Stable Diffusion:文生图、图生图与ControlNet插件在Webui中的简单介绍
你有没有想过用 Stable Diffusion 这个强大的 AI 图像生成器来创作你想要的图像?比如,你可以用文生图模式来根据文字生成图像,用图生图模式来对图像进行变换,用 ControlNet 插件来控制生成过程。
你有没有想过用 Stable Diffusion 这个强大的 AI 图像生成器来创作你想要的图像?比如,你可以用文生图模式来根据文字生成图像,用图生图模式来对图像进行变换,用 ControlNet 插件来控制生成过程。
今天我就来简单介绍一下 Stable Diffusion Webui 的基本界面与基础功能,主要包括文生图、图生图与ControlNet 插件的部分。
更多stable diffusion模型插件可以扫描下方,免费获取

01 文生图(Text to Image)
文生图(Text to Image)的主要功能是通过你输入的一段文本描述(英文)来生成与文本相关的图像。其核心部分是Prompt和Negative prompt,Prompt用来描述你想要生成的东西,Negative prompt用来描述你不想在图像中出现的东西。主要界面如下:
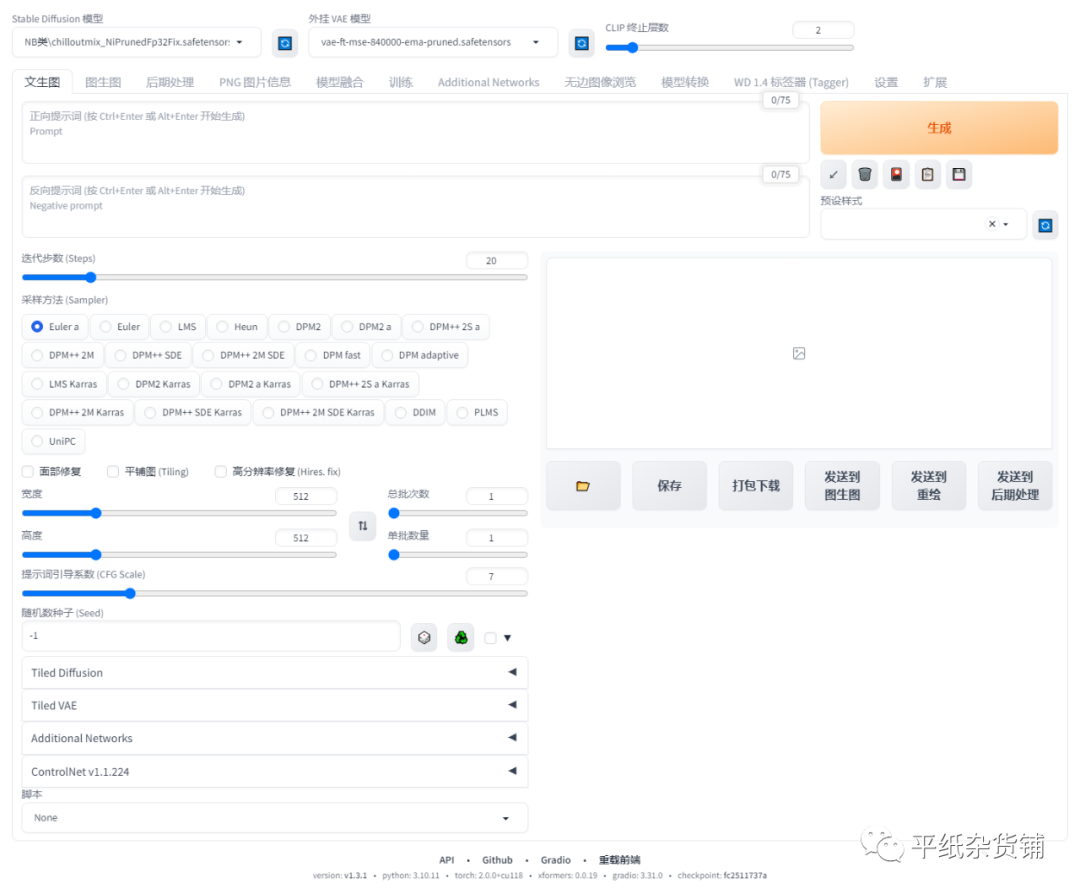
使用方法:
- 在左上角的prompt文本框中输入你想要生成的图像的描述,比如“a photo of building”,一栋建筑的照片。
- 在右上角选择你想要使用的模型,比如“realistic-archi-sd15_v3”。
- 在下方调整你想要使用的参数,比如“分辨率(由于SD模型训练时是通过512*512大小的图片训练的,所以通常分辨率建议设置为64的倍数)”、“批量大小”、“种子”等。
- 点击“提交”按钮,等待图像生成完成。
- 在左下角查看生成的图像,可以点击“保存”按钮将其保存到本地。
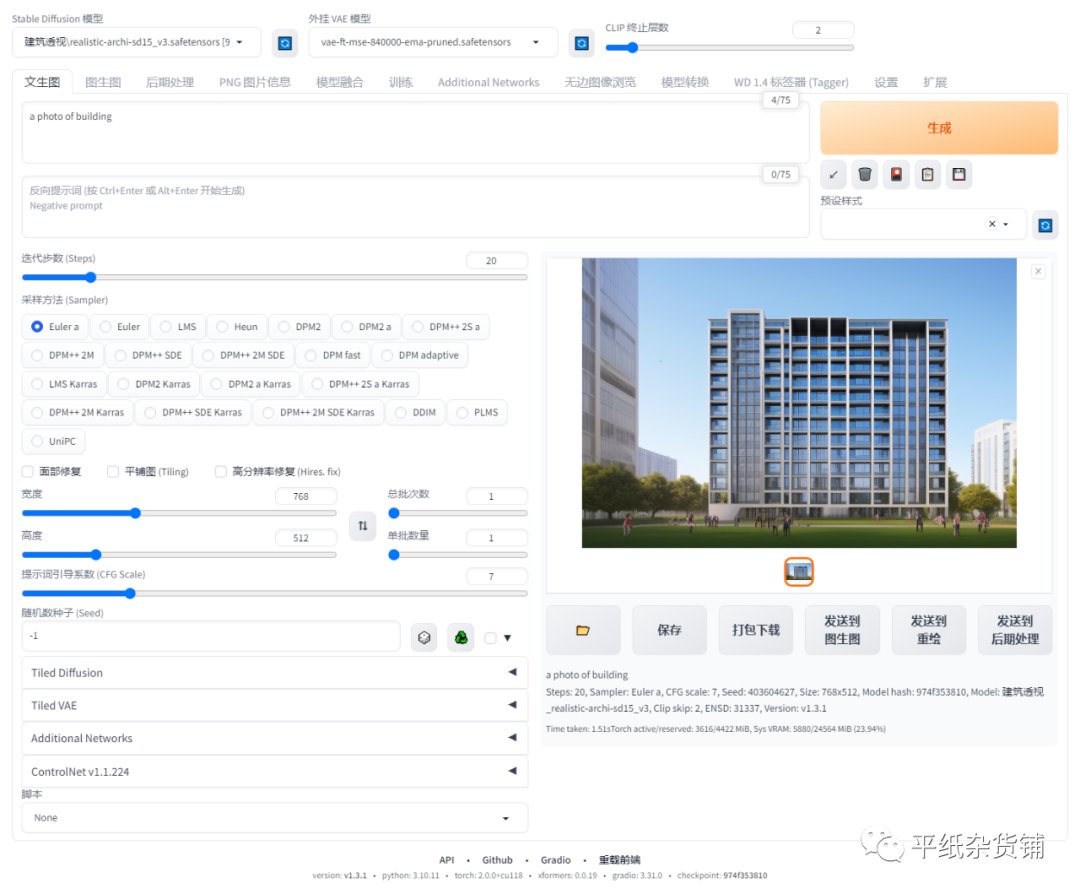
注意事项:
- 如果使用了循环或X/Y/Z绘图插件,生成时间会相应增加。
- 如果使用了X/Y/Z绘图插件,生成结果会以网格形式展示,每个单元格代表一个不同参数组合下的结果。

但X/Y/Z矩阵多用于测试模型集、LoRA模型或者是特定参数的设定,这样可以一次性生成不同权重与模型的矩阵图,便于测试生成效果。
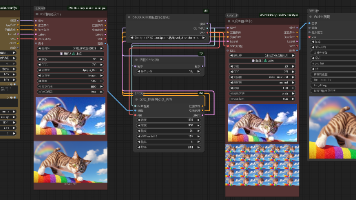
02 图生图(Image to Image)
图生图(Image to Image)板块可以让你输入一张图像,然后对其进行处理或转换。其基本界面如下,包含了两个比较明显的反推功能,一个是CLIP反推,一个是DeepBooru反推。
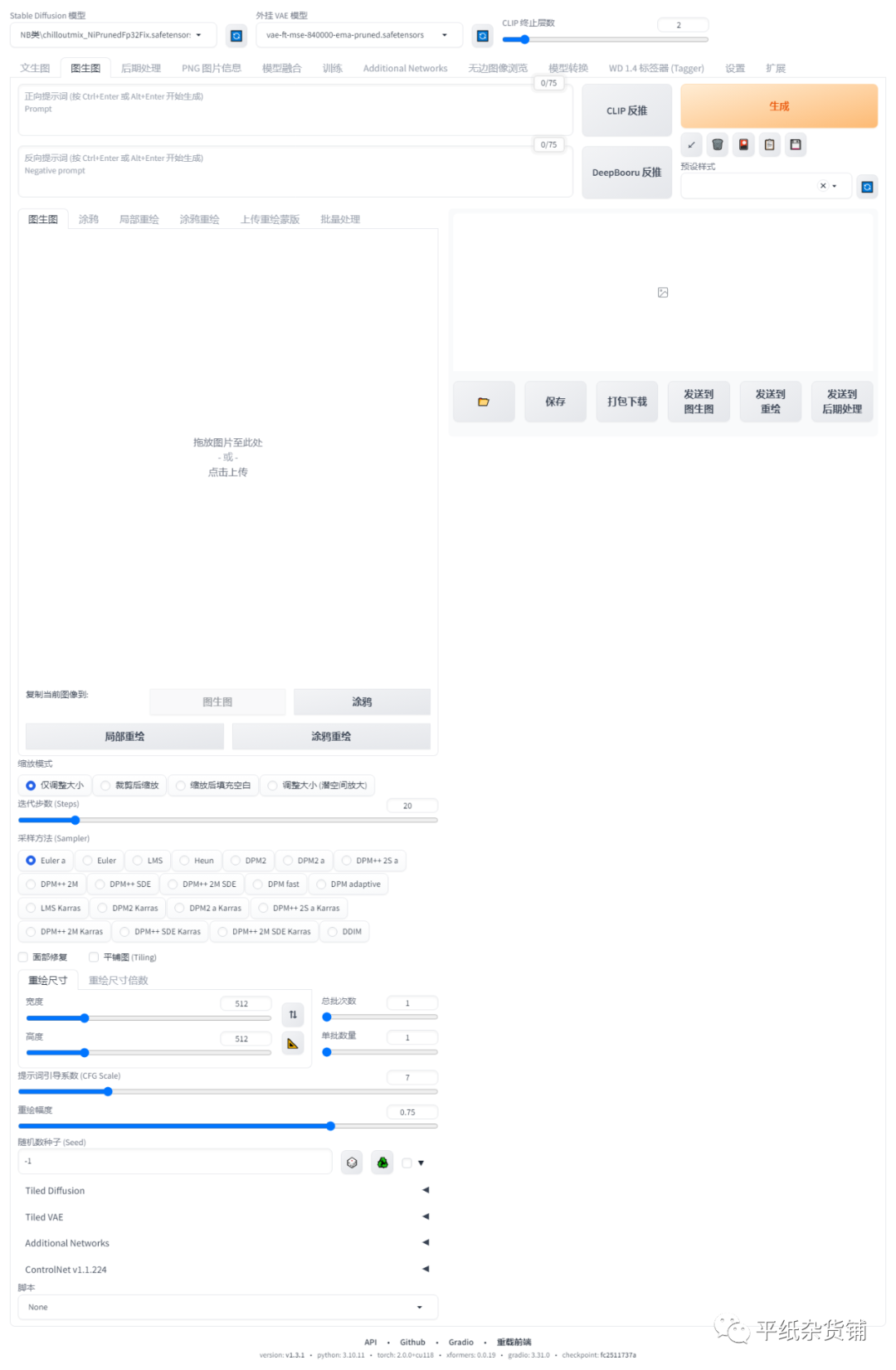
两个都能从图片生成提示词,但两者的区别是什么呢?
- CLIP反推
CLIP反推是指使用CLIP模型来从图像中提取自然语言描述,也就是用一个句子来概括图像的内容。而CLIP模型是一个多模态的神经网络,它可以同时理解图像和文本,并在大规模的自然语言数据集上进行预训练。
优点是可以生成更通顺完整的句子并捕捉图像中对象的关系,如:
a girl standing in a field looking at a large object in the sky with a bird flying over it
缺点是可能会生成一些不准确或不相关的描述,比如把外星飞船识别成了bird,而且需要加载Google的图像语义识别服务,可能会有一些延迟或限制。
- DeepBooru反推
DeepBooru反推是指使用DeepBooru模型来从图像中提取标签信息,也就是用一个一个的单词来描述图像中的物体和特征。DeepBooru模型是一个基于深度学习的图像标注系统,可在训练数据集上学习不同类型和风格的图像标签。
优点是可以生成更精确和丰富的标签,比如:
1girl, aircraft, airship, architecture, bird, bridge, building, castle, city, clock, clock_tower, cloud, cloudy_sky, day, desert, dress, facing_away, from_behind, horizon, long_hair, moon, ocean, outdoors, scenery, short_sleeves, sky, solo, sun, tower, water, watercraft, white_dress
缺点是可能会生成一些冗余或重复的标签,比如“aircraft”和“airship”。而且DeepBooru反推需要安装本地插件,可能会有一些兼容性或稳定性的问题。
简单来说,如果在图生图中插入一张千里江山图的照片,分别用两个反推来推理图片的提示词,那你得到的结果是:

CLIP反推得到的是:
a painting of a mountain range with blue rocks and trees in the foreground and a river running through it, Emperor Huizong of Song, detailed painting, a silk screen, cloisonnism一幅山脉的画,前景是蓝色的岩石和树木,一条河流穿过它,宋徽宗皇帝,详细的绘画,丝网印刷,景泰蓝
DeepBooru反推得到的是:
traditional_media, painting_\(medium\), blue_flower, no_humans, outdoors, rock, grass, watercolor_\(medium\), blue_rose传统_媒体,绘画_ \(中\),blue_flower,没有人,户外,岩石,草,水彩_ \(中\),蓝玫瑰
总结来说,CLIP反推和DeepBooru反推都是一种从图像中提取文字信息的方法,但它们有不同的侧重点和适用场景:CLIP反推更适合生成自然语言描述,而DeepBooru反推更适合生成标签信息。CLIP反推更依赖于网络服务,而DeepBooru反推更依赖于本地插件。
03 ControlNet插件
ControlNet插件(ControlNet Plugin)可以通过内置的多种预处理器模型对生成的图像进行更强的控制,毕竟没有控制的AI绘图只是盲目地抽卡而已,对规划设计来说,设计还是需要建立在各种各样的限制条件之下才有意义。
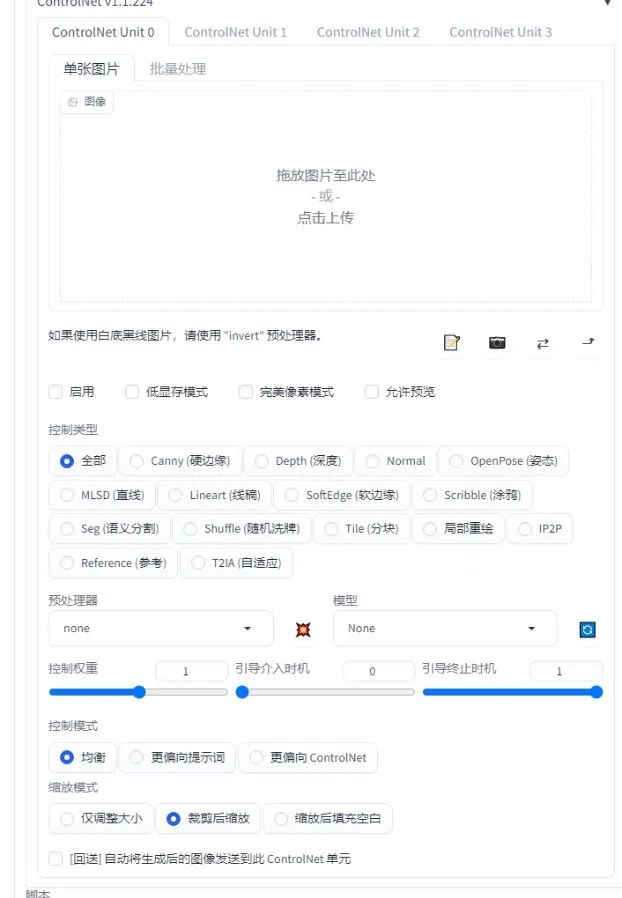
下面根据公开的教程整理了一些基于ControlNet插件的常用功能:
| 功能 | 方法 | 应用模型 |
|---|---|---|
| 线稿上色 | 通过 ControlNet 边缘检测模型或线稿模型提取线稿(可提取参考图片线稿,或者手绘线稿),再根据提示词和风格模型对图像进行着色和风格化。 | Canny/ SoftEdge/Lineart |
| 涂鸦成图 | 通过 ControlNet 的 Scribble 模型提取涂鸦图(可提取参考图涂鸦,或者手绘涂鸦图),再根据提示词和风格模型对图像进行着色和风格化。 | Scribble |
| 建筑/室内设计 | 通过 ControlNet 的 Lineart/MLSD 模型提取建筑的线条结构和几何形状,构建出建筑线框(可提取参考图线条,或者手绘线条),再配合提示词和建筑/室内设计风格模型来生成图像。 | Lineart/ MLSD |
| 材质控制 | 通过 ControlNet 的 Segmentation 语义分割模型,标注画面中的不同区块颜色和结构(不同颜色代表不同类型对象),从而控制画面的构图和内容。 | Seg |
| 背景替换 | 在img2img 图生图模式中,通过ControlNet的Depth_leres 模型中的 remove background 功能移除背景,再通过提示词更换想要的背景。 | Depth,预处理器 Depth_leres |
| 图片指令 | 通过 ControlNet 的 Pix2Pix 模型(ip2p),可以对图片进行指令式变换,如“Make it snow/fire/rainning”等。 | ip2p,预处理器选择 none |
| 风格迁移 | 通过 ControlNet 的 Shuffle 模型提取出参考图的风格,再配合提示词将风格迁移到生成图上。 | Shuffle |
| 人物三视图 | 通过 ControlNet 的 Openpose 模型精准识别出人物姿态,再配合提示词和风格模型生成同样姿态的图片。 在 ControlNet1.1 版本中,提供了多种姿态检测方式,包含:openpose 身体、openpose_face 身体+脸、openpose_faceonly 只有脸、openpose_full 身体+手+脸、openpose_hand 手,可以根据实际需要灵活应用。 | OpenPose |
| 图片光源控制 | 如果想对生成的图片进行打光,可以在 img2img 模式下,把光源图片上传到图生图区域,ControlNet 中放置需要打光的原图,ControlNet 模型选择 Depth。 | Depth |
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)
👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)