30.flink table 中的数据类型映射
flinkTable中的所有数据类型都是class封装的,在这之中有一个基类: org.apache.flink.table.types.DataType,所有的类型都是该类的实现类。除此之外Flinktable还提供了一个final类型的类,该类提供了大量的静态方法可以指定访问实现了 org.apache.flink.table.types.DataType接口的真正实现类, 这个final类型
数据类型映射
-
- 基类
- 导入所有的类型
- flink table类型和java的映射
-
- 1.CHAR
- 2.VARCHAR / STRING
- 3.BINARY
- 4.VARBINARY / BYTES
- 5.DECIMAL
- 5.TINYINT
- 6.SMALLINT
- 7.INT
- 8.BIGINT
- 9.FLOAT
- 10.DOUBLE
- 11.DATE
- 12.TIME
- 13.TIMESTAMP
- 14.TIMESTAMP WITH TIME ZONE
- 15.TIMESTAMP_LTZ
- 16.INTERVAL YEAR TO MONTH
- 17.INTERVAL DAY TO SECOND
- 18.ARRAY
- 19.MAP
- 20.MULTISET
- 21.ROW
- 22.User-Defined Data Types
- 23.BOOLEAN
- 24.RAW
- 25.NULL
- 26.默认映射推断表
基类
flinkTable中的所有数据类型都是class封装的,在这之中有一个基类: org.apache.flink.table.types.DataType, 所有的类型都是该类的实现类。感兴趣的可以骑点开源码看一下。 除此之外Flink table还提供了一个final类型的类,该类提供了大量的静态方法可以指定访问实现了 org.apache.flink.table.types.DataType接口的真正实现类, 这个final类型的类是: org.apache.flink.table.api.DataTypes
flink table支持的所有的类都可以由: org.apache.flink.table.api.DataTypes直接访问到。
导入所有的类型
上面的图片是目前flink table中支持的所有的类型,如果你点开DataTypes的源码你会发现其上图中的每一个都是静态方法。java在 JDK 1.5 之后增加了一种静态导入的语法,用于导入指定类的某个静态成员变量、方法或全部的静态成员变量、方法。如果一个类中的方法全部是使用 static 声明的静态方法,则在导入时就可以直接使用 import static 的方式导入。
为了使代码的可读性更强我们可以:
import static org.apache.flink.table.api.DataTypes.*;
然后代码中就可以直接用了,比如: INT(), FLOAT(), 就这样直接用即可。
flink table类型和java的映射
1.CHAR
- flink sql: CHAR CHAR(n)
- java:DataTypes.CHAR(n)
- Bridging to JVM Types:
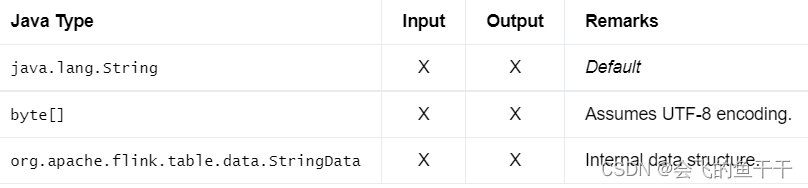
意思是:flink sql语句中使用的类型是CHAR, 对应的Flink 中的实现类是:DataTypes.CHAR(n), 与此同时当table-to-DataStream 的时候对应的java最终的类型是图中的描述。 一般有一个默认值,Default标注的行为默认值。如果你想更改默认行为可以用:
DataType t = DataTypes.CHAR(3).bridgedTo(byte[].class);//这是一个例子,其他的也是一样
接下来的介绍都按照这个结构来介绍。
2.VARCHAR / STRING
- flink sql: VARCHAR/VARCHAR(n)/STRING
- java:DataTypes.VARCHAR(n)/DataTypes.STRING()
- Bridging to JVM Types:
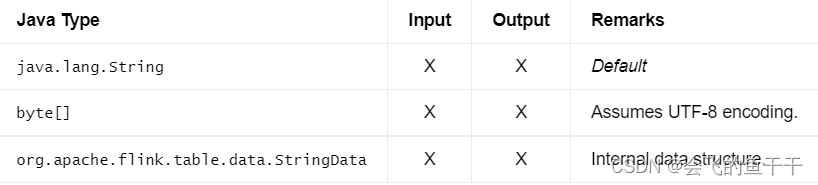
3.BINARY
- flink sql:BINARY/BINARY(n)
- java:DataTypes.BINARY(n)
- Bridging to JVM Types:
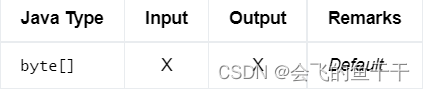
4.VARBINARY / BYTES
- flink sql:VARBINARY/VARBINARY(n)/BYTES
- java:DataTypes.VARBINARY(n)/DataTypes.BYTES()
- Bridging to JVM Types:

5.DECIMAL
-
flink sql:
DECIMAL
DECIMAL§
DECIMAL(p, s)DEC DEC(p) DEC(p, s) NUMERIC NUMERIC(p) NUMERIC(p, s) -
java:DataTypes.DECIMAL(p, s)
-
Bridging to JVM Types:

5.TINYINT
Data type of a 1-byte signed integer with values from -128 to 127.
- flink sql:TINYINT
- java:DataTypes.TINYINT()
- Bridging to JVM Types:
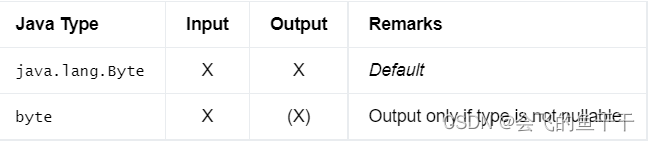
6.SMALLINT
Data type of a 2-byte signed integer with values from -32,768 to 32,767.
- flink sql:SMALLINT
- java:DataTypes.SMALLINT()
- Bridging to JVM Types:

7.INT
Data type of a 4-byte signed integer with values from -2,147,483,648 to 2,147,483,647.
- flink sql:INT/INTEGER
- java:DataTypes.INT()
- Bridging to JVM Types:

8.BIGINT
Data type of an 8-byte signed integer with values from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807.
- flink sql:IBIGINT
- java:DataTypes.BIGINT()
- Bridging to JVM Types:
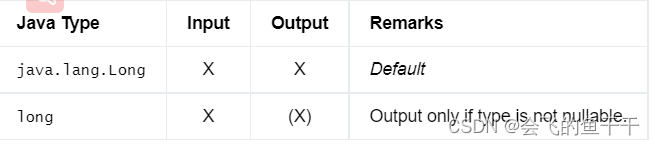
9.FLOAT
4字节单精度浮点数的数据类型。与SQL标准相比,该类型不接受参数
- flink sql:FLOAT
- java:DataTypes.FLOAT()
- Bridging to JVM Types:
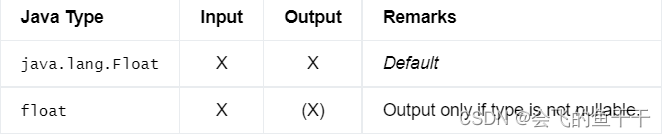
10.DOUBLE
8字节双精度浮点数的数据类型。
- flink sql:DOUBLE/DOUBLE PRECISION
- java:DataTypes.DOUBLE()
- Bridging to JVM Types:

11.DATE
日期的数据类型,取值范围为0000-01-01 ~ 99999-12-31。
与SQL标准相比,范围从0000年开始。
- flink sql:DATE
- java:DataTypes.DATE()
- Bridging to JVM Types:
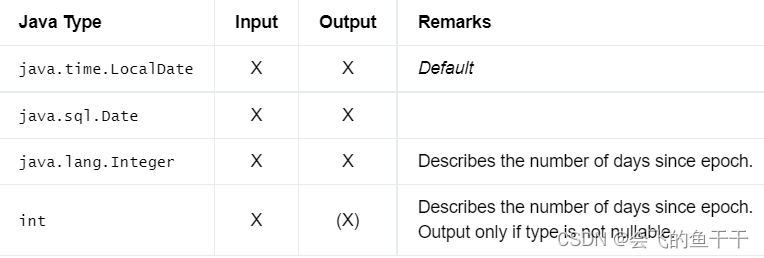
12.TIME
不带时区的时间数据类型,由小时:分:秒[.分数]组成,精度不超过纳秒,取值范围为00:00:00.000000000 ~ 23:59:59.999999999。
- flink sql:DataTypes.TIME§ //p表示精度位数(毫秒3,微秒6,纳秒9)
- java:DataTypes.TIME§
- Bridging to JVM Types:

13.TIMESTAMP
不带时区的时间戳数据类型,由年-月-日小时:分:秒[.分数]组成,精度不超过纳秒,取值范围为00000-01-01 00:00:00.000000000至99999-12-31 23:59:59.999999999。
- flink sql:
TIMESTAMP
TIMESTAMP§
TIMESTAMP WITHOUT TIME ZONE
TIMESTAMP§ WITHOUT TIME ZONE - java:DataTypes.TIMESTAMP§
- Bridging to JVM Types:
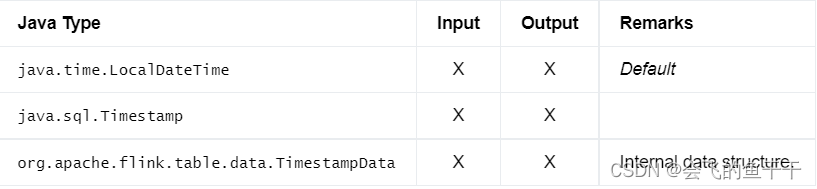
14.TIMESTAMP WITH TIME ZONE
时间戳的数据类型,该时间戳的时区由年-月-日小时:分:秒[.分数]区域组成,精度不超过纳秒,取值范围从0000001-01 00:00:00.000000000 +14:59到999912-31 23:59:59 999999999 -14:59。
与TIMESTAMP_LTZ相比,时区偏移信息物理地存储在每个数据中。它单独用于每个计算、可视化或与外部系统的通信
- flink sql:
TIMESTAMP WITH TIME ZONE
TIMESTAMP§ WITH TIME ZONE - java:DataTypes.TIMESTAMP_WITH_TIME_ZONE§
- Bridging to JVM Types:
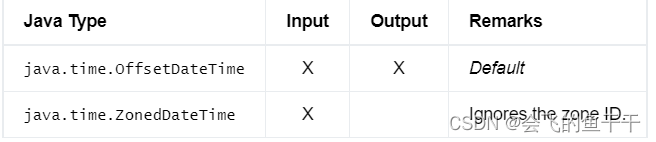
15.TIMESTAMP_LTZ
本地时区由年-月-日小时:分:秒[.分数]区域组成的时间戳的数据类型,精度不超过纳秒,取值范围为0000001-01 00:00:00.000000000 +14:59到999912-31 23:59:59 999999999 -14:59。
与TIMESTAMP WITH TIME ZONE相比,时区偏移信息不是物理地存储在每个数据中。相反,该类型假设表生态系统边缘的UTC时区中的java.time.Instant语义。每个数据都在当前会话中配置的本地时区进行解释,以便计算和可视化
这种类型通过允许根据配置的会话时区解释UTC时间戳,填补了非时区和时区强制时间戳类型之间的空白。
类型可以使用TIMESTAMP_LTZ§声明,其中p是小数秒的位数(精度)。P的值必须在0到9之间(两者都包括在内)。如果不指定精度,则p等于6。
- flink sql:
TIMESTAMP_LTZ
TIMESTAMP_LTZ§
TIMESTAMP WITH LOCAL TIME ZONE
TIMESTAMP§ WITH LOCAL TIME ZONE - java:
DataTypes.TIMESTAMP_LTZ§
DataTypes.TIMESTAMP_WITH_LOCAL_TIME_ZONE§ - Bridging to JVM Types:

16.INTERVAL YEAR TO MONTH
- flink sql:
INTERVAL YEAR
INTERVAL YEAR§
INTERVAL YEAR§ TO MONTH
INTERVAL MONTH - java:
DataTypes.INTERVAL(DataTypes.YEAR())
DataTypes.INTERVAL(DataTypes.YEAR§)
DataTypes.INTERVAL(DataTypes.YEAR§, DataTypes.MONTH())
DataTypes.INTERVAL(DataTypes.MONTH()) - Bridging to JVM Types:
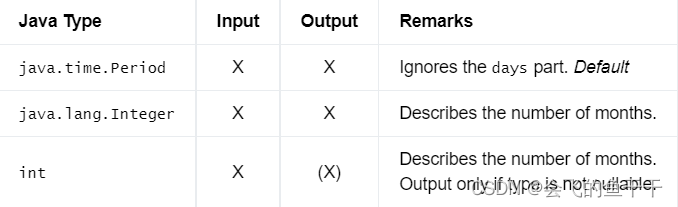
17.INTERVAL DAY TO SECOND
类型可以使用上面的组合来声明,其中p1是天的位数(日精度),p2是小数秒的位数(小数精度)。P1的值必须在1到6之间(两者都包括在内)。P2的值必须在0到9之间(包括两者)。如果不指定p1,默认值为2。如果不指定p2,默认值为6。
- flink sql:
INTERVAL DAY
INTERVAL DAY(p1)
INTERVAL DAY(p1) TO HOUR
INTERVAL DAY(p1) TO MINUTE
INTERVAL DAY(p1) TO SECOND(p2)
INTERVAL HOUR
INTERVAL HOUR TO MINUTE
INTERVAL HOUR TO SECOND(p2)
INTERVAL MINUTE
INTERVAL MINUTE TO SECOND(p2)
INTERVAL SECOND
INTERVAL SECOND(p2) - java:
DataTypes.INTERVAL(DataTypes.DAY())
DataTypes.INTERVAL(DataTypes.DAY(p1))
DataTypes.INTERVAL(DataTypes.DAY(p1), DataTypes.HOUR())
DataTypes.INTERVAL(DataTypes.DAY(p1), DataTypes.MINUTE())
DataTypes.INTERVAL(DataTypes.DAY(p1), DataTypes.SECOND(p2))
DataTypes.INTERVAL(DataTypes.HOUR())
DataTypes.INTERVAL(DataTypes.HOUR(), DataTypes.MINUTE())
DataTypes.INTERVAL(DataTypes.HOUR(), DataTypes.SECOND(p2))
DataTypes.INTERVAL(DataTypes.MINUTE())
DataTypes.INTERVAL(DataTypes.MINUTE(), DataTypes.SECOND(p2))
DataTypes.INTERVAL(DataTypes.SECOND())
DataTypes.INTERVAL(DataTypes.SECOND(p2)) - Bridging to JVM Types:
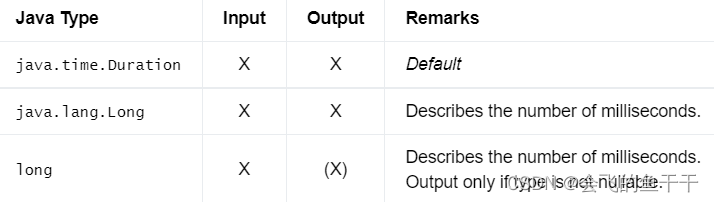
18.ARRAY
具有相同子类型的元素数组的数据类型。
与SQL标准相比,数组的最大基数不能指定,但固定为2,147,483,647。此外,任何有效类型都支持作为子类型。
- flink sql:
ARRAY
t ARRAY - java:DataTypes.ARRAY(t)
- Bridging to JVM Types:
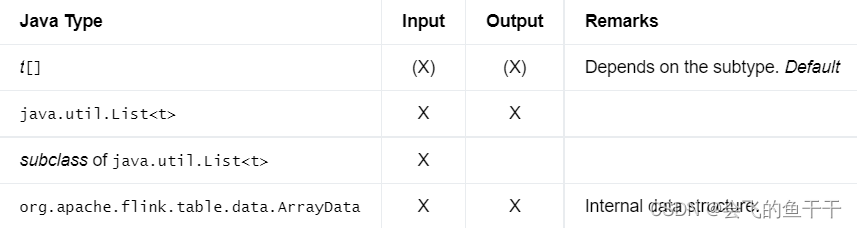
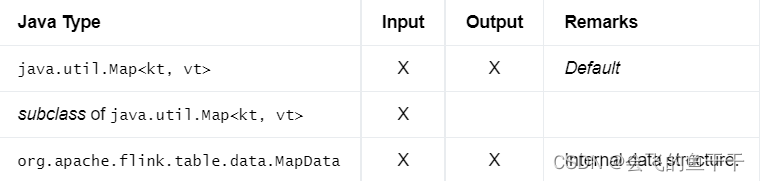
19.MAP
- flink sql:MAP<kt, vt>
- java:DataTypes.MAP(kt, vt)
- Bridging to JVM Types:
20.MULTISET
Data type of a multiset (=bag). Unlike a set, it allows for multiple instances for each of its elements with a common subtype. Each unique value (including NULL) is mapped to some multiplicity.
元素类型没有限制;确保唯一性是用户的责任。
- flink sql:
MULTISET
t MULTISET - java:DataTypes.MULTISET(t)
- Bridging to JVM Types:
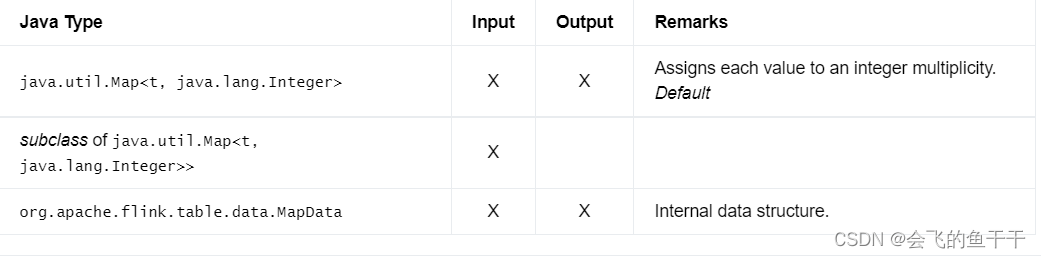
因为允许重复,因此转换结果用Map<value,num>来存储,第一个是值,第二个是该值在集合中出现的次数。
21.ROW
Data type of a sequence of fields.
A field consists of a field name, field type, and an optional description. The most specific type of a row of a table is a row type. In this case, each column of the row corresponds to the field of the row type that has the same ordinal position as the column.
Compared to the SQL standard, an optional field description simplifies the handling with complex structures.
A row type is similar to the STRUCT type known from other non-standard-compliant frameworks.
翻译:
字段序列的数据类型。
字段由字段名、字段类型和可选的描述组成。表中行最具体的类型是行类型。在本例中,行中的每一列都对应于与列的序号位置相同的行类型的字段。
与SQL标准相比,可选字段描述简化了复杂结构的处理。 行类型类似于其他非标准兼容框架中的STRUCT类型。
你可以类比C语言的STRUCT。
- flink sql:
ROW<n0 t0, n1 t1, …>
ROW<n0 t0 ‘d0’, n1 t1 ‘d1’, …>
ROW(n0 t0, n1 t1, …>
ROW(n0 t0 ‘d0’, n1 t1 ‘d1’, …) - java:
DataTypes.ROW(DataTypes.FIELD(n0, t0), DataTypes.FIELD(n1, t1), …)
DataTypes.ROW(DataTypes.FIELD(n0, t0, d0), DataTypes.FIELD(n1, t1, d1), …) - Bridging to JVM Types:

22.User-Defined Data Types
指的是用户自定义的类型,一般指的是我们自己定义的class类对象。但是class必须符合下面的规范。
- The class must be globally accessible which means it must be declared
public, static, and not abstract.
翻译—>class 必须是public 修饰的,或者是static修饰的,且不能是抽象类,- The class must offer a default
constructor with zero arguments or a full constructor that assigns all
fields.
翻译—>class 必须提供一个无参的构造方法,或者一个赋值所有字段的完整构造函数。- 所有的字段要么用public 修饰, 要么提供public 的get/set 方法,二者必须满足其一。
- All fields must be mapped to a data type either implicitly
via reflective extraction or explicitly using the @DataTypeHint
annotations.
翻译–>所有字段必须通过反射提取隐式映射到数据类型,或者使用@DataTypeHint注释显式映射到数据类型。- Fields that are declared static or transient are ignored.
翻译–>声明为静态或暂态的字段将被忽略。
只要字段类型不(传递地)引用自身,反射提取就支持字段的任意嵌套。
声明的字段类(例如public int age;)必须包含在为本文档中每个数据类型定义的支持的JVM桥接类列表中(例如java.lang.Integer或int for int)。
对于某些类,为了将类映射到数据类型(例如@DataTypeHint(“DECIMAL(10, 2)”),需要使用注释来为java.math.BigDecimal分配固定的精度和比例)。
例子:
class User {
// extract fields automatically
public int age;
public String name;
// enrich the extraction with precision information
public @DataTypeHint("DECIMAL(10, 2)") BigDecimal totalBalance;
// enrich the extraction with forcing using RAW types
public @DataTypeHint("RAW") Class<?> modelClass;
}
- flink sql:
不支持 - java:
DataTypes.of(User .class); - Bridging to JVM Types:
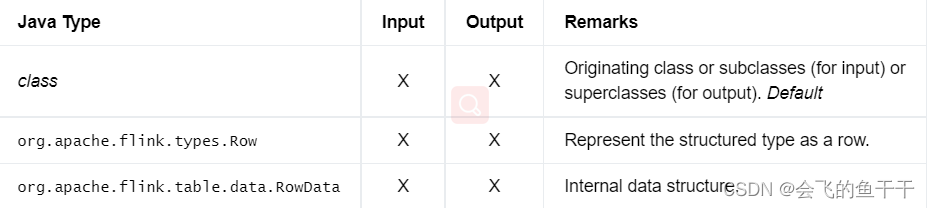
table-to-datastream 的时候如果不提供转化的自定义的类,则默认用Row包装行数据。
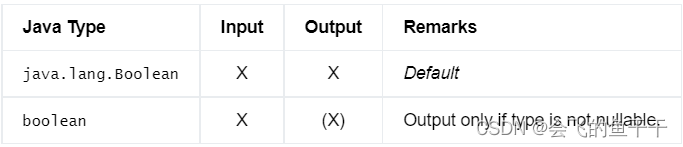
23.BOOLEAN
- flink sql:BOOLEAN
- java:
DataTypes.BOOLEAN() - Bridging to JVM Types:
24.RAW
任意序列化类型的数据类型。这种类型是表生态系统中的黑箱,在flink识别到无法转化的行数据时候会用RAW包装,这是个黑盒。 The raw type is an extension to the SQL standard.
- flink sql:RAW(‘class’, ‘snapshot’)
- java:
DataTypes.RAW(class, serializer)
DataTypes.RAW(class) - Bridging to JVM Types:
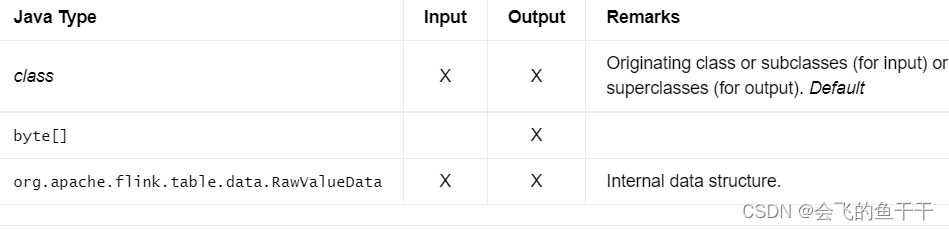
The type can be declared using RAW(‘class’, ‘snapshot’) where class is the originating class and snapshot is the serialized TypeSerializerSnapshot in Base64 encoding. Usually, the type string is not declared directly but is generated while persisting the type.
In the API, the RAW type can be declared either by directly supplying a Class + TypeSerializer or by passing Class and letting the framework extract Class + TypeSerializer from there.
25.NULL
表示非类型化NULL值的数据类型。
null类型是SQL标准的扩展。空类型除了null之外没有其他值,因此,它可以转换为任何可空类型,类似于JVM语义。
这种类型有助于在使用NULL字面量的API调用中表示未知类型,以及桥接到定义此类类型的JSON或Avro等格式。
这种类型在实践中不是很有用,这里只是为了完整而提及。
- flink sql:NULL
- java:
DataTypes.NULL() - Bridging to JVM Types:
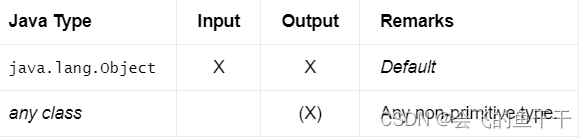
26.默认映射推断表
在API中的许多位置,Flink试图使用反射从类信息中自动提取数据类型,以避免重复的手动模式工作。但是,反射式提取数据类型并不总是成功的,因为逻辑信息可能会丢失。因此,可能有必要在类或字段声明附近添加额外的信息,以支持提取逻辑。
下表列出了可以隐式映射到数据类型而不需要进一步信息的类。
| Class | Data Type |
|---|---|
| java.lang.String | STRING |
| java.lang.Boolean | BOOLEAN |
| boolean | BOOLEAN NOT NULL |
| java.lang.Byte | TINYINT |
| byte | TINYINT NOT NULL |
| java.lang.Short | SMALLINT |
| short | SMALLINT NOT NULL |
| java.lang.Integer | INT |
| int | INT NOT NULL |
| java.lang.Long | BIGINT |
| long | BIGINT NOT NULL |
| java.lang.Float | FLOAT |
| float | FLOAT NOT NULL |
| java.lang.Double | DOUBLE |
| double | DOUBLE NOT NULL |
| java.sql.Date | DATE |
| java.time.LocalDate | DATE |
| java.sql.Time | TIME(0) |
| java.time.LocalTime | TIME(9) |
| java.sql.Timestamp | TIMESTAMP(9) |
| java.time.LocalDateTime | TIMESTAMP(9) |
| java.time.OffsetDateTime | TIMESTAMP(9) WITH TIME ZONE |
| java.time.Instant | TIMESTAMP_LTZ(9) |
| java.time.Duration | INVERVAL SECOND(9) |
| java.time.Period | INTERVAL YEAR(4) TO MONTH |
| byte[] | BYTES |
| T[] | ARRAY |
| java.util.Map<K, V> | MAP<K, V> |
| structured type T | anonymous structured type T |
例子:
package com.redis.ip.parse.flink.tableAndsql.pojo;
import org.apache.flink.table.annotation.DataTypeHint;
import java.sql.Timestamp;
public class Animal {
public String name;
@DataTypeHint(value = "TIMESTAMP(3)", bridgedTo = java.sql.Timestamp.class)
public Timestamp my_time;
public Animal() {
}
public Animal(String name, Timestamp my_time) {
this.name = name;
this.my_time = my_time;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Timestamp getMy_time() {
return my_time;
}
public void setMy_time(Timestamp my_time) {
this.my_time = my_time;
}
}
public class TypeBridge {
public static void main(String[] args) {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
long time = System.currentTimeMillis();
DataStream<Animal> ds = env.fromElements(
new Animal("麻雀", new Timestamp(time+1000)),
new Animal("麻雀", new Timestamp(time+2000)),
new Animal("麻雀", new Timestamp(time+3000)),
new Animal("老虎", new Timestamp(time+1000)),
new Animal("老虎", new Timestamp(time+20000)),
new Animal("老虎", new Timestamp(time+30000))
);
// DataType t = DataTypes.TIMESTAMP(3).bridgedTo(java.sql.Timestamp.class);
Schema schema = Schema.newBuilder()
// .columnByExpression("","cast(my_time as TIMESTAMP(3))")
.watermark("my_time","my_time - INTERVAL '2' MILLIONS").build();
Table table = tableEnv.fromDataStream(ds,schema);
table.printSchema();
}
}
根据表格我们知道: java.sql.Timestamp -->TIMESTAMP(9) ,
但是水位线时间要求TIMESTAMP(p) p取值范围最大为3,否则抛出异常。 因此我在字段注解了:
@DataTypeHint(value = “TIMESTAMP(3)”, bridgedTo = java.sql.Timestamp.class) ,意思是用TIMESTAMP(3)做映射,而不是用默认的TIMESTAMP(9), 理论上我的逻辑应该是对的,不幸的是依旧报错如下:
此问题如果后续解决我会更新文章,也期待有小伙伴知道。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)