ELIC图像压缩算法
此时解码器由于缺少对应 “特征编码 -重构图片” 对应的映射关系, 两个相邻编码值之间也不存在任何关联, 模型也无从知道位置 2 编码值的重构结果应该介于位置 1 和 3 编码值之间, 输出结果就会出现模糊或乱码。针对 MSE-optimized 模型在 bpp 较小时出现的模糊问题, 在损失函数中引入 LPIPS 损失,该损失更加注重肉眼主观视觉效果, 最终在 bpp 变化不大的情况下解压图片的
讲述ELIC图像压缩算法理论基础及详细解析,除此之外还补充了可以改进的地方。
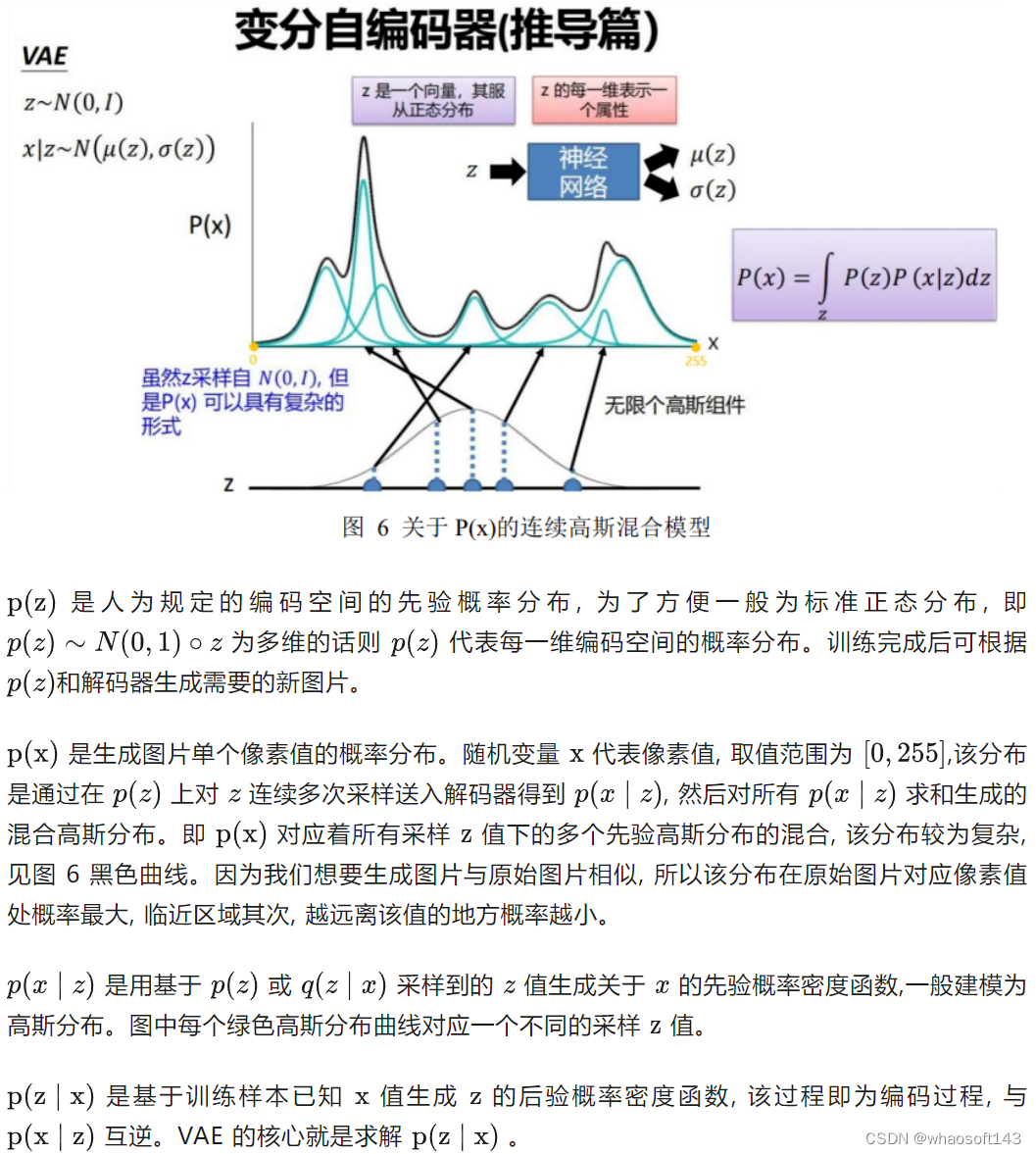
信息量

信息熵

KL 散度
也叫相对熵。用于衡量两个概率分布之间的差异。其值越大, 则两个概率分布的差异越大; 当两个概率分布完全相等时相对熵值为 0 。

交叉嫡

KL 散度可以被用于计算代价,而在特定情况下最小化 KL 散度等价于最小化交叉熵。而交叉熵的运算更简单,所以常用交叉熵来当做代价。
熵编码
摘编码即编码过程中按熵原理不丢失任何信息的编码。熵编码需要知道独立分布的待编码变量及其概率。常见的熵编码有: 香农(Shannon)编码、哈夫曼(Huffman)编码、算术编码 (Arithmetic Coding)、非对称数字系统编码(ANS)等。

自编码器(AE)
输入无标签数据从中提取有效低维特征, 并利用低维特征重构出输入数据。
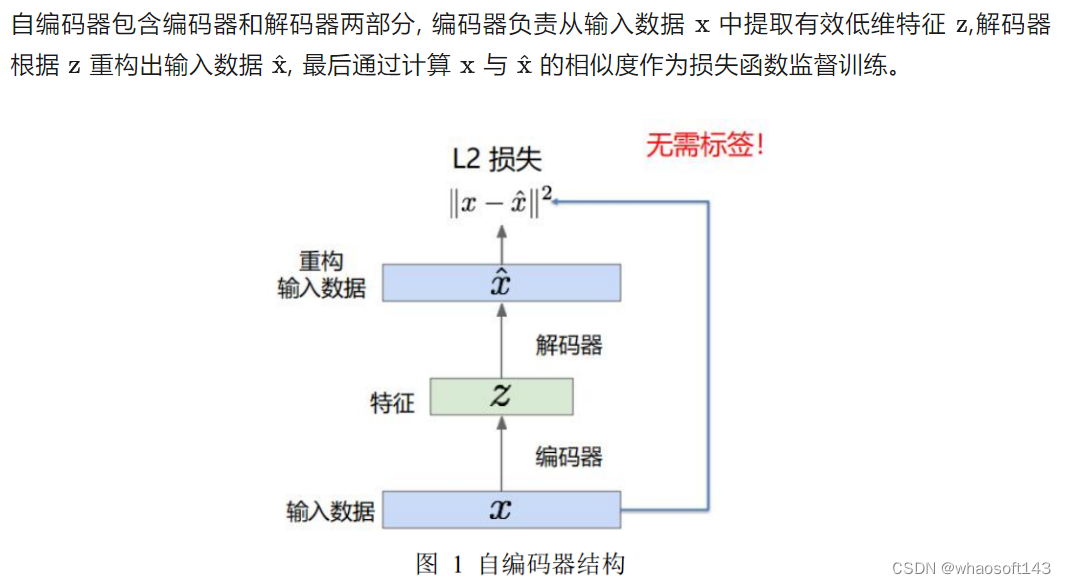
不难发现,图像压缩和解压的过程本质就是自编码器结构,压缩就是提取图像中的低维重要特征,方便传输和存储,解压则是根据压缩特征恢复原始图像的过程。所以图像压缩算法的架构基于自编码器,而自编码器还应用于数据可视化分析、以图搜图等。
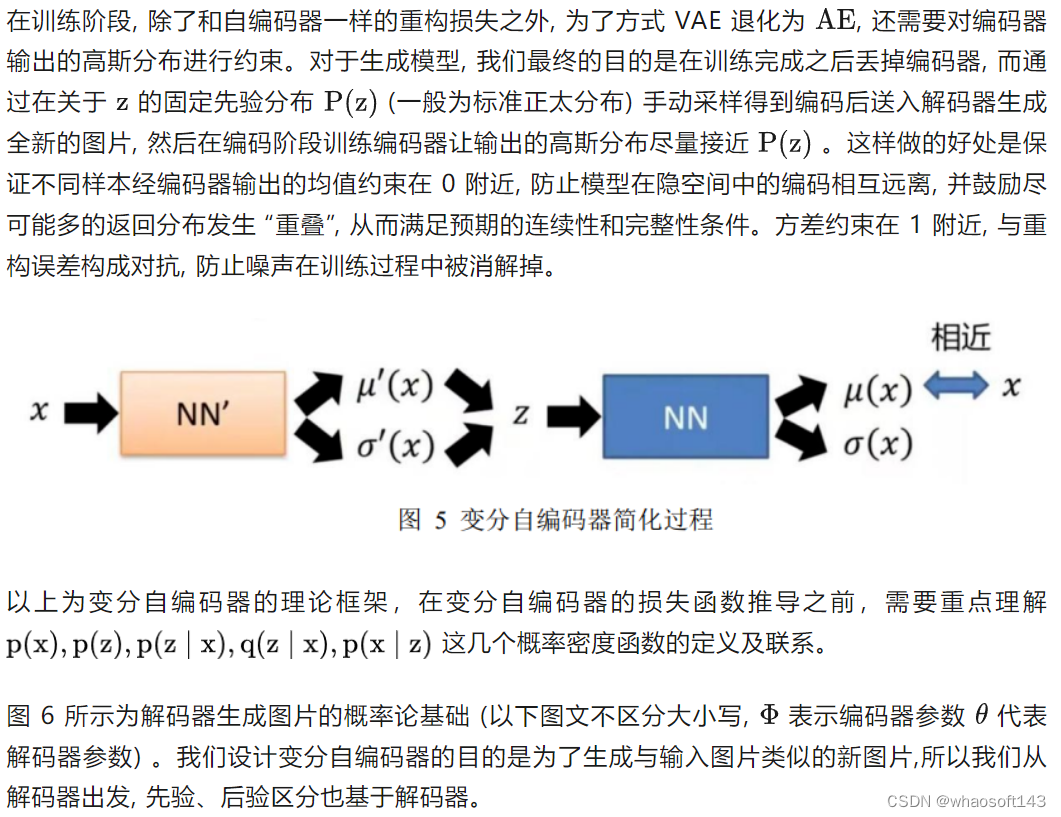
变分自编码器(VAE)
自编码器 (AE) 存在的问题:
自编码器本质上通过训练数据学到的是 “输入图片-特征编码-重构图片” 之间固定的映射关系。
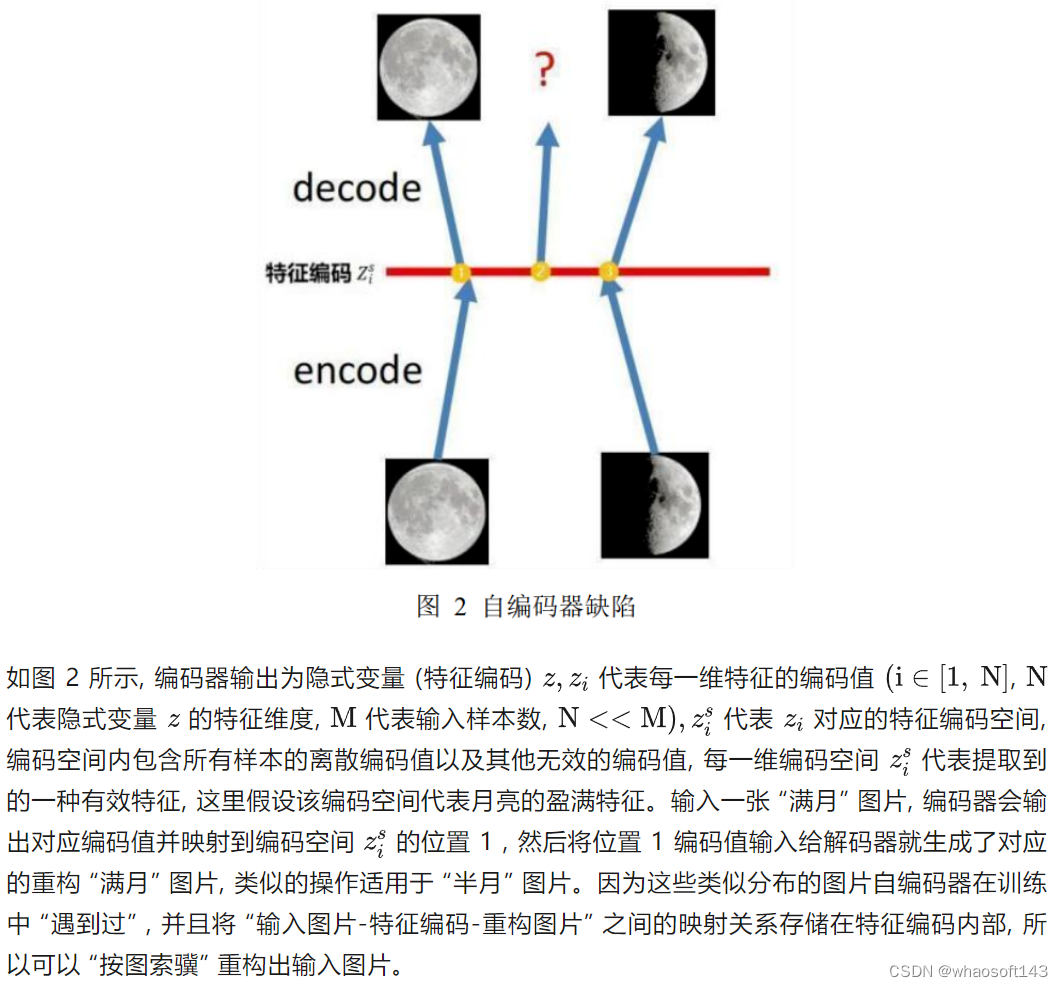
但是如果我们输入一张 “四分之一月” 的图片或者直接在编码空间取位置 1 和 3 之间的位置 2 编码值, 输入解码器是否能重构出输入图片呢? 此时解码器由于缺少对应 “特征编码 -重构图片” 对应的映射关系, 两个相邻编码值之间也不存在任何关联, 模型也无从知道位置 2 编码值的重构结果应该介于位置 1 和 3 编码值之间, 输出结果就会出现模糊或乱码。这也说明了自编码器存在泛化性差且不具备生成能力的缺陷。
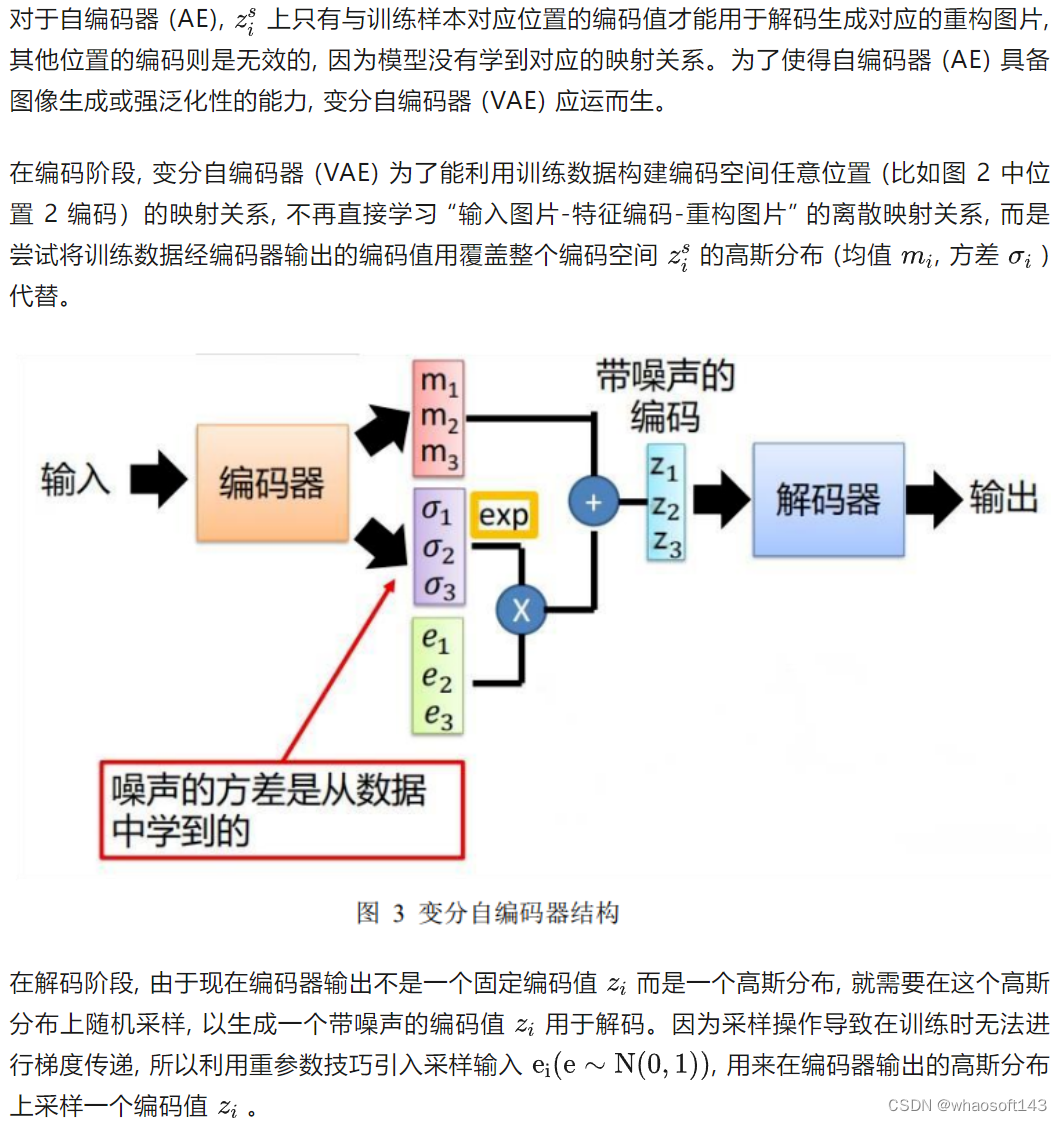

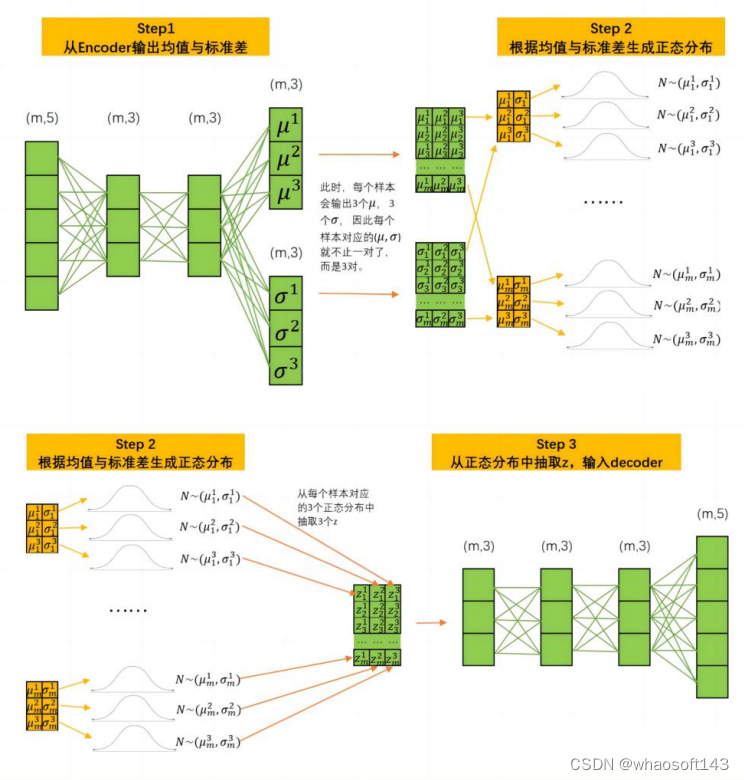 图 4 变分自编码器正向传播
图 4 变分自编码器正向传播


超先验变分图像压缩模型
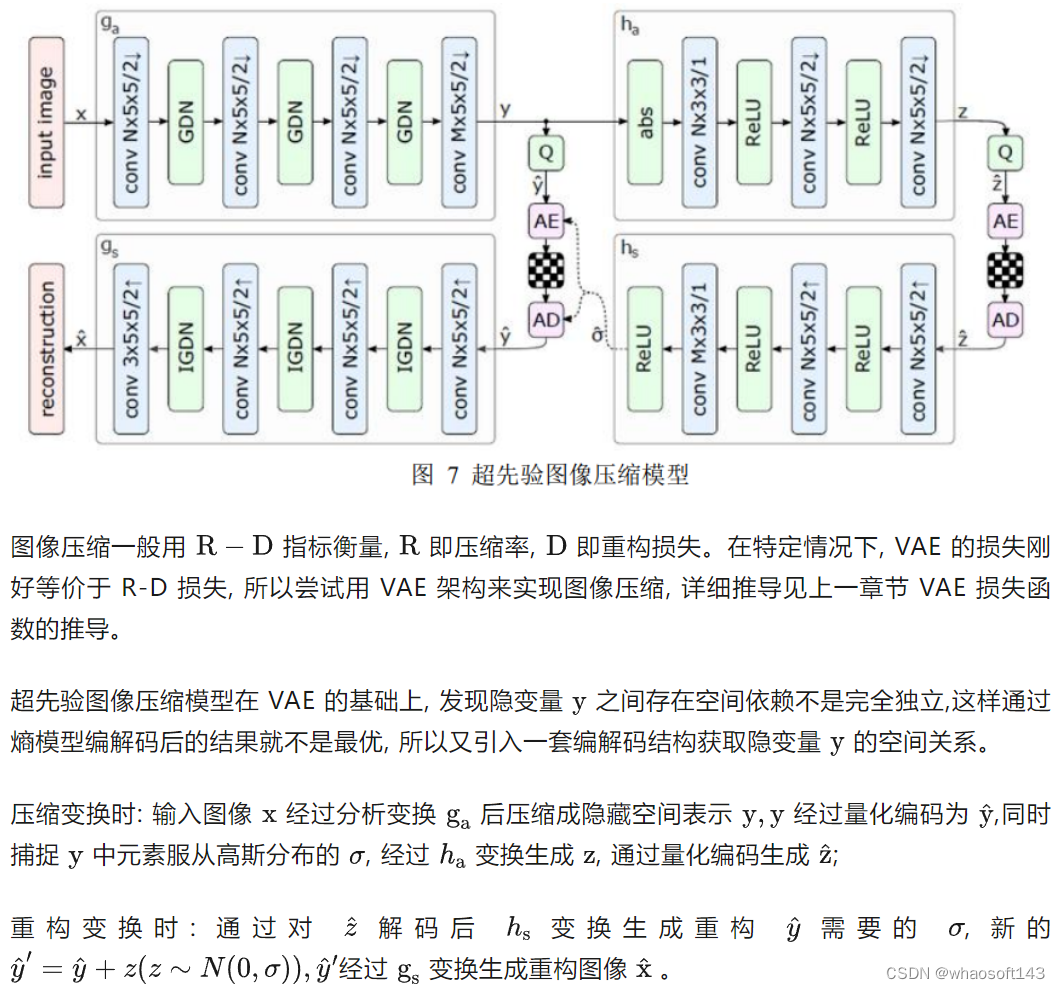
根据 VAE 推导出损失函数定义:
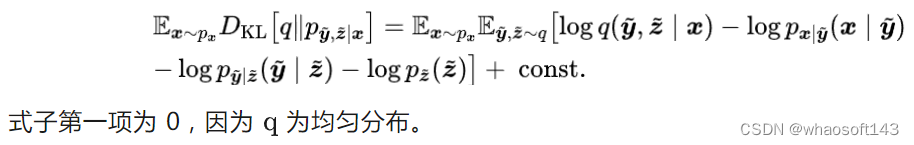
第二项代表重构损失。
第三、四项代表相应交叉嫡, 代表编码长度损失。
ELIC
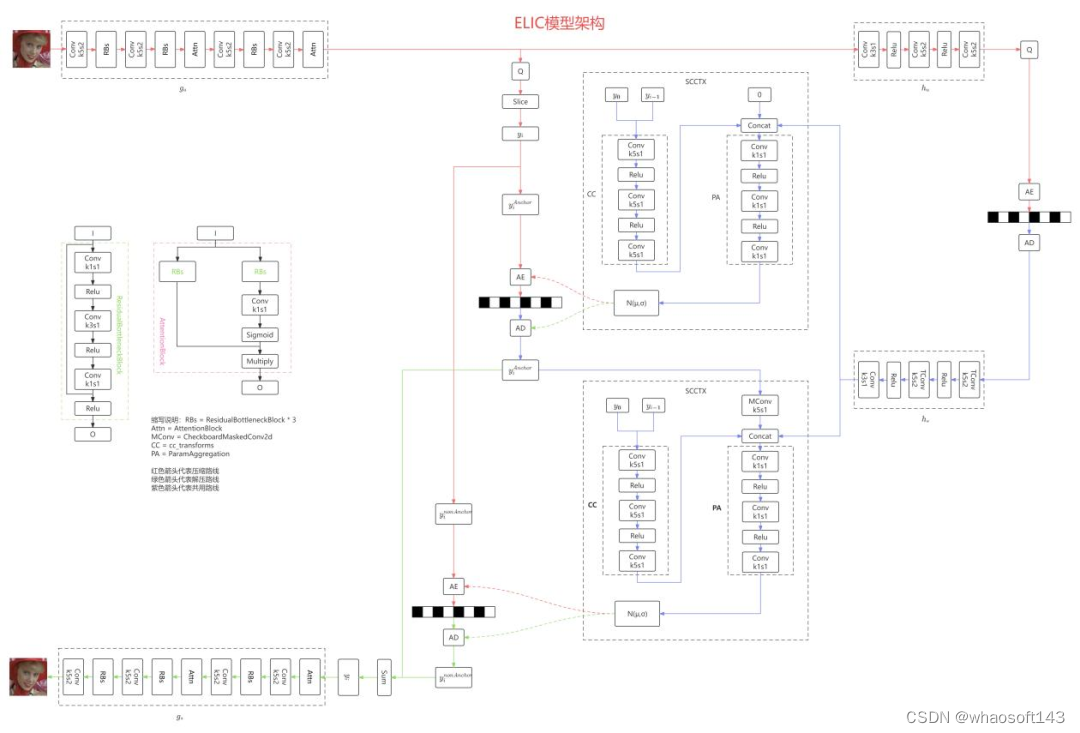 图8ELIC模型结构(红色箭头代表压缩路线,绿色箭头代表解压路线,紫色箭头代表共用路线)
图8ELIC模型结构(红色箭头代表压缩路线,绿色箭头代表解压路线,紫色箭头代表共用路线)
本文在基于超先验变分图像压缩模型架构的基础上, 提出对编码特征进行空间和通道两个维度融合的上下文结构 SCCTX,与超先验信息融合之后共同预测编码特征之间存在的依赖关系用于摘模型编解码。其中通道维度还进行不均匀分组并按照信息重要程度顺序存储,空间维度采用两阶段棋盘格方法加速。 whaosoft aiot http://143ai.com
改进 1
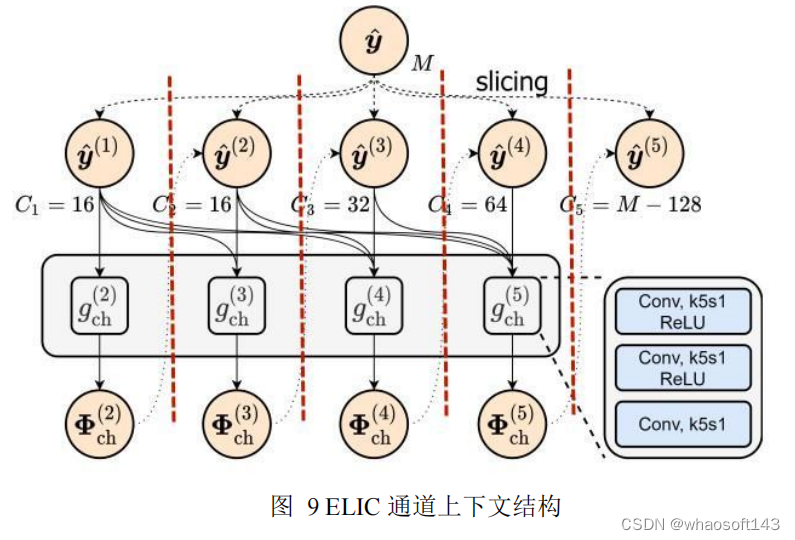
项目要求满足随机渐进压缩(随机丢包均能解压出图片), 原版 ELIC 虽然也支持渐进压缩, 但是限制只能末端丢包, 不满足要求。为此我们进行第一项改进, 将 ELIC 的通道维度上下文中通道间的联系 “斩断” (图 9 中红色虚线), 这样通道间不存在依赖关系, 当前解压包就不需要前一个解压包信息才能解压。
改进 2
针对输出的压缩包大小不够均匀的问题, 将通道数全部改为 64 , 保证各个包的理论容量相同。在损失函数中对不同压缩包的 bpp 损失计算方差并加入损失函数监督训练, 结果有效保证了各个压缩包的大小均匀。
改进 3
针对 MSE-optimized 模型在 bpp 较小时出现的模糊问题, 在损失函数中引入 LPIPS 损失,该损失更加注重肉眼主观视觉效果, 最终在 bpp 变化不大的情况下解压图片的清晰度有较大提升。根据参考文献 5、6, 还可以引入 GAN-loss 来进一步增强重构图片的真实视觉效果。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 9
9 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)