详解使用PyTorch搭建卷积网络对一维数据集识别(全流程)
最近在做一维信号的识别,网上大多数案例是针对图像的二维信号识别。虽然一维二维本质上没什么区别,但在处理方式上还是略有不同,因此在此做一个简单记录,方便更好地熟悉模式识别的流程。本文旨在使用PyTorch框架结合一维卷积神经网络(1D CNN)对一维信号进行分类。内容包括数据形式,数据加载、数据集构建、模型训练和模型测试、混淆矩阵可视化、模型导出、模型参数可视化、onnx推理等步骤。上述所有代码中变
文章目录
- 前言
- 一、环境配置
- 二、模型训练和测试
-
- 1.导入库
- 2.读入数据
-
- 2.1 数据形式
- 2.2 Dataset、DataLoader加载数据集
- 3 配置CPU或GPU
- 4 网络搭建
-
- 4.1 网络搭建
- 4.2 网络结构可视化
- 5 网络训练和测试
- 三、网络保存、推理
-
- 1 模型保存
- 2 混淆矩阵
- 3 网络训练权重可视化
- 4 导出为onnx
- 5 onnxruntime 推理
- 总结
前言
最近在做一维信号的识别,网上大多数案例是针对图像的二维信号识别。虽然一维二维本质上没什么区别,但在处理方式上还是略有不同,因此在此做一个简单记录,方便更好地熟悉模式识别的流程。
本文旨在使用PyTorch框架结合一维卷积神经网络(1D CNN)对一维信号进行分类。内容包括数据形式,数据加载、数据集构建、模型训练和模型测试、混淆矩阵可视化、模型导出、模型参数可视化、onnx推理等步骤。
一、环境配置
以下代码所用框架是基于torch 1.10.0+cu113,电脑安装的cuda版本是10.2,python为3.10。虽然cuda版本(10.2)低于torch所需的cuda要求(11.3),但可正常使用GPU加速。规律可能是:如果A调用B,那么B的版本最好不超过A。
所用工具是jupyter notebook。本人习惯调试时在jupyter notebook,这样方便随时输出变量的内容、尺寸等信息。
二、模型训练和测试
1.导入库
导入必要的库,主要是
# 使用GPU进行训练:
import torch
import numpy as np
from torch import nn
from torch.utils.data import DataLoader,Dataset,random_split
from scipy.io import loadmat
import torch.nn.functional as F
import matplotlib.pyplot as plt
import time
2.读入数据
2.1 数据形式
数据集是先用matlab处理后保存成.mat的形式,并且将6类信号提前分成X_train,X_test,Y_train,Y_test四个mat文件(X中是样本数据,Y是样本标签)。(数据如果是excel、csv、txt格式可使用对应的方式导入)
- 训练集有11445个样本,每个样本长度为5000,X_train尺寸为(11445,5000),Y_train尺寸为(11445,1);
- 测试集有2864个样本,每个样本长度为5000,X_test尺寸为(2864,5000),Y_test尺寸为(2864,1)。
由于网络需要标签形式是一维数据,因此将Y.flatten()方法将削减一个维度。
## load data
'''
pytorch网络要求输入格式:
一维信号:
原始数据格式:(11445,5000),表示11445组样本,每个样本5000个采样点(二维形式)
标签:(11445,)(一维形式)
输入到网络的格式:使用DataLoader将数据加载为以下格式
数据(batch, 1, 5000):1表示通道数,5000为信号长度
标签(batch,)
'''
X_train=loadmat('./X_train.mat')
X_test=loadmat('./X_test.mat')
Y_train=loadmat('./Y_train.mat')
Y_test=loadmat('./Y_test.mat')
X_train=X_train['X_train'] ## X_train:(11445,5000)
X_test=X_test['X_test'] ## X_test:(2864,5000)
Y_train=Y_train['Y_train'].flatten() ## Y_train:(11445,1),after flatten: (11445,)
Y_test=Y_test['Y_test'].flatten()
#########################################################################
## 将信号类型和标签值对应
cls=['Beat','Cement','dahang','Dig','Excavator','Noise']
cls_to_idx=dict((j,i) for i,j in enumerate(cls))
cls_to_idx
数据标签与信号类型对应:
{'Beat': 0, 'Cement': 1, 'dahang': 2, 'Dig': 3, 'Excavator': 4, 'Noise': 5}
输入样本按需进行归一化处理,将其归一化到(-1,1之间):
- 问题1:为什么进行归一化
使用归一化只要是为了防止梯度爆炸,让模型更快更好的收敛,即加速训练 - 问题二:归一化到(0,1)还是(-1,1)
建议(-1, 1)因为大部分网络是偏好零对称输入的。如果样本数据中全是非零值,也可以选择(0,1)
# 归一化
from sklearn.preprocessing import MinMaxScaler
min_max_scaler =MinMaxScaler(feature_range=(-1,1))
X_train=min_max_scaler.fit_transform(X_train.T)
X_test=min_max_scaler.fit_transform(X_test.T)
X_train=X_train.T
X_test=X_test.T
归一化后按照上面所说的将数据集整理成网络需要的形式,将X_train的维度从(11445,5000)整理成(11445,1,5000),X_test同理。这一步是为了匹配卷积层的输入形式,因此添加一个通道维度(如果你的网络第一层不是卷积层,则不需要做这一步)。
X_train=X_train.reshape(X_train.shape[0],1,X_train.shape[1]) ## X_train:(11445,1,5000)
X_test=X_test.reshape(X_test.shape[0],1,X_test.shape[1])
print(X_train.shape)
2.2 Dataset、DataLoader加载数据集
数据加载主要用到 torch.utils.data下的Dataset,DataLoader,random_split。
torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写__len__(self)、getitem(self, idx):方法。然后使用DataLoader将数据按批次打包。
注意:
加载数据要将数据类型转成float32,标签形式为int64(long)
# 自定义数据集类
class MyDataset(Dataset):
def __init__(self, X_data, Y_data):
"""
初始化数据集,X_data 和 Y_data 是两个列表或数组
X_data: 输入特征
Y_data: 目标标签
"""
self.X_data = torch.from_numpy(X_data).float()
self.Y_data = torch.from_numpy(Y_data).long()
print( self.X_data.shape )
print( self.Y_data.shape )
print( self.X_data.dtype )
print( self.Y_data.dtype )
def __len__(self):
"""返回数据集的大小"""
return len(self.X_data)
def __getitem__(self, idx):
"""返回指定索引的数据"""
x = self.X_data[idx] # 转换为 Tensor
y = self.Y_data[idx]
return x, y
# load train data
dataset_train = MyDataset(X_train, Y_train)
dataloader_train=DataLoader(dataset_train,batch_size=16,shuffle=True)
#load test data
data_test=MyDataset(X_test, Y_test)
dataloader_test=DataLoader(data_test,batch_size=16)
3 配置CPU或GPU
这一步只要放在网络训练前就可以。使用GPU训练要将网络、数据、损失函数放到cuda上,有两种方法:这里以model为例:
model=model.to("cuda"); ##model=model("cpu")
model=model.cuda() ##model=model.cpu()
在后面的代码可以注意一下网络、数据、损失函数都是在哪些步骤放到cuda上的。
# 使用GPU进行训练:
'''
网络模型
数据
损失函数
三者调用cuda()
# cpu or gpu
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
## Using cuda device
4 网络搭建
4.1 网络搭建
这里搭建一个具有两层卷积、一层池化、两个全连接层的模型,并且定义好损失函数、优化器。一般多分类(超过2种)选择损失函数为nn.CrossEntropyLoss(),优化器中Adam或SDG都比较常用。
class MyModel(nn.Module):
def __init__(self,):
## 一般有训练参数的层在构造函数中定义,如BatchNorm1d。conv等,建议dropout也在构造函数中定义
## 前向传播一般有训练参数的层在构造函数中定义,如BatchNorm1d。conv等,建议dropout也在构造函数中定义
'''
PyTorch官方推荐:具有学习参数的(例如,conv2d, linear, batch_norm)采用nn.Xxx方式,
没有学习参数的(例如,maxpool, loss func, activation func)等根据个人选择使用nn.functional.xxx或者nn.Xxx方式。
但关于dropout,个人强烈推荐使用nn.Xxx方式,
'''
super(MyModel,self).__init__()
self.batchnorm1=nn.BatchNorm1d(1,affine=False) ## BatchNorm1d(num_features)这里num_features是通道数
self.block1=nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=4, kernel_size=3, stride=1,padding=1),
nn.ReLU(),
nn.Conv1d(in_channels=4, out_channels=8, kernel_size=5, stride=1,padding=2),
nn.ReLU(),
nn.MaxPool1d(2)
)
self.dropout=nn.Dropout(0.3)
self.linear1=nn.Linear(8*2500,64)
self.relu=nn.ReLU()
self.linear2=nn.Linear(64,6)
def forward(self,x):
x=self.batchnorm1(x)
x=self.block1(x)
x=x.view(-1,8*2500)
x=self.relu(self.linear1(x))
x=self.dropout(x)
x=self.linear2(x)
return x
## Loss and Optimizer
model=MyModel()
model=model.to(device) ## 这里将网络放到cuda上
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device) ## 这里将损失函数放到cuda上
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
这里需要掌握一些网络输入输出尺寸的知识,因为从卷积层到全连接层过度需要计算尺寸:
- 卷积层输出基本计算公式
W为输入大小,F 为卷积核大小,P 为填充大小(padding),S为步长(stride),N为输出大小。有如下计算公式: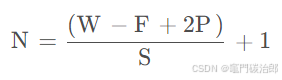
因此若要输入输出尺寸一样,即N=W,则需S=1,P=(F-1)/2,卷积核尺寸F一般都是奇数。 - 池化层输出尺寸
池化层一般默认步长和核大小一致,输出尺寸等于(输入值/步长)并向下取整。例如输入尺寸是1000,池化步长为3,则输出尺寸为【1000/3】=333(这里的【】是向下取整符号)。
4.2 网络结构可视化
torchinfo是一个用于PyTorch模型信息打印的Python包。它提供了一种简单而快速的方法来打印PyTorch模型的参数数量、计算图和内存使用情况等有用的信息,从而帮助深度学习开发人员更好地理解和优化他们的模型
安装,
pip install torchinfo
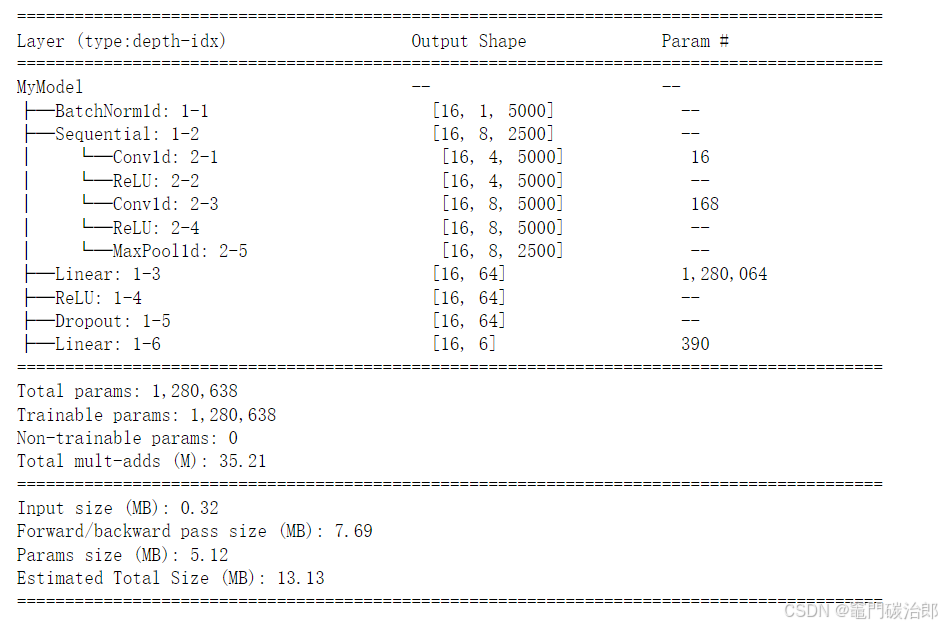
torchinfo最主要的是下面的summary函数,第一个参数输入网络模型,第二个参数可以输入表示输入尺寸的元组,例如(batch_size, channels, height, width)。
- model: 要分析的PyTorch模型,必须是torch.nn.Module的实例。
- input_data: 用于模型前向传播的输入数据。它可以是一个torch.Tensor对象,也可以是一个包含多个输入张量的元组。此外,还可以提供一个表示输入尺寸的元组,例如(batch_size, channels, height, width)。
from torchinfo import summary
summary(model,(16,1,5000))
5 网络训练和测试
数据和网络准备好后,就可以开始训练和测试了,建议训练和测试过程以函数的形式编写,这对于理解网络前向后向传播大有帮助。
以下代码是单次epoch下的训练和测试函数
注意训练时要将网络设成训练模式:model.train();测试时要将网络设成评估模式:model.eval()
两者区别在于
调用model.eval()的作用是将模型中的某些特定层或部分切换到评估模式。例如Dropout层和BatchNorm层等。这些层在训练和推断过程中的行为是不同的,因此在评估模式下需要将它们关闭。
## model train
def train(dataloader,model,loss_fn,optimizer):
num_batch=len(dataloader)
size=len(dataloader.dataset)
train_acc,train_loss=0,0
model.train()
for X,Y in dataloader:
X, Y = X.to(device), Y.to(device) ## 这里将数据放cuda上
pred=model(X)
loss=loss_fn(pred,Y)
## back
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc+=(pred.argmax(1)==Y).sum().item()
train_loss+=loss.item()
train_acc=train_acc/size
train_loss=train_loss/num_batch
return train_loss,train_acc
def test(dataloader,model):
model.eval()
num_batch=len(dataloader)
size=len(dataloader.dataset)
test_acc,test_loss=0,0
with torch.no_grad(): # 使用torch.no_grad()可以显著降低测试用例的GPU占用
for X,Y in dataloader:
X,Y=X.to(device), Y.to(device)
pred=model(X)
loss=loss_fn(pred,Y)
test_acc+=(pred.argmax(1)==Y).sum().item()
test_loss+=loss.item()
test_acc=test_acc/size
test_loss=test_loss/num_batch
return test_loss,test_acc
然后开始进行训练和测试了,这里把测试集当作网络训练过程的验证集使用,因为验证集和测试集都不参与反向传播过程。
train_loss = []
train_acc = []
test_loss = []
test_acc = []
epochs = 30
for epoch in range(epochs):
train_begin=time.time()
epoch_loss, epoch_acc = train(dataloader_train, model, loss_fn, optimizer)
train_end=time.time()
train_time=train_end-train_begin
test_begin=time.time()
epoch_test_loss, epoch_test_acc = test(dataloader_test, model)
test_end=time.time()
test_time=test_end-test_begin
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
print("epoch:{}, train_loss: {:.5f},train_acc: {:.2f}%,train_time: {:.2f},test_loss: {:.5f},test_acc: {:.2f}%,test_time: {:.2f}".format(
epoch+1,epoch_loss,epoch_acc*100,train_time,epoch_test_loss,epoch_test_acc*100,test_time))
print("Done!")
以下便是训练过程了,可以看出使用GPU训练还是很快的,单次epoch时间约3.5s,而用CPU则需要40s左右,可以看出速度差异还是很大的。
训练过程准确率和损失值曲线变化:
plt.figure(figsize=(3, 2))
plt.xlabel("epopch")
plt.ylabel("acc/%")
plt.plot([i+1 for i in range(epochs)],[i*100 for i in train_acc])
plt.plot([i+1 for i in range(epochs)],[i*100 for i in test_acc])
plt.figure(figsize=(3, 2))
plt.xlabel("epopch")
plt.ylabel("loss")
plt.plot([i+1 for i in range(epochs)],[i for i in train_loss])
plt.plot([i+1 for i in range(epochs)],[i for i in test_loss])
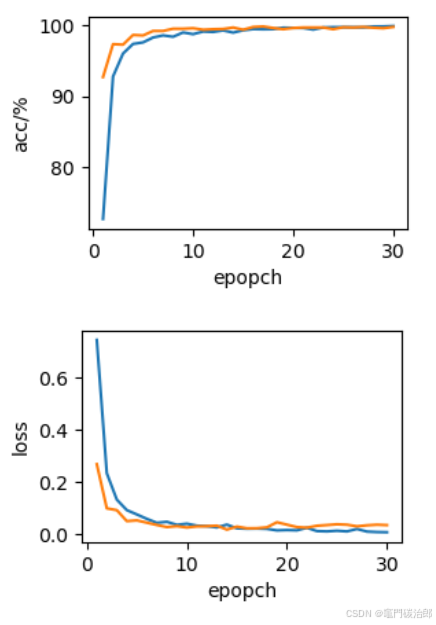
到这里模型的训练工作就完成了,下面就是模型保存、结果可视化、模型推理等操作了。
三、网络保存、推理
1 模型保存
模型的本质是一堆用某种结构存储起来的参数,所以在保存的时候有两种方式,
- 直接保存整个模型
直接将整个模型保存下来,之后直接加载整个模型,但这样会比较耗内存。
注意在加载时需要定义一下目标网络类,或者从其他模块把你原来定义的网络类导过来。
## save model
model=model.to('cpu')
torch.save(model,'model_original.pth')
## load model
model=torch.load('model_original.pth')
- 只保存权重参数
只保存模型的参数,之后用到的时候再创建一个同样结构的新模型,然后把所保存的参数导入新模型。
#保存
model=model.to('cpu')
torch.save(model.state_dict(), PATH)
#读取
the_model = TheModelClass(*args, **kwargs)
the_model.load_state_dict(torch.load(PATH))
上面命令中model=model.to(‘cpu’)是为了把模型转到cpu上,否则保存的网络或者网络参数都是cuda形式,加载后也是cuda形式。运行时若没有调用cuda可能会报错。
2 混淆矩阵
网络测试结果以往往以混淆矩阵的形式展示。这里将测试集输入到网络中识别,以下是代码:
## confusion_matrix
def confusion_matrix(preds, labels, conf_matrix):
preds = torch.argmax(preds, 1)
for p, t in zip(preds, labels):
conf_matrix[p, t] += 1
return conf_matrix
#首先定义一个 分类数*分类数 的空混淆矩阵
conf_matrix = torch.zeros(6, 6)
# 使用torch.no_grad()可以显著降低测试用例的GPU占用
with torch.no_grad():
model.eval()
for X,Y in dataloader_test:
# imgs: torch.Size([50, 3, 200, 200]) torch.FloatTensor
# targets: torch.Size([50, 1]), torch.LongTensor 多了一维,所以我们要把其去掉
# targets = targets.squeeze() # [50,1] -----> [50]
X,Y=X.to(device),Y.to(device)
# 将变量转为gpu
# print(step,imgs.shape,imgs.type(),targets.shape,targets.type())
out = model(X)
#记录混淆矩阵参数
conf_matrix = confusion_matrix(out, Y, conf_matrix)
conf_matrix=conf_matrix.cpu()
conf_matrix=np.array(conf_matrix.cpu())# 将混淆矩阵从gpu转到cpu再转到np
corrects=conf_matrix.diagonal(offset=0)#抽取对角线的每种分类的识别正确个数
per_kinds=conf_matrix.sum(axis=1)#抽取每个分类数据总的测试条数
print("混淆矩阵总元素个数:{0},测试集总个数:{1}".format(int(np.sum(conf_matrix)),len(data_test)))
print(conf_matrix)
# 获取每种Emotion的识别准确率
print("每种事件总个数:",per_kinds)
print("每种事件预测正确的个数:",corrects)
print("每种事件的识别准确率为:{0}".format([rate*100 for rate in corrects/per_kinds]))
输出如下: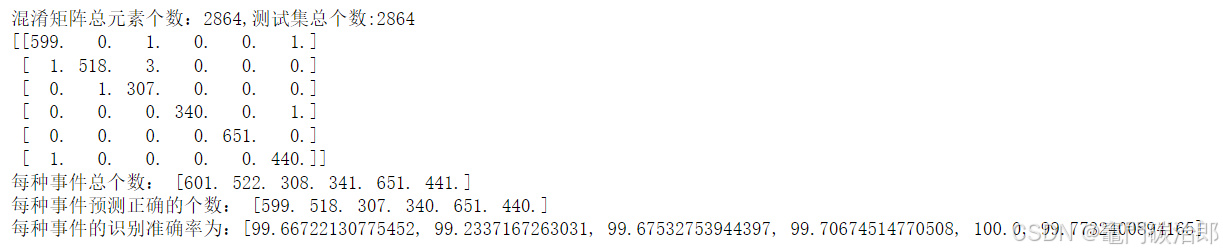
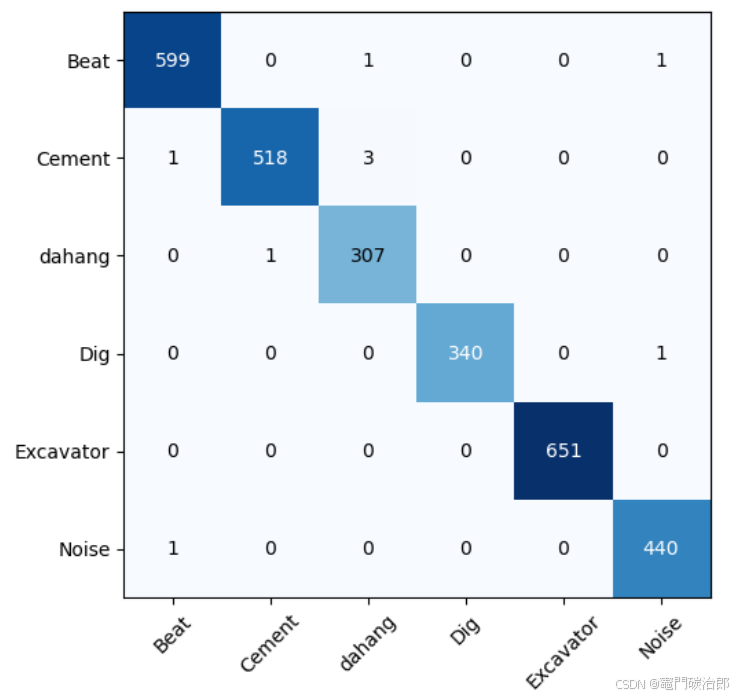
这样看若是觉得不高级,那么就转成比较常见的混淆矩阵图片形式:
# 绘制混淆矩阵
num_cls=len(cls)#这个数值是具体的分类数,大家可以自行修改
labels = ['Beat','Cement','dahang','Dig','Excavator','Noise'] #每种类别的标签
# 显示数据
plt.imshow(conf_matrix, cmap=plt.cm.Blues)
# 在图中标注数量/概率信息
thresh = conf_matrix.max() / 2 #数值颜色阈值,如果数值超过这个,就颜色加深。
for x in range(num_cls):
for y in range(num_cls):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(conf_matrix[y, x])
plt.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
plt.tight_layout()#保证图不重叠
plt.yticks(range(num_cls), labels)
plt.xticks(range(num_cls), labels,rotation=45)#X轴字体倾斜45°
plt.show()
plt.close()
3 网络训练权重可视化
上面所说网络训练好的权重保存在model.state_dict(),若按照网络前向传播的过程拆解成矩阵运算的形式做推理,则需要将权重导出后。以下是网络训练后各层的权重参数(无训练参数的层不包括在内,如池化、激活层等)
## 模型权重
for i in model.state_dict():
a=model.state_dict()[i].numpy()
print(i,'\t',a.shape,a)
输出各层权重参数如下,然后可将参数保存成txt、csv等形式,按照网络前向传播过程做推理。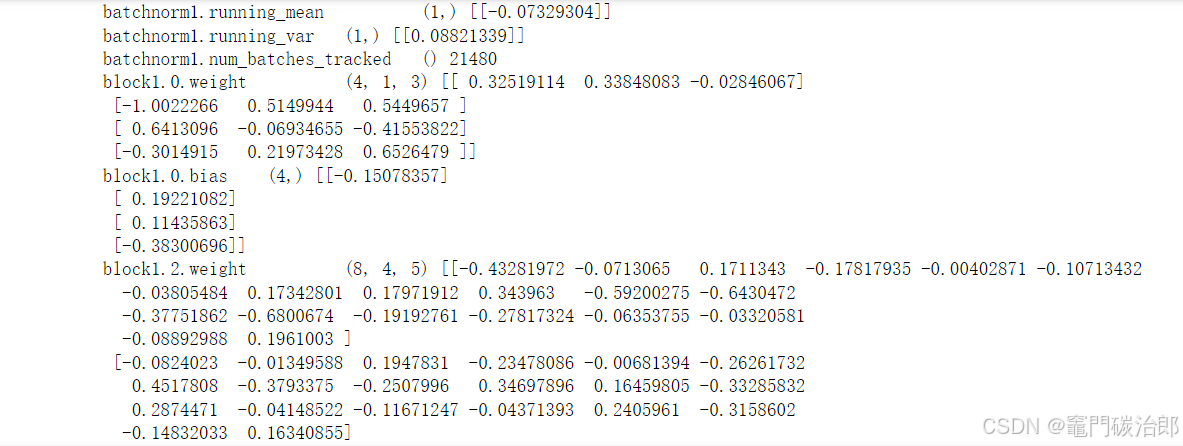
4 导出为onnx
ONNX (Open Neural Network Exchange) 是一个开放的深度学习模型文件格式,旨在促进不同深度学习框架之间的互操作性。它提供了一种标准的方式来表示机器学习模型,使得模型可以在多个框架之间进行共享和迁移。
把 PyTorch 模型转换成 ONNX 模型时,需要调用torch.onnx.export,该函数参数各说明可自行百度。该函数以追踪的形式构建整个网络。
所谓追踪,就是自定义一个尺寸和原网络输入数据样本一致的变量,其第0维为batch_size,可设为1,将其传入到函数参数中,然后便可追踪该变量在网络的轨迹从而构建整个网络。以下是参考代码,包含了函数关键参数,其余参数使用默认就可。
torch.onnx.export(model, args, path, export_params, verbose, input_names, output_names, do_constant_folding, dynamic_axes, opset_version)
batch_size = 1 #批处理大小
input_shape = (1,5000) #输入数据
# set the model to inference mode
x = torch.randn(batch_size,*input_shape) # 生成张量
export_onnx_file = "original.onnx" # 目的ONNX文件名
torch.onnx.export(model,
x,
export_onnx_file,
opset_version=14,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
dynamic_axes={"input":{0:"batch_size"}, # 批处理变量
"output":{0:"batch_size"}})
执行后在相同路径下生成一个名为"original.onnx"的文件,该文件可在 https://netron.app/打开,如下所示,包含网络结构,各层名称和权重参数等信息
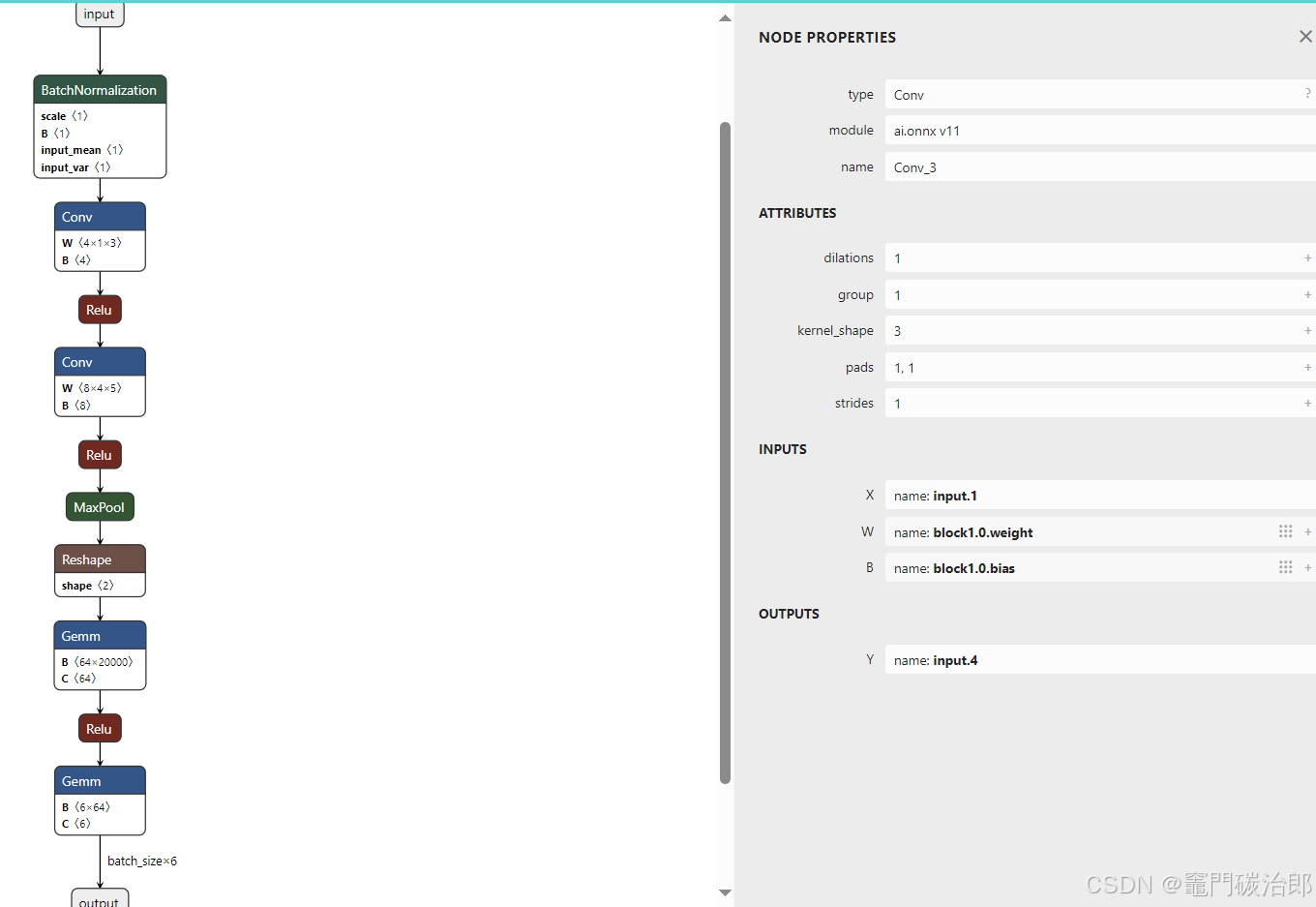
5 onnxruntime 推理
安装onnxruntime,onnxruntime有cpu和gpu版的,由于model保存的是cpu形式,这里安装的onnxruntime也是cpu版。版本就是1.14.0(版本别太低就行)
pip install onnxruntime==1.14
从测试集中随便选择一组数据,将数据类型转为float32,注意onnx模型的输入是array形式,不是tensor张量。
'''
这里测试onnx 和onnxruntime
'''
## 测试集中随便选择一组数据
idx=8000
data1=X_train[idx]
# data1=torch.from_numpy(data1).float()
data1=data1.astype(np.float32)
data1=data1.reshape(1,data1.shape[0],data1.shape[1]) ##数据维度第一维一定是batch_size,以对应onnx输入结构,即(batch_size,1,信号长度)
label=Y_train[idx]
#####################################################
## test onnx
import onnx
import onnxruntime as ort
# 加载ONNX模型
onnx_model = onnx.load("original.onnx")
onnx.checker.check_model(onnx_model) # 检查ONNX模型是否合法
print(onnx.helper.printable_graph(onnx_model.graph)) # 打印ONNX模型结构
## onnxruntime
ort_session = ort.InferenceSession("original.onnx")
inputs = {ort_session.get_inputs()[0].name: data1} ## onnx输入是array数组,数据类型float32
outs = ort_session.run(None,inputs)
for i in outs:
print("model predict: {},actually result:{}".format(i.argmax(axis=1),label))
输出:
目标类型为1,实际输出类型也是1,结果一致。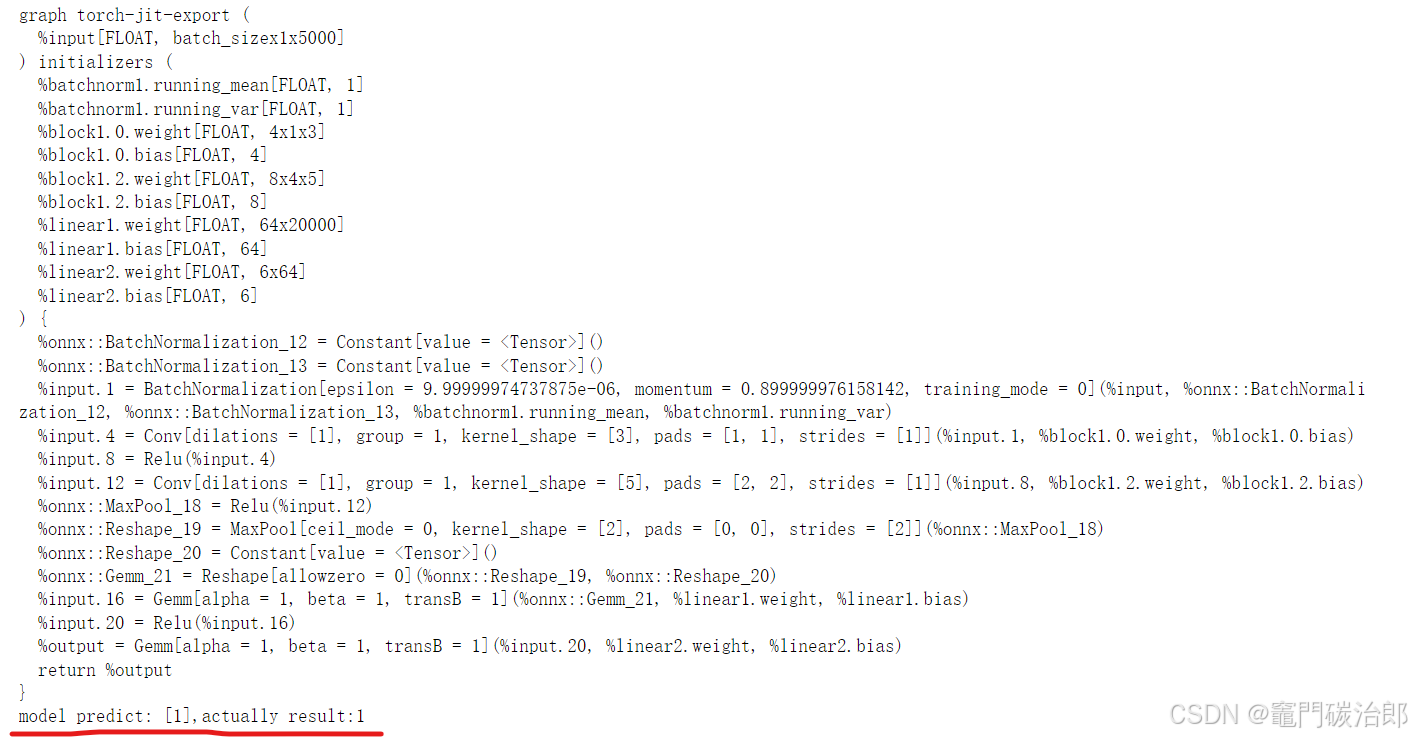
总结
- 上述所有代码中变量名称无重复的,我在jupyter中调试都是从上往下依次运行的,可以将代码块按照顺序依次运行调试;
- 本实例搭建了一个简单的网络,但也基本包含了网络搭建的全部流程 。不管简单还是复杂模型,不管是一维信号还是二维信号识别,此流程都可以作为参考;

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 65
65 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)