c# url encode编码转换_encode 和decode——带你探索编码与解码的世界
本文作者:孙晓玲文字编辑:余术玲技术总编:张邯重磅!!!爬虫俱乐部将于2019年10月2日至10月5日在湖北武汉举行Python编程技术培训,本次培训采用理论与案例相结合的方式,旨在帮助零基础学员轻松入门Python,由浅入深学习和掌握Python编程技术,尤其是爬虫技术和文本分析技术。该培训目前在火热招生中,点击《爬虫俱乐部2019十一Python编程技术培训报名啦!》或点击文末...
本文作者:孙晓玲
文字编辑:余术玲
技术总编:张 邯
重磅!!!爬虫俱乐部将于2019年10月2日至10月5日在湖北武汉举行Python编程技术培训,本次培训采用理论与案例相结合的方式,旨在帮助零基础学员轻松入门Python,由浅入深学习和掌握Python编程技术,尤其是爬虫技术和文本分析技术。该培训目前在火热招生中,点击《爬虫俱乐部2019十一Python编程技术培训报名啦!》或点击文末阅读原文,了解培训详细信息,抓紧时间报名吧!在7月31日的推文中,已经为大家简单介绍了Unicode编码的由来,并且介绍了Python中查看单个字符编码的一对互逆函数ord(c)和chr(i)。今天将继续为大家介绍Python中有关中文编码的小知识并介绍有关编码和解码的两种数据处理方法encode和 decode。一、常见的中文编码GB2312编码是在ASCII编码基础上扩展来的,在1980年由中国国家标准总局发布,其中最主要的变化就是引入了简体中文的编码,一共容纳了包括简体中文在内的6000多个字符。仅仅是简体中文肯定是不够用的,1995年,GBK编码在GB2312编码的基础上进行扩充,加入了繁体中文和一些符号的编码,扩充后容纳了20000多个字符。56个民族56枝花,中华儿女56个民族不同民族之间的语言符号也有一定的差异,为了编码大团圆,2000年,GBK再一次被扩充,就产生了GB18030编码,GB18030编码不仅容纳简体中文和繁体中文,还纳入少数民族汉字,一共70000多个汉字和字符,GB18030是在GB2312和GBK的基础上扩充的,比GB2312和GBK更广阔。二、.encode()方法和.decode()方法.encode( )和.decode()分别称为编码方法和解码方法,字符串通过编码转换为字节码(一种二进制数据类型,如Unicode编码),字节码通过解码转换为可以被人类读懂的字符串。它们的关系如下图所示。
str0= '爬虫俱乐部'byte0= str0.encode('gb2312') # 以gb2312编码对str0进行编码,获得bytes类型对象print(byte0)
str0= '爬虫俱乐部'byte0= str0.encode('gb2312') # 以gb2312编码对str0进行编码,获得bytes类型对象str1=byte0.decode('gb2312')# 对gb2312编码的byte0进行解码,获得str类型对象print(str1)
成功将“爬虫俱乐部”的二进制编码解码为字符串“爬虫俱乐部”。
三、网络爬虫应用前面已经为大家介绍过,默认情况下,Python 源码文件以 UTF-8 编码方式处理。但并非所有的网页的源代码都是UTF-8 编码的,较新的网页一般为UTF-8编码,一些有年代的网站可能是GB2312等其他编码方式,这样我们获取的网页源代码中的中文将出现乱码,或者post的表单需要使用GBK编码的字节流形式传送,encode和decode就能为我们解决问题。以爬取新浪财经高管任职信息为例。在本例中,为了阅读简便我们选取平安银行的高管任职信息为例。新浪财经的网页源代码为GB2312编码,所以当我们直接打印网页源代码的文本格式数据时,中文就会显示乱码。import requests #导入requests模块url="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml"text=requests.get(url).text#通过requests 模块的get方式将源代码赋给textprint(text)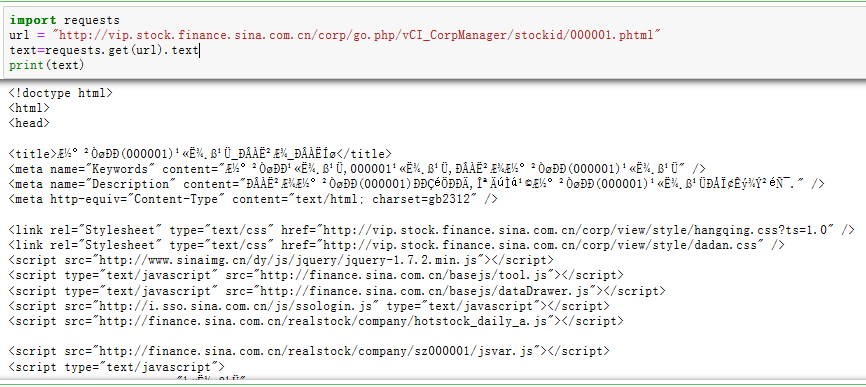
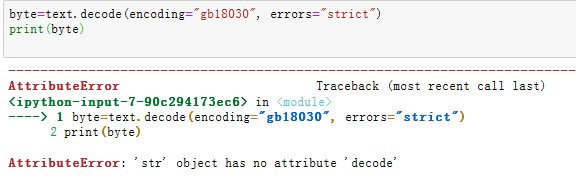
byte=text.decode(encoding="gb18030",errors="strict")print(byte)结果如下:
import requestsurl="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml"content=requests.get(url).content#将源代码的编码字节赋给contentbyte=content.decode(encoding="gb18030",errors="strict")print(byte)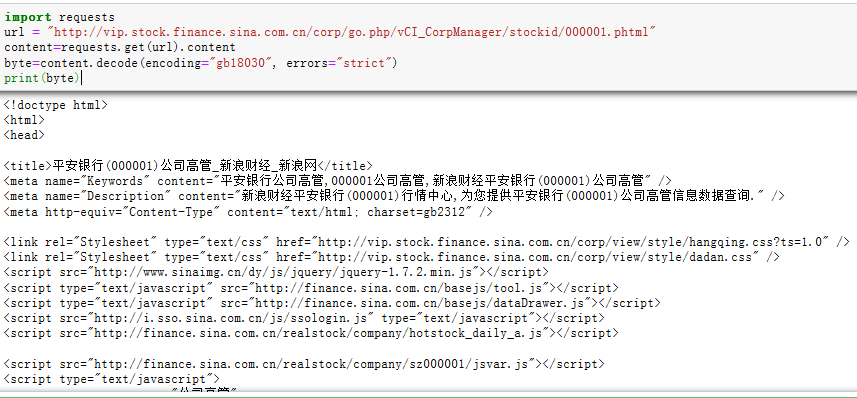
import requestsurl="http://vip.stock.finance.sina.com.cn/corp/go.php/vCI_CorpManager/stockid/000001.phtml"text=requests.get(url)text.encoding= "gb18030"print(text.text)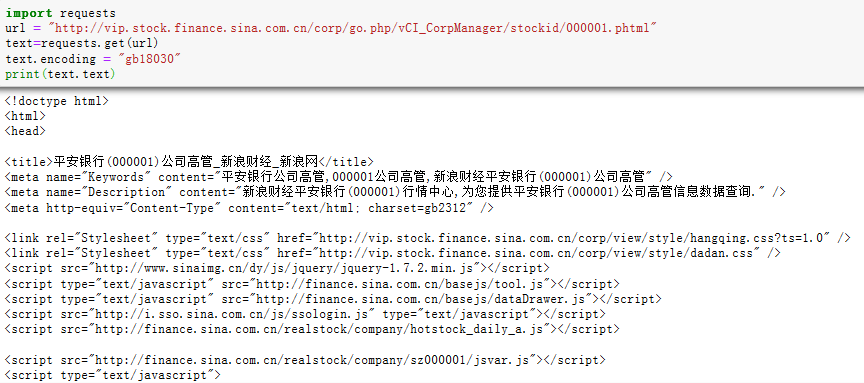

对爬虫俱乐部的推文累计打赏超过1000元我们即可给您开具发票,发票类别为“咨询费”。用心做事,只为做您更贴心的小爬虫!
往期推文推荐
字符串方法(二)
如何快速生成分组变量?
用Stata实现数据标准化字符串方法介绍
Jupyter Notebook的使用
Stata16新功能之“框架”——frlink连接多个数据集(3)Stata16新功能之“框架”——基础命令大合集(2)三分钟教你读懂Python报错解析XML文件命令更新之reg2docx:将回归结果输出到word
命令更新之t2docx——报告分组均值t检验
爬虫俱乐部2019十一Python编程技术培训报名啦!
数据类型——Dict、Set与Frozenset简析
数据类型介绍——tuple、list和range对象把pdf文件批量转成docx文件格式化字符串方法的比较朝花夕拾—— 如何输出内存中的矩阵与绘图Stata16新功能——定义图形元素的绝对大小Stata16新功能之“框架”——读入多个数据集(1)关于我们
微信公众号“爬虫俱乐部”分享实用的stata命令,欢迎转载、打赏。爬虫俱乐部是由李春涛教授领导下的研究生及本科生组成的大数据分析和数据挖掘团队。
此外,欢迎大家踊跃投稿,介绍一些关于stata的数据处理和分析技巧。
投稿邮箱:statatraining@163.com
投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到关于stata分析数据的问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)