AI Studio中的视觉数据集合
§01 视觉图像集合在PaddlePaddle环境中,存在 一些自带数据集合 ,其中的机器视觉(vision)数据集合包括:print('Dataset for Vision:', paddle.vision.datasets.__all__)print('Dataset for text:', paddle.text.__all__)Dataset for Vision: ['Dat
简 介: ※对于Paddle中的vision中的图片数据Cifar10, FashionMNIST进行显示与测试。
关键词: Cifar10,FashionMNIST
§01 视觉图像集合
在PaddlePaddle环境中,存在 一些自带数据集合 ,其中的机器视觉(vision)数据集合包括:
print('Dataset for Vision:', paddle.vision.datasets.__all__)
print('Dataset for text:', paddle.text.__all__)
Dataset for Vision: ['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST', 'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']
Dataset for text: ['Conll05st', 'Imdb', 'Imikolov', 'Movielens', 'UCIHousing', 'WMT14', 'WMT16', 'ViterbiDecoder', 'viterbi_decode']
1.1 Cifar10数据集合
Cifar10数据集合是彩色图片,是机器学习以及深度神经网络的重要的数据库。
1.1.1 下载数据集合
(1)下载代码
train_dataset = paddle.vision.datasets.Cifar10(mode='train')
经过14秒左右,数据集合从 https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz下载到本地的 /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz。
Cache file /home/aistudio/.cache/paddle/dataset/cifar/cifar-10-python.tar.gz not found, downloading https://dataset.bj.bcebos.com/cifar/cifar-10-python.tar.gz
Begin to download
Download finished
运行时长:13.845秒结束时间:2021-12-15 11:03:15
(2)下载文件
检查本地的数据文件:
aistudio@jupyter-262579-3225298:~/.cache/paddle/dataset/cifar$ ls
cifar-10-python.tar.gz
将 cifar-10文件拷贝到主目录下,然后下载到电脑本地。
aistudio@jupyter-262579-3225298:~/.cache/paddle/dataset/cifar$ cp * $HOME/.

▲ 图1.1.1 将数据文件下载到本地
在本地打开该压缩包,可以看到其中包含如下的文件。
└─cifar-10-batches-py
batches.meta
data_batch_1
data_batch_2
data_batch_3
data_batch_4
data_batch_5
readme.html
test_batch
在其中的 readme.html包含着对于该数据集合元有连接的说明: CIFAR-10 and CIFAR-100 datasets

▲ 图1.1.2 Cifar-10数据集合
1.1.2 数据文件操作
(1)文件解压缩
首先在AI Studio中,将Cifar-10压缩包移动到**/data**目录下,

▲ 图1.1.3 利用BML 环境下鼠标右键“提取压缩包“将压缩文件加压缩到当前文件下
(2)文件读取
在 CIFAR-10 and CIFAR-100 datasets 网站给出了数据文件的操作方法。
Ⅰ.使用pickle打开文件
filename = 'data/cifar-10-batches-py/data_batch_1'
def unpickle(file):
import _pickle as cPickle
with open(file, 'rb') as f:
dict = cPickle.load(f, encoding='bytes')
return dict
d = unpickle(filename)
Ⅱ.数据格式
print(type(d))
print(len(d))
print(d.keys())
<class 'dict'>
4
dict_keys([b'batch_label', b'labels', b'data', b'filenames'])
Ⅲ.读取各个键值
- batch_label: b’training batch 1 of 5’
- labels:
print(len(d[b'labels']))
print(type([b'labels']))
10000
<class 'list'>
[6, 9, 9, 4, 1, 1, 2, 7, 8, 3, 4, 7, 7, 2, 9, 9, 9, 3, 2, 6, 4, 3, 6, 6, 2, 6, 3, 5, 4, 0, 0, 9, 1, 3, 4, 0, 3, 7, 3, 3, 5, 2, 2, 7, 1, 1, 1, 2, 2, 0, 9, 5, 7, 9, 2, 2, 5, 2, 4, 3, 1, 1,
......
8, 2, 6, 2, 9, 7, 7, 7, 9, 8, 9, 4, 4, 7, 1, 0, 4, 3, 6, 3, 9, 8, 3, 6, 8, 3, 6, 6, 2, 6, 7, 3, 0, 0, 0, 2, 5, 1, 2, 9, 2, 2, 1, 6, 3, 9, 1, 1, 5]
- data:
print(type(d[b'data']))
print(len(d[b'data']))
print(d[b'data'][0].shape)
print(d[b'data'][0])
<class 'numpy.ndarray'>
10000
(3072,)
[ 59 43 50 ... 140 84 72]
可以看到data中是图像的bytes值,它们的格式:
-
The first 1024 entries contain the red channel values
-
the next 1024 the green
-
and the final 1024 the blue.
-
显示data图片:
imgdata = d[b'data'][0]
imgdata = array(zip(imgdata[:1024],
imgdata[1024:1024*2],
imgdata[1024*2:])).reshape(32,32,3)
plt.imshow(imgdata)
plt.show()

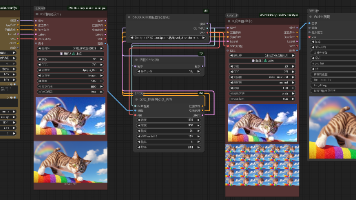
▲ 图1.1.4 第一张图片
plt.figure(figsize=(8,6))
for j in range(3):
for i in range(5):
imgdata = d[b'data'][i+j*5]
imgdata = array(list(zip(imgdata[:1024], imgdata[1024:1024*2], imgdata[1024*2:]))).reshape(32,32,3)
plt.subplot(3,5, j*5+i+1)
plt.axis('off')
plt.imshow(imgdata)
plt.show()

▲ 图1.1.5 数据前15个图片
- filename:
print(d[b'filenames'][:15])
[b’leptodactylus_pentadactylus_s_000004.png’, b’camion_s_000148.png’, b’tipper_truck_s_001250.png’, b’american_elk_s_001521.png’, b’station_wagon_s_000293.png’, b’coupe_s_001735.png’, b’cassowary_s_001300.png’, b’cow_pony_s_001168.png’, b’sea_boat_s_001584.png’, b’tabby_s_001355.png’, b’muntjac_s_001000.png’, b’arabian_s_001354.png’, b’quarter_horse_s_000672.png’, b’passerine_s_000343.png’, b’camion_s_001895.png’]
| leptodactylus | camion | tipper | american | station |
|---|---|---|---|---|
| 钩爪鱼 | 卡米翁 | 自卸车 | 美国公司 | 站 |
| coupe | cassowary | cow | sea | tabby |
| 轿跑 | 鹤鸵 | 牛,母牛 | 海 | 虎斑猫 |
| muntjac | arabian | quarter | passerine | camion |
| 麂 | 阿拉伯人 | 季度 | 雀形目 | 卡米翁 |
1.1.3 数据集合操作
(1)读入数据集合
train_dataset = paddle.vision.datasets.Cifar10(mode='train')
test_dataset = paddle.vision.datasets.Cifar10(mode='test')
(2)显示数据集合
for i in train_dataset:
print(type(i))
print(i[1].shape)
print(type(i[0]))
plt.imshow(i[0])
plt.show()
break
<class 'tuple'>
()
<class 'PIL.Image.Image'>

▲ 图1.1.6 Cifar10图像
from headm import * # =
import paddle
import paddle.nn.functional as F
from paddle import nn
from paddle.metric import accuracy as acc
from paddle.vision.transforms import Compose,Normalize,Resize
from paddle.vision import ToTensor
train_dataset = paddle.vision.datasets.Cifar10(mode='train')
test_dataset = paddle.vision.datasets.Cifar10(mode='test')
for i in train_dataset:
print(type(i))
print(i[1].shape)
print(array(i[0]).swapaxes(0,2))
plt.imshow(i[0])
plt.show()
break
train_dataset[0][0]
class Dataset(paddle.io.Dataset):
def __init__(self, num_samples):
super(Dataset, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
data = array(train_dataset[index][0]).astype('float32').swapaxes(0,2)
label = train_dataset[index][1].astype('int64')
return data, label
def __len__(self):
return self.num_samples
_dataset = Dataset(len(train_dataset))
train_loader = paddle.io.DataLoader(_dataset, batch_size=100, shuffle=True)
data = train_loader().next()
printf(data)
print(train_loader.__len__())
class cifar10(paddle.nn.Layer):
def __init__(self, ):
super(cifar10, self).__init__()
self.cv1 = paddle.nn.Conv2D(in_channels=3, out_channels=6, kernel_size=5, stride=1, padding=0)
self.cv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=84)
self.L3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.cv1(x)
x = F.relu(x)
x = self.mp1(x)
x = self.cv2(x)
x = F.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = F.relu(x)
x = self.L2(x)
x = F.relu(x)
x = self.L3(x)
return x
model = paddle.Model(cifar10())
model.prepare(optimizer=paddle.optimizer.Adam(parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
model.fit(train_loader, epochs=5, batch_size=64, verbose=1)
1.2 FashionMNIST数据集合
对于普通的MNIST数据集合我们比较熟悉,这款FashionMNIST是什么鬼?
在 Fashion-MNIST:替代MNIST手写数字集的图像数据集 给出了Fashion_MNIST的基本介绍。
FashionMNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。

▲ 图1.2.1 Fashion-MNIST数据集合
1.2.1 数据库下载
(1)下载过程
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5], std=[127.5], data_format='CHW')])
train_dataset = paddle.vision.datasets.FashionMNIST(mode='train', transform=transform)
Cache file /home/aistudio/.cache/paddle/dataset/fashion-mnist/train-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/fashion_mnist/train-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/fashion-mnist/train-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/fashion_mnist/train-labels-idx1-ubyte.gz
Begin to download
…
Download finished
(2)下载文件
可以点击:
- https://dataset.bj.bcebos.com/fashion_mnist/train-labels-idx1-ubyte.gz
- https://dataset.bj.bcebos.com/fashion_mnist/train-images-idx3-ubyte.gz
直接下载到fashion_mnist 数据集合。
可以在AI Studio的 **/home/aistudio/.cache/paddle/dataset/fashion-mnist/**看到如下两个数据文件。
train-images-idx3-ubyte.gz
train-labels-idx1-ubyte.gz
1.2.2 数据库显示
(1)数据结构
print(train_dataset)
data_loader = paddle.io.DataLoader(train_dataset, batch_size=16, shuffle=True)
print(train_dataset.__len__())
data = data_loader().next()
print(data)
<paddle.vision.datasets.mnist.FashionMNIST object at 0x7fde091b0a50>
60000
[Tensor(shape=[16, 1, 28, 28], dtype=float32, place=CPUPlace, stop_gradient=True,
[[[[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
...,
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
。。。。。。
[[[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
...,
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ],
[-1. , -1. , -1. , ..., -1. , -1. , -1. ]]]]), Tensor(shape=[16, 1], dtype=int64, place=CPUPlace, stop_gradient=True,
[[0],
[3],
[6],
[1],
[2],
[2],
[7],
[4],
[8],
[3],
[5],
[8],
[1],
[3],
[8],
[5]])]
(2)数据图片
plt.figure(figsize=(5,5))
plt.imshow(data[0][0].numpy().reshape([28,28]), cmap=plt.cm.binary)
plt.show()

▲ 图1.2.2 fashion_mnist第一张图片
plt.figure(figsize=(5,5))
for j in range(3):
for i in range(5):
imgdata = data[0][i+j].numpy().reshape([28,28])
plt.subplot(3,5, j*5+i+1)
plt.axis('off')
plt.imshow(imgdata)
plt.show()

▲ 图1.2.3 Fashion_mnist 前15张图片
1.2.3 数据文件操作
既然在替代MNIST中已经介绍这个数据库的格式与MNIST相同,那么采用与MNIST相同的_pickle函数进行操作是否可以呢?
根据 LeYan Chen MNIST 介绍数据结构考察Fashion_MNIST文件。
1.2.4 训练LeNet识别FashionMNIST
(1)建立网络
aisi
aisi net conv#2 mp#2 L#3
aisi forward conv1. mp1 conv2. mp2- L1. L2. L3
import sys,os,math,time
import matplotlib.pyplot as plt
from numpy import *
import paddle
import paddle.nn.functional as F
from paddle import nn
from paddle.metric import accuracy as acc
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5], std=[127.5], data_format='CHW')])
train_dataset = paddle.vision.datasets.FashionMNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.FashionMNIST(mode='test', transform=transform)
class mnist(paddle.nn.Layer):
def __init__(self, ):
super(mnist, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=84)
self.L3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = F.relu(x)
x = self.L2(x)
x = F.relu(x)
x = self.L3(x)
return x
model = paddle.Model(mnist())
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001,
parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
(2)训练结果

▲ 图1.2.4 训练过程
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-11 [[64, 1, 28, 28]] [64, 6, 28, 28] 156
MaxPool2D-11 [[64, 6, 28, 28]] [64, 6, 14, 14] 0
Conv2D-12 [[64, 6, 14, 14]] [64, 16, 10, 10] 2,416
MaxPool2D-12 [[64, 16, 10, 10]] [64, 16, 5, 5] 0
Linear-16 [[64, 400]] [64, 120] 48,120
Linear-17 [[64, 120]] [64, 84] 10,164
Linear-18 [[64, 84]] [64, 10] 850
===========================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 3.95
Params size (MB): 0.24
Estimated Total Size (MB): 4.38
---------------------------------------------------------------------------
{'total_params': 61706, 'trainable_params': 61706}
1.2.5 使用稠密网络

▲ 图1.2.5 训练过程与结果
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Linear-22 [[64, 784]] [64, 120] 94,200
Linear-23 [[64, 120]] [64, 84] 10,164
Linear-24 [[64, 84]] [64, 10] 850
===========================================================================
Total params: 105,214
Trainable params: 105,214
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.19
Forward/backward pass size (MB): 0.10
Params size (MB): 0.40
Estimated Total Size (MB): 0.70
---------------------------------------------------------------------------
{'total_params': 105214, 'trainable_params': 105214}
※ 数据总结 ※
对于Paddle中的vision中的图片数据Cifar10, FashionMNIST进行显示与测试。
■ 相关文献链接:
● 相关图表链接:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)