别再乱用数据集成工具了!数据入仓时如何匹配可视化需求?
ETL 工具的价值,并不在于其本身有多么复杂的技术,而在于它能否为可视化提供高质量、结构化的数据基础。对于企业来说,不能仅仅从技术角度去看待 ETL 工具,而是要从实际的可视化需求出发,反向推导 ETL 的设计和实施。在数据入仓阶段,就要提前预埋好分析所需的维度,预判可能出现的数据质量风险,这样才能让可视化真正成为决策的有力支撑,成为决策者洞察业务的 “眼睛”。正如 Gartner 所言:“未来五
在数据驱动的决策时代,ETL(Extract, Transform, Load)工具是数据入仓的核心技术,但许多企业却因误用工具而导致数据质量低下、可视化结果失真。据统计,45%的ETL项目超预算,56%未能实现预期价值。究其根源,问题往往出在未将ETL流程与最终的可视化需求对齐。本文从数据质量、工具适配、架构设计等角度,探讨如何避免“工具滥用”,找到匹配企业级可视化需求的ETL工具实现数据入仓与可视化的无缝衔接。
一、ETL的实质是什么
ETL 的实质是为满足特定的数据使用需求,对来自不同源的数据进行抽取、转换和加载,以确保数据的准确、可用和高效。
1.数据抽取
从各种源系统,如数据库、文件系统、外部数据源等,提取数据。这是一个基础步骤,涉及确定数据源、连接数据源以及选择需要抽取的数据。例如,从企业的销售管理系统抽取销售订单数据。
2.数据转换
对抽取的数据进行一系列的处理和转换,以确保数据的质量和一致性。这包括数据清理,如去除重复数据、填补缺失值;数据格式转换,如日期格式、数值格式的统一;数据集成,将多个数据源的数据进行合并和关联;以及数据映射,将数据转换为适合目标系统的格式。例如,将不同地区销售数据中的产品名称统一为标准格式。
3.数据加载
将转换后的数据加载到目标数据仓库或数据湖中。这一步骤需要考虑数据的存储结构、数据的插入方式以及数据的更新策略。例如,将经过清洗和整理的销售数据加载到企业的数据分析平台,以便进行后续的商业智能分析和数据挖掘。
通过 ETL 过程,可以将分散、异构、不一致的数据,转换为统一、干净、结构化的数据,以支持决策支持、数据挖掘、数据分析等不同的数据使用需求。
二、ETL 工具的常见误区:为何你的可视化结果总出问题?
(一)忽视数据质量的 “隐形杀手”
数据源系统为了追求性能,常常会舍弃一些约束机制,像是字段校验、外键关联等。这就导致了一系列的数据问题,例如数据格式错误,像出现非法日期、缺失身份证号等情况;还有一致性缺失的问题,比如用户 ID 在账务表中有记录,可用户表里却找不到对应记录。这些看似只是些微小的差错,但在进行可视化呈现时,就会被极大地放大,造成图表失真或者误导决策的严重后果。举个例子,数据里存在缺失值,放到折线图里,就会导致折线出现断点,影响对数据趋势的判断;而外键不一致的情况,则可能引发仪表盘上的指标相互矛盾,让决策者无从下手。
(二)低估数据转换的复杂性
在 ETL 过程里,仅仅完成所谓的 “基础清洗” 远远不够。因为可视化需求往往涉及到多维分析,像是时间序列分析、地域分布展示、用户分群对比等。这就意味着在数据转换阶段,就得预先构建好维度的完整性。比如说,销售数据如果没在 ETL 阶段补充上地域编码或者用户标签,那后续的可视化工具就没办法直接生成热力图来展示不同地区的销售热度,也无法做出分群对比图来分析不同用户群体的购买差异。
(三)技术选型与需求脱节
当下,许多企业在选择 ETL 工具时,存在盲目跟风的情况,要么一股脑儿地选用开源工具,像 Kettle;要么就直接挑商业工具,比如 Informatica。但却没好好考虑这些工具对于可视化场景的支持能力。就拿 Kettle 来说,它的图形界面确实很友好,操作起来相对简单,可一旦遇到处理 NoSQL(Not Only SQL,泛指非关系型数据库)数据的时候,兼容性就差得不行,很容易出问题。而 Talend 虽然支持复杂的数据转换操作,但可能因为内存占用过高,在大规模数据处理时,就会出现性能瓶颈,拖慢整个数据处理流程,影响后续的可视化呈现。
三、如何优化数据可视化效果
(一)冲突点1:转换逻辑与可视化维度不匹配
数据转换逻辑如果不能充分满足可视化需求,就会导致在进行多维分析时,数据维度不完整或不准确,从而无法生成所需的可视化结果。例如,无法支持时间序列分析、地域分布展示、用户分群对比等,影响了数据的深度洞察和决策支持。
1.优化策略
①分层建模
在ETL过程中,构建分层的数据模型,将数据划分为不同层级,如明细层(DWD:Data Warehouse Detail)、汇总层(DWS:Data Warehouse Summary),根据具体的可视化需求,预先计算和存储相应的汇总数据和指标。这样可以确保在数据加载到BI工具时,已经具备完整的维度信息,能够快速响应各类多维分析需求。
②动态参数化
根据可视化工具的使用场景和需求变化,对ETL过程中的数据转换逻辑进行动态参数化设置。在抽取数据阶段,通过参数配置来确定需要抽取的数据字段、过滤条件等;在转换阶段,依据不同可视化需求,灵活地调整数据聚合粒度、计算指标等参数,从而更精准地满足可视化分析的多维度要求。
(二)冲突点2:数据延迟影响实时可视化
实时可视化要求数据能够及时更新和展示,但在传统的ETL流程中,数据抽取、转换和加载过程往往存在一定的延迟,导致无法满足实时监控、实时决策等场景的需求。
优化策略
①混合架构
结合批处理和流处理技术,构建混合的ETL架构。对于需要历史数据支持的分析需求,采用批处理方式处理大规模的历史数据;而对于实时数据,则利用流处理技术,对数据进行实时的抽取、转换和加载,确保数据能够及时地更新到BI工具中,满足实时可视化的需要。
②增量加载
采用增量加载的方式,只同步和加载相对于上一次数据抽取之后发生变更的数据。这可以通过CDC(Change Data Capture,即变更数据捕获)技术来实现。通过识别和捕获数据源中的新增、修改和删除操作,仅将这些变化的数据传输到目标数据仓库中,大大缩短了数据加载的时间,减少了数据延迟,提高数据实时性。
(三)冲突点3:数据清洗过程缺乏透明度
在ETL的数据清洗阶段,如果清洗规则不清晰、不可追溯,就会导致数据质量难以保证,进而影响可视化的准确性和可信度。
优化策略
①可视化清洗日志
将数据清洗的过程和结果以可视化的方式进行记录和展示。通过热力图、散点图等可视化图表,直观地呈现数据清洗前后的缺失值分布、异常值位置等信息,让用户能够清晰地了解数据清洗的效果和数据质量的变化情况,有助于及时发现问题并进行优化。
②规则可追溯
在ETL工具中,对清洗规则的版本和变更历史进行详细记录和管理。当数据出现问题或需要对清洗规则进行调整时,能够快速追溯规则的变更过程,明确规则的执行情况,从而更好地分析和解决问题,提高数据清洗的透明度和可靠性。
四、工具选型:如何匹配企业级可视化需求?
(一)开源工具(如 Kettle)
- 优势 :成本低,这对于预算有限的企业来说,是个很大的吸引力;而且社区活跃,遇到问题时,往往能在社区里找到解决方案或者得到他人的帮助,适合中小型项目使用。
- 局限 :内存占用比较高,在处理大规模数据时,可能会出现性能问题;对 NoSQL 数据的支持也比较弱,如果企业的数据源里有大量的 NoSQL 数据,使用 Kettle 就会比较吃力,这时候可能需要搭配 Python 脚本来增强其灵活性,弥补这方面的不足。
- 适用场景 :主要用于离线报表的生成以及一些低频次的数据分析场景。因为这些场景对实时性要求不高,数据量相对也没那么庞大,Kettle 完全能够胜任。
(二)商业工具(如FineDataLink)
- 优势 :帆软的 FDL(FineDataLink),具备实时数据同步、ETL 和 ELT 定时数据计算等核心能力。它最大的特点是所见即所得,通过简单拖拽就可以处理好数据,这样的话企业内的大部分人都能利用FDL做好数据处理,能满足企业多种场景下的数据预处理需求。
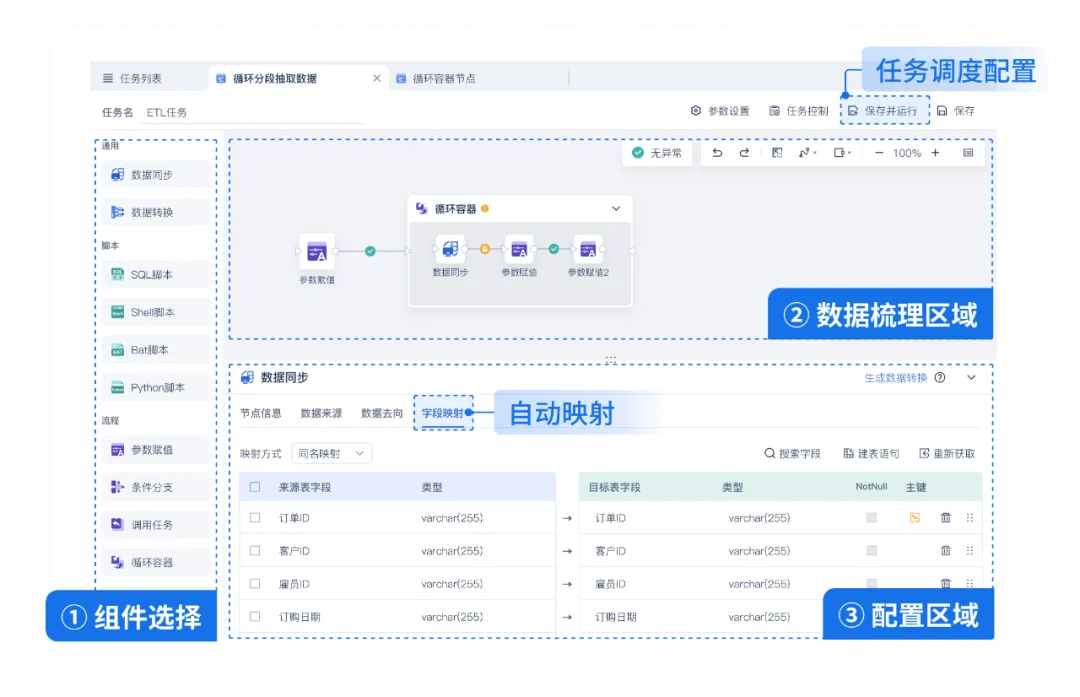
- 适用场景 :适用于高并发的实时大屏展示场景,比如一些大型企业的运营监控中心,需要实时展示大量的业务数据;还有复杂的数据血缘追踪场景,当数据出现问题时,能够快速追溯到数据的源头,找出问题所在。
FineDataLink使用链接:帆软通行证登录
(三)云原生工具(如 AWS Glue)
- 优势 :具备弹性扩缩容的能力,能够根据数据处理的需求,自动调整资源的分配,避免资源浪费;而且能无缝对接云上的 BI(Business Intelligence,商业智能)工具,像 QuickSight,方便企业在云端进行一站式的数据处理和可视化分析。
- 适用场景 :对于处于多云环境中的企业来说,是个不错的选择;同时,如果企业有快速迭代的可视化项目需求,云原生工具也能够很好地适应,快速响应业务的变化。
使用链接:无服务器数据集成 — AWS Glue 数据集成引擎 — AWS
结语
ETL 工具的价值,并不在于其本身有多么复杂的技术,而在于它能否为可视化提供高质量、结构化的数据基础。对于企业来说,不能仅仅从技术角度去看待 ETL 工具,而是要从实际的可视化需求出发,反向推导 ETL 的设计和实施。在数据入仓阶段,就要提前预埋好分析所需的维度,预判可能出现的数据质量风险,这样才能让可视化真正成为决策的有力支撑,成为决策者洞察业务的 “眼睛”。正如 Gartner 所言:“未来五年,80% 的数据项目失败将归因于数据准备与消费场景的割裂。” 只有跳出单纯的 “工具思维”,从整体的业务需求和可视化目标出发,才能让数据真正流动起来,驱动业务的增长。
免费送大家一份《数据仓库建设方案》,包含了数仓的技术架构、数仓建设关键动作、数仓载体/工具、配置参考、大数据场景支撑案例等内容,免费下载:数据仓库建设解决方案 - 帆软数字化资料中心

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 7
7 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)