Hadoop全分布式集群搭建(全网最详细,保姆级教程)
Hadoop全分布式集群搭建
在上一篇Hadoop环境搭建(全网最详细,保姆级教程)中已经搭建好了一个单机Hadoop环境,接下来搭建全分布式Hadoop集群
首先对Hadoop全分布示集群进行简单介绍和规划
一个集群由一个主机,若干台子机组成
一台主机master,在HDFS中担任NameNode角色、在YARN中担任ResourceManager角色。
若干台子机在HDFS中担任DataNode角色、在YARN中担任NodeManager角色
内部IP地址可以自己更改
| 服务器名称 | 内部IP地址 | HDFS | YARN |
|---|---|---|---|
| matser | 192.168.56.100 | NameNode | ResourceManager |
| data1 | 192.168.56.101 | DataNode | NodeManager |
| data2 | 192.168.56.102 | DataNode | NodeManager |
| data3 | 192.168.56.103 | DataNode | NodeManager |
搭建步骤
第一步全复制上次搭建好的单机
选中上次搭建好的单机,单机鼠标右键——>点击复制——>输入虚拟机的名称“data1”——>MAC地址设定选择“重新生成 MAC 地址”——>点击“下一步”——>勾选“完全复制”——>点击“复制”。
第二步设置网卡
将在每台机器上设置两张网卡
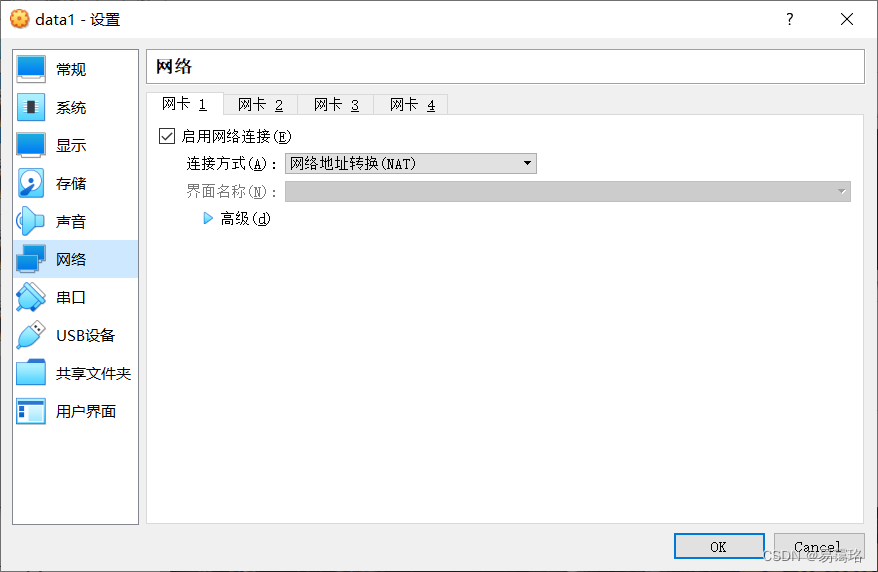
- 网卡1:设置为“NAT网卡”,用于连接外部网络
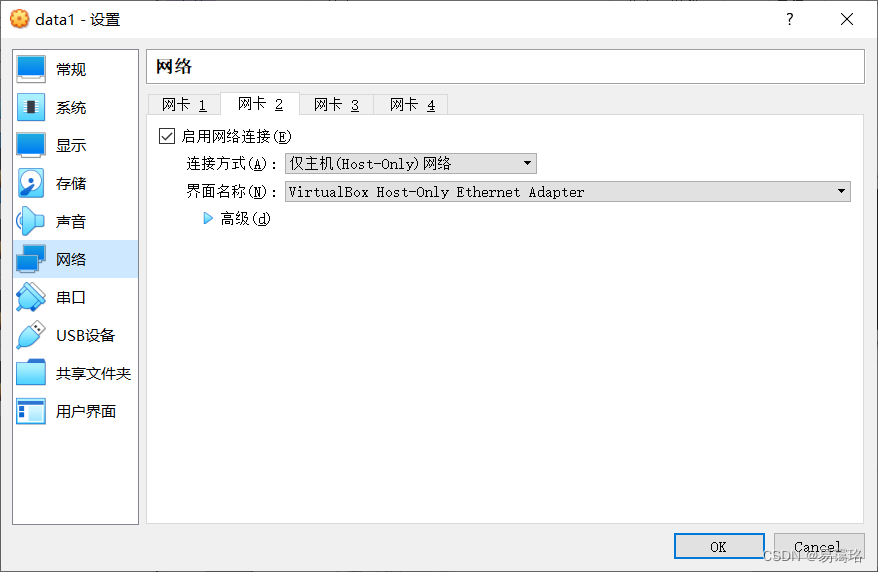
- 网卡2:设置为“仅主机适配器”,用于内部网络通信,连接虚拟机与真机
操作步骤:选中“data1”——>单机“设置”——>单机“网络”——>单机"网卡1"——>选择“网络地址转换(NAT)”——>单机"网卡2"——>勾选"启用网络连接"——>选择“仅主机网络”——>点击“确定”
第三步设置data1服务器
启动data1打开终端
1.编辑interfaces网络配置文件
sudo gedit /etc/network/interfaces
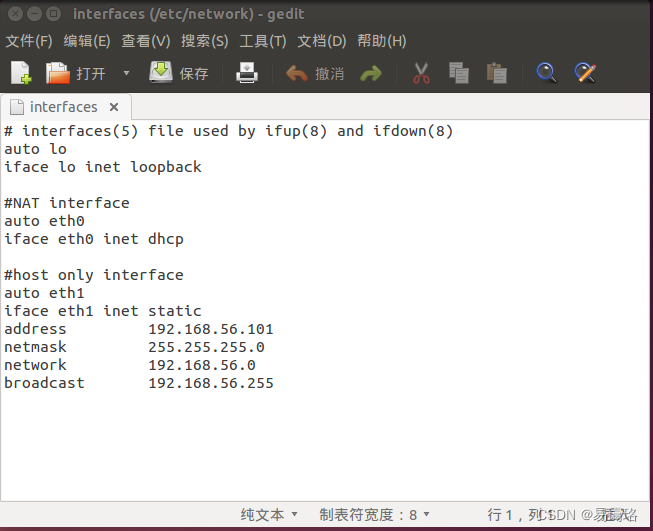
设置网卡1,可以通过Host主机连接至外部网络,设置为eth0,并且设置dhcp自动获得ip地址
auth eth0
iface eth0 inet dhcp
设置网卡2,用于建立内部网络,设置为eth1,并且设置为static固定ip
auth eth1
iface eth1 inet static
address 192.168.56.101
network 255.255.255.0
network 192.168.56.0
broadcast 192.168.56.255
2.编辑hostname主机名
sudo gedit /etc/hostname
输入data1即可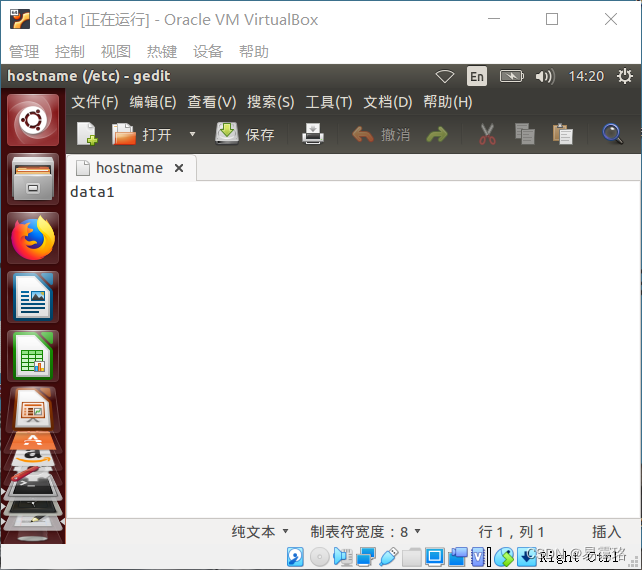
3.编辑hosts文件
sudo gedit /etc/hosts
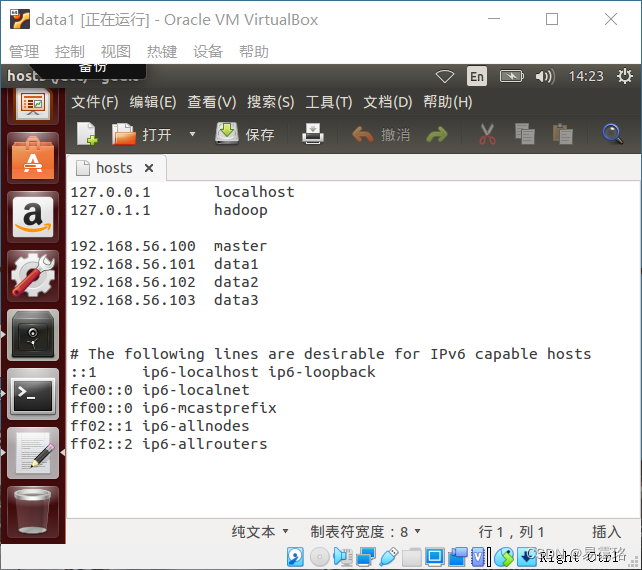
4.编辑core-site.xml文件
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
将localhost改为master即可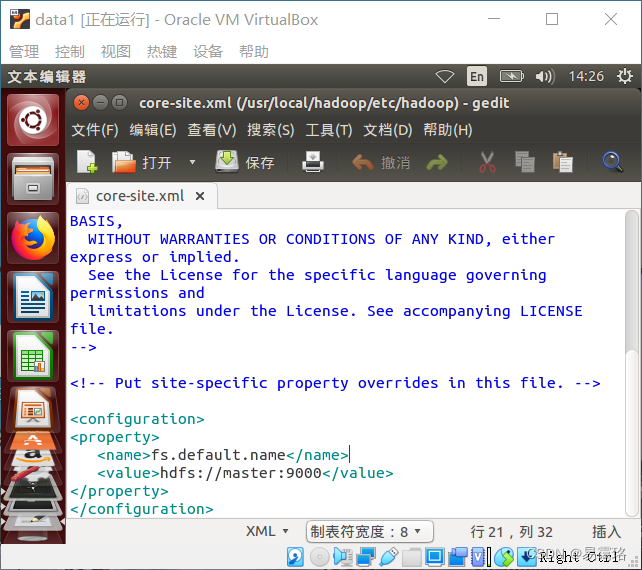
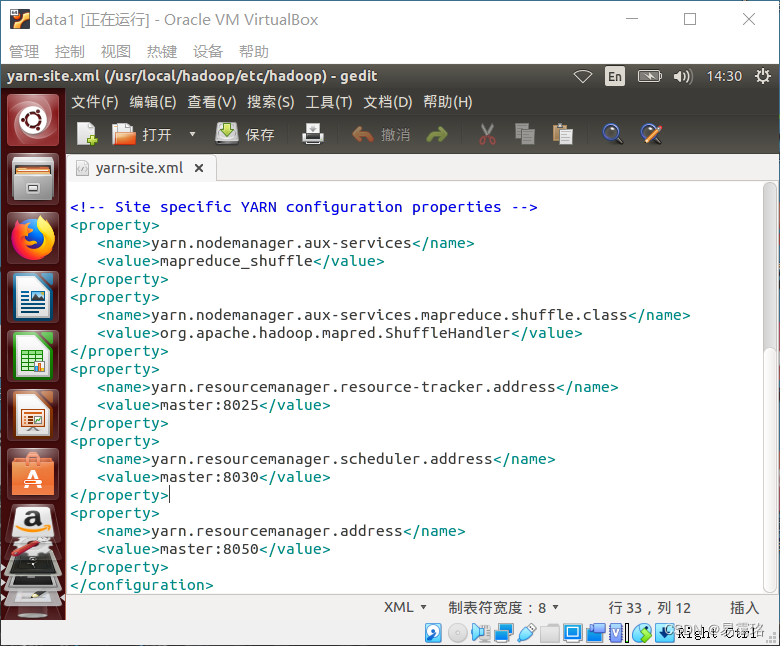
5.编辑yarn-site.xml文件
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
将下面配置添加进去
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
6. 编辑mapred-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
修改mapreduce.job.tracker的连接地址为master:54311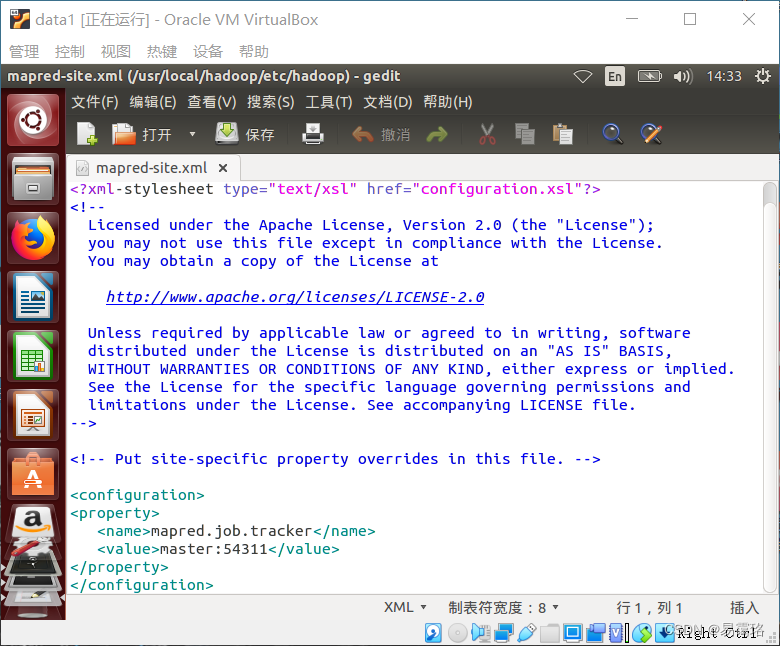
7. 编辑hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
设置datanode HDFS存储目录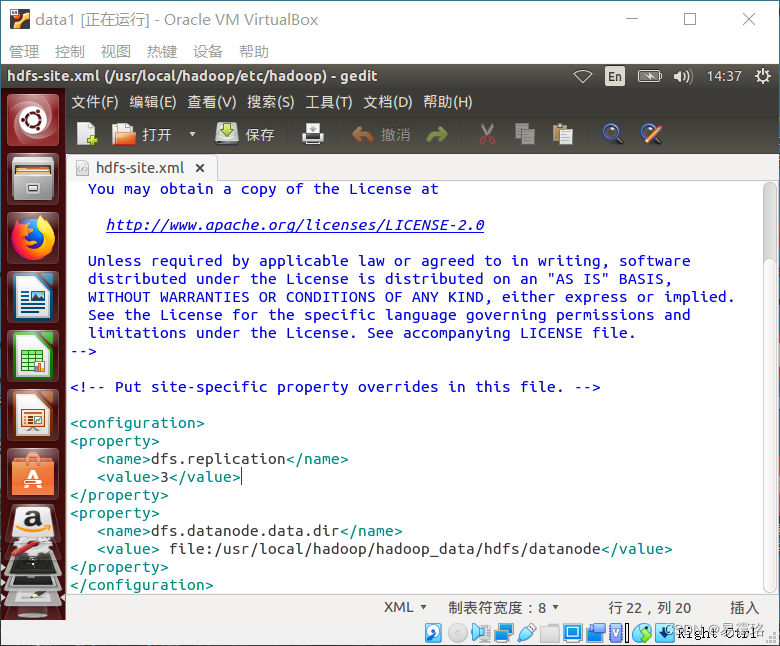
关机重新启动
打开终端输入 ifconfig 查看ip是否配置成功,打开浏览器查看是否能连接网络,检查都为正常然后关机
第四步 按照第一步完成复制data1为data2,data3,master三台机器并修改配置
分别启动三台机器进行修改
- 分别设置data2,data3服务器
data2:将ip改为192.168.56.102
data3:将ip改为192.168.56.103
master:将ip改为192.168.56.100
sudo gedit /etc/network/interfaces
- 分别设置data2,data3主机名
data2:输入data2
data3:输入data3
master:输入master
sudo gedit /etc/hostname
- master修改配置文件
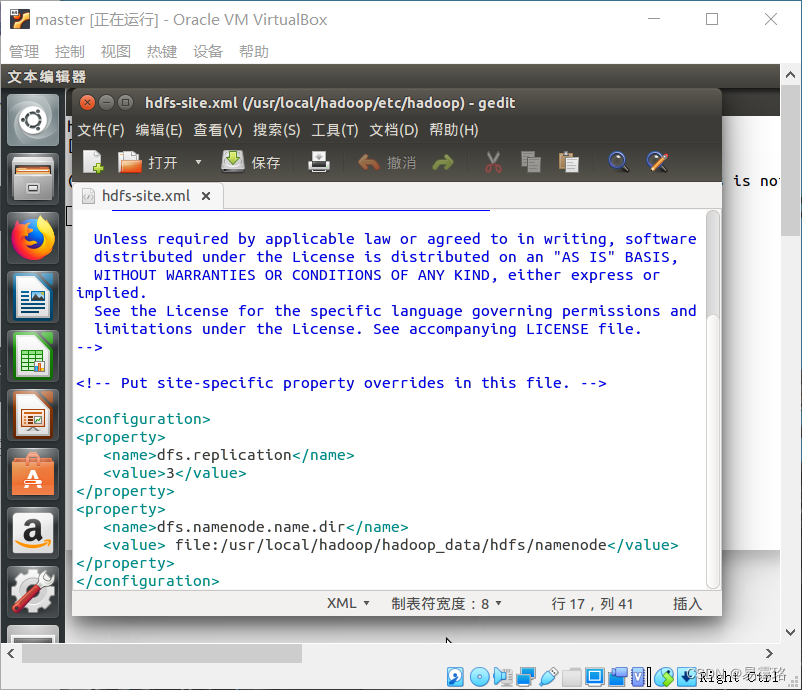
hdfs-site.xml
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
删除datanode的设置,并更改为namenode的配置
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value> file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
</configuration>
编辑master文件
目的告诉hadoop哪些机器是namenode
sudo gedit /usr/local/hadoop/etc/hadoop/masters
输入master即可
编辑slaves文件
目的告诉hadoop哪些机器是datanode
sudo gedit /usr/local/hadoop/etc/hadoop/slaves
并列输入
data1
data2
data3
配置完毕,关机。
第五步启动四台机器,并通过master连接data1,data2,data3创建HDFS目录
一、在子机上创建datanode HDFS目录
-
在master终端输入
ssh data1连接到data1 -
删除hdfs 所有目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
- 创建datanode存储目录
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
- 将目录的所有者改为hduser
sudo chown -R hduser:hduser /usr/local/hadoop
- 退出data1,回到master终端输入
exit - 分别在data2,data3机器上重复2~4的操作
二、.在master上重新创建namenode HDFS目录并格式化
- 删除hdfs目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
- 创建namenode目录
mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
- 将目录的所有者改为hduser
sudo chown -R hduser:hduser /usr/local/hadoop
- 格式化namednode
haoop namenode -format
或者是 hdfs namenode -format
第六步启动集群
(确保四台机器全部启动后)
在master终端输入 start-all.sh
启动后查看运行的进程终端输入jps
再连到data1,data2,data3查看正在运行的进程(三个子机运行的进程相同)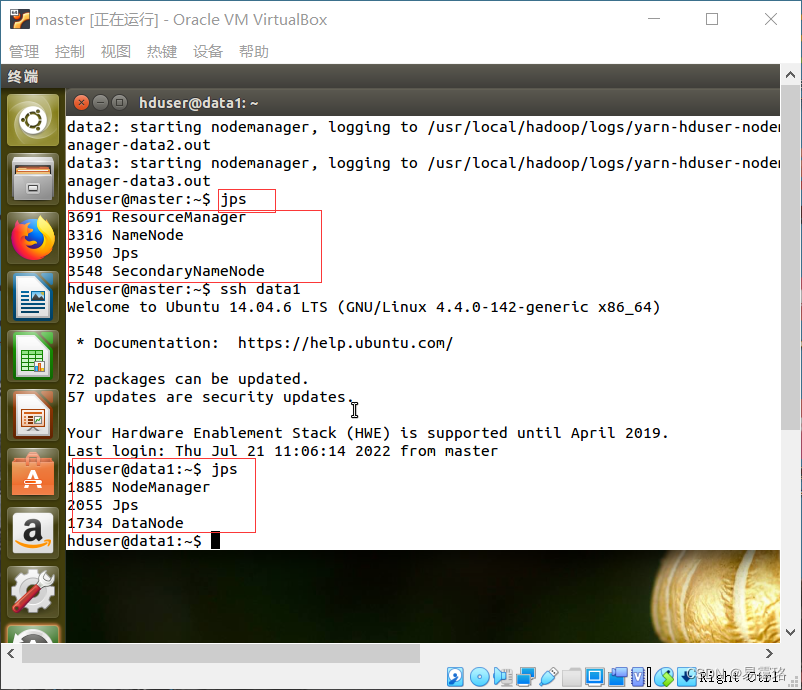
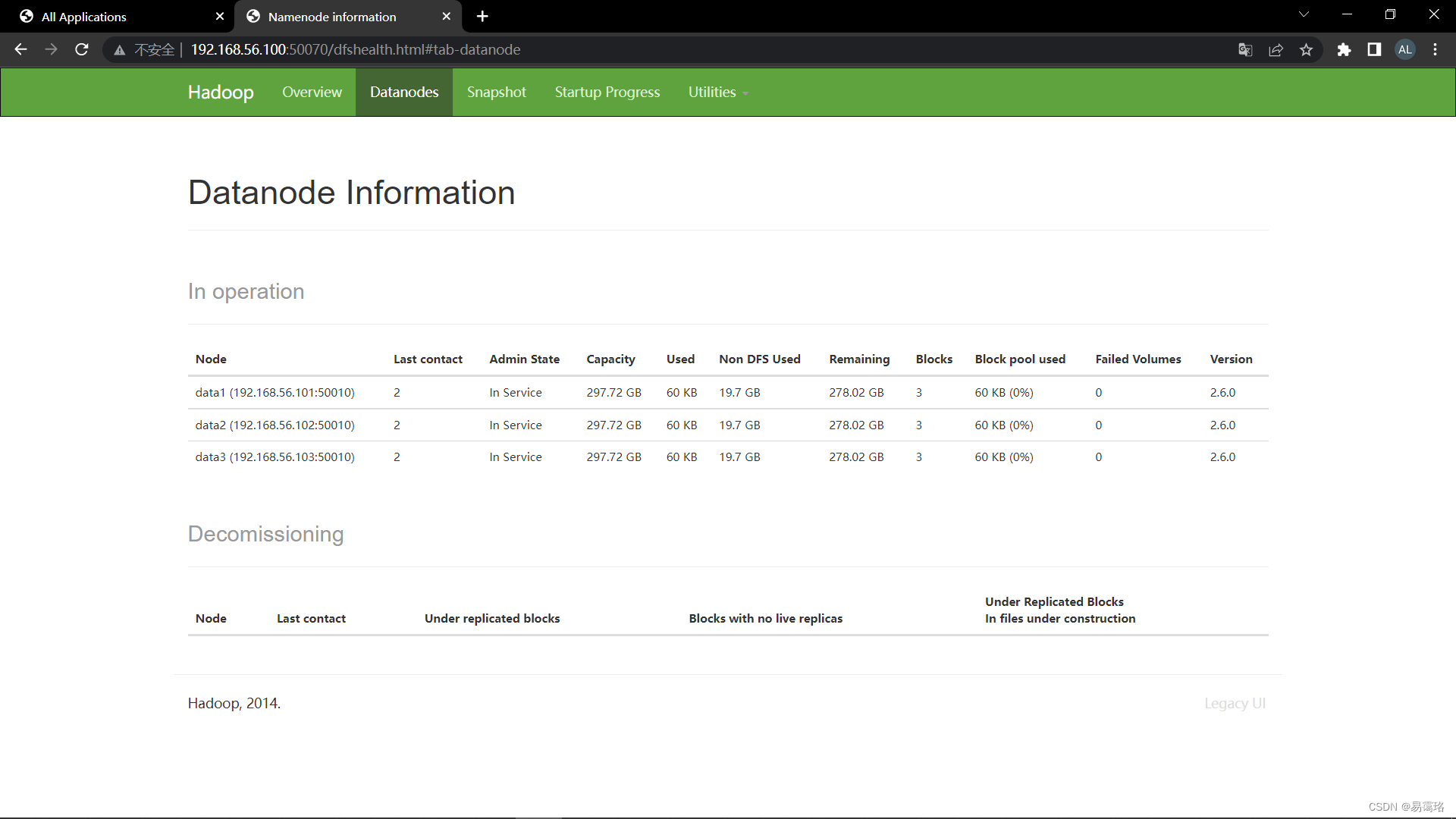
再在浏览器中输入192.168.56.100:8088/cluster和192.168.56.100:50070(或者在虚拟机中的浏览器输入localhost:8088/cluser和localhost:50070)能正常这打开两个网页说明hadoop集群搭建成功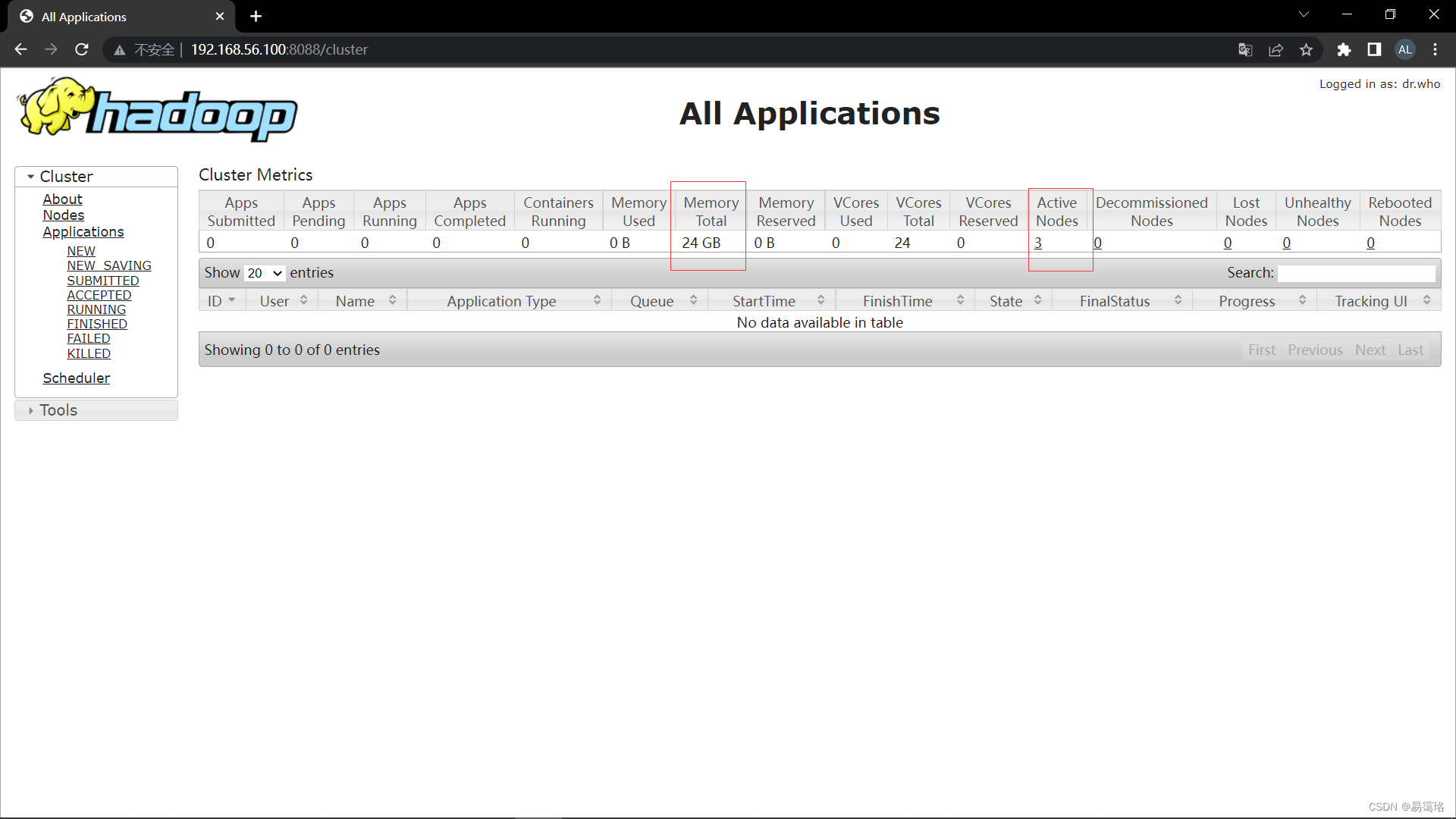

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)