深度学习(二)-认识要从线性回归和逻辑回归说起
一、前言本章开始之前先来了解一下几个概念:预测值和真实值预测值为模型自动计算的结果(标签)真实值为数据本身的结果损失函数损失函数是用来权衡预测值和真实值之间的差异的,通过这个差异我们可以判断模型参数的好坏,指导模型如何做下一步优化。最简单的损失函数如均方差,通过预测值和真实值之间的差值来计算预测的差异性二、线性回归1、基础概念线性回归主要是基于一种假设:我们所要求解的目标变量y和特征变量x之间呈线
一、前言
本章开始之前先来了解一下几个概念:
- 预测值和真实值
- 预测值为模型自动计算的结果(标签)
- 真实值为数据本身的结果
- 损失函数
- 损失函数是用来权衡预测值和真实值之间的差异的,通过这个差异我们可以判断模型参数的好坏,指导模型如何做下一步优化。
- 最简单的损失函数如均方差,通过预测值和真实值之间的差值来计算预测的差异性
二、线性回归
1、基础概念
线性回归主要是基于一种假设:我们所要求解的目标变量y和特征变量x之间呈线性关系,也就是我们中学所学的:
y=kx+by=kx+by=kx+b
机器学习常用:
y=Wx+by=Wx+by=Wx+b
虽说没有公式就没有伤害,但公式还是要有的!
我们的目标是找到一个合适WWW和一个合适bbb,以确定y和x的之间的关系,这个过程我们称之为训练,根据这个关系我们可以在已知xxx的条件下计算出yyy,这个过程我们称之为预测。
然而在实际的问题中,特征变量x的往往不只一个,也就是影响目标变量y的因素存在多个(x1,x2,x3...xnx_1,x_2,x_3...x_nx1,x2,x3...xn),此时,一元的线性回归已经不能解决问题,就需要使用多元线性回归:
y=W1x1+W2x2+W3x3+...Wnxn+By=W_1x_1+W_2x_2+W_3x_3+...W_nx_n+By=W1x1+W2x2+W3x3+...Wnxn+B
在假设了xxx和yyy的关系符合线性特征以后,下一步就是求解合适的参数W1,W2...Wn,BW_1,W_2...W_n,BW1,W2...Wn,B,这里的合适如何衡量呢?
我们可以采用损失函数来衡量,预测的结果相对于真实结果损失(误差)严重,我们认为参数不合适,损失越小则认为参数越合适。
这里的损失函数可以采用均方误差:
loss=1n∑i=1n(y预测值−y真实值)loss= \frac{1}{n} \sum_{i=1}^n (y_{预测值} - y_{真实值})loss=n1i=1∑n(y预测值−y真实值)
这个容易理解,预测值减去真实值,即是误差值。
将y预测值y_{预测值}y预测值替换为线性回归函数之后即为:
loss=1n∑i=1n(W1x1+W2x2+W3x3+...Wnxn+B−y真实值)2loss= \frac{1}{n} \sum_{i=1}^n(W_1x_1+W_2x_2+W_3x_3+...W_nx_n+B-y_{真实值})^2loss=n1i=1∑n(W1x1+W2x2+W3x3+...Wnxn+B−y真实值)2
不要害怕这么长的公式,因为并不需要我们手动打草稿计算!我们需要知道的是理解这个过程,从而知道如何选择模型,如何调整模型的参数使得模型最优。
2、模型求解
在定义完模型以后,下一步就是进行模型的求解,那如何求解呢,可以按照正常人的思维来理解:
要使得模型最优,让尽可能多的x和y之间符合某种规律,就需要使得预测误差losslossloss的值最小!
如此,目标就得到进一步拆解:
- 求出loss最小时W1,W2,W3...Wn,BW_1,W_2,W_3...W_n,BW1,W2,W3...Wn,B的值(这里的最小不是很准确,因为很难求出,一般都是较小)
求解的过程中,我们引入一个新的算法:梯度下降法。
其核心是对自变量进行不断的更新迭代,使得目标函数losslossloss不断逼近最小值,具体过程让W1,W2,W3...Wn,BW_1,W_2,W_3...W_n,BW1,W2,W3...Wn,B沿着梯度最大的反方向更新,直到梯度较为平稳后停止。
更新的计算过程如下:
w=w−ηdww=w-\eta dww=w−ηdw
例如一条高山上的河流,要以最快的速度到达山底(求最小值),自然是通过最为陡峭(梯度最大)的坡度进行流淌。
下面举一个小栗子:
已知函数y=x2−2x+1y=x^2-2x+1y=x2−2x+1 求yyy最小时xxx的值
第一步:初始化x0=0x^0=0x0=0,η=0.1\eta=0.1η=0.1(随机初始化)
第二步:对函数求导y导数=dw=2x−2y^ {导数} =dw=2x-2y导数=dw=2x−2
迭代:
第1次:x1=x0−ηdx=0−0.1∗(2∗0−2)=0.2x^1=x^0-\eta dx=0-0.1*(2*0-2)=0.2x1=x0−ηdx=0−0.1∗(2∗0−2)=0.2
第2次:x2=x1−ηdx=0.36x^2=x^1-\eta dx=0.36x2=x1−ηdx=0.36
…
第22次:x22=x21−ηdx=0.999...x^{22}=x^{21}-\eta dx=0.999...x22=x21−ηdx=0.999...
第23次:x23=x22−ηdx=0.9999..x^{23}=x^{22}-\eta dx=0.9999..x23=x22−ηdx=0.9999..
从中可以发现,通过多次迭代xxx的值越来越趋近于1,而我们画出y=x2−2x+1y=x^2-2x+1y=x2−2x+1的函数图像来看,x=1x=1x=1时,yyy值最小。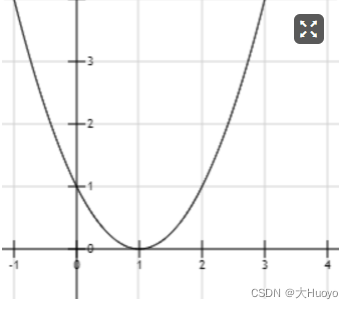
另外我们也可以通过令y导数=dw=2x−2=0y^ {导数} =dw=2x-2=0y导数=dw=2x−2=0的方式求解yyy最小时x=22=1x=\frac{2}{2}=1x=22=1,这种方式看起来更加简单快捷,为什么不使用这种方式,要整一个梯度下降法呢?
因为在现实的问题中,要求解的参数并非屈指可数,求解就变得异常困难,而梯度下降法虽然不那么精确,但至少能够在可承受的范围内给出一个相对满意的结果!
三、逻辑回归
1、基础概念
逻辑回归可以看做是线性回归的一种扩展,线性回归解决的是目标变量y和特征变量x之间的拟合问题,其输出是连续的,连续的值对于预测数值是极好的,但是对于分类问题却显得无能为力,比如要判断购物之后的评论是好评还是差评,这个时候科学家们想出了一个办法:
在已有线性的基础上加上一层可以进行逻辑判断的函数(通常叫做激活函数),再设定一个阈值,如果输出的连续值大于这个阈值,表示好评,小于阈值,表示差评,这样从理论上就完成了分类任务,也就是逻辑回归(事实上,很多分类算法都是基于此种模式)。
由于连续值yyy的范围太广,阈值的设置就成了一个新的问题,为了解决这个问题,常规的做法是讲yyy的范围进行压缩,映射都一个固定的空间内,比如0到1、-1到1等,如此,一些特定函数得以排上档期,如sigmoid: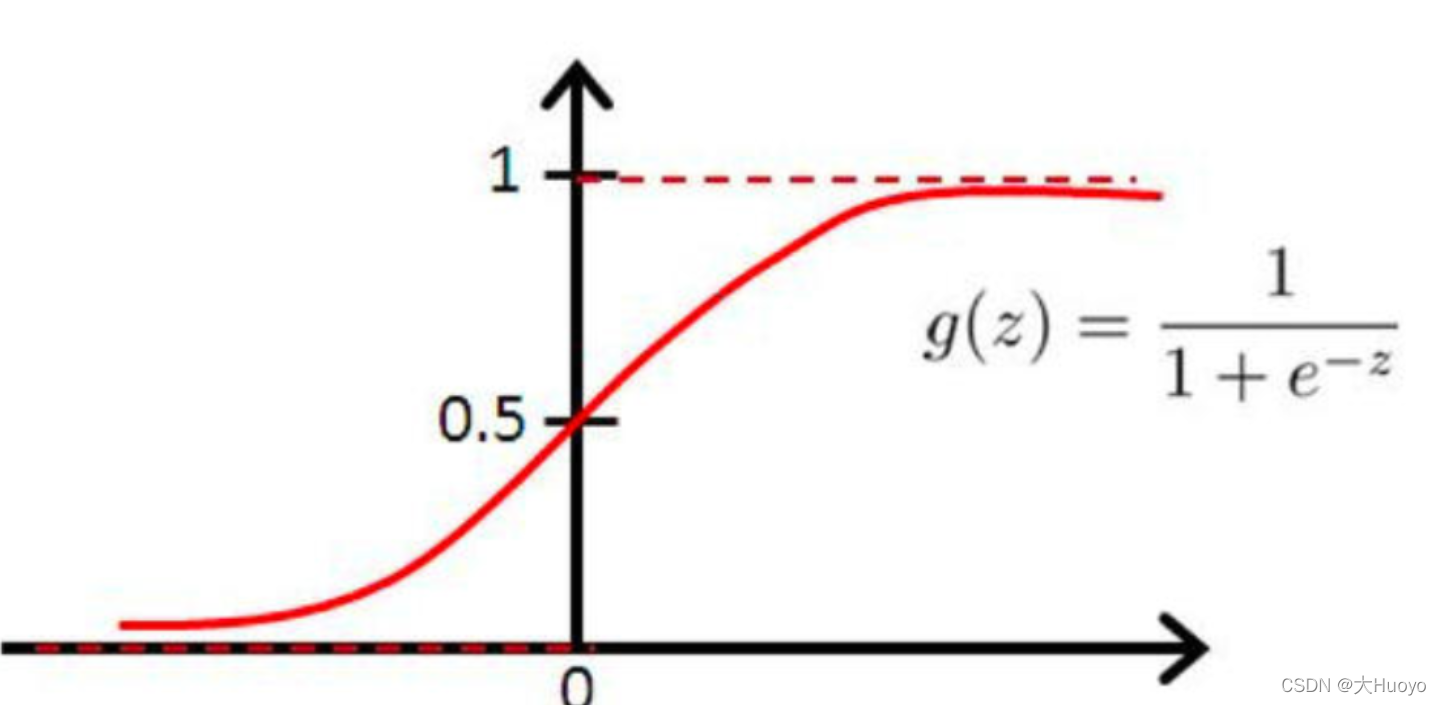
以0.5位阈值,大于0.5表示好评,小于0.5即可表示差评。
如tanh: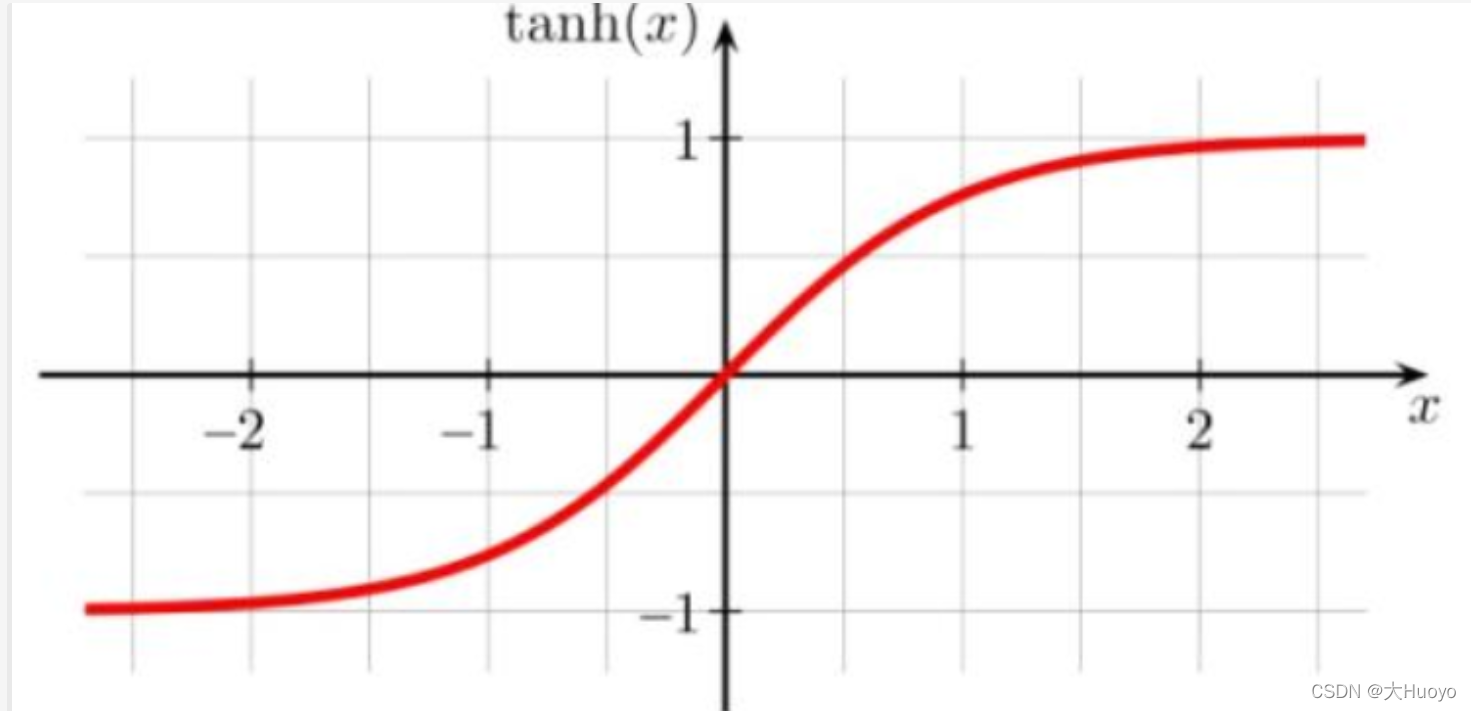
以0位阈值,大于0表示好评,小于0即可表示差评。
如此,以sigmoid为例,逻辑回归的损失函数为:
loss=1n∑i=1n(sigmoid(W1x1+W2x2+W3x3+...Wnxn+B)−y真实值)2loss=\frac{1}{n}\sum_{i=1}^n(sigmoid(W_1x_1+W_2x_2+W_3x_3+...W_nx_n+B)-y_{真实值})^2loss=n1i=1∑n(sigmoid(W1x1+W2x2+W3x3+...Wnxn+B)−y真实值)2
2、模型求解
模型的求解方式和线性回归一致,不做多余赘述。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)