详解使用Anaconda Prompt训练和测试YOLOv8(训练自己的数据集)
Yolov8是Ultralytics公司推出的Yolo系列目标检测算法,可以用于图像分类、物体检测和实例分割等任务。YOLOv8有很多种下载和配置方法,这里提供两种方法。推荐在虚拟环境中使用pip命令下载,这个下面会介绍。ultralytics 是一个专注于计算机视觉任务的 Python 库,提供了从模型加载、训练到导出的完整功能。无论是研究还是生产环境,ultralytics 都能满足需求。最好
在计算机视觉领域,目标检测技术始终占据着核心地位。YOLOv8在继承前代优势的基础上,进一步优化性能,在学术和工业上都受到强烈关注。YOLO系列模型训练和测试都有比较套路的流程,因此这里写一个博客作为备忘录,把关键步骤记录下来,希望也能帮助到大家快速上手 YOLOv8 。
前言
Yolov8是Ultralytics公司推出的Yolo系列目标检测算法,可以用于图像分类、物体检测和实例分割等任务。YOLOv8有很多种下载和配置方法,这里提供两种方法。
- 官网下载:YOLOv8-github
- 使用pip命令下载:pip install ultralytics
推荐在虚拟环境中使用pip命令下载,这个下面会介绍。ultralytics 是一个专注于计算机视觉任务的 Python 库,提供了从模型加载、训练到导出的完整功能。无论是研究还是生产环境,ultralytics 都能满足需求。
一、环境配置
电脑系统:windows
pytorch版本:torch1.9.0+cu102,torchvision0.10.0+cu102,python 3.9(torch1.9和python3.9可兼容目前绝大多数yolo模型)
工具:Anaconda
1. Anaconda安装
Anaconda 主要用于数据科学、机器学习和科学计算。它提供了一个方便的环境管理工具Anaconda Prompt,使用户可以轻松地创建、管理和切换不同的 Python 环境。本文使用Anaconda Prompt进行yolov8的训练、测试和导出。
Anaconda清华镜像源下载
最新版最详细Anaconda新手安装+配置+环境创建教程
我下载的是“Anaconda3-2023.03-1-Windows-x86_64”
2. 创建虚拟环境
做新项目建议新建一个虚拟环境,尤其是yolo这种比较大的项目,可避免了各种包的版本的冲突。打开Anaconda Prompt,建立一个名为yolov8虚拟环境
conda create -n yolov8 python=3.9 -y
建立后激活所建立的虚拟环境
conda activate yolov8
3. 在虚拟环境中安装必要的库(torch、requirements.txt)
在激活虚拟环境的条件下,安装最重要的torch库。安装的pytorch版本是1.9.0,torchvision版本是0.10.0,python是3.9,其他的依赖库按照requirements.txt文件安装即可。不想查torch版本的话可直接复制下面命令即可
pip install torch==1.9.0+cu102 torchvision==0.10.0+cu102 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
然后安装requirements.txt中其他依赖项,requirements.txt内容如下:(新建一个txt文件,命名为requirements.txt,把下面内容复制过去)
# Ultralytics requirements
# Usage: pip install -r requirements.txt
# Base ----------------------------------------
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.6.0
Pillow>=7.1.2
PyYAML>=5.3.1
requests>=2.23.0
scipy>=1.4.1
#torch>=1.7.0
#torchvision>=0.8.1
tqdm>=4.64.0
# Logging -------------------------------------
tensorboard>=2.4.1
# clearml
# comet
# Plotting ------------------------------------
pandas>=1.1.4
seaborn>=0.11.0
# Export --------------------------------------
# coremltools>=6.0 # CoreML export
# onnx>=1.12.0 # ONNX export
# onnxsim>=0.4.1 # ONNX simplifier
# nvidia-pyindex # TensorRT export
# nvidia-tensorrt # TensorRT export
# scikit-learn==0.19.2 # CoreML quantization
# tensorflow>=2.4.1 # TF exports (-cpu, -aarch64, -macos)
# tflite-support
# tensorflowjs>=3.9.0 # TF.js export
# openvino-dev>=2022.3 # OpenVINO export
# Extras --------------------------------------
psutil # system utilization
thop>=0.1.1 # FLOPs computation
# ipython # interactive notebook
# albumentations>=1.0.3
# pycocotools>=2.0.6 # COCO mAP
# roboflow
certifi>=2022.12.7 # not directly required, pinned by Snyk to avoid a vulnerability
在虚拟环境下使用cd命令进入到requirements.txt所在位置,直接用以下命令安装就行,这里我是把requirements.txt放在桌面上了
pip install -r requirements.txt

注意,在下载依赖项时numpy默认版本超过了2.0,可能导致后面运行不兼容。因此在安装好requirements.txt中的依赖项后,手动对numpy降级,比如安装版本在1.15.0~1.26.0。以numpy1.23.0为例。
pip install numpy==1.23.0
4. 安装ultralytics库
ultralytics 库是开源的目标检测框架,支持 YOLOv5、v8 、v9、v10等最新版本的 YOLO 模型。安装也相当简单,在虚拟环境中直接pip,这里我安装的是ultralytics 8.3.105。
pip install ultralytics==8.3.105
最后安装的库如下所示:
注意,以上所有库的安装都需在虚拟环境下进行,所安装的库都在以下路径中
D:\Anaconda\envs\yolov8\Lib\site-packages
到这里所有库的安装工作就完成了。接下来就可以准备数据集了。
二、整理自己的数据集
这里我在免费网站https://www.cvmart.net/dataSets下载的公开数据集,里面有大量可用于目标检测的图片。我下载的是fire_smoke数据集,里面大约100张图片,链接https://www.cvmart.net/dataSets/detail/314。你也可以用自己的数据集。
1. 数据标注工具
使用标注工具给图片标注,生成可用于训练的标签形式。如labelimg、labelme,make sense等。
推荐一款非常好用的在线数据标注工具make sense。可用于小型数据集标注非常方便,注意导出标签时选择yolo格式。下面是make sense网站链接。

2. 数据集格式
创建一个名为mydata的文件夹,里面有images、labels两个文件夹:
images: 包含train和val两个文件夹,每个文件夹下存放图片(.jpg)
labels:包含train和val两个文件夹,每个文件夹下存放标注信息,yolo格式(.txt)
3. 建立mydata.yaml
新建一个txt文件,把名字改为mydata.yaml(注意后缀.txt要改成.yaml),再把下面内容复制过去,只需要修改自己的数据集路径和类别就行
- mydata.yaml包含需要训练的图片的根目录path,以及train和val的具体位置。并修改类别数“nc”和类别名“names”。如果是在自己电脑上训练,建议使用绝对路径(我这里是把mydata文件夹放在桌面)
mydata.yaml内容如下(上面注释部分不用管):
# Ultralytics YOLO 🚀, GPL-3.0 license
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco # dataset root dir
train: C:\Users\huangda\Desktop\mydata\images\train # train images (relative to 'path') 118287 images
val: C:\Users\huangda\Desktop\mydata\images\val # val images (relative to 'path') 5000 images
test: # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 2
names:
0: fire
1: smoke
mydata.yaml整理好放到“…\Anaconda\envs\yolov8\Lib\site-packages\ultralytics\cfg\datasets”文件夹里。这个文件夹其实就是上面安装的ultralytics里的文件夹,里面全是.yaml文件。(一定将mydata.yaml放在此文件夹下,这样就不用考虑路径问题)
- D:\Anaconda\envs\yolov8\Lib\site-packages\ultralytics\cfg\datasets

这样数据部分也准备好了,下面就可以开始训练了。
三、YOLOV8训练、测试和导出
yolov8有两种方式可进行训练、测试:
- 在Anaconda Prompt中使用命令提示符(个人觉得这种方式更好用些)
- 在Pycharm中使用.py脚本的形式训练
本文介绍使用Anaconda Prompt命令行进行训练。(注意训练前一定先激活虚拟环境),后面有空再写使用Pycharm训练的流程。
1. YOLO训练
首先先激活虚拟环境。YOLOv8训练后的结果会保存在“path\runs\detect\trainX”形式的文件夹下(这里path是基路径)。
我建议新建一个result文件夹,把监测结果都放在该文件夹下。这里我在桌面新建一个result文件夹,然后使用“cd”命令进入到该文件夹中(这样该文件夹就成为基路径path,后续相对路径的基路径都是该文件夹)

通过命令直接进行训练,在其中指定参数,命令如下:
yolo task=detect mode=train model=yolov8n.pt data=mydata.yaml batch=1 epochs=50 imgsz=640 workers=0 device=0
具体参数可参考官网中的详细说明
https://docs.ultralytics.com/zh/modes/train/#resuming-interrupted-trainings
下面只就其关键的参数做简要说明:
- task: YOLO模型的任务选择,选择你是要进行检测、分类等操作;可选[‘detect’, ‘segment’, ‘classify’, ‘init’]
- mode: YOLO模式的选择,选择要进行训练、推理、输出、验证等操作;可选[‘train’, ‘val’, ‘predict’]
- model:传入的model.yaml文件或者model.pt文件,用于构建网络和初始化,不同点在于只传入yaml文件的话参数会随机初始化,传入.pt会下载预训练权重并加载。默认None;可选[yolov8s.yaml、yolov8m.yaml、yolov8l.yaml、yolov8x.yaml]
- data: 训练数据集的配置yaml文件,默认None;
- batch: 训练批大小,默认16;
- epochs:训练轮次,默认100
- imgsz: 训练图片大小,默认640;
- device: 指定用于训练的计算设备:单个GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu) 或MPS for Apple silicon (device=mps).
- workers: 载入数据的线程数。
注意:
- 使用model=yolov8n.pt时,程序会检索路径中是否有yolov8n.pt,若没有则会自动下载(下载速度贼慢)。这里我提前下载好yolov8n.pt,放到result文件下了,这样程序就不用下载了。
- batch不要太大,否则显存会爆满无法训练;
- windows用户要把workers=0,我原来没设置就导致很多报错。
- 命令中model=yolov8n.pt(也可以放yolov8n.pt的绝对路径) data=mydata.yaml(也可以放mydata.yaml的绝对路径)
训练过程首先会显示你所用的训练的硬件设备信息,接着是你的参数配置模型结构信息,并告知你训练的结果会保存在runs\detect\trainXX中(这里是相对路径,若初始没有会新建)

1.1 训练结果
经过50轮训练,训练结果保存在result\runs\detect\train中。weights文件下是训练权重last.pt和best.pt。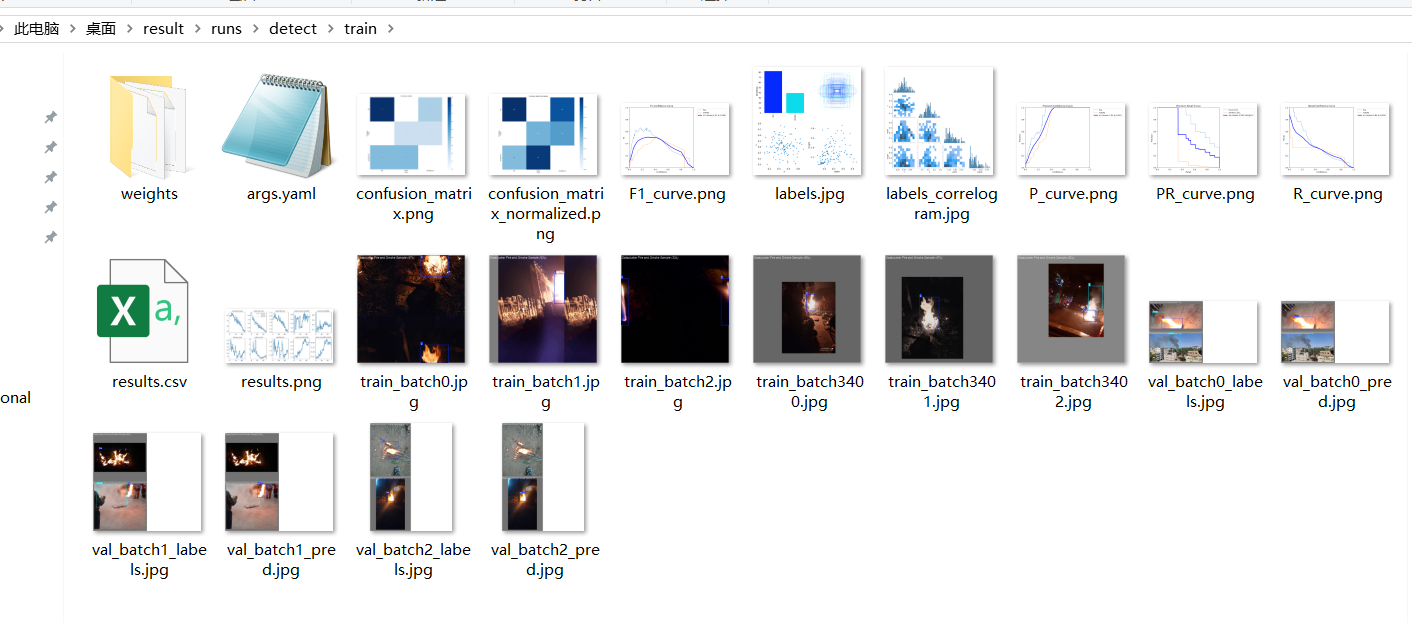

2. YOLO测试
训练好模型之后,会生成一个模型文件,保存在所设置的目录下,之后就可以调用该模型进行推理了,我们也可以用官方的预训练权重来进行推理。将训练得到的best.pt复制到result文件夹下,这样就可以不用输入绝对路径了。
推理的方式和训练一样,输入以下命令
yolo task=detect mode=predict model=best.pt source=C:\Users\huangda\Desktop\mydata\images\val device=0
注意
- model=best.pt,这里也可以用best.pt的绝对路径;
- source:可以是文件夹或具体的图片;(这里我用的是文件夹的绝对路径)

检测的结果保存在result\runs\detect\predict中,下面是一张检测结果,效果还算可以,如果训练次数再多一点效果估计会更好。

3. YOLO模型输出
当我们进行部署的时候可以进行文件导出,然后在进行部署。YOLOv8支持的输出格式有如下
- ONNX(Open Neural Network Exchange):ONNX是一个开放的深度学习模型表示和转换的标准。它允许在不同的深度学习框架之间共享模型,并支持跨平台部署。导出为 ONNX 格式的模型可以在支持ONNX 的推理引擎中进行部署和推理。
- TensorFlow SavedModel:TensorFlow SavedModel 是 TensorFlow 框架的标准模型保存格式。它包含了模型的网络结构和参数,可以方便地在 TensorFlow 的推理环境中加载和使用。
- PyTorch JIT(Just-In-Time):PyTorch JIT 是 PyTorch 的即时编译器,可以将 PyTorch 模型导出为优化的 Torch 脚本或 Torch 脚本模型。这种格式可以在没有 PyTorch 环境的情况下进行推理,并且具有更高的性能。
- Caffe Model:Caffe 是一个流行的深度学习框架,它使用自己的模型表示格式。导出为 Caffe 模型的文件可以在 Caffe 框架中进行部署和推理。
- TFLite(TensorFlow Lite):TFLite 是 TensorFlow 的移动和嵌入式设备推理框架,支持在资源受限的设备上进行高效推理。模型可以导出为 TFLite 格式,以便在移动设备或嵌入式系统中进行部署。
- Core ML(Core Machine Learning):Core ML 是苹果的机器学习框架,用于在 iOS 和 macOS 上进行推理。模型可以导出为 Core ML 格式,以便在苹果设备上进行部署。
这里导出为onnx格式,命令行命令如下:
yolo task=detect mode=export model=best.pt format=onnx
这里说没有onnx、onnxslim、onnxruntime库,且要求onnx>=1.12.0。
直接在虚拟环境中安装所需的库就行
pip install onnx==1.13.0
pip install onnxslim
pip install onnxruntime
安装好后在执行导出命令就可以了,导出过程如下
结果保存在result文件夹下,名称为“best.onnx”。
四、可能出现的问题总结
最好按照上述的部署步骤。如果和上面配置的环境不一样(如库的版本,cuda版本,虚拟环境是否激活,版本问题很重要所以上面一些重要的库都附上了我下载的版本),可能出现的问题及解决方案:
1. 'yolo‘ 不是内部或外部命令,也不是可运行的程序
在进行训练和预测时的命令中,这里的yolo其实是安装ultralytics库时安装的yolo.exe程序。如果pip install ultralytics未在对应的虚拟环境下就会出现以上问题。解决方法就是把在对应的虚拟环境下安装ultralytics库,或者把yolo.exe复制到对应的虚拟环境中。
yolo task=detect mode=train model=yolov8n.pt data=mydata.yaml batch=1 epochs=50 imgsz=640 workers=0 device=0
正常在虚拟环境中安装后位置在…\Scripts中
2. 使用GPU训练yolo损失值为nan的现象
我的显卡是GTX1650,最初安装cuda11.3训练时损失值全是nan。
原因:这是因为16系显卡与cuda 11.3版本的不兼容导致的,不知道11.x别的版本会不会出现这样的问题
解决方法:
卸载原先的cuda,安装低版本的,我是安装cuda10.2 后就没再出现这个问题
3. OSError: [WinError 1455] 页面文件太小,无法完成操作
解决方法:减少batch或者图片尺寸imgsz
4. 解决导入torchvision出错的问题
原因:(1) torchvision与torch不匹配(从https://pytorch.org/get-started/previous-versions/上查对应版本就行了)
(2) torchvision与cuda版本不匹配,torchvision版本应不超过cuda版本(10.2),否则会导入错误
UserWarning: Failed to load image Python extension: warn(f“Failed to load image Python extension:-CSDN博客
实际中运行时可能还会出现其他奇奇怪怪的问题,出现问题就去解决,一般网上都有相应的解决方案。这样也能锻炼解决问题的能力。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 52
52 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)