使用BlenderProc制作自己的6D位姿估计数据集,并使用开源代码进行训练
介绍了基于BlenderProc的虚拟数据集制作流程,并使用基于YOLOX框架的开源代码进行训练,最终得到了输入为单一RGB图像,输出为物体6D位姿的模型。
目录
2.2.1 下载Blenderproc与bop_toolkit并安装
1 引言
从11月中开始接到任务,跑一份基于YOLOX的位姿估计代码。前后用了大概一个月的时间来打通这一套流程。因为之前从来没有接触过6D位姿估计,所以其实干的都是一些工程性质的工作,跑代码调bug。虽然最终效果并不是很理想,但是还是希望记录总结一下。这整个流程很多地方我自己还是一知半解,主要是图个跑通代码,不正确之处还请各位大佬指教。
使用https://github.com/TexasInstruments/edgeai-yolox.git开源代码进行训练,目的是识别灭火器的6D位姿。
这套流程大致分为三个部分:
1.制作灭火器模型文件
2.制作6D位姿估计数据集
3.使用开源代码进行训练
2 步骤
2.1 制作ply格式的灭火器模型文件
环境:blender 4.0.2
前期准备:灭火器.stl文件
2.1.1 导入文件
打开blender软件,左上角文件选项,导入.stl文件。
2.1.2 选择模型原点
根据需求选择模型的原点。这将影响blenderproc生成数据集时的gt数据。比如模型原点如果在灭火器底部,那么物体坐标系将以此为原点。
xyz轴同理,根据需要进行调整。右键选择“设置原点”可以更改原点位置。快捷键n可以唤起变换面板,在这里调整模型的位置、旋转、缩放以及比例。
2.1.3 绘制模型颜色
在这里踩了一个坑。.ply文件仅保存顶点颜色信息,因此不可以仅绘制纹理,需要进行顶点颜色绘制。
点击“纹理绘制”选项卡,选择顶点绘制,然后就可以按照需要对模型进行上色。
注意:我的项目识别目标为灭火器,不需要太多精细的纹理信息,因此直接上色就可以满足需求。
对于需要精确纹理信息的模型,可能还需要其他操作。这部分我不太了解,在此不做拓展。
4.导出.ply文件
左上角文件选项,导出.ply文件。选择ASCII格式,勾选uv坐标与顶点法向信息,导出。
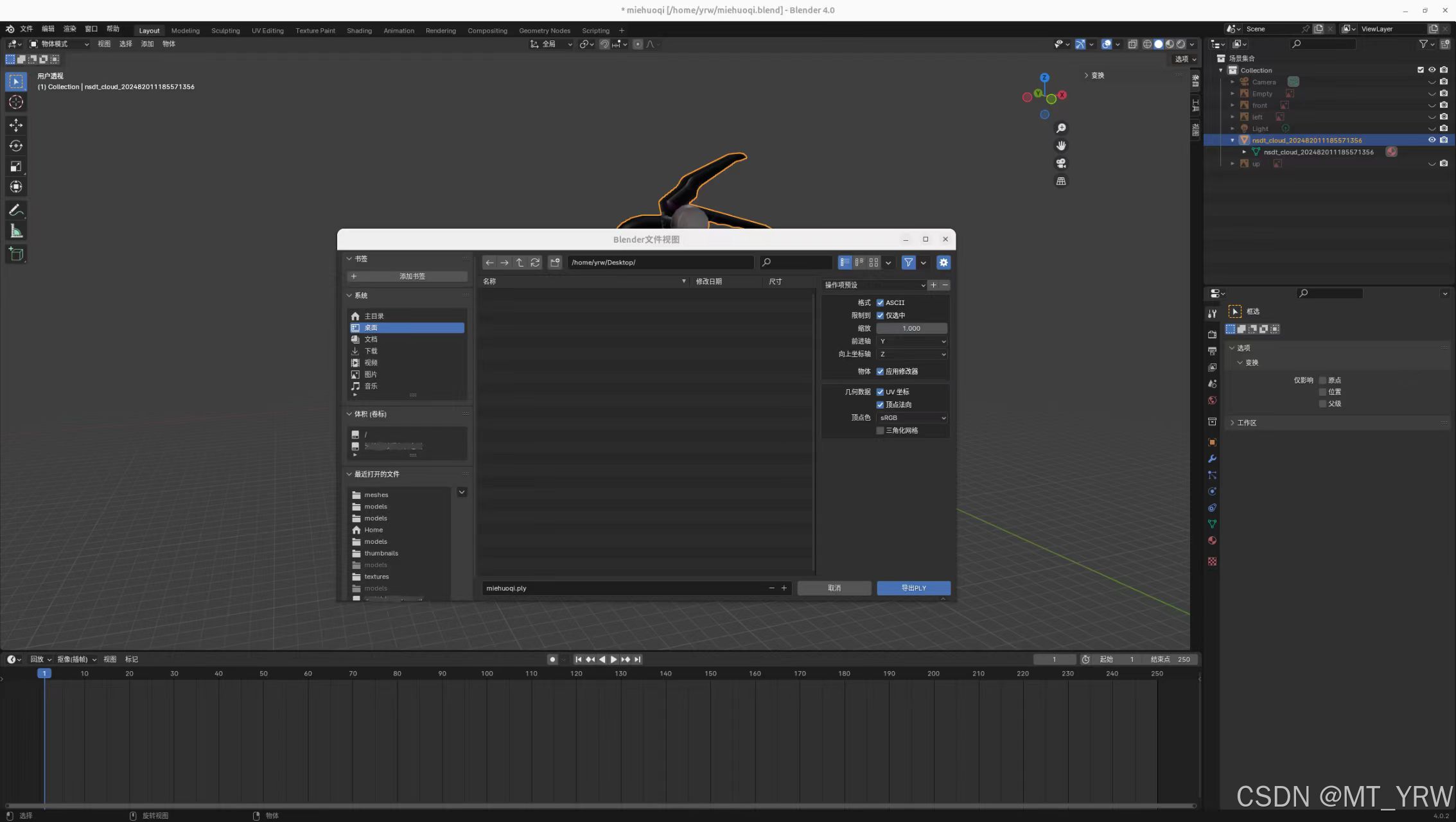
至此完成了.ply模型文件的准备
2.2 制作6D位姿估计数据集
环境:Blenderproc 2.8.0,bop_toolkit_lib 1.0
前期准备:.ply模型文件
2.2.1 下载Blenderproc与bop_toolkit并安装
地址:https://github.com/DLR-RM/BlenderProc.git
https://github.com/thodan/bop_toolkit.git
安装这两个库只需要跟着readme文件一步步走就可以了,在此不多加赘述。
2.2.2 制作model_info.json文件
model_info.json文件存储了模型的尺寸信息。可以使用meshlab软件来进行获取。
meshalab安装非常简单:
sudo apt-get install meshlab终端输入meshlab,打开meshlab软件:
meshlab
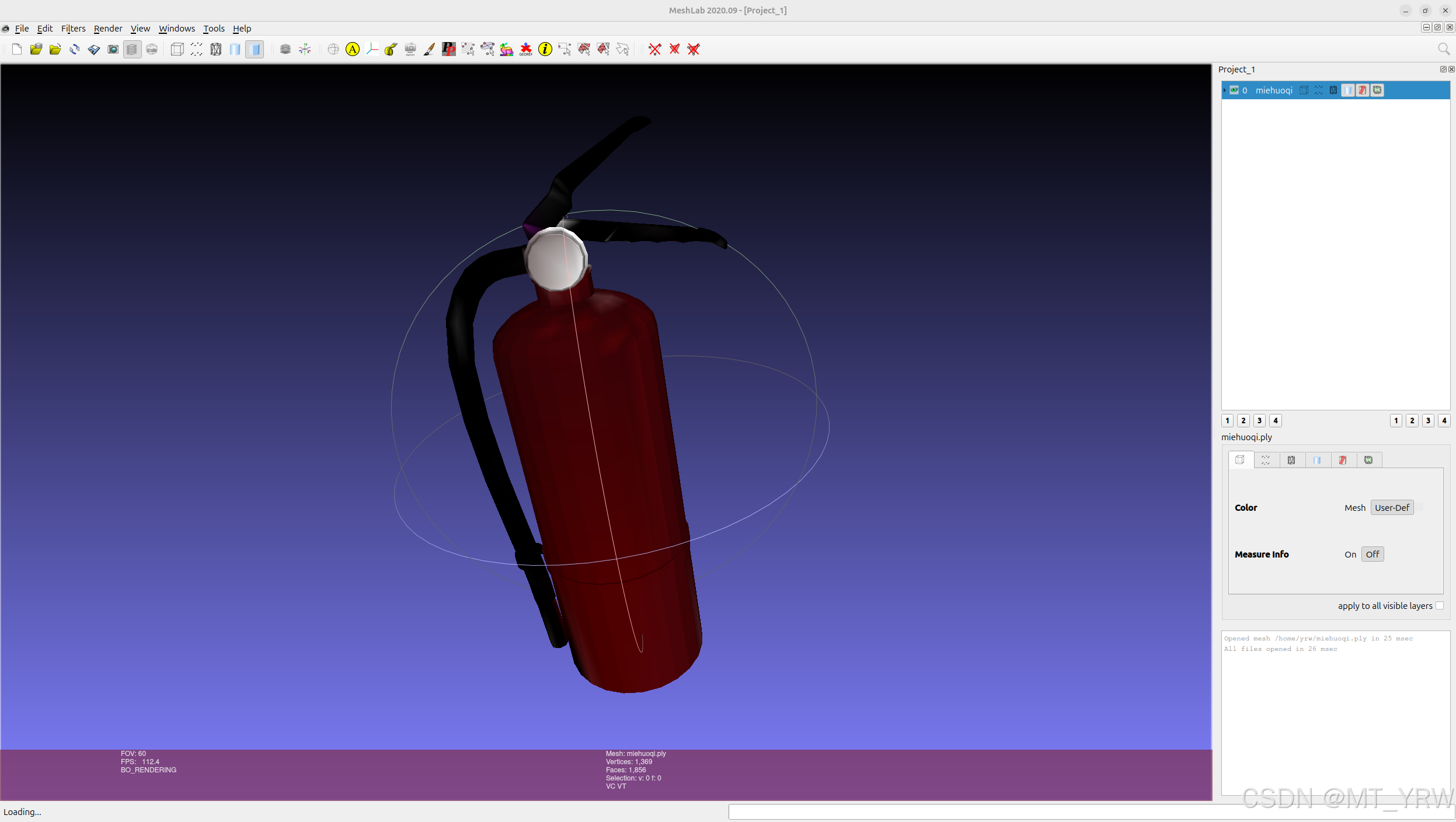
将2.1中制作好的.ply模型文件导入
选中模型文件,点击filters选项卡中Quality Measure and Computations,选择Compute Geometric Measures。
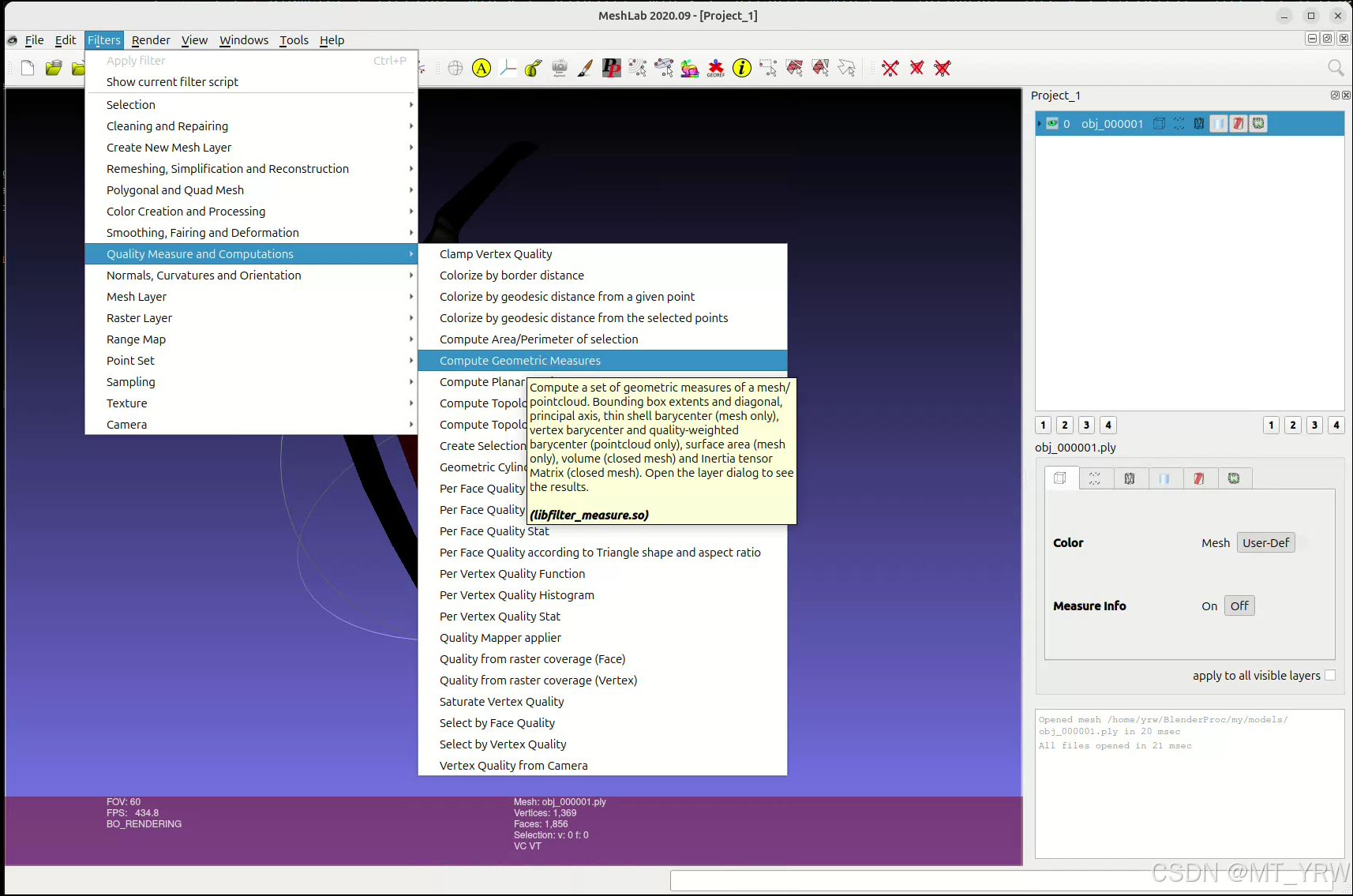
最终在页面右下角会出现相应的模型数据。
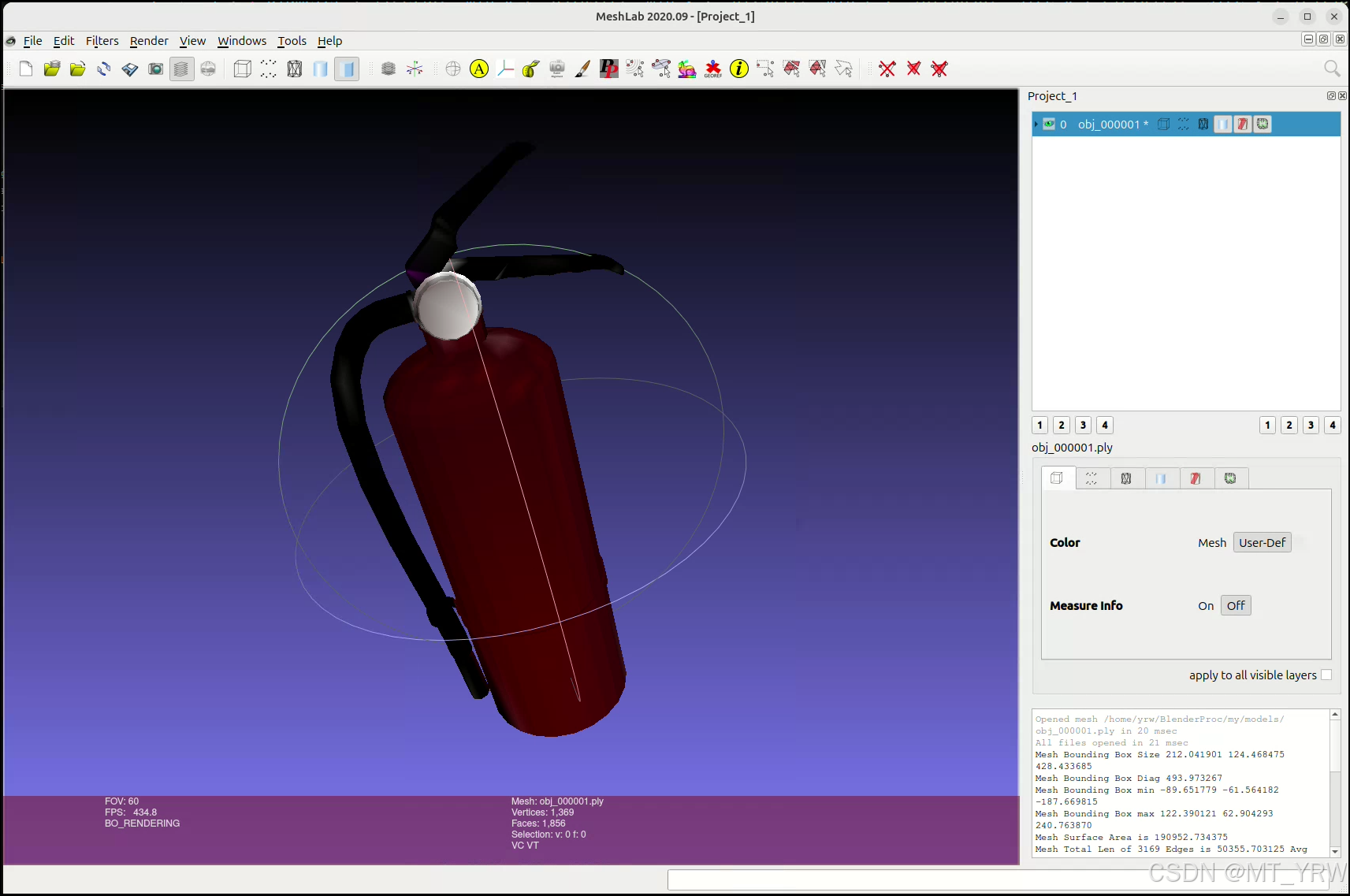
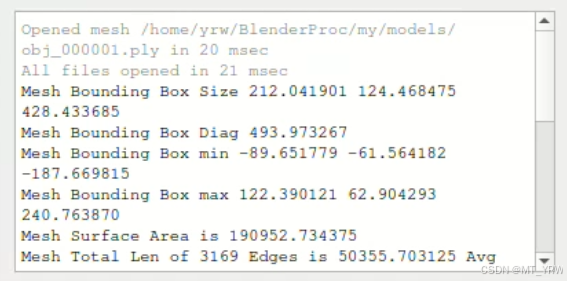
将输出的信息写入model_info.json文件中。

2.2.3 文件结构
在使用blenderproc库来生成数据集之前,确保你的文件夹以此格式存在于Blenderproc文件夹内:
blenderproc
├──my
├── models
├──model_info.json
├──obj_000001.ply
└── camera.json其中,camera.json是相机内参数据,内容如下:
{
"cx": 327.582,
"cy": 247.230,
"depth_scale": 1.0,
"fx": 601.949,
"fy": 601.940,
"height": 480,
"width": 640
}2.2.4 修改接口文件
生成数据集的文件存在于/BlenderProc/examples/datasets/bop_challenge/中。
我在学习这套流程的时候以lm数据集作为模板,因此对main_lm_upright.py的内容进行修改,使得blenderproc可以生成仅包含目标灭火器的数据集。
修改1
main_lm_upright.py 16行:
target_bop_objs = bproc.loader.load_bop_objs(bop_dataset_path = os.path.join(args.bop_parent_path, 'lmo'), mm2m = True)改为:
target_bop_objs = bproc.loader.load_bop_objs(bop_dataset_path = os.path.join(args.bop_parent_path, 'my'), mm2m = True)修改2
main_lm_upright.py 24行
bproc.loader.load_bop_intrinsics(bop_dataset_path = os.path.join(args.bop_parent_path, 'lmo'))改为:
bproc.loader.load_bop_intrinsics(bop_dataset_path = os.path.join(args.bop_parent_path, 'my'))修改3
main_lm_upright.py 143行
bproc.writer.write_bop(os.path.join(args.output_dir, 'bop_data'),
target_objects = sampled_target_bop_objs,
dataset = 'lmo',
depth_scale = 0.1,
depths = data["depth"],
colors = data["colors"],
color_file_format = "JPEG",
ignore_dist_thres = 10)改为:
bproc.writer.write_bop(os.path.join(args.output_dir, 'bop_data'),
target_objects = sampled_target_bop_objs,
dataset = 'my',
depth_scale = 0.1,
depths = data["depth"],
colors = data["colors"],
color_file_format = "JPEG",
ignore_dist_thres = 10)修改4
/home/your_name/blender/blender-4.2.1-linux-x64/custom-python-packages/lib/python3.11/site-packages/bop_toolkit_lib/dataset_params.py
get_model_params函数,增加"my":[1]:
# Object ID's.
obj_ids = {
"lm": list(range(1, 16)),
"lmo": [1, 5, 6, 8, 9, 10, 11, 12],
"tless": list(range(1, 31)),
"tudl": list(range(1, 4)),
"tyol": list(range(1, 22)),
"ruapc": list(range(1, 15)),
"icmi": list(range(1, 7)),
"icbin": list(range(1, 3)),
"itodd": list(range(1, 29)),
"hbs": [1, 3, 4, 8, 9, 10, 12, 15, 17, 18, 19, 22, 23, 29, 32, 33],
"hb": list(range(1, 34)), # Full HB dataset.
"ycbv": list(range(1, 22)),
"hope": list(range(1, 29)),
"hopev2": list(range(1, 29)),
"hot3d": list(range(1, 34)),
"handal": list(range(1, 41)),
"my":[1],
}[dataset_name]解释:obj_ids用来读取.ply文件,“my”这个名字要与2.2.3文件结构中的文件名对齐。
修改5
同修改4,dataset_params.py中,get_model_params函数
symmetric_obj_ids = {
"lm": [3, 7, 10, 11],
"lmo": [10, 11],
"tless": list(range(1, 31)),
"tudl": [],
"tyol": [3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 15, 16, 17, 18, 19, 21],
"ruapc": [8, 9, 12, 13],
"icmi": [1, 2, 6],
"icbin": [1],
"itodd": [2, 3, 4, 5, 7, 8, 9, 11, 12, 14, 17, 18, 19, 23, 24, 25, 27, 28],
"hbs": [10, 12, 18, 29],
"hb": [6, 10, 11, 12, 13, 14, 18, 24, 29],
"ycbv": [1, 13, 14, 16, 18, 19, 20, 21],
"hope": [],
"hopev2": [],
"hot3d": [1, 2, 3, 5, 22, 24, 25, 29, 30, 32],
"handal": [26, 35, 36, 37, 38, 39, 40],
"my":[],
}[dataset_name]解释:这部分代码存储了具有对称性的模型的id。如果模型不对称,写空即可
修改6
同修改4,dataset_params.py中,get_split_params函数,加入以下代码:
elif dataset_name == "my":
p["scene_ids"] = {"train": [1], "test": [2]}[split]
p["im_size"] = (640, 480)
if split == "test":
p["depth_range"] = (346.31, 1499.84) # Range of camera-object distances.
p["azimuth_range"] = (0, 2 * math.pi)
p["elev_range"] = (0, 0.5 * math.pi)2.2.5 下载背景纹理文件
blender会随机加载背景纹理信息来生成数据集。
新建文件夹backgrounds,在该文件夹下打开终端,使用以下命令行来下载纹理信息:
blenderproc download cc_textures 下载一部分就可以ctrl+c停止了。
2.2.6 下载开源数据集模型
在生成数据集时,main_lm_upright.py文件的19、20、21行加载了一部分其他数据集的模型作为干扰以形成遮挡,从而提高生成数据集的质量。因此在运行命令之前,需要下载对应的数据集模型。bop官网网址:BOP: Benchmark for 6D Object Pose Estimation
main_lm_upright.py中需要的数据集模型包含tless、ycbv与tyol。在官网中找到对应的数据集的Base archive与Object models,下载。
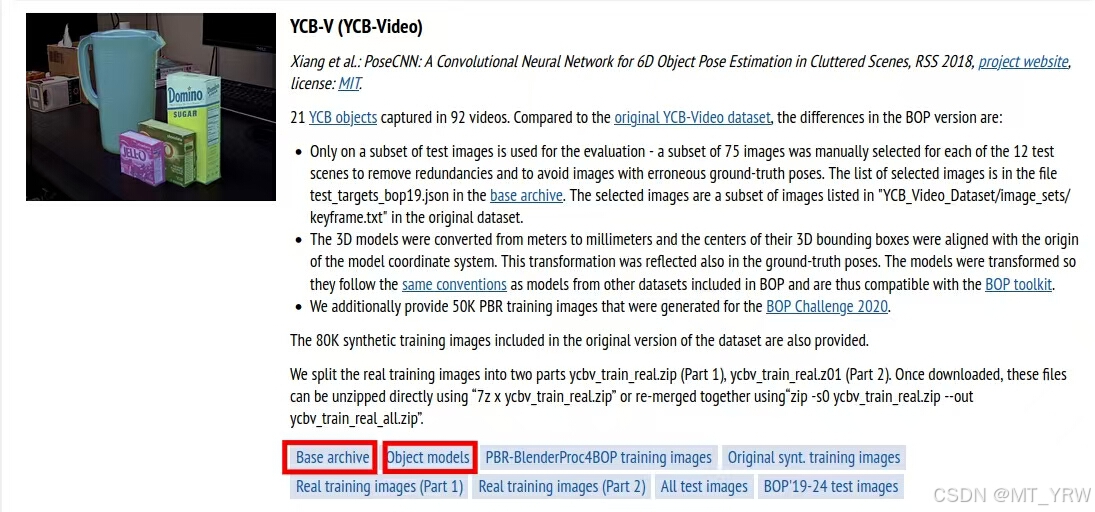
解压后放入“my”文件夹的同级目录中。

2.2.7 生成数据集
在生成数据集之前需要注意:
64-67行代码分别对目标物体与干扰物体进行了随机抽样。
sampled_target_bop_objs = list(np.random.choice(target_bop_objs, size=1, replace=False)) ##### 15
sampled_distractor_bop_objs = list(np.random.choice(tless_dist_bop_objs, size=1, replace=False))
sampled_distractor_bop_objs += list(np.random.choice(ycbv_dist_bop_objs, size=1, replace=False))
sampled_distractor_bop_objs += list(np.random.choice(tyol_dist_bop_objs, size=1, replace=False))代码64行对加载的目标模型进行了随机抽样,其中size为抽样数量,replace代表了是否有放回抽样。
这里建议使用无放回抽样,并将size改为输入模型的数量,保证每次数据集生成时,所有模型都会出现在图像中。
同理,65-67行对加载的干扰模型进行了随机抽样。如果不需要干扰物体,可以注释掉这几行代码,也可以修改65-67行代码的size参数来改变干扰物体的数量。(我在这里设置了1)
使用以下命令行生成数据集:
blenderpoc run examples/datasets/bop_challenge/main_lm_upright.py
<path_to_bop_data>
resources/cctextures
examples/datasets/bop_challenge/output其中,<path_to_bop_data>是模型文件夹的路径,resources/cctextures 是包含背景纹理文件夹的路径,examples/datasets/bop_challenge/output 是输出路径。

每次执行这个命令行的时候,blender会随机选择一种房间背景纹理,并将物体随机摆放到这个生成的房间内,拍摄25张图像。如果想每次多生成一些图像,可以修改main_lm_upright.py中116行的while cam_poses < 25语句。
重新执行命令行会再次随机选择房间背景纹理并随机摆放物体。如果输出目录不变,那么新生成的图像与数据将会自动加入之前已经生成的文件夹,并不会覆盖上一次的数据。
即:数据集数量 = cam_poses 命令行运行次数
可以根据需求调整cam_poses条件句和运行命令行的次数。
比如:while cam_poses < 100,并执行10次命令行,则最终的数据集会包含1000张图像信息。
生成后的数据集文件夹格式如下:
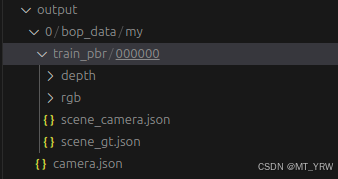
其中,scene_camera.json存储了相机的内参与外参,scene_gt.json存储了物体的旋转矩阵、平移矩阵以及物体类别id。
将生成的数据集以以下格式存放于文件夹中:
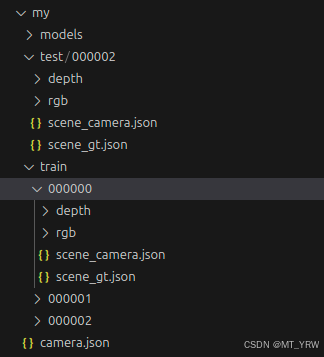
其中,每个文件夹(000000、000001、000002)中数据集的数量最好保持一致。但文件夹的个数可以根据需求而定。在我的例子中,train中每个文件夹包含1000张数据集,一共3000张。
2.2.8 生成标注文件
lmo数据集的格式如下所示:
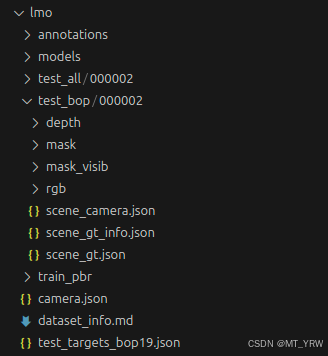
通过BlenderProc生成的数据集仅包含了深度图像、彩色图像、scene_camera.json与scene_gt.json文件,接下来还需要通过bop_toolkit来生成mask、mask_visib和scene_gt_info.json文件。其中,mask包括了目标物体掩码;mask_visib包括了相机可见部分的目标物体掩码;scene_gt_info.json包含了物体边界框、可见边界框、所有像素数量、有效像素数量、可见像素数量与可见比例。
bop_toolkit中的calc_gt_info.py与calc_gt_masks.py对应了这三份文件的生成。
首先对dataset_params.py进行修改。方法与2.2.4修改接口文件中的修改4到修改6完全相同,不过这次修改的dataset_params.py位于/your/path/to/bop_toolkit/bop_toolkit_lib/dataset_params.py中。
其次,对/your/path/to/bop_toolkit/bop_toolkit_lib/config.py进行修改。只需要修改15行的路径即可。将其改为:
datasets_path = r"/path/to/your/datasets/"注意,只需要写到数据集的上一级目录即可。比如我的数据集位置:/home/ubuntu/edgeai-yolox/datasets/my,则将config.py中的路径修改为“/home/ubuntu/edgeai-yolox/datasets/“即可。
最后,修改calc_gt_info.py的29行与calc_gt_masks.py的23行
"dataset_split": "train"注意,需要保证数据集文件夹的名字与该项一致。
使用命令行运行文件生成标注:
python calc_gt_info.py
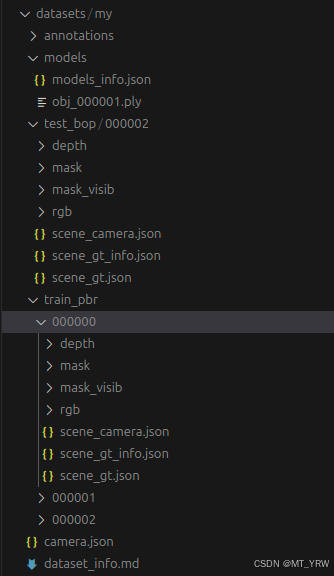
python calc_gt_masks.py训练集标注生成完毕后,将"dataset_split"参数改为“test”,重新运行命令行。
最终得到的数据集如图所示:
2.3 使用开源代码进行训练
使用了https://github.com/TexasInstruments/edgeai-yolox.git这份开源代码进行训练,目的是识别灭火器的6D位姿。
这份代码基于YOLOX框架,对ycbv与lmo两个开源数据集进行了训练。因此如果希望利用这套代码训练自己的数据集。需要对代码多处进行修改。在此不一一赘述,如果有需要可以直接git我修改后的代码。
修改后的代码链接:https://github.com/MT-YRW/edgeai-yolox-MY.git
可以直接替换单一物体数据集并使用yolox-s模型进行训练。具体的训练过程可以参考我的readme文件。
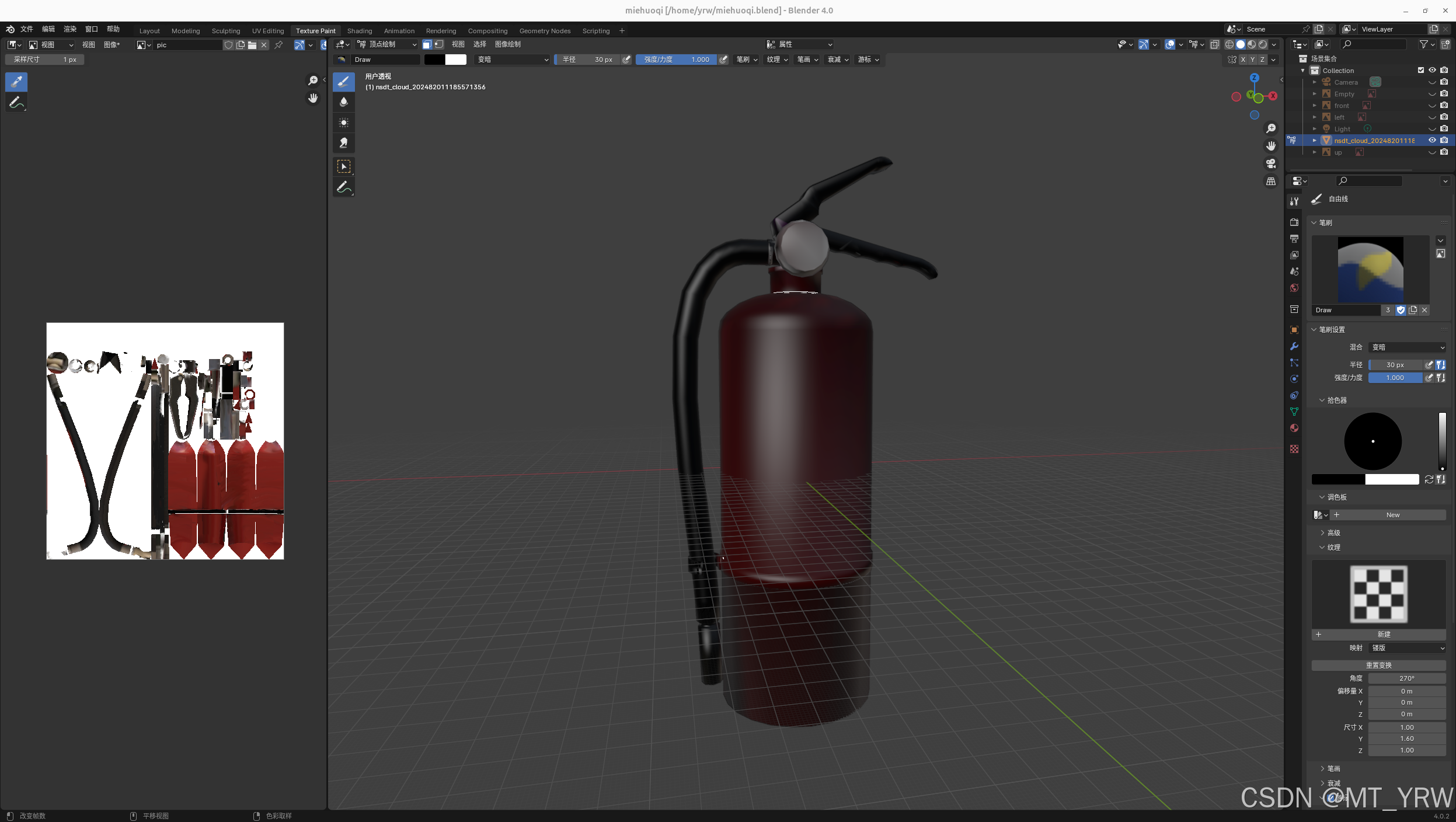
3000张训练集,500张测试集,训练150轮。最终模型的训练效果如图所示。



由于我的训练集和测试集都是由BlenderProc渲染得到的虚拟数据集,且使用的物体模型并不是完全按照真实检测的灭火器进行制作,因此检测虚拟物体时精度较好,而检测真实物体时精度会有所下降。同时由于硬件的关系,使用的相机无法输出640480的图像,而是输出1280
720的图像。这导致推理之前需要过一个cv.resize,我猜测也一定程度上导致了识别不准确。
3 总结
介绍了一种基于BlenderProc的虚拟数据集制作方法,并使用基于YOLOX框架的开源代码进行训练,最终得到了输入为单一RGB图像,输出为物体6D位姿的模型。
虽然我成功进行训练并得到了较为准确的识别结果,但是我对6D位姿估计和edgeai-yolox这套开源代码的理解还非常浅显。如果你在进行相关的工程或者研究,希望这篇博客能够提供一些帮助。
如果有表述不正确的地方,还请各位大佬们指正。
4 参考链接与文献
6D位姿估计--BlenderProc合成数据集-CSDN博客
Blender——苹果的纹理绘制_blender纹理绘制-CSDN博客
https://github.com/TexasInstruments/edgeai-yolox.git
https://github.com/DLR-RM/BlenderProc.git

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)