AI智能化生成测试用例
图片使用pytesseract 或者百度paddleOCR识别文字。###要保持文档的结构不变,元信息不变。3.1、遍历word文档的图片及表格。2.3、LLM参数调整及联动。3.6 解析应答转为思维导图。3.4 选取LLM 大模型。用例分布及消耗的资源。3.5 生成测试用例。
·
一、要解决的问题
- 文本输入产品需求,生成测试用例
- 上传Pdf/word(图片、表格),解析后生成测试用例
- 生成测试用例前定制默认提示词
- 支持不同的大模型,可控制相关度、用例数量生成测试用例
- 测试用例支持json、excel、xmind思维导图格式
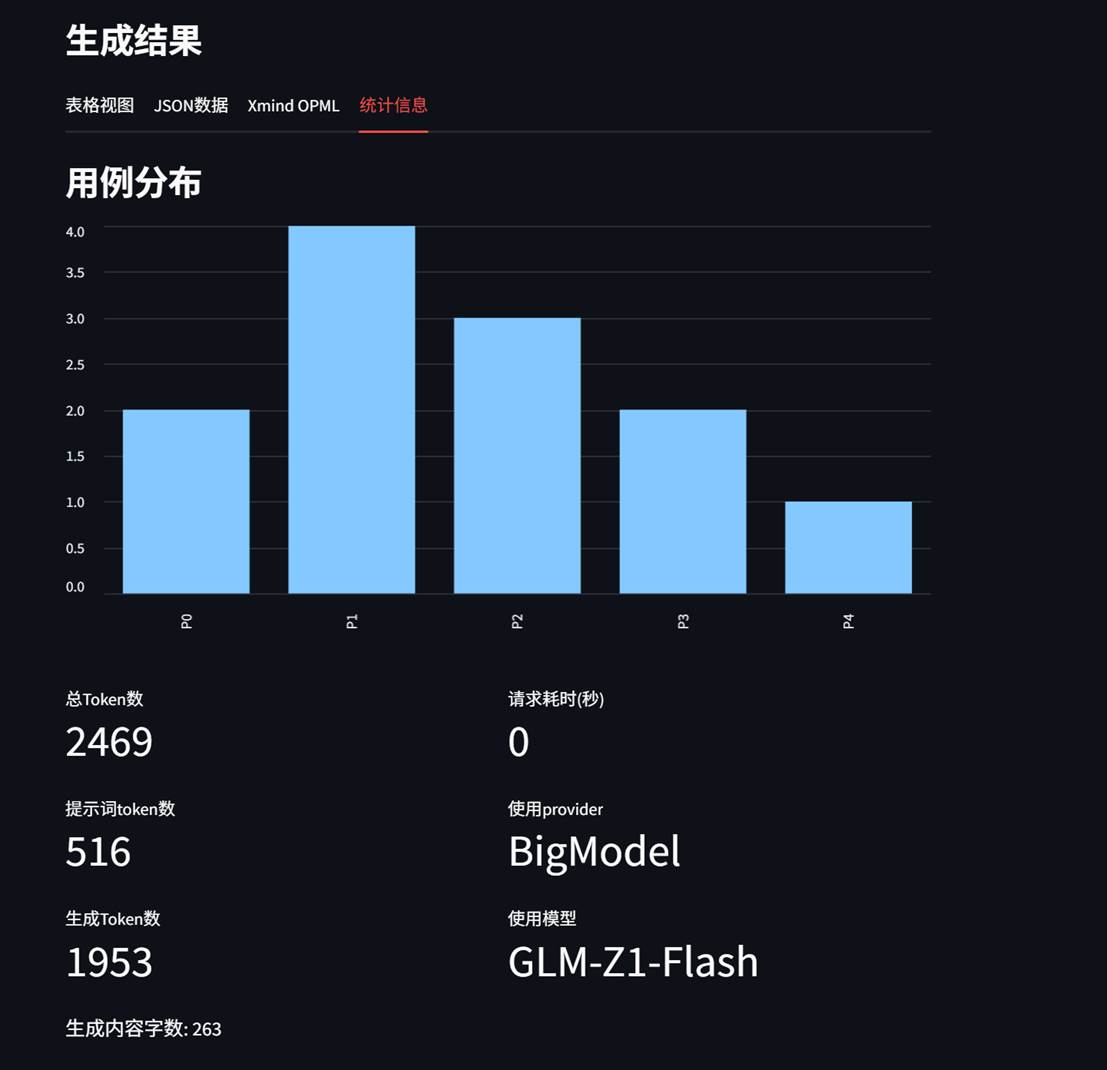
- 可清晰透视消耗的token,用例分布
- …
二、 效果
2.1、文档解析
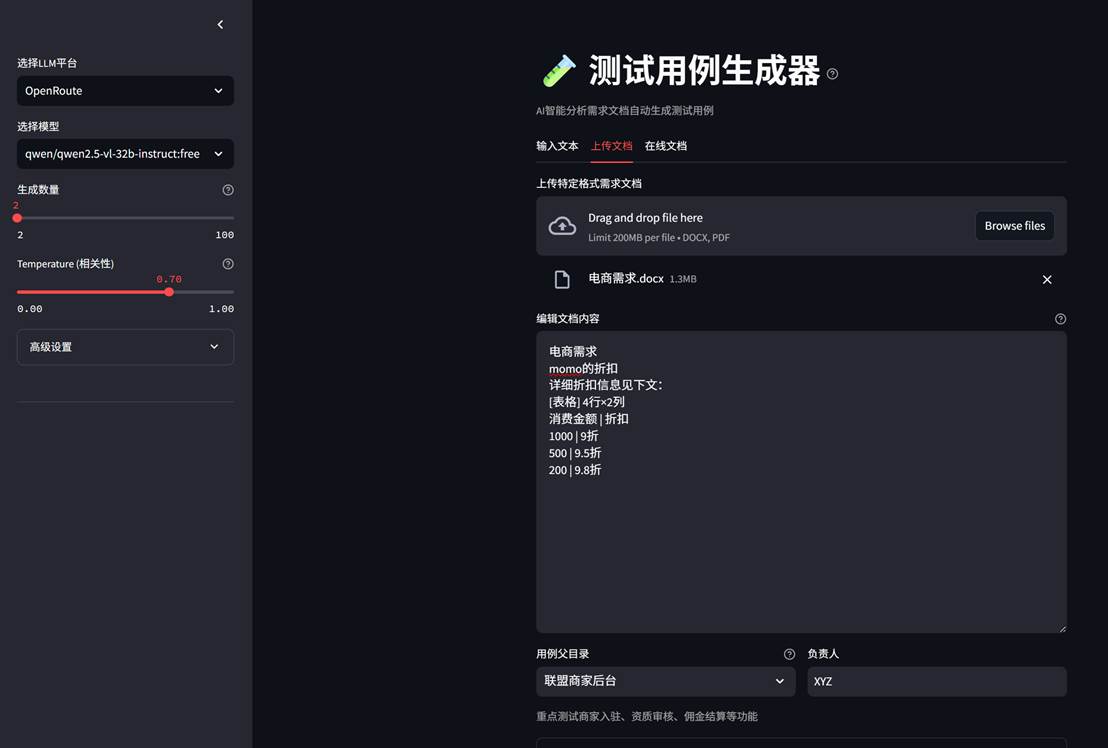
2.2 定制提示词
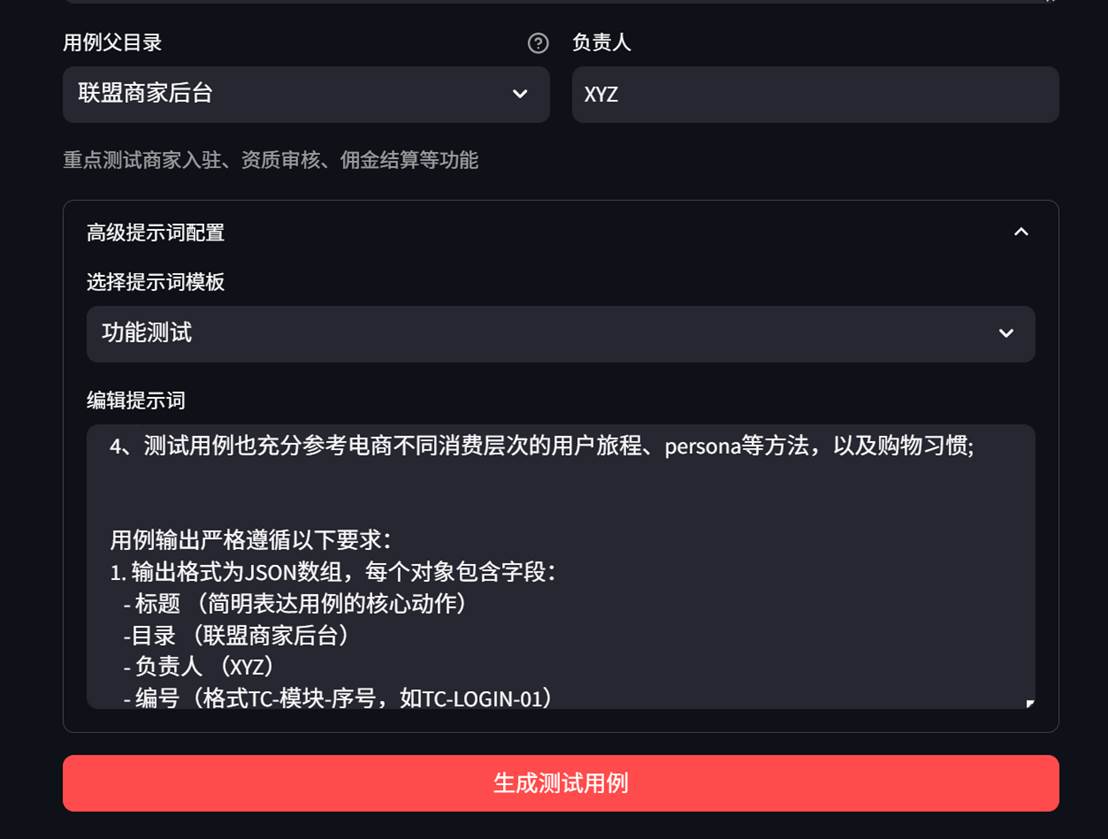
2.3、LLM参数调整及联动
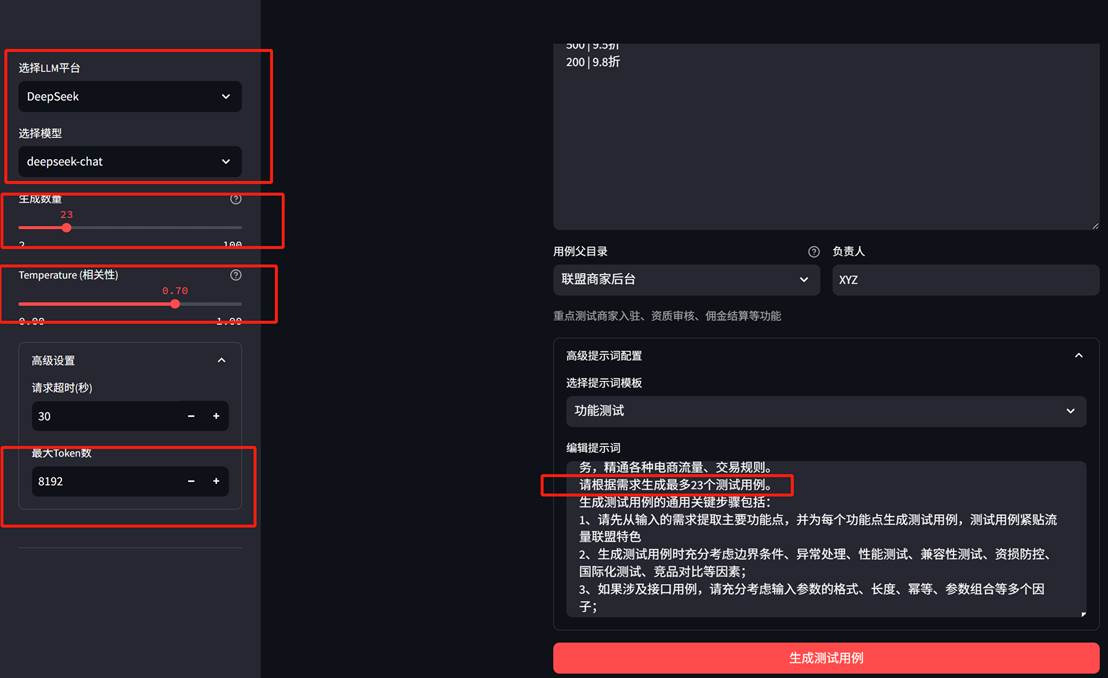
2.4 生成效果
表格形式
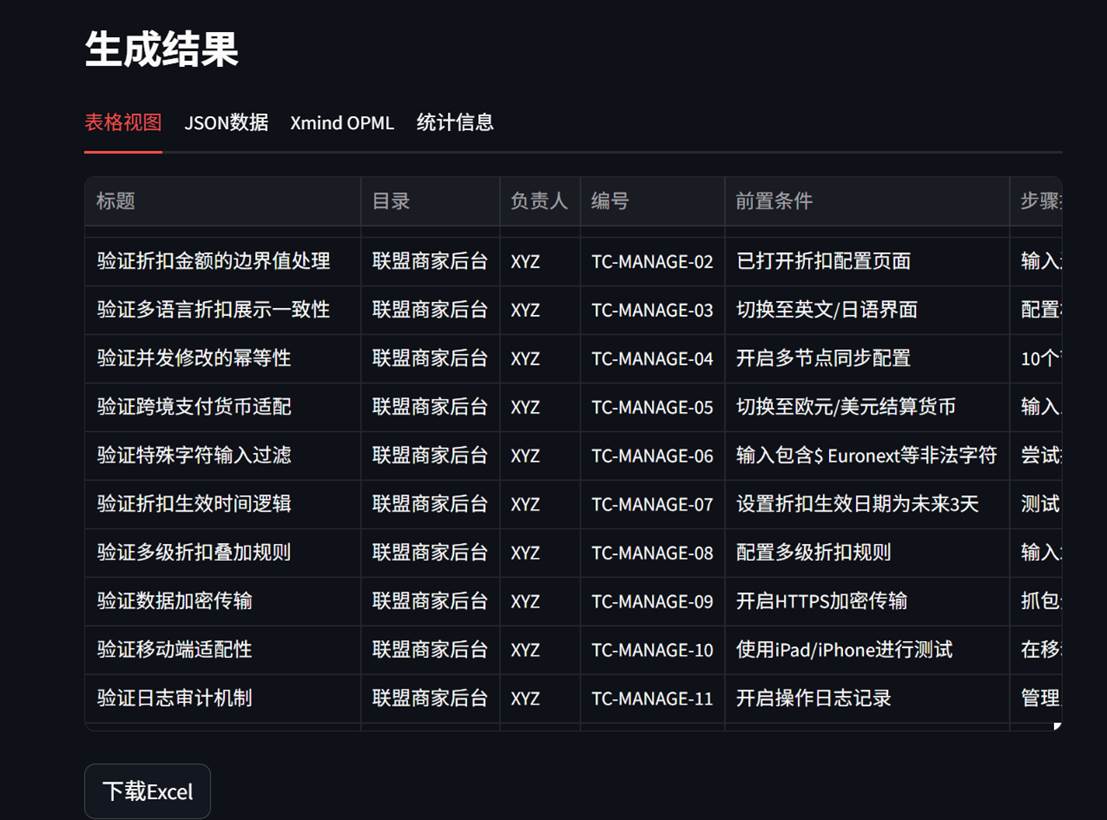
用例分布及消耗的资源
三、关键技术点解析
3.1、遍历word文档的图片及表格
###要保持文档的结构不变,元信息不变。能支持嵌套表格
def parse_document(self) -> List[Dict[str, Union[str, List]]]:
"""
解析文档内容,按顺序提取文本、表格和图像
"""
if not self.document:
self.load_document()
# 先提取文档中的所有图片
all_images = self.extract_images_from_document()
document_content = []
element_count = {'text': 0, 'table': 0, 'image': 0}
try:
logger.info("开始解析文档内容...")
for block_type, block in self.iter_block_items(self.document):
if block_type == 'paragraph':
paragraph = block
if self.is_toc_paragraph(paragraph):
continue
# 提取段落中的图片
images = self.extract_images_from_paragraph(paragraph, all_images)
for desc, image_text in images:
document_content.append({
'type': 'image',
'content': image_text,
'description': desc
})
element_count['image'] += 1
text = paragraph.text.strip()
if text:
document_content.append({
'type': 'text',
'content': text,
'style': paragraph.style.name,
'font_size': paragraph.style.font.size.pt if paragraph.style.font.size else None
})
element_count['text'] += 1
elif block_type == 'table':
table_data = self.parse_table(block)
if table_data:
document_content.append({
'type': 'table',
'content': table_data,
'rows': len(table_data),
'columns': len(table_data[0]) if table_data else 0
})
element_count['table'] += 1
logger.info(
f"文档解析完成。文本段落: {element_count['text']}, 表格: {element_count['table']}, 图像: {element_count['image']}")
return document_content
except Exception as e:
logger.error(f"文档解析过程中发生错误: {str(e)}", exc_info=True)
raise3.2 提取图片
def extract_images_from_paragraph(self, paragraph: Paragraph, all_images: Dict[str, io.BytesIO]) -> List[
Tuple[str, str]]:
"""
从段落中提取关联的图片
"""
images = []
try:
# 获取段落XML
p_xml = paragraph._p.xml
root = ET.fromstring(p_xml)
# 查找所有drawing元素
for drawing in root.findall('.//{*}drawing'):
# 查找blip元素(包含图片引用)
for blip in drawing.findall('.//{*}blip'):
rId = blip.attrib.get('{http://schemas.openxmlformats.org/officeDocument/2006/relationships}embed')
if rId and rId in self.doc_rels:
image_path = 'word/' + self.doc_rels[rId] # 构建完整图片路径
if image_path in all_images:
self.image_counter += 1
image_stream = all_images[image_path]
ocr_text = self.extract_text_from_image(image_stream)
images.append((f"Image {self.image_counter}", ocr_text))
except Exception as e:
logger.error(f"从段落提取图片失败: {str(e)}")
return images图片使用pytesseract 或者百度paddleOCR识别文字。
3.3 提取表格
def parse_table(self, table: Table) -> List[List[Union[str, List]]]:
"""
解析表格内容,支持嵌套表格
"""
table_data = []
try:
for row in table.rows:
row_data = []
for cell in row.cells:
cell_content = self.parse_table_cell(cell)
row_data.append(cell_content)
table_data.append(row_data)
return table_data
except Exception as e:
logger.error(f"表格解析失败: {str(e)}", exc_info=True)
return []3.4 选取LLM 大模型
def _load_providers_from_env(self) -> Dict[str, Dict]:
"""
从.env文件加载LLM提供者配置
格式示例:
LLM_PROVIDERS=OpenRoute,QWen,DeepSeek # 定义启用的提供者
OPENROUTE_MODELS=gpt-3.5-turbo,gpt-4 # 定义各提供者的模型
"""
providers = {}
enabled_providers = os.getenv("LLM_PROVIDERS", "OpenRoute,QWen,DeepSeek,Volces,SiliconFlow,BigModel,HunYuan,QianFan,MoonShot").split(",")
for provider in enabled_providers:
provider = provider.strip()
if not provider:
continue
# 获取基础配置
base_url = os.getenv(f"{provider.upper()}_BASE_URL")
app_key = os.getenv(f"{provider.upper()}_APP_KEY")
if not app_key:
logger.warning(f"跳过未配置APP_KEY的提供者: {provider}")
continue
# 获取模型列表
models_env = os.getenv(f"{provider.upper()}_MODELS", "")
models = [m.strip() for m in models_env.split(",") if m.strip()]
if not models:
logger.warning(f"提供者 {provider} 没有配置可用模型,使用默认")
models = self._get_default_models(provider)
providers[provider] = {
"base_url": base_url,
"app_key": app_key,
"models": models,
"timeout": int(os.getenv(f"{provider.upper()}_TIMEOUT", str(self.timeout))),
"max_tokens": int(os.getenv(f"{provider.upper()}_MAX_TOKENS", "8192"))
}
return providers3.5 生成测试用例
def generate_testcase(
self,
platform: str,
model: str,
prompt: str,
temperature: float = 0.7,
max_tokens: Optional[int] = None
) -> Tuple[Optional[str], Optional[Dict]]:
"""
生成测试用例
:param platform: 平台名称
:param model: 模型名称
:param prompt: 提示词
:param temperature: 温度参数(0-1)
:param max_tokens: 最大token数(可选)
:return: (生成的文本, 元数据)
"""
if platform not in self.available_models:
logger.error(f"不支持的平台: {platform}")
return None, None
provider_config = self.available_models[platform]
app_key = provider_config["app_key"]
base_url = provider_config["base_url"]
models = provider_config["models"]
if not app_key:
logger.error(f"{platform} API密钥未配置")
return None, None
if model not in models:
logger.error(f"模型 {model} 不在 {platform} 的可用模型列表中")
return None, None
# 使用提供者特定配置或默认值
timeout = provider_config.get("timeout", self.timeout)
max_tokens = max_tokens or provider_config.get("max_tokens", 806)
logger.info(f"base_url={base_url},api_key={app_key}")
#try:
client = openai.OpenAI(
api_key=app_key,
base_url=base_url,
timeout=timeout
)
# 记录开始时间
start_time = time.time()
# 发起请求(带重试机制)
print(f"prompt={prompt}")
for attempt in range(self.max_retries + 1):
try:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=min(max(temperature, 0), 1), # 确保在0-1范围内
max_tokens=max_tokens,
stream=False
)
break # 成功则跳出重试循环
except Exception as e:
if attempt == self.max_retries:
raise
wait_time = (attempt + 1) * 2 # 指数退避
logger.warning(f"请求失败,第{attempt + 1}次重试,等待{wait_time}秒...")
time.sleep(wait_time)
# 处理响应
completion = response.choices[0].message.content
elapsed = time.time() - start_time
logger.info(
f"LLM请求成功 | 平台: {platform} | 模型: {model} | "
f"耗时: {elapsed:.2f}s | 使用token: {response.usage.total_tokens}"
)
return completion, {
"model": model,
"provider": platform,
"usage": {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
},
"timing": {
"response_time": elapsed,
"start_time": start_time,
"end_time": time.time()
},
"config": {
"temperature": temperature,
"max_tokens": max_tokens
}
}3.6 解析应答转为思维导图
def json_to_opml(json_data, title_str):
opml = ET.Element('opml', version='2.0')
head = ET.SubElement(opml, 'head')
title = ET.SubElement(head, 'title')
title.text = title_str
body = ET.SubElement(opml, 'body')
root_outline = ET.SubElement(body, 'outline', {
'text': "用例根目录"
})
build_outline(root_outline, json_data)
return opml3.7 更多
加入:
https://t.zsxq.com/ZgMii 获取源代码。或者加v: liangjianzhao2020加入高质量测试效能群


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)