图像处理:文档图像矫正DocReal
向AI转型的程序员都关注了这个号????????????前言文档图像矫正在图像处理领域属于相对冷门但是很有用的一个任务,这个任务的相关文章还是比较少的,DocReal是2024 WACV的最新文档矫正文章,结合了之前一些技术的亮点,还是值得一看的。paper:DocRealhttps://paperswithcode.com/paper/docreal-robust-document-dewarp

向AI转型的程序员都关注了这个号👇👇👇
前言
文档图像矫正在图像处理领域属于相对冷门但是很有用的一个任务,这个任务的相关文章还是比较少的,DocReal是2024 WACV的最新文档矫正文章,结合了之前一些技术的亮点,还是值得一看的。
paper:DocReal
https://paperswithcode.com/paper/docreal-robust-document-dewarping-of-real
这篇文章建议看两个文章作为背景会更容易理解:
1)paperedge:https://github.com/cvlab-stonybrook/PaperEdge
2)DDCP:图像处理:文档图像矫正DDCP
https://blog.csdn.net/WiSirius/article/details/135752325?spm=1001.2014.3001.5502
一、介绍
文档图像矫正是计算机视觉中的一项重要任务,具有许多实际应用。控制点法(如DDCP)由于其简单高效而备受关注。然而,由于背景噪声和多种变形类型,不准确的控制点预测可能导致不令人满意的性能。为了解决这些问题,提出了一种强大的文档矫正方法,即DocReal,它利用Enet有效地去除背景噪声,并使用注意力增强控制点(AECP)模块更好地捕捉局部变形。此外,通过合成具有3D变形和附加变形类型的2D图像来增强训练数据。提出的方法表现出卓越的矫正精度。
主要贡献如下:
1)提出了一个稳健的文档图像矫正框架,采用 Enet 来有效地消除背景噪音并使用增强注意力控制点(AECP)模块,以更好进行精细矫正。
2)利用 Doc 3D 中的3D图像数据,在Doc3D数据集中用3D变形合成 2D 图像。此外,我们通过添加各种噪声和随机选择的背景来增强训练数据。还通过公式模拟了额外的四种卷曲和折叠变形,以丰富训练数据的变形类型(这部分和DDCP有点像,DDCP的数据生成也是通过公式模拟的—https://github.com/gwxie/Synthesize-Distorted-Image-and-Its-Control-Points)。
二、方法论
基于控制点的DDCP方法仍然面临很大的局限性,特别是在不同的拍摄环境、文本类型和噪声背景下在文本上准确放置控制点时。此任务处理不当可能会导致严重的文本变形和背景残留。为了克服这些挑战,我们从 PaperEdge 方法中汲取灵感,开发了一种新的流程,即 DocReal,它首先使用 Enet 检测文档边缘信息,去除背景噪声并提取文档主体。然后,我们利用注意力增强控制点(AECP)网络来更好地捕获文档的局部变形,与 DDCP 方法相比,预测更准确的控制点。
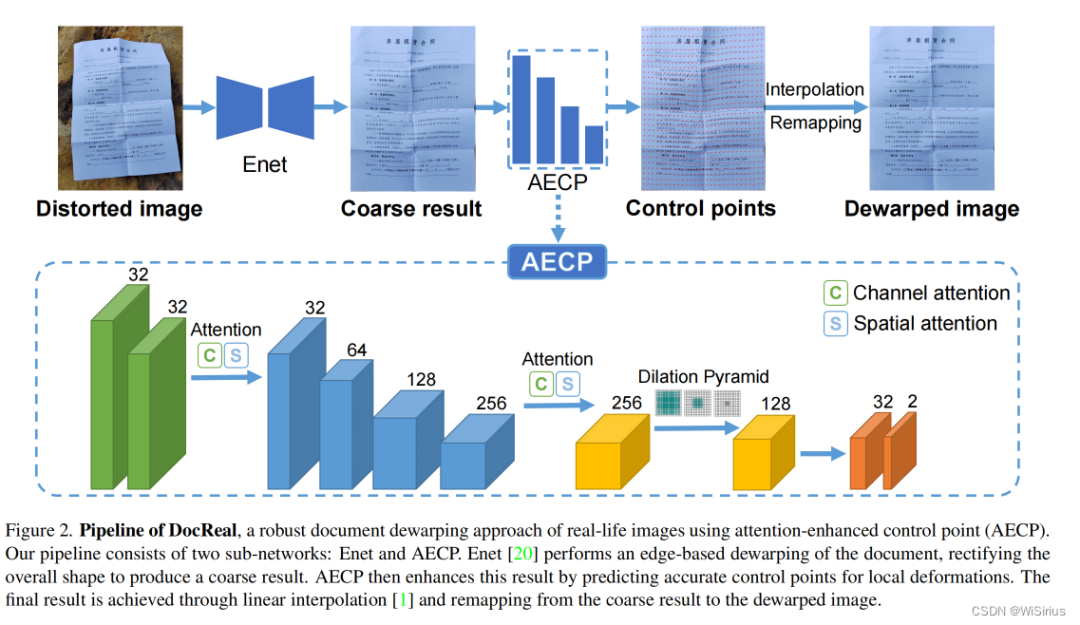
1.模型结构
1)Enet:
Enet 是一个全卷积的编码器-解码器架构,在编码器中使用 6 个残差块,解码器有 4 个残差块。Enet在合成图像(3D数据)和基于真实图像的弱监督训练(和paperedge训练Enet的方式一样)。
2)AECP:
AECP 包括四个子模块,它们协同工作以提高局部变形的控制点预测精度。第一个子模块(图中的绿色)使用两个卷积(k=3,s=2)提取输入图像 I ∈ R 992×992×3 的浅层特征。第二个子模块包含了4层卷积(k=3)。值得注意的是,这两个子模块都通过注意力模块(CBAM模块)得到增强,该模块利用通道注意力和空间注意力来优先考虑关键信息,例如浅层特征(包括光、阴影和纹理)和深层特征(如表格) 线、文本线和整体变形)。
第三个子模块(图中的黄色)利用空洞卷积金字塔来拓宽全局感受野。膨胀金字塔由六层组成,最大膨胀率为18。将具有不同尺度的六层特征连接起来,然后将它们输入到1×1卷积层中以获得全局变形特征。第四个子模块(图中的橙色)使用两层卷积网络来预测控制点P ∈ R 2×31×31。31 × 31 网格上的每个控制点都有跨越整个文档的 (x, y) 坐标,从而形成一个强大的控制点框架,增强不同环境条件和文本类型下的可读性。
(个人感觉整个AECP网络结构就是在DDCP的网络上加了一个CBAM模块,其它部分都一样,包括空洞卷积连接部分!)
2.损失函数
损失函数和DDCP一样,详细可查看我之前的博客—图像处理:文档图像矫正DDCP
https://blog.csdn.net/WiSirius/article/details/135752325?spm=1001.2014.3001.5502
3.数据合成
有效的文档图像矫正需要具有真实和多样变形的训练数据。然而,DDCP方法的训练数据是由两个函数合成的,导致2D网格与真实世界的变形有显著差异。虽然Doc3D数据集为训练数据提供了丰富而逼真的3D变形,但它不能直接用于训练需要2D数据的控制点网络。
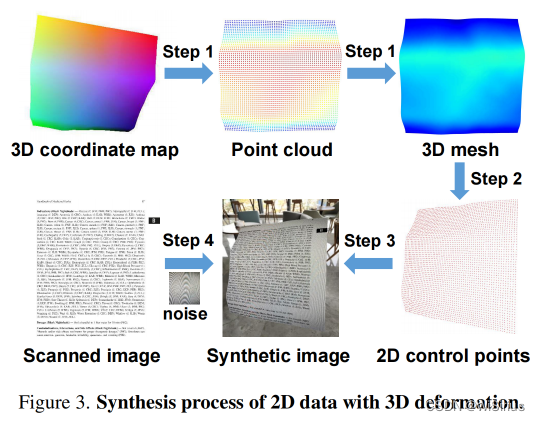
为了克服这个限制,提出了一种新方法,通过以下四个步骤合成具有 3D 变形的 2D 训练数据,如图所示。
1)首先从Doc3D数据集中3D图像的点云中采样31x31的控制点,并将其转换为 3D 网格。
2)其次,在 3D 坐标系中随机设置相机距离和拍摄角度,将 3D 网格中的控制点映射到 2D 控制点。
3)第三,通过将扫描图像的参考点映射到 2D 控制点并插值像素来生成具有 3D 变形的 2D 扭曲图像。
4)后,我们在扫描图像中随机添加各种噪声,例如莫尔图案、指纹、阴影等,以丰富具有随机背景的合成图像。所提出的数据合成方法可以生成大量具有真实且多样化的 3D 变形的 2D 训练数据,这对于训练文档图像去扭曲的控制点网络至关重要。
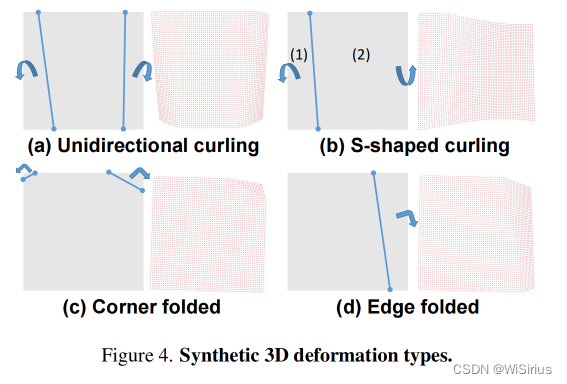
4.数据增强
虽然 Doc3D 数据集提供了一系列变形,但它缺乏书籍类型的真正卷曲。为了解决这个问题,论文使用公式模拟书籍的卷曲,并添加额外的折叠变形来增强训练数据,从而实现更稳健的模型性能。
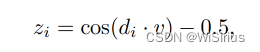

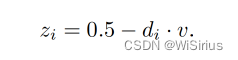
其中仅修改z轴值,0.5为原始z值,di为控制点到最近线的距离,v为控制卷曲程度的超参数。
5.实验结果


总结
个人感觉DocReal结合了paperedge中Enet和DDCP中的控制点思想还是个挺有意思的想法。文章造数据的方法倒是很值得关注,文档矫正很重要的一点是数据精确性,文章造数据的方法很大程度扩充了矫正数据。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献150条内容
已为社区贡献150条内容

所有评论(0)