大模型微调数据集的制作
通过mineru将pdf转成md,然后将md传入easy-dataset中生成jsonl类型的数据集
大模型微调数据集的制作
数据集制作流程:先通过mineru将pdf转成md,然后将md传入easy-dataset中生成jsonl类型的数据集
基于mineru开源工具进行pdf-md格式转换
一、环境配置
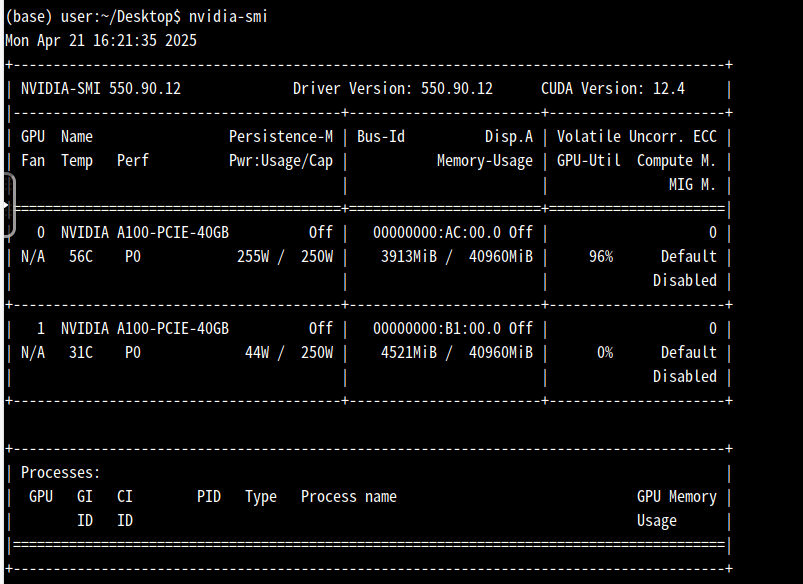
(1)检查INVIDIA驱动是否安装,执行以下命令行
nvidia-smi
(2)如果没有安装INVIDIA驱动,执行以下命令
如果INVIDIA驱动已经安装,跳过此步骤
sudo apt-get update
sudo apt-get install nvidia-driver-570-server
(3)安装Anaconda
如果Anaconda已经安装,跳过此步骤
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
bash Anaconda3-2024.06-1-Linux-x86_64.sh
(4)创建conda虚拟环境,安装magic-pdf
任意路径下,执行以下命令
conda create -n mineru 'python>=3.10' -y
conda activate mineru
pip install -U "magic-pdf[full]" -i https://pypi.tuna.tsinghua.edu.cn/simple
此时记住命令行的输出信息,尤其是magic-pdf的存储路径(存储地址),我的是 /home/kasm-user/magic-pdf.json
(5)下载模型权重文件
任意路径下,执行以下命令
pip install huggingface_hub
wget https://github.com/opendatalab/MinerU/raw/master/scripts/download_models_hf.py -O download_models_hf.py
python download_models_hf.py
(6)修改配置文件
任意路径下,执行以下命令,命令中的文件地址是上文中要求记录的magic-pdf的存储地址
vim /home/kasm-user/magic-pdf.json
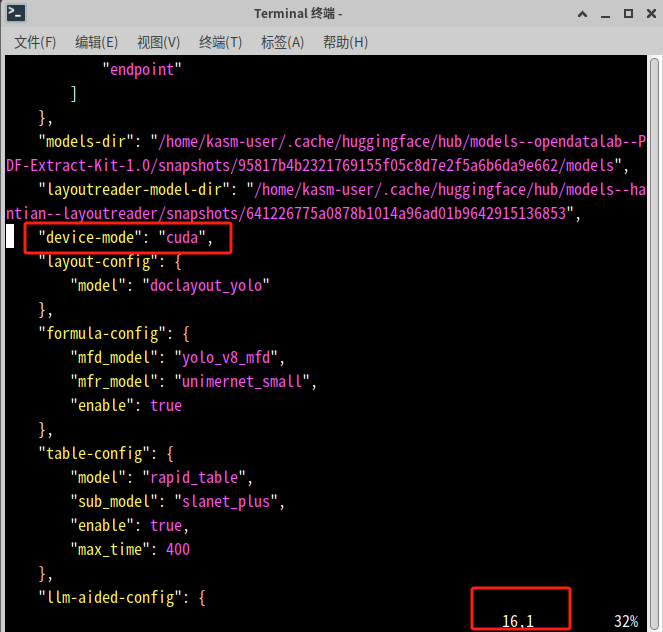
(7)修改magic-pdf.json文件中的内容,将第16行“device-mode”:"cpu"改为“device-mode”:“cuda”
(8)下载样例图片
选择想要存储图片的路径,执行以下命令
wget https://github.com/opendatalab/MinerU/raw/master/demo/pdfs/small_ocr.pdf
(9)测试magic-pdf
在上一步存储图片的路径,执行以下命令
magic-pdf -p small_ocr.pdf -o ./output
二、借助gradio部署MinerU
执行以下命令,进入mineru虚拟环境
conda activate mineru
执行以下命令,安装依赖
pip install gradio gradio-pdf
执行以下命令,下载项目
git clone https://github.com/opendatalab/MinerU.git
执行以下命令,进入到以下路径
cd MinerU/projects/gradio_app
修改MinerU/projects/gradio_app路径下app.py的代码,将服务部署在局域网的8000端口处
vim app.py
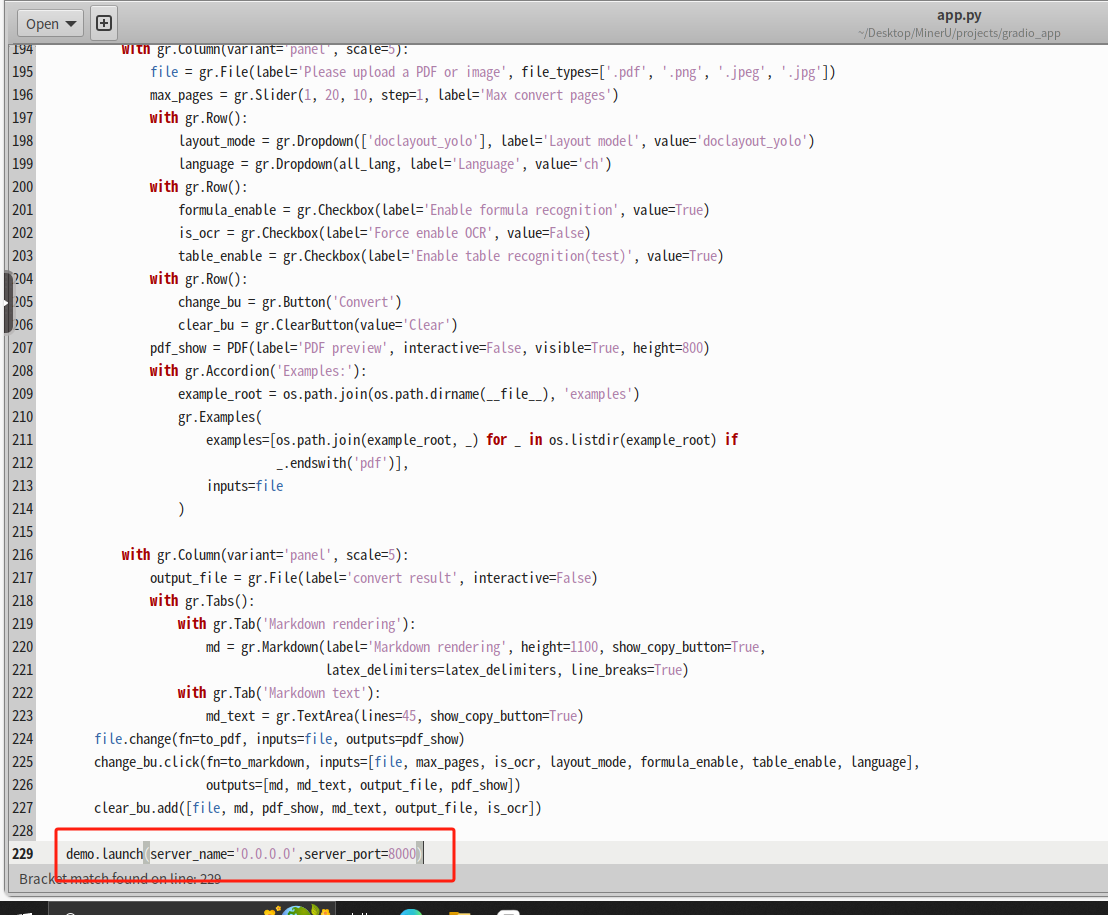
# 将app.py文件中229行的demo.launch(server_name='0.0.0.0')改为demo.launch(server_name='0.0.0.0',server_port=8000)
三、启动服务器,成功部署MinerU
在之前创建app.py的文件路径下,另外创建一个终端,进入mineru虚拟环境中
conda activate mineru
执行以下命令
python app.py
四、访问服务器
点击链接,访问服务器
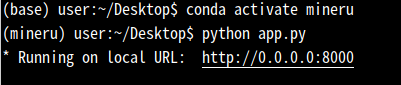
点击上传pdf文件,点击convert进行文件类型转换
项目部署成功!8000端口对应局域网的192.168.10.230:50014
基于easy-dataset开源工具的大模型微调数据集的制作
一、配置环境
前言:
某些命令执行过程中,可能有些包下载不下来,尝试打开科学上网,并且给科学上网设置为允许局域网接入,然后在服务器中,在自己想要安装的项目路径处,打开终端,执行以下命令
export http_proxy=http://192.168.8.45:54633
export https_proxy=http://192.168.8.45:54633
注意!其中的ip地址因每天DHCP协议给自己主机分配的IP地址不同而不同(每个人的不一样,我的是192.168.8.45,Windows操作系统通过cmd界面输入ipconfig查看自己的,然后将上述命令行中的ip地址进行相应调整),另外,端口号在科学上网的允许局域网接入设置中查看,服务器通过这个端口实现科学上网(执行上述命令后,只有当前终端能够科学上网,其他的不能)
配置完成后,尝试curl www.google.com,检查是否科学上网成功
(1)安装Node.js 18.x or higher
使用apt install nodejs安装的并不是最新版的node.js,较为简单的安装最新版需要安装curl和git包,没有安装的话,在自己想要安装的项目路径处,打开终端,执行以下命令:
sudo apt install git curl
安装结束或者已经安装了的话执行以下命令:
curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
sudo apt-get install -y nodejs
执行完上述指令,通过node -v检查是否安装nodejs成功,通过npm -v检查是否安装npm成功,输出版本号则安装成功
(2)安装pnpm (如果不安装pnpm而采用npm的话,后续安装依赖会出现安装失败的情况,因此推荐安装pnpm)
进入到项目路径,执行以下命令
npm intall pnpm -g
(3)下载项目
选择自己想要安装的项目路径地址,执行以下命令
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-dataset
(4)安装依赖
在项目根目录路径下,执行以下命令
pnpm install
出现pnpm install失败,提示说canvas, electron, sharp三个脚本无法安装
发现github项目的issue中就有人讨论项目版本更新后(1.2.5)无法pnpm install
尝试手动下载低版本的(1.2.3),虽然还会有canvas等脚本无法安装,至少是warning,还能继续往后进行
(5)构建依赖
在项目根目录路径下,执行以下命令
pnpm run build
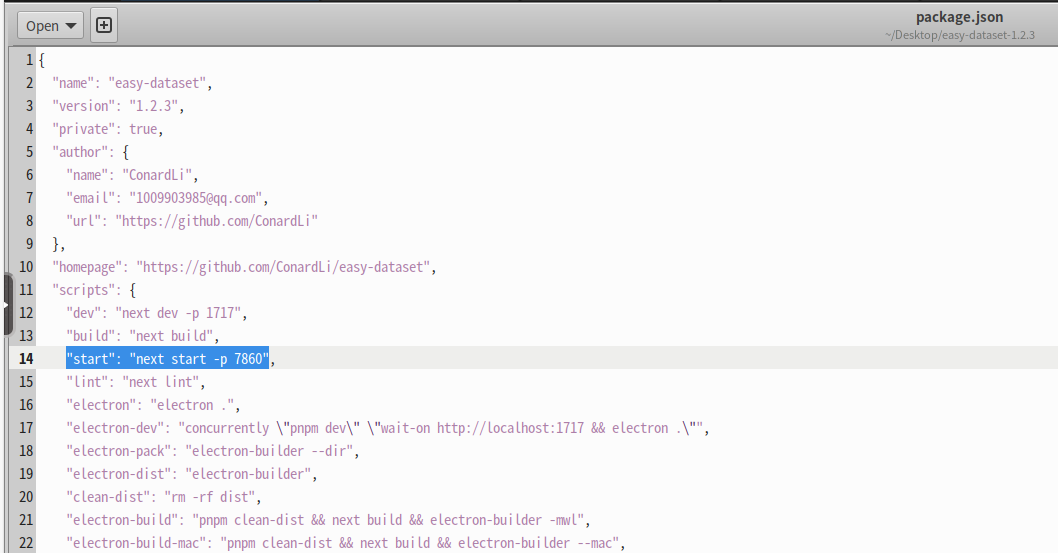
(6)修改package.json配置文件
package.json配置文件的第14行,修改为"start": “next start -p 7860”,使其部署在7860端口,对应局域网 192.168.10.23:50014
(7)部署服务器
pnpm run start
二、使用easy-dataset
(1)进行配置
pnpm run start执行后会开放一个前端端口,访问后进行模型配置
创建项目

输入模型名称,创建项目
进入到选择模型界面,将列表中的模型全部删去
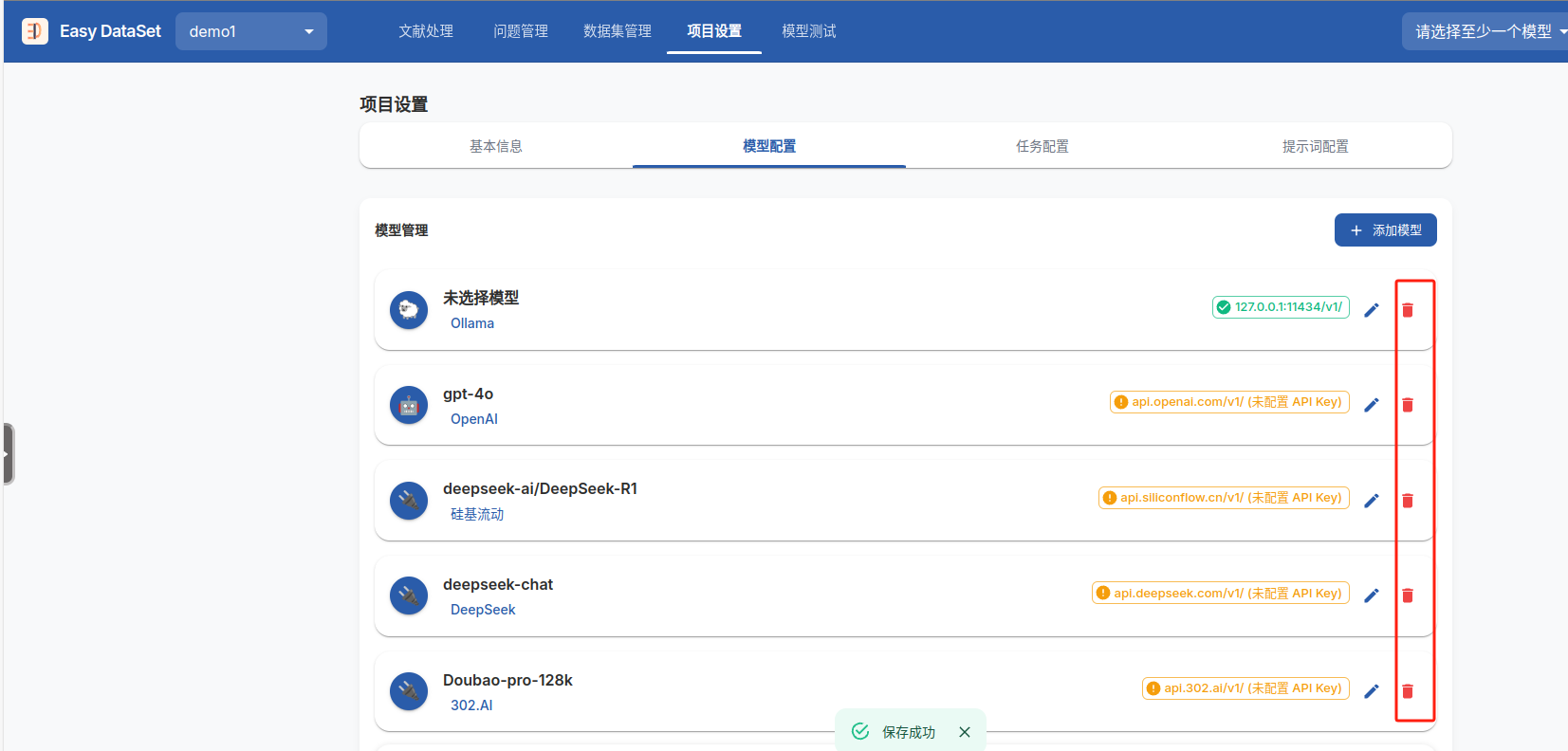
要求至少保留一个模型,那就保留一个模型,点击添加模型
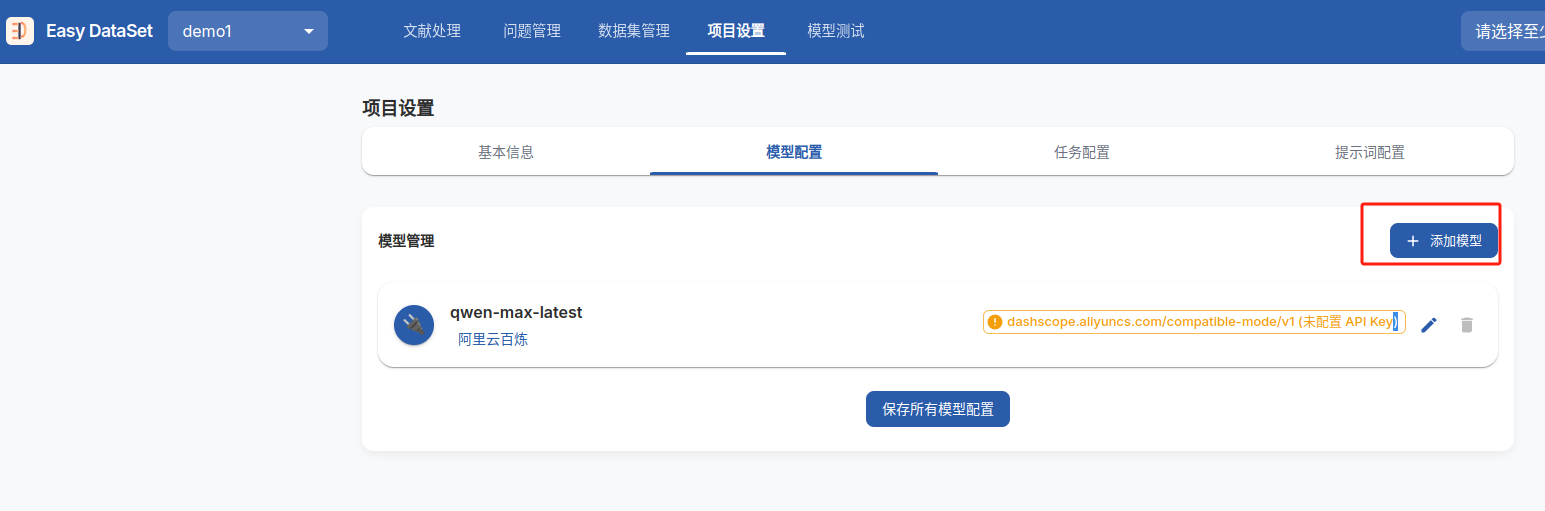
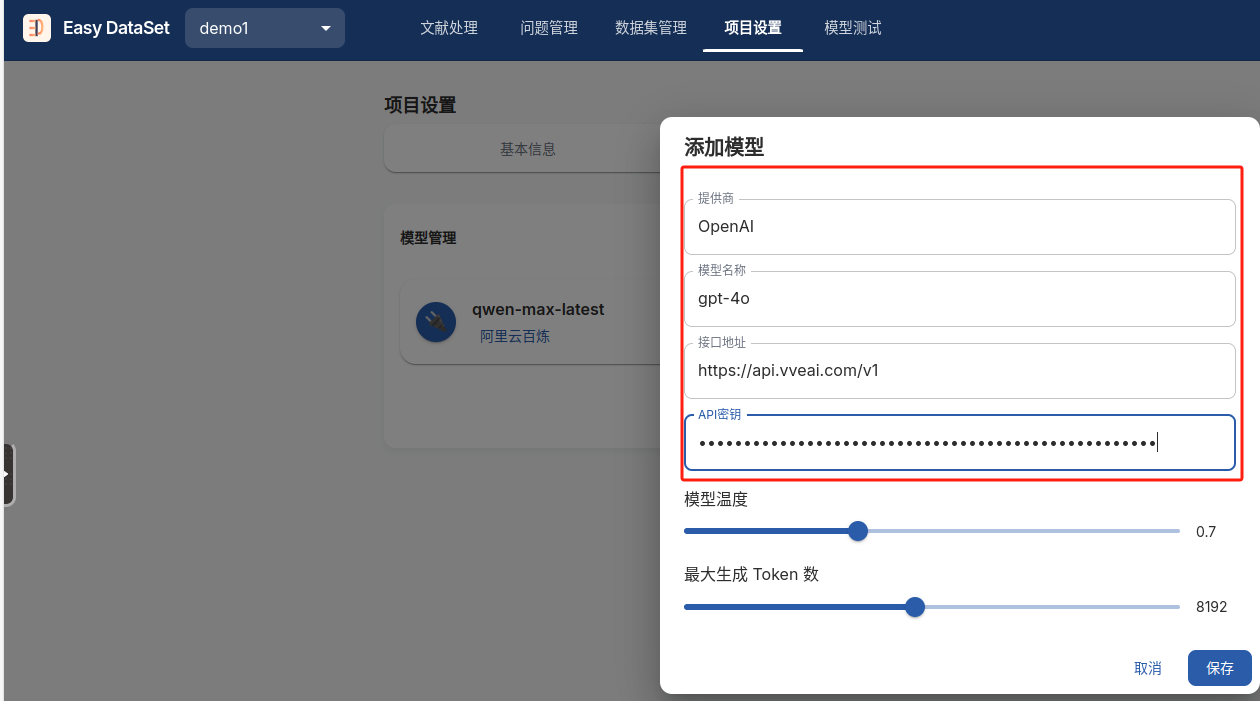
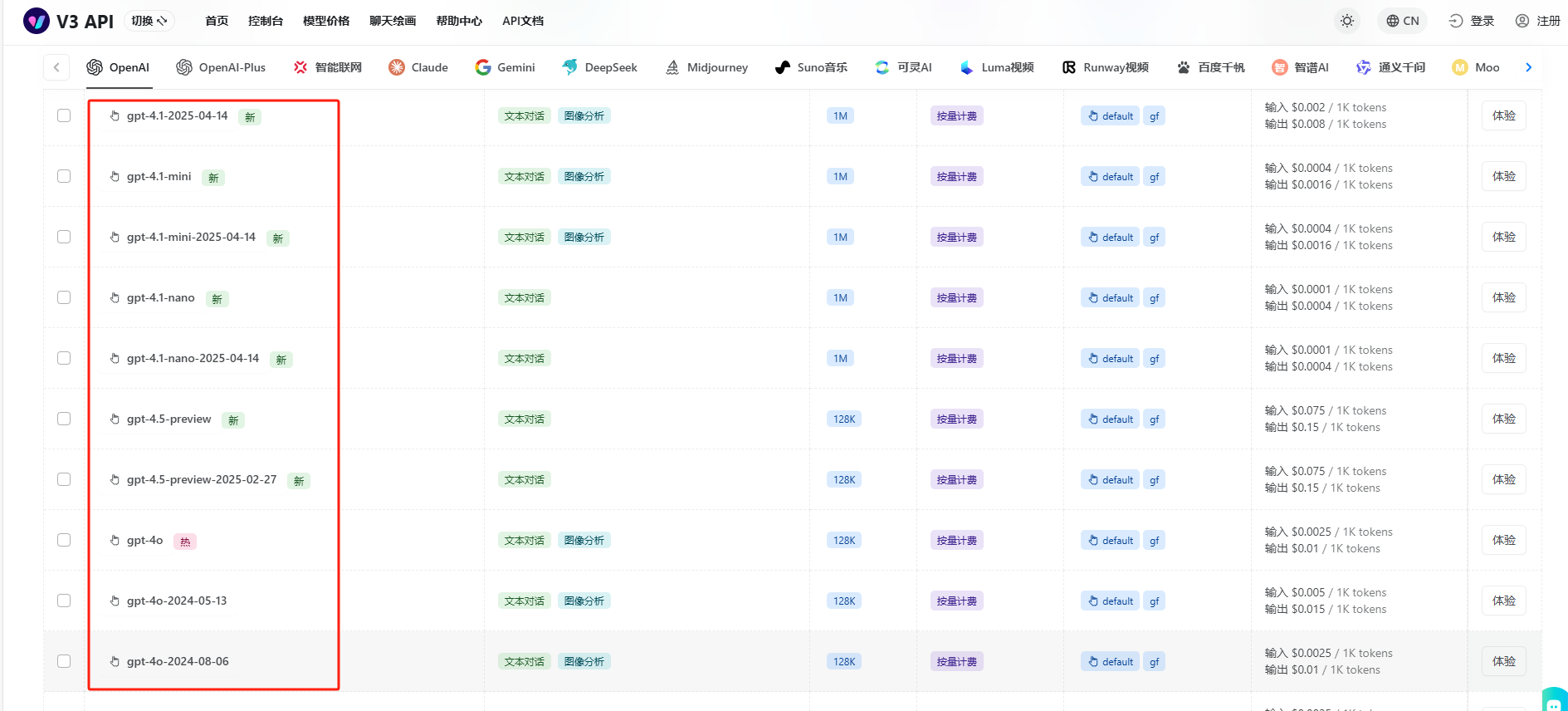
完成模型基本信息填写,包括但不限于base_url、api_key、选用的模型名称(从https://api.gpt.ge/pricing?tab=OpenAI中有可供选择的模型列表,选择后需要按量付费)
可供选择的模型列表
模型配置完成之后,可以在模型测试输入对话看模型是否配置成功,有回复则配置成功
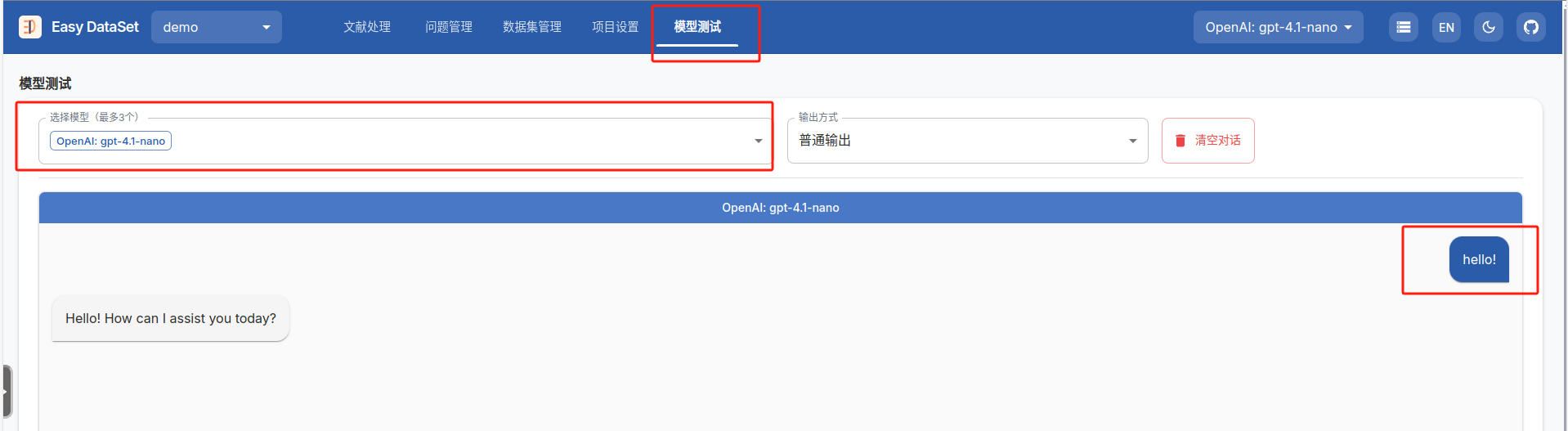
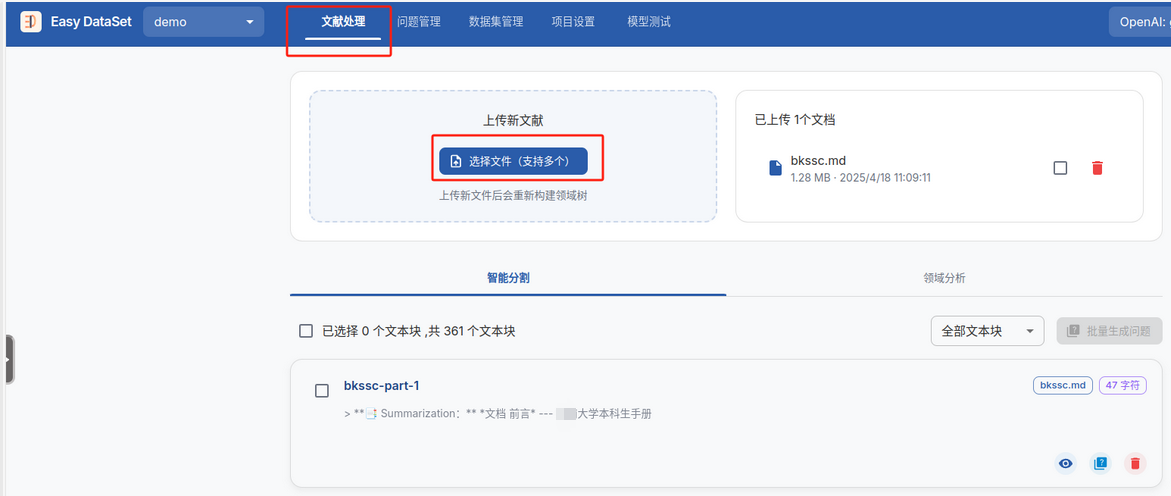
上传文件(此处推荐上传markdown类型的文件,如果手里只有pdf文件,推荐使用mineru:pdf转markdown工具)
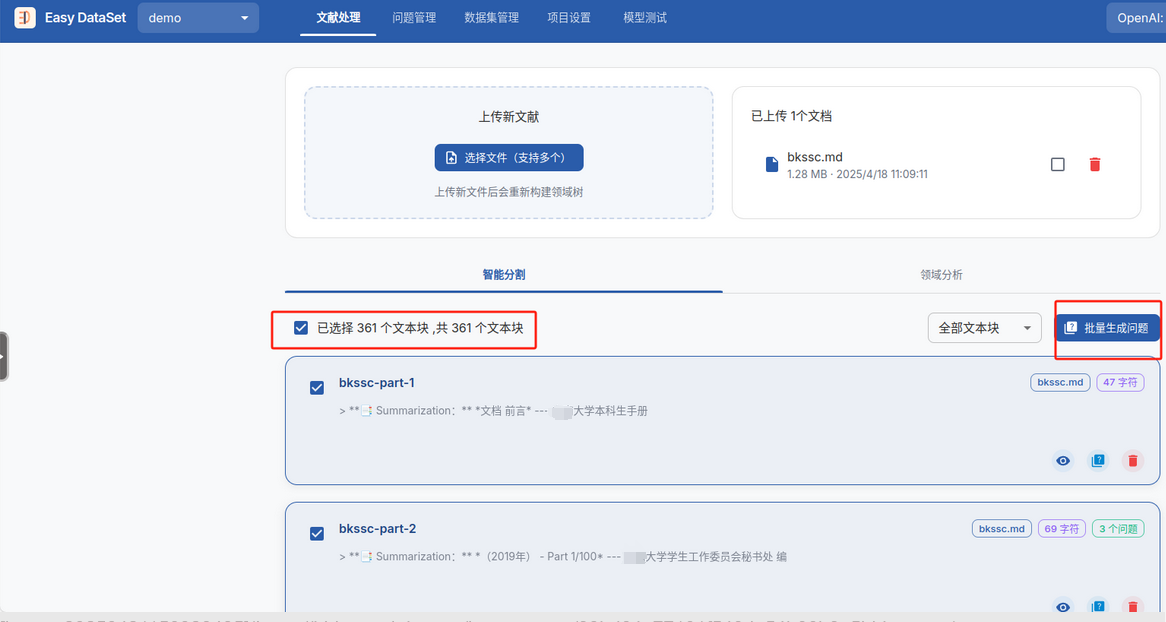
EasyDataSet进行智能分割之后,调用模型API进行批量生成问题
生成问题之后,进入问题管理,选择质量好的问题,批量构造数据集
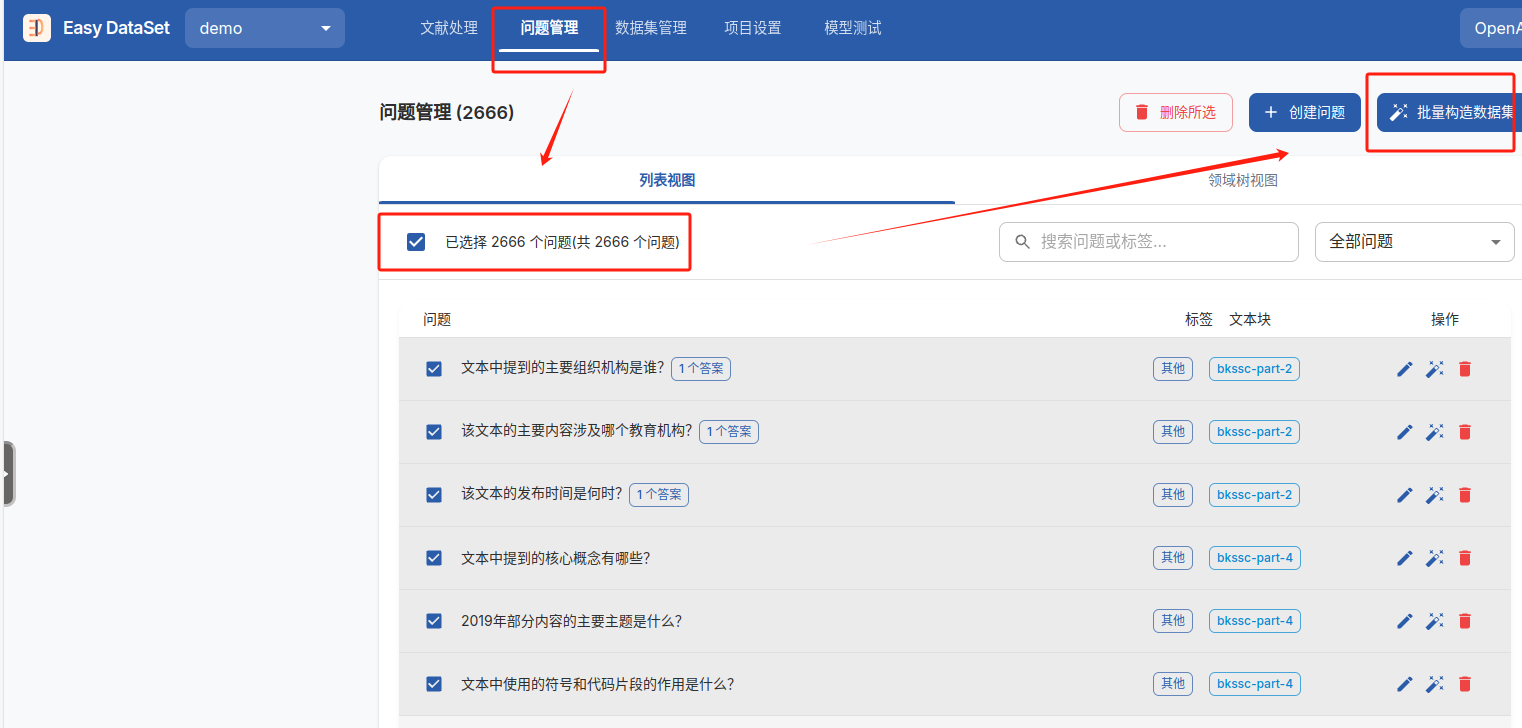
构造数据集后,进入数据集管理,选择质量好的问题,导出数据集(70页的word文档,生成了2666条问题,大概有效的有1786条问题 )
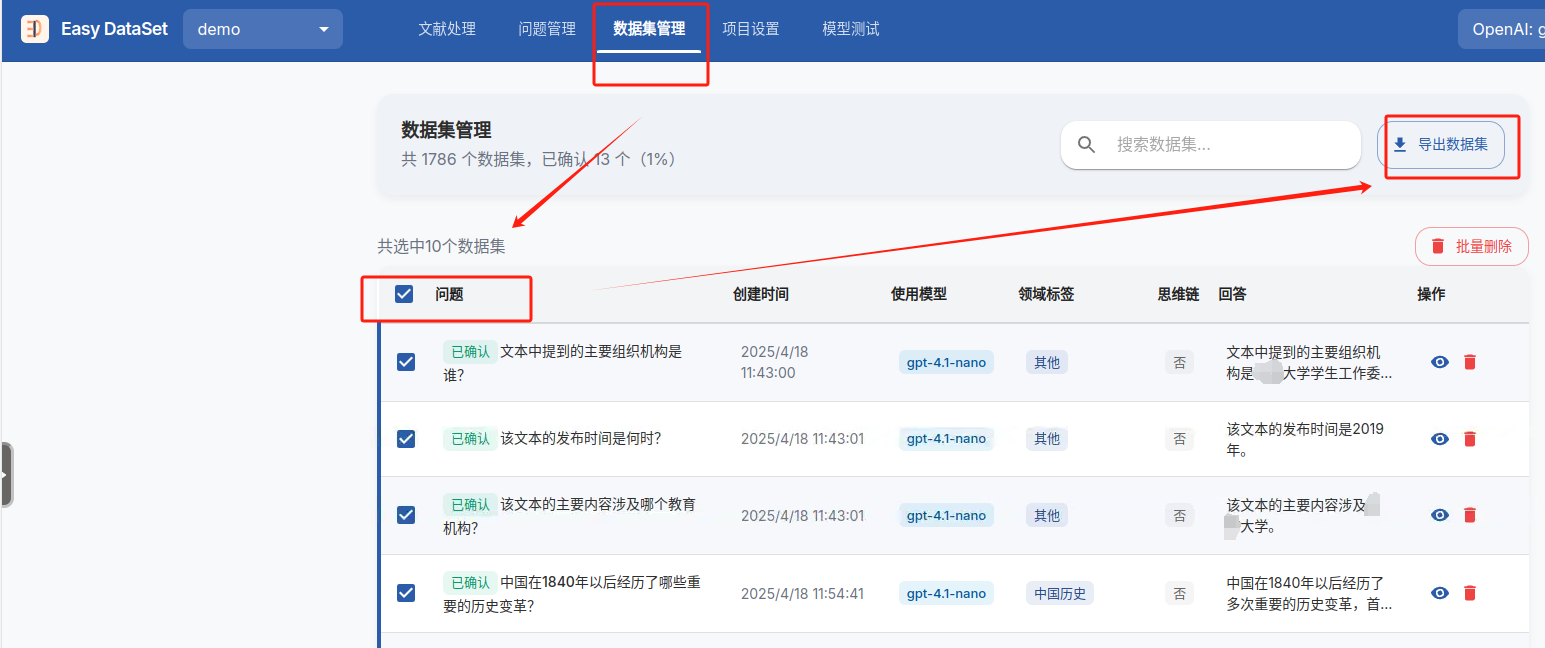
选择文件格式为JSONL,数据集风格为ShareGPT,不包含思维链,确认导出
在导出大模型微调数据集时,“提问是否包含思维链” 这一选项通常指的是生成的提问(Question)是否显式包含模型推理所需的中间步骤或逻辑链条(Chain-of-Thought, CoT)
我的目标是通过xx大学本科生手册来微调大模型,就是简单的规章制度问答问题,显然不需要思维链
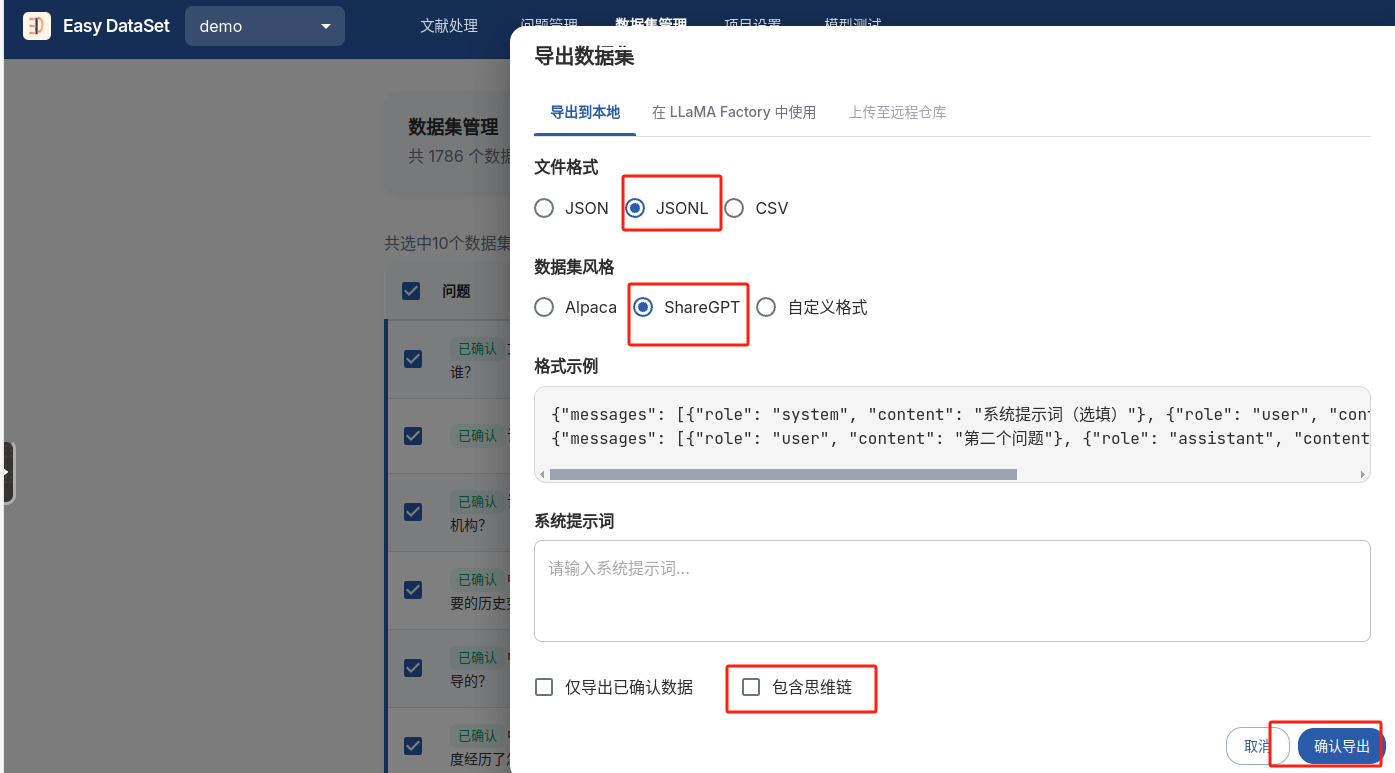
数据集导出成功
easy-dataset部署在7860端口,对应局域网 192.168.10.23:50014

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)