简单认识路透社数据集reuters
官网的信息如下:这个数据集一共有11228个样本,每个样本被单标签标记(每个样本只被打上一个标签),标签类别的总数是超过46。按照自然语言处理的流程,每条文本会被预处理,最终成为向量才能被使用。这个过程请见:它针对每条样本将文本转化成一个列表,列表当中的元素是对应词表的序号。这个词表是按照词频降序进行排列的。值得注意的是,load_data使用的词表最开始有三个功能类,分别代表填充padding、
1 数据来源
官网的信息如下:Reuters newswire classification dataset![]() https://keras.io/api/datasets/reuters/
https://keras.io/api/datasets/reuters/
这个数据集一共有11228个样本,每个样本被单标签标记(每个样本只被打上一个标签),标签类别的总数是46。
按照自然语言处理的流程,每条文本会被预处理,最终成为向量才能被使用。这个过程请见:Where can I find topics of reuters dataset · Issue #12072 · keras-team/keras![]() https://github.com/keras-team/keras/issues/12072
https://github.com/keras-team/keras/issues/12072
它针对每条样本将文本转化成一个列表,列表当中的元素是对应词表的序号。这个词表是按照词频降序进行排列的。值得注意的是,load_data使用的词表最开始有三个功能类,分别代表填充padding、序列开始start of sequence、未知词unknow。

2 函数
这个和调用IMDB数据集的函数大多相似,可以先参考:
认识IMDB数据集-CSDN博客![]() https://blog.csdn.net/weixin_65259109/article/details/144945051
https://blog.csdn.net/weixin_65259109/article/details/144945051
2.1 load_data
2.1.1 调用参数
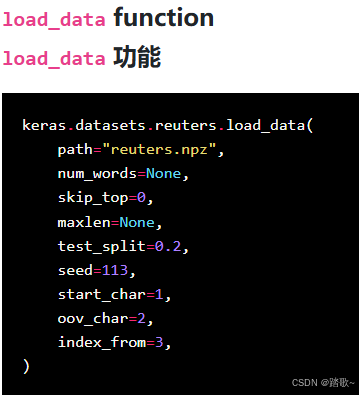
与IMDB不同的是出现了test_split参数,这个参数是管训练集和测试集的比例的。
- test_split: Float between
0.and1.. Fraction of the dataset to be used as test data.0.2means that 20% of the dataset is used as test data. Defaults to0.2.
test_split:在0. 和 1 之间浮动。要用作测试数据的数据集的分数。0.2表示 20% 的数据集用作测试数据。默认值为0.2。
2.1.2 返回
这个函数的返回是四个列表
Returns 返回
- Tuple of Numpy arrays:
(x_train, y_train), (x_test, y_test).
Numpy 数组元组:(x_train, y_train), (x_test, y_test).
x_train,x_test: lists of sequences, which are lists of indexes (integers). If the num_words argument was specific, the maximum possible index value isnum_words - 1. If themaxlenargument was specified, the largest possible sequence length ismaxlen.x_train、x_test:序列列表,它们是索引(整数)的列表。如果 num_words 参数是特定的,则最大可能的索引值为num_words - 1。如果指定了maxlen参数,则可能的最大序列长度为maxlen。
y_train,y_test: lists of integer labels (1 or 0).y_train、y_test:整数标签列表(1 或 0)。
2.2 get_word_index

这个函数返回一个字典用于存储索引和词的映射关系。实际进行转换的时候,要注意有三个功能列。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 18
18 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)