CUDA与TensorRT模型部署优化与模型部署一百问
Tensor Core 是 NVIDIA 的一些新架构(如 Volta、Turing 和 Ampere)中引入的专门硬件单元,用于高效地执行深度学习中的矩阵运算。
0. 笔者的一点个人理解
模型部署与优化是当前许多自动驾驶公司投入人力物力去做的模块,如何将模型高效部署在特定的芯片上至关重要。深度学习模型的部署与优化是一个综合性的过程,涉及多个关键考虑因素。虽然工具如TensorRT为模型提供了强大的优化,但其应用并非无限,有时需要开发者手动调整或补充。此外,选择CUDA Cores还是Tensor Cores、考虑前后处理的效率,以及进一步的性能分析和基准测试,都是确保模型在特定硬件上达到最佳性能的关键步骤。今天我将会为大家分享下模型部署的关键考虑与实践策略。
1. FLOPS TOPS
首先,我们来解释FLOPS和TOPS的含义:
FLOPS:是Floating Point Operations Per Second的缩写,意思是每秒浮点运算次数。它是衡量计算机或计算设备在每秒内执行的浮点运算次数的指标。通常用于表示处理器的计算性能。例如,1 TFLOPS表示每秒执行1万亿次浮点运算。
TOPS:是Tera Operations Per Second的缩写,意思是每秒运算次数。它与FLOPS类似,但通常用于衡量整数运算或混合型的运算能力,而不仅仅是浮点运算。
下面列出一个关于NVIDIA A100(基于发布时的公开资料)的性能参数表格。请注意,这些性能数字代表了理论上的峰值计算能力,实际应用中的性能可能会因为各种因素而有所不同。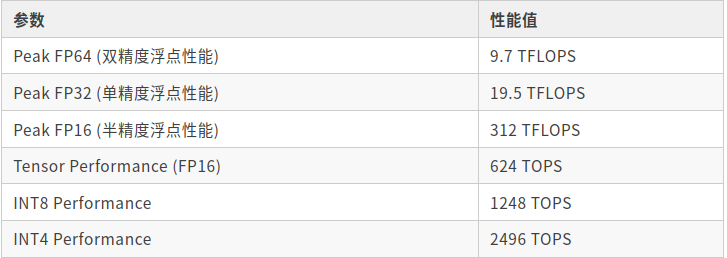
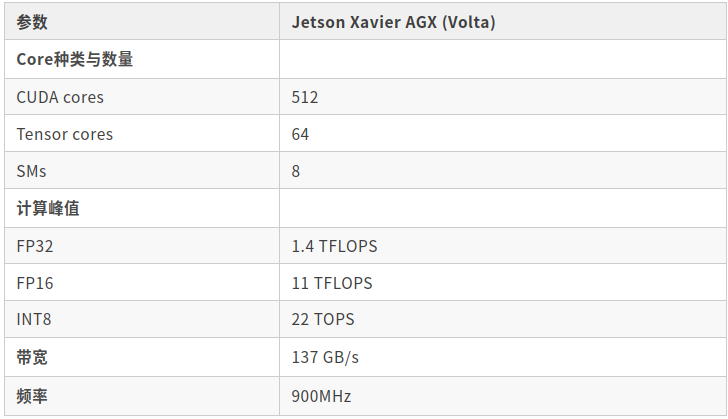
下面是Jetson Xavier AGX Volta的参数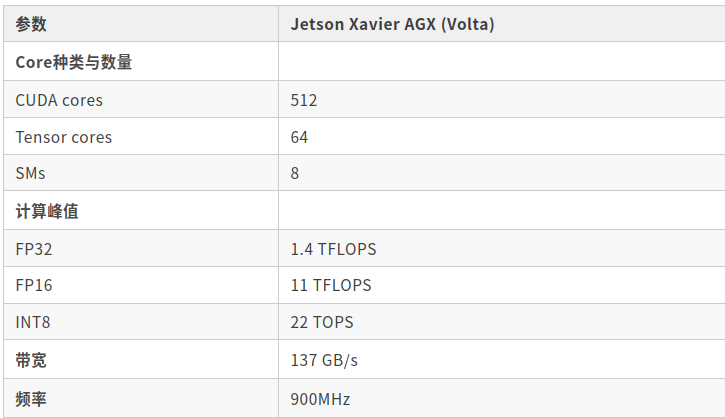
Tensor Performance (FP16): Tensor Core的半精度浮点性能,特别针对深度学习和AI应用进行了优化。
INT8 Performance: 8位整数性能,常用于某些深度学习工作负载。
INT4 Performance: 4位整数性能,适用于需要更高吞吐量但可以接受较低精度的应用。
这些数据提供了一个全面的视图,显示了A100在不同精度和数据类型下的性能。不同的应用和任务可能会根据其对计算精度和速度的需求来选择最适合的数据类型和运算模式。
2. FLOPs
这个容易弄混淆,这个只是衡量模型大小的指标,下面展示YOLOV5跟Swin Transformer的FLOPs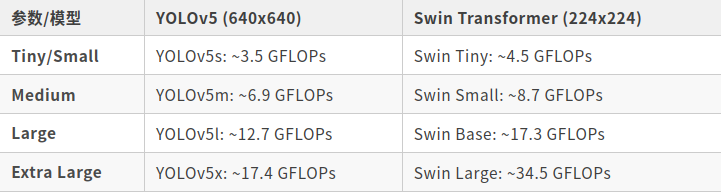
2.1 模型的规模与计算复杂性的关系:
- 对于每个模型系列(不论是YOLOv5还是Swin Transformer),当模型规模增加(从Tiny到Extra Large)时,计算复杂性(FLOPs)也相应增加。这很容易理解,因为更大的模型通常具有更多的层和参数,因此需要更多的计算。
2.2 模型输入尺寸的影响:
- YOLOv5的输入尺寸为640x640,而Swin Transformer的为224x224。即使如此,较小的Swin Transformer模型仍然具有相似或更高的FLOPs。这突显了Transformer结构相较于传统的卷积网络结构在计算上的密集性。
2.3 模型类型的不同:
- 正如前面提到的,YOLOv5是一个目标检测模型,而Swin Transformer主要设计用于图像分类。将这两者进行对比可能不完全公平,因为它们是为不同的任务优化的。不过,这个对比提供了一个关于不同模型和结构计算复杂性的大致感觉。
2.4 FLOPs与性能的关系:
- 虽然FLOPs提供了关于模型计算复杂性的信息,但它并不直接等同于模型的实际运行速度或效率。其他因素,如内存访问、优化技术、硬件特性等,都会影响实际性能。
- 同样,FLOPs也不直接等同于模型的准确性。有时,较小的模型经过适当的训练和优化可能会表现得相当好。
总的来说,这个表格提供了一个视觉上的对比,展示了两种不同模型结构在不同规模下的计算复杂性。但解释这些数据时,要考虑到模型的具体用途、设计目标和其他相关因素。
总的来说,这个表格提供了一个视觉上的对比,展示了两种不同模型结构在不同规模下的计算复杂性。但解释这些数据时,要考虑到模型的具体用途、设计目标和其他相关因素。
3. CUDA Core and Tensor Core
3.1 CUDA Core:
- 定义: CUDA Core 是 NVIDIA GPU 中用于执行浮点和整数运算的基本计算单元。
- 用途: CUDA Cores 主要用于通用的图形和计算任务,比如图形渲染、物理模拟和其他数值计算等。
3.2 Tensor Core:
定义: Tensor Core 是 NVIDIA 的一些新架构(如 Volta、Turing 和 Ampere)中引入的专门硬件单元,用于高效地执行深度学习中的矩阵运算。
用途: Tensor Cores 专门设计用于深度学习计算,尤其是进行大规模的矩阵乘法和加法操作,这些操作是神经网络训练和推理的核心。
简而言之,CUDA Core 是 GPU 的通用计算工作,处理各种图形和计算任务,而 Tensor Core 则是为深度学习任务特别设计的高效计算单元。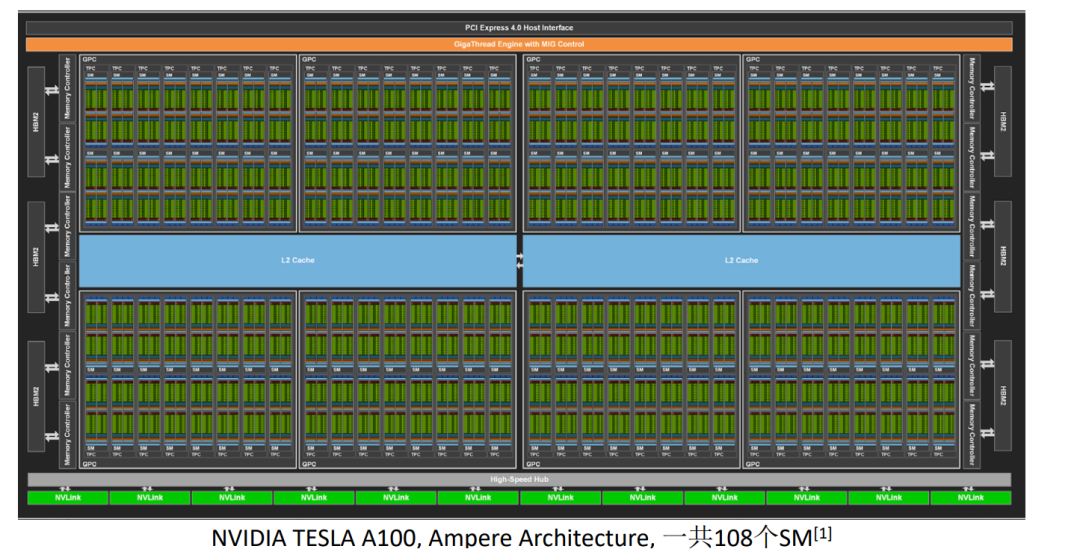
A100 有 6912 个 CUDA Core,而只有 432 个 Tensor Core。尽管 Tensor Cores 的数量较少,但它们在处理特定的深度学习任务时非常高效。
3.3 设计目的:
CUDA Cores 是通用的计算单元,能够处理各种任务,包括图形、物理模拟和通用数值计算等。Tensor Cores 则专门设计用于深度学习计算,尤其是矩阵乘法和累加操作。性能:
单一的 CUDA Core 能够执行基本的浮点和整数运算。每个 Tensor Core 能够在一个周期内处理一小块矩阵的乘法和累加操作(例如 4x4 或 8x8)。这使得它们在处理深度学习操作时非常高效。使用场景:
当执行图形渲染或通用计算任务时,主要使用 CUDA Core。当执行深度学习训练和推理任务时,尤其是使用库如 cuDNN 或 TensorRT 时,Tensor Cores 会被积极利用,以实现最大的计算效率。使用 A100 作为例子,我们可以清楚地看到 NVIDIA 是如何通过结合 CUDA Cores 和 Tensor Cores 来提供高效的深度学习和通用计算性能的。
4. Roofline model
Roofline Model 是一个可视化工具,用于表征计算密集型应用的性能。它提供了一个框架,通过该框架,开发者可以理解应用的性能瓶颈,并与某个特定硬件的理论峰值性能进行对比。Roofline 模型的主要目标是提供对算法和硬件交互的深入了解,从而为优化提供指导。
Roofline模型基本上是一个图,其中:
-
x轴: 计算与数据移动的比率,通常用“浮点运算次数/字节”表示。
-
y轴: 性能,通常以“FLOPS”为单位。
在此图上有两个主要部分: -
Roof: 这代表了硬件的性能上限。这是两部分组成的:
-
计算上限:这通常是以FLOPS为单位的峰值计算性能。
-
带宽上限:这是数据从主存储器移动到计算单元的最大速率。
Line:这表示应用或算法的性能。它的斜率由内存访问和浮点计算的比率决定。
通过观察算法在Roofline模型上的位置,开发者可以判断算法是受计算能力限制还是受带宽限制,并据此决定优化策略。
案例一: RTX 3080
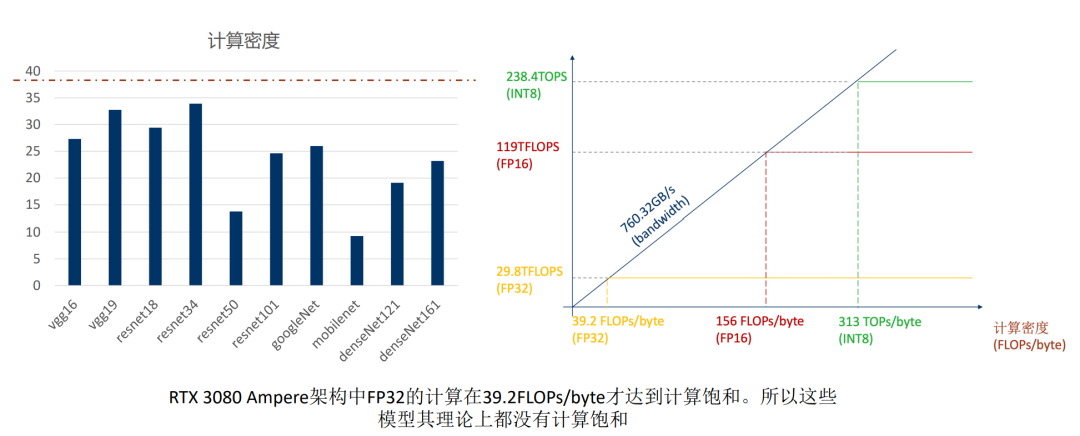
案例二: Jetson Xavier AGX Volta

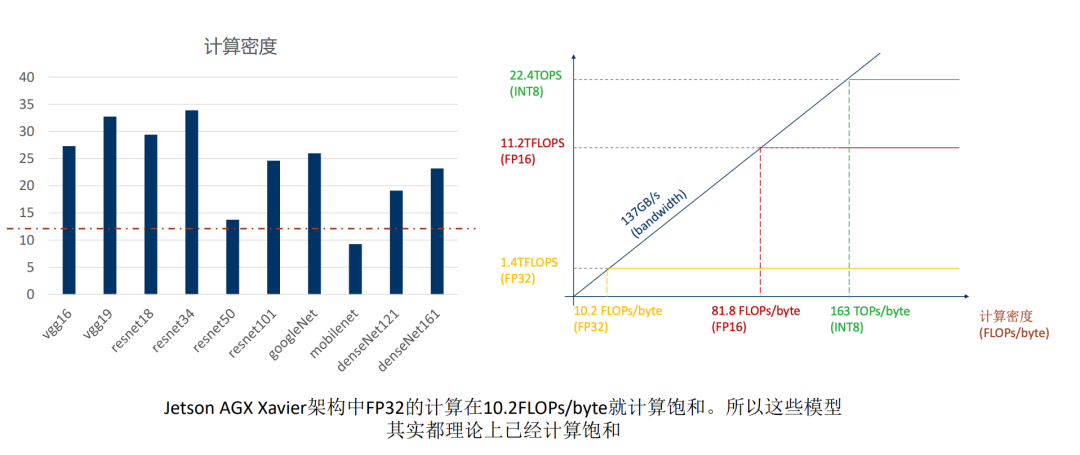
也可以从这两个案例的对比看出来边缘端跟服务器端的区别,所以TensorRT CUDA的掌握就很重要, 能够使用这些SDK满足客户的需求也是我们求职的一个机会
5. 模型部署的一些误区
5.1 模型性能与FLOPs
FLOPs, 即浮点运算次数, 通常被用来衡量模型的计算复杂性。然而,它并不足以完全描述模型的性能。尽管FLOPs反映了模型的计算负荷,但实际的推理速度和效率还受到其他因素影响。例如,访问内存、数据的转换和重塑,以及其他与计算无关但与深度神经网络操作相关的部分。此外,像前后处理这样的步骤,也可能占据显著的时间,尤其是在一些轻量级模型中。
5.2 TensorRT的局限性
TensorRT是NVIDIA提供的一个强大的工具,可以对深度学习模型进行优化以获得更好的推理性能。然而,它的优化能力并非没有局限。例如,某些低计算密度的操作,如1x1的conv,depthwise conv, 可能不会被TensorRT重构。有些操作,如果GPU不能优化,TensorRT可能会选择在CPU上执行。但开发者可以手动调整代码,使某些CPU操作转移到GPU。此外,如果遇到TensorRT尚不支持的算子,可以通过编写自定义插件来补充。
1x1 conv, depthwise conv 这些算子出现在mobileNet上面,Transformer的优化也是把最后的FC层用这两个算子去替换,他们虽然降低了参数量,但是减少了计算的密度。
5.3 CUDA Core与Tensor Core的选择考量
NVIDIA的最新GPU通常配备了CUDA Cores和Tensor Cores。虽然Tensor Cores专门为深度学习操作优化,但TensorRT不一定总是使用它们。实际上,TensorRT通过内核自动调优选择最优的内核执行方式,这可能意味着某些情况下INT8的性能比FP16还差。要有效利用Tensor Cores,有时需要确保tensor的尺寸为8或16的倍数。
5.4 前后处理的时间开销
在深度学习的应用中,前处理(如图像调整和归一化)和后处理(如结果解释)是不可或缺的步骤。然而,对于轻量级的模型,这些处理步骤可能比实际的DNN推理还要耗时。部分前后处理步骤由于其复杂逻辑不适合GPU并行化。但解决方案是将这些逻辑中的并行部分移至GPU或在CPU上使用优化库如Halide,这样可以提高某些任务,如模糊、缩放的效率。
很多时候在做YOLO的后处理的时候我们会喜欢把它放在GPU上面去做,这样会给人一种很快的感觉,但是这种并不是必要的,第一,GPU没有排序的功能,第二,YOLO系列我们使用阈值先过滤掉一大部分的时候剩下来的bbox已经是很少的了,也不见得说会快很多。
5.5 并不是TRT跑通了就结束了
创建并使用TensorRT推理引擎仅仅是优化流程的开始。为了确保模型达到最佳性能,开发者需要进一步对其进行基准测试和性能分析。NVIDIA提供了如nsys, nvprof, dlprof, Nsight等工具,这些工具可以帮助开发者精确地确定性能瓶颈、寻找进一步的优化机会以及识别不必要的内存访问。
6. 常见问答
Q1: GPU版本,CUDA版本与TensorRT版本之间的关系
答:这三者的版本有对应关系,具体来说:高版本的GPU驱动向下兼容CUDA版本;下载TensorRT前需要确认cuda版本。具体参考以下链接:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
Q2: 代码里的 grid/block 对应硬件上的 SM 的关系是什么
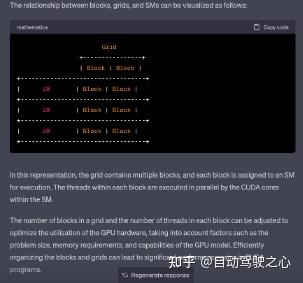
回答:首先需要理解grid/block是软件层的概念,而SM是硬件层的概念。所以我们在GPU中是找不到grid/block的,所以只能抽象去理解这个关系。一般来讲一个kernel对应一个grid,分给多个SM去处理。之后每一个SM去处理一个grid中的多个block。这里需要注意的是,block不可以跨越SM去分配,也就是一个block里面的多线程统一由同一个SM中分配资源。因为block中的thread是共享资源的(比如shared memory)。
Q3: 各位佬,我有一个问题,jetson系列,一般都是共享内存,是不是不需要使用cudaMemcpy这个函数了? 要使用其他的memcpy方式吗?
关于共享内存在英伟达官方做了一个简短的介绍,链接如下,帮助理解
在 CUDA C / C ++ 中使用共享内存 - NVIDIA 技术博客
对于共享内存的shared-memory-cuda-cc/使用,Jetson系列确实可以直接访问共享内存而无需使用cudaMemcpy函数。首先,理解一下cudaMemcpy函数的功能: (库函数官方介绍)
NVIDIA CUDA Library: cudaMemcpy (horacio9573.no-ip.org)
从这个函数的介绍,翻译理解一下是将 count 个字节从 src 指向的内存区域复制到 dst 指向的内存区域。是将一个内存空间中的数据复制到另个内存空间中。关于这个函数及相关函数的用法,主要是用于主机内存与GPU内存之间的数据传输,或者是其他内存间的拷贝工作。而共享内存用于 同一个线程块内的线程之间共享数据,所以不涉及到内存数据的转移的话,不用copy函数。故 得出上述结论。。
这里提问者估计混淆了一个概念,你这里想表达的是统一内存(unified memory)而不是共享内存(shared memory)。shared memory无论是不是jetson,只要是GPU一般都会有的概念。而unified memory是Jetson中的概念,表示的是CPU和GPU共享同一片“虚拟”内存(注意这里实际意义上还不是共享同一片物理内存)。所以也就没有了CPU到GPU的数据拷贝过程。使用unified memory的编程方式跟平时有一些差异,你可以看看这篇文章,写的比较详细。以及官方文档
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#unified-memory-programming
Q4: host内存应该不能直接传到share memory吧?肯定要过一次显存,我理解的没问题吧? 如果遇到只需要读一次的情况,比如说resize操作,是不是就不需要用到共享内存了呢
回答:嗯,shared memory中的数据是从显存(global memory)中取出来的,所以需要先过一次显存。默认下kernel中如果没有特殊指定,会跳过shared memory直接从global memory中取数据。所以你说的只读一次的情况是可以不用共享内存的。
Q5: 为什么trtexec转换engine时,采用FP16推理、INT8量化,推理延时可能变得更久?
可能原因是:
a. 量化后可能会引入一些多余的计算操作和内部的一些reshape。对于小模型,多余的计算带来的延时并不明显;而reshape会涉及一些内存操作,这个是延时变长的主要原因。对于reshape引起的延时变长,我们的解决办法是让TensorRT不做一些额外的这些操作,但TensorRT内部产生的reshape我们没有办法解决的。
b. 另外,TensorRT有kernel auto tuning的机制,因此选择的kernel不一定是效率最高的。
Q6: 什么是Myelin?
这是TensorRT内部的一个概念,负责graph compilation(图编译)和execution backend(执行后端)的内容。
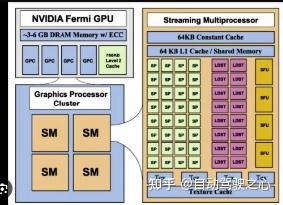
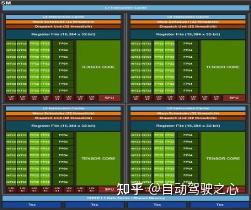
Q7: constant cache和constant memory的区别?
constant cache和constant memory是两个概念,cache更靠近计算单元,所以速度更快。constant cache是以前GPU版本中的概念,比如早期Fermi架构的SM block(上图)。而现在Ampere架构的SM如下图所示。
Q8: 在cuda, cudnn, tensorrt版本相同的情况下,可以将其他电脑上转换好的trt直接在自己电脑运行吗?
不同的GPU架构针对trt的优化方式不一样,所以移植到另外一个平台可能会不兼容。
Q9: 模型部署后,用什么手段分析推理性能?
可以利用Nsight工具分析模型推理性能。通过该工具可以捕获模型各个kernel运行的时间。针对运行情况,我们再做优化。
Q10:神经网络中吞吐和延迟的关系?
吞吐是用来描述一个硬件设备单位时间内可以完成的计算量;延迟是用来描述一个模型推理所需的时间。延迟又分为计算产生的延迟和数据传输(包括数据同步)造成的延迟。我们可以用nsys和Nsight Compute工具定量分析不同阶段的延时情况。
Q11: tensorrt量化方法?
trt默认和推荐的量化算法是entropy,但具体需要看情况,有时候选择minmax或者percentile会达到更好的效果。这个需要结合op的特点一起考虑。
Q12: 模型导出fp32的trt engine没有明显精度损失,导出fp16损失很明显,可能的原因有哪些?
比较突出的几个可能性就是:对一些敏感层进行了量化导致掉精度比较严重,或者权重的分布没有集中导致量化的dynamic range的选择让很多有数值的权重都归0了。另外,minmax, entropy, percentile这些计算scale的选择没有根据op进行针对性的选择也会出现掉点。
Q13: onnx模型推理结果正确,但tensorRT量化后的推理结果不正确,大概原因有哪些?
出现这种问题的时候,需要先确认两种模型推理的前处理(例如,对输入的各种预处理需要和pytoch模型的训练预处理完全一致)和后处理是否一致。确认是量化引起的问题时,可能原因有:
a. calibrator的算法选择不对;
b. calibration过程使用的数据不够;
c. 对网络敏感层进行了量化;
d. 对某些算子选择了不适合OP特性的scale计算。
Q14: 采用tensorRT PTQ量化时,若用不同batchsize校正出来模型精度不一致,这个现象是否正常?
这个现象是正常的,因为calibration(校正)是以tensor为单位计算的。对于每次计算,如果histogram的最大值需要更新,那么PTQ会把histogram的range进行翻倍。
参考链接:https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html#enable_int8_c
不考虑内存不足的问题,推荐使用更大的batch_size,这样每个batch中包含样本更加丰富,校准后的精度会更好。但具体设置多大,需要通过实验确定(从大的batch size开始测试。一点一点往下减)。需要注意的是batch_size越大,校准时间越长。
Q15: 关于对齐内存访问的疑问:如果使用L1cache,访问的颗粒度为128B,对齐的首地址应该为128B偶数倍,不应该是0B,256B,512B…吗?
实际上这里的偶数倍(even multiple)指的是地址是偶数倍的,并非128B的偶数倍。比较官方的解释可以参考如下链接:https://www.nvidia.com/content/PDF/sc_2010/CUDA_Tutorial/SC10_Fundamental_Optimizations.pdf(P.8后内容中有介绍)
Q16: 如何使用nsight或CUDA runtime api分析模型推理性能?
通过nsight可以看到核函数的名字(可通过名字推测它是用cuda core或tensor core, fp16还是int8)还有可以查看memory的流动。
Q17: 如何尽量减少GPU和CPU之间的数据交互或内存分配与回收****?
由于在推理过程中,CPU与GPU之间的数据拷贝耗时较长或出现频繁分配和回收内存的现象,这大大降低了模型推理性能。我们可以采用在推理模型前分配好所需要的最大内存(做到内存复用)以降低内存分配或回收的次数。针对CPU与GPU之间数据相互拷贝问题,我们需要优化代码流程,尽量减少拷贝的次数或寻找更好的方法去掩盖这个动作需要的时间。
Q18: 如果QAT可以使模型尽可能减少量化带来的误差,那么可以不做敏感层分析,直接将整个网络量化为INT8吗?
不建议这么做,从经验来看,敏感层量化到INT8精度会下降很多,所以还是有必要进行敏感层分析。
Q19: 模型量化到INT8后,推理时间反而比FP16慢,这正常吗?
正常的,这可能是tensorrt中内核auto tuning机制作怪(会把所有的优化策略都运行一遍,结果发现量化后涉及一堆其他的操作,反而效率不高,索性使用cuda core,而非tensorrt core)。当网络参数和模型架构设计不合理时,trt会添加额外的处理,导致INT8推理时间比FP16长。我们可以通过trt-engine explorer工具可视化engine模型看到。
Q20: 请教一下,engine推理的时候,batchsize=1和batchsize=4,推理时间相差也接近4倍合理吗?有什么办法让多batch的推理时间接近单batch吗?比如加大显存?
回答:(韩君)这个可能出现的原因有很多,有可能单个batchsize的推理就已经把GPU资源全部吃满了,所以batchsize=4的时候看似加大了并行度,实际上也可能是在串行。建议把模型推理放在nsight system上分析一下,看看硬件资源占用率。
Q21: 在device固定的情况下呢?有什么参数设置或者增加streams的方式吗?试过把workspace设到最大,只有轻微的提升
回答:(韩君)workspace的大小跟性能提升关联不大,workspace是使用在创建推理引擎时TensorRT选择tactics来进行优化的,workspace越大可以选择的tactics越丰富。但除非特别的小,一般关联不是那么大。试试fp16, int8这种量化参数来试试量化,cuda-graph来试试kernel launch的隐藏,builderOptimizationLevel的等级设置高一点等等。光靠参数优化还是有点局限。可以看看模型架构是否有冗长。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)