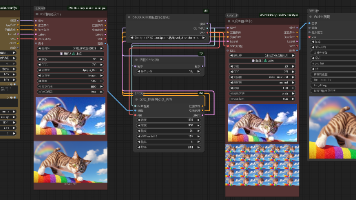
数据增强、yolo格式数据集划分
将原先的labels、images文件夹划分生成test、train、val文件夹。在完成数据增强和数据集划分后,需要创建一个。文件,以供 YOLO 训练使用。
·
1. 数据增强与同步标签 (augment.py)
import cv2
import albumentations as A
import os
def augment_with_labels(image_dir, label_dir, output_image_dir, output_label_dir, num_augmented=5):
"""
对 YOLO 格式的图像和标签进行数据增强。
:param image_dir: 原始图像目录
:param label_dir: 原始标签目录
:param output_image_dir: 增强后的图像保存目录
:param output_label_dir: 增强后的标签保存目录
:param num_augmented: 每张图像生成的增强样本数量
"""
if not os.path.exists(output_image_dir):
os.makedirs(output_image_dir)
if not os.path.exists(output_label_dir):
os.makedirs(output_label_dir)
# 定义增强管道
augmentation_pipeline = A.Compose([
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.2),
A.RandomRotate90(p=0.5),
A.ShiftScaleRotate(shift_limit=0.1, scale_limit=0.2, rotate_limit=30, p=0.5)
], bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))
# 遍历所有图片和标签
for image_name in os.listdir(image_dir):
if image_name.endswith(".jpg") or image_name.endswith(".png"):
# 加载图片
image_path = os.path.join(image_dir, image_name)
image = cv2.imread(image_path)
# 加载对应的标签
label_name = os.path.splitext(image_name)[0] + ".txt"
label_path = os.path.join(label_dir, label_name)
if not os.path.exists(label_path):
print(f"⚠️ 标签文件 {label_path} 不存在,跳过该文件!")
continue
with open(label_path, "r") as file:
lines = file.readlines()
bboxes = []
class_labels = []
for line in lines:
parts = line.strip().split()
class_labels.append(int(parts[0]))
bboxes.append([float(x) for x in parts[1:]])
# 生成增强样本
for i in range(num_augmented):
augmented = augmentation_pipeline(image=image, bboxes=bboxes, class_labels=class_labels)
augmented_image = augmented['image']
augmented_bboxes = augmented['bboxes']
augmented_labels = augmented['class_labels']
# 保存增强后的图片
augmented_image_name = f"{os.path.splitext(image_name)[0]}_aug_{i}.jpg"
cv2.imwrite(os.path.join(output_image_dir, augmented_image_name), augmented_image)
# 保存增强后的标签
augmented_label_name = f"{os.path.splitext(image_name)[0]}_aug_{i}.txt"
with open(os.path.join(output_label_dir, augmented_label_name), "w") as file:
for bbox, label in zip(augmented_bboxes, augmented_labels):
# 确保类别 ID 是整数
file.write(f"{int(label)} {' '.join(map(str, bbox))}\n")
print(f"✅ 增强完成: {image_name}")
if __name__ == "__main__":
# 输入和输出路径
image_dir = "images" # 原始图像目录
label_dir = "labels1" # 原始标签目录
output_image_dir = "augmented_images" # 增强后图像保存目录
output_label_dir = "augmented_labels" # 增强后标签保存目录
# 执行数据增强
augment_with_labels(image_dir, label_dir, output_image_dir, output_label_dir)2.数据集划分 (dataset_split.py):划分images和labels
import os
import shutil
import random
random.seed(0)
def split_data(total_image_path, total_txt_path, split_dataset_path, train_rate, val_rate, test_rate):
# **检查路径是否存在**
if not os.path.exists(total_image_path):
raise FileNotFoundError(f"错误: 图片文件夹 '{total_image_path}' 不存在!")
if not os.path.exists(total_txt_path):
print(f"⚠️ 警告: 标签文件夹 '{total_txt_path}' 不存在,可能缺少部分数据。")
# **获取所有图片文件并过滤非图片文件或子目录**
total_eachclass_image = [
f for f in os.listdir(total_image_path)
if os.path.isfile(os.path.join(total_image_path, f)) and f.lower().endswith(('.jpg', '.jpeg', '.png'))
]
if len(total_eachclass_image) == 0:
raise ValueError("错误: 图片文件夹为空,无法进行数据划分!")
# 打乱数据
random.shuffle(total_eachclass_image)
# 数据集划分
train_end = int(train_rate * len(total_eachclass_image))
val_end = int((train_rate + val_rate) * len(total_eachclass_image))
train_images = total_eachclass_image[:train_end]
val_images = total_eachclass_image[train_end:val_end]
test_images = total_eachclass_image[val_end:]
# 创建目标数据集目录
for dataset_type in ['train', 'val', 'test']:
os.makedirs(os.path.join(split_dataset_path, dataset_type, 'images'), exist_ok=True)
os.makedirs(os.path.join(split_dataset_path, dataset_type, 'labels'), exist_ok=True)
# 复制文件
def copy_files(image_list, dataset_type):
for image in image_list:
img_src = os.path.join(total_image_path, image)
img_dst = os.path.join(split_dataset_path, dataset_type, 'images', image)
shutil.copy(img_src, img_dst)
# 复制对应的标签
txt_name = os.path.splitext(image)[0] + '.txt'
txt_src = os.path.join(total_txt_path, txt_name)
txt_dst = os.path.join(split_dataset_path, dataset_type, 'labels', txt_name)
if os.path.exists(txt_src): # **添加判断,只有存在才复制**
shutil.copy(txt_src, txt_dst)
else:
print(f"⚠️ 警告: {txt_src} 不存在,跳过该文件!")
copy_files(train_images, 'train')
copy_files(val_images, 'val')
copy_files(test_images, 'test')
print(f"✅ 数据集划分完成!训练集: {len(train_images)},验证集: {len(val_images)},测试集: {len(test_images)}")
if __name__ == '__main__':
total_image_path = "images"
total_txt_path = "labels" # 确保 labels 目录存在
split_dataset_path = "dataset_split"
split_data(total_image_path, total_txt_path, split_dataset_path, train_rate=0.7, val_rate=0.2, test_rate=0.1)
将原先的labels、images文件夹划分生成test、train、val文件夹
 --------->
---------> 
3. 生成 dataset.yaml 配置文件
在完成数据增强和数据集划分后,需要创建一个 dataset.yaml 文件,以供 YOLO 训练使用
train、val、test:数据集的存放路径- nc:表示需要识别的目标类别数量。
- names:目标类别的名称列表
train: /root/yolov8/datasets/train
val: /root/yolov8/datasets/val
test: /root/yolov8/datasets/test
# test:后面有一个空格
nc: 1
names: ['car']
4. 文件结构示例
最终,生成的数据集文件结构如下:
dataset_split/
│── train/
│ ├── images/
│ │ ├── img1.jpg
│ │ ├── img2.jpg
│ │ ├── ...
│ ├── labels/
│ ├── img1.txt
│ ├── img2.txt
│ ├── ...
│
│── val/
│ ├── images/
│ ├── labels/
│
│── test/
│ ├── images/
│ ├── labels/
│
│── dataset.yaml # YOLO 数据集配置文件

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)