二分图最大匹配——匈牙利算法详解
贵圈真乱(
文章目录
一、前言
关于二分图的基本知识见:二分图及染色法判定
二、二分图最大匹配
2.1概念
“任意两条边都没有公共端点”的边的集合被称为图的一组匹配。在二分图中,包含边数最多的一组匹配被称为二分图的最大匹配。
我们称匹配的边为匹配边,匹配边的两个端点为匹配点,相应的自然有了非匹配边和非匹配点的概念。
2.2交替路
从一个非匹配点出发,依次经过非匹配边、匹配边、非匹配边形成的路径叫交替路。
2.3增广路
从一个未匹配点出发,走交替路,若能到达另一个未匹配点,则这条交替路称为增广路。
增广路显然有如下性质:
- 长度len为奇数
- 路径上第1、3、5……len条边是非匹配边,第2、4……len - 1条边是匹配边
正因为以上性质,如果我们把路径上所有边的状态取反,原来的匹配边变成非匹配边,原来的非匹配边变成匹配边,那么得到的新的边集仍然是一组匹配,并且匹配边数+1.
从而得到以下推论:
二分图的一组匹配是最大匹配,当且仅当图中不存在包含该匹配的增广路。(伯日引理 (Berge’s Lemma))
2.4匈牙利算法
**匈牙利算法(Hungary Algorithm)**又称牛头人算法增广路算法,用于计算二分图的最大匹配。
2.4.1算法原理
算法流程十分简单:
- 设匹配边集S = Ø,即所有边都是非匹配边
- 找到增广路path,将增广路上所有边状态取反,得到更大的匹配S‘
- 重复2,直到没有增广路
算法的关键在于如何找到增广路。
我们将二分图的点分为左部节点和右部节点,匈牙利算法依次尝试给给每一个左部节点u寻找一个匹配的右部节点v。右部节点v能和左部节点u匹配需要满足以下两个条件之一:
- v本身就是非匹配点
- 此时u~v为长度为1的增广路
- v已经跟左部节点u’匹配,但是从u‘出发能找到另一个右部节点v’和其匹配。
- 此时uvu‘~v’就是一条增广路
在具体的程序实现中,我们采用深度优先搜索的框架,递归的从u出发去找增广路,若找到,则在回溯时,正好把路径上的匹配状态取反。另外,可以用全局标记数组来维护节点的访问情况,避免重复搜索。
匈牙利算法的正确性基于贪心策略,它的一个重要特点是:当一个节点成为匹配点后,至多因为找到增广路而更换匹配对象,但是绝不会再变回非匹配点。
对于每个左部节点,寻找增广路最多遍历整张二分图一次。因此,该算法的时间复杂度为O(nm),其中n为点数目,m为边数目。
该做法的正确性证明(upd on 2026.03.02):
假设二分图的左部点集合为 L = { v 1 , v 2 , . . . , v n } L = \{v_1, v_2, ..., v_n\} L={v1,v2,...,vn},右部点集合为 R R R。
我们设 L k = { v 1 , v 2 , . . . , v k } L_k = \{v_1, v_2, ..., v_k\} Lk={v1,v2,...,vk} 表示前 k k k 个左部点组成的集合。
设 M k M_k Mk 为算法在处理完前 k k k 个点后得到的匹配。我们要证明的数学归纳法假设是:
在第 k k k 步结束时, M k M_k Mk 是子图 G k = ( L k ∪ R , E ) G_k = (L_k \cup R, E) Gk=(Lk∪R,E) 中的最大匹配。1. 初始情况(Base Case)
当 k = 0 k=0 k=0 时,左部点集合为空,匹配 M 0 M_0 M0 也为空。空图的最大匹配就是空集,假设成立。2. 归纳步骤(Inductive Step)
假设在第 k − 1 k-1 k−1 步结束时, M k − 1 M_{k-1} Mk−1 已经是子图 G k − 1 G_{k-1} Gk−1(前 k − 1 k-1 k−1 个点和所有右部点组成的图)的最大匹配。
现在我们要加入第 k k k 个点 v k v_k vk,并在新的子图 G k G_k Gk 中从 v k v_k vk 开始寻找增广路。这里只有两种情况:
情况 A:找到了从 v k v_k vk 出发的增广路。
我们将这条路径上的匹配边和非匹配边反转,得到新的匹配 M k M_k Mk。此时匹配数 ∣ M k ∣ = ∣ M k − 1 ∣ + 1 |M_k| = |M_{k-1}| + 1 ∣Mk∣=∣Mk−1∣+1。
因为只增加了一个左部点 v k v_k vk,最大匹配数最多只能比原来增加 1。现在它确实增加了 1,所以 M k M_k Mk 必然是新子图 G k G_k Gk 的最大匹配。情况 B:没有找到从 v k v_k vk 出发的增广路。
算法此时什么也不做,直接令 M k = M k − 1 M_k = M_{k-1} Mk=Mk−1。我们需要证明,此时 M k M_k Mk 依然是新子图 G k G_k Gk 的最大匹配。反证法:假设 M k M_k Mk 不是 G k G_k Gk 的最大匹配。根据伯日引理,如果它不是最大匹配,那么在 G k G_k Gk 中必然存在一条相对于 M k M_k Mk 的增广路 P P P。
既然在 G k − 1 G_{k-1} Gk−1 中没有增广路(因为 M k − 1 M_{k-1} Mk−1 是 G k − 1 G_{k-1} Gk−1 的最大匹配),而加入 v k v_k vk 后突然有了增广路 P P P,那么这条增广路 P P P 必然包含了新加入的顶点 v k v_k vk。
由于增广路的定义是“两端都是未匹配点”,而 v k v_k vk 目前就是一个未匹配点,所以 v k v_k vk 必定是这条增广路 P P P 的一个端点(起点)。
矛盾,故 M k M_k Mk 是 G k G_k Gk 的最大匹配
3. 结论
当算法运行完 n n n 步(遍历完所有的左部点)后,根据归纳法, M n M_n Mn 必然是全图 G = ( L ∪ R , E ) G = (L \cup R, E) G=(L∪R,E) 的最大匹配。
伯日引理: 全图中不存在任何增广路,那么 M n M_n Mn 是全图的最大匹配。
2.4.2算法示例
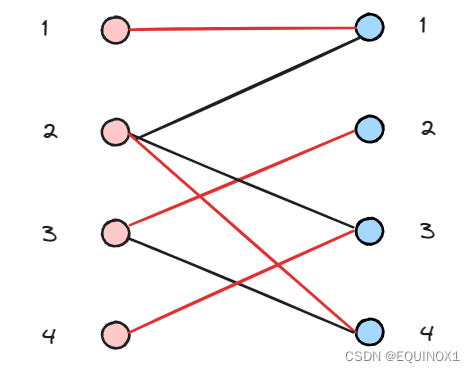
有二分图如下,左部节点1、2、3、4,右部节点1、2、3、4
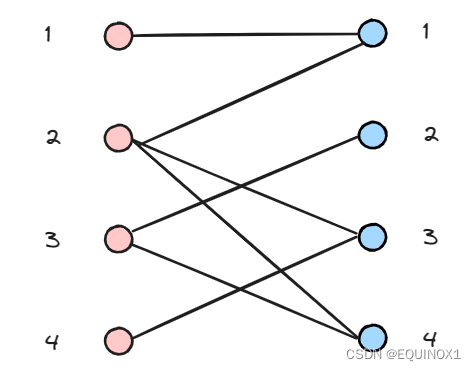
左1匹配右1
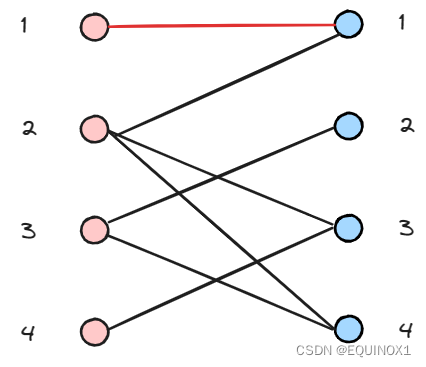
左2尝试匹配右1失败
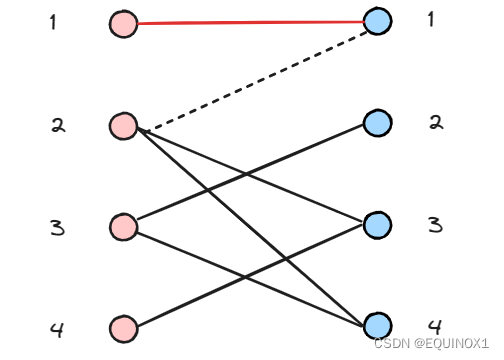
左2匹配右3
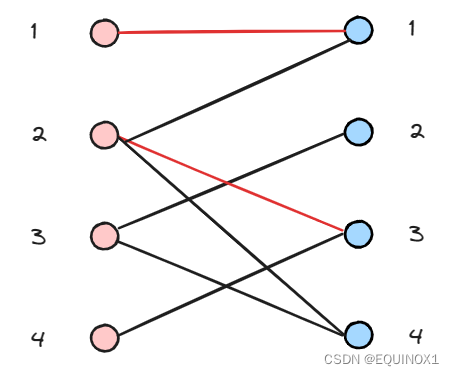
左3匹配右2
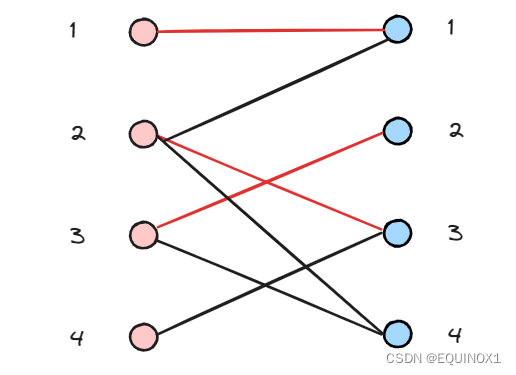
左4尝试匹配右3,递归左2尝试匹配右1失败

左2继续尝试匹配右4,成功找到增广路
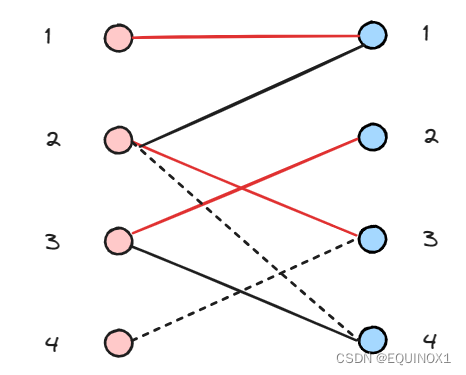
回溯时把增广路取反,左4得以匹配右3
2.4.3代码实现
bool dfs(int u)
{
for (int i = head[u]; ~i; i = edges[i].nxt)
{
int v = edges[i].v;
if (vis[v])
continue;
vis[v] = 1;
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true;
}
}
return false;
}
//main
for (int i = 1; i <= n; i++)
{
memset(vis, 0, sizeof(vis));
if (dfs(i))
cnt++;
}
3.5完备匹配
给定一张二分图, 其左部、右部节点数相同,均为N个节点。如果该二分图的最大匹配包含N条匹配边,则称该二分图具有完备匹配。
3.6多重匹配
给定一张包含N个左部节点、M个右部节点的二分图。从中选出尽量多的边,使第i(1≤i≤N) 个左部节点至多与kli条选出的边相连,第j(1≤j≤M)个右部节点至多与kri条选出的边相连。该问题被称为二分图的多重匹配。
当kli = krj=1时,上述问题就简化为二分图最大匹配。因此,多重匹配是一个广义的“匹配”问题,每个节点可以与不止一-条“匹配”边相连,但不能超过一个给定的限制。
3.6.1多重匹配的解决方案
- 拆点。把第i个左部节点拆成kli 个不同的左部节点,第j个右部节点拆成krj个右部节点。对于原图中的每条边(i , j), 在 i 拆成的所有节点与 j 拆成的所有节点之间连边。然后求解二分图最大匹配。
- 如果所有的kli=1,或者所有的krj=1,即只有一侧是“多重”匹配,不妨设左部是“多重”的,那么可以直接在匈牙利算法中让每个左部节点执行kli次dfs。
- 在第2种方案中,当然也可以交换左右两部,设“右部”是多重的,修改匈牙利算法的实现,让右部节点可以匹配krj次,超过匹配次数后,就要依次尝试递归当前匹配的krj个左部节点,看能否找到增广路。
- 网络流。这是最一般也是最高效的解决方法。
3.OJ练习
二分图匹配的模型有两个要素:
1.节点能分成独立的两个集合,每个集合内部有0条边。
2.每个节点只能与1条匹配边相连。
我们把它简称为“0要素”和“1要素”。在把实际问题抽象成二分图匹配时,我们就要寻找题目中具有这种“0”和“1”性质的对象,从而发现模型构建的突破口。
3.1模板
P3386 【模板】二分图最大匹配 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
洛谷模板题,检验以下自己的匈牙利算法板子是否正确,以便于在后续问题中使用。
#include <iostream>
#include <cstring>
#include <queue>
#include <algorithm>
#include <string>
using namespace std;
using pii = pair<int, int>;
#define N 510
#define M 50010
struct edge
{
int v, nxt;
} edges[M << 1];
int head[N], match[N]{0}, idx = 0, n, m, e, a, b, cnt = 0;
bool vis[N];
void addedge(int u, int v)
{
edges[idx] = {v, head[u]};
head[u] = idx++;
}
bool dfs(int u)
{
for (int i = head[u]; ~i; i = edges[i].nxt)
{
int v = edges[i].v;
if (vis[v])
continue;
vis[v] = 1;
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true;
}
}
return false;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
// freopen("out.txt", "w", stdout);
memset(head, -1, sizeof(head));
cin >> n >> m >> e;
for (int i = 1; i <= e; i++)
{
cin >> a >> b;
addedge(a, b);
}
for (int i = 1; i <= n; i++)
{
memset(vis, 0, sizeof(vis));
if (dfs(i))
cnt++;
}
cout << cnt;
return 0;
}
3.2棋盘覆盖
首先对于一个矩阵而言,我们根据行列坐标相加的奇偶性可以对其进行二染色,并且任何一个格子和其四个方向上的相邻格子颜色不同。
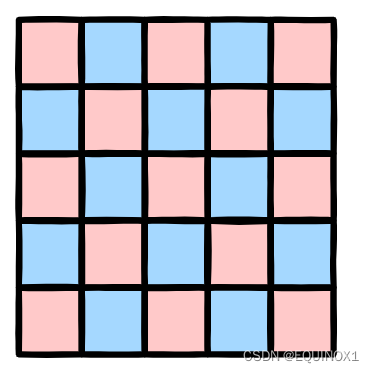
这样我们就可以将问题抽象为二分图匹配问题。
0要素:同色格子之间无边 1要素:每个格子只能被一张骨牌覆盖
一个骨牌一定是覆盖了两个颜色不同的方格,我们按照颜色将格子分为左部点和右部点,被骨牌覆盖的两个左右部点即为一个匹配,求最多的骨牌数目就是求最大匹配。
基本上还是板子题,由于数据量很小所以用了邻接矩阵,由于有的格子不能放置,所以要加个条件。
奇数格子还是偶数格子作为左部点没有区别。
直接看代码:
#include <iostream>
#include <cstring>
#include <queue>
#include <algorithm>
#include <string>
using namespace std;
using pii = pair<int, int>;
#define N 110
#define M 50010
int n, t, a, b, cnt = 0, dir[5]{1, 0, -1, 0, 1};
pii match[N][N];
bool g[N][N], vis[N][N];
bool dfs(int x, int y)
{
for (int i = 0; i < 4; i++)
{
int nx = x + dir[i], ny = y + dir[i + 1];
int pos = (nx - 1) * n + ny;
if (nx < 1 || ny < 1 || nx > n || ny > n || vis[nx][ny] || g[nx][ny])
continue;
vis[nx][ny] = 1;
if (match[nx][ny].first == -1 || dfs(match[nx][ny].first, match[nx][ny].second))
{
match[nx][ny] = {x, y};
return true;
}
}
return false;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
memset(g, 0, sizeof(g));
memset(match, -1, sizeof(match));
cin >> n >> t;
while (t--)
{
cin >> a >> b;
g[a][b] = 1;
}
for (int i = 1; i <= n; i++)
{
for (int j = (i & 1) ? 1 : 2; j <= n; j += 2)
{
if (!g[i][j])
{
memset(vis, 0, sizeof(vis));
if (dfs(i, j))
cnt++;
}
}
}
cout << cnt;
return 0;
}
3.3車的放置
1要素:每行每列只能有一个车,对于(i,j)放置车,相当于i行j列都被占用,即i行和j列连边
0要素:一个车不能既在第i行又在第j行,所以行与行之间无边
#include <iostream>
#include <cstring>
#include <queue>
#include <algorithm>
#include <string>
using namespace std;
using pii = pair<int, int>;
#define N 210
#define M 50010
int n, m, t, a, b, cnt = 0, dir[5]{1, 0, -1, 0, 1};
int match[N]{0};
bool g[N][N]{0}, vis[N];
bool dfs(int i)
{
for (int j = 1; j <= m; j++)
{
if (g[i][j] || vis[j])
continue;
vis[j] = 1;
if (!match[j] || dfs(match[j]))
{
match[j] = i;
return true;
}
}
return false;
}
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0), cout.tie(0);
cin >> n >> m >> t;
while (t--)
{
cin >> a >> b;
g[a][b] = 1;
}
for (int i = 1; i <= n; i++)
{
memset(vis, 0, sizeof(vis));
if (dfs(i))
cnt++;
}
cout << cnt;
return 0;
}
3.4导弹防御塔
1要素:没个炮弹只能打一个敌人,每个敌人只能被一个炮弹打(注意是炮弹而非炮台)
0要素:敌人不能打敌人,炮弹不能打炮弹
一个炮台是可以发出多枚炮弹的,也就是说一个炮台可以和多个敌人连边,这就是多重匹配的问题了。
题目又要求最短时间,我们发现这个可行时间具有单调性,所以可以用二分查找来逼近。
我们二分可行时间,每个可行时间对应每个炮台最多打出的炮弹数目p,我们将每个炮台拆为p个点,然后每个点都有自己的发射时间,对每个敌人枚举炮弹,如果能被打就连边
然后跑匈牙利,根据每个敌人能否被打到来收缩区间。
#include <iostream>
#include <cmath>
#include <cstring>
#include <vector>
#include <string>
#include <cmath>
using namespace std;
using pii = pair<int, int>;
#define sc scanf
#define N 55
#define int long long
#define precision 1e-9
int n, m;
double t1, t2, v, cost[N][N];
int match[N * N]{0};
bool vis[N * N], f;
pii a[N], b[N];
vector<int> g[N];
bool dfs(int u)
{
for (auto v : g[u])
{
if (vis[v])
continue;
vis[v] = true;
if (!match[v] || dfs(match[v]))
{
match[v] = u;
return true;
}
}
return false;
}
signed main()
{
// ios::sync_with_stdio(false);
// cin.tie(0), cout.tie(0);
// freopen("in.txt", "r", stdin);
sc("%lld%lld%lf%lf%lf", &n, &m, &t1, &t2, &v);
t1 /= 60;
for (int i = 1; i <= m; i++)
sc("%lld%lld", &b[i].first, &b[i].second);
for (int i = 1; i <= n; i++)
sc("%lld%lld", &a[i].first, &a[i].second);
for (int i = 1; i <= m; i++)
for (int j = 1; j <= n; j++)
cost[i][j] = sqrt((b[i].first - a[j].first) * (b[i].first - a[j].first) + (b[i].second - a[j].second) * (b[i].second - a[j].second)) / v;
double l = 0, r = 1e6;
while (r - l > precision)
{
double mid = (l + r) / 2;
int p = (mid + t2) / (t1 + t2);
p = min(m, p);
for (int i = 1; i <= m; i++)
{
g[i].clear();
for (int j = 1; j <= n; j++)
for (int k = 1; k <= p; k++)
if (cost[i][j] + t1 * k + t2 * (k - 1) <= mid)
g[i].push_back((j - 1) * p + k);
}
f = true;
memset(match, 0, sizeof(match));
for (int i = 1; i <= m && f; i++)
memset(vis, 0, sizeof(vis)) , f = dfs(i);
f ? r = mid : l = mid;
}
printf("%.6lf", r);
return 0;
}

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
 54
54 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)