2022前端笔记
tip:只记录本人记得不牢固的,或者有启发的点,新手建议多看书1、原型链实例对象的constructor也会指向构造函数因为没有constructor属性会通过原型链找(容易忽略,是个小陷阱)function Person() {}var person = new Person();console.log(person.constructor === Person); // true__proto
JS
1、原型链
实例对象的constructor也会指向构造函数
因为没有constructor属性会通过原型链找(容易忽略,是个小陷阱)
function Person() {}
var person = new Person();
console.log(person.constructor === Person); // true
__proto__
来自于 Object.prototype,更像是一个 getter/setter,使用 obj.__proto__ 时,可以理解成返回了 Object.getPrototypeOf(obj)
2、继承
原型链继承:子函数的原型是父函数的实例对象。
缺点不能传参,引用属性共享
构造函数继承:子函数中通过call调用父函数,改变this
缺点:每次都要调用父函数
组合继承缺点:调用两次父构造函数
一次是设置子类型实例的原型的时候:
Child.prototype = new Parent();
一次在创建子类型实例的时候:
var child1 = new Child('kevin', '18'); // 调用了Child中的Parent.call(this, name);
3、作用域链
新版ES2018中规定执行上下文包含了:
词法环境(这就是旧版的作用域链和this合在一起)
变量环境
…其他
[[scope]]中保存了当前函数的作用域链,这个属性无法访问,属于内部属性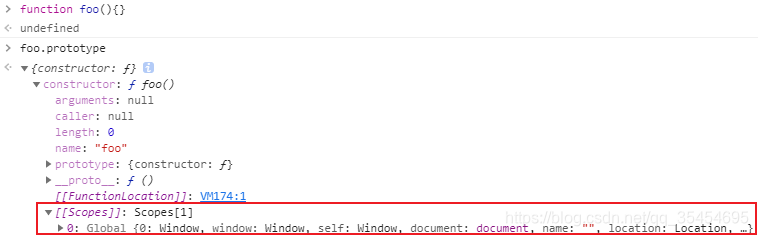
函数执行上下文中,作用域链 和 变量对象 的创建过程
简单栗子:
var scope = "global scope"
function checkscope(){
var scope2 = 'local scope'
return scope2
}
checkscope()
执行过程,伪代码:
1)函数创建,保存作用域链到 内部属性[[scope]]
checkscope.[[scope]] = [
globalContext.VO //有全局环境
]
2)执行上下文压入执行栈
ECStack = [
checkscopeContext, //压入栈
globalContext
]
3)执行上下文初始化:
上下文对象复制函数的[[scope]]属性创建作用域链
checkscopeContext = { //创建上下文
Scope: checkscope.[[scope]],
this: undefined,
}
用 arguments 创建活动对象AO,加入形参、函数声明、变量声明
checkscopeContext = {
AO: { //创建这个对象
arguments: {
length: 0
},
scope2: undefined,
},
Scope: checkscope.[[scope]],
this: undefined,
}
将活动对象压入 checkscope 作用域链顶端
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: undefined
},
Scope: [AO, [[Scope]]], // 压入栈
this: undefined,
}
4)执行函数:修改AO的属性值
checkscopeContext = {
AO: {
arguments: {
length: 0
},
scope2: 'local scope' // 修改这里
},
Scope: [AO, [[Scope]]],
this: undefined,
}
5)函数返回后,执行上下文从栈中弹出
ECStack = [
globalContext // 只剩全局上下文
];
4、闭包
MDN
闭包定义:闭能够访问自由变量的函数
自由变量:在函数中使用的,但既不是函数参数也不是函数的局部变量的变量(就是上层上下文中的变量)
定义:
1)从理论角度:所有的函数。因为创建的时候就讲上层上下文的数据保存,并可以引用
2)从实践角度:
- 即使创建它的上下文已经销毁,它仍然存在(比如,内部函数从父函数中返回)
- 在代码中引用了自由变量
var data = [];
for (var i = 0; i < 3; i++) {
data[i] = (function (i) {
return function(){
console.log(i);
}
})(i);
}
data[0]();
data[1]();
data[2]();
通过IIFE创建了函数上下文
data[0]执行函数时,作用域链多了一层
匿名函数Context = {
AO: {
arguments: {
0: 0,
length: 1
},
i: 0
}
}
data[0]Context = {
Scope: [AO, 匿名函数Context.AO globalContext.VO]
}
能找到i的值,就不会再去全局上下文找,所以值是对的
5、变量对象
在函数上下文中,我们用活动对象(activation object, AO)来表示变量对象。
在全局上下文中,全局对象就是变量对象
只有当进入一个执行上下文中,这个执行上下文的变量对象才会被激活,所以叫activation object
执行上下文的代码分成两个阶段:
1)进入执行上下文初始化
变量对象包括:
- 函数的所有形参 (如果是函数上下文)
- 函数声明,后声明的会覆盖之前的
- 变量声明,不会干扰已存在的同名形参或者函数名
简单栗子
AO = {
arguments: {
0: 1,
length: 1
},
a: 1,
b: undefined,
c: reference to function c(){},
}
2)执行代码
根据代码修改AO中的值
6、this
ECMAScript的类型分为两种:语言类型、规范类型
语言类型 就是7种基本类型:string,number,bigint,boolean,null,undefined,symbol 和一种引用类型:obj
规范类型 用来用算法描述 ECMAScript 语言结构和 ECMAScript 语言类型,用来描述语言底层行为逻辑。包括:Reference, List, Completion, Property Descriptor, Property Identifier, Lexical Environment, 和 Environment Record。
Reference
定义: 用来解释诸如 delete、typeof 以及赋值等操作行为
三部分组成:
- base value (属性所在的对象或者是EnvironmentRecord,值只可能是 undefined, an Object, a Boolean, a String, a Number, or an environment record 其中的一种)
- referenced name (属性名称)
- strict reference (是否是严格引用)
Reference 组成部分的方法,比如 GetBase 和 IsPropertyReference。
两个组成部分的方法
1.GetBase
返回 reference 的 base value
2.IsPropertyReference
简单的理解:如果 base value 是一个对象,就返回true。
GetValue:用于从 Reference 类型获取对应值的方法
调用 GetValue,返回的将是具体的值,而不再是一个 Reference
如何确定this的值
步骤:
1.计算 MemberExpression 的结果赋值给 ref
2.判断 ref 是不是一个 Reference 类型
2.1 如果 ref 是 Reference,并且 IsPropertyReference(ref) 是 true, 那么 this 的值为 GetBase(ref)
2.2 如果 ref 是 Reference,并且 base value 值是 Environment Record, 那么this的值为 ImplicitThisValue(ref)
ImplicitThisValue 该方法始终返回 undefined
2.3 如果 ref 不是 Reference,那么 this 的值为 undefined
什么是 MemberExpression ?
- PrimaryExpression // 原始表达式 可以参见《JavaScript权威指南第四章》
- FunctionExpressio // 函数定义表达式
- MemberExpression [ Expression ] // 属性访问表达式
- MemberExpression . IdentifierName // 属性访问表达式
- new MemberExpression Arguments // 对象创建表达式
说白了就是比如 foo.bar()、foo[0]、foo.obj 这些运算中,括号、点运算符、中括号运算符之前的表达式要先进行计算,为 null 或者其他不能用的情况就会报错。
几种调用情况下的this
var value = 1;
var foo = {
value: 2,
bar: function () {
return this.value;
}
}
foo.bar()
1、计算 MemberExpression 的结果 赋值给 ref 如下:
var ref = {
base: foo,
name: 'bar',
strict: false
};
2、IsPropertyReference(ref) 由于 ref.base 是 foo,所以返回 true
3、执行 GetBase(ref) 返回 foo, 赋值给 this
------------------------------------------------
(foo.bar)()
1、括号没有对 foo.bar 做任何计算,所以结果同上
------------------------------------------------
(foo.bar = foo.bar)()
1、赋值计算调用了 GetValue, 返回的不再是 Reference 类型, this 为 undefined
------------------------------------------------
(false || foo.bar)()
同上,调用了 GetValue
------------------------------------------------
(foo.bar, foo.bar)()
同上,调用了 GetValue
------------------------------------------------
foo()
1、计算 MemberExpression 的结果 赋值给 ref 如下:
var ref = {
base: EnvironmentRecord,
name: 'foo',
strict: false
};
2、base value 是 EnvironmentRecord, this 的值为 ImplicitThisValue(ref), 返回 undefined
上述情况是从规范的角度去理解 this,大部分人是从调用的角度去理解,但是这个角度会无法去理解为何 (false || foo.bar)() 这种情况的 this 值
7、立即执行函数表达式(IIFE)
先看一组比较:
function foo(){}() 报错,js解析器会当成函数声明
var foo = function(){console.log(1)}() 可以执行
function foo(){}(1) 不会报错,等同于下面的代码
function foo(){}
(1)
在 js 里圆括号中不能包含声明,所以一般使用此方法将函数声明变成表达式
用类似 JQ 的返回对象来做私有变量会更好点,也是早期的模块化
8、instanceof 和 typeof 的实现原理
js 如何存储数据类型信息
js 在底层存储变量的时候,会在变量的机器码的低位1-3位存储其类型信息
- 000:对象
- 010:浮点数
- 100:字符串
- 110:布尔
- 1:整数
两个特殊值:null:所有机器码均为0undefined:用 −2^30 整数来表示
所以 typeof 判断 null 为对象,机器码低位相同
instanceof 原理:右边变量的 prototype 在左边变量的原型链上
function new_instance_of(leftVaule, rightVaule) {
let rightProto = rightVaule.prototype // 取右表达式的 prototype 值
leftVaule = leftVaule.__proto__ // 取左表达式的__proto__值
while (true) {
if (leftVaule === null) {
return false;
}
if (leftVaule === rightProto) {
return true;
}
leftVaule = leftVaule.__proto__
}
}
9、bind
特点:
1)返回函数
2)传参2次:调用bind的时候可以传参,返回的新函数调用时也可以传参 3)绑定之后返回的新函数,作为构造函数时,绑定的this应该失效
具体实现
Function.prototype.bind2 = function (context) {
let self = this;
let args = [...arguments].slice(1) // 拿到第一次调用时,除了上下文之外的其他参数
let fBound = function () {
var bindArgs = Array.prototype.slice.call(arguments); // 获取第二次调用的参数
// 第三个特点,如果是构造函数调用,绑定这个构造函数的实例为 this, 否则是我们传的上下文
return self.apply(this instanceof fNOP ? this : context, args.concat(bindArgs));
}
// 将被绑定函数的原型 放到 返回函数的原型链上,
// 通过空函数中转,防止修改一个影响另一个
let fNOP = function () {}
fNOP.prototype = this.prototype
fBound.prototype = new fNOP()
return fBound; // 第一个特点,返回函数
}
10、call 和 apply
第一个参数指定为 null 或 undefined 时会自动替换为指向全局对象
call 的实现
Function.prototype.call = function (thisArg) {
// 先判断当前的甲方是不是一个函数(this就是Product,判断Product是不是一个函数)
if (typeof this !== 'function') {
throw new TypeError('当前调用call方法的不是函数!')
}
// 保存甲方给的参数
const args = [...arguments].slice(1)
// 传入的是 null 或者 undefined
thisArg = thisArg || window
// 将调用call的函数保存为乙方的一个属性,为了保证不与乙方中的key键名重复使用Symbol
const fn = Symbol('fn')
thisArg[fn] = this
// 执行保存的函数,这个时候作用域就是在乙方的对象的作用域下执行,改变的this的指向
const result = thisArg[fn](...args)
// 执行完删除刚才新增的属性值
delete thisArg[fn]
// 返回执行结果
return result
}
apply 的实现
Function.prototype.appy= function (thisArg) {
if (typeof this !== 'function') {
throw new TypeError('当前调用apply方法的不是函数!')
}
// 此处与call有区别,因为只有2个参数,其他一样
const args = arguments[1]
thisArg = thisArg || window
const fn = Symbol('fn')
thisArg[fn] = this
const result = thisArg[fn](...args)
delete thisArg[fn]
return result
}
11、柯里化
Function.length 表示形参的个数,不包括剩余参数个数,同时只计算第一个有默认值之前的参数
柯里化(Curry):一个函数接收一个多参函数,并且返回多个嵌套的只接受一个参数的函数
简单栗子:
fn(1)(2)(3)
偏函数应用(Partial Application):每个嵌套的函数可以接受不止一个参数
简单栗子:
fn(1,2)(3)
实现(不考虑占位符)
占位符根据多种不同情况用 if-else 处理,用一个数组保存占位符在总的参数列表中的位置,然后替换
function curry(targetFn) {
return function curried(...args) {
// 如果参数个数 达到 目标函数所需的参数,执行目标函数
if (args.length >= targetFn.length) {
return targetFn.apply(this, args)
} else {
// 否则递归柯里化函数:将上次递归抛出的函数获得的参数 args2,和以前累计的参数 args 传递给柯里化函数
return function(...args2) {
return curried.apply(this, [...args, ...args2])
}
}
}
}
12、垃圾回收
v8引擎的内存限制
V8引擎在64位系统下最多只能使用约1.4GB的内存,在32位系统下最多只能使用约0.7GB的内存。
原因:
1)浏览器端很少需要操作太多内存资源的场景
2)JS 单线程机制
没有复杂的多线程执行场景,对程序内存要求低
3)垃圾回收机制
垃圾回收耗时久。假设V8的堆内存为1.5G,那么V8做一次小的垃圾回收需要50ms以上,而做一次非增量式回收甚至需要1s以上。内存使用过高,必然垃圾回收时间变长,主线程等待时间也变长。
node 中可以手动设置内存最大与最小值
设置新生代内存中单个半空间的内存最小值,单位MB
node --min-semi-space-size=1024 xxx.js
设置新生代内存中单个半空间的内存最大值,单位MB
node --max-semi-space-size=1024 xxx.js
设置老生代内存最大值,单位MB
node --max-old-space-size=2048 xxx.js
查看当前node进程所占用的实际内存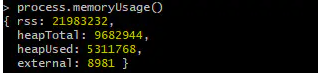
heapTotal:V8 当前申请到的堆内存总大小。
heapUsed:当前内存使用量。
external:V8 内部的 C++ 对象所占用的内存。
rss(resident set size):表示驻留集大小,是给这个node进程分配了多少物理内存,这些物理内存中包含堆,栈和代码片段。
对象,闭包等存于堆内存,变量存于栈内存,实际的JavaScript源代码存于代码段内存
使用 Worker 线程时,rss 也包括 Worker 线程的值,但其他的值只针对当前线程
垃圾回收策略
总结:基于分代式垃圾回收机制,根据对象的存活时间将内存进行不同的分代,然后采用不同的垃圾回收算法
V8的内存结构
分为几个部分:
新生代(new_space):大多数的对象开始都会被分配在这里,这个区域相对较小但是垃圾回收特别频繁。该区域被分为两半,一半用来分配内存,另一半用于在垃圾回收时将需要保留的对象复制过来。老生代(old_space):新生代中的对象在存活一段时间后就会被转移到老生代内存区,垃圾回收频率较低。老生代又分为老生代指针区和老生代数据区,前者包含大多数可能存在指向其他对象的指针的对象,后者只保存原始数据对象,这些对象没有指向其他对象的指针。大对象区(large_object_space):存放体积超越其他区域大小的对象,每个对象都会有自己的内存,垃圾回收不会移动大对象区。代码区(code_space):代码对象,会被分配在这里,唯一拥有执行权限的内存区域。map区(map_space):存放Cell和Map,每个区域都是存放相同大小的元素,结构简单
新生代
构成:两个 semispace (半空间)
使用算法:Scavenge算法,牺牲空间换时间。老生代内存生命周期长,可能会存储大量对象,不适用这种算法
具体实现使用了 Cheney 算法。
1、激活状态的区域叫做 From 空间,垃圾回收时把 From 空间中不能回收的对象复制到 To 空间
2、清除 From 中所有的非存活对象,两个空间呼唤身份
缺点:浪费空间,一半的内存用于复制
反思:为什么不标记完直接清除,而使用 Scavenge ,应该也是为了整理内存碎片
对象晋升
两个条件满足其一:
- 对象是否经历过一次Scavenge算法
- To空间的内存占比是否已经超过25%(防止变成 From 空间后,后续对象内存分配时内存过高溢出)
老生代
使用算法:Mark-Sweep (标记清除) 和 Mark-Compact (标记整理)
总步骤:标记、整理、清除
1)Mark-Sweep (标记清除)
详细步骤:
- 垃圾回收器在内部构建一个根列表, 保存所有的根节点
- 从所有根节点出发,遍历其可以访问到的子节点,标记为活动的
- 释放所有非活动的内存块
根节点类型
- 全局对象
- 本地函数的局部变量和参数
- 当前嵌套调用链上的其他函数的变量和参数
问题
一次标记清除后,内存空间可能会出现不连续的状态-----内存碎片
后面如果需要分配一个大对象而空闲内存不足以分配,就会提前触发垃圾回收,所以需要 标记整理
2)Mark-Compact (标记整理)
详细步骤:
- 将所有活动对象往堆内存的一端移动
3)性能提升
全停顿:由于 JS 是单线程的,垃圾回收的过程会阻塞主线程同步任务
增量标记:标记、交给主线程、回到标记暂停的地方继续标记
如果在老生代中,对堆内存中所有的存活对象遍历,势必会造成性能问题。
于是 V8 引擎先标记内存中的一部分对象,然后暂停,将执行权重新交给 JS 主线程,待主线程任务执行完毕后再从原来暂停标记的地方继续标记,直到标记完整个堆内存。
挺像使用 setTimeout 优化技巧,也是把一个大的任务拆成很多个小任务,这样就可以间断性的渲染 UI,不会有卡顿的感觉
基于增量标记, V8 引擎后续继续引入了延迟清理(lazy sweeping)和增量式整理(incremental compaction)、并行标记、并行清理
如何避免内存泄漏
避免使用全局变量:因为 window 对象可以作为根节点,上面的属性都是常驻的
手动清除定时器
少用闭包
清除DOM引用:对保存在属性中的 dom 引用及时释放成 null
使用弱引用:WeakMap 和 WeakSet 中的引用都是弱引用,只要对象没有其他的引用,这个对象中所有属性的内存都会被释放掉
13、浮点数精度
数字类型
Number 类型使用 IEEE 二进制浮点数算术标准 中的 双精度64位表示法,也就是64位字节存储一个浮点数
浮点数转二进制
浮点数 (Value) 可以这样表示
Value = sign * exponent * fraction
1)1 位存储 S,0 表示正数,1 表示负数。
2)11 位存储 E(阶码) + bias,对于 11 位来说,bias 的值是 2^(11-1) - 1,也就是 1023。
最大值是1024,因为E可能为1,所以bias的值是固定的1023,存储的时候通过存储的二进制值减去1023反推得到E的值。
3)52 位存储 Fraction。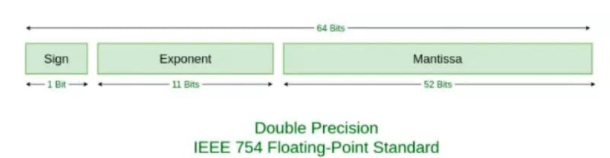
0.1 对应的二进制
Sign 是 0,E + bias 是 -4 + 1023 = 1019,1019 用二进制表示是 1111111011,Fraction是1001100110011…(下方位1.不用存,是固定的)
1 * 1.1001100110011…… * 2^-4
64字节位表示0 01111111011 1001100110011001100110011001100110011001100110011010
0.2 对应的 64 字节0 01111111100 1001100110011001100110011001100110011001100110011010
浮点数的运算
例如:0.1 + 0.2
1)对阶
把阶码调整为相同
0.1 是 1.1001100110011…… * 2^-4,阶码是 -4
0.2 是 1.10011001100110…* 2^-3,阶码是 -3
小阶对大阶:0.1 的 -4 调整为 -3, 数字会变大,所以前面的应该变小,也就是右移,符号位补0
2)尾数运算
0.1100110011001100110011001100110011001100110011001101
+ 1.1001100110011001100110011001100110011001100110011010
———————————————————————————————————————————————————
10.0110011001100110011001100110011001100110011001100111
结果:10.0110011001100110011001100110011001100110011001100111 * 2^-3
3)规格化
移一位:1.0011001100110011001100110011001100110011001100110011(1) * 2^-2
4)舍入处理(0 舍 1 入)
括号里的1是多出来的,会舍弃,并进1
5)溢出判断(这里没有)
6)结果
0 01111111101 0011001100110011001100110011001100110011001100110100
十进制就是 0.30000000000000004440892098500626
由于两次存储时的精度丢失,再加上运算时的精度丢失,导致了这个结果
扩展:为什么(2.55).toFixed(1)等于2.5?
简单总结:2.55的存储要比实际存储小一点,导致0.05的第1位尾数不是1,所以就被舍掉了
14、new
特点:
1)返回的对象,可以访问传入的构造函数里的属性
2)返回的对象,可以访问传入的构造函数 原型 里的属性
3)判断构造函数是否有返回值,如果是对象就返回对象,不是的话就返回我们创建的
实现(使用一个函数模拟)
function objectFactory() {
var obj = new Object(),
Constructor = [].shift.call(arguments); // 拿到传入的构造函数
obj.__proto__ = Constructor.prototype; // 创造的实例对象 连接 构造函数的prototype
var ret = Constructor.apply(obj, arguments); // 应用剩余的传入参数,this 改为创造的实例对象
return typeof ret === 'object' ? ret : obj; // 判断返回值
};
15、事件循环
特点:
当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。
同一次事件循环中,微任务永远在宏任务之前执行。、
node环境
node 选择 chrome v8 引擎作为js解释器,v8 引擎将 js 代码分析后去调用对应的 node api,而这些 api 最后则由 libuv 引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。
实际上node中的事件循环存在于libuv引擎中
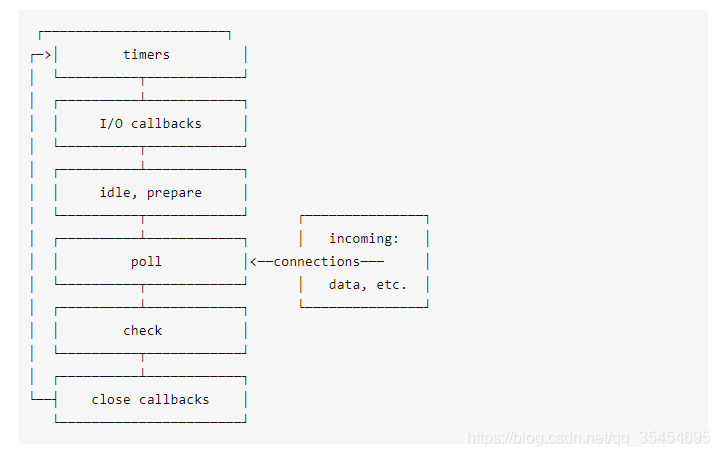
poll 阶段
1)先查看 poll queue 中是否有事件
2)当 poll queue 为空时,检查是否有 setImmediate() 的 callback,进入 check 阶段
3)同时检查是否有到期的 timer,按照调用顺序放到timer queue中,进入 timer 阶段
4)2、3步顺序不一定,看具体的代码环境。
5)如果两者的 queue 都是空的,那么loop会在poll阶段停留,直到有一个i/o事件返回,循环会进入 i/o callback 阶段并立即执行这个事件的 callback
check 阶段 和 timer 阶段
check 阶段专门用来执行 setImmediate() 方法的回调,当 poll 阶段进入空闲状态进入
timer 阶段执行 setTimeout 或者 setInterval 函数的回调
I/O callback阶段
执行大部分I/O事件的回调,包括一些为操作系统执行的回调。
例如一个TCP连接生错误时,系统需要执行回调来获得这个错误的报告。
close阶段
当一个 socket 连接或者一个 handle 被突然关闭时(例如调用了 socket.destroy() 方法),close 事件会被发送到这个阶段执行回调。否则事件会用 process.nextTick()方法发送出去。
process.nextTick
node中存在着一个特殊的队列,即nextTick queue
当事件循环准备进入下一个阶段之前,会先检查nextTick queue中是否有任务,如果有,那么会先清空这个队列,且不会停止,所以可能造成内存泄漏。
setTimeout 与 setImmediate 的区别与使用场景
在在定时器回调或者 I/O 事件的回调中,setImmediate 方法的回调永远在 timer 的回调前执行。
其他场景取决于当时机器情况
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
immediate
timeout
16、Promise
17、Generator
for of 可以自动遍历迭代器的值
简易状态机(不用设初始变量,不用切换状态,更简洁,更安全)
let clock = function*() {
while (true) {
console.log('Tick!');
yield;
console.log('Tock!');
yield;
}
};
CSS 部分
1、盒模型
默认情况下,块级元素的内容宽度是其父元素的宽度的100%,并且与其内容一样高。
内联元素高宽与他们的内容高宽一样
标准模型和IE模型的区别
IE模型元素宽度 width = content + padding + border,高度计算相同
标准模型元素宽度 width = content,高度计算相同
js 如何 设置 获取 盒模型对应的宽和高
- dom.style.width/height 只能取到行内样式的宽和高,style 标签中和 link 外链的样式取不到。
- window.getComputedStyle(dom).width/height 取到的是最终渲染后的宽和高, 多浏览器支持,IE9以上支持。
- dom.getBoundingClientRect().width/height 也是得到渲染后的宽和高,大多浏览器支持。IE9以上支持,除此外还可以取到相对于视窗的上下左右的距离
2、BFC
定义
决定了元素如何对其内容进行定位,以及与其他元素的关系和相互作用。提供了一个环境,一个环境中的元素不会影响到其他环境中的布局。
原理(渲染规则)
- BFC 元素垂直方向的边距会发生重叠。属于不同 BFC 外边距不会发生重叠
- BFC 的区域不会与浮动元素的布局重叠。
- BFC 元素是一个独立的容器,外面的元素不会影响里面的元素。里面的元素也不会影响外面的元素。
- 计算 BFC 高度的时候,浮动元素也会参与计算(清除浮动)
创建BFC
- html 根元素
- overflow不为visible
- float的值不为none
- position的值不为static或relative
- display属性为inline-blocks,table,table-cell,table-caption,flex,inline-flex
场景:防止 margin 合并、给普通盒子加上可以清除浮动,父元素加上 BFC 可以包含浮动子元素高度等
3、选择器
类别:
- 简单选择器: id 、class
- 属性选择器:通用语法由方括号([]) 组成,其中包含属性名称。[attr]、[attr=val]、[attr~=val](attr中包含val的元素,a[class~=“logo”],包含 logo 类名的 a),[attr^=val],[attr$=val],[attr*=val](包含 val 的元素)
- 伪类(Pseudo-classes):hover、active
- 伪元素(Pseudo-elements): ::after
- 组合器(Combinators):+ - > ~ (+ ~ 选择兄弟元素只会向后选择,不会选择前面的兄弟,+是相邻的兄弟)
- 多用选择器
4、Position
确定包含块:
完全依赖于这个元素的 position 属性
- position 属性为 static 、 relative 或 sticky:最近的祖先块元素(inline-block, block 或 list-item)的内容区的边缘组成
- position 属性为 absolute:最近的 position 的值不是 static 的祖先元素的内边距区的边缘
- position 属性是 fixed:连续媒体的情况下包含块是 viewport(视口),分页媒体是分页区域
- absolute 或 fixed:也可能是满足以下条件的最近父级元素的内边距
1)transform 或 perspective 的值不是 none
2)will-change 的值是 transform 或 perspective
3)filter 的值不是 none 或 will-change 的值是 filter(只在 Firefox 下生效).
4)contain 的值是 paint (例如: contain: paint;)
包含块计算百分值
1、计算 height 、top 及 bottom 中的百分值,是通过包含块的 height 的值。如果包含块的 height 值会根据它的内容变化,而且包含块的 position 属性的值被赋予 relative 或 static ,那么,这些值的计算值为 auto。
2、要计算 width, left, right, padding, margin 这些属性由包含块的 width 属性的值来计算它的百分值。
定位上下文
绝对定位的元素的相对位置元素
stickey
设置了 top 值,当这个元素距离顶部 30px 时,会变成 fixed 定位粘在顶部
.positioned {
position: sticky;
top: 30px;
left: 30px;
}
5、Flex
默认情况下,flex 容器中有一些设置:
元素不会在主维度方向拉伸,但是可以缩小。
元素被拉伸来填充交叉轴大小。
flex-basis 属性为 auto。
flex-wrap 属性为 nowrap。
注意交叉轴的拉伸,如果一些元素比其他元素高的话,会拉伸矮的元素
flex-flow
是 flex-direction 和 flex-wrap 的简写属性
flex 的一些简写含义
flex: initial === flex: 0 1 auto (把 flex 元素重置为 Flexbox 的初始值)
flex: auto === flex: 1 1 auto (自由伸缩)
flex: none === flex: 0 0 auto (无法伸缩)
flex: 2 === flex: 2 1 0% 单值语法只改变 grow
flex-basis
默认设置为 auto:先检测是否设置了绝对值,没有设置的话就使用 flex 子元素的 max-content 大小作为 flex-basis,不会超过元素最大宽度
如果要让三个不同尺寸的flex子元素,在剩余空间分配后保持同一宽度,应使用 flex: 1 1 0,尺寸计算值是 0 表示所有的空间都用来争夺
flex-shrink
数值越大收缩的越快,并且最小不会小于内容的 min-content(也就是能把内容显示出来)
6、样式优先级
从0开始,一个行内样式+1000,一个id选择器+100,一个属性选择器、class或者伪类+10,
一个元素选择器,或者伪元素+1,通配符+0
!important > 行内样式 > 内联样式 and 外联样式
样式指向同一元素,权重规则生效,权重大的被应用
样式指向同一元素,权重规则生效,权重相同时,就近原则生效,后面定义的被应用
样式不指向同一元素时,权重规则失效,就近原则生效,离目标元素最近的样式被应用
7、圣杯/双飞翼
相同点:中间栏要在放在文档流前面优先渲染。前一半是相同的,也就是三栏全部 float 浮动,左右两栏加上负 margin 让其跟中间栏 div 并排,以形成三栏布局。
不同点:解决”中间栏div内容不被遮挡“问题的思路不一样,圣杯使用相对定位配合 right和 left 属性,双飞翼通过 middle 的子元素使用 margin 为左右两栏留出位置
圣杯
- 4个元素:container、middle、left、right
- 父元素设置 overflow: hidden; 形成 BFC, 同时左右 padding 设置成左右子元素宽度
- 子元素全部 float:left;
- left、right 设置各自的宽度,同时 position: relative; left: -leftWidth, right 设置 right: -rightWidth;
- middle设置width: 100%;
双飞翼
- 5个元素:container、middle、middle 的儿子 inner、left、right
- 父元素设置overflow: hidden; 形成BFC, 同时左右 padding 设置成左右子元素宽度
- 子元素全部 float:left;
- left、right 设置各自的宽度
- middle 设置width: 100%;
- inner 设置左右边距为左右栏宽度,为左右栏腾出宽度
注意:左栏 margin-left: -100% 以包含块内容区左侧(当然以相邻元素右侧 margin 为基准也可以,一个道理)为基准线,负值表示向基准线移动靠近。
同时给 left、middle、right设置上 padding-bottom: 9999px; margin-bottom: -9999px; 可以形成三列保持等高(利用背景会显示在 padding 区域,视觉上欺骗,只能用与纯色背景)
8、margin 负值原理
- left 负值就是以包含块(Containing Block)内容区域的左边 或 该元素左侧相连元素 margin 的右边为参考线
- top 负值就是以包含块(Containing Block)内容区域的上边 或 该元素上方相连元素 margin 的下边为参考线
- right 负值是以元素自身的 border-right 为参考线
- bottom 负值是以元素自身的 border-bottom 为参考线
多列等高布局原理就是通过 padding 撑开盒子,同时相同的 负margin 告诉浏览器计算文档流布局时减去对应的值,让下方的元素上来占据位置。同时父元素 overflow:hidden 形成 BFC 并且遮挡超出部分,以最高元素为准。
还可以给 ul 加上负 margin以消除每行最后一项的正margin
9、CSS3新特性
过渡
transition: CSS属性,花费时间,效果曲线(默认ease),延迟时间(默认0)
transition:width,.5s,ease,.2s
可以使用 scale(0)~scale(1) 制作下拉列表展开效果
动画
animation:动画名称,一个周期花费时间,运动曲线(默认ease),动画延迟(默认0),
播放次数(默认1),是否反向播放动画(默认normal),是否暂停动画(默认running)
animation-fill-mode : none | forwards | backwards | both;
none:不改变默认行为。
forwards :当动画完成后,保持最后一个关键帧。
backwards:在动画显示之前,应用第一个关键帧。
both:向前和向后填充模式都被应用
选择器
p:nth-child(2): 表示选中 父元素的第二个子元素并且是p标签
p:nth-of-type(2): 表示选中 父元素的第二个是p标签的元素
背景
background-clip: border-box、padding-box、content-box (背景全部绘制,只显示某些部分)
background-origin:属性同上(背景从哪里开始绘制)
background-size
文字
word-break:
normal 浏览器默认规则
break-all 允许单词内换行(随意换)
keep-all; 半角空格或连字符处换行
word-wrap:
normal:默认
break-word: 实在没有好的换行点就换行
省略号
单行:禁止换行,超出隐藏,超出省略号
overflow:hidden;
white-space:nowrap;
text-overflow:ellipsis;
多行:
兼容性不太好
overflow:hidden;
text-overflow:ellipsis;
display:-webkit-box;
-webkit-line-clamp:2; (两行文字)
-webkit-box-orient:vertical;
伪元素方案:兼容性还可以
p{
position:relative;
line-height:1.4em;
/*设置容器高度为3倍行高就是显示3行*/
height:4.2em;
overflow:hidden;
}
p::after{
content:'...';
font-weight:bold;
position:absolute;
bottom:0;
right:0;
padding:0 20px 1px 45px;
background:#fff;
}
10、CSS模块化
手写时代
行内样式缺点
- 样式不能复用。
- 样式权重太高,样式不好覆盖。
- 表现层与结构层没有分离。
- 不能进行缓存,影响加载效率。
导入样式缺点
- 导入样式,只能放在 style 标签的第一行,放其他行则会无效。
- @import 声明的样式表不能充分利用浏览器并发请求资源的行为,其加载行为往往会延后触发或被其他资源加载挂起。
- 由于 @import 样式表的延后加载,可能会导致页面样式闪烁。
所以一般我们只用内嵌样式和外部样式
预处理器时代 Sass/Less
打包出来的结果和源生的 css 都是一样的,只是对开发者友好,写起来更顺滑
平台 PostCSS
提供各种插件构建复杂功能
使用场景:
- 配合 stylelint 校验 css 语法
- 自动增加浏览器前缀 autoprefixer
- 编译 css next 的语法
CSS Modules
打包的时候会自动将类名转换成 hash 值,CSS Modules 不能直接使用,而是需要进行打包。
webpack 中进行配置
// webpack.config.js
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use:{
loader: 'css-loader',
options: {
modules: {
// 自定义 hash 名称
localIdentName: '[path][name]__[local]--[hash:base64:5]',
}
}
}
]
}
};
CSS In JS
最出名的是 styled-components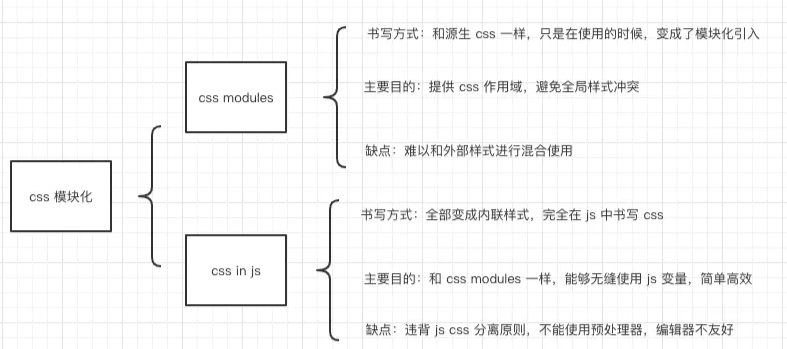
11、CSS 性能优化
- 合并 css 文件,如果页面加载10个css文件,每个文件1k,那么也要比只加载一个100k的css文件慢。
- 减少 css 嵌套,最好不要嵌套三层以上。
- 不要在 ID 选择器前面进行嵌套,ID本来就是唯一的而且权限值大,嵌套完全是浪费性能。
- 建立公共样式类,把相同样式提取出来作为公共类使用。
- 减少通配符 * 或者类似 [hidden=“true”] 这类选择器的使用,挨个查找所有…这性能能好吗?
- 巧妙运用css的继承机制,如果父节点定义了,子节点就无需定义。
- 拆分出公共 css 文件这样一次下载后就放到缓存里,当然这种做法会增加请求,具体做法应以实际情况而定。
- 不用 css 表达式,对性能的浪费可能是超乎你想象的。
- 少用 css rest,可能会觉得重置样式是规范,但是其实其中有很多操作是不必要不友好的,有需求有兴趣,可以选择 normolize.css。
- cssSprite,减少了 http 请求。
- 善后工作,css压缩(在线压缩工具 YUI Compressor)
- GZIP压缩
避免使用@import
- 影响浏览器的并行下载
- 多个@import会导致下载顺序紊乱
避免过分重排 与 重绘
- 一个节点触发来reflow,会导致他的子节点和祖先节点重新渲染
- 常见重排元素
- 大小有关的 width,height,padding,margin,border-width,border,min-height
- 布局有关的 display,top,position,float,left,right,bottom
- 字体有关的 font-size,text-align,font-weight,font-family,line-height,white-space,vertical-align
- 隐藏有关的 overflow,overflow-x,overflow-y
- 建议
- 不要一条条的修改 dom 样式,每一次设置都会触发一次reflow,预先定义好 class,然后修改 dom 的 classname
- 不要修改影响范围较大的 dom
- 动画元素使用绝对定位
- 不要table布局,因为一个很小的改动会造成整个table重新布局
- 常见重绘元素
- 颜色 color,background
- 边框样式 border-style,outline-color,outline,outline-style,border-radius,box-shadow,outline-width
- 背景相关 background,background-image,background-position,background-repeat,background-size
- tips:选择器是从右向左匹配的,出于性能考虑,选择器选择时大部分元素是不会被选择的
12、层叠上下文
定义:浏览器三维概念,Z轴上的每一层可以视为一个层叠上下文
层叠水平
同一个层叠上下文中用来区分元素距离用户的远近,所有元素都有层叠水平,z-index 只能影响定位元素以及 flex 盒子的孩子元素
层叠顺序
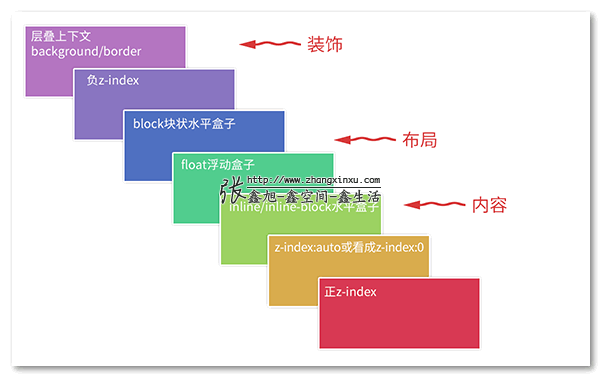
内容为王,所以内联元素在上
层叠准则
文档流后面的元素会覆盖前面的
明显的层叠水平标示时,谁大谁在上
比较时先比父级
常见的层叠上下文的创建
1、页面根元素
2、设置了 z-index 的定位元素
3、设置了 z-index 的 flex 的子元素
4、元素的opacity值不是1
5、元素的transform值不是none
13、居中
Grid
flex
绝对定位 + transform/calc/负 margin
绝对定位 left right top bottom为 0,margin 为 auto
这种方案子元素不设置宽高,就可以铺满父级(用做遮罩层)
margin: 0 auto: display: block; /* 还可以是 table | flex | grid,但不能是 inline-xxx */
inline-block + line-height:元素的 height 和 line-height 相同的时候,会使其文本内容垂直居中,再将里面的元素设置为 inline-block,这样元素就会被当做文本对待了
table-cell,一般不用
14、浮动元素
浮动元素只能影响行内元素,间接影响了包含块的布局
浮动元素只会浮动在文档流后面的块元素上,不会侵犯前面的块元素领地
让浮动元素撑开包含块:BFC、空内容伪元素设置 clear:both(把伪元素的边界放到所有浮动元素下面,所以撑开)、包含块自己也浮动(其实也是 BFC)
HTML & 浏览器
1、行内元素、块级元素
区别
块级元素:
① 总是在新行上开始,占据一整行;
② 高度,行高以及外边距和内边距都可控制;
③ 不加控制的话宽度会撑满浏览器,与内容无关;
④ 它可以容纳内联元素和其他块元素。
行内元素:
① 和其他元素都在一行上;
② 行高及外边距和内边距部分可改变(水平方向有效,竖直方向无效)。 如果是可替换元素,比如 input ,竖直方向是有效的
③ 宽度只与内容有关;
④ 行内元素只能容纳文本或者其他行内元素。
2、跨标签页通信
同源页面间的通信
BroadCast Channel
const page = new BroadcastChannel('channel');
page.onmessage = function (e) {
const data = e.data;
const text = '[receive] ' + data.msg + ' —— tab ' + data.from;
console.log('[BroadcastChannel] receive message:', text);
};
page.postMessage(mydata);
Service Worker
本身不具备通信属性,但是可以作为后台长期运行的 worker,建立通信站
/* 页面中注册 */
navigator.serviceWorker.register('../service.js').then(function () {
console.log('Service Worker 注册成功');
});
/* 页面中监听 */
navigator.serviceWorker.addEventListener('message', function (e) {
const data = e.data;
});
/* 页面中发送消息 */
navigator.serviceWorker.controller.postMessage(mydata);
// service worder 代码,监听 message 事件,通过 self.clients.matchAll 获取所有注册页面,
// 然后循环将消息通过 postMessage 发送给所有页面
self.addEventListener('message', function (e) {
console.log('service worker receive message', e.data);
e.waitUntil(
self.clients.matchAll().then(function (clients) {
if (!clients || clients.length === 0) {
return;
}
clients.forEach(function (client) {
client.postMessage(e.data);
});
})
);
});
LocalStorage
特性:当 LocalStorage 变化时,会触发 storage 事件
// 根据传入的 key 区分值
window.addEventListener('storage', function (e) {
if (e.key === 'yangyi') {
const data = JSON.parse(e.newValue);
}
});
// 传输消息的页面,正常 setItem,加上时间戳(因为 storage 事件只在值真的改变时触发)
mydata.st = +(new Date);
window.localStorage.setItem('ctc-msg', JSON.stringify(mydata));
上面三个属于订阅发布模式,下面两个是共享存储+轮询
Shared Worker
普通的 Worker 之间独立运行、数据互不相通;而多个 Tab 注册的 Shared Worker 可以实现数据共享
缺点:无法主动通知所有页面,必须轮询
// 页面中注册,第二个参数是 Shared Worker 名称,也可以留空
const sharedWorker = new SharedWorker('../worker.js', 'worker-name');
/* Shared Worker 思路 */
1、监听 connect 事件
2、只能根据传入的数据中的字段,区分是否是获取数据还是发送数据,只有 postMessage 方法
3、每个页面需要轮询请求数据:sharedWorker.port.postMessage({get: true});
IndexDB
轮询查询指定的数据是否被更新,不是很友好
window.open
window.open 会返回打开的页面的 window 对象引用,然后通过window.opener.postMessage(mydata) 发送消息
缺点:必须通过 window.open,并且只能一个传一个
非同源页面之间的通信
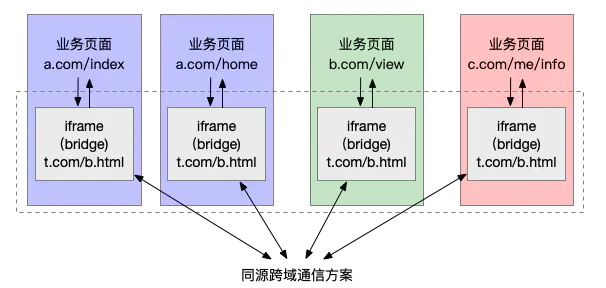
如上图,每个业务页面都有一个 iframe,所有 iframe 的 url 是相同的(也可以不同,同源就行),iframe 之间使用上面的同源页面的通信方式
此外还有基于服务端的:Websocket、SSE(服务端推送事件)
他俩区别:
- WebSocket 很复杂, SSE 简洁轻量
- WebSocket 是二进制协议,SSE 是文本协议(一般是 utf-8 编码),用 SSE 传输二进制数据时数据会变大,所以如果传输二进制数据还是 WS 厉害。
- WebSocket 最大的优势在于它是双向交流的,SSE 是单向的。如果需要1次/秒以上的频率,那么选 WS
3、hash 和 history 路由模式
路由需要实现的功能
- 浏览器地址变化,切换页面
- 点击【后退】、【前进】按钮,内容可以跟随变化
- 刷新浏览器,也可以显示当前路由对应内容
hash 模式
原理:使用 window.location.hash 属性及窗口的 onhashchange 事件
- hash 为 #号后面跟着的字符,也叫散列值。
- 散列值的改变不会触发浏览器请求服务器,从而导致页面重载
触发 hashchange 事件的几种情况
- 散列值的变化(浏览器的前进、后退,JS 修改)
- URL 直接输入带哈希的链接,请求完毕之后会触发
- URL 只改变哈希的值按回车
- a 标签的 href 属性设置
history模式
原理
- window.history 指向 History 对象,它表示当前窗口的浏览历史。当发生改变时,只会改变页面的路径,不会刷新页面。
- 浏览器工具栏的“前进”和“后退”按钮,其实就是对 History 对象进行操作
属性
History.length:当前窗口访问过的网址数量(包括当前网页)History.state:History 堆栈最上层的状态值(默认为 undefined)
方法
History.back():移动到上一个网址,等同于浏览器的后退键。对于第一个访问的网址,该方法无效果。
History.forward():移动到下一个网址,等同于浏览器的前进键。对于最后一个访问的网址,该方法无效果。
History.go():接受一个整数作为参数,以当前网址为基准,移动到参数指定的网址。如果参数超过实际存在的网址范围,该方法无效果;如果不指定参数,默认参数为0,相当于刷新当前页面。
History.pushState:在历史中添加一条记录, 不会触发页面刷新,,三个参数: object、title、url,分别为传递给新页面的对象、标题、新的网址(必须同域,防止恶意代码让用户以为还在同站)
注意:URL 参数设置了一个新的锚点值(即 hash),并不会触发 hashchange 事件。
History.replaceState:修改当前历史记录,参数同上
事件 popstate
- 仅仅调用 pushState() 方法或 replaceState() 方法 ,并不会触发该事件;
- 只有用户点击浏览器倒退按钮和前进按钮,或者使用 JavaScript 调用 History.back()、History.forward()、History.go() 方法时才会触发。
- 该事件只针对同一个文档,如果浏览历史的切换,导致加载不同的文档,该事件也不会触发。
- 页面第一次加载的时候,浏览器不会触发 popstate 事件。
- 回调函数的参数中的 state ===
缺点
改变页面地址后,强制刷新浏览器时会404,因为会触发请求,而服务器中没有这个页面,所以一般单页应用会全部重定向到 index.html 中
4、DOM 树
什么是 DOM
HTML 文件字节流无法直接被渲染引擎理解,需要转化为对 HTML 文档结构化的表述,也就是 DOM。
作用
- 页面的视角:DOM 是生成页面的基础数据结构。
- JavaScript 脚本视角:DOM 提供给 JS 脚本操作的接口,JS 可以访问 DOM 结构,改变文档的结构、样式和内容。
- 安全视角:一道防线,一些不安全的内容在 DOM 解析阶段就被拒之门外了。
如何生成
渲染引擎内部,有一个叫 HTML 解析器(HTMLParser)的模块,将 HTML 字节流转换为 DOM 结构
HTML 解析器,是网络进程加载了多少数据,便解析多少数据。过程如下:
- 网络进程接收到响应头之后,根据响应头中的 content-type 字段来判断文件的类型,从而选择或创建一个渲染进程
- 渲染进程准备好之后,网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据“喂”给 HTML 解析器
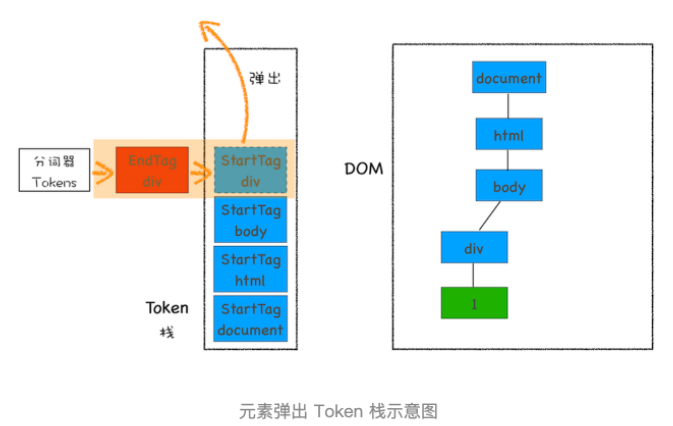
喂给数据之后,字节流转换为 DOM 的三个阶段:
-
分词器做词法分析,将字节流转换为 Token
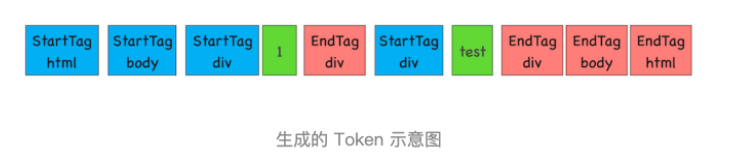
-
Token 解析为 DOM 节点 3. 同时将 DOM 节点添加到 DOM 树中
三种情况:
- 如果入栈的是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点。
- 如果是文本 Token,会生成一个文本节点,然后将该节点加入到 DOM 树中。文本 Token 不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点。
- 如果是 EndTag 标签,HTML 解析器会查看 Token 栈顶的元素是否是 StartTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。
简单示例图:
JavaScript 是如何影响 DOM 生成的
一、内嵌 js
<html>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
</script>
<div>test</div>
</body>
</html>
遇到 js 时,渲染引擎判断这是一段脚本,HTML 解析器就会暂停 DOM 的解析,因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构,执行完毕之后继续解析,流程是一样的。
二、外部引入 js
<html>
<body>
<div>1</div>
<script type="text/javascript" src='foo.js'></script>
<div>test</div>
</body>
</html>
chrome 有一个优化操作,当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件
解析过程同上是一样的
三、JS 中有操作 css
<head>
<style src='theme.css'></style>
</head>
<body>
<div>1</div>
<script>
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang' // 需要 DOM
div1.style.color = 'red' // 需要 CSSOM
</script>
<div>test</div>
</body>
</html>
渲染引擎在遇到 JavaScript 脚本时,不管该脚本是否操纵了 CSSOM,都会执行 CSS 文件下载(因为引擎无法确定是否已下载),解析操作,再执行 JavaScript 脚本。JavaScript 脚本是依赖样式表的,这又多了一个阻塞过程。
总结:JavaScript 会阻塞 DOM 生成,而样式文件又会阻塞 JavaScript 的执行
四、优化操作
-
CDN 加速
-
压缩文件的体积
-
如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码。
二者都是异步的,但使用 async 标志的脚本文件一旦加载完成,会立即执行;而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行。
5、事件
EventTarget 接口
addEventListener 的第三个参数默认是 false 冒泡,还可以设置为属性配置对象
- capture:布尔值,是否在捕获阶段触发。
- once:布尔值,监听函数是否只触发一次,然后自动移除。
- passive:布尔值,表示监听函数不会调用事件的preventDefault方法。如果监听函数调用了,浏览器将忽略这个要求,并在监控台输出一行警告。
当添加多个监听时,先添加先触发
removeEventListener 没有返回值
dispatchEvent 手动触发事件,参数为某个 event, 比如 click
事件模型
三种绑定事件方法
- 标签上直接使用 on-xxxx,这种方式只会在冒泡阶段触发,必须加圆括号执行
- 元素对象使用 onclick 等事件,window.onload = doSomething,不用加圆括号
- addEventListener
事件的传播
- 第一阶段:从 window 对象传导到目标节点(上层传到底层),称为“捕获阶段”(capture phase)。
- 第二阶段:在目标节点上触发,称为“目标阶段”(target phase)。
- 第三阶段:从目标节点传导回 window 对象(从底层传回上层),称为“冒泡阶段”(bubbling phase)。
stopPropagation 阻止冒泡和捕获,但不会阻止当前节点的事件触发后面的监听函数
stopImmediatePropagation 彻底取消当前事件,后面的监听函数也不会触发
Event 对象
当 Event.cancelable 属性为true时,调用 Event.preventDefault() 才可以取消这个事件,阻止浏览器对该事件的默认行为
Event.currentTarget 属性返回事件当前所在的节点
Event.target 属性返回原始触发事件的那个节点
Event.isTrusted 表示该事件是否由真实的用户行为产生
Event.composedPath() 返回一个数组,成员是事件的最底层节点和依次冒泡经过的所有上层节点。
键盘事件
mousemove:当鼠标在一个节点内部移动时触发。鼠标持续移动会连续触发。为了避免性能问题,应该做节流。
节流:每隔一段时间,只执行一次函数
防抖:在事件被触发 n 秒后再执行回调,如果在这 n 秒内又被触发,则重新计时
mouseenter:鼠标进入一个节点时触发,进入子节点不会触发这个事件
mouseleave:鼠标离开一个节点时触发,离开父节点不会触发这个事件
mouseover:鼠标进入一个节点时触发,进入子节点会再一次触发这个事件
mouseout:鼠标离开一个节点时触发,离开父节点也会触发这个事件
wheel:滚动鼠标的滚轮时触发
触发顺序:mousedown、mouseup、click、dblclick
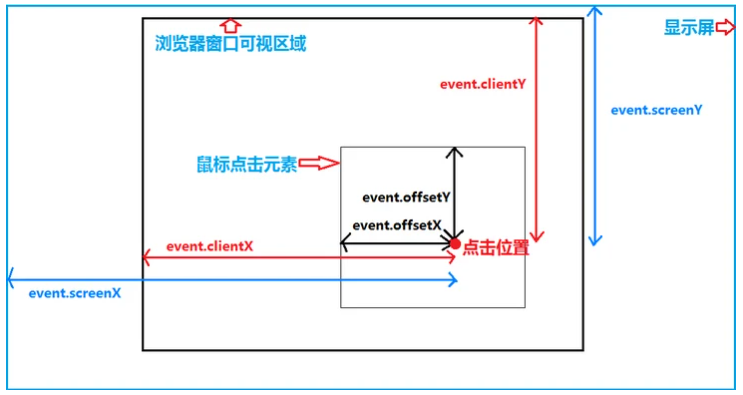
几个计算距离的属性:clientX/Y(浏览器可视)、pageX/Y(相对文档区域左上角距离,会随着页面滚动而改变)、offsetX/Y(当前DOM)、screenX/Y(显示器)
6、缓存机制
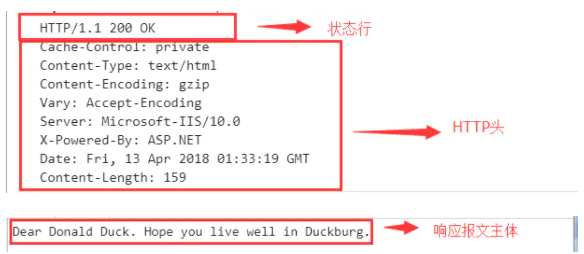
HTTP 报文
HTTP请求报文格式
请求行
HTTP头(通用信息头,请求头,实体头)
请求报文主体(只有POST才有报文主体)

HTTP报文格式为:
状态行
HTTP头(通用信息头,响应头,实体头)
响应报文主体
缓存过程
- 浏览器每次发起请求,先在浏览器缓存中查找请求的结果以及缓存标识
- 浏览器每次拿到返回的请求结果,都会将该结果和缓存标识存入浏览器缓存中
浏览器是否需要向服务器重新发送 HTTP 请求,取决于 我们选择的缓存策略
强制缓存
三种情况:
- 不存在该缓存结果和缓存标识,强制缓存失效,则直接向服务器发起请求
- 存在该缓存结果和缓存标识,但该结果已失效,强制缓存失效,则使用协商缓存
- 存在该缓存结果和缓存标识,且该结果尚未失效,强制缓存生效,直接返回该结果
Expires
HTTP/1.0 的字段,值是服务器返回的过期时间。
缺点:时区不同的话,客户端和服务端有一方的时间不准确发生误差,那么强制缓存则会直接失效
Cache-Control
HTTP/1.1 的字段
- public:所有内容都将被缓存(客户端和代理服务器都可缓存)
- private:所有内容只有客户端可以缓存,Cache-Control 的默认取值
- no-cache:客户端缓存内容,但是是否使用缓存则需要经过协商缓存来验证决定
- no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存
- max-age=xxx (xxx is numeric):缓存内容将在 xxx 秒后失效
注意:
刷新:浏览器会在 js 和图片等文件解析执行后直接存入内存缓存中,刷新页面从内存缓存中读取(from memory cache);而css文件则会存入硬盘文件中,每次渲染页面都需要从硬盘读取缓存(from disk cache)。
关闭再打开:之前的进程内存已清空,所以都是硬盘缓存
协商缓存
缓存结果失效后,根据缓存标识发送 HTTP 请求,服务器进行判断
标识
Last-Modified / If-Modified-Since
前者:响应头中,表示文件在服务器最后被修改的时间
后者:请求头,值同上,告诉服务器进行判断,文件是否改变,没变则使用缓存,变了就返回最新的
Etag / If-None-Match
前者:响应头中,表示文件在服务器中唯一标识
后者:请求头,值同上,告诉服务器进行判断,文件是否改变,没变则使用缓存,变了就返回最新的
注:Etag / If-None-Match 优先级高于 Last-Modified / If-Modified-Since,同时存在则只有Etag / If-None-Match生效。
总结
- 强制缓存优先于协商缓存进行,若强制缓存( Expires 和 Cache-Control )生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since 和 Etag / If-None-Match)
- 协商缓存由服务器决定是否使用缓存,若协商缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存
- 优先内存,再硬盘
7、Chrome 浏览器架构
进程、线程、协程
一个进程是应用正在运行的程序,操作系统会为进程分配私有的内存空间以供使用。
协程是运行在线程中更小的单位,async/await 就是基于协程实现的。
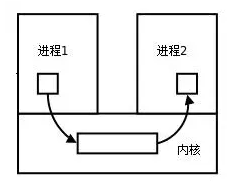
进程间通信(IPC)
一个进程可以让操作系统开启另一个进程处理不同的任务。进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷到内核缓冲区,进程2再从内核缓冲区把数据读走,这就是IPC(Inter Process Communication)。
套接字(socket)
凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行
套接字的特性由3个属性确定,它们分别是:域、端口号、协议类型。
三种套接字:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取 TCP 协议的数据,数据报套接字只能读取 UDP 协议的数据。
管道/匿名管道(pipe)
- 管道是半双工的,数据只能向一个方向流动;需要双方通信时,需要建立起两个管道。
- 只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程);
- 单独构成一种独立的文件系统:管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在与内存中。
- 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据(队列)。
有名管道(FIFO)
相比上面可以非亲缘关系
浏览器架构
一、多进程架构(每个页面都是单独的)
浏览器进程(Browser process)
管理 Chrome 应用本身,包括地址栏、书签、前进和后退按钮。同时也负责网络请求、文件访问等,也负责其他进程的调度。
渲染进程(Renderer process)
渲染进程负责站点的渲染,其中也包括 JavaScript 代码的运行,web worker 的管理等。
插件进程(Plugin process)
GPU 进程(GPU process)
GPU 进程负责提供成像的功能
好处
- 一个页面没有相应不会阻塞其他页面
- 借助操作系统对进程安全的控制,浏览器可以将页面放置在沙箱中,核心进程代码可以运行在隔离的环境中,保证安全。
缺点
- 相同功能无法共用,会浪费内存,比如 V8 引擎
- Chrome 限制了最大进程数,为了节省内存,最大进程数取决于硬件的能力。当使用多个页签访问相同的站点时,浏览器不会创建新的渲染进程
二、面向服务的架构
当 Chrome 运行在拥有强大硬件的计算机上时,会将一个服务以多个进程的方式实现,提高稳定性
当计算机硬件资源紧张时,则可以将多个服务放在一个进程中节省资源。
三、iframe
出于安全考虑,从 Chrome 67 开始每个 iframe 打开的站点由独立的渲染进程处理被默认启用。
浏览器进程
包括几个线程
- UI 线程负责绘制工具栏中的按钮、地址栏等。
- 网络线程负责从网络中获取数据。
- 存储线程负责文件等功能。
一次页面访问
一、输入处理
UI 线程会先判断我们输入的内容是要搜索的内容还是要访问一个站点,因为地址栏同时也是一个搜索框。
二、访问开始
按下回车访问,UI 线程将借助网络线程访问站点资源,网络线程根据适当的网络协议,例如 DNS lookup 和 TLS 为这次请求建立连接
三、处理响应数据
根据 Content-Type ,如果是 HTML ,网络线程会将数据传递给渲染进程做进一步的渲染工作。
如果数据类型是 zip 文件或者其他文件格式时,会将数据传递给下载管理器做进一步的文件预览或者下载工作
在开始渲染之前,网络线程要先检查数据的安全性。如果返回的数据来自一些恶意的站点,网络线程会显示警告的页面。同时,Cross Origin Read Blocking(CORB) 策略也会确保跨域的敏感数据不会被传递给渲染进程。
四、渲染过程
在第二步,UI 线程将请求地址传递给网络线程时,UI 线程就已经知道了要访问的站点。此时 UI 线程就同时查找或启动一个渲染进程。如果网络线程按照预期获取到数据,则渲染进程就已经可以开始渲染了,减少了等待时间。
当然,如果出现重定向的请求时,提前初始化的渲染进程可能就不会被使用,但相比正常访问站点的场景,重定向往往是少数。
五、提交访问
当数据和渲染进程后,浏览器进程通过 IPC 向渲染进程提交这次访问,同时也会保证渲染进程可以通过网络线程继续获取数据。渲染进程在所有 onload 事件都被触发后向浏览器进程发送完毕的消息,访问结束,文档渲染开始。
这时可能还有异步的 js 在加载资源
为了能恢复访问历史信息,当页签或窗口被关闭时,访问历史的信息会被存储在硬盘中。
访问不同的站点
当访问其他页面时,一个独立的渲染进程将被用于处理这个请求,为了支持像unload的事件触发,老的渲染进程需要保持住当前的状态,知道用户做出选择。
Service worker
开发者可以决定用本地存储的数据还是网络访问。当访问开始时,网络线程会根据域名检查是否有 Service worker 会处理当前地址的请求,如果有,则 UI 线程会找到对应的渲染进程去执行 Service worker 的代码。
如果 worker 决定使用网络,进程间的通信已经造成了一些延迟,这时候可以使用 Navigation Preload:sw 启动时并行网络请求,加上下面的请求头,服务器进行配合,sw 中进行开启
await self.registration.navigationPreload.enable();
请求头:Service-Worker-Navigation-Preload: true
渲染进程
渲染进程最重要的工作就是将 HTML、CSS 和 Javascript 代码转换成一个可以与用户产生交互的页面
主线程负责解析,编译或运行代码等工作,如果使用 Worker ,Worker 线程会负责运行一部分代码。合成线程和光栅线程也是运行在渲染进程中的,负责更高效和顺畅的渲染页面。
解析过程
DOM 的创建
主线程解析 HTML 文本字符串,并且将其转化成 Document Object Model(DOM),静默处理标签的丢失、未闭合等错误
1.额外资源的加载
当 HTML 主解析器发现了类似 img 或 link 这样的标签时,预加载扫描器(副解析器)就会启动,它会马上找出接下来即将需要获取的资源(比如样式表,脚本,图片等资源)的 URL ,然后发送请求给浏览器进程的网络线程,而不用等到主解析器恢复运行,从而提高了整体的加载时间
2.JavaScript 会阻塞转化过程
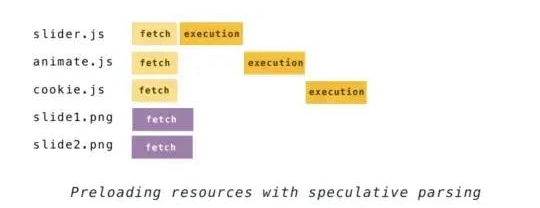
解析执行还是要等主线程空闲,并且只能读到 HTML 中的资源,当 HTML 分析器发现
样式计算
主线程遍历 DOM 结构中的元素及其样式,同时创建出带有坐标和元素尺寸信息的布局树(Layout tree),只包含将会在页面中显示的元素
伪元素会出现在布局树中,不会在 DOM 树中
一、渲染过程是昂贵的
布局树改变时,绘制需要重构页面中变化的部分,数据变化会引起后续一系列的的变化
渲染操作运行在主线程中,可能被正在运行的 Javascript 代码所阻塞。可以将 Javascript 操作优化成小块,然后使用 requestAnimationFrame()
使用 setTimeout 或 setInterval 来执行动画之类的视觉变化,这种做法的问题是,回调将在帧中的某个时点运行,可能刚好在末尾,而这可能经常会使我们丢失帧,导致卡顿
二、合成(Compositing)
1)光栅化
浏览器将文档结构、每一个元素的样式,元素的几何信息,绘制的顺序等转化成屏幕上像素的过程
2)层(Layer): 主线程遍历布局树找到 层 需要生成的部分,可以使用 css 属性 will-change、transform、Z-index 让浏览器创建层
分层优点:减少不必要的重新绘制、实现较为复杂的动画、方便实现复杂的CSS样式
3)栅格线程与合成线程
合成线程将层拆分成许多块,并决定块的优先级,发送给栅格线程。栅格线程光栅化这些块并将它们存储在 GPU 缓存中,合成线程使用 draw quads 收集这些信息并创建合成帧
4)好处
合成的好处在于其独立于主线程,不需要等待样式计算和 Javascript 代码的运行,但如果布局或者绘制需要重新计算则主线程是必须要参与的
总结
浏览器的渲染过程就是将文本转换成图像的过程
渲染进程中的主线程完成计算工作,合成线程和栅格线程完成图像的绘制工作
事件
发生交互时,浏览器进程首先接收到事件,将事件类型和位置信息等发送给负责当前页签的渲染进程,渲染进程找到事件发生的元素并且触发事件监听器。
合成线程对事件的处理
当页面被合成线程合成过,合成线程会标记那些有事件监听的区域。当事件发生在响应的区域时,合成线程就会将事件发送给主线程处理(这里会阻塞 UI 变化,详情见 passive 改善滚屏)。如果在非事件监听区域,则渲染进程直接创建新的帧而不关心主线程。
减少发送给主线程的事件数量
touchmove 这样的事件每秒向主线程发送 120 次可能会造成主线程执行时间过长而影响性能
Chrome 合并了连续的事件,类似 mousewheel,mousemove,touchmove这样的事件会被延迟到下一次 requestAnimationFrame 前触发
类似 keydown, keyup, mouseup 的离散事件会立即被发送给主线程处理。
8、浏览器工作原理
高层结构
- 用户界面 - 包括地址栏、前进/后退按钮等。除了浏览器主窗口显示的请求的页面外,其他都属于用户界面。
- 浏览器引擎 - 在用户界面和呈现引擎之间传送指令。
- 呈现引擎(应该也叫做渲染引擎)- 负责显示请求的内容。如果返回 HTML,它就负责解析 HTML 和 CSS 内容,显示在屏幕上。
- 网络 - 用于网络调用,比如 HTTP 请求。其接口与平台无关,并为所有平台提供底层实现。
- 用户界面后端 - 绘制基本的窗口小部件,比如组合框和窗口。使用与平台无关的通用接口,在底层使用操作系统的用户界面方法。
- JavaScript 解释器。用于解析和执行 JavaScript 代码。
- 数据存储。这是持久层。浏览器需要在硬盘上保存各种数据,例如 Cookie
呈现引擎主流程
解析是什么
定义:将文档转化成为有意义的结构,称作解析树或者语法树
过程:词法分析 和 语法分析 ,迭代过程
1.词法分析器
将输入内容分解成一个个有效标记,将无关的字符(比如空格和换行符)分离出来
2.解析器
根据语言的语法规则分析文档的结构,构建解析树(由 DOM 元素和属性节点构成的树结构)。
解析器向词法分析器请求一个新标记,尝试将其与某条语法规则进行匹配。
如果发现了匹配规则,解析器会将一个对应于该标记的节点添加到解析树中,然后继续请求下一个标记。如果没有规则可以匹配,解析器就会将标记存储到内部,并继续请求标记,直至所有内部存储的标记都有对应匹配的规则。如果找不到,解析器就会引发一个异常。这意味着文档无效,包含语法错误。
HTML 解析
无法用常规的 自上而下 或 自下而上 的解析器进行解析,原因在于:
- 语言的宽容本质。
- 浏览器对一些常见的无效 HTML 用法采取包容态度。
- 解析过程需要不断地反复。源内容在解析过程中通常不会改变,但是在 HTML 中,js 如果包含 document.write,就会添加额外的标记,这样解析过程实际上就更改了输入内容。
所以使用专有的 标记化算法(状态机) 和 树构建算法(状态机)
标记化算法:
- 初始状态是数据状态
- 遇到字符 < 时,状态更改为“标记打开状态”
- 遇到标签名时,“标记名称状态”
- 遇到 > 标记时,会发送当前标记给构建器,状态改回“数据状态”
- 遇到标签中的每一个字符时,会创建发送字符标记,知道遇到下一个 <
树构建算法:根据接收的标记,创建并插入对应的 DOM 元素,改变对应的状态。
“initial mode”、“before html”、“before head” 之类的状态
CSS 解析
-
预加载扫描器(预解析器)会提前去请求如CSS、JavaScript和web字体。
-
构建 render 树(也叫呈现树、渲染树):非可视化的 DOM 元素不会插入呈现树中,处理 html 和 body 标记就会构建呈现树根节点,对应于 CSS 规范中所说的容器 block,也是最上层的 block
浏览器利用规则树来优化构建时的样式计算,保存计算过的匹配路径重复使用
这里没有说 cssom树,其实就是把 css 解析成树的结构
布局
呈现树中的元素(也叫呈现器),并不包含位置和大小信息。计算这些值的过程称为布局或重排。
1.Dirty 位系统:浏览器给每个需要重新布局的元素进行标记
“dirty” 和 “children are dirty”一个表示自身,一个表示至少有一个子代
2.全局布局(同步)和增量布局(异步)
全局布局是指触发了整个呈现树范围的布局,触发原因可能包括:
- 字体大小更改。
- 屏幕大小调整。
增量布局:当来自网络的额外元素添加到 DOM 树之后
绘制
系统遍历呈现树,并调用呈现器的“paint”方法,将呈现器布局阶段计算的每个框转换为屏幕上的实际像素
绘制可以将布局树中的元素分解为多个层。将内容提升到GPU上的层(而不是CPU上的主线程)可以提高绘制和重新绘制性能,但会以内存管理为代价
合成
当文档的各个部分以不同的层绘制,相互重叠时,必须进行合成,以确保它们以正确的顺序绘制到屏幕上,并正确显示内容。
呈现引擎的线程
单线程,在 Firefox 和 Safari 中,该线程就是浏览器的主线程。而在 Chrome 浏览器中,该线程是标签进程的主线程
9、内存泄漏
什么是内存
由大量触发器组成,每个触发器包含几个晶体管,能够存储一个位。单个触发器可以通过唯一标识符寻址,我们可以读取和覆盖它们。
内存生命周期
内存分配 -> 内存使用 -> 内存释放
强弱引用的垃圾回收区别
const map = new Map([[obj, 'info']])
obj = null // 重写obj,obj 代表的内存不会被回收
const map = new WeakMap([[obj, 'info']])
obj = null // 重写obj,obj 代表的内存会被回收
内存泄漏的一些场景
-
意外的全局变量
-
被遗忘的计时器(vue 组件中的一定要在 beforeDestroy 时清掉)
-
被遗忘的事件监听器(同上)
-
被遗忘的订阅发布事件监听器,需要用 off 删掉(同上)
-
强引用中没有使用 api 释放,只是单纯删除掉变量的引用
let map = new Set(); let value = { test: 22}; map.add(value); map.delete(value); // 有效 value = null; // 无效 -
被遗忘的未使用的闭包
-
脱离 DOM 的引用
let elements = {
btn: document.querySelector(’#button’)
}
document.body.removeChild(elements.btn)
// elements .btn = null 加上这一句才不泄露,因为 DOM 占用的那块内存还被对象引用
发现内存泄漏
-
打开谷歌开发者工具,切换至 Performance 选项,勾选 Memory 选项,点击运行按钮
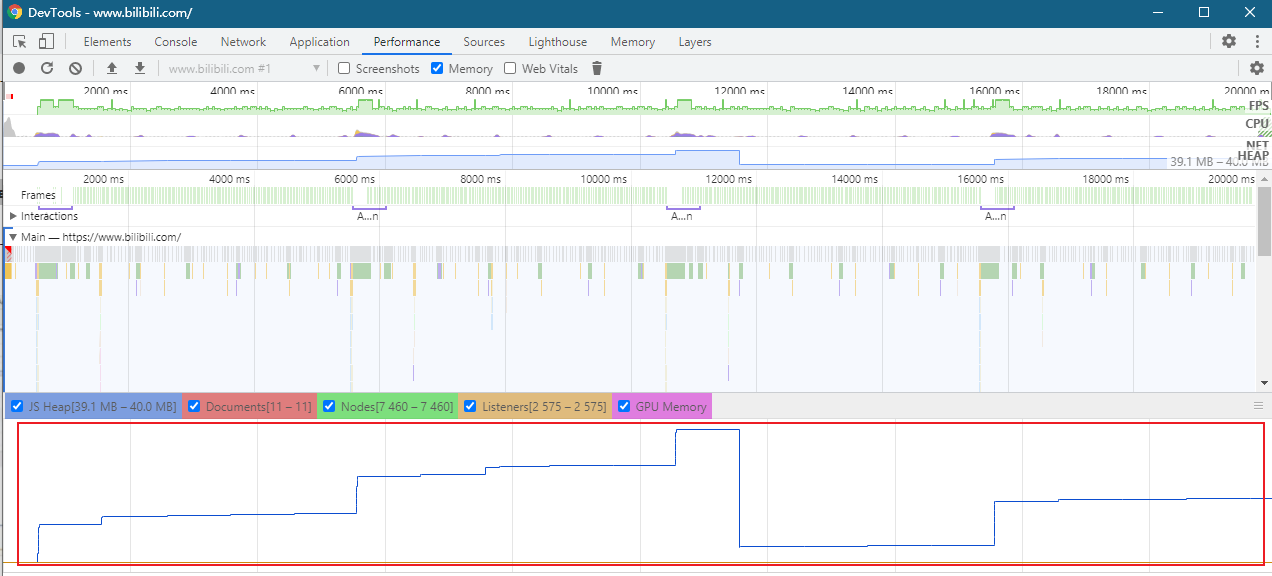
上图红框内就是内存变化,如果是一直递增,那基本可以确定存在泄漏
-
切换至 Memory 选项,点击运行获取网页快照
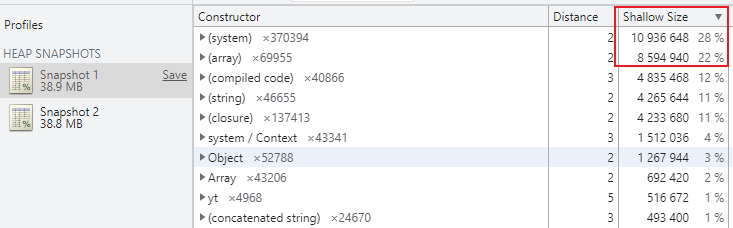
根据内存占用大小,点击左侧元素,再找到具体的文件与代码位置即可
10、性能
优化性能指标 RAIL
含义:
- Response
- Animation
- Idle
- Load
Response: 事件处理最好在 50ms 内完成
- 事件处理函数在 50ms 内完成,考虑到 idle task 的情况,事件会排队,等待时间大概在50ms。适用于click,toggle,starting animations 等,不适用于 drag 和 scroll 。
- 复杂的 js 计算尽可能放在后台,如 web worker,避免对用户输入造成阻塞
- 超过 50ms 的响应,一定要提供反馈,比如倒计时,进度百分比等。
Animation: 在10ms内产生一帧
- 为了保证浏览器60帧,每一帧的时间在16ms左右,但浏览器需要用 6ms 来渲染每一帧。
Idle: 最大化空闲时间
每一次事件循环结束时的空闲时间,完成一些延后的工作,比如加载剩余不可见页面。 requestIdleCallback API
Load: 传输内容到页面可交互的时间Time to Interactive(TTI)不超过5秒
- 让你的页面在一个中配的3G网络手机上打开时间不超过5秒
- 对于第二次打开,尽量不超过2秒
测试与优化
- F12选用中配的3G网络(400kb/s,400ms RTT)
- 延后加载阻塞渲染的资源,
- 可以采用 lazy load,code-splitting 等 其他优化 手段,让第一次加载的资源更少
性能优化手段
从输入URL按下回车开始,每一步可以做的优化如下
一、缓存
本地数据存储
localStorage、sessionStorage、indexedDB,对于一些特殊的、轻量级的业务数据,可以考虑使用本地存储作为缓存(比如每日排行榜列表)
内存缓存(Memory)
浏览器帮我们实现的优化
Cache API
不规定该缓存什么、什么情况下需要缓存,也不必须搭配 Service Worker 。
当然 Service Worker 与 Cache API 还是一个功能非常强大的组合,能够实现堆业务的透明。
Cache API 提供的缓存可以认为是“永久性”的,关闭浏览器或离开页面之后,下次再访问仍然可以使用,每个域可以有多个不同的 Cache 对象。
navigator.storage.estimate().then(function(estimate) {
console.log(estimate.quota)
});
153634836480 约等于 153GB
HTTP 缓存
如果前面的步骤都没没有命中缓存,就会到 HTTP request 的阶段
强缓存:直接读取「disk cache」,不够灵活,服务器更新资源不能及时通知
响应头:
Expires和Cache-Control,前者设置过期时间,与本地时间对比,后者设置一个最大时间比如max-age=300,300s内走强缓存协商缓存
- 最后修改时间:服务器第一次响应时返回 Last-Modified,而浏览器在后续请求时带上其值作为 If-Modified-Since(精度不够,如果时间很短)
- 文件标识:服务器第一次响应时返回 ETag,而浏览器在后续请求时带上其值作为 If-None-Match,一般会用文件的 MD5 作为 ETag
Push Cache
最后一个缓存检查
HTTP/2 的 Push 功能所带来的。请求一个资源的同时,服务端可以为你“推送”一些其他资源 --不久的将来会用到的一些资源。比如样式表,避免了浏览器收到响应、解析到相应位置时才会请求所带来的延后
特点:
- 匹配上时,并不会在额外检查资源是否过期
- 存活时间很短,甚至短过内存缓存(Chrome 中为 5min 左右)
- 只会被使用一次
- HTTP/2 连接断开将导致缓存直接失效
二、请求
避免多余重定向
DNS 预解析
请求网站流程:
- 本地 hosts 文件中的映射
- 本地 DNS 缓存
- 在 TCP/IP 参数中设置的 DNS 查询服务器,也叫 本地 DNS
- 如果该服务器无法解析域名(没有缓存),且不需要转发,会向根服务器请求;
- 根服务器根据域名类型判断对应的顶级域名服务器(.com),返回给本地 DNS,然后重复该过程,直到找到该域名;
- 如果设置了转发,本地 DNS 会将请求逐级转发,直到转发服务器返回或者也不能解析。
上述服务前端不好切入,但可以通过设置属性,告诉浏览器尽快解析(并不保证,根据网络、负载等做决定)
<link rel="dns-prefetch" href="//yourwebsite.com">
预先建立连接
建立连接不仅需要 DNS 查询,还需要进行 TCP 协议握手,有些还会有 TLS/SSL 协议,这些都会导致连接的耗时
使用预连接时浏览器处理:
- 首先,解析 Preconnect 的 url
- 其次,根据当前 link 元素中的属性进行 cors 的设置
- 然后,默认先将 credential 设为 true,如果 cors 为 Anonymous 并且存在跨域,则将 credential 置为 false
- 最后,进行连接。
浏览器也不一定完成连接,视情况
<link rel="preconnect" href="//sample.com" crossorigin>
// 值不写具体的 use-credentials 都相当于设置成 Anonymous
三、服务端响应(了解)
使用流进行响应
如果不使用 websocket ,就只能让页面加载不完,一直给页面加东西,这样就一直在传输数据(不是很好)
业务聚合
使用 BFF 层
- 比如第二个接口依赖第一个接口,两个接口加起来是 400ms,如果这两个请求放在 BFF 层,因为都在服务器所以离后端‘近’,两个接口只需 40 ms,再通过前端一个请求返回,加起来就是 240 ms
- 如果一个业务需要在前端并发三、四个请求来获取完整数据
避免代码问题
- 频繁地 JSON.parse 和 JSON.stringify 大对象
- CPU 密集型任务导致事件循环 delay 严重 …
四、页面解析与处理
浏览器收到请求后,做三件事:
- 页面 DOM 的解析
- 静态资源的加载
- 静态资源的解析与处理
先看解析部分
注意资源在页面文档中的位置
JavaScript 会阻塞 DOM 构建,而 CSSOM 的构建又会阻塞 JavaScript 的执行。
CSS 放到头部,保证了下面的 DOM 构建后,CSSOM 构建完毕。JS 放到尾部就不会被阻塞
使用 defer 和 async
如果 JS 中不存在影响 DOM 的话。
区别:
- defer 会在 HTML 解析完成后,按照 script 标签顺序执行,async 执行顺序随机
- defer 脚本的编译执行一定在 DOMContentLoaded 之前,async 脚本的编译执行一定在 Onload 之前
- async 下载完成就立即开始执行,同时阻塞页面解析(实验了2021/8/5并不会阻塞)

页面文档压缩
一般 webpack 就会帮打包,同时后端 gzip 也是开启的
DOMContentLoaded 事件何时触发
- Document 正在加载时返回 “loading”
- 当它完成解析但仍在加载子资源时返回 “interactive”
- 当它加载完毕后返回 "complete "
当值发生变化时,Document 对象上的 readystatechange 事件会被触发
DOMContentLoaded 事件在所有的子资源加载完发生,在第二步之后,第三步之前
五、页面静态资源
总体原则
-
减少不必要的请求
TCP/IP 的拥塞控制也使其传输有慢启动(slow start)的特点,速度会慢慢变快。因此,发送过多的“小”请求可能也不是一个很好的做法
-
减少包体大小
-
降低应用资源时的消耗
一段 CPU 密集的计算,或者进行频繁的 DOM 操作
-
利用缓存
CSS、JS 对页面加载与交互的影响
1)CSS 与 HTML
- link 标签放在 head 标签中,CSS 的加载,不会阻塞 HTML 的解析(HTML解析完会触发DOMContentLoaded 事件,所有依赖资源加载完才触发 load 事件,然后进行样式计算、布局、绘制、合成图层)
- link 标签放在 body 标签底部,CSS 的加载,不会阻塞页面内容的呈现,但是页面没有样式。加载完解析后会发生一次页面跳动,渲染出样式。
- link 标签放在 2个 div 中间,第一个 div 先展示,但是没样式。css 加载解析,第二个 div 显示,随后两个 div 都有了样式
2)JS 与 HTML
- 内联 JS 放在 head 标签中,执行,阻塞 HTML 解析
- 内联 JS 放在 body 标签中,执行,阻塞 HTML 解析,已解析的正常显示
- 外部 JS 放在 head 标签中,加载,阻塞 HTML 解析
- 外部 JS 放在 body 标签中,加载,阻塞 HTML 解析,已解析的正常显示
3)JS 与 CSS
- 如果
JavaScript
1.减少不必要的请求
1)代码拆分(code split)与按需加载
document.getElementById('btn').addEventListener('click', e => {
// 在这里加载 chat 组件相关资源 chat.js
const script = document.createElement('script');
script.src = '/static/js/chat.js';
document.getElementsByTagName('head')[0].appendChild(script);
});
比如点击之后再加载
webpack 通过 dynamic import 去做代码拆分
2)代码合并
利用打包工具,减少请求
2.减少包体大小
1)代码压缩
UglifyJS、gzip
2)Tree Shaking
与传统 DCE(dead code elimination)不太一样,传统 DCE :不可能执行的代码
代码不会被执行,不可到达
代码执行的结果不会被用到
代码只会影响死变量(只写不读)
uglify 做 JS 的 DCE 时,更关注没有用到的代码,而这个功能依赖于 ES6 module 的静态规范,所有依赖可以在编译期确定
ES6模块 和 CommonJS 区别
- CommonJS:引入基础数据类型时,属于复制该变量。引入复杂数据类型时,浅拷贝该对象。 模块默认 export 的是一个对象,即使导出的是基础数据类型
- ES6:不管是基础(复杂)数据类型,都只是对该变量的动态只读引用。只读表示不能修改变量值,复杂数据类型可以添加属性方法,不允许更改内存空间
3)优化 polyfill 的使用
使用 browserslist 告诉其他插件,项目支持的浏览器兼容范围
4)webpack
npm install --save-dev webpack-bundle-analyzer
查看包的体积大小
3.解析与执行
1)解析耗时
通过删除不必要的代码也有利于解析
2) 避免 Long Task
一般认为每个任务超过50ms执行就是长任务,阻塞主线程。
解决:web worker 或者 时间分片
3)是否真的需要框架
一些落地页、静态页没必要使用框架
4.缓存
1)发布与部署:非覆盖式发布----文件名中包含文件内容的 Hash,内容修改后,文件名就会变化;同时,设置不对页面进行强缓存,这样静态资源由于 uri 变了,肯定不会走缓存,而没有变动的资源则仍然可以使用缓存
2)将基础库、公共库代码单独打包
基础库被单独打包,即使业务代码经常变动,也不会导致整个缓存失效
webpack v4.x中使用 `optimization.splitChunks
3)减少 webpack 编译不当带来的缓存失效
使用 Hash 来替代自增 ID
每个模块 webpack 都会分配一个唯一的模块 ID,一般情况下 webpack 会使用自增 ID
- 由于增/删了新的其他模块,导致后续所有的模块 ID 都变更了,文件 MD5 也就变化了
- webpack 的入口文件除了包含它的 runtime、业务模块代码,同时还有一个用于异步加载的小型 manifest,任何一个模块的变化,最后必然会传导到入口文件
将 runtime chunk 单独拆分出来
通过
optimization.runtimeChunk把包含 manifest 的 runtime 部分单独分离出来
使用 records
通过 recordsPath 配置让 webpack 产出一个包含模块信息记录的 JSON 文件,其中包含了一些模块标识的信息,可以用于之后的编译。尽量避免破坏缓存
// webpack.config.js module.exports = { //... recordsPath: path.join(__dirname, 'records.json') };
CSS
1.关键 CSS
将关键 CSS 的内容通过
骨架屏是这种思路的一个延展,先返回不包含实际功能的静态页面
2.优化资源请求
1)按需加载
2)合并文件
3)请求的优先级排序
浏览器中的各类请求是有优先级排序的
link 标签上其实有一个 media 属性来处理媒体查询下的加载优先级
<link rel="stylesheet" href="navigator.css" media="all" />
<link rel="stylesheet" href="list.css" media="all" />
<link rel="stylesheet" href="navigator.small.css" media="(max-width: 500px)" />
<link rel="stylesheet" href="list.small.css" media="(max-width: 500px)" />
页面大于 500 px 时,优先级会降低,它们也不再会阻塞页面的渲染,但不是不加载
4)慎用 @import
5)监控类脚本位置
应该放到 css 前面,否则会被 css 阻塞加载,变成串行
3.减少包体大小
1)压缩:本地与网络
2)合适的兼容性:配合 browserslist 添加后缀
4.解析与渲染树构建
1)简化选择器
避免过多的嵌套与复杂度
2)使用先进的布局方式
新版的 flex 性能更好
5.利用缓存
使用 css-loader 和 style-loader,会导致耦合在 JavaScript 代码中,通过运行时添加 style 标签注入页面。更好的做法是使用 MiniCssExtractPlugin 插件
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
module.exports = {
plugins: [
new MiniCssExtractPlugin({
filename: '[contenthash:8].css',
chunkFilename: '[contenthash:8].css'
}),
],
module: {
rules: [{
test: /\.css$/,
use: [
MiniCssExtractPlugin.loader,
'css-loader'
]
}]
}
};
图片
1.优化请求数
1)雪碧图
background-url 设置为统一大图,background-position 定位自己
2)懒加载
function loadIfNeeded($img) {
const bounding = $img.getBoundingClientRect();
if (
getComputedStyle($img).display !== 'none'
&& bounding.top <= window.innerHeight
&& bounding.bottom >= 0
) {
$img.src = $img.dataset.src;
$img.classList.remove('lazy');
}
}
// 这里使用了 throttle,你可以实现自己的 throttle,也可以使用 lodash
const lazy = throttle(function () {
const $imgList = document.querySelectorAll('.lazy');
if ($imgList.length === 0) {
document.removeEventListener('scroll', lazy);
window.removeEventListener('resize', lazy);
window.removeEventListener('orientationchange', lazy);
return;
}
$imgList.forEach(loadIfNeeded);
}, 200);
document.addEventListener('scroll', lazy);
window.addEventListener('resize', lazy);
window.addEventListener('orientationchange', lazy);
注意点:
- 设置合理的占位图,避免图片加载后的页面“抖动”。
- 首屏可以不需要懒加载
3) CSS 中的图片懒加载
.login {
background-url: url(/static/img/login.png);
}
如果不应用到具体的元素,浏览器不会去下载该图片。可以通过切换 className 实现懒加载
2. 减小图片大小
1)使用 WebP,有损无损都会优于 jpeg/png,兼容性写法
<picture>
<source type="image/webp" srcset="/static/img/perf.webp">
<source type="image/jpeg" srcset="/static/img/perf.jpg">
<img src="/static/img/perf.jpg">
</picture>
2)使用 SVG 应对矢量图场景,有时也会更小
3)使用 video 替代 GIF,相同效果,GIF 比视频(MPEG-4)大 5~20 倍
<video autoplay loop muted playsinline>
<source src="video.webm" type="video/webm">
<source src="video.mp4" type="video/mp4">
<img src="animated.gif">
</video>
4)渐进式 JPEG
5)压缩图片(imagemin-webpack-plugin)
6)选择合适的图片(srcset、sizes)
带w的是宽度描述符,x是像素描述符,sizes只对前者有用
<img srcset="small.jpg 480w, large.jpg 1080w" sizes="50w" src="large.jpg" >
7)删除图片中的元信息
字体
1)font-display(设置 font-display: swap 防止网络加载时字体不显示FOIT (Flash of Invisible Text),先使用默认字体)
@font-face {
font-family: 'Samplefont';
src: url(/static/samplefont.woff2) format('woff2'),
url(/static/samplefont.woff) format('woff');
font-display: swap;
}
2) Font Face Observer(利用这个库在js中加载字体)
视频
1)使用合适的视频格式(webm体积小)
2)压缩
3)移除不必要的音轨(做 gif 时)
4)使用‘流’
HLS (HTTP Live Streaming) 技术(一个 .m3u8 的索引文件和一系列包含播放内容的 .ts 分片),浏览器通过不断下载一小段的分片来进行视频播放,避免了完整视频下载的流量消耗。
5)移除不必要的视频(小屏媒体查询隐藏视频)
六、运行时
1. 注意强制同步布局
1)什么是强制同步布局
var $ele = document.getElementById('main');
$ele.classList.remove('large');
var height = $ele.offsetHeight;
移除类名之后,马上获取元素高度。浏览器为了保证高度值正确,浏览器会立即进行布局。
解决:应该交换第二、三行
2)批量化 dom 操作,有一个库 fastDom
2.长列表优化
1)虚拟列表
核心思想:只渲染可见区域附近的列表元素
好处:不会频繁的 DOM 创建与销毁,只修改内部节点与内容,利用创建合成层也可以提高性能
大致思路:
- 监听页面滚动(或者其他导致视口变化的事件);
- 滚动时根据滚动的距离计算需要展示的列表项;
- 将列表项中展示的数据与组件替换成当前需要展示的内容;
- 修改偏移量到对应的位置。(可以修改top值或者父元素padding,方案很多)
2)原生的 Virtual Scroller(暂时不建议生产环境使用)
3. 避免 JavaScript 运行时间过长
渲染进程主线程既要负责渲染又要负责 js 解析
1)任务分解
document.body.innerHTML = '';
for(var i = 0; i < 1e9; i++) {1+1}
上述代码会被阻塞导致页面不会立马被清空
使用 requestAnimationFrame 把任务分解,每次渲染帧之前做一个子任务
document.body.innerHTML = '';
let step = 0;
function subtask() {
if (step === 1e9) { return; }
window.requestAnimationFrame(function () {
for(var i = 0; i < 1e8; i++) {step++; 1+1}
subtask();
});
}
subtask();
2)延迟执行
使用的 requestIdleCallback ,在空闲时间执行回调函数
window.requestIdleCallback(deadline => {
if (deadline.timeRemaining() > 100) {// 剩余的空闲时间大于 100ms
// 一些可以等浏览器空闲了再去做的事
}
}, {timeout: 5000}) // 超时5s强制执行
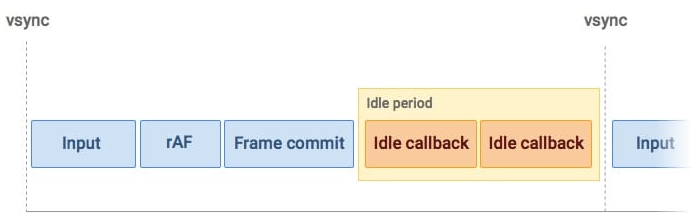
或者使用 setTimeout
3)并行计算
使用 Web Worker
4.善用 Composite
1)部分样式使用后会有自己单独的渲染层:
- 根元素(HTML)
- 有明确的定位属性(relative、fixed、sticky、absolute)
- 透明的(opacity 小于 1)
- 有 CSS 滤镜(fliter)
- 有 CSS mix-blend-mode 属性(不为 normal)
- 有 CSS transform 属性(不为 none)
- 当前有对于 opacity、transform、fliter、backdrop-filter 应用动画
- overflow 不为 visible
某些特殊的渲染层会被认为是合成层,有一个 GraphicsContex,负责输出该层的位图,位图是存储在共享内存中,作为纹理上传到 GPU 中,最后由 GPU 将多个位图进行合成。
2)提升成合成层部分方法(前提是已经有单独渲染层):
- video 元素及视频控制栏
- 3D 或者 硬件加速的 2D Canvas 元素(2D的没有)
- 在 DPI 较高的屏幕上,fix 定位的元素。(DPI 较低的不行,渲染层的提升会使得字体渲染方式由子像素变为灰阶,抗锯齿效果变差)
- 3D transforms:translate3d、translateZ 等
- 设置了animation 或者 transition 的活动中的 transform、opacity
- 具有 will-change 属性
所以一般通过 transform: translateZ(0) 或者 will-change: xxx(兼容性问题)
3)好处:
- 合成层的位图,会交由 GPU 合成,比 CPU 处理要快;
- 当需要 repaint 时,只需要 repaint 本身,不会影响到其他的层;
- 对于 transform 和 opacity 效果,不会触发 layout 和 paint。
4)缺点:
层爆炸:由于隐式合成 或者 人为设置了太多层
隐式合成原因:
举例:
h1 与 1000个 li 都设置了 overflow: hidden 形成渲染层
h1设置了 animation ,同时是 transform ,循环运动,变成合成层。由于动态交叠不确定性,浏览器会把 1000 个 li 都提升为合成层,导致爆炸
元素的不经意的重叠也导致合成层的产生
解决方法:设置明确的合适的 z-index 或者 浏览器自带的层压缩
层压缩有些情况无法实施:
- video 元素、iframe 的渲染层
- 渲染层同合成层 有不同的具有 transform 或者 opacity 的祖先层
- 相对于合成层滚动的渲染层
5)优化建议
- 动画使用 transform 实现,避免改变 Left / top,由于和 Document 在同一个图形层导致不停的重绘
- 减少隐式合成,设置合适的 z-index
- 减少合成层大小:对于一些纯色图层来说,使用 width 和 height 属性减小合成层的物理尺寸,然后再用 transform: scale(…) 放大
5.滚动事件的性能优化
防抖 节流
6.Passive event listeners
移动端滚动时,有时候是触发点击而不是让用户继续滑动
下面的代码告诉浏览器不要做默认事件,但是可能后面的操作执行了200ms,浏览器就只能等着
div.addEventListener('touchstart', function (e) {
e.preventDefault();
// 做了一些操作……
}, true);
使用第三个属性告诉浏览器不用等待,直接滚动,代码不会阻止滚动
div.addEventListener('touchstart', function (e) {
// 做了一些操作……
}, {passive: true});
七、预加载
1.Resource Hints
一种预加载相关的标准,包括 DNS Prefetch、Preconnect、Prefetch 与 Prerender,还有一个与 Resource Hints 类似的 Preload
1)Prefetch(as 指定文件类型,只提前加载,不会预处理)
<link rel="prefetch" href="/prefetch.js" as="script">
2)Prerender(提前加载,预处理)
<link rel="prerender" href="//sample.com/nextpage.html">
3)Preload(和 Prefetch 差不多,区别在于该请求优先级较高,建议对一些当前页面会马上用到资源使用 Preload)
<link rel="preload" href="./nextpage.js" as="script">
4)webpack 中的使用方式
只需要在 dynamic import 中添加相应注释
// prefetch
import(/* webpackPrefetch: true */ './sub1.js');
// preload
import(/* webpackPreload: true */ './sub2.js')
2.基于 JavaScript 的预加载
上面的像是声明式技术,也可以使用 js 显示加载(可用 PreloadJs 库)
let img = new Image();
img.src = '/static/img/prefetch.jpg';
3.视频预加载
1)添加 preload 属性
一种推荐的方式是设置 poster 与 preload: meta。poster 规定下载时显示的图像,后者只加载一定的元数据
2)使用 Preload Link
<link rel="preload" as="video" href="/static/sample.mp4">
3)通过 range 请求头先获取一小段视频数据
<video id="video" controls></video>
<script>
const mediaSource = new MediaSource();
video.src = URL.createObjectURL(mediaSource);
mediaSource.addEventListener('sourceopen', sourceOpen, { once: true });
function sourceOpen() {
URL.revokeObjectURL(video.src);
const sourceBuffer = mediaSource.addSourceBuffer('video/webm; codecs="vp09.00.10.08"');
// Fetch beginning of the video by setting the Range HTTP request header.
fetch('file.webm', { headers: { range: 'bytes=0-567139' } })
.then(response => response.arrayBuffer())
.then(data => {
sourceBuffer.appendBuffer(data);
sourceBuffer.addEventListener('updateend', updateEnd, { once: true });
});
}
function updateEnd() {
// Video is now ready to play! 缓存了多少秒
var bufferedSeconds = video.buffered.end(0) - video.buffered.start(0);
// Fetch the next segment of video when user starts playing the video.
video.addEventListener('playing', fetchNextSegment, { once: true });
}
function fetchNextSegment() {
fetch('file.webm', { headers: { range: 'bytes=567140-1196488' } })
.then(response => response.arrayBuffer())
.then(data => {
const sourceBuffer = mediaSource.sourceBuffers[0];
sourceBuffer.appendBuffer(data);
// TODO: Fetch further segment and append it.
});
}
</script>
4.预加载策略
1)quicklink(策略其实非常直接,核心就是当链接进入到视口后,会对其进行预加载)
2)Guess.js
八、监控
1.Lab data:例如在本地 CI/CD 时加入 lighthouse
2.Field data:也叫做 RUM (Real User Monitoring),采集线上数据,比较难调试与复现
CI:持续集成(CONTINUOUS INTEGRATION)合并到主干前自动化测试并交付
CD:持续交付(CONTINUOUS DELIVERY)自动化的发布流,部署需手动批准
CD:持续部署(CONTINUOUS DEPLOYMENT)全自动部署
11、重排、重绘
重绘不一定导致重排,但重排一定会导致重绘。
一、重排
定义:重排也叫回流,简单的说就是重新生成布局,重新排列元素。、
触发重排的因素:大小、位置改变、页面的第一次渲染(不用记具体属性)
范围:全局影响 或者 局部影响
优化建议:
1.减少重排范围
1)改变样式尽量不要通过父元素
2)不要使用 table 布局,一个小改动影响整个 table
2.减少重排次数
1)样式集中改变
统一在 cssText 变量中编辑,或者使用 class。虽然大部分现代浏览器都会有 Flush 队列进行渲染队列优化
var left = 10;
var top = 10;
// bad
el.style.left = left + "px";
el.style.top = top + "px";
el.style.cssText += "; left: " + left + "px; top: " + top + "px;"; // better
el.className += " className"; // better
2)分离读写操作(统一读取,统一赋值)
// bad 强制刷新 触发四次重排+重绘
div.style.left = div.offsetLeft + 1 + 'px';
div.style.top = div.offsetTop + 1 + 'px';
div.style.right = div.offsetRight + 1 + 'px';
div.style.bottom = div.offsetBottom + 1 + 'px';
// good 缓存布局信息 相当于读写分离 触发一次重排+重绘
var curLeft = div.offsetLeft;
var curTop = div.offsetTop;
var curRight = div.offsetRight;
var curBottom = div.offsetBottom;
div.style.left = curLeft + 1 + 'px';
div.style.top = curTop + 1 + 'px';
div.style.right = curRight + 1 + 'px';
div.style.bottom = curBottom + 1 + 'px';
从 4 次重排变为 1 次,得益于浏览器的渲染队列机制
它会把重排或者重绘操作放进渲染队列,等到队列中的操作到了一定的数量或者到了一定的时间间隔时,浏览器就会批量执行这些操作。
3)将 DOM 离线
- 使用 display:none,然后进行大量变更,再显示。触发两次重排重绘
- 通过 documentFragment 创建一个 dom 碎片,变化不会触发重新渲染
4)使用 absolute 或 fixed 脱离文档流
5)优化动画
- 外层元素添加属性成为单独的渲染层
- 启用 GPU 加速(提升成合成层)
二、重绘
定义:没有改变布局,外观发生改变
三、浏览器中查看页面渲染时间
Performance 录制,圆饼图可以看到各个阶段的时间,点击 EventLog 可以看到详细的每个步骤的时间
12、白屏
一、一些 Web 性能术语
FP(First Paint,首次绘制)
屏幕上首次发生视觉变化的时间
FCP(First Contentful Paint,首次内容绘制)
首次绘制文本、图片(包含背景图)、非白色的canvas或SVG
FMP(First Meaningful Paint,首次有效绘制)
“主要内容”开始出现在屏幕上的时间点。是我们测量用户加载体验的主要指标
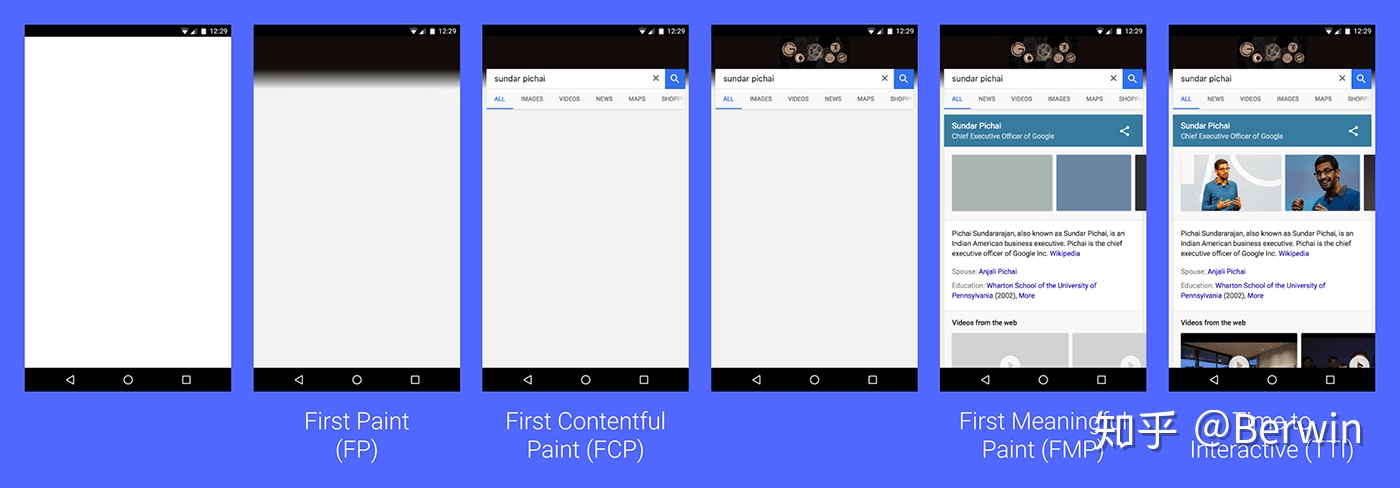
LCP(Largest Contentful Paint,最大内容绘制)
可视区“内容”最大的可见元素开始出现在屏幕上的时间点。
站在用户的角度,FMP 与 LCP 可以表示我们的产品需要多久才能体现出价值。
TTI(Time to Interactive,可交互时间)
网页第一次 完全达到可交互状态 的时间点。主线程的任务均不超过50毫秒
FCI(First CPU Idle,第一次 CPU 空闲,也就是主线程空闲)
对TTI的一种补充,最小可交互时间。FCI 代表浏览器真正的第一次可以响应用户的输入,而 TTI 代表浏览器已经可以持续性的响应用户的输入。
FID(First Input Delay,首次输入延迟)
用户如果在 TTI 之前交互,那么 FID 就高。如果是之后,FID 就短,代表用户真实线上数据。可以使用 web-vitals 测试
TTFB(Time to First Byte)
浏览器接收第一个字节的时间
DCL (DomContentloaded事件触发的时间,HTML 解析完)
L (onLoad事件触发的时间,所有资源加载完)
博客文章更侧重FMP(用户希望尽快看到有价值的内容),后台管理系统或在线 PPT 更侧重TTI(用户希望尽快与产品进行交互)
二、优化手段同第十点(也是从页面展示的各个阶段思考)
13、大量图片加载优化
问题一:启动页面时加载过多图片
对于 Vue 项目,延迟加载,给需要立即加载的图片给一个标识
在自定义指令的 bind 中,如果是立即加载的就发请求,返回的 promise 保存在一个数组中。如果是首屏可见但设置了延迟加载,优先级提高(利用 getBoundingClientRect 与 window.innerHeight 作对比),也立即发请求。
如果是设置了延时请求的图片,则在下一个 Tick 用 Promise.all 判断数组中所有 promise 是否完成,完成了清空数组,加载图片。
为什么不直接使用 getBoundingClientRect,因为只有当 DOM 元素插入到 DOM 树中,并且页面进行重排和重绘后,我们才能够知道该元素是否在首屏中,这里有延时
扩展方案:域名切分,提升并发数、HTTP/2 协议
问题二:部分图片体积过大
一张图片的文件大小 = 图片总像素数目 * 编码单位像素所需字节数
单位像素优化
1)「有损」的删除一些像素数据
2)「无损」的图片像素压缩
某些压缩算法:一张图片中的某一个像素点和其周围的像素点很接近,就只记录像素间的差值。
几种图片格式优劣:
jpeg 和 png 不支持动画效果
jpeg 图片体积小但是不支持透明度
WebP 格式和 jpeg 格式相比,其体积更减少 30%,同时还支持动画和透明度
图片像素总数优化
不同设备使用合适的图片。viewport 方案,flexible 方案已经过时
- 使用 vw 来实现页面的适配,并且通过 PostCSS 的插件 postcss-px-to-viewport 把 px 转换成 vw。
- 为了更好的实现长宽比,特别是针对于img、vedio和iframe元素,通过PostCSS插件postcss-aspect-ratio-mini
- 为了解决1px的问题,使用 PostCSS 插件 postcss-write-svg,自动生成 border-image 或者background-image 的图片
14、从 URL 输入到页面展现到底发生了什么?
一、键盘或触屏输入 URL 并回车确认
后端:通过 nohup 或者 PM2 启动服务器(Nginx)的守护进程,定位到服务器上 www 文件夹(网站根目录),通过 Node 监听 80/443 端口收到的请求。
前端:浏览器——CPU——操作系统内核——操作系统GUI——浏览器
“守护进程”(daemon)就是一直在后台运行的进程
nohup 命令对 server.js 进程的处理
- 阻止 SIGHUP 信号发到这个进程
- 关闭标准输入
- 重定向标准输出和标准错误到文件nohup.out
- nohup 命令不会自动把进程变为"后台任务",所以必须加上 & 符号(只要在命令的尾部加上符号&,启动的进程就会成为"后台任务")
在敲回车前,浏览器已经在做一些预处理(智能匹配可能的 URL 给出提示,提前建立 TCP 连接)
二、URL 解析/DNS 查询
浏览器:
- 判断协议。是 http/https 就按照 Web 来处理
- 安全检查
- 判断域名还是 IP,对域名进行解析
两种 DNS 解析方式
递归查询
- 浏览器缓存
- 系统缓存(hosts 文件,安全隐患,会被病毒修改 hosts 文件指向恶意 IP)
- 路由器缓存
- ISP DNS 缓存(本地域名服务器,与运营商有关,如电信、联通,或者通用的114.114.114.114)
- 根名称服务器——顶级名称服务器——二级名称服务器——权威名称服务器
默认使用递归查询,有两种情况会改变:
- DNS 请求报头部的 RD 字段没有置 1
- 所配置的本地名称服务器上是禁用递归查询(即在应答 DNS 报文头部的 RA 字段置 0)
Recursion Desired Recursion Available
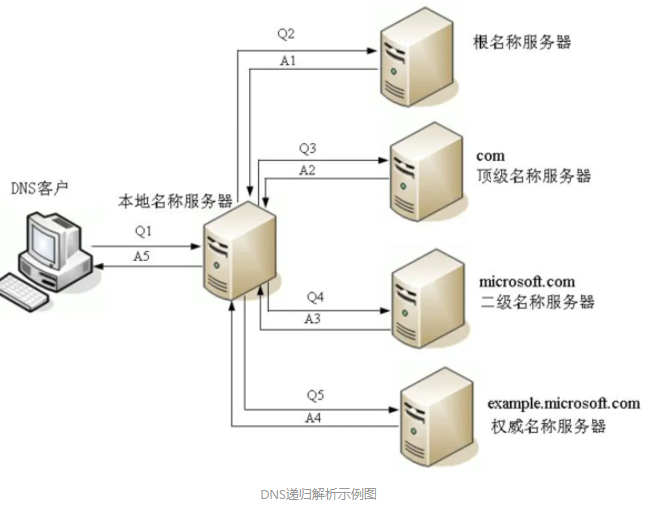
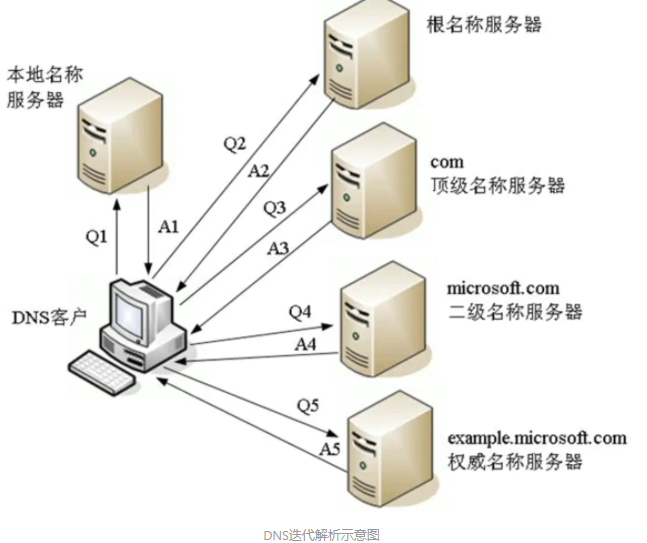
迭代查询
1、2、3、4步相同
后面步骤不同点在于,每次都是由 DNS 客户端发送同样的请求给不同的域名服务器
三、应用层客户端发送 HTTP 请求
TCP/IP 协议分为 4 层:应用层、【表示层、会话层】、传输层、网络层、数据链路层、【物理层】
请求分为:请求报头、请求主体(get 是查询字符串,post 是 body)
HTTP/1.1 200 OK
Server: Tengine
Date: Mon, 09 Aug 2021 08:14:19 GMT
Content-Type: image/gif
Content-Length: 43
Connection: keep-alive
Last-Modified: Mon, 28 Sep 1970 06:00:00 GMT
Access-Control-Allow-Origin: *
Cache-Control: no-cache, no-store, must-revalidate
Pragma: no-cache
Expires: Mon, 28 Sep 1970 05:00:00 GMT
发送请求流程(总)
-
应用程序处理
对数据进行编码处理,相当于 OSI 的表示层
编码后不一定马上发送,这种控制时间的管理功能,相当于 OSI 的会话层
-
TCP 模块的处理
根据应用的指示,建立连接、发送数据以及断开连接,在应用层数据前端附加 TCP 首部
-
IP 模块的处理
在 TCP 传过来的数据前端加上自己的 IP 首部,参考路由控制表决定接受此 IP 包的路由或主机
-
网络接口(以太网驱动)的处理
给数据附加上以太网首部,发送给接收端
HTTP 的连接管理模型
短连接
每一个 HTTP 请求之前都会有一次 TCP 握手,而且是连续不断的。
这是 HTTP/1.0 的默认模型,HTTP/1.1 中,只有当 Connection 被设置为 close 时才会用到这个模型
长连接(keep-alive 连接)
发送完请求后不关闭,节省了新建 TCP 连接握手的时间(HTTP 流水线),服务器可以使用 Keep-Alive 协议头来指定一个最小的连接保持时间。
不使用流水线:客户端必须要等前一个请求的响应返回,新的请求才能发过去
HTTP 流水线(pipeling)
同一条长连接上发出连续的请求,而不用等待应答返回。
好处:避免连接延迟、性能还会因为两个 HTTP 请求可能被打包到一个 TCP 消息包中得到提升
缺点:1. 一些代理服务器不能正确处理。2. 复杂场景太多:资源大小、有效带宽、影响范围、重要消息可能延后,导致带来的改善并不明显。3. Head-of-line Blocking 连接头阻塞问题:RFC 2616规定服务器必须按照请求收到的顺序发送响应,前面的请求处理过慢会堵塞后面的请求响应
局限:只有 idempotent 方式(幂等:多次执行结果相同),比如 GET、HEAD、PUT 和 DELETE。浏览器默认不启用
对比 HTTP2.0多路复用:后者是基于流,无论请求还是响应,只要逻辑上允许就可以传输,如果两个请求没有依赖关系,响应的返回也不分先后顺序,不堵塞
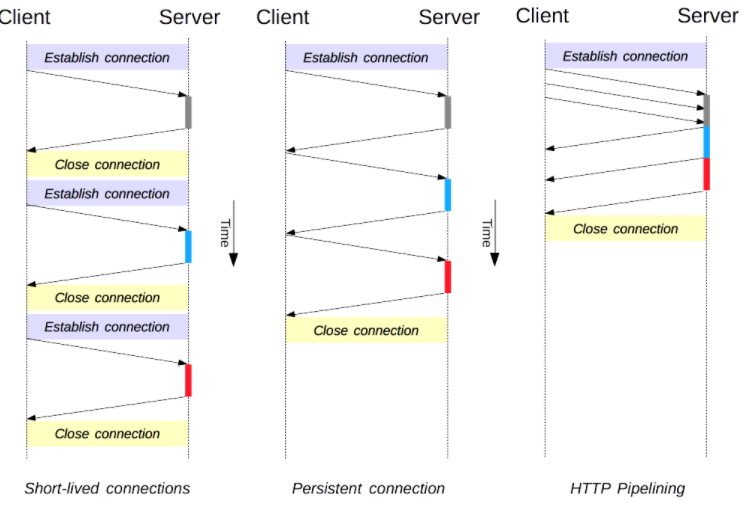
HTTP 2.0
1)二进制分帧:请求头封装成帧头(headers frame),请求主体封装成帧体 data frame
HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码
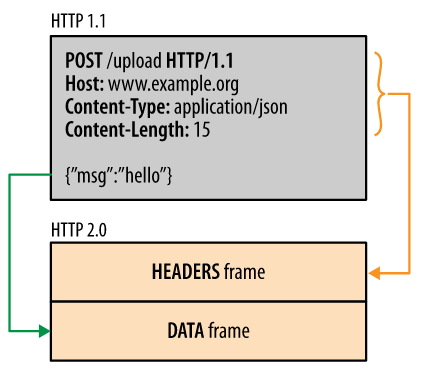
2)数据流:一个 TCP 连接可以有多条,承载一条或多条消息的双向字节流
消息:表示请求与响应的完整的一系列帧
帧:最小单位,每个帧都有帧头,至少包含当前帧所属的数据流
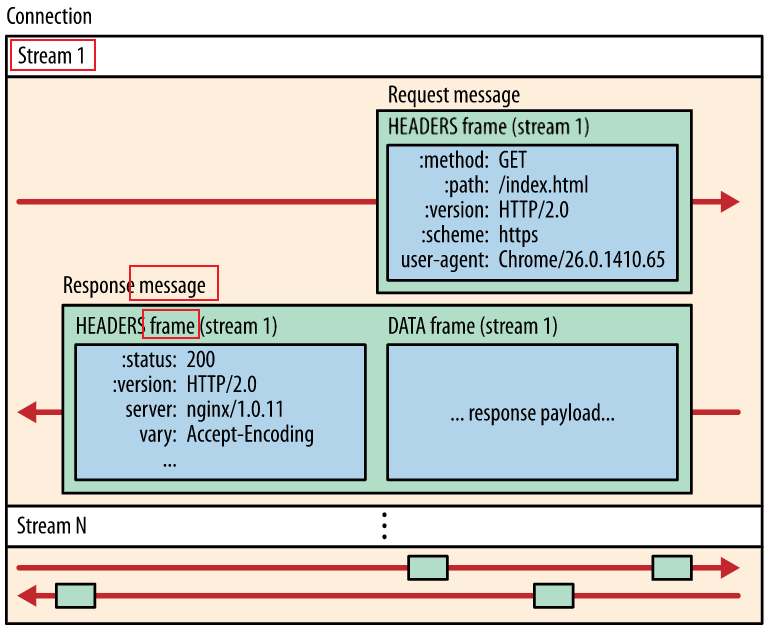
3)请求与响应复用(多路复用)
原理:客户端和服务器可以将 HTTP 消息分解为互不依赖的帧,然后交错发送,最后再在另一端把它们重新组装起来
好处:并行交错发送多个请求或响应、不必再做很多优化(雪碧图、域名分片)、消除不必要的延迟…
4)数据流优先级:向每个数据流分配一个介于 1 至 256 之间的整数,根据数字的比例分配资源,同时如果写明 B&C 数据流依赖 A,则先处理 A,再分配 B、C
5)每个来源一个连接搞定
6)流控制:阻止发送方向接收方发送大量数据的机制,以免超出后者的需求或处理能力。比如用户暂停视频之后,停止缓冲。HTTP2.0 的流控制与 TCP 的流控制不一样,提供了构建快给服务器和客户端自定义
7)服务器推送
8)标头压缩:通过静态霍夫曼代码对传输的标头字段进行编码,减少大小。客户端和服务器同时维护和更新一个包含之前见过的标头字段的索引列表,后续只编码索引即可找到键值对
域名分片
已经过时的技术(MDN),建议升级到 HTTP/2
创建多个子域名,www1.example.com、www2.example.com 来接受请求,每个域名都能同时建立6条连接
四、传输层 TCP 传输报文
TCP 和 UDP 的比较
TCP 是面向连接的、可靠的全双工(数据同时双向传播)流协议。实行“顺序控制”或“重发控制”机制,具备"流量控制"、“拥塞控制”、提高网络利用率等功能。
UDP 是不可靠的无连接的数据报协议。可以确保发送消息的大小,不能保证消息一定会到达与顺序
TCP 三次握手过程
- A 向 B 发送一个含有同步序列号(seq=j)的标志位(SYN=1)的数据段,请求建立连接
- B 收到 A 的请求后,用一个带有确认应答(ack=j+1)和同步序列号(seq=k)标志位(SYN=1,ACK=1)的数据段响应 A
- A 收到这个数据段后,检查 ack 是否为 J+1 ,ACK 是否为1。正确则发送一个确认应答,其中 ack = K+1,ACK 标志位=1
翻译:
- A:我要连接你了
- B:OK,什么时候给我发
- A:现在开始发
特点:
没有应用层的数据,SYN 这个标志位只有在 TCP 建立连接时才会被置1 ,握手完成后 SYN 标志位被置0。
TCP 四次挥手
- A 完成数据传输,控制位 FIN=1,提出关闭请求
- B 发送 ACK =1 ,表示收到消息,但是数据可能还没接受完,所以请等待
- B 发送 FIN =1,数据接收完毕,发送关闭请求
- A 发送 ACK = 1,A端关闭,B 收到后也同时关闭
名词
SYN TCP建立连接时为1,ACK =1和 FIN=1 都表示数据已收到
五、网络层 IP 协议查询 MAC 地址
IP 协议给 TCP 协议传过来的数据加上 IP 首部,ARP 协议可以将 IP 地址解析成对应的 MAC 地址(物理地址)。
IP 地址同一网络内唯一,MAC 地址全球唯一
六、 数据到达数据链路层
找到对方的 MAC 地址后,已被封装好的 IP 包再被封装到数据链路层的数据帧结构中,将数据发送到数据链路层传输,再通过物理层的比特流送出去,客户端结束
七、 服务器接收数据
服务器在链路层接收到数据包,再层层向上直到应用层,每层都会拆包,重新组成 HTTP 请求报文
八、服务器响应请求并返回相应文件
http 监听进程得到这个请求后,一般启动一个新的子进程去处理请求,父进程继续监听。如果是文件,则直接返回,如果是动态请求则调用响应的函数,读写 DB 数据,最后把正文加上一个响应头封装成 HTTP 响应包,通过 TCP IP 送回
九、浏览器开始处理数据信息并渲染页面
1)根据返回的状态码,判断是 200 直接渲染界面,还是 300 开头重定向,或者 400 500 报错之类
2)当得到200后,面临的是多国语言的编码解析,响应头是一个 ascii 的标准字符集的文本好办,但是响应的正文本质上就是一个字节流。首先浏览器会去看响应头里面指定的 encoding 域,如果有,那么就按照指定的 encoding 去解析字符,如果没有,浏览器会使用比较智能的方式,去猜测和判断这一坨字节流应该使用什么字符集去解码
3)解析 HTML 构建 dom 树,遇到内联脚本就执行(阻塞主线程),内联样式会先保存,外联 JS 分情况(不写 async 和 defer 的就直接加载并执行,阻塞主线程),外联 CSS 加载(不阻塞)。有图片啥的就直接请求
4)根据 dom 树和 css 构建的 cssom 树 合成 render 树
十、将渲染好的页面图像显示出来,并开始响应用户的操作。
从内存到 LCD/LED,再由光线进入人眼
15、动画性能
总结:
- 精简DOM,合理布局
- 使用 transform 代替 left、top 减少使用引起页面重排的属性
- 开启硬件加速(提升为合成层)
- 尽量避免浏览器创建不必要的图形层
- 尽量减少 js 动画,如需要,使用对性能友好的 requestAnimationFrame
- 使用 chrome performance 工具调试动画性能
transform 的执行效率
<!-- 左图 -->
div { height: 100px; transition: height 1s linear; }
div:hover { height: 200px; }
<!-- 右图 -->
div { transform: scale(0.5); transition: transform 1s linear; }
div:hover { transform: scale(1.0); }
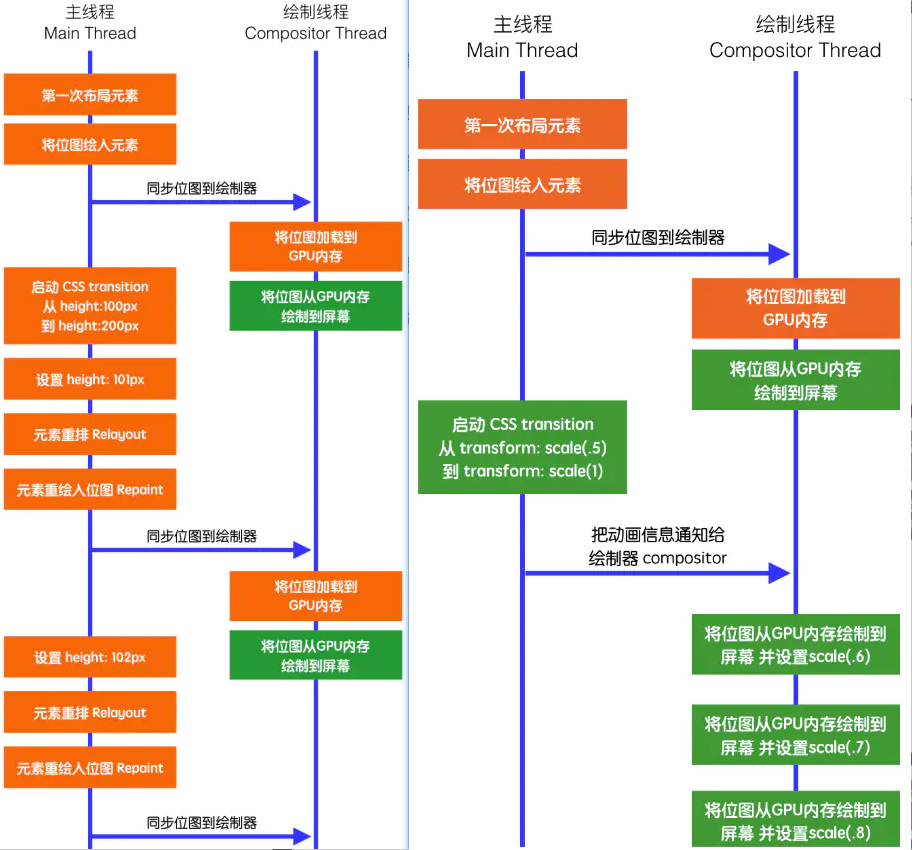
橙色表示性能消耗大,绿色较小。由于 transition 改变高度导致每一帧都会触发重排,渲染进程主线程就会堵塞,而 GPU 很擅长同一位图的位移、旋转等,所以很丝滑
16、渲染合成层
增量异步 reflow
有些情况下,浏览器并不会立刻 reflow 或 repaint ,而是会把这样的操作积攒一批,然后做一次 reflow。
层的概念
Chrome 中不同类型的层:某些特殊的渲染层(负责 DOM 子树)被提升为合成层(Compositing Layers),合成层拥有单独的图形层(GraphicsLayer,负责渲染层的子树),其中的 GraphicsContext 输出该层的位图,作为纹理(texture)上传给 GPU,GPU 将多个位图进行合成,显示到屏幕上
纹理:从主存储器(RAM)移动到图像存储器( GPU 中的 VRAM )的位图图像(bitmapimage)
Chrome 使用纹理从 GPU上获得大块的页面内容,将纹理应用到一个非常简单的矩形网格就能很容易匹配不同的位置(position)和变形(transformation)
好处:
-
合成层的位图,会交由 GPU 合成,比 CPU 处理快
-
需要 repaint 时,只需要 repaint 本身,不影响其他层
-
transform 和 opacity 不会触发 layout 和 paint
注意:GPU 只把绘图上下文的位图输出进行组合,绘图上下文的位图生成还是 CPU 执行
其他概念在性能优化手段中有分析
工程化
1、模块化机制
一、模块化的理解
什么是模块
- 复杂的程序依据规则封装成几个块,组合在一起
- 块的内部数据与实现是私有的, 只是向外部暴露一些接口通信
模块化的进化过程
-
全局 function 模式 : 将不同的功能封装成不同的全局函数
缺点:污染全局命名空间,模块成员之间看不出直接关系
-
namespace 模式 : 简单对象封装
缺点:数据不安全,可以直接被外部修改
-
IIFE 模式:匿名函数自调用(闭包)
好处:数据私有
缺点:当前模块无法引用其他模块
-
IIFE 模式增强 :引入依赖(现代模块实现的基石)
比原始 IIFE 多了一步,要引入的模块先放入参数中,html 引入文件时注意顺序
// module.js文件
(function(window, $) {
let data = 'yang.plus'
//操作数据的函数
function foo() {
$('body').css('background', 'red')
}
function bar() {
otherFun() //内部调用
}
//内部私有的函数
function otherFun() {
console.log('otherFun()')
}
//暴露行为
window.myModule = { foo, bar }
})(window, jQuery) // 直接引入需要的模块
模块化的好处
- 避免命名冲突(减少命名空间污染)
- 更好的分离, 按需加载
- 高复用性
- 高可维护性
引入多个
- 请求过多
- 依赖模糊(不知道具体的依赖关系,所以引入顺序容易弄混)
- 难以维护(模块多了容易乱)
所以需要模块化规范解决这些问题
二、模块化规范
CommonJS
1)概述
每个文件就是一个模块,有自己的作用域。
在服务器端,模块的加载是运行时同步加载的。
在浏览器端,模块需要提前编译打包处理
2)特点
- 所有代码都运行在模块作用域,不会污染全局作用域。
- 模块可以多次加载,但是只会在第一次加载时运行一次,然后运行结果就被缓存,以后加载直接读取缓存结果。要想让模块再次运行,必须清除缓存。
- 模块加载的顺序,按照其在代码中出现的顺序。
3)基本语法
- 暴露模块:module.exports = value 或 exports.xxx = value
- 引入模块:require(xxx)。如果是第三方模块,xxx为模块名。如果是自定义模块,xxx为模块文件路径
- 加载某个模块,其实就是加载模块的 module.exports 属性
4)模块的加载机制
输入的是被输出的值的拷贝,一旦输出一个值,模块内部的变化影响不到这个值
AMD
CommonJS 规范加载模块是同步的,浏览器端一般采用AMD规范(依赖注入思想)。
通过 requireJS 库来实现 AMD 规范(已不维护)
// 定义有依赖的模块,数组注入,回调中传入参数
define(['dataService'], function(dataService) {
let name = 'Tom'
function showMsg() {
alert(dataService.getMsg() + ', ' + name)
}
// 暴露模块
return { showMsg }
})
<body>
<!-- 引入require.js 并指定 js 主文件的入口 -->
<script data-main="js/main" src="js/libs/require.js"></script>
</body>
CMD
专门用于浏览器端,模块的加载是异步的,模块使用时才会加载执行,整合了CommonJS和AMD规范的特点
sea.js库(已不维护)
ES6 模块化
静态化,编译时就能确定模块的依赖关系,以及输入和输出的变量
1)ES6模块化语法
具名引入、导出,引入时有多个需要花括号
/** 定义模块 math.js **/
var basicNum = 0;
var add = function (a, b) {return a + b;};
export { basicNum, add };
/** 引用模块 **/
import { basicNum, add } from './math';
function test(ele) {ele.textContent = add(99 + basicNum);}
默认引入、导出,引入时可以随意取名
// export-default.js
export default function () {console.log('foo');}
// import-default.js
import customName from './export-default';
customName(); // 'foo'
2)ES6 模块与 CommonJS 模块的差异
① CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用。
② CommonJS 模块是运行时加载,ES6 模块是编译时输出接口。
因为 module.exports 属性只有在脚本运行完才会生成。ES6 模块则不是,对外接口是一种静态定义,解析阶段生成
三、总结
- CommonJS 规范主要用于服务端编程,加载模块是同步的,不适合在浏览器环境。因为同步意味着阻塞加载,浏览器资源是异步加载的,因此有了 AMD CMD 解决方案。
- AMD 规范在浏览器环境中异步加载模块,而且可以并行加载多个模块。不过,AMD 规范开发成本高,代码的阅读和书写比较困难,模块定义方式的语义不顺畅。
- CMD 规范与 AMD 规范很相似,都用于浏览器编程,依赖就近,延迟执行,可以很容易在Node.js 中运行。不过,依赖 SPM 打包(压缩、简单化命名),模块的加载逻辑偏重
- ES6 在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS 和 AMD 规范,成为浏览器和服务器通用的模块解决方案。
2、Tree-Shaking
基于 ES6 模块的静态分析机制,传统的 DCE 消灭不可能执行的代码,Tree-shaking 更关注消除没有用到的代码,uglify 完成了 javascript 的 DCE
sideEffects
package.json 中添加 sideEffects 属性,将其值设置为 false。告知 webpack,项目中都是 ”pure“(纯正 ES6 模块),可以安全地删除未用到的 export。
通过把值设置为包含路径的数组,告诉 webpack 哪些不能优化
usedExports
也是告诉 webpack 开启 tree shaking,没有 sideEffects 好,因为后者允许跳过整个模块
3、uglify 原理
JS 的代码压缩原理:
- 将 code 转换成AST
- 将 AST 进行优化,生成一个更小的 AST
- 将新生成的 AST 再转化成 code
babel,eslint,v8 的逻辑均与此类似
astexplorer 可以看具体的 ast 树内容
var UglifyJS = require('uglify-js'); // 2.x 版本
// 原始代码
var code = `var a;
var x = { b: 123 };
a = 123,
delete x`;
// 通过 UglifyJS 把代码解析为 AST
var ast = UglifyJS.parse(code);
ast.figure_out_scope();
// 转化为一颗更小的 AST 树
compressor = UglifyJS.Compressor();
ast = ast.transform(compressor);
// 再把 AST 转化为代码
code = ast.print_to_string();
// var a,x={b:123};a=123,delete x;
表达式有值,语句一般无值
4、Babel 原理
Babel 的处理流程
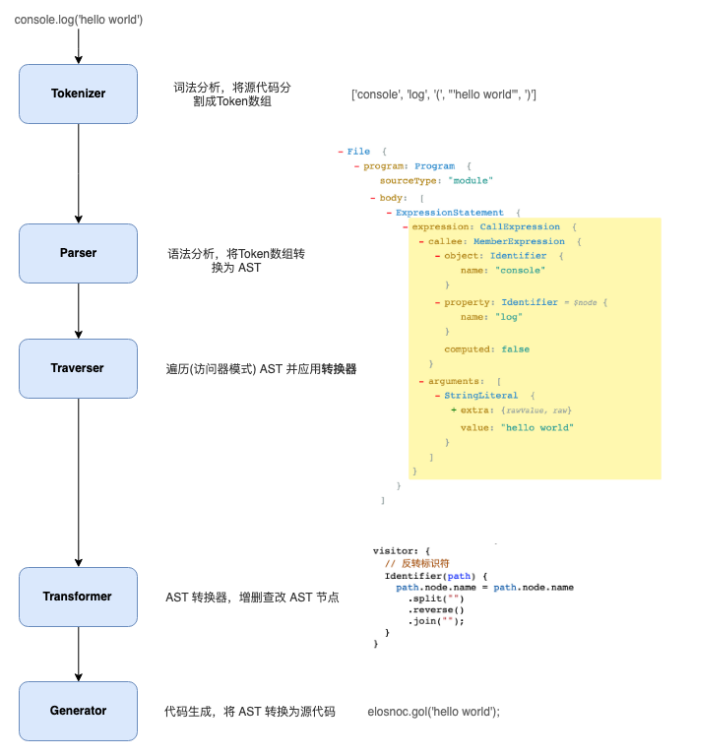
词法解析(Lexical Analysis)
将字符串形式的代码转换为 Tokens(令牌),Tokens 可以视作是一些语法片段组成的数组。
例如 for (const item of items) {} 的词法解析结果(AST、syntax、tokens网站)

还可以选择加入location(位置)、行号列号等信息
语法解析(Syntactic Analysis)
解析器 (Parser) 会把 Tokens 转换为抽象语法树 (Abstract Syntax Tree,AST)
console.log(‘hello world’) 会解析为

Program、CallExpression、Identifier 这些都是节点的类型,每个节点都是一个有意义的语法单元。 这些节点类型定义了一些属性来描述节点的信息
AST 是 Babel 转译的核心数据结构,后续的操作都依赖于 AST
转换(Transform)
转换阶段会对 AST 进行遍历,在这个过程中对节点进行增删查改。Babel 所有插件都是在这个阶段工作, 比如语法转换、代码压缩。
代码生成(Generator)
把 AST 转换回字符串形式的 Javascript,同时这个阶段还会生成 Source Map。
Babel 的架构
Babel 和 Webpack 为了适应复杂的定制需求和频繁的功能变化,都使用了微内核 的架构风格。它们的核心非常小,大部分功能都是通过插件扩展实现的
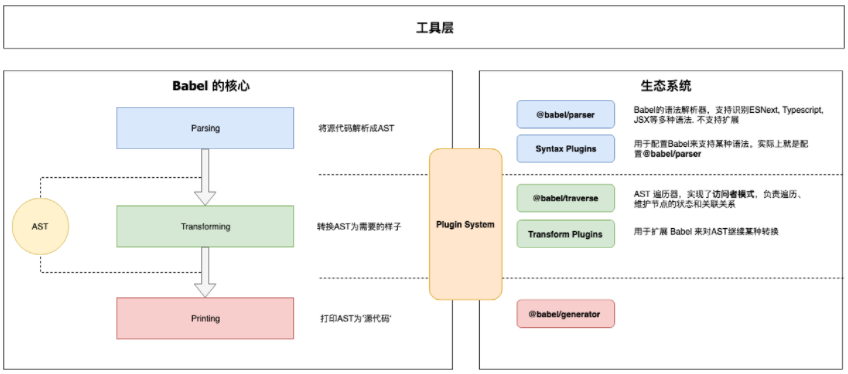
核心
@babel/core 这也是上面说的‘微内核’架构中的‘内核’,主要做:
- 加载和处理配置(config)
- 加载插件
- 调用 Parser 进行语法解析,生成 AST
- 调用 Traverser 遍历 AST,并使用访问者模式应用’插件’对 AST 进行转换
- 生成代码,包括 SourceMap 转换和源代码生成
核心周边支撑
- Parser(@babel/parser): 将源代码解析为 AST 就靠它。 内置支持很多语法. 例如 JSX、Typescript、Flow、以及最新的 ECMAScript 规范。目前为了执行效率,parser 是不支持扩展的,由官方进行维护。
- Traverser(@babel/traverse): 实现了访问者模式,对 AST 进行遍历,转换插件会通过它获取感兴趣的 AST 节点,对节点继续操作, 访问器模式。
- Generator(@babel/generator): 将 AST 转换为源代码,支持 SourceMap
插件
-
语法插件(@babel/plugin-syntax-):@babel/parser 已经支持很多 JavaScript 语法特性,Parser 也不支持扩展。因此 plugin-syntax- 实际上只是用于开启或者配置 Parser 的某个功能特性。
一般用户不需要关心这个,Transform 插件里面已经包含了相关的plugin-syntax-*插件了。用户也可以通过 parserOpts 配置项来直接配置 Parser
-
转换插件: 用于对 AST 进行转换, 实现转换为 ES5 代码、压缩、功能增强等目的。 Babel 仓库将转换插件划分为两种(只是命名上的区别):
- @babel/plugin-transform-*: 普通的转换插件
- @babel/plugin-proposal-*: 还在’提议阶段’(非正式)的语言特性, 目前有这些
-
预定义集合(@babel/presets-*): 插件集合或者分组,主要方便用户对插件进行管理和使用。比如 preset-env 含括所有的标准的最新特性; 再比如 preset-react 含括所有 react 相关的插件。
插件开发辅助
- @babel/template:将字符串代码转换为 AST,生成辅助代码(helper)时用到。
- @babel/types:AST 节点构造器和断言
- @babel/helper-*: 一些辅助器,用于辅助插件开发,例如简化AST操作
- @babel/helper: 辅助代码,单纯的语法转换可能无法让代码运行起来,比如低版本浏览器无法识别 class 关键字,这时候需要添加辅助代码,对 class 进行模拟。
工具
- @babel/node:直接运行需要 Babel 处理的 JavaScript 文件
- @babel/register: Patch NodeJs 的 require 方法,支持导入需要 Babel 处理的JavaScript 模块
访问者模式
Babel 有那么多插件,如果每个插件自己去遍历 AST,对不同的节点进行不同的操作,维护自己的状态。这样子不仅低效,它们的逻辑分散在各处,会让整个系统变得难以理解和调试。
转换器操作 AST 一般都是使用访问器模式
- 由访问者 (Visitor) 进行统一的深度优先遍历操作,提供节点的操作回调
- 插件(设计模式中称为‘具体访问者’)只需要定义自己感兴趣的节点类型,当访问者访问到对应节点时,就调用插件的访问 (visit) 方法
- 响应式维护节点之间的关系
Babel 会按照插件定义的顺序来应用访问方法,当注册多个插件时,babel-core 最后传递给访问器的数据结构大概长这样:
{
Identifier: {
enter: [plugin-xx, plugin-yy,] // 数组形式
}
}
当进入某个节点时,插件会按顺序被执行,只有少数情况需要注意定义顺序
节点上下文
访问者在访问一个节点时, 会无差别地调用 enter 方法
每个 visit 方法都接收一个 Path 对象(上下文对象),包含了很多信息:
- 当前节点信息
- 节点的关联信息。父节点、子节点、兄弟节点等等
- 作用域信息
- 上下文信息
- 节点操作方法。节点增删查改
- 断言方法。isXXX, assertXXX
副作用的处理
AST 转换本身是有副作用的,比如插件将旧的节点替换了,那么访问者就没有必要再向下访问旧节点了,而是继续访问新的节点
traverse(ast, {
ExpressionStatement(path) {
// 将 `console.log('hello' + v + '!')` 替换为 `return ‘hello’ + v`
const rtn = t.returnStatement(t.binaryExpression('+', t.stringLiteral('hello'), t.identifier('v')))
path.replaceWith(rtn)
},
}
当操作’污染’了 AST 树后,访问者需要记录这些状态,响应式(Reactive)更新 Path 对象的关联关系, 保证正确的遍历顺序,从而获得正确的转译结果
作用域的处理
AST 转换的前提是保证程序的正确性
在 Babel 中,使用 Scope 对象来表示作用域。我们可以通过 Path 对象的 scope 字段来获取当前节点的 Scope 对象,我们可以通过这些属性来判断修改 ast 时会不会造成父子作用域破坏性改变
{
path: NodePath;
block: Node; // 所属的词法区块节点, 例如函数节点、条件语句节点
parentBlock: Node; // 所属的父级词法区块节点
parent: Scope; // ⚛️指向父作用域
bindings: { [name: string]: Binding; }; // ⚛️ 该作用域下面的所有绑定(即该作用域创建的标识符/变量)
}
Scope 对象提供了一个 generateUid 方法来生成唯一的、不冲突的标识符
5、Webpack 构建流程
简单的 Webpack 构建过程:
- 根据配置,识别入口文件;
- 逐层识别模块依赖(包括 Commonjs、AMD、或 ES6 的 import 等,都会被识别和分析);
- Webpack 主要工作内容就是分析代码,转换代码,编译代码,最后输出代码;
- 输出最后打包后的代码。
Webpack 构建原理
-
初始化参数
解析 Webpack 配置参数,合并 Shell 传入和 webpack.config.js 文件配置的参数,形成最后的配置结果。
-
开始编译
上一步得到的参数初始化 compiler 对象,注册所有配置的插件,插件监听 Webpack 构建生命周期的事件节点,做出相应的反应,执行对象的 run 方法开始执行编译。
-
确定入口
从配置文件( webpack.config.js )中指定的 entry 入口,开始解析文件构建 AST 语法树,找出依赖,递归下去。
-
编译模块
递归中根据文件类型和 loader 配置,调用所有配置的 loader 对文件进行转换,再找出该模块依赖的模块,再递归本步骤直到所有入口依赖的文件都经过了本步骤的处理。
-
完成模块编译并输出
递归完后,得到每个文件结果,包含每个模块以及他们之间的依赖关系,根据 entry 配置生成代码块 chunk 。
-
输出完成
输出所有的 chunk 到文件系统。
实现一个简单的 webpack
1)npm init -y 初始化一个项目,安装四个依赖包
- @babel/parser : 用于分析通过 fs.readFileSync 读取的文件内容,并返回 AST (抽象语法树) ;
- @babel/traverse : 用于遍历 AST, 获取必要的数据;
- @babel/core : babel 核心模块,提供 transformFromAst 方法,用于将 AST 转化为浏览器可运行的代码;
- @babel/preset-env : 将转换后代码转化成 ES5 代码;
2)从构建原理的第三步开始实现 wbepack
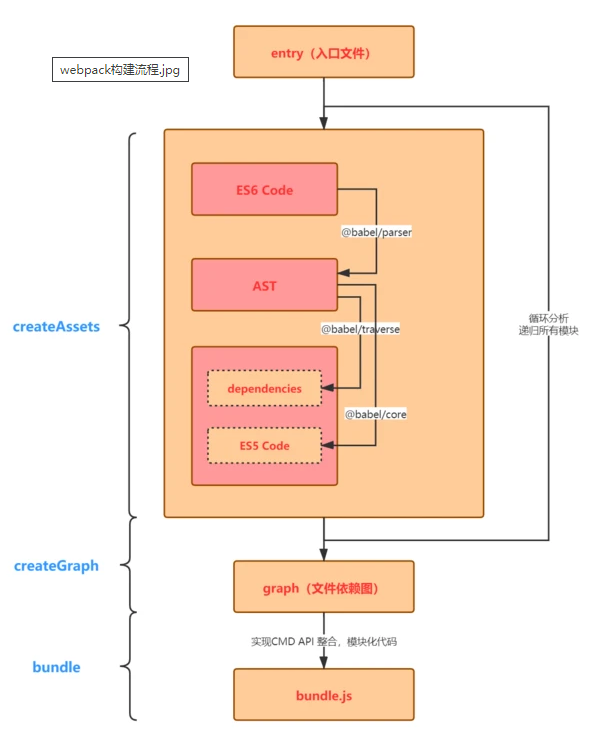
手写 Webpack 的核心是实现以下三个方法:
- createAssets : 收集和处理文件的代码;
- createGraph :根据入口文件,返回所有文件依赖图;
- bundle : 根据依赖图整个代码并输出;
const fs = require("fs");
const path = require("path");
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
// 由于 traverse 采用的 ES Module 导出,我们通过 require 引入的话就加.default
const babel = require("@babel/core");
let moduleId = 0; // 区分
const createAssets = filename => {
const content = fs.readFileSync(filename, "utf-8"); // 根据文件名,同步读取文件流
// 将读取文件流 buffer 转换为 AST
const ast = parser.parse(content, {
sourceType: "module" // 指定源码类型
})
const dependencies = []; // 用于收集文件依赖的路径
// 通过 traverse 提供的操作 AST 的方法,获取每个节点的依赖路径
traverse(ast, {
ImportDeclaration: ({node}) => {
dependencies.push(node.source.value);
}
});
// 将 AST 转换为浏览器可运行代码
const {code} = babel.transformFromAstSync(ast, null, {
presets: ["@babel/preset-env"]
});
let id = moduleId++; // 设置当前处理的模块ID
return {
id,
filename,
code,
dependencies
}
}
/**
* 递归所有依赖模块,循环分析每个依赖模块的依赖,生成一份依赖图谱
* @param entry
* @returns {[{filename: string, code: string, id: number, dependencies: []}]}
*/
function createGraph(entry) {
const mainAsset = createAssets(entry); // 获取入口文件下的内容
const queue = [mainAsset]; // 入口文件的结果作为第一项
for(const asset of queue){
const dirname = path.dirname(asset.filename);
asset.mapping = {};
asset.dependencies.forEach(relativePath => {
const absolutePath = path.join(dirname, relativePath); // 转换文件路径为绝对路径
const child = createAssets(absolutePath);
asset.mapping[relativePath] = child.id; // 相对路径作为key,保存模块ID
queue.push(child); // 递归去遍历所有子节点的文件
})
}
return queue;
}
/**
* 输出编译后的结果
* @param graph 依赖图谱
*/
function bundle(graph) {
let modules = "";
graph.forEach(item => {
modules += `
${item.id}: [
function (require, module, exports){
${item.code}
},
${JSON.stringify(item.mapping)}
],
`
})
return `
(function(modules){
function require(id){
const [fn, mapping] = modules[id];
function localRequire(relativePath){
return require(mapping[relativePath]);
}
const module = {
exports: {}
}
fn(localRequire, module, module.exports);
return module.exports;
}
require(0);
})({${modules}})
`
}
let graph = createGraph('./src/index.js');
const result = bundle(graph);
eval(result)
上面比较难理解的是 bundle 中的 IIFE,在 IIFE 上面对依赖图谱进行了遍历,把图谱中每个模块的代码与依赖的模块 mapping(对象形式:{ 相对路径:模块 ID })构造成数组,作为参数传给 IIFE。
IIFE 中先拿出来每个模块的执行函数与 mapping,执行函数传入新创建的 module 对象与 module.exports 属性,防止代码执行不支持 cjs 的导出方式。
localRequire 方法就是在执行代码中的 require 方法,会使用我们自己封装的 localRequire 方法,传入执行代码中的路径就是代码中 import 的相对路径,依赖模块递归调用新定义的 require 方法,最后执行完所有代码。
执行代码就是我们模块中的代码经过 createAssets 转换后的代码,需要执行
6、webpack 插件机制
依赖于一个核心的库, Tapable
Tapable 是什么
一个类似于 nodejs 的 EventEmitter 的库,主要是控制钩子函数的发布与订阅。
tapable 提供的 hook 机制比较全面,分为同步和异步两个大类(异步中又区分异步并行和异步串行),而根据事件执行的终止条件的不同,又衍生出 Bail/Waterfall/Loop 类型。
const {
SyncHook
} = require('tapable')
// 创建一个同步 Hook,指定参数,这里的参数要用数组,tapable默认也会转化为数组
const hook = new SyncHook(['arg1', 'arg2'])
// 注册,a 代表标记的插件(没啥用好像)
hook.tap('a', function (arg1, arg2) {
console.log('a')
})
hook.tap('b', function (arg1, arg2) {
console.log('b')
})
hook.call(1, 2) // 调用钩子,触发回调
//a
//b
最好的实践就是把所有的钩子暴露在一个类的 hooks 属性里面,定义触发钩子的方法。开发者在在需要的时候调用方法,就会触发所有绑定了的函数
class Car {
constructor() {
this.hooks = {
accelerate: new SyncHook(["newSpeed"]),
brake: new SyncHook(),
calculateRoutes: new AsyncParallelHook(["source", "target", "routesList"])
};
}
setSpeed(newSpeed) {
// call(xx) 传参调用同步钩子的API
this.hooks.accelerate.call(newSpeed);
}
useNavigationSystemPromise(source, target) {
const routesList = new List();
// 调用promise钩子(钩子返回一个promise)的API
return this.hooks.calculateRoutes.promise(source, target, routesList).then(() => {
return routesList.getRoutes();
});
}
useNavigationSystemAsync(source, target, callback) {
const routesList = new List();
// 调用异步钩子API
this.hooks.calculateRoutes.callAsync(source, target, routesList, err => {
if(err) return callback(err);
callback(null, routesList.getRoutes());
});
}
}
-
BasicHook: 执行每一个,不关心函数的返回值,有 SyncHook、AsyncParallelHook、AsyncSeriesHook。
我们平常使用的 eventEmit 类型中,这种类型的钩子是很常见的。
-
BailHook: 顺序执行 Hook,遇到第一个结果 result !== undefined 则返回,不再继续执行。有:SyncBailHook、AsyncSeriseBailHook, AsyncParallelBailHook。
BailHook 场景:假设我们有一个模块 M,如果它满足 A 或者 B 或者 C 三者任何一个条件,就将其打包为一个单独的。这里的 A、B、C 不存在先后顺序
compile
在 webpack 环境中应用一个插件时,插件将收到此 compiler 对象的引用。可以使用 compiler 来访问 webpack 的主环境。
compilation
运行 webpack 开发环境中间件时,每当检测到一个文件变化,就会创建一个新的 compilation,从而生成一组新的编译资源。
表现了当前的模块资源、编译生成资源、变化的文件、以及被跟踪依赖的状态信息
官方文档中的示例插件
class MyExampleWebpackPlugin {
// 定义 `apply` 方法
apply(compiler) {
// 指定要追加的事件钩子函数
compiler.hooks.compile.tapAsync(
'afterCompile',
(compilation, callback) => {
console.log('This is an example plugin!');
console.log('Here’s the `compilation` object which represents a single build of assets:', compilation);
// 使用 webpack 提供的 plugin API 操作构建结果
compilation.addModule(/* ... */);
callback();
}
);
}
}
7、webpack loader 机制(暂时放弃)
8、前端微服务(暂时放弃)
操作系统
进程
定义: 是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础
线程
定义: 是操作系统能够进行运算调度的最小单位,是进程中的实际运作单位
协程
定义:是一个特殊的函数。这个函数可以在某个地方被“挂起”,并且可以重新在挂起处外继续运行。不是被操作系统内核所管理,由程序所控制的。性能有大幅度的提升,因为不会像线程切换那样消耗资源(在一个线程内,一个协程运行时,其他协程会被挂起。线程可以并行)
深入理解
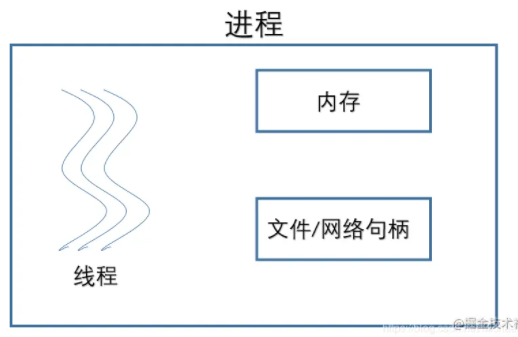
内存:这里指的是逻辑内存,是内存的寻址空间
文件/网络句柄: 所有的进程共有,例如打开同一个文件,去抢同一个网络的端口这样的操作是被允许的。
线程(栈+PC+TLS):
栈:主线程的入口main函数,会不断的进行函数调用, 每次调用的时候,会把所有的参数和返回地址压入到栈中。
PC(寄存器的一种):Program Counter 程序计数器,操作系统真正运行的是一个个的线程, 而我们的进程只是它的一个容器。PC就是指向当前的指令,而这个指令是放在内存中。 每个线程都有一串自己的指针,去指向自己当前所在内存的指针。 计算机绝大部分是存储程序性的,说的就是我们的数据和程序是存储在同一片内存里的 这个内存中既有我们的数据变量又有我们的程序。所以我们的PC指针就是指向我们的内存的。
缓冲区溢出:有个地方用来存用户名数据。 然后黑客把数据输入的特别长,超出了我们给数据存储的内存区,这时候跑到了我们给程序分配的一部分内存中。黑客就可以通过这种办法将他所要运行的代码写入到用户名框中,来植入进来。解决方法就是限制用户名的长度不超过用户名的缓冲区的大小
TLS:thread local storage 存储我们线程所独有的数据
进程之间怎么进行交互
管道:是一种半双工(只能写或者读)的通信方式,数据只能单向流动
1)匿名管道( pipe ):,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
2)高级管道:将一个程序当做一个子进程在当前程序启动
3)有名管道:允许无亲缘关系进程间的通信
消息队列通信:
有消息的链表,存放在内核中并由消息队列标识符标识。克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点
信号量:
是一个计数器,可以用来控制多个进程对共享资源的访问。主要作为进程间以及同一进程内不同线程之间的同步手段,常作为锁机制。
信号:
通知接收进程某个事件已经发生,类似订阅发布模式
共享内存通信:
这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式
套接字通信:
可用于不同机器间的进程通信。通信双方命名socket、双方绑定地址到socket、监听客户端连接、相互发送数据、关闭
线程间的通信方式
1)使用全局变量
2)等待/通知机制(订阅发布模式)
进程调度策略
1)先来先服务调度算法
先进队列的先做
2)短作业(进程)优先调度算法
从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行。或者把处理机进程
3)高优先权优先调度算法
系统将从后备队列中选择若干个优先权最高的作业装入内存,或者把处理机分配给就绪队列中优先权最高的进程
非抢占式优先权算法:处理机分配给某个进程后,必须一直执行,除非主动放弃或者完成
抢占式优先权调度算法:有更高优先级进程出现时,处理机会重新分配
优先级倒置现象:A(低优先级)和 C(高优先级)需要同样的资源, A 在执行时被 B(中优先级)的进程抢占,此时资源并没有释放,而 C 这时候由于拿不到共用资源,所以无法抢占 B
解决方案: A 和 C 共用资源时,临时提升 A 的优先级,释放后回到原优先级
死锁
定义:
- 互斥条件 —> 一个资源每次只能被一个线程使用
- 请求与保持条件 —> 一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件 —> 线程已获得的资源,在未使用完之前,不能强行剥夺
- 循环等待条件 —> 唯一需要记忆的造成死锁的条件(若干线程之间形成一种头尾相接的循环等待资源关系)
避免方法:在并发程序中,避免了逻辑中出现复数个线程互相持有对方线程所需要的独占锁的的情况
阻塞 I/O 到 I/O 多路复用
阻塞 I/O:指进程发起调用后,会被挂起(阻塞),直到收到数据再返回(使用多线程处理多个文件描述符)
缺点:多线程切换有一定的开销,因此引入非阻塞 I/O
非阻塞 I/O:不会将进程挂起,调用时会立即返回成功或错误,因此可以在一个线程里轮询多个文件描述符是否就绪。
缺点:次发起系统调用,只能检查一个文件描述符是否就绪。当文件描述符很多时,系统调用的成本很高
I/O 多路复用:通过一次系统调用,检查多个文件描述符的状态。在文件描述符较多的场景下,避免了频繁的用户态和内核态的切换,减少了系统调用的开销
缺点:引入了一些额外的操作和开销,性能更差
网络
一、七层网络模型
- OSI: open system interconnection 开放式系统互联参考模型
- OSI 和 TCP/IP 的对应关系和协议
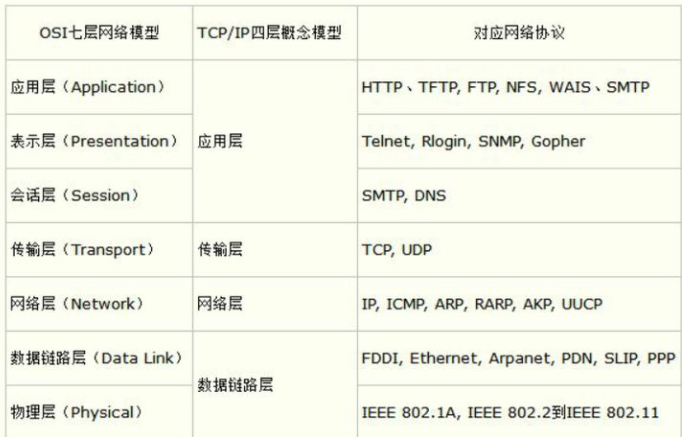
OSI 模型各层的基本作用


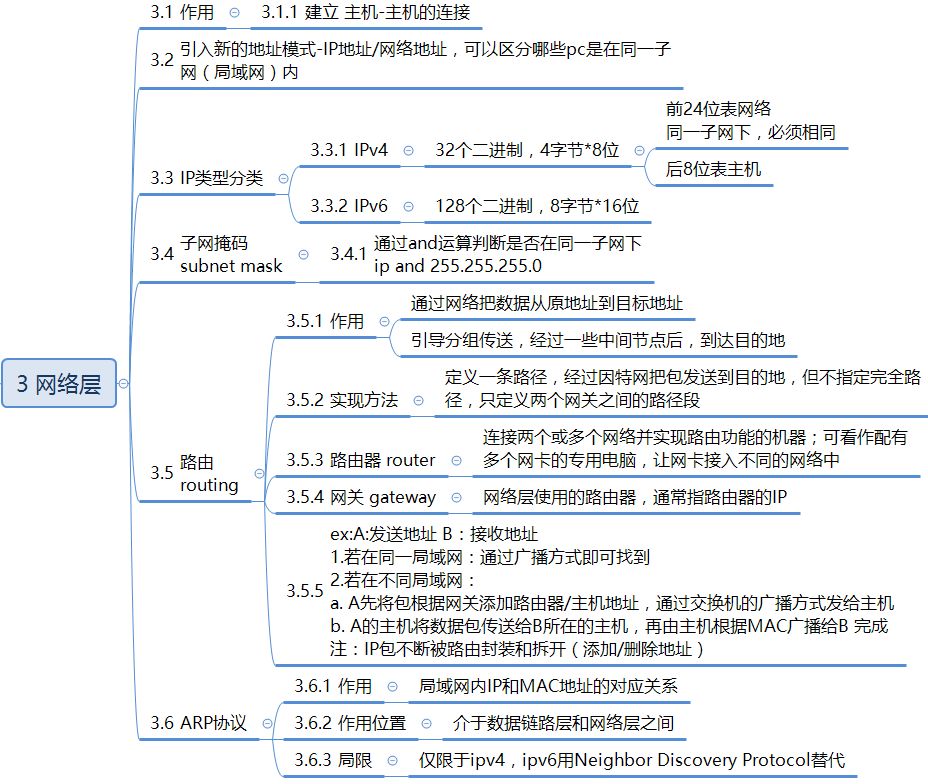
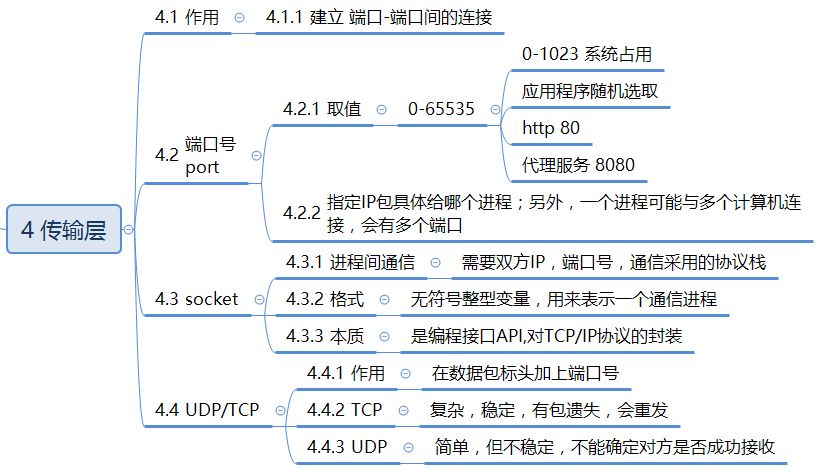

数据链路层数据包(以太网数据包)格式,除了应用层没有头部,其他都有
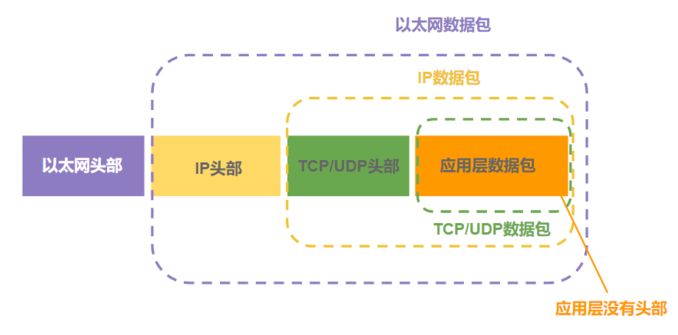
由于以太网数据包的数据部分,最大长度为 1500 字节,当 IP 包过大时,会分割下来,但是每个分割包的头部都一样
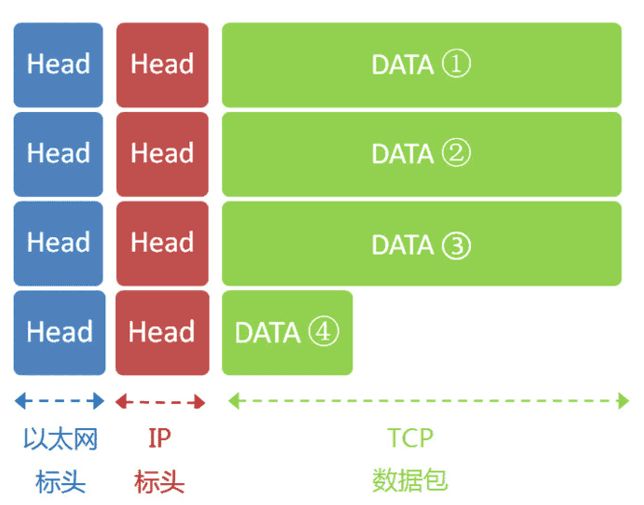
数据包在传送时的封装和解封装:
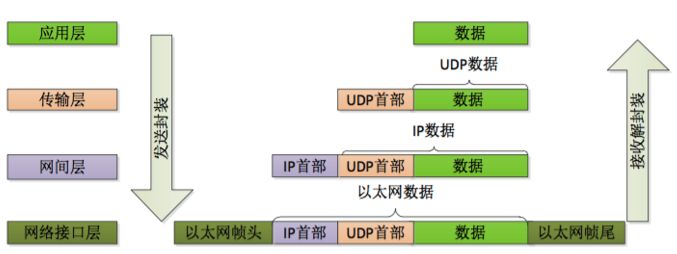
二、HTTP
HTTP 0.9 / 1.0
HTTP 0.9 版本的协议简单到极点:请求时,不支持请求头,只支持 GET 方法,最传统的 request – response
HTTP 1.0 主要扩展:
-
在请求中加入了HTTP版本号,如:GET /coolshell/index.html HTTP/1.0
-
HTTP 开始有 header了,不管是 request 还是 response 都有 header 了。
header 把元数据和业务数据解耦,也是控制逻辑和业务逻辑的分离
-
增加状态码。
-
还有 Content-Type 可以传输其它的文件
缺点:每请求一个资源都要新建一个TCP 链接,而且是串行请求。
HTTP 1.1
- 可以设置 keepalive 来让 HTTP 重用 TCP 链接,重用 TCP 链接可以省了每次请求都要在广域网上进行的 TCP 的三次握手的巨大开销。这就是所谓的“HTTP 长链接” 或是 “请求响应式的 HTTP 持久链接”。
- 支持 pipeline 网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。(注:非幂等的 POST 方法或是有依赖的请求是不能被pipeline 化的)
- 支持 Chunked Responses ,也就是说,在 Response 的时候,不必说明 Content-Length 这样,客户端就不能断连接,直到收到服务端的 EOF 标识。这种技术又叫 “服务端Push模型”,或是 “服务端Push式的 HTTP 持久链接”
- 增加了 cache control 机制。
- 协议头注增加了 Language, Encoding, Type 等等头,让客户端可以跟服务器端进行更多的协商。
- 正式加入了一个很重要的头—— HOST。这样的话,服务器就知道你要请求哪个网站了。因为可以有多个域名解析到同一个IP上,要区分用户是请求的哪个域名,就需要在HTTP的协议中加入域名的信息,而不是被DNS转换过的IP信息。
- 正式加入了 OPTIONS 方法,其主要用于 CORS – Cross Origin Resource Sharing 应用。
HTTP/1.1 应该分成两个时代:一个是2014年前,一个是2014年后。因为2014年 HTTP/1.1 有了一组 RFC(评论意见稿)(7230 /7231/7232/7233/7234/7235),这组 RFC 又叫“HTTP/2 预览版”。其中影响 HTTP 发展的是两个大的需求:
- 一个是加大了HTTP的安全性,比如使用 TLS 协议。
- 另一个是让HTTP可以支持更多的应用,在 HTTP/1.1 下,HTTP已经支持四种网络协议:
- 传统的短链接。
- 可重用 TCP 的的长链接模型。
- 服务端 push 的模型。
- WebSocket模型。
HTTP/2
基于 Google 一个实验型的协议:SPDY
HTTP/1.1 可以重用 TCP 链接,但是请求还是串行发的,需要保证其顺序。然而,网页请求中资源类的东西占了整个 HTTP 请求中最多的传输数据量。所以,如果能够并行这些请求,那就会增加更大的网络吞吐和性能。
同时,HTTP/1.1传输数据时,是以文本的方式,借助耗 CPU 的 zip 压缩的方式减少网络带宽,但是耗了前端和后端的 CPU,数据传输的成本比较大。
HTTP/2 和 HTTP/1.1 最主要的不同是:
-
二进制分帧:增加了数据传输的效率。http2.0 会将所有传输信息分割为更小的消息和帧,并对它们采用二进制格式的编码将其封装,兼容上一代 http 标准,header 封装到 Headers 帧中,而 request body 将被封装到 Data 帧中
帧(frame):类型 Type, 长度 Length, 标记 Flags, 流标识 Stream 和 有效载荷 frame payload
消息(message):一个完整的请求或者响应,由一个或多个 Frame 组成
流:连接中的一个虚拟信道,可以承载双向消息传输。每个流有唯一整数标识符,为了防止两端流 ID 冲突,客户端发起的流具有奇数 ID,服务器端发起的流具有偶数 ID。一个 http2 连接上可包含多个并发打开的流,这个并发流的数量能够由客户端设置。
流标识:描述二进制 frame 的格式,使得每个 frame 能够基于 http2 发送
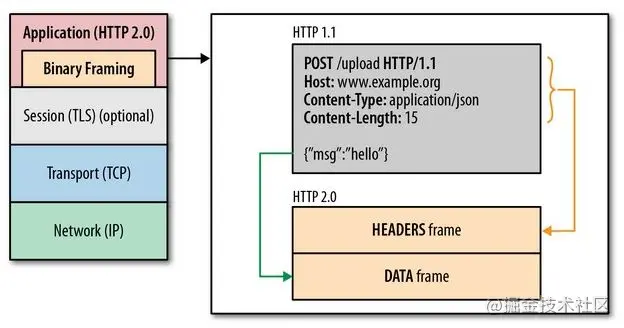
-
多路复用 (Multiplexing) / 连接共享:HTTP/2 可以在一个 TCP 链接中并发请求多个 HTTP 请求,移除了 HTTP/1.1中 的串行请求。
每个数据流都拆分成很多互不依赖的帧,这些帧可以交错(乱序发送),还可以分优先级,最后再在另一端把它们重新组合起来
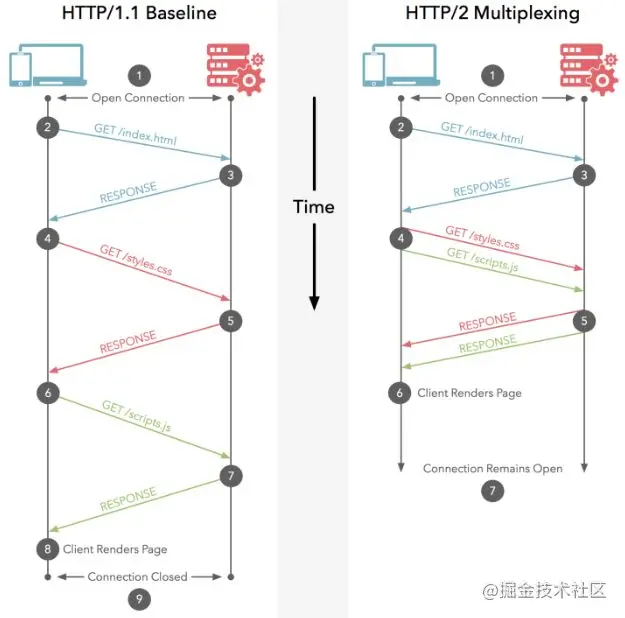
-
头部压缩:用 header 字段表里的索引代替实际的 header。HPACK 算法使用一份索引表来定义常用的 http Header,请求的时候只需要发送在表里的索引位置即可,常见的用静态表,动态表用来追加。HPACK 同时还会将字符串进行霍夫曼编码来压缩字符串大小,比如 User-Agent。
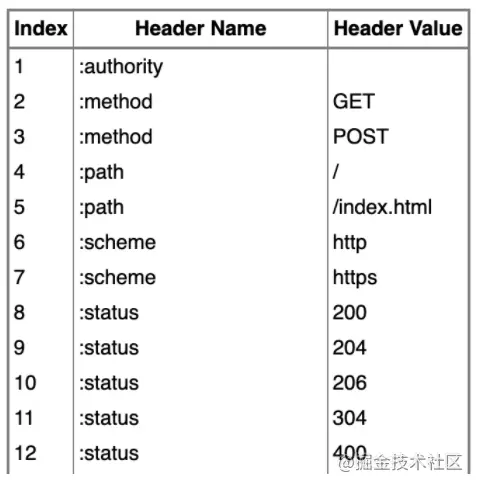
常见的 gzip 等是报文内容(body)的压缩,二者合作效果更好
-
请求优先级:每个流都带有一个 31 比特的优先值:0 表示最高优先级;2的31次方-1 表示最低优先级,需要维护一个“优先级树”来用于来做一些资源和请求的调度和控制
-
服务端推送:HTTP/2 允许服务端在客户端放 cache,你没有请求的东西,我服务端可以先送给你放在你的本地缓存中。比如,你请求X,我服务端知道 X 依赖于 Y,虽然你没有请求 Y,但我把把 Y 跟着 X 的请求一起返回客户端。
服务端会发送一个 Frame Type 为 PUSH_PROMISE 的 Frame,里面带了 PUSH 需要新建的 Stream ID。告诉客户端:接下来我要用这个 ID 向你发送东西,客户端准备好接着。客户端解析 Frame 时,发现它是一个 PUSH_PROMISE 类型,便会准备接收服务端要推送的流
HTTP/3
http/2 主要的问题:
1)队首阻塞问题:若干个 HTTP 的请求在复用一个 TCP 的连接,TCP 协议收集排序整合 HTTP 请求,所以一旦发生丢包,所有的 HTTP 请求都必需等待这个丢了的包被重传回来,哪怕丢的那个包不是我这个 HTTP 请求的
1.x 中 http 层和 tcp 层都存在,2的多路复用解决了 http 层,但是 tcp 层还是会有,并且由于强制使用 TLS 协议,还多了 TLS 协议层面的队头阻塞
2)多次握手 RTT 高:tcp 连接、tsl/ssl 连接、http 数据交换
3)拥塞控制副作用:如果网络上出现拥塞,大家都会丢包,于是都进入拥塞控制的算法中,算法会让所有人都“冷静”下来,然后进入一个“慢启动”的过程,包括在 TCP 连接建立时,这个慢启动也在,所以导致 TCP 性能迸发地比较慢。
解决方法:在 UDP 基础上改造一个具备 TCP 协议优点的新协议 QUIC !
-
Head-of-Line blocking 问题。UDP 不管顺序,不管丢包,QUIC 的多个 stream 之间没有依赖等待关系 (当然,QUIC 的一个任务是要像 TCP 稳定,所以 QUIC 有自己的丢包重传机制)
-
改进的拥塞控制:没有固定的算法,可以根据需要切换
1)支持热插拔
在应用层实现了拥塞控制,不再像 tcp 依赖于操作系统和硬件层,可以根据不同的网络环境,支持动态的选择拥塞控制算法,单个应用程序的不同连接也能支持配置不同的拥塞控制
2)单调递增的 Packet Number
使用 Packet Number 代替了 TCP 的 sequence number,每个 Packet Number 都严格递增,而不是 TCP sequence number 的保持不变,避免 TCP 重传的歧义问题
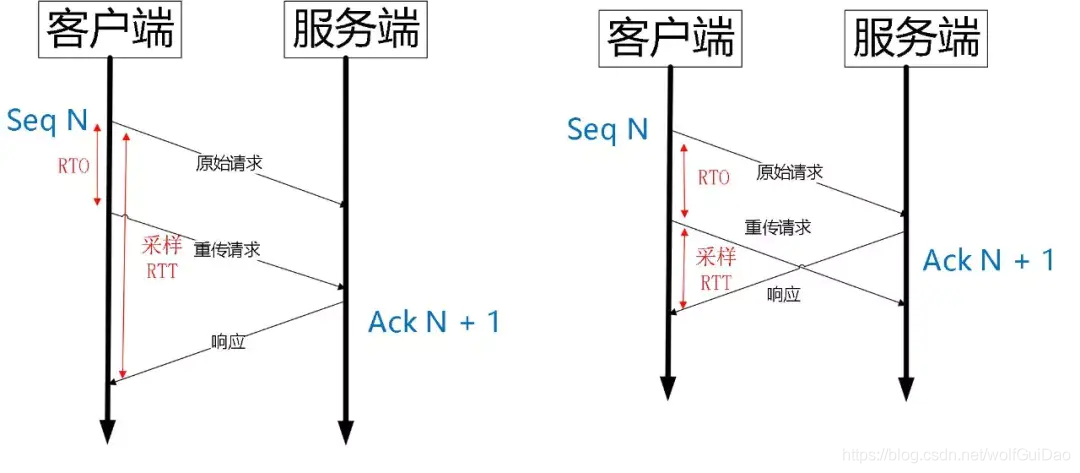
序列号不变导致无法区分是原始请求还是重传请求,并且判断错误导致采样 RTT 过大或过小
光靠严格递增的 Packet Number 无法保证数据的顺序性和可靠性,QUIC 又引入了一个 Stream Offset 的概念
如上图,发送端先后发送了 Pakcet N 和 Pakcet N+1,Stream 的 Offset 分别是 x 和 x+y。假设 Packet N 丢失了,发起重传,重传的 Packet Number 是 N+2,但是它的 Stream 的 Offset 依然是 x,这样就算 Packet N + 2 是后到的,依然可以将 Stream x 和 Stream x+y 按照顺序组织起来
3)不允许 Reneging(中途退出)
定义:接收方丢弃已经接收并且上报给 SACK 选项的内容,主要是考虑到服务器资源有限,比如 Buffer 溢出,内存不够等情况。QUIC 在协议层面禁止 Reneging,一个 Packet 只要被 Ack,就认为它一定被正确接收,减少了这种干扰
4)更多的 Ack 块
TCP 的 Sack 选项能够告诉发送方已经接收到的连续 Segment 的范围,方便发送方对没有收到的数据段进行选择性重传。更多的 Sack Block 可以提升网络的恢复速度,减少重传量
5)Ack Delay 时间(这里存疑,因为这个时间取决于服务器,而不是网络状况)
TCP 的 RTT 不会计算 ACK Delay 时间
TCP:RTT = timestamp2 - timestamp1
QUIC:RTT = timestamp2 - timestamp1 - ACK Delay
-
0RTT 建链:
首次连接
- 客户端发送 client hello
- 服务器计算自己的公钥私钥,然后将公钥和一个素数一个整数打包成 config 发送给客户端
- 客户端生成自己的私钥,通过素数和整数生成公钥,使用私钥和服务端的公钥生成数据加密的密钥 K
- 用密钥 K 加密数据,并把自己的公钥给服务端
- 服务端根据自己的私钥和客户端的公钥生成客户端同样的密钥 K 解密数据。为了保证安全,根据上面的规则再生成一套公私钥和密钥 M,然后把新公钥和加密过的数据发送给客户端,客户端根据新公钥和自己的老私钥计算出 M,解密数据
- 之后都是用 M 加密数据,K 只用一次
非首次连接
-
客户端会把 config 包存储下来,后续连接时直接使用,跳过这个 RTT,变成 0 RTT,当然这个 config 保存是有时限的
问:为什么 K 只用一次呢?
答:基于前向安全,密钥泄漏不会让之前加密的数据被泄漏,影响的只有当前
-
连接迁移
QUIC 摒弃了 TCP 五元组(源IP地址,源端口,目的IP地址,目的端口和传输层协议),使用64位的随机数作为连接的 ID,并使用该 ID 表示连接。当我们从 4G 环境切换到 wifi 环境时,如果是 TCP 手机的 IP 地址就会发生变化,这时必须创建新的 TCP 连接才能继续传输数据,QUIC则不会,因为 connection ID 没变
NAT 是什么:Network Address Translation,网络地址转换。专用网内部的一些主机已经分配到了本地 IP 地址(即仅在本专用网内使用的专用地址),但又想和因特网上的主机通信(并不需要加密)时,可使用NAT方法,将其本地地址转换成全球IP地址
然而 connection id 也有问题 ,一些不够“聪明”的等价路由交换机,通过五元组来做 hash 把请求的 IP 转到后端的实际的服务器上,然而,他们不懂connection id,只懂五元组,导致属于同一个 connection id 但是五元组不同的网络包就转到了不同的服务器上,这就是导致数据不能传到同一台服务器上,数据不完整,链接只能断了。所以,需要更聪明的算法(可以参看 Facebook 的 Katran 开源项目 )
-
流量控制
TCP 双方约定一定大小的窗口,在这个窗口内的包都可以同步发送(避免不必要的等待),接收方收到一个 packet 时会回复 ACK 给发送方,发送方收到 ACK 后移动发送窗口,发送后续数据。
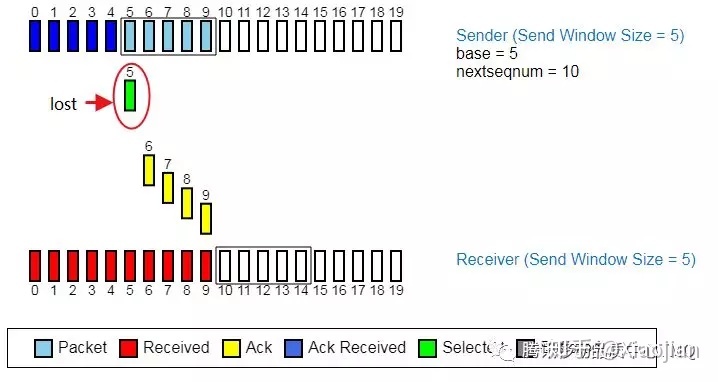
packet 5的 ACK 包丢失,导致发送方无法移动发送窗口,但接收方已经在等待后面的包了。必须等到接收方超时重传这个 ACK 包,发送方收到这个 ACK 包后,发送窗口才会移动
QUIC 分为两种流量控制
1)stream 级别:握手时,接收方通过传输参数设置 stream 的初始限制,可用窗口 = 最大窗口 - 已接收的最大偏移字节数
2)Connection 级别:限制所有 streams 相加起来的总字节数,防止超过缓冲容量。可用窗口 = stream 1 可用窗口 + stream 2 可用窗口 + stream 3 可用窗口
-
头压缩算法 QPACK:基于 QUIC 的 QPACK 利用两个附加的 QUIC stream,一个用来发送字典表的更新给对方,另一个用来 ack 对方发过来的 update
HTTP/3 目前没有太多的协议业务逻辑上的东西,更多是HTTP/2 + QUIC协议。但因为动到了底层协议,所以在普及方面上可能会比 HTTP/2 要慢的多的多。
HTTPS
定义:在 HTTP 和 TCP 之间建立了一个安全层,HTTP 与 TCP 通信的时候,必须先进过一个安全层,对数据包进行加密,然后将加密后的数据包传送给 TCP,相应的 TCP 必须将数据包解密,才能传给上面的 HTTP
一、TLS/SSL 的功能实现依赖三类基本算法
非对称加密:实现身份认证和密钥协商
对称加密:对信息进行加密
散列函数:验证信息完整性
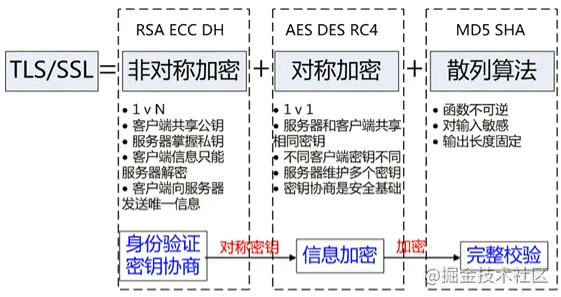
二、SSL 和 TLS 的区别
SSL 是 TLS 的前身
三、对称加密
有一个密钥,它可以加密一段信息,也可以对加密后的信息进行解密
缺点:单独使用时,无法保证密钥发送过去不泄露
四、 非对称加密
公私钥方案:公钥发送给对方,对方加密数据后,传过来用私钥解密
五、HTTPS 方案
- 某网站拥有用于非对称加密的公钥 A、私钥 B。
- 浏览器向服务器请求,服务器把公钥 A 明文给传输浏览器。
- 浏览器随机生成一个用于对称加密的密钥 X,用公钥 A 加密后传给服务器。
- 服务器拿到后用私钥 B 解密得到密钥 X。
- 这样双方就都拥有密钥 X 了,且别人无法知道它。之后双方所有数据都通过密钥 X 加密解密即可。
然而这方案并不完美
六、中间人攻击
- 某网站拥有用于非对称加密的公钥 A、私钥 B。
- 浏览器向服务器请求,服务器把公钥 A 明文给传输浏览器。
- 中间人劫持到公钥 A,保存下来,把数据包中的公钥 A 替换成自己伪造的公钥 C(它当然也拥有公钥 C 对应的私钥 D)。
- 浏览器生成一个用于对称加密的密钥 X,用公钥 C(浏览器无法得知公钥被替换了)加密后传给服务器。
- 中间人劫持后用私钥 D 解密得到密钥 X,再用公钥 A 加密后传给服务器。
- 服务器拿到后用私钥 B 解密得到密钥 X。
中间人通过一套“狸猫换太子”的操作,掉包了服务器传来的公钥,进而得到了密钥 X。根本原因是浏览器无法确认收到的公钥是不是网站自己的。
七、如何证明浏览器收到的公钥一定是该网站的公钥
通过数字证书
网站在使用 HTTPS 前,需要向 CA 机构(如同公理,大家都认可)申领一份数字证书,数字证书里含有证书持有者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书里获取公钥就行了,证书就如身份证,证明“该公钥对应该网站”
八、如何放防止数字证书被篡改
数字签名的制作过程:
- CA 机构拥有非对称加密的私钥和公钥。
- CA 机构对证书明文数据 T 进行 hash。
- 对 hash 后的值用私钥加密,得到数字签名 S。
明文和数字签名共同组成了数字证书,这样一份数字证书就可以颁发给网站了。
浏览器验证过程:核心是把解密得到的 CA 的 hash 值 与自己用同样算法加密得到的 hash 值比对
- 拿到证书,得到明文 T,签名 S。
- 用 CA 机构的公钥对 S 解密(由于是浏览器信任的机构,所以浏览器保有它的公钥。详情见下文),得到 S’。
- 用证书里指明的 hash 算法对明文 T 进行 hash 得到 T’。
- 显然通过以上步骤,T’ 应当等于 S‘,除非明文或签名被篡改。所以此时比较 S’ 是否等于 T’,等于则表明证书可信。
问:中间人有可能篡改该证书吗
答:中间人拿不到 CA 的私钥,所以改了证书但是改不了正确的签名,浏览器自己得到的 hash 值是对不上这个签名的
问:中间人有可能把证书掉包吗
答:证书里包含域名,浏览器只要判断这个证书是不是自己请求的那个域名就可以
问:为什么制作数字签名时需要 hash 一次
答:性能问题。非对称加密效率较差,证书信息一般较长,直接加密比较耗时。hash 后得到的是固定长度的信息
九、怎么证明 CA 机构的公钥是可信的
操作系统、浏览器本身会预装一些它们信任的根证书,如果其中会有 CA 机构的根证书,这样就可以拿到它对应的可信公钥。
实际上证书之间的认证也可以不止一层,可以A 信任 B,B 信任 C,叫做信任链或数字证书链
十、每次进行 HTTPS 请求时都必须在 SSL/TLS 层进行握手传输密钥吗
为了节省资源,服务器会为每个浏览器(或客户端软件)维护一个 session ID,在 TLS 握手阶段传给浏览器,浏览器生成好密钥传给服务器后,服务器会把该密钥存到相应的 session ID下,之后浏览器每次请求都会携带session ID,服务器会根据 session ID 找到相应的密钥并进行解密加密操作
websocket
与 http 的不同点:
- WS握手时使用 HTTP 来建立连接,但是定义了一系列新的 header 域,这些域在 HTTP 中并不会使用;
- WS的连接不能通过中间人来转发,它必须是一个直接连接;
- 通信双方在任何时刻向另一方发送数据;
- 数据的传输使用帧来传递,性能开销小,通信高效
- 可以发送文本,也可以发送二进制数据。
请求时数据:
GET /uin=xxxxxxxx&app=xxxxxxxxx&token=XXXXXXXXXXXX HTTP/1.1
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Key: 1/2hTi/+eNURiekpNI4k5Q==
Sec-WebSocket-Protocol: binary, base64
- 第一行类型必须为GET,协议版本号必须大于1.1
- Upgrade 字段必须包含,值为 websocket
- Connection 字段必须包含,值为 Upgrade
- Sec-WebSocket-Key 字段必须包含 ,记录着握手过程中必不可少的键值。
- Sec-WebSocket-Protocol 字段必须包含 ,记录着使用的子协议
- Origin):指明请求的来源,Origin头部主要用于保护 Websocket 服务器免受非授权的跨域脚本调用 Websocket API 的请求。也就是不想被没授权的跨域访问与服务器建立连接,服务器可以通过这个字段来判断来源的域并有选择的拒绝。
响应数据:
HTTP/1.1 101 Switching Protocols
Server: WebSockify Python/2.6.6
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: hXXXXXXXXXXXXXXxGmM= // 就是请求的 key
Sec-WebSocket-Protocol: binary
报文、报文段、分组、包、数据报、帧、数据流
-
报文
应用层的信息分组称为报文,网络中交换与传输的数据单元,包含了将要发送的完整的数据信息,在传输过程中会不断地封装成分组、包、帧,封装的方式就是添加一些控制信息组成的首部,那些就是报文头
-
报文段(TCP一般这么叫,UD一般叫数据报)
起始点和目的地都是传输层的信息单元
-
分组/包(packet)
起始和目的地是网络层。是在网络中传输的二进制格式的单元,为了提高通信性能和可靠性,数据会被分成多个更小的部分。在每个部分的前面加上一些必要的控制信息组成的首部,有时也会加上尾部,就构成了一个分组
-
数据报(datagram,这里主要指的 ip datagram,UDP datagram还是在传输层的)
起始点和目的地都使用无连接网络服务的的网络层的信息单元。
-
帧(frame)
数据链路层的传输单元
-
数据单元
物理层的信息。同一机器的服务数据单元(SDU)、不同机器之间的协议数据单元(PDU)
TCP
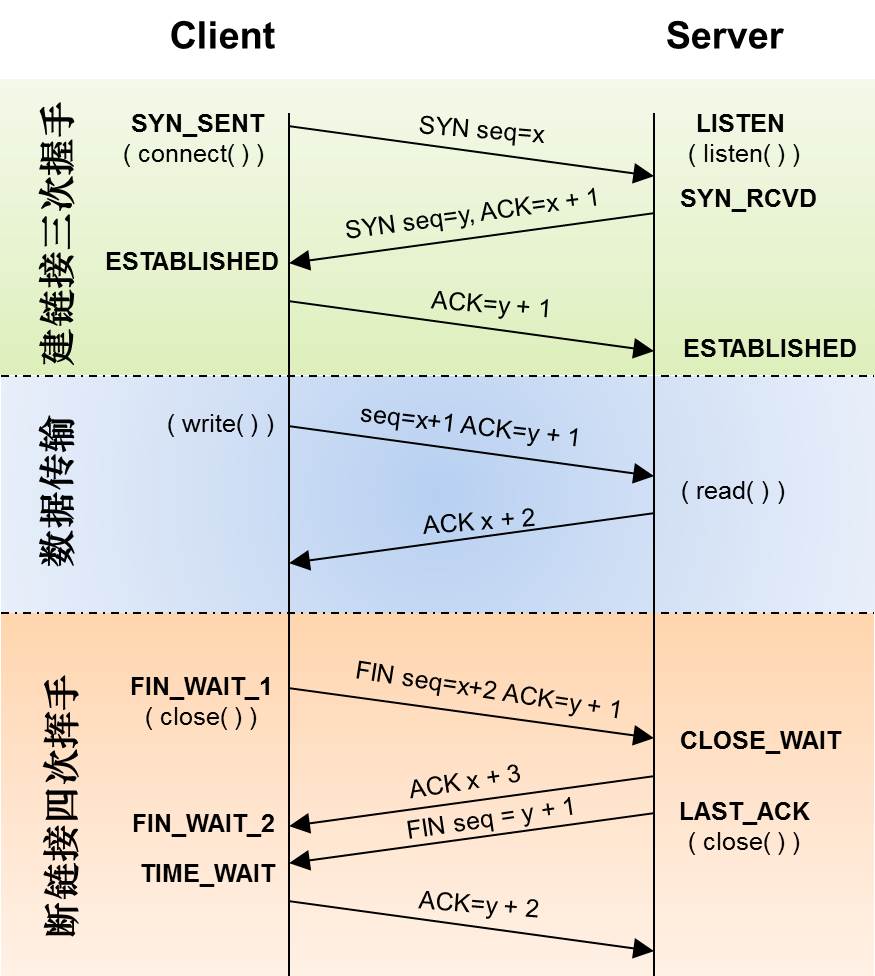
三次握手
- 客户端发送一个SYN段,并指明客户端的初始序列号,即ISN©.
- 服务端发送自己的SYN段作为应答,同样指明自己的ISN(s)。为了确认客户端的SYN,将ISN©+1作为ACK数值。这样,每发送一个SYN,序列号就会加1. 如果有丢失的情况,则会重传。
- 为了确认服务器端的SYN,客户端将ISN(s)+1作为返回的ACK数值。
四次挥手
- 客户端发送一个FIN段,并包含一个希望接收者看到的自己当前的序列号K. 同时还包含一个ACK表示确认对方最近一次发过来的数据。
- 服务端将K值加1作为ACK序号值,表明收到了上一个包。这时上层的应用程序会被告知另一端发起了关闭操作,通常这将引起应用程序发起自己的关闭操作。
- 服务端发起自己的FIN段,ACK=K+1, Seq=L
- 客户端确认。ACK=L+1
为什么要三次握手
主要是要初始化 Sequence Number 。通信的双方要互相通知对方自己的初始化 Sequence Numbers – seq。也就上图中的 x 和 y。这个号要作为以后的数据通信的序号,以保证应用层接收到的数据不会因为网络上的传输的问题而乱序(TCP会用这个序号来拼接数据)
为什么要四次挥手
握手时 ACK 和 SYN 可以放在一个报文里发送给客户端。关闭连接时,当收到对方的 FIN 报文时,仅仅表示对方不再发送数据了但是还能接收数据。己方是否现在关闭发送数据通道,需要上层应用来决定,因此,己方 ACK 和 FIN 一般都会分开发送
小知识
-
ISN
三次握手的一个重要功能是客户端和服务端交换 ISN(Initial Sequence Number)
如果ISN是固定的,攻击者很容易猜出后续的确认号
ISN = M + F(localhost, localport, remotehost, remoteport)M 是一个计时器,每隔4毫秒加1。F是一个 Hash 算法
-
syn flood 攻击
恶意的向某个服务器端口发送大量的 SYN 包,则可以使服务器打开大量的半开连接,分配 TCB 端口(Transmission Control Block),服务器会一直保持 Listening 状态,从而消耗大量的服务器资源。
防范方法:
1)无效连接的监视释放:监视系统的半开连接和不活动连接,当达到一定阈值时拆除这些连接(可能造成正常连接错误释放,入门级方法)
2)延缓 TCB 分配方法:当正常连接建立起来后再分配 TCB。Syn Cache 和 Syn Cookie(通过源端口、目标端口、时间戳打造一个特殊的 cookie 发过去,攻击者不会响应,正常连接接收后会发回来,然后服务器建立连接)
-
连接队列
在外部请求到达时,被服务程序最终感知到前,连接可能处于SYN_RCVD状态(进入半连接队列)或是ESTABLISHED状态,但还未被应用程序接受(进入全连接队列)
-
建连接时 SYN 超时
第三次握手 server 一直没有收到 ACK ,会重发SYN-ACK。Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s,总共31s,再等32s 后才会断开连接
-
关于 MSL(Maximum Segment Lifetime 报文最大存活时间) 和 TIME_WAIT
TIME_WAIT状态的主要目的有两个:
- 优雅的关闭 TCP 连接,尽量保证被动关闭的一端收到它自己发出去的 FIN 报文的 ACK 确认报文;
- 处理延迟的重复报文,避免前后两个使用相同四元组的连接中的前一个连接的报文干扰后一个连接。
问:为什么发送了最后一个 ACK 报文之后需要等待 2MSL 时长的 TIME_WAIT 状态
答:第一个 MSL 是为了等自己发出去的最后一个 ACK 从网络中消失,而第二 MSL 是为了等在对端收到 ACK 之前的一刹那可能重传的 FIN 报文从网络中消失
-
Sequence Number
Wireshark 中使用 Statistics ->Flow Graph… 可以看到,SeqNum 的增加是和传输的字节数相关的。三次握手后,来了两个Len:1440的包,而第二个包的 SeqNum 就成了1441。然后第一个ACK 回的是1441,表示第一个1440收到了
重传机制
SeqNum 和 Ack 是以字节数为单位,所以 ack 的时候,不能跳着确认,只能确认最大的连续收到的包,不然发送端就以为之前的都收到了。
1)超时重传机制(初级)
举个栗子:发送方发现收不到数据包3的 ACK 后,等待一定时间进行重传。
缺点:4和5即使已经收到,发送方也不知道。重传时有两种情况:只传timeout的3、连着后面的4、5一起传。但是都不太好,第一种节省带宽但是慢,第二种浪费带宽还有可能做无用功,因为接收方可能已经到了
2)快速重传机制(中级)
如果包没有连续到达,就 ack 最后那个可能被丢了的包,如果发送方连续收到3次相同的ack,就重传。举个栗子:发送方发出了1,2,3,4,5份数据,2因为某些原因没收到,3到达了,于是ack回2。后面的4和5都到了,但是还是 ack 回2。发送端收到了三个 ack=2 的确认,知道了2还没有到,于是就马上重传2。接收方收到2后,ack 回6。
好处:不用等待漫长的 timeout 时间
缺点:无法分辨是哪个数据返回的2,无法解决发送方重传一个还是多个的问题
3)SACK 方法(Selective Acknowledgment)
ACK 还是用的快速重传,但是在 TCP 头里加一个 SACK 的东西,返回已收到的数据范围
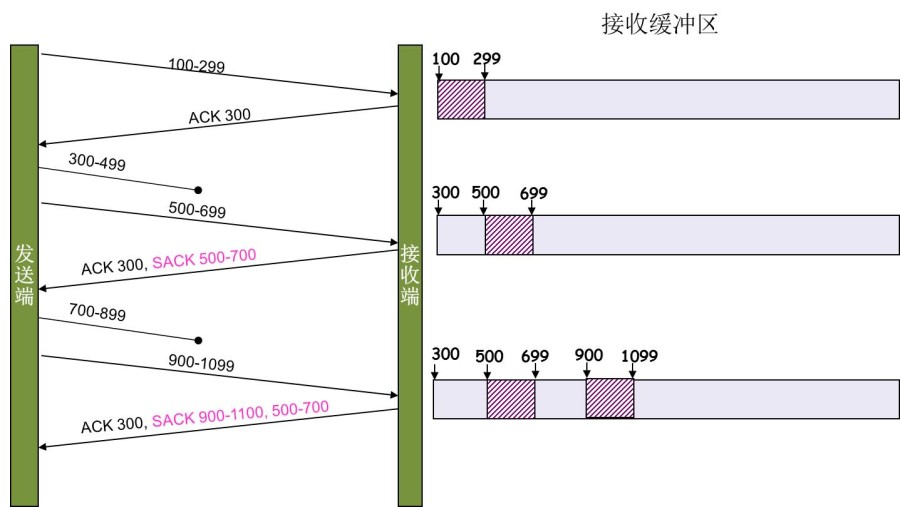
发送方不能完全依赖SACK,还是要依赖ACK。因为接收方因为某些极端情况(内存不够)等,有权放弃 SACK 里的数据段(Reneging)
Duplicate SACK(标识重复收到数据)
1)ACK丢包
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
3000-3499 3000-3499 3500 (ACK dropped)
3500-3999 3500-3999 4000 (ACK dropped)
3000-3499 3000-3499 4000, SACK=3000-3500
前两个包的 ACK 已经丢失,发送方重传了 3000-3499 的包,接收方返回的 ACK 是4000,发送方就知道 4000 之前的包都收到了,这个 SACK 被 ACK 覆盖,是 D-SACK
2)网络延误
Transmitted Received ACK Sent
Segment Segment (Including SACK Blocks)
500-999 500-999 1000
1000-1499 (delayed)
1500-1999 1500-1999 1000, SACK=1500-2000
2000-2499 2000-2499 1000, SACK=1500-2500
2500-2999 2500-2999 1000, SACK=1500-3000
1000-1499 1000-1499 3000, SACK=1000-1500
1000-1499 的包延误了,后续 ACK 都是返回的 1000,触发快速重传一直到 3000 的包。然后之前的 1000-1499 包发送过来了,此时的 SACK 也在 ACK 范围内,所以也是 D-SACK。发送方由此得知是网络延迟而不是包或者ACK丢了
流量控制(滑动窗口)
为了可靠传输,TCP 需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包
TCP 里有一个字段叫 Window,又叫 Advertised-Window,表示接收端还有多少缓冲区可以接收数据。发送端根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。
发送方的滑动窗口示意图:
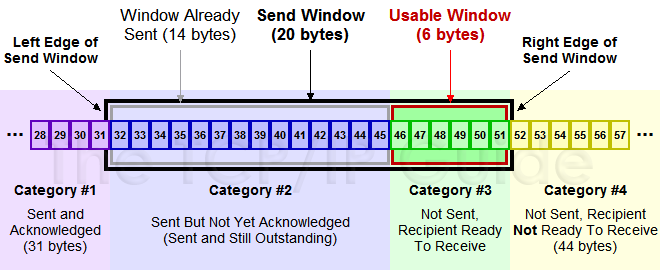
- #1已收到 ack 确认的数据。
- #2发出去还没收到 ack 的。
- #3在窗口中还没有发出的(接收方还有空间)。
- #4窗口以外的数据(接收方没空间)
Zero Window
如果 server 处理数据慢导致没有及时取走窗口中的数据并发送 ACK,server 的滑动窗口会慢慢变成 0,从而导致发送方的滑动窗口也变成0。此时 TCP 使用 ZWP(Zero Window Probe技术):发送端在窗口变成0后,会发ZWP的包给接收方,让接收方来 ack 他的 Window 尺寸,一般会发3次。如果3次过后还是0的话,有的 TCP 实现就会发 RST 把链接断了。
Silly Window Syndrome(糊涂窗口综合症)
当滑动窗口很小时,再发送数据会浪费带宽。为了发送几个字节的数据,需要搭上TCP+IP头的40个字节,TCP 的 RFC 还规定任何一个 IP 设备都得最少接收576尺寸的大小。
解决方法:接收端和发送端一般都采取延时传输的思路,等待数据量大之后再传
拥塞控制
TCP 通过一个 timer 采样了 RTT 并计算 RTO(Retransmission Timeout),如果网络上的延时突然增加,TCP 重传数据,但是本来网络就不好,这样导致网络中堵塞的数据越来越多,加大网络负担
于是引入了拥塞控制:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复
MSS(最大分段大小),对于以太网来说,MTU是1500字节,除去TCP+IP头的40个字节,真正的数据传输可以有1460,这就是MSS(Max Segment Size)
cwnd Congestion Window (拥塞窗口),发送端控制
ssthresh slow start threshold 慢开始阈值,一般值是65535,2^16
慢启动
1)连接建好的开始先初始化cwnd = 1,表明可以传一个 MSS 大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数上升
4)还有一个 ssthresh,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
如果网速很快的话,ACK 也会返回得快,RTT 也会短,那么慢启动就一点也不慢
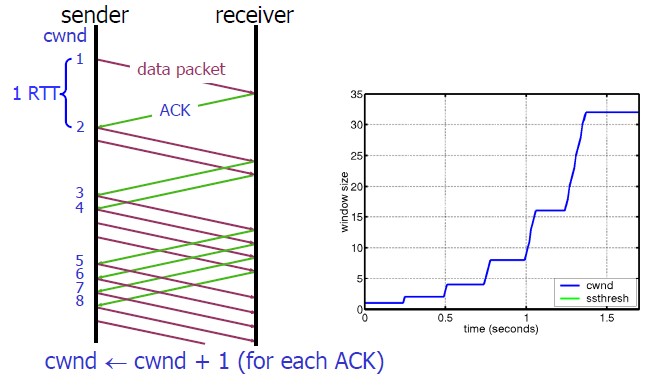
拥塞避免
当 cwnd 达到 ssthresh 时,算法如下:
1)收到一个 ACK 时,cwnd = cwnd + 1/cwnd(基本不变)
2)当每过一个 RTT 时,cwnd = cwnd + 1(完成一个加一个)
拥塞发生(拆分了就是重传+恢复)
在这里触发重传机制,丢包时有两种情况:
1)初级:等到 RTO 超时,重传数据包。TCP 认为这种情况太糟糕,反应也很强烈。
- sshthresh = cwnd /2
- cwnd 重置为 1
- 进入慢启动过程
2)中级:Fast Retransmit 算法,也就是在收到3个duplicate ACK 时就开启重传,而不用等到RTO超时。
- TCP Tahoe的实现和 RTO 超时一样。
- TCP Reno 的实现是:
- cwnd = cwnd /2
- sshthresh = cwnd
- 进入快速恢复算法——Fast Recovery
快速恢复算法 – Fast Recovery
cwnd 窗口表示的是发送频率,快速重传和快速恢复算法一般同时使用。快速恢复算法认为,你还有3个 Duplicated Acks 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈
使用 TCP Reno 算法时,此时 cwnd 和 sshthresh 被重传机制更新:
- cwnd = cwnd /2
- sshthresh = cwnd
快速恢复算法执行如下:先加3、再重传、旧ACK则+1、新ACK则表示全部收到进入拥塞避免
-
cwnd = ssthresh + 3 * MSS (3表示有三个包发出去但是没有确认,如果也算在内会导致可继续发的包很少)
-
发送方重传 Duplicated ACKs 指定的数据包(已丢失的)
-
如果再收到 duplicated Acks,那么cwnd = cwnd +1 (又有丢失的包后面的包被接收,窗口变大)
-
如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了(重传的包被接收,ACK 返回目前收到的最后面的数据包)
通俗解释:你既然收到 3 Dup-ACK,乐观一点,也就是丢失报文(假设序号n)之后的报文中,起码有三个已经发送成功了。那我先给你一点透支额度,不让你cwnd=cwnd/2了,而是cwnd=cwnd/2+3,3就是给你的透支额度。之后呢,我也不让你线性缓慢增长,而是假设你收到的每个ACK,都意味着有一个后面的报文发送成功了(n+x),我都会给你透支额度(此时每个dupACK都让窗口加1,就是允许你多发)。
等到你收到一个新鲜的ACK,也就是之前丢失的报文重传成功了,你要把额度都还给我,重新回到你原有的大小。因此你看到cwnd=ssthresh,cwnd变小了。其实这是在还账,因为你本来就应该在 MD 的时候变成这么大的。
如果不这么干直接变成1/2,结果是发送方先几乎停止发送,忽然移动大范围窗口又达到很高的发送频率。
UDP
主要特点
- 无连接。减少了开销和发送数据之前的时延
- 尽最大努力交付。不需要维持复杂的连接状态表
- 面向报文(TCP面向字节流)。UDP 对应用层交下来的报文,既不合并,也不拆分,直接发送。TCP 有一个缓冲,会把较长的数据块划分短一点,也会积累足够的字节在构成报文段发送
- 没有拥塞控制、流量控制
- 首部开销小,只有8个字节,比 TCP 的20个字节的首部要短
- 支持一对一、一对多、多对一和多对多的交互通信
头部格式
包括源端口号、目标端口号、数据包长度、检验和
检验和在接收方收到数据后会重新算一次看是否匹配
设计架构
MVC
M:Model 数据模型
V:View 界面视图
C:Controller 控制器,协调用户操作、Model、 View
最原始的 MVC 通信都是单向的
服务端 MVC
Spring MVC 等 Model 一般存储在数据库中。View 通常是编写的页面模板,模板与 Model 绑定,在里面通过变量嵌入动态数据。Controller 一般处理 Web 前端请求
客户端 MVC
用户在 view 上输入,controller 进行逻辑判断,通知 model 中的数据改变,最后反映到 view 上发生视图改变
缺点:controller 会慢慢变的越来越臃肿,因为包含了所有 view 的业务逻辑操作。v 和 c 过于紧密,不是可复用的。
MVP
-
Passive View(被动视图模式)
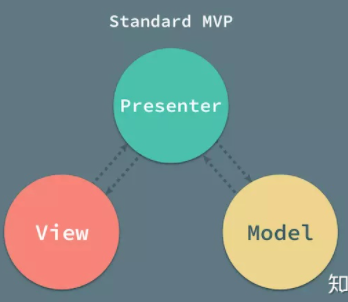
这个模式下 View 是完全被动的,只有显示数据逻辑和触发操作入口,所有的逻辑都由 Presenter 承担。View 和 Model 不直接交互,Presenter 将数据通过 View 的接口设置到视图控件上,同时负责响应 View 的事件,做出处理,根据需要更新 Model,然后触发视图重新加载或者刷新。(类似发布订阅的感觉)
-
Supervising Controller(监督控制器)
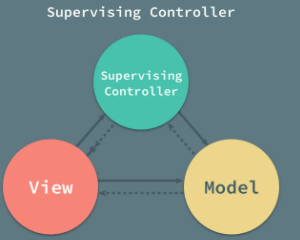
被动视图模式中 View 必须提供非常多的接口,有些繁琐。监督控制器模式 View 可以与 Model 进行通信,少了一层中间层,做一些简单的 UI 与数据的交互
MVVM
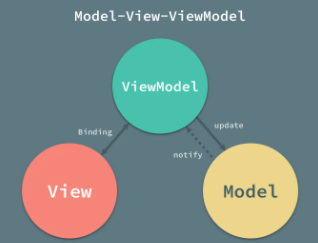
首先在 View 和 ViewModel 中需要进行绑定,省去了 MVP 中视图与数据需要通过接口通信。VM 和 model 之间可以双向通信,当 model 处理完业务逻辑更新数据后通知 VM,然后自动更新 View
单点登录
同域名下的单点登录
利用 Cookie 的特点:domain 属性设置为当前域的父域,父域的 cookie 会被子域所共享
操作:将 Cookie 的 domain 属性设置为父域的域名(主域名),同时将 Cookie 的 path 属性设置为根路径。这样 token 被保存到父域中即可让所有子域访问
不同域名下的单点登录
使用一个认证中心,专门处理登录请求、
1、应用A发现用户未登录,url 跳转到认证中心并携带当前网址用做回调
2、用户在认证中心登录之后,生成一个 cookie 在用户浏览器中,并跳回到之前页面并在 url 上携带 token
3、应用A读取token,发送到认证中心进行校验,登录成功
4、应用B打开之后无 token 未登录,跳转到认证中心,由于 cookie 的存在进行检查,如果登录有效直接跳回应用B并携带 token,应用B进行校验登录成功

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)