神经网络基础知识
神经网络是一种模仿生物神经系统的计算模型,由输入层、隐藏层和输出层组成,通过神经元之间的连接传递信号。其工作原理包括前向传播和反向传播两个阶段,通过调整权重来学习数据模式。常见的神经网络类型包括前馈神经网络、循环神经网络、卷积神经网络和生成对抗网络。构建神经网络的基本步骤包括数据准备、模型构建、训练和评估。以PyTorch为例,实现一个简单二分类神经网络需要定义模型结构、选择损失函数和优化器,并进
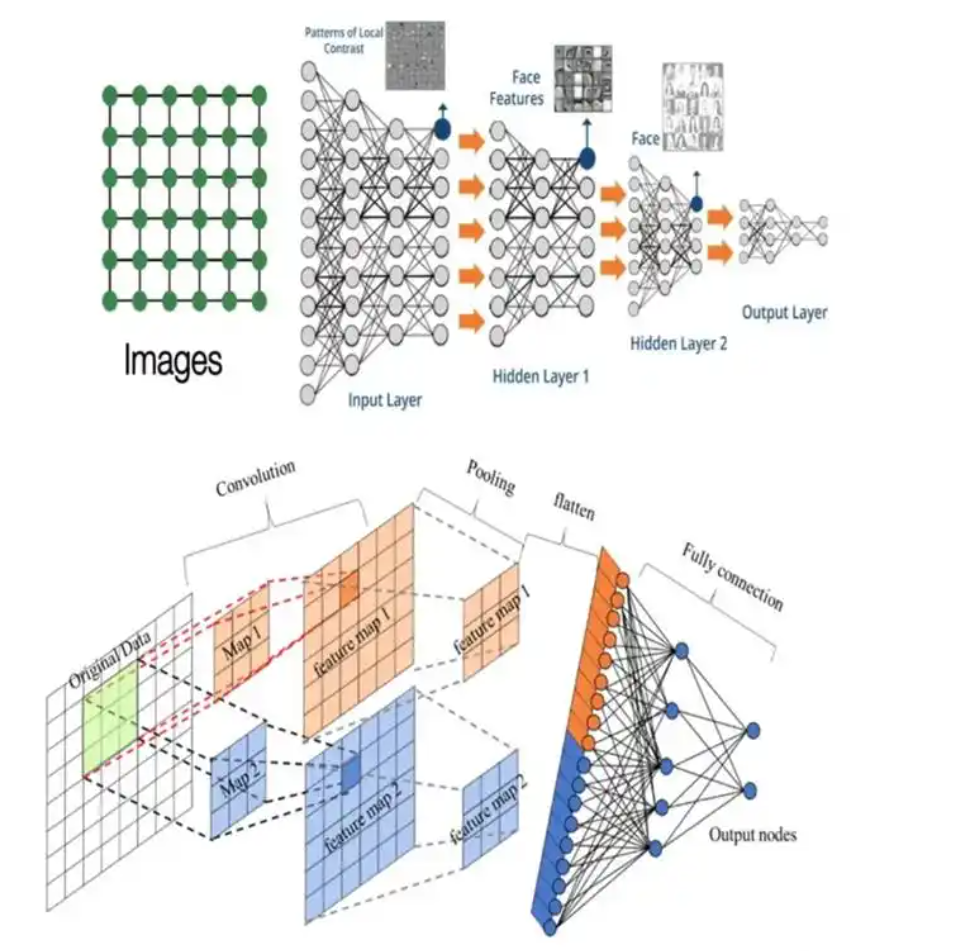
神经网络基础概述
神经网络(Neural Networks)是一种模仿人类神经系统结构和功能的计算模型,由大量相互连接的神经元组成,旨在通过学习数据中的模式和规律,实现对复杂任务的自动化处理,如分类、回归、预测等。
一、神经网络的基本组成
-
神经元(Neuron)
- 定义:神经网络的基本单元,也称为节点或感知器。
- 结构:每个神经元接收多个输入信号,对输入进行加权求和,然后通过一个激活函数(Activation Function)产生输出。
- 数学表示:假设神经元有 nn 个输入 x1,x2,...,xnx1,x2,...,xn,对应的权重为 w1,w2,...,wnw1,w2,...,wn,偏置为 bb,则神经元的输出 yy 可以表示为:y=f(∑i=1nwixi+b)y=f(∑i=1nwixi+b),其中 ff 是激活函数。
- 类比:可以将神经元类比为生物神经系统中的神经细胞,输入信号类似于神经细胞的树突接收到的信号,输出信号类似于轴突传递的信号。
-
层(Layer)
- 输入层(Input Layer):负责接收外部输入数据,不进行任何计算,只是将数据传递给下一层。
- 隐藏层(Hidden Layer):位于输入层和输出层之间,对输入数据进行复杂的变换和处理。一个神经网络可以有一个或多个隐藏层,隐藏层的数量和每层的神经元数量是神经网络结构的重要参数,会影响网络的性能和学习能力。
- 输出层(Output Layer):产生神经网络的最终输出结果,输出的形式取决于具体的任务。例如,在分类任务中,输出可能是每个类别的概率;在回归任务中,输出可能是一个连续的数值。
-
连接(Connection)
- 定义:神经元之间的连接用于传递信号,每个连接都有一个权重,权重决定了信号在传递过程中的强度。
- 作用:权重是神经网络学习的关键参数,通过调整权重,神经网络可以学习到数据中的模式和规律。
二、神经网络的工作原理
-
前向传播(Forward Propagation)
- 过程:输入数据从输入层进入神经网络,依次经过各个隐藏层,最终到达输出层。在每一层,神经元接收上一层的输出作为输入,进行加权求和并通过激活函数产生输出,然后将输出传递给下一层。
- 示例:假设有一个简单的神经网络,包含一个输入层(2个神经元)、一个隐藏层(3个神经元)和一个输出层(1个神经元)。输入数据为 [x1,x2][x1,x2],隐藏层的权重矩阵为 W1W1(大小为 3×23×2),偏置向量为 b1b1(大小为 3×13×1),输出层的权重向量为 W2W2(大小为 1×31×3),偏置为 b2b2。则前向传播的过程如下:
- 隐藏层的输出 h=f(W1[x1,x2]T+b1)h=f(W1[x1,x2]T+b1),其中 ff 是隐藏层的激活函数。
- 输出层的输出 y=f(W2h+b2)y=f(W2h+b2),其中 ff 是输出层的激活函数。
-
反向传播(Back Propagation)
- 目的:当神经网络的输出与预期结果存在误差时,通过反向传播算法将误差从输出层反向传播到输入层,同时调整各层神经元之间的连接权重,以减小误差。
- 过程:
- 计算误差:使用损失函数(Loss Function)计算神经网络的输出与预期结果之间的误差。常见的损失函数有均方误差(Mean Squared Error,MSE)、交叉熵损失(Cross-Entropy Loss)等。
- 梯度计算:根据链式法则,计算损失函数对每个权重的梯度。梯度表示了损失函数在该权重方向上的变化率,即权重调整的方向和幅度。
- 权重更新:使用优化算法(如随机梯度下降法 Stochastic Gradient Descent,SGD)根据梯度更新权重,使得损失函数逐渐减小。
三、神经网络的类型
-
前馈神经网络(Feedforward Neural Networks,FNN)
- 定义:信息在网络中单向传播,从输入层经过隐藏层到输出层,没有反馈连接。
- 应用:广泛应用于分类、回归等任务,如图像识别、语音识别等。
-
循环神经网络(Recurrent Neural Networks,RNN)
- 定义:具有反馈连接,能够处理序列数据。在RNN中,神经元的输出不仅会传递给下一层,还会反馈给自身,使得网络具有记忆能力。
- 应用:常用于处理时间序列数据,如自然语言处理、股票价格预测等。
-
卷积神经网络(Convolutional Neural Networks,CNN)
- 定义:专门为处理具有网格结构的数据而设计,如图像。CNN通过卷积层、池化层等结构自动提取数据的特征。
- 应用:在图像分类、目标检测、图像分割等领域取得了巨大的成功。
-
生成对抗网络(Generative Adversarial Networks,GAN)
- 定义:由生成器和判别器两个神经网络组成。生成器负责生成逼真的数据样本,判别器负责判断输入的数据是真实样本还是生成样本。两者通过对抗训练不断提高性能。
- 应用:可用于图像生成、数据增强等任务。
四、神经网络的训练过程
-
数据准备
- 收集数据:收集与任务相关的数据集,数据集应包含输入数据和对应的标签(对于监督学习任务)。
- 数据预处理:对数据进行清洗、归一化、标准化等处理,以提高神经网络的训练效果和收敛速度。
- 数据划分:将数据集划分为训练集、验证集和测试集。训练集用于训练神经网络,验证集用于调整模型的超参数和防止过拟合,测试集用于评估模型的最终性能。
-
模型构建
- 选择网络结构:根据任务的需求和数据的特点,选择合适的神经网络结构和层数。
- 初始化参数:对神经网络的权重和偏置进行初始化,常用的初始化方法有随机初始化、Xavier初始化等。
-
模型训练
- 设置训练参数:包括学习率、批量大小、训练轮数等。学习率决定了权重更新的步长,批量大小是指每次训练时使用的样本数量,训练轮数是指整个训练集被遍历的次数。
- 进行前向传播和反向传播:使用训练集对神经网络进行训练,通过前向传播计算输出和误差,通过反向传播更新权重。
- 模型评估:在训练过程中,使用验证集对模型进行评估,观察模型在验证集上的性能变化。如果模型在验证集上的性能不再提升,可能出现了过拟合现象,此时可以提前停止训练。
-
模型测试
- 使用测试集评估模型:在模型训练完成后,使用测试集对模型进行最终评估,计算模型在测试集上的准确率、召回率、F1值等指标,以评估模型的泛化能力。
-
模型部署
- 将训练好的模型部署到实际应用中:根据具体的应用场景,将神经网络模型集成到相应的系统中,实现对新数据的预测和处理。
构建一个简单的神经网络可以通过以下步骤完成,这里以Python和常用的深度学习框架PyTorch为例,详细介绍如何实现一个用于解决简单二分类任务(如判断输入数据属于哪一类)的神经网络。
一、准备工作
- 安装PyTorch
- 如果尚未安装PyTorch,可以通过以下命令安装(以pip为例):
pip install torch torchvision
二、构建简单神经网络的步骤
1. 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
torch:PyTorch的核心库,用于张量操作和神经网络构建。torch.nn:包含神经网络的各种层和模块。torch.optim:提供优化算法,如随机梯度下降法。sklearn:用于生成示例数据、数据划分和预处理。
2. 生成示例数据
# 生成一个简单的二分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 转换为PyTorch张量
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.LongTensor(y_train)
X_test_tensor = torch.FloatTensor(X_test)
y_test_tensor = torch.LongTensor(y_test)
- 使用
make_classification生成一个具有1000个样本、20个特征的二分类数据集。 - 将数据划分为训练集和测试集,比例为8:2。
- 对数据进行标准化处理,使每个特征的均值为0,方差为1,这有助于神经网络的训练。
- 将数据转换为PyTorch张量,以便在神经网络中使用。
3. 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self, input_size):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, 10) # 输入层到隐藏层,隐藏层有10个神经元
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(10, 2) # 隐藏层到输出层,输出层有2个神经元(对应二分类)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 初始化模型
input_size = 20
model = SimpleNN(input_size)
- 定义一个名为
SimpleNN的神经网络类,继承自nn.Module。 - 在
__init__方法中,定义神经网络的结构:fc1:一个全连接层,将输入数据从input_size维映射到10维。relu:ReLU激活函数,用于引入非线性。fc2:另一个全连接层,将10维数据映射到2维,对应二分类任务的输出。
- 在
forward方法中,定义数据的前向传播过程。 - 初始化模型,输入特征维度为20。
4. 定义损失函数和优化器
# 定义损失函数(交叉熵损失)
criterion = nn.CrossEntropyLoss()
# 定义优化器(随机梯度下降法)
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
- 使用交叉熵损失函数
nn.CrossEntropyLoss,适用于多分类任务(二分类是多分类的特例)。 - 使用随机梯度下降法(SGD)作为优化器,学习率为0.01。
5. 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
- 设置训练轮数为100。
- 在每一轮训练中:
- 进行前向传播,计算模型的输出和损失。
- 进行反向传播,计算梯度。
- 使用优化器更新模型的参数。
- 每10轮打印一次损失值,以便观察训练过程。
6. 测试模型
with torch.no_grad():
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == y_test_tensor).sum().item() / y_test_tensor.size(0)
print(f'Accuracy on test set: {accuracy * 100:.2f}%')
- 在测试阶段,使用
torch.no_grad()上下文管理器,禁用梯度计算,以节省内存和计算资源。 - 计算模型在测试集上的输出,并使用
torch.max获取预测的类别。 - 计算模型在测试集上的准确率。
三、完整代码示例
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_train_tensor = torch.FloatTensor(X_train)
y_train_tensor = torch.LongTensor(y_train)
X_test_tensor = torch.FloatTensor(X_test)
y_test_tensor = torch.LongTensor(y_test)
# 定义神经网络模型
class SimpleNN(nn.Module):
def __init__(self, input_size):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, 10)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
input_size = 20
model = SimpleNN(input_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
learning_rate = 0.01
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
outputs = model(X_train_tensor)
loss = criterion(outputs, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试模型
with torch.no_grad():
outputs = model(X_test_tensor)
_, predicted = torch.max(outputs.data, 1)
accuracy = (predicted == y_test_tensor).sum().item() / y_test_tensor.size(0)
print(f'Accuracy on test set: {accuracy * 100:.2f}%')
四、总结
通过以上步骤,我们构建了一个简单的神经网络,用于解决二分类任务。在实际应用中,你可以根据具体任务的需求调整神经网络的结构、超参数等,以获得更好的性能。例如,增加隐藏层的数量和神经元的数量、使用不同的激活函数、调整学习率等。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 32
32 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)