计算机毕业设计hadoop+spark+hive漫画推荐系统 动漫视频推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据
计算机毕业设计hadoop+spark+hive漫画推荐系统 动漫视频推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据
·
流程:
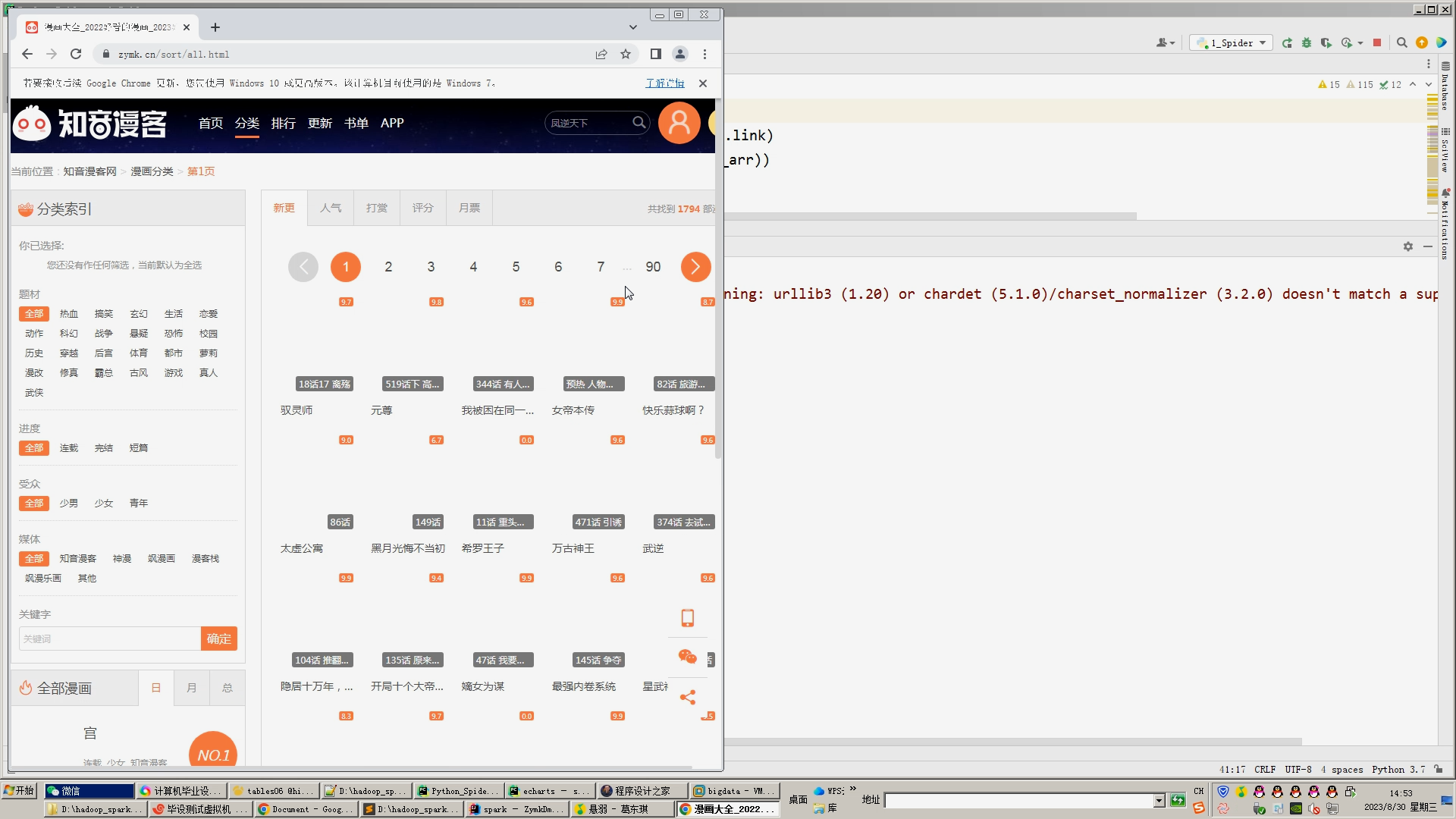
1.DrissionPage+Selenium自动爬虫工具采集漫画视频、详情、标签等约200万条漫画数据存入mysql数据库;
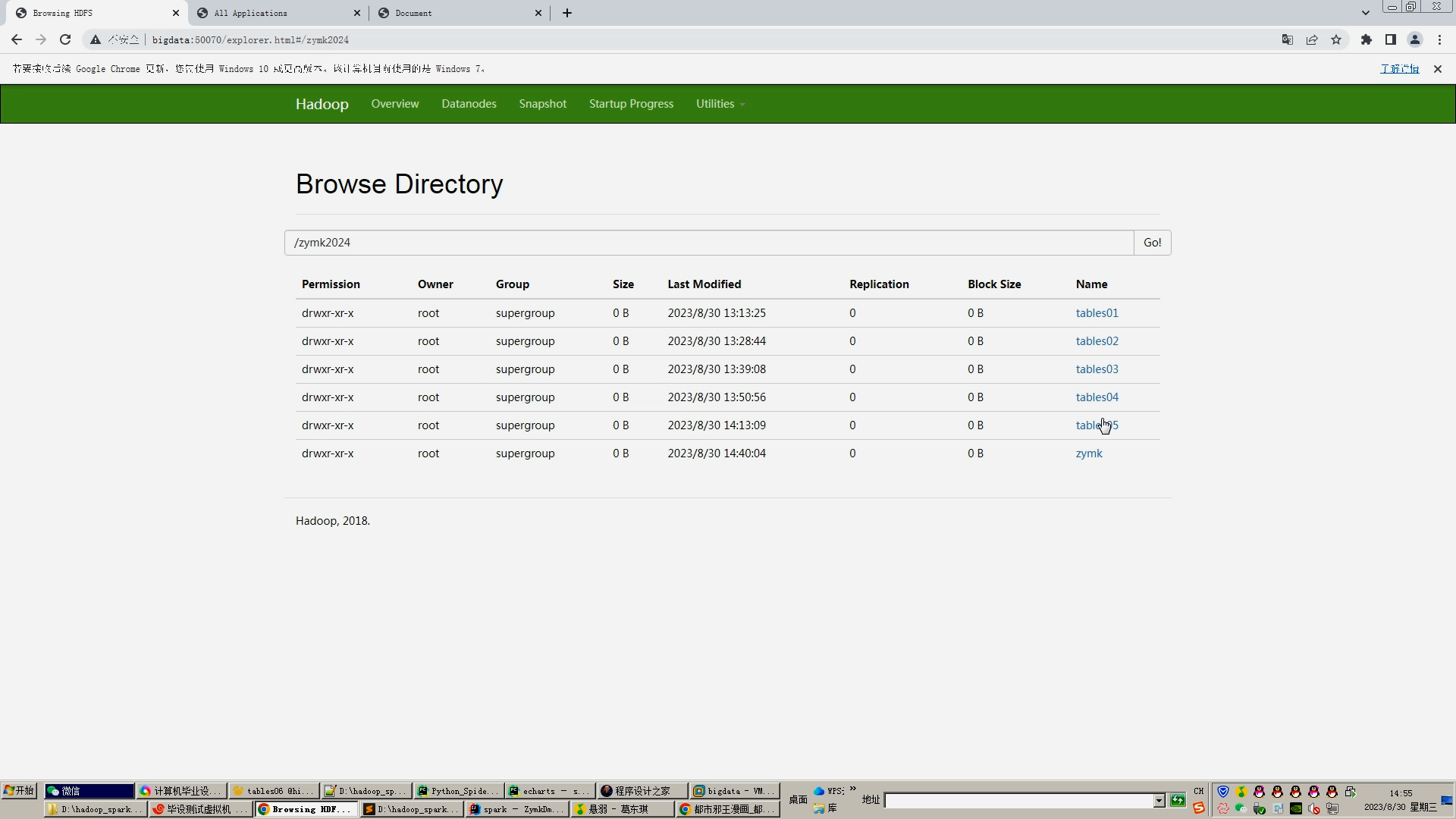
2.Mapreduce对采集的动漫数据进行数据清洗、拆分数据项等,转为.csv文件上传hadoop的hdfs集群;
3.hive建库建表导入.csv动漫数据;
4.一半指标使用hive_sql分析得出,一半指标使用Spark之Scala完成;
5.sqoop对分析结果导入mysql数据库;
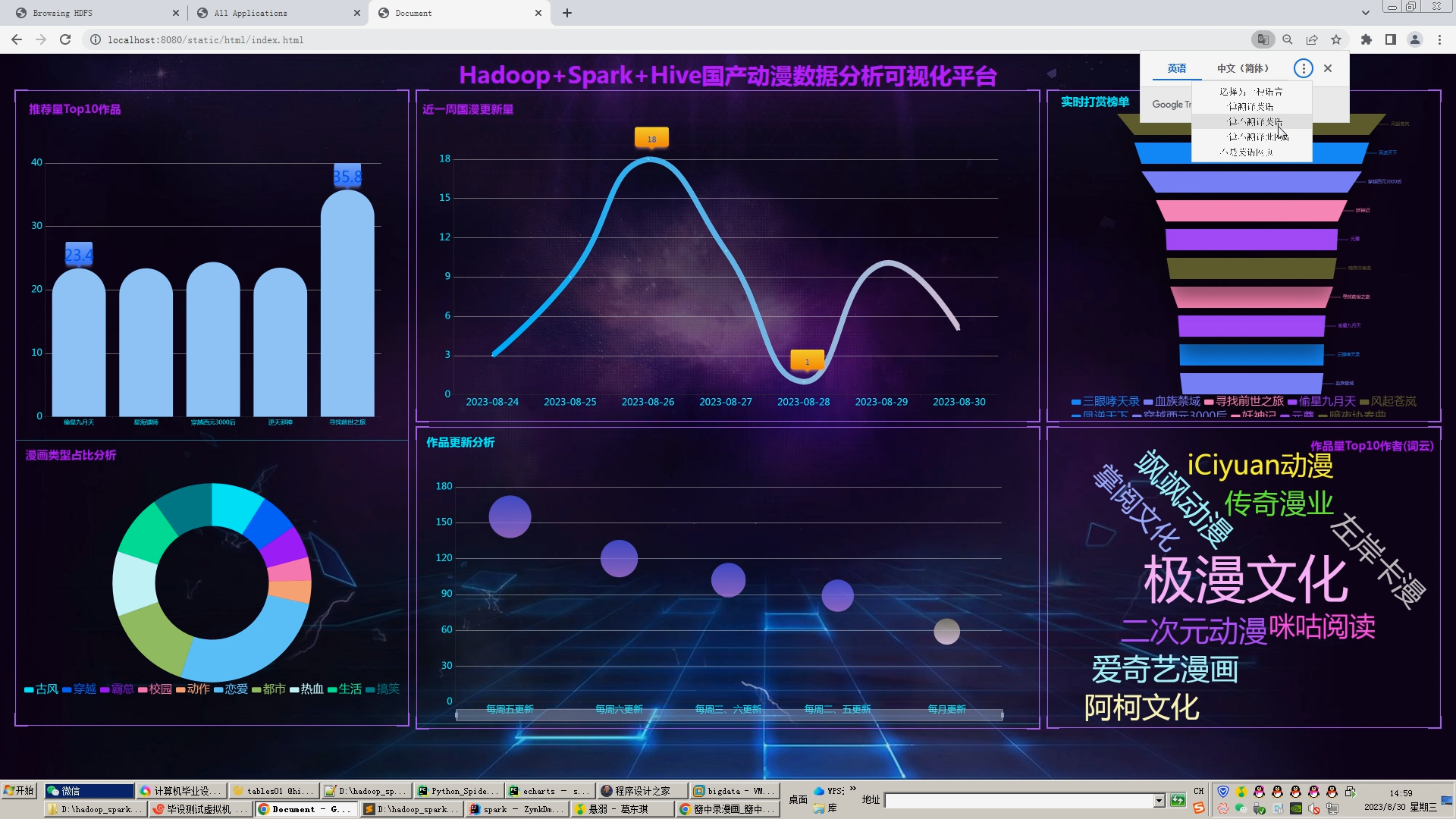
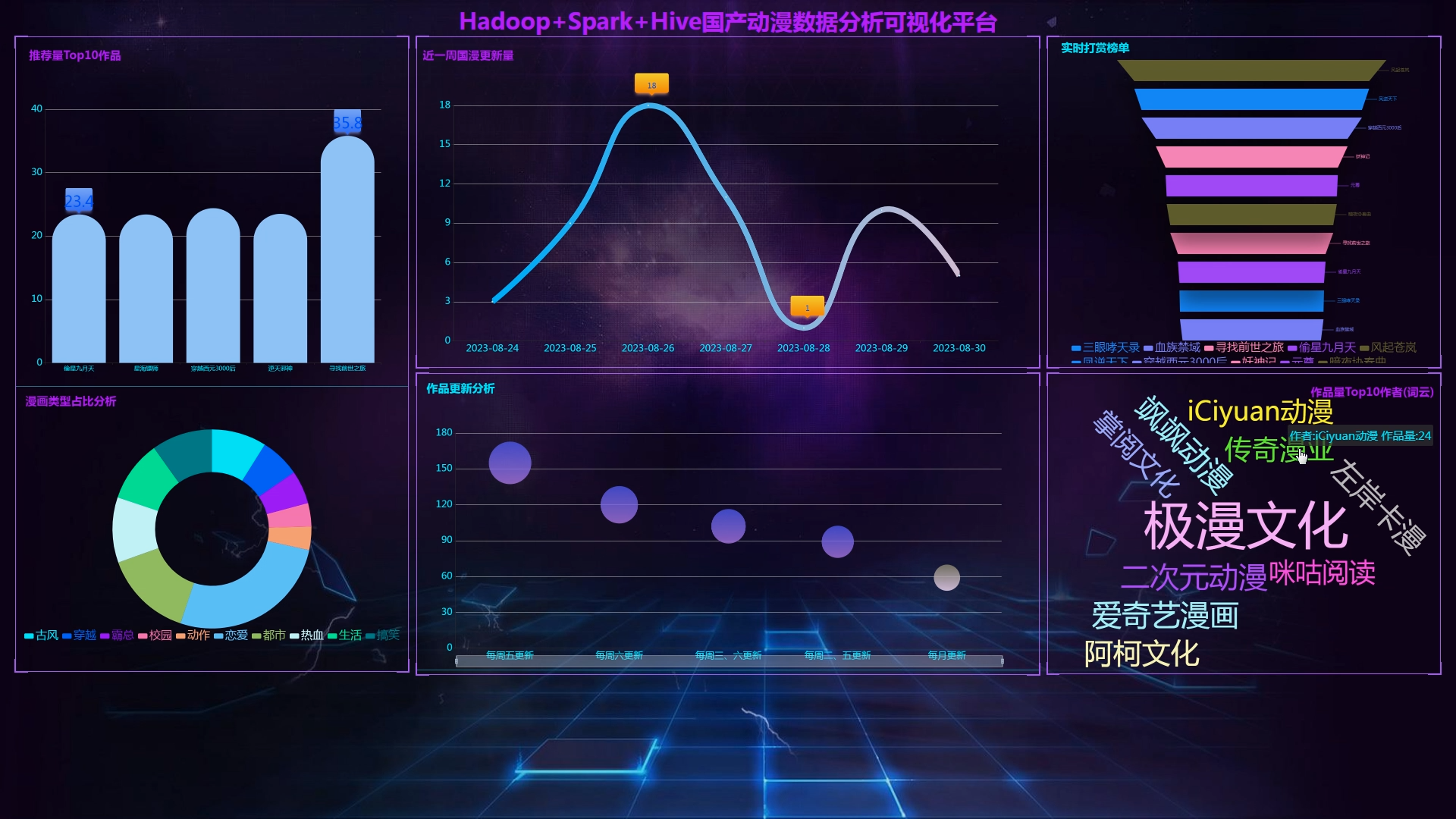
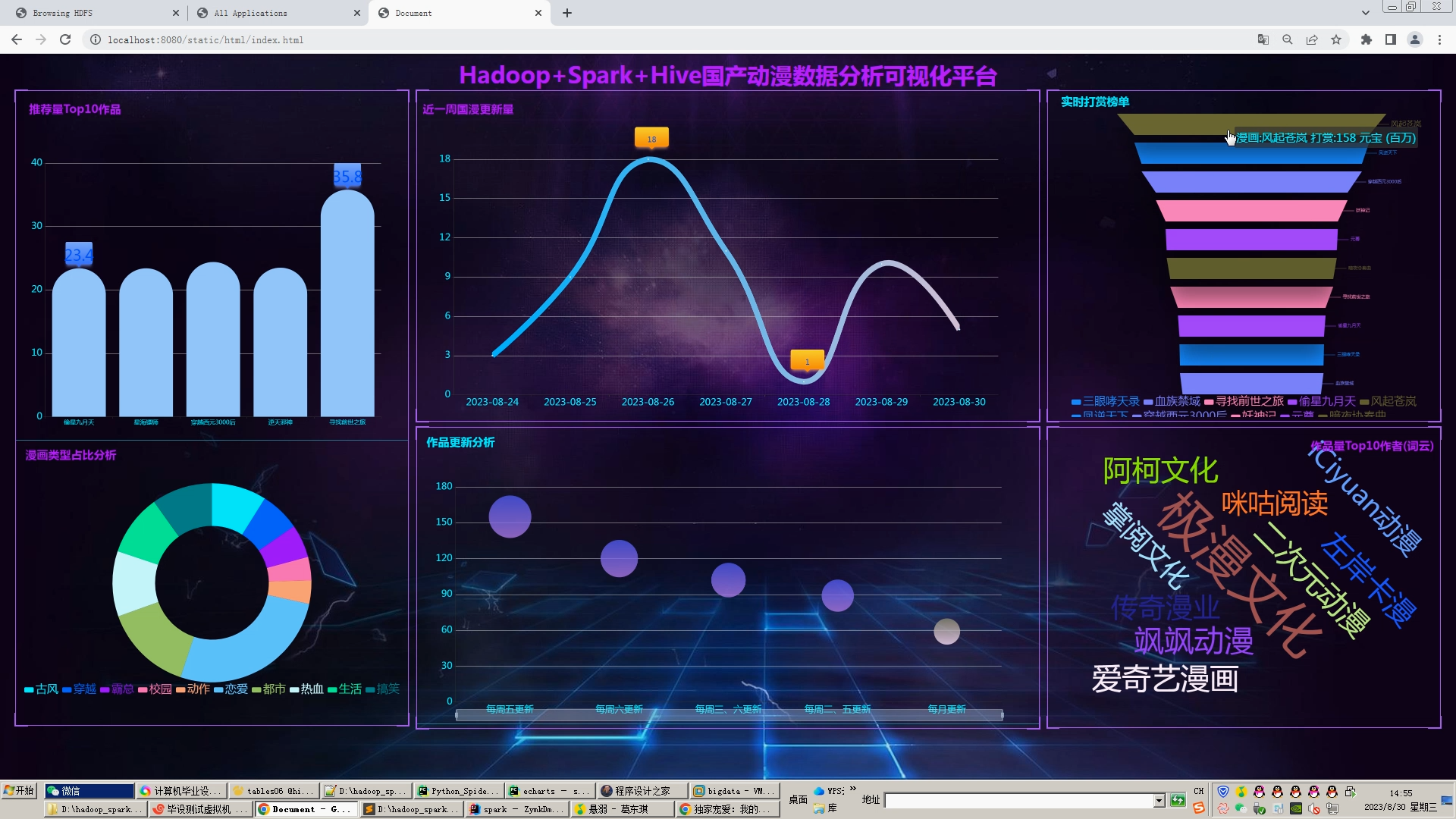
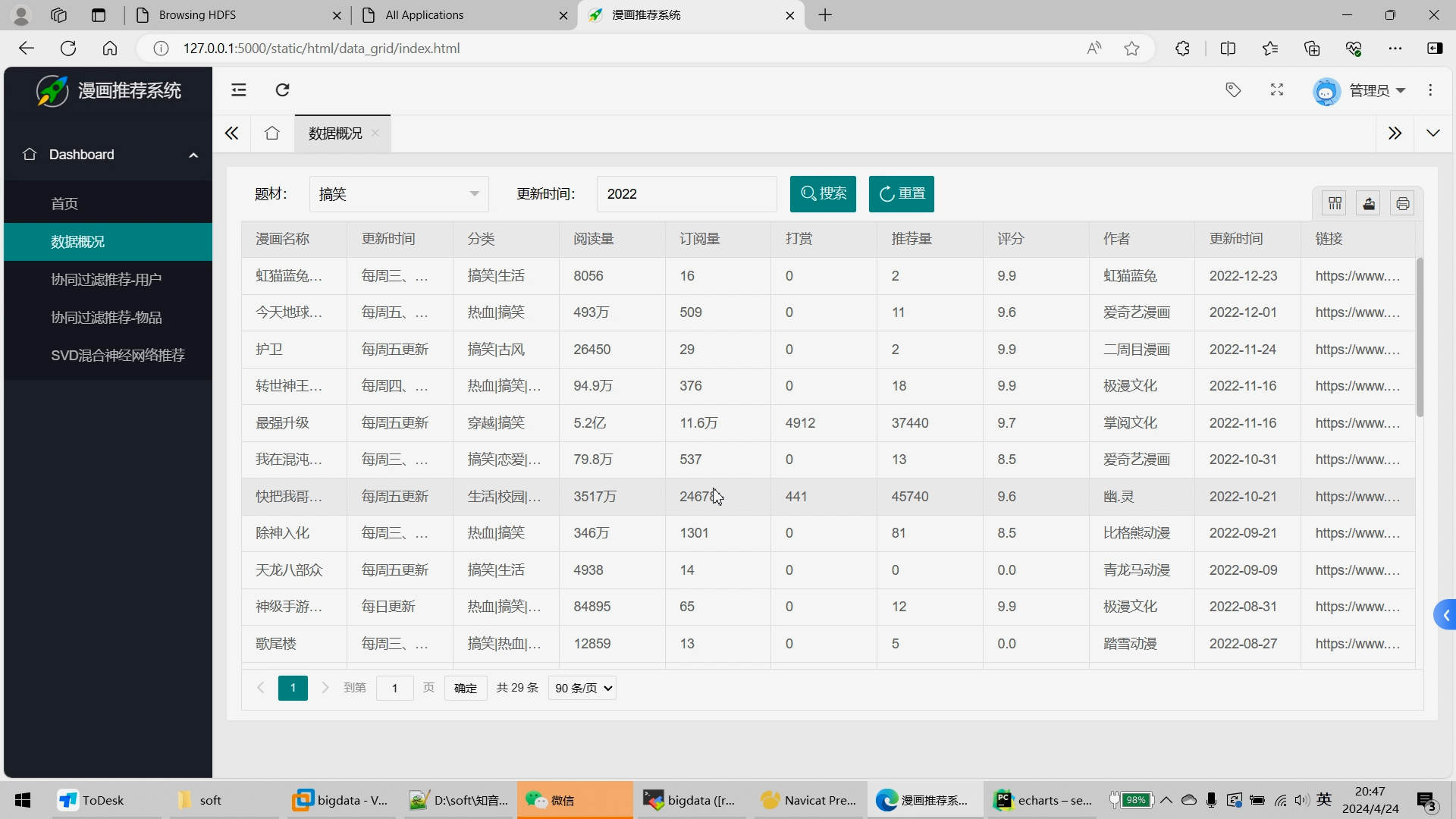
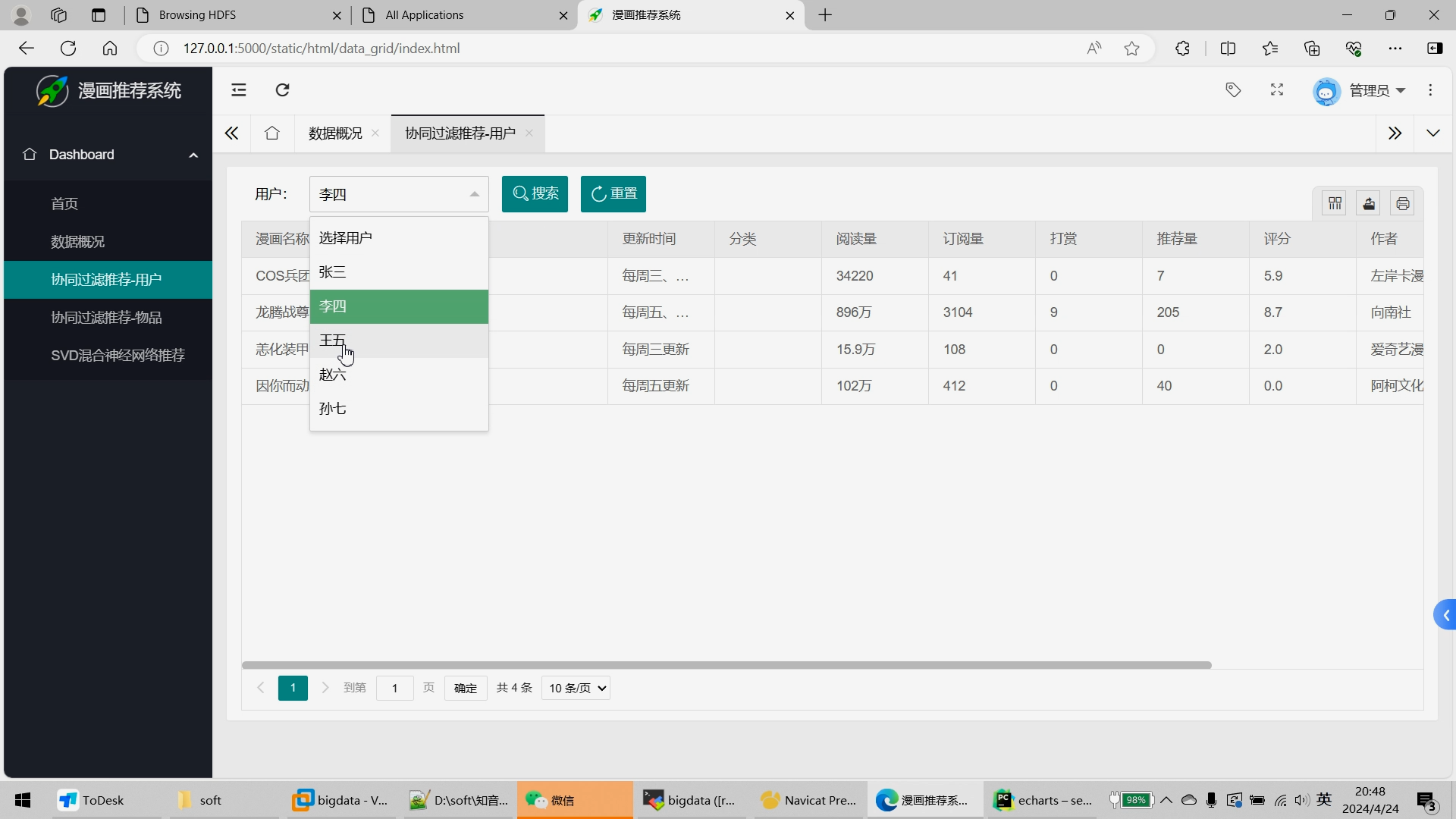
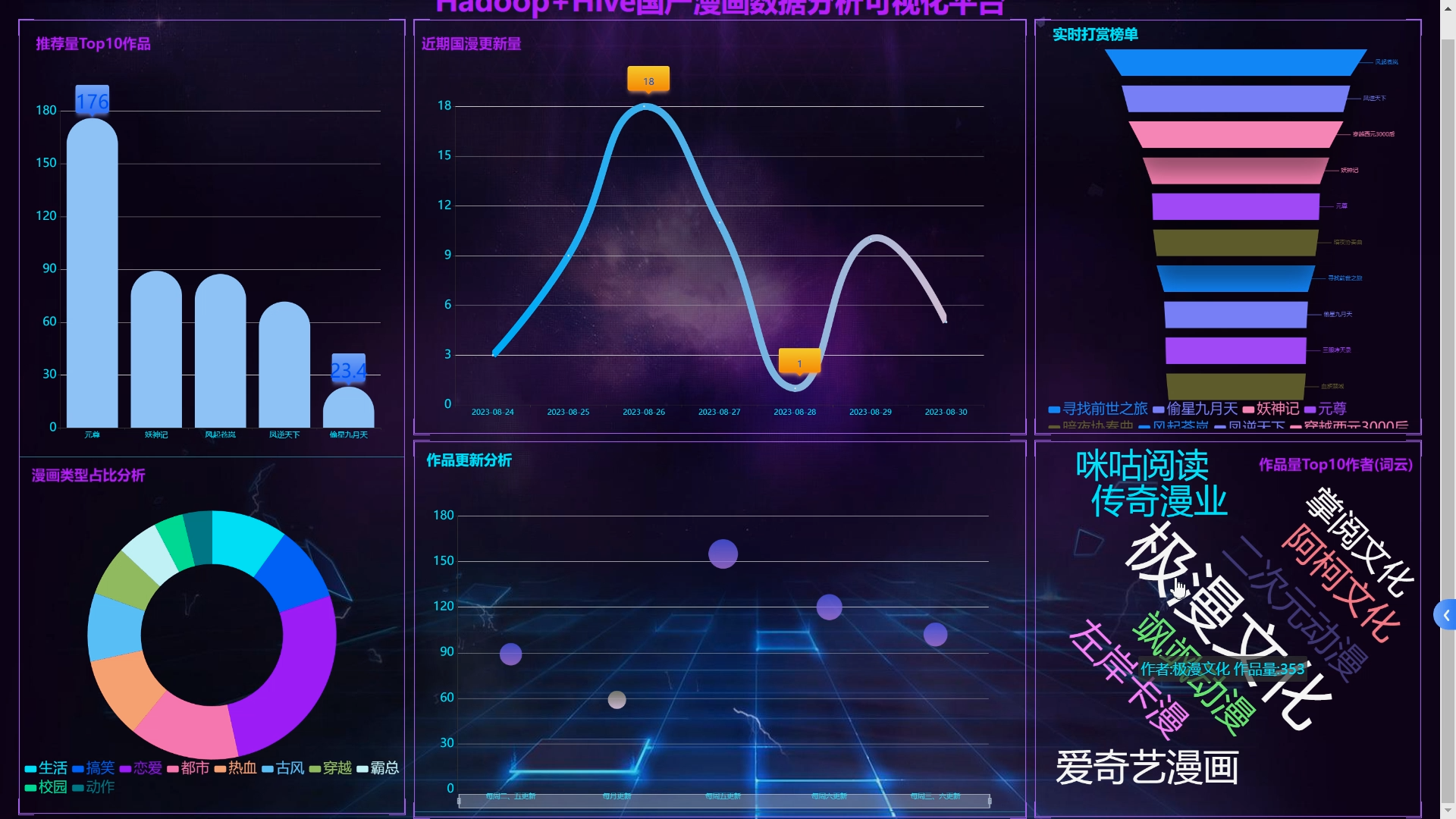
6.Flask+echarts搭建可视化大屏;
创新点:Python全新DrissionPage+Selenium双爬虫使用、海量数据、爬虫、可视化大屏、离线hive+实时Spark双实现
可选装:推荐系统、预测系统、知识图谱、后台管理等。
核心算法代码分享如下:
import csv
import pymysql
import requests
connect = pymysql.connect(host="bigdata",port=3306, user="root",
password="123456", database="hive_zymk")
cur = connect.cursor()
cur.execute("select * from tb_zymk " )
rv = cur.fetchall()
lines=0
for result in rv:
id=result[0]
title=result[1]
update_times=result[2]
tags=result[3]
content=result[4]
readings=result[5]
subscribes=result[6]
rewards=result[7]
monthtickets=result[8]
recommends=result[9]
comments=result[10]
scores=result[11]
author=result[12]
zps=result[13]
ctime=result[14]
img=result[15]
url=result[16]
#title字段去掉特殊字符
title = title.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace('\t', '')
# 内容字段去掉特殊字符
content = content.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace('\t', '')
#zps
zps = zps.strip().replace(',', ',').replace('"', '').replace("'", '').replace("\n", '').replace('\r', '').replace('\t', '')
# 阅读量替换汉字数值入亿 万
temp_readings=readings
if '亿' in readings:
temp_readings=float(readings.replace('亿',''))*100000000
elif '万' in readings:
temp_readings = float(readings.replace('万', '')) * 10000
readings = str(int(temp_readings))
#订阅量subscribes
temp_subscribes=subscribes
if '亿' in subscribes:
temp_subscribes=float(subscribes.replace('亿',''))*100000000
elif '万' in subscribes:
temp_subscribes = float(subscribes.replace('万', '')) * 10000
subscribes = str(int(temp_subscribes))
#打赏rewards
temp_rewards=rewards
if '亿' in rewards:
temp_rewards=float(rewards.replace('亿',''))*100000000
elif '万' in rewards:
temp_rewards = float(rewards.replace('万', '')) * 10000
rewards = str(int(temp_rewards))
#monthtickets月票
temp_monthtickets=monthtickets
if '亿' in monthtickets:
temp_monthtickets=float(monthtickets.replace('亿',''))*100000000
elif '万' in monthtickets:
temp_monthtickets = float(monthtickets.replace('万', '')) * 10000
monthtickets = str(int(temp_monthtickets))
#recommends 推荐数
temp_recommends=recommends
if '亿' in recommends:
temp_recommends=float(recommends.replace('亿',''))*100000000
elif '万' in recommends:
temp_recommends = float(recommends.replace('万', '')) * 10000
recommends = str(int(temp_recommends))
#ctime需要去掉空格
ctime=ctime.strip()
if update_times == None or len(update_times) == 0 or update_times == '' or update_times == 'None':
update_times = '无'
#tags标签字段拆分
# 标签
tags_arr=tags.split('|')
for tag in tags_arr:
print(tag)
zps_arr = zps.split('|')
for zp in zps_arr:
print(zp)
zymk_file = open("zymk.csv", mode="a+", newline='', encoding="utf-8")
zymk_writer = csv.writer(zymk_file)
zymk_writer.writerow(
[id,title,update_times,tag,content,readings,subscribes,rewards,monthtickets,recommends,comments,scores,author,zp,ctime,img,url])
zymk_file.close()
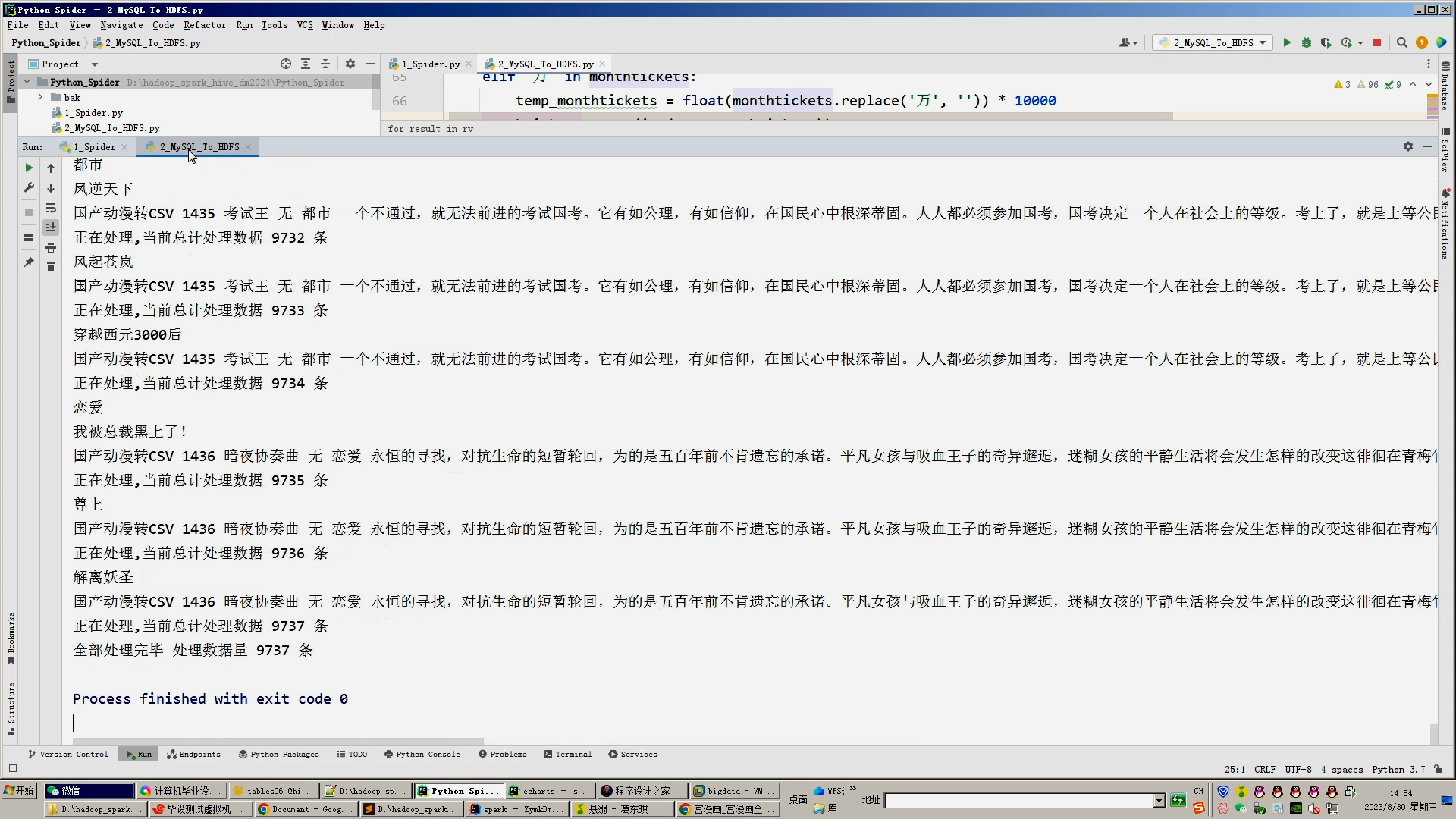
print('国产动漫转CSV',id,title,update_times,tag,content,readings,subscribes,rewards,monthtickets,recommends,comments,scores,author,zp,ctime,img,url)
lines=lines+1
print('正在处理,当前总计处理数据', lines,'条')
print('全部处理完毕','处理数据量',lines,'条')

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 6
6 0
0- 0



 已为社区贡献582条内容
已为社区贡献582条内容

所有评论(0)