vLLM深度解析:高性能大语言模型推理引擎全揭秘
vLLM(Vectorized Large Language Model Serving System)是由加州大学伯克利分校团队开发的高性能、易扩展的大语言模型推理引擎。它专注于通过创新的内存管理和计算优化技术,实现高吞吐、低延迟、低成本的模型服务。
什么是vLLM?
vLLM(Vectorized Large Language Model Serving System)是由加州大学伯克利分校团队开发的高性能、易扩展的大语言模型推理引擎。它专注于通过创新的内存管理和计算优化技术,实现高吞吐、低延迟、低成本的模型服务。
核心特点:
- 高性能推理
:支持分布式推理,能高效利用多机多卡资源。
- 显存优化
:采用PagedAttention内存管理技术,显著提升GPU显存利用率。
- 多场景适配
:无论是低延迟的在线服务,还是资源受限的边缘部署,vLLM都能提供卓越的性能表现。
中文站点:https://vllm.hyper.ai/docs/
英文站点:https://docs.vllm.ai/en/latest/index.html
vLLM vs Ollama:对比分析
在LLM推理引擎的选择上,vLLM和Ollama是两个常见的选项。对比如下:
| 对比维度 | Ollama | vLLM |
备注 |
|---|---|---|---|
| 量化与压缩策略 |
默认采用4-bit/8-bit量化,显存占用降至25%-50% |
默认使用FP16/BF16精度,保留完整参数精度 |
Ollama 牺牲精度换显存,vLLM 牺牲显存换计算效率 |
| 优化目标 |
轻量化和本地部署,动态加载模型分块,按需使用显存 |
高吞吐量、低延迟,预加载完整模型到显存,支持高并发 |
Ollama 适合单任务,vLLM 适合批量推理 |
| 显存管理机制 |
分块加载 + 动态缓存,仅保留必要参数和激活值 |
PagedAttention + 全量预加载,保留完整参数和中间激活值 |
vLLM 显存占用为 Ollama 的 2-5 倍 |
| 硬件适配 |
针对消费级GPU(如RTX 3060)优化,显存需求低 |
依赖专业级GPU(如A100/H100),需多卡并行或分布式部署 |
Ollama 可在 24GB 显存运行 32B 模型,vLLM 需至少 64GB |
| 性能与资源平衡 |
显存占用低,但推理速度较慢(适合轻量级应用) |
显存占用高,但吞吐量高(适合企业级服务) |
量化后 Ollama 速度可提升,但仍低于 vLLM |
| 适用场景 |
个人开发、本地测试、轻量级应用 |
企业级API服务、高并发推理、大规模部署 |
根据显存和性能需求选择框架 |
总结:Ollama更适合个人开发和轻量级应用,而vLLM则更适合企业级服务和高并发场景。
DeepSeek-R1-Distill-Qwen-32B模型对比
DeepSeek-R1-Distill-Qwen-32B模型在Ollama和vLLM框架下的显存占用、存储需求及性能对比
| 指标 | Ollama (4-bit) | vLLM (FP16) | 说明 |
|---|---|---|---|
| 显存占用 |
19-24 GB |
64-96 GB |
Ollama通过4-bit量化压缩参数,vLLM需保留完整FP16参数和激活值 |
| 存储空间 |
20 GB |
64 GB |
Ollama存储量化后模型,vLLM存储原始FP16精度模型 |
| 推理速度 |
较低(5-15 tokens/s) |
中高(30-60 tokens/s) |
Ollama因量化计算效率降低,vLLM通过批处理和并行优化提升吞吐量 |
| 硬件门槛 |
高端消费级GPU(≥24GB) |
多卡专业级GPU(如2×A100 80GB) |
Ollama勉强单卡运行,vLLM需多卡并行或分布式部署 |
ModelScope:开源模型即服务(MaaS)平台
ModelScope是由阿里巴巴集团推出的开源模型即服务(MaaS)平台,旨在简化模型应用的过程,为AI开发者提供灵活、易用、低成本的一站式模型服务产品。
核心功能:
- 汇集多种最先进的机器学习模型,涵盖NLP、CV、语音识别等领域。
- 提供丰富的API接口和工具,方便开发人员集成和使用模型。
- 支持模型的下载、部署和推理,降低开发门槛。
安装与使用:
-
下载DeepSeek模型
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple -
创建模型存放目录
mkdir -p /data/deepseek-ai/models/deepseek-70b -
下载DeepSeek-R1-Distill-Llama-70B模型
modelscope download --local_dir /data/deepseek-ai/models/deepseek-70b --model deepseek-ai/DeepSeek-R1-Distill-Llama-70B
docker部署
下载 Docker 二进制包
Docker 官方网站下载二进制包文件
wget https://download.docker.com/linux/static/stable/x86_64/docker-26.1.4.tgz
解压 Docker 压缩包
tar -zxvf docker-26.1.4.tgz
移动二进制文件到系统目录
mv docker/* /usr/bin/
创建 Docker 用户和组
-
创建 Docker 组
groupadd docker -
创建 Docker 用户,并将其添加到 Docker 组
useradd -s /sbin/nologin -M -g docker docker
配置 Docker 服务
创建并配置 docker.service 文件
-
打开或创建
docker.service文件vim /usr/lib/systemd/system/docker.service -
添加以下内容:
[Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target firewalld.service Wants=network-online.target [Service] Type=notify ExecStart=/usr/bin/dockerd ExecReload=/bin/kill -s HUP $MAINPID LimitNOFILE=infinity LimitNPROC=infinity TimeoutStartSec=0 Delegate=yes KillMode=process Restart=on-failure StartLimitBurst=3 StartLimitInterval=60s [Install] WantedBy=multi-user.target
配置国内 Docker 镜像加速
-
创建 Docker 配置目录:
mkdir -p /etc/docker -
打开或创建
daemon.json文件:vim /etc/docker/daemon.json -
添加以下内容:
{ "registry-mirrors": ["https://docker.rainbond.cc"] }
启动 Docker 服务
-
启动 Docker 服务
systemctl start docker -
设置 Docker 服务开机启动
systemctl enable docker
验证 Docker 安装
-
查看 Docker 版本
docker -v
vLLM容器化部署指南
环境准备
-
更新软件包列表并安装NVIDIA容器工具包
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit -
配置NVIDIA容器运行时
sudo nvidia-ctk runtime configure --runtime=docker -
重加载系统服务并重启Docker
sudo systemctl daemon-reload sudo systemctl restart docker -
下载vllm/vllm-openai容器
docker pull vllm/vllm-openai -
查看vllm/vllm-openai容器
docker images
启动vLLM容器
docker run -itd --restart=always --name vllm_ds70 \
-v /data/deepseek-ai:/data \
-p 18005:8000 \
--gpus all \
--ipc=host \
vllm/vllm-openai:latest \
--dtype bfloat16 \
--served-model-name DeepSeek-R1-Distill-Llama-70B \
--model "/data/models/deepseek-70b" \
--gpu-memory-utilization 0.9 \
--tensor-parallel-size 8 \
--max-model-len 30000 \
--api-key token-abc123参数解释:
-
--restart=always
:容器退出后自动重启,除非显式停止或dockerd服务重启。
-
--name vllm_ds70
为容器指定一个名称,便于后续管理和操作。
-
-v /data/deepseek-ai:/data
将主机上的/data/deepseek-ai目录挂载到容器的/data目录,用于存储模型文件和数据。
-
-p 18005:8000
将容器的8000端口映射到主机的18005端口,用于通过主机端口访问容器内的服务。
-
-itd
命令选项组合,-i和-t、-d,保持容器在后台运行,同时允许用户通过Docker logs或attach命令查看输出。
-
--gpus all
:允许容器使用宿主机的所有GPU资源。
-
--dtype bfloat16
-
--dtype {auto,half,float16,bfloat16,float,float32}
:指定数据类型,优化内存使用和计算效率。auto模式会根据模型类型自动选择精度,而half或float16则常用于半精度计算以节省显存。
-
--tensor-parallel-size 8
:设置张量并行的大小,通过将模型分割到多个GPU上进行并行计算,提升模型推理的速度和效率。
-
--ipc=host
:配置容器的IPC(Inter-Process Communication)模式,允许容器与宿主机或其他容器共享共享内存,提升模型并行性能。
-
--served-model-name DeepSeek-R1-Distill-Llama-70B
:指定服务的模型名称,标识当前服务的模型,便于管理和路由
-
--model "/data/models/deepseek-70b"
指定模型文件的路径,告诉服务从哪里加载模型权重和配置文件,确保模型能够正确加载。
-
--gpu-memory-utilization 0.95
设置GPU内存使用率,限制模型使用的GPU内存占比,避免因内存不足导致服务崩溃。
-
--tensor-parallel-size 8
设置张量并行的大小,通过将模型分割到多个GPU上进行并行计算,提升模型推理的速度和效率。
-
--max-model-len 30000
设置模型的最大上下文长度,限制模型在一次推理中能处理的最大输入长度,避免因过长输入导致性能问题。
-
--api-key token-abc123
指定API密钥,用于身份验证和授权,确保只有有权限的用户才能访问服务。
查看vLLM容器日志
docker logs -f b05b9c3646ec
访问vLLM容器
docker exec -it b05b9c3646ec /bin/bash
vLLM API 调用测试
curl http://192.168.1.34:18005/v1/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer token-abc123" \-d '{"model": "DeepSeek-R1-Distill-Llama-70B","prompt": "北京的著名景点有哪些","max_tokens": 1000,"temperature": 0.3}'
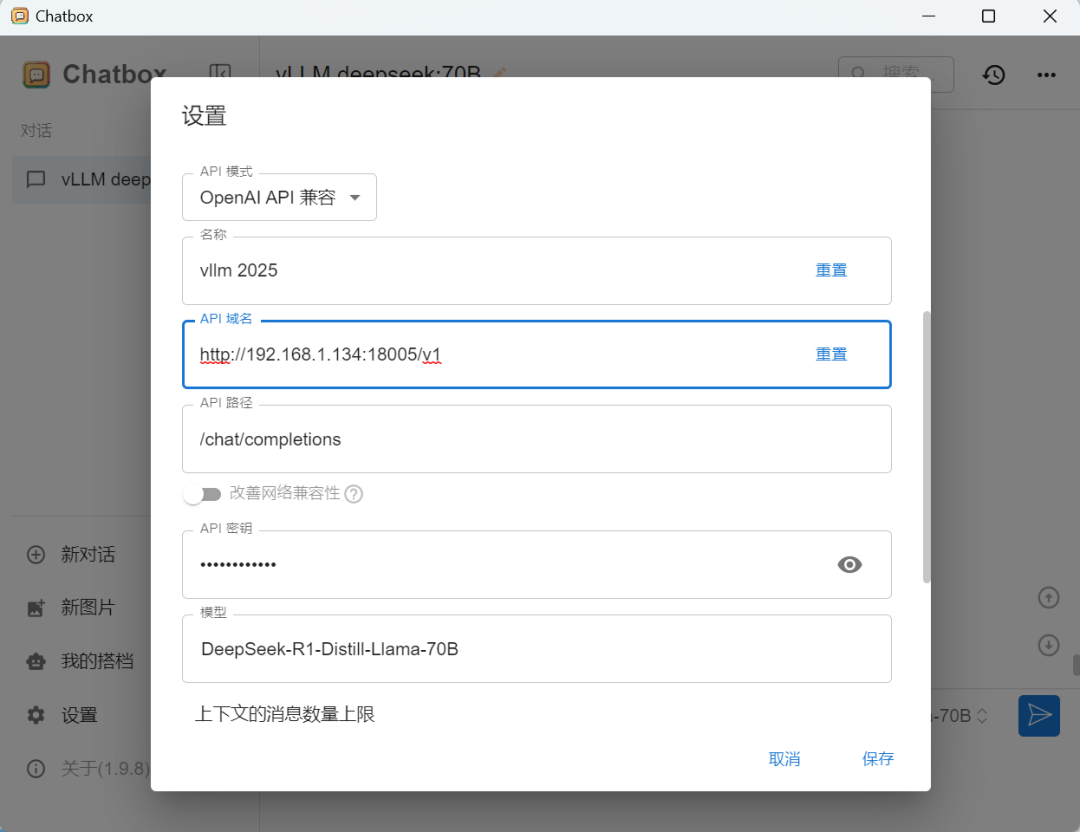
Chatbox设置
DeepSeek-R1 模型 Ollama VS vLLM 占用显存对比
|
Model |
Base Model |
Ollama |
vLLM |
|---|---|---|---|
|
DeepSeek-R1-Distill-Qwen-1.5B |
Qwen2.5-Math-1.5B |
1.1GB |
3-6 GB |
|
DeepSeek-R1-Distill-Qwen-7B |
Qwen2.5-Math-7B |
4.7GB |
14-21 GB |
|
DeepSeek-R1-Distill-Llama-8B |
Llama-3.1-8B |
4.9GB |
16-24 GB |
|
DeepSeek-R1-Distill-Qwen-14B |
Qwen2.5-14B |
9.0GB |
28-42 GB |
|
DeepSeek-R1-Distill-Qwen-32B |
Qwen2.5-32B |
20GB |
64-96 GB |
|
DeepSeek-R1-Distill-Llama-70B |
Llama-3.3-70B-Instruct |
43GB |
140-210 GB |
|
DeepSeek-R1-671B |
DeepSeek-R1-671B |
404GB |
1342-2013 GB |

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)