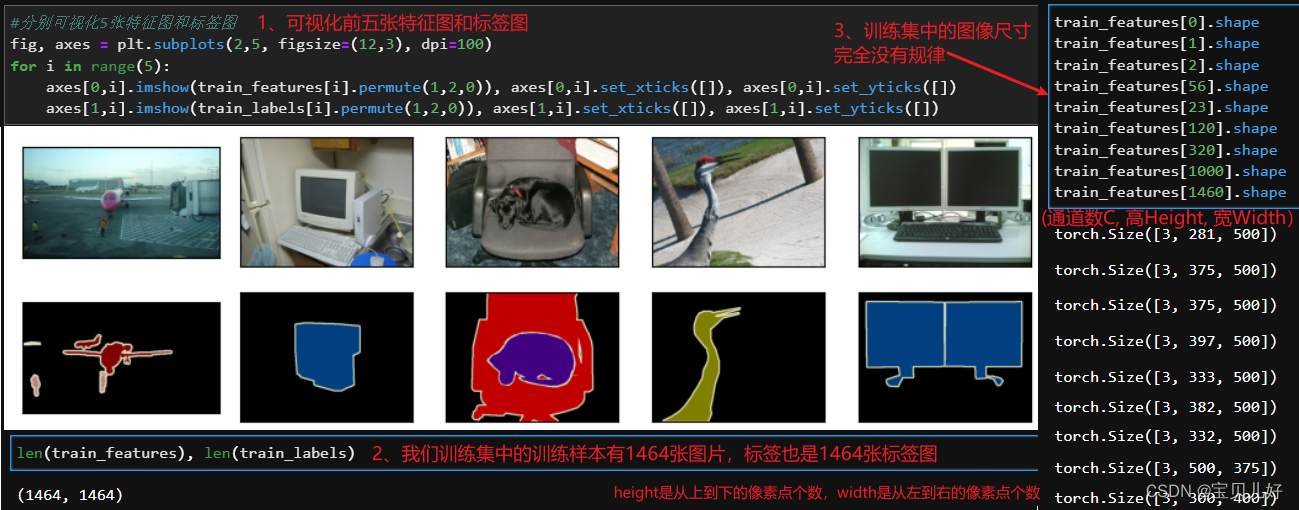
(2)标签图像数据
前面我们说了:这个数据集的标签数据是一个8位PNG格式,就是一个单通道的颜色索引图像。意思就是这个标签图像是一个单通道的图像(因为是8位嘛)。
那单通道就是一副灰度图像,灰度图像怎么能显示成彩色呢?所以每个png格式的标签图像还自带一个调色板(就是一个256个颜色值列表)!于是一个8位的数据就可以表示成32位的彩色了!也所以叫伪彩色!如下图的红框中所示:png图像是用8位存储的,也就是图像的数据是(0,256)之间的数字;当要显示该图像的时候,(0,256)这些数字就唯一对应一组(R,G,B)数值,这个对应关系就是调色板,这样8位的灰度图像就可以显示成32位的彩色图像了,此时的彩色图像就是一个伪彩色图像。
下图其余部分是VOC2012语义分隔数据集的调色板信息:像素值0代表背景,255代表边界,1~20为20个类别。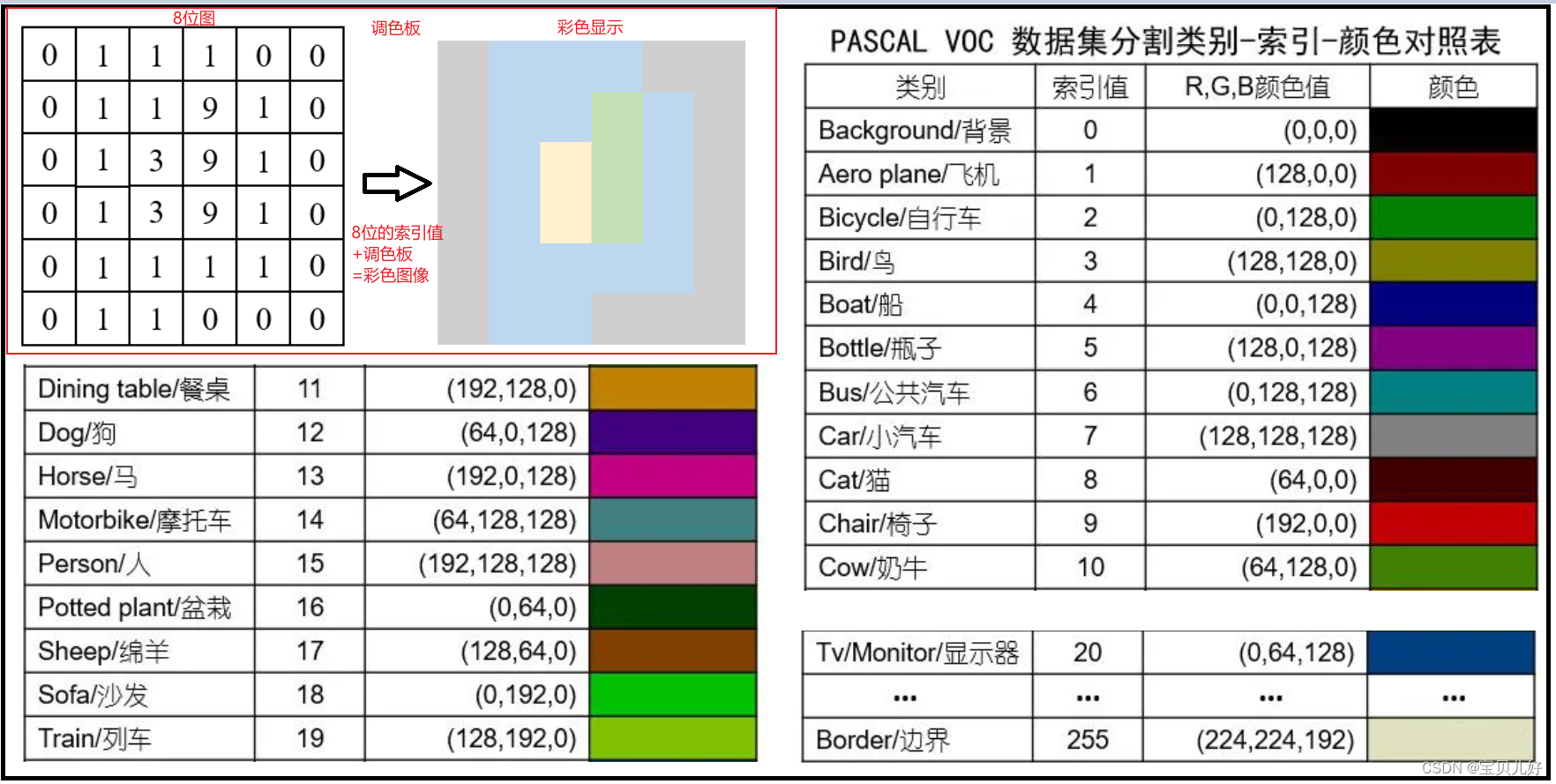
查看、并验证我们训练集标签图像的调色板信息是不是都一样: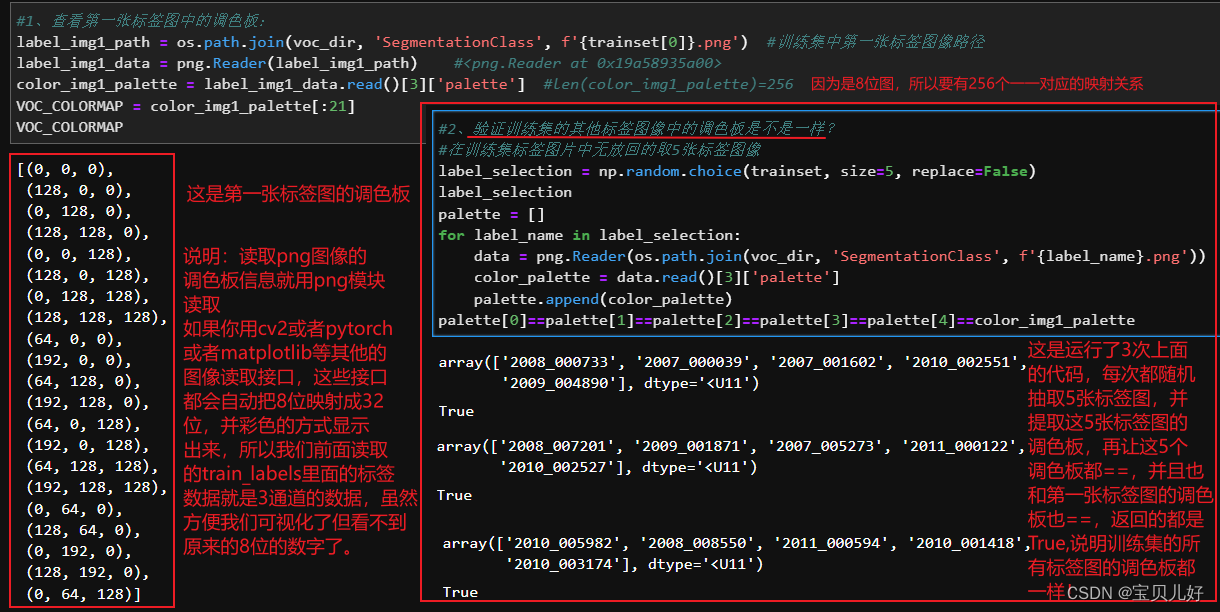
(3)处理标签数据:构建从RGB到VOC类别索引的映射
因为我们训练模型时的损失计算是:每张图片对应位置像素之间的交叉熵作为损失的,所以标签图片的每个像素点的值应该是0-20,所以要找到标签图像每个像素点对应的VOC类别标号。
这里面是有一个公式:位置信息都从这个公式(R*256+G)*256+B中算得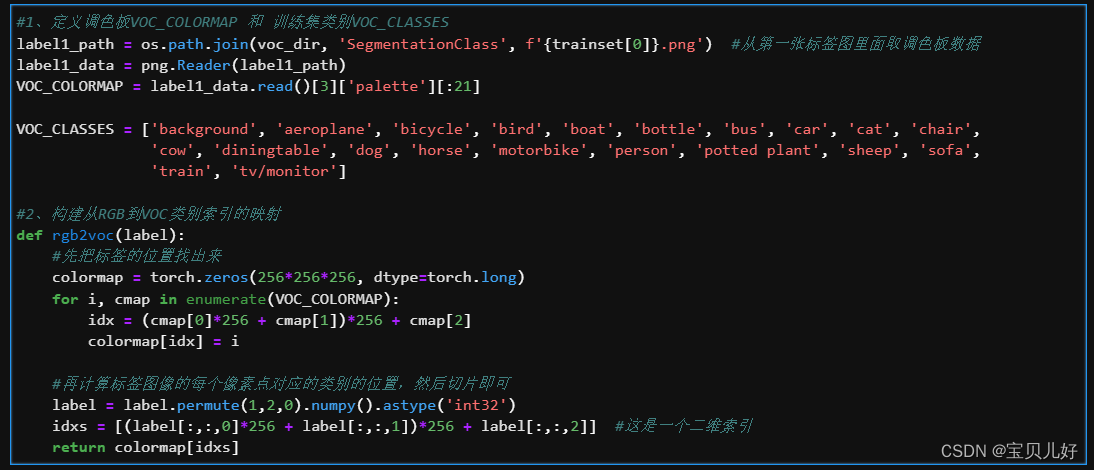
下面我们验证一下上面的函数对不对,就是看看映射关系对不对: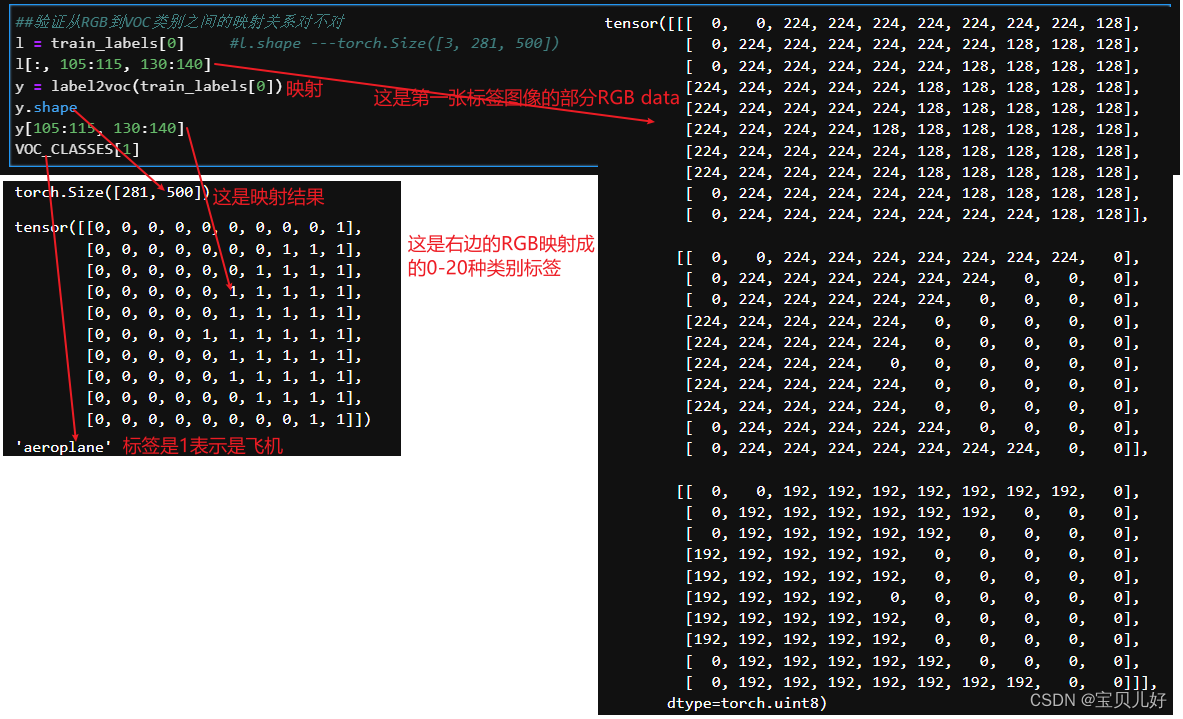
可见我们的映射是正确的。就是我们读取的train_labels里面的标签图像,我们放入rgb2voc()函数,就得到这张标签图像的每个像素点的类别。
3、数据预处理、数据增强
此时我们要考虑一下几点:
(1)我们的训练集和测试集是什么?
这是我们的训练集和验证集:
也就是说,现在train.txt里面的图片名是有原图和标签图的,原图在JPEGImages里面,标签图在SegmentationClass里面。
val.txt里面的图片名也是有原图和标签图的,原图也在JPEGImages里面,标签图也在SegmentationClass里面。
也就是说,对于这个数据集,我们要想做语义分隔,就只能用这1464+1449=2913张图片了,其他图片没有标签我们没法用啊。因为虽然JPEGImages里面有17125张图片,但SegmentationClass里面只有2913张图片,也就是train.txt和val.txt里面的所有图片。
基于以上分析,这个数据量实在是有点小,为了避免过拟合,我们训练集和测试集都用trainval.txt文件里面的图片,其中训练集我们随机取2500张图片,测试集我们用剩下的413张图片。
(2)图像尺寸问题?
我们知道,输入Unet模型进行训练的数据一定是要尺寸事先规定好的尺寸,但本训练集和验证集的数据尺寸都大小不一!所以要先确定输入数据的尺寸,这里我们先暂定256x256这样的尺寸吧,因为如果输入图像尺寸太大,硬件又跟不上,很难训练了。
那定这个尺寸行不行呢?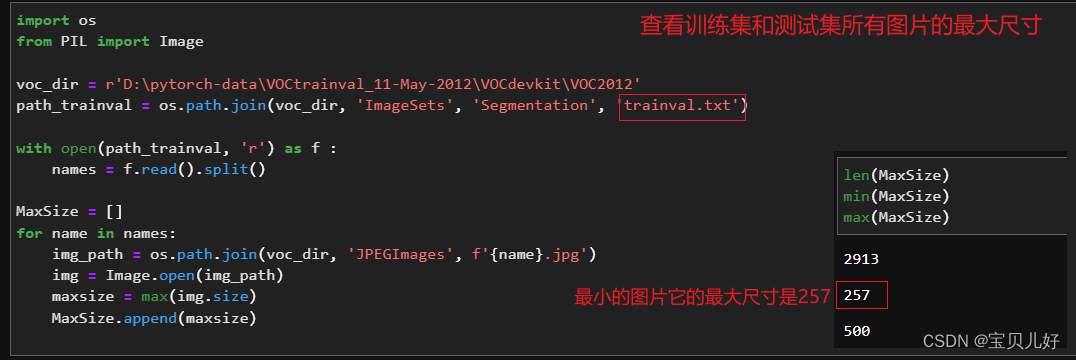
可见,我们训练集和测试集所有图片的最大边最少也是257的,所以我们选择输入数据是256x256是没问题的。
但是现在就又出现一个问题:如果把这些图片都信息无损得变成256x256呢?我查找资料看到一个最靠谱的方法是:先生成一个和图片最大尺寸一样的方形黑底图(就是所有像素都是(0,0,0)),然后把图片贴到这个大黑方形图上,然后再resize到256x256。这里我们就也采用这种方法。
这里要说明的是,我们的特征图(就是JPEGImage里面的2913张图)的尺寸是和对应的SegmentationClass里面的标签图的尺寸是一样的。
(3)数据增强部分怎么做?首先是不适合做选择增强的,因为如果特征图旋转了,标签图也得跟着相同的旋转,这样像素对像素的特征和标签才能保持一致,这样操作非常麻烦,所以我们数据增强就不做旋转了。那就只做随机裁剪吧。但是要说明的是,随机裁剪也是特征图和标签图同时随机裁剪,就是你随机后,还得要保证特征图对应的标签图的随机是一致的,就是特征图的像素是要和标签图的对应像素是一致的。
所以随机裁剪的数据增强操作我们就是在(2)中的resize步骤里面做了。
(4)随机裁剪完毕后,还得记得把特征图再映射成VOC类别数字
综上所有考虑,我们的代码实现过程是:
#导库
import os
from PIL import Image
import png
from torchvision import transforms
import torchvision
from torch.utils.data import random_split
from torch.utils.data import DataLoader
import random
from PIL import ImageDraw
import torch
import torch.nn as nn
from torch import optim
from torchvision.utils import save_image
#定义几个全局变量:
voc_dir = r'D:\pytorch-data\VOCtrainval_11-May-2012\VOCdevkit\VOC2012'
path_train_file = os.path.join(voc_dir, 'ImageSets', 'Segmentation', 'train.txt')
path_JPEGImages = os.path.join(voc_dir, 'JPEGImages')
path_SegmentationClass = os.path.join(voc_dir, 'SegmentationClass')
save_path = r'D:\pytorch-data\VOC_train_image'
weight_file = r'C:\Users\25584\Desktop\myunet.pt'
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person', 'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
COLOR_MAP = {0:(0, 0, 0), 1:(128, 0, 0), 2:(0, 128, 0), 3:(128, 128, 0), 4:(0, 0, 128), 5:(128, 0, 128), 6:(0, 128, 128),
7:(128, 128, 128), 8:(64, 0, 0), 9:(192, 0, 0), 10:(64, 128, 0), 11:(192, 128, 0), 12:(64, 0, 128),
13:(192, 0, 128), 14:(64, 128, 128), 15:(192, 128, 128), 16:(0, 64, 0), 17:(128, 64, 0), 18:(0, 192, 0),
19:(128, 192, 0), 20:(0, 64, 128)}
num_classes = len(VOC_CLASSES)#1、生成黑色画布把图片贴进去
def paste_img(img_path):
img = Image.open(img_path)
max_size = max(img.size)
mask = Image.new('RGB', (max_size, max_size), (0,0,0))
mask.paste(img, (0,0))
return mask
#2、获取标签的调色板信息
def get_VOCcolormap():
label1_path = os.path.join(voc_dir, 'SegmentationClass', '2007_000032.png') #从第一张标签图里面取调色板数据
label1_data = png.Reader(label1_path)
VOC_COLORMAP = label1_data.read()[3]['palette'][:21]
return VOC_COLORMAP
#3、将标签图像从RGB映射到VOC类别数据
def RGB2VOC(rgb, colormap):
temp_map = torch.zeros(256*256*256, dtype=torch.long)
for i, cmap in enumerate(colormap):
idx = (cmap[0]*256 + cmap[1])*256 + cmap[2]
temp_map[idx] = i
idxs = [(rgb[:,:,0]*256 + rgb[:,:,1])*256 + rgb[:,:,2]]
return temp_map[idxs]
#4、随机裁剪
def RandCrop(feature, label, h, w):
rect = torchvision.transforms.RandomCrop.get_params(feature, (h,w))
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
return feature, label
#5、将模型前向传播结果softmax后,得到voc类别,再将VOC转化为RGB,用于可视化
def RE2RGB(yhat): #yhat>>>torch.Size([8, 21, 256, 256])
voc = torch.max(yhat,dim=0).indices #([256, 256])
mask = Image.new('RGB', (256, 256))
draw = ImageDraw.Draw(mask)
for i in range(voc.shape[0]):
for j in range(voc.shape[1]):
draw.point((i,j), COLOR_MAP[voc[i,j].item()])
return mask
#6、写加载数据的类--加载的时候进行裁剪、转VOC类别
class VOCSegDataset(torch.utils.data.Dataset):
def __init__(self, features, labels, num_classes):
super().__init__()
self.features = features
self.labels = labels
self.lens = len(features)
self.classes = num_classes
def __len__(self):
return self.lens
def __getitem__(self, index):
feature = self.features[index]
label = self.labels[index]
feature, label = RandCrop(feature, label, 256, 256) #这部分是数据增强:裁剪 特征和标签裁剪完毕后还是PIL格式的图片 grb三通道的
voc_label = RGB2VOC(np.array(label).astype('int32'), get_VOCcolormap()) #把标签转成VOC类别 此时已经是tensor类型了
T = transforms.ToTensor()
feature = T(feature)
label = T(label)
return feature, label, voc_label##加载数据全过程
#1、把所有图片都贴到黑底上
with open(path_train_file, 'r') as f:
train_img_names = f.read().split() #1464张图片 train_img_names是一个list:['2007_000032', '2007_000039', '2007_000063',,,]
JPEGImages, Segmentations = [], [] #都是PIL格式的
for img in train_img_names:
jpg_img = os.path.join(path_JPEGImages, f'{img}.jpg') #获取训练集特征图片的路径
JPEGImages.append(paste_img(jpg_img)) #将图片贴到黑色方形画布上,并放入JPEGImages
png_img = os.path.join(path_SegmentationClass, f'{img}.png') #训练集的特征图片同理
Segmentations.append(paste_img(png_img))
#2、加载数据
data = VOCSegDataset(JPEGImages, Segmentations, num_classes=21)
#3、分小批次
batchdata = DataLoader(data, batch_size=8, shuffle=True) #183个批次效果如下: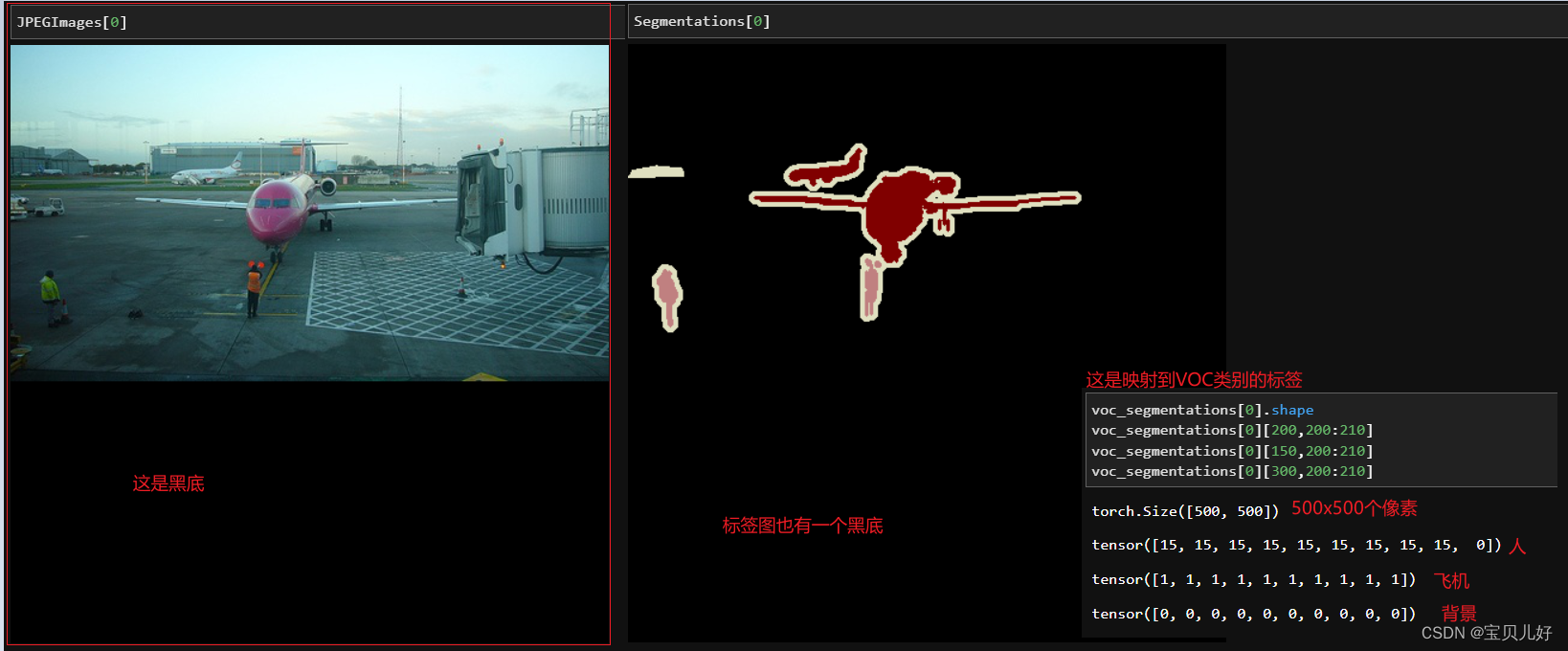
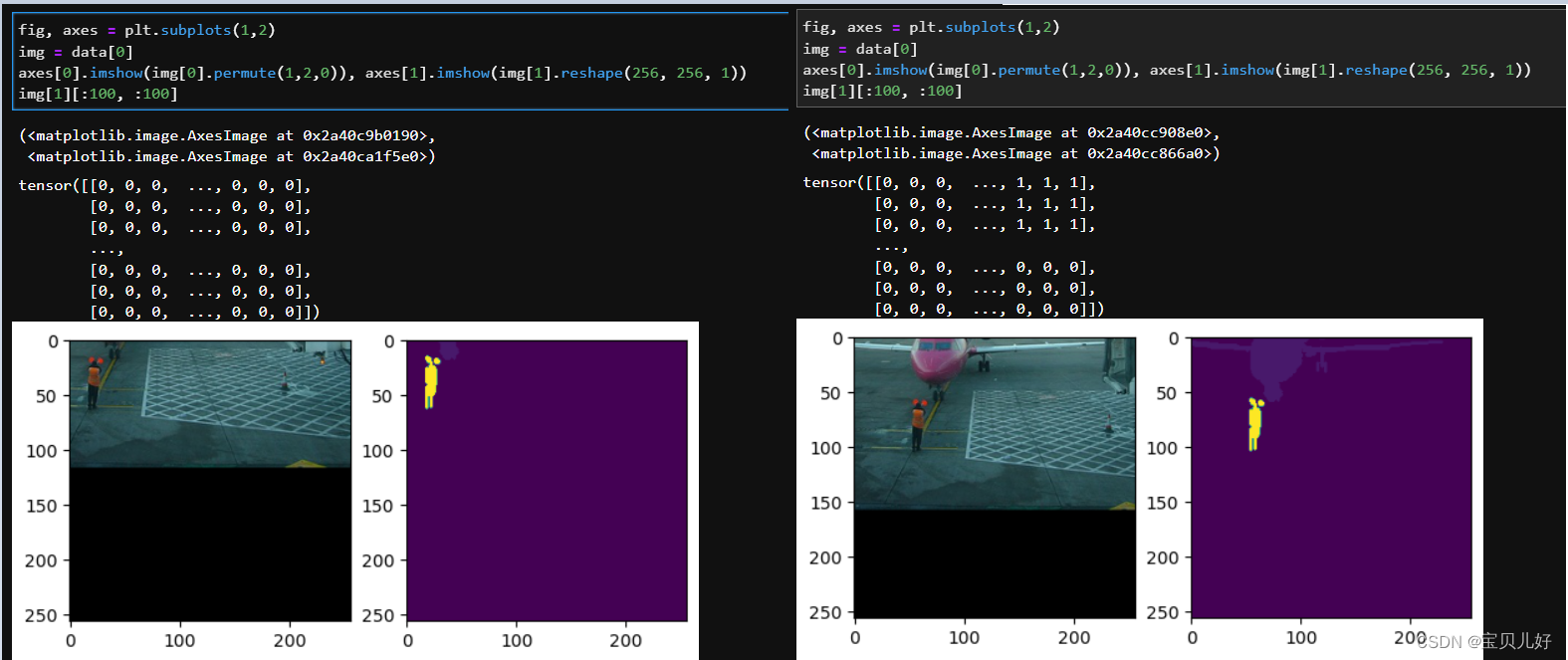
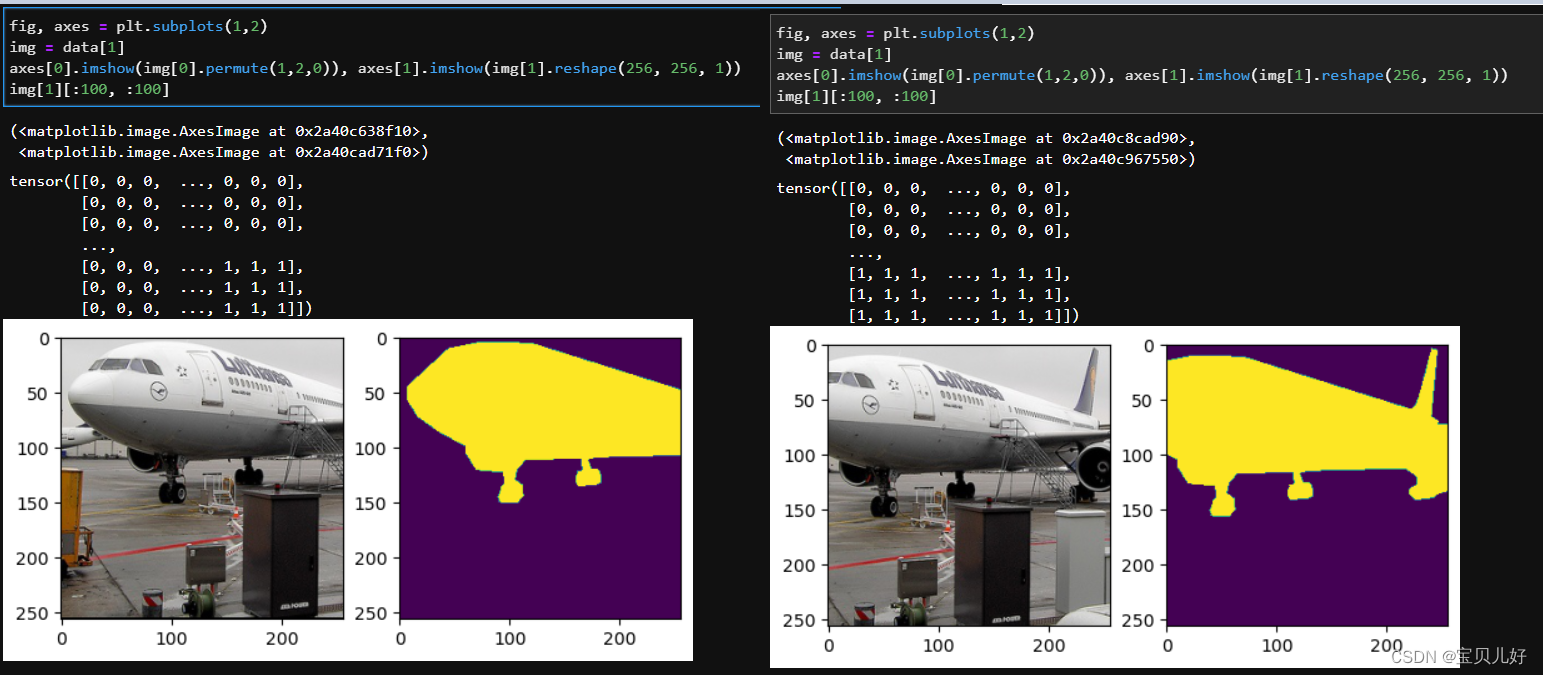
4、写架构
前面我们复现了U-net架构,这里我们还用这个架构,但是要对这个架构进行微调,因为一是:输入输出不一样,所以头和尾都得重新写。二是前面复现的unet架构是原论文作者首次提出的架构,此后针对这个架构的一些缺点,大家又提出了unet++、unet3+等等,所以这里我们先从简单开始,微调一下unet的架构看看训练效果。
#写unet架构
class basic_conv(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False),nn.BatchNorm2d(out_channels),nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.up = nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)
)
def forward(self, x):
return self.up(x)
class Unet(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.block1 = basic_conv(3,64) #in(3,256,256)-(64,256, 256)-(64,256,256)
self.maxpool1 = nn.MaxPool2d(2) #out(64, 128,128)
self.block2 = basic_conv(64, 128) #out(128, 128,128)-(128, 128,128)
self.maxpool2 = nn.MaxPool2d(2) #out(128, 64, 64)
self.block3 = basic_conv(128, 256) #out(256, 64, 64)-(256, 64, 64)
self.maxpool3 = nn.MaxPool2d(2) #out(256, 32, 32)
self.block4 = basic_conv(256, 512) #out(512, 32, 32)-(512, 32, 32)
self.maxpool4 = nn.MaxPool2d(2) #out(512,16,16)
self.block5 = basic_conv(512, 1024) #out(1024,16, 16)-(1024, 16, 16)
self.block6_1 = upsample(1024, 512) #out(512,32, 32)
self.block6_2 = basic_conv(1024, 512) #in(1024,32,32)-out(512,32, 32)-(512,32,32)
self.block7_1 = upsample(512, 256) #out(256,64, 64)
self.block7_2 = basic_conv(512, 256) #in(512,64, 64)-out(256,64,64)-(256,64,64)
self.block8_1 = upsample(256, 128) #out(128, 128,128)
self.block8_2 = basic_conv(256, 128) #in(256,128,128)-out(128,128,128)-(128,128,128)
self.block9_1 = upsample(128, 64) #out(64,256,256)
self.block9_2 = basic_conv(128, 64) #in(128,256,256)-out(64,256,256)-(64,256,256)
self.block9_3 = nn.Conv2d(64,num_classes,kernel_size=1, bias=False) #out(21,256,256)
def forward(self, x):
block1 = self.block1(x) #(64,256,256)
pool1 = self.maxpool1(block1) #(64, 128,128)
block2 = self.block2(pool1) #(128, 128,128)
pool2 = self.maxpool2(block2) #(128, 64, 64)
block3 = self.block3(pool2) #(256, 64, 64)
pool3 = self.maxpool3(block3) #(256, 32, 32)
block4 = self.block4(pool3) #(512, 32, 32)
pool4 = self.maxpool4(block4) #(512,16,16)
block5 = self.block5(pool4) #(1024, 16, 16)
block6_1 = self.block6_1(block5) #(512,32, 32)
concat1 = torch.cat([block6_1,block4], dim=1) #(1024,32,32)
block6_2 = self.block6_2(concat1) #(512,32,32)
block7_1 = self.block7_1(block6_2) #(256,64, 64)
concat2 = torch.cat([block7_1,block3], dim=1) #(512,64, 64)
block7_2 = self.block7_2(concat2) #(256,64,64)
block8_1 = self.block8_1(block7_2) #(128, 128,128)
concat3 = torch.cat([block8_1,block2], dim=1) #(256,200,200)
block8_2 = self.block8_2(concat3) #(128,128,128)
block9_1 = self.block9_1(block8_2) #(64,256,256)
concat4 = torch.cat([block9_1,block1], dim=1) #(128,256,256)
block9_2 = self.block9_2(concat4) #(64,256,256)
block9_3 = self.block9_3(block9_2) #(num_classes,256,256)
return block9_3查看这个架构的参数及计算量:
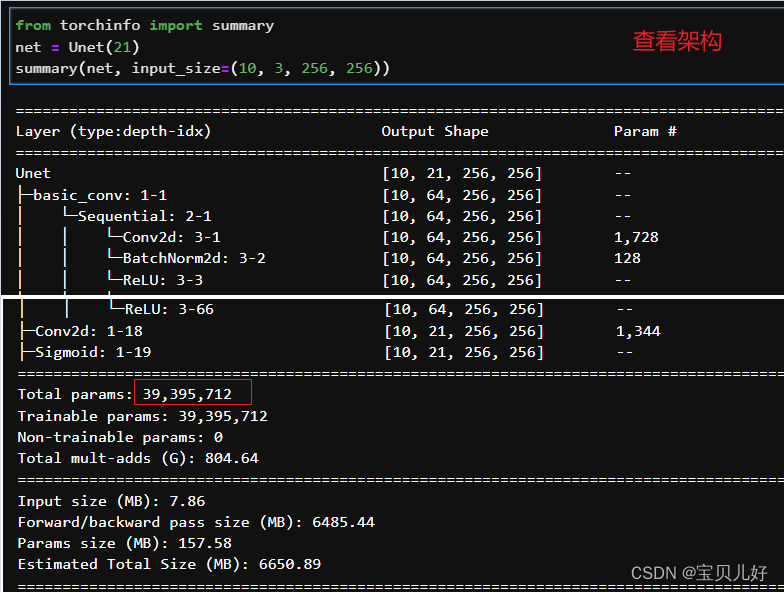
这个网络的参数都近4000万个,所以你的计算资源一定要跟得上。
5、训练模型
我们加载了batchdata, 搭建了Unet网络,下面就是训练这个网络了:
#训练模型
net = Unet(num_classes=num_classes) #实例化模型
if os.path.exists(weight_file): #如果以前有训练过,就加载已经训练好的参数
net.load_state_dict(torch.load(weight_file))
print('net weights load success....')
else:
print('net weights loading fall.....')
opt = optim.Adam(net.parameters()) #设置优化器
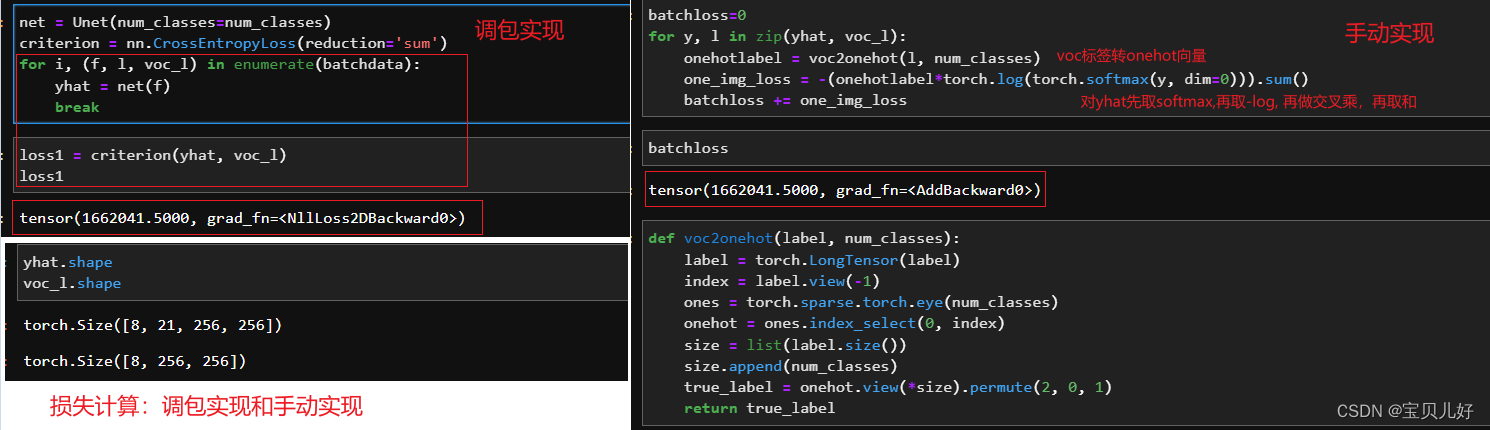
criterion = nn.CrossEntropyLoss(reduction='sum') #计算损失
epoch = 1 #一个epoch有183个批次
before_loss = 1000000
while True:
for i, (f, l, voc_l) in enumerate(batchdata): #voc_l>>>torch.Size([8, 256, 256]) f>>torch.Size([8, 3, 256, 256])
yhat = net.forward(f) #torch.Size([8, 21, 256, 256])
loss = criterion(yhat, voc_l)
opt.zero_grad(set_to_none=True)
loss.backward()
opt.step()
if i%5 == 0: #训练5个批次就打印一次
print('epoch:{}, batch:{}, trainloss:{}'.format(epoch, i, loss.item()))
feature = f[0]
label = l[0]
out = RE2RGB(yhat[0])
out_ = torch.from_numpy(np.array(out)).permute(2,0,1).float()/255.0
img = torch.stack([feature, label, out_], dim=0)
save_image(img, f'{save_path}/{epoch}_{i}.png')
if loss < before_loss: #loss出现新低就保存模型
torch.save(net.state_dict(), weight_file)
before_loss = loss
print('net weights saved...')
torch.save(net.state_dict(), weight_file)
epoch+=1训练效果如下:
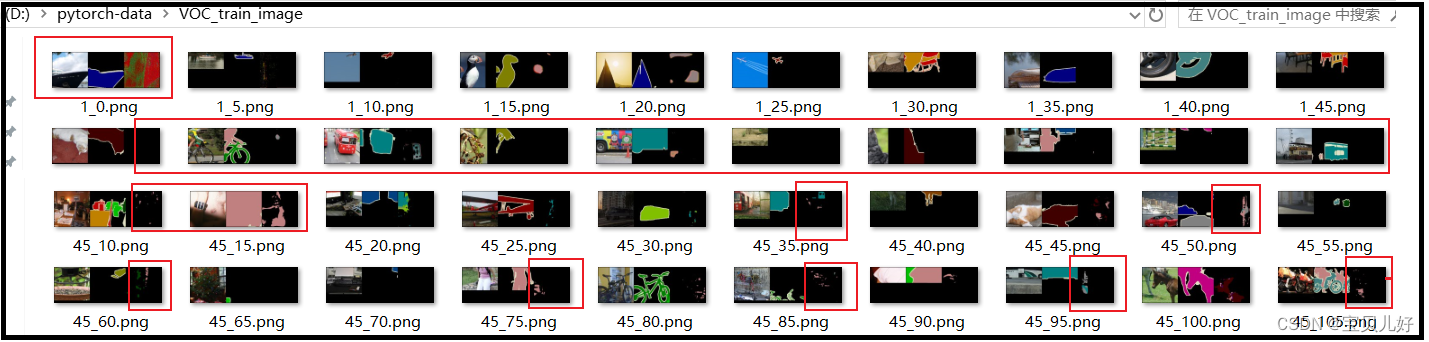
我只训练了不到50个epochs就停了,以后有计算资源了再继续训练,因为这不到50个epochs我已经跑了两天两夜了,得有60个小时了,我怕我电脑受不了就停了。。。
上图是每5个batch就生成一张上述图片,左边是原图、中间是标签图、右边是模型生成的标签图。从上图可以看出,第一张图片(也就是1_0.png)就是网络参数全部随机初始化后正向传播后生成的图片,可见还有原图的一些大轮廓和小细节,但是到了后面,在损失函数的牵引下,模型参数开始向损失函数减小的方向调整,模型输出的图片就是全黑了,一直训练到40个epochs左右,右边图像才开始渐渐有彩色斑点出现了。从上图看45个epochs模型远远没有收敛,还是非常非常的欠拟合,只需要继续训练即可。我从网上看其他人训练UNET也是说通常都得300个epochs左右,所以如果计算资源充足的小伙伴可以自己继续训练,本人也很期待效果。。。我就一台电脑,如果继续训练我就无所事事,所以训练就暂停了,后面还有目标检测、实例分隔等等内容,所以不再这里长期停留了。。。
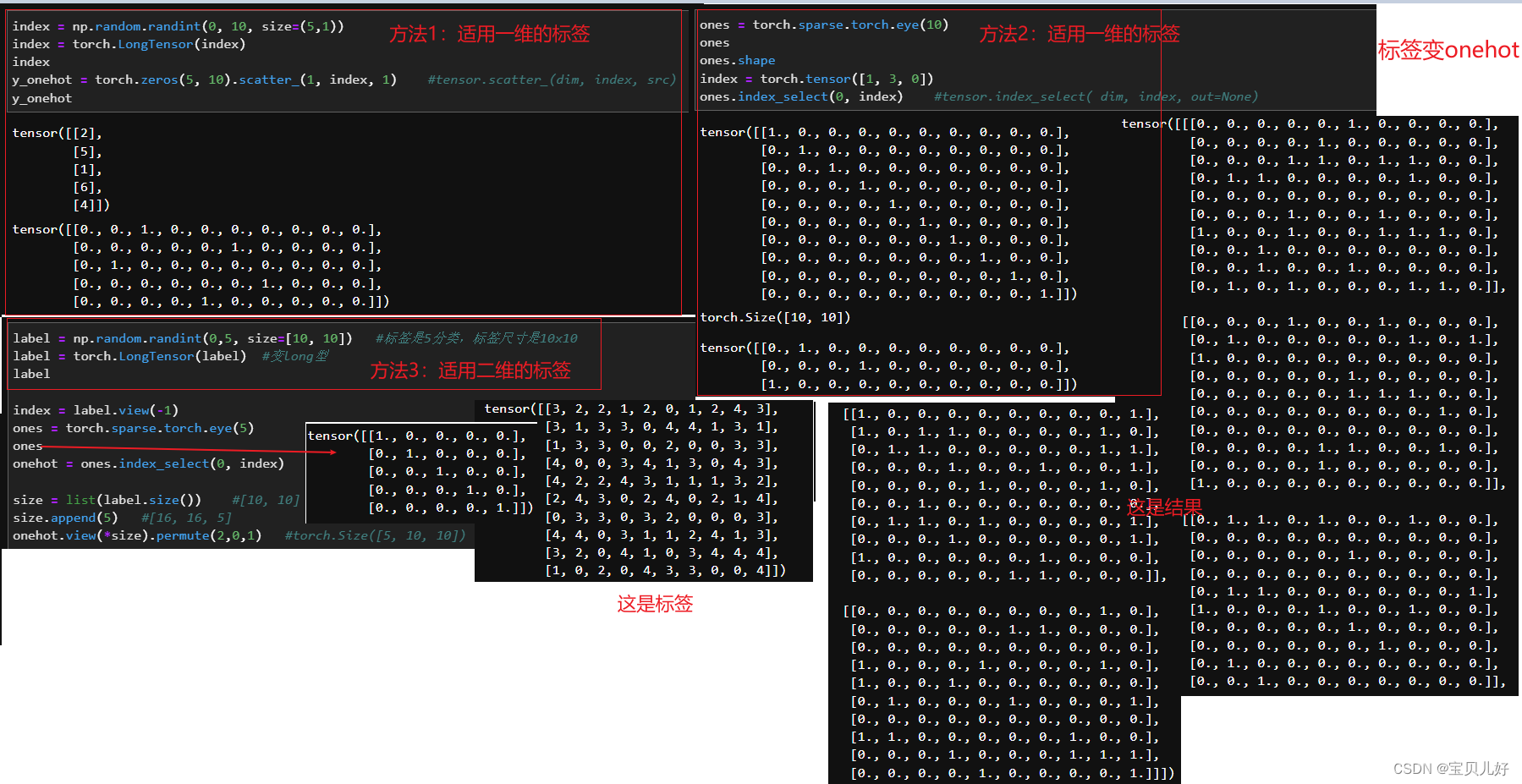
写在最后,相关小知识点总结:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 23
23 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)