前端,在项目中引入ai助手(deepseek,llama);dify使用
前段时间做了在项目中引入ai助手,可以实现直接通过对话指令实现三维渲染或操作,并且还能做一些基础聊天。现对完成过程做一个回忆。主要记录比较简单的调通过程,有未提及或不对的地方,望大家指出。也希望对你有所帮助。
摘要:前段时间做了在项目中引入ai助手,可以实现直接通过对话指令实现三维渲染或操作,并且还能做一些基础聊天。现对完成过程做一个回忆。主要记录比较简单的调通过程,有未提及或不对的地方,望大家指出。也希望对你有所帮助。
1.直接使用deepseek线上服务-付费
(这个主要是我一开始熟悉一下流程,付费的deepseek也可以在下文本地部署中使用,免费服务请直接看目录第二条dify的使用)
API文档地址:首次调用 API | DeepSeek API Docs
个人使用DeepSeek-V3,小充了几元做调试用(根本用不完😂)
官网价格如下:
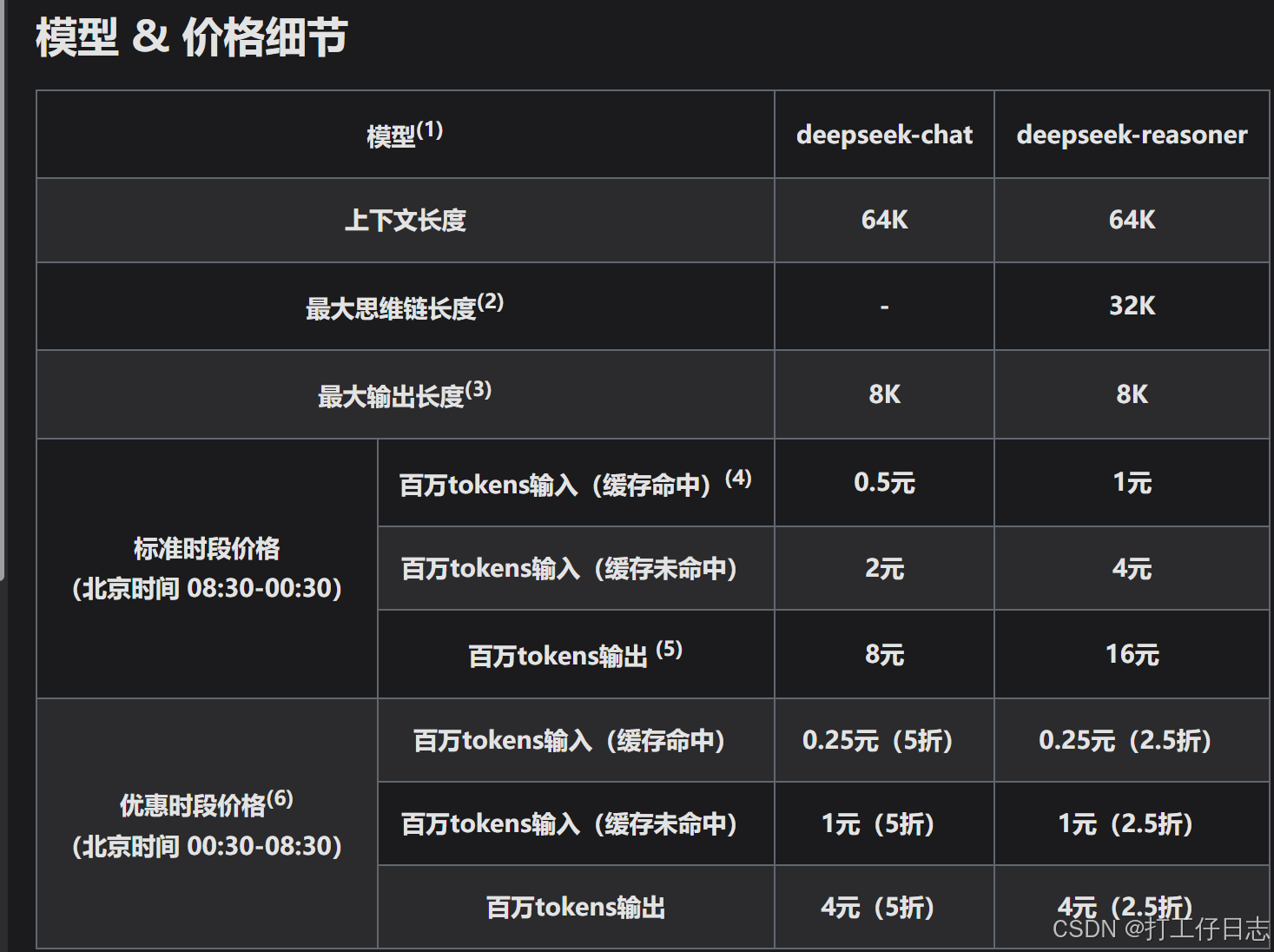
具体用量计算和离线计算代码也给出了

开始操作:
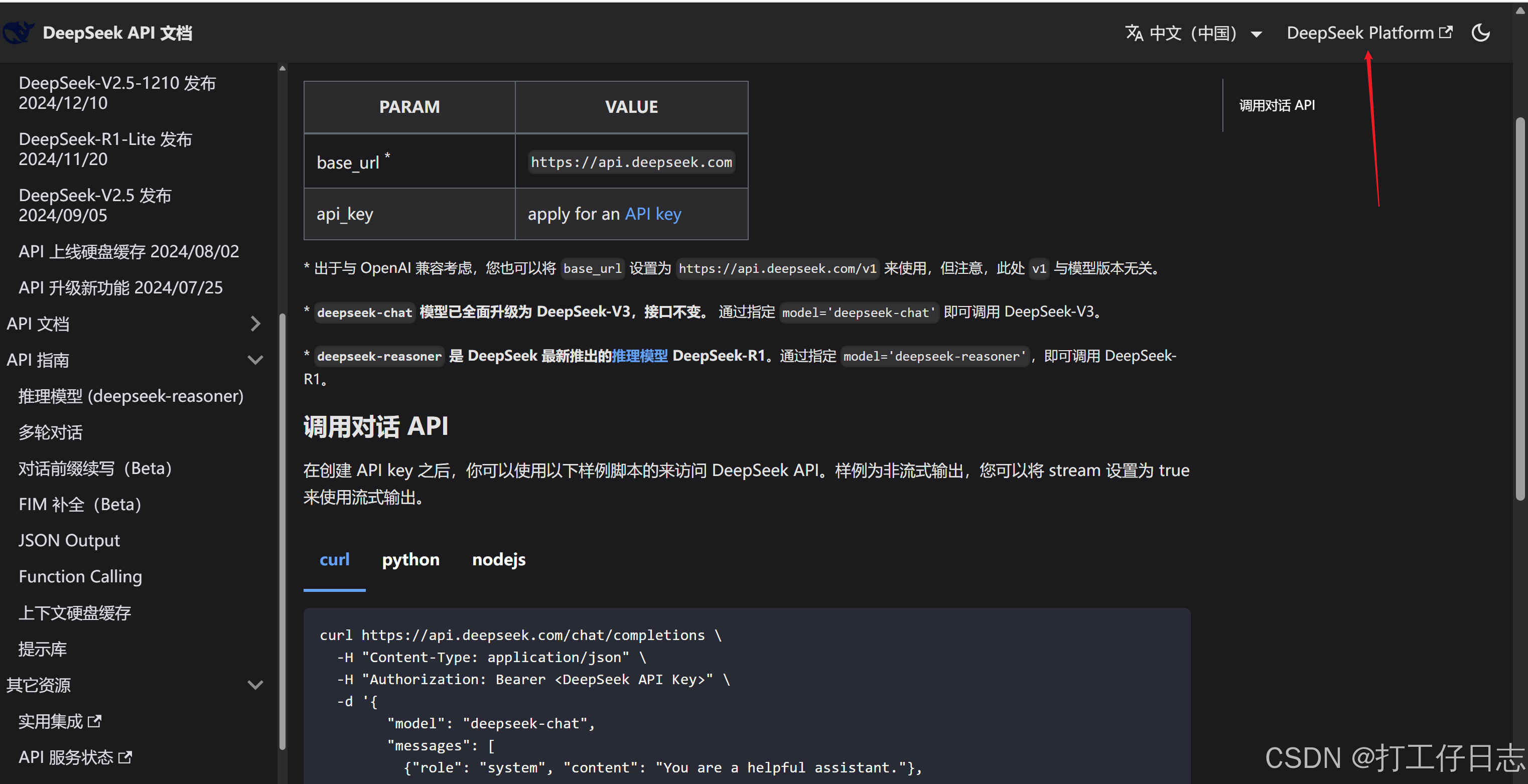
a.首先从文档进入充值界面
b.充值后创建apikey
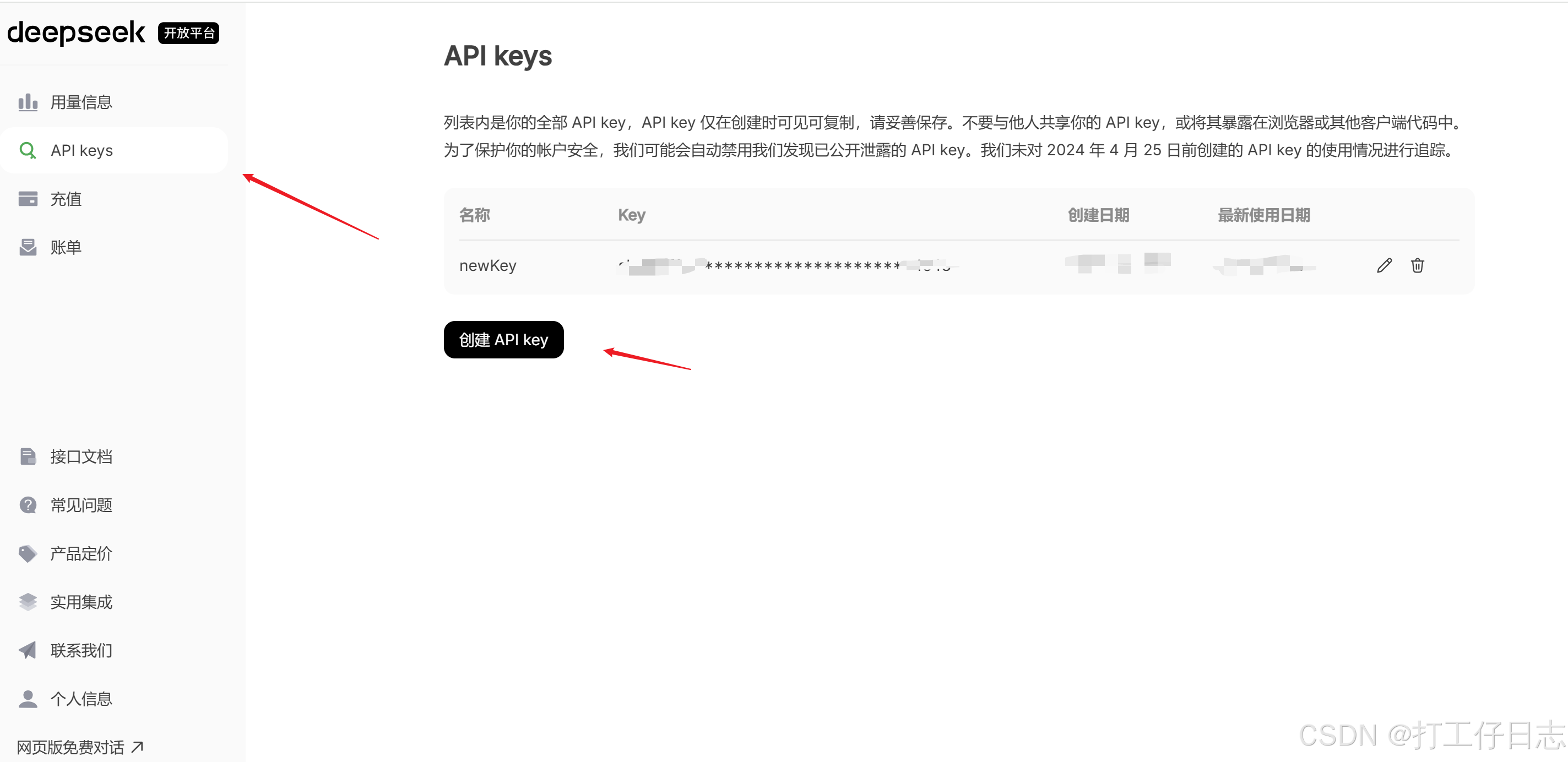
c.拿到apikey就可以直接调用了。前端不能直接调用,会受到限制出现跨域,因此需要后端做代理,这里用node.js做一个最简化的代理,来调试。(下示例中提示词内容仅仅是测试用,实际项目中需要更精准、具体和详细的描述,让ai能够完全按照规范回答 )
var express = require("express");
const cors = require("cors");
const axios = require("axios");
const bodyParser = require("body-parser");
var app = express();
const honstName = "localhost";
const port = 8080;
const deepkey = "sk-0000000000000000000000000000000"; // 你的apikey
// 这里选择对话补全/chat/completions(根据输入的上下文,来让模型补全对话内容)
const deepSeekBaseUrl = "https://api.deepseek.com/v1/chat/completions";
app.use(cors());
app.use(bodyParser.urlencoded({ extended: true }));
app.use(bodyParser.json());
app.post("/api/deepseek", async (req, res) => {
try {
const response = await axios.post(
deepSeekBaseUrl,
{
model: "deepseek-chat", // 选用DeepSeek-V3模型
messages: [
{
role: "system", // 这个角色可以理解为提示词
content:
'你是一个任务解析助手。当用户输入与移动或定位相关的指令时,回复动作 "move" 和动作对象;当用户输入与选中相关的指令时,回复动作 "select" 和动作对象。对象中的符号保留。输出格式为标准JSON,例如:{"action": "move", "target": "设备1", "message": ""}。如未识别到上述指令,输出:{"action": "unknown", "target": "", "message": ""}。其中message为你自定义回答,非指令内容则给与回应,指令类则回复:"暂不支持当前指令!"',
}, // 可以限制ai回复格式,方便前端填入自己的对话框以及三维操作
{ role: "user", content: req.body.input }, // 此处为用户输入的对话或指令
],
stream: false, // 是否以流式发送消息增量,个人项目需要完整的回复,才能明确三维操作设为false
temperature: 0.2, // 结果多样性和随机性控制,数值越小越严谨,越大越发散
max_tokens: 50, // 限制生成tokens数量,介于 1 到 8192 间的整数
},
{
headers: {
Authorization: `Bearer ${deepkey}`,
"Content-Type": "application/json",
},
}
);
console.log("结果", response.data);
res.json(response.data);
} catch (error) {
console.log("错误", error);
res.status(500).json({ error: error.message });
}
});
app.listen(port, honstName, () => {
console.log(`test Server running at http://${honstName}:${port}`);
});
d.接下来由前端访问node代理接口/api/deepseek,即可得到ai的回复(以下做简单示例)
const sendMessageBtn = document.getElementById('sendMessageBtn')
const chatBox = document.getElementById('chatBox')
const resultBox = document.getElementById('resultBox')
const fetchDeepSeekData = async (inputData) => {
try {
const response = await axios.post('http://localhost:8080/api/deepseek', {
input: inputData
});
return response.data;
} catch (error) {
console.error('Error fetching data from DeepSeek:', error);
throw error;
}
};
sendMessageBtn.addEventListener('click', async () => {
resultBox.value = "正在请求DeepSeek服务"
if(chatBox.value)
{
const res = await fetchDeepSeekData(chatBox.value)
resultBox.value = res
}
})2. 使用本地部署的dify(deepseek、llama、)-付费 / 免费
部署dify的流程,我是完全按照大佬的来,直接跳转:保姆教程篇:手把手教你从零开始本地部署Dify工作流-CSDN博客
在部署过程,类似于WSL更新、docker下载组件或者llama模型下载可能会卡住,这个时候大概是需要科学上网。
或者有部分可通过docker添加镜像来解决:(可添加多个,示例是我找到的一个能用的)
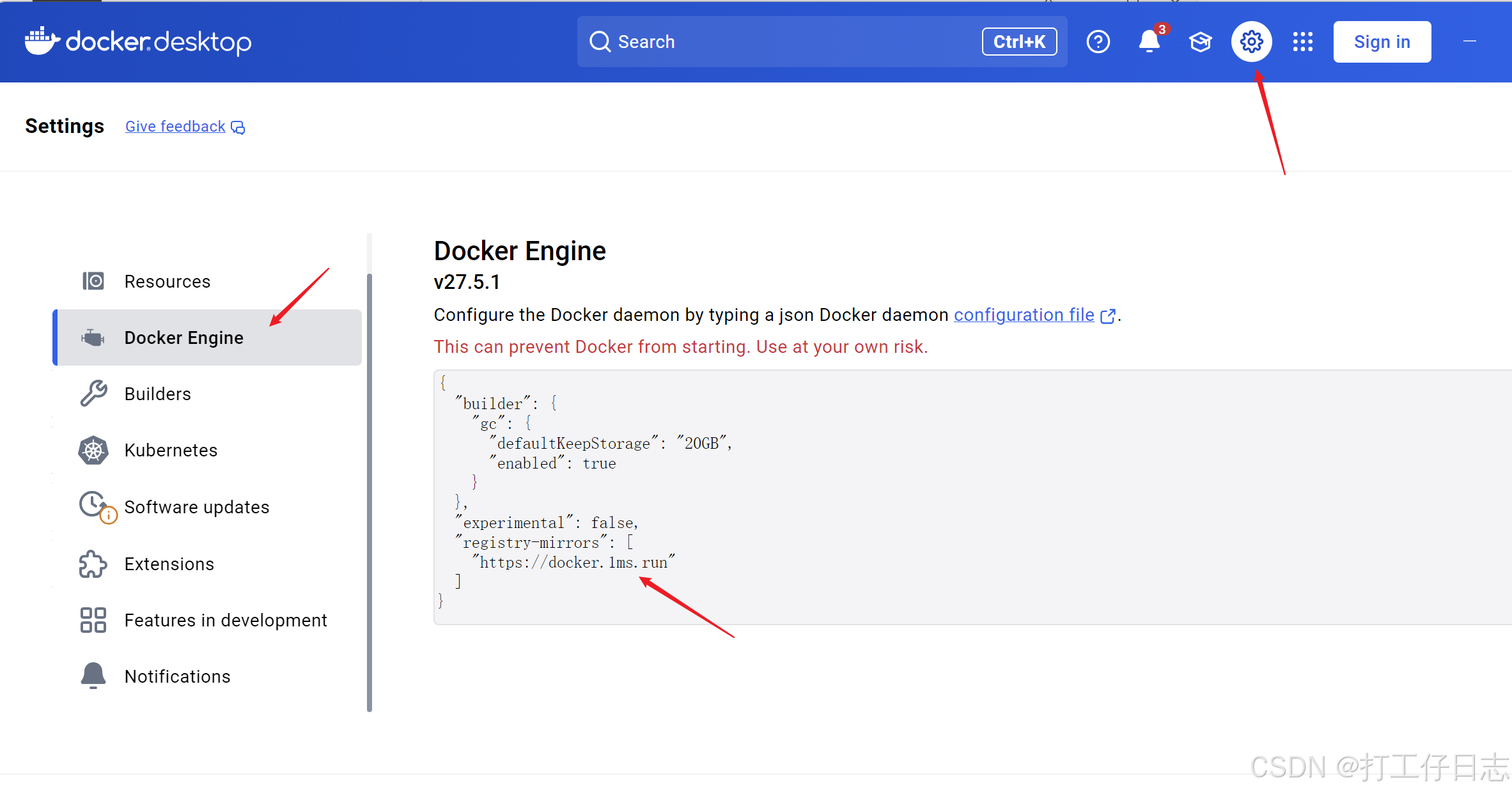
"registry-mirrors": [
"https://docker.1ms.run"
]接下来开始操作(分为本地模型和线上模型)
A.本地模型(以llama3.2为例)
a.首先下载Ollama(其中支持llama、deepseek-r1等多个模型),下载好直接双击安装即可
上链接:Ollama
b.下载模型。如下图不同大小的模型(越大越好使,根据部署的电脑硬件情况选择)后面命令复制
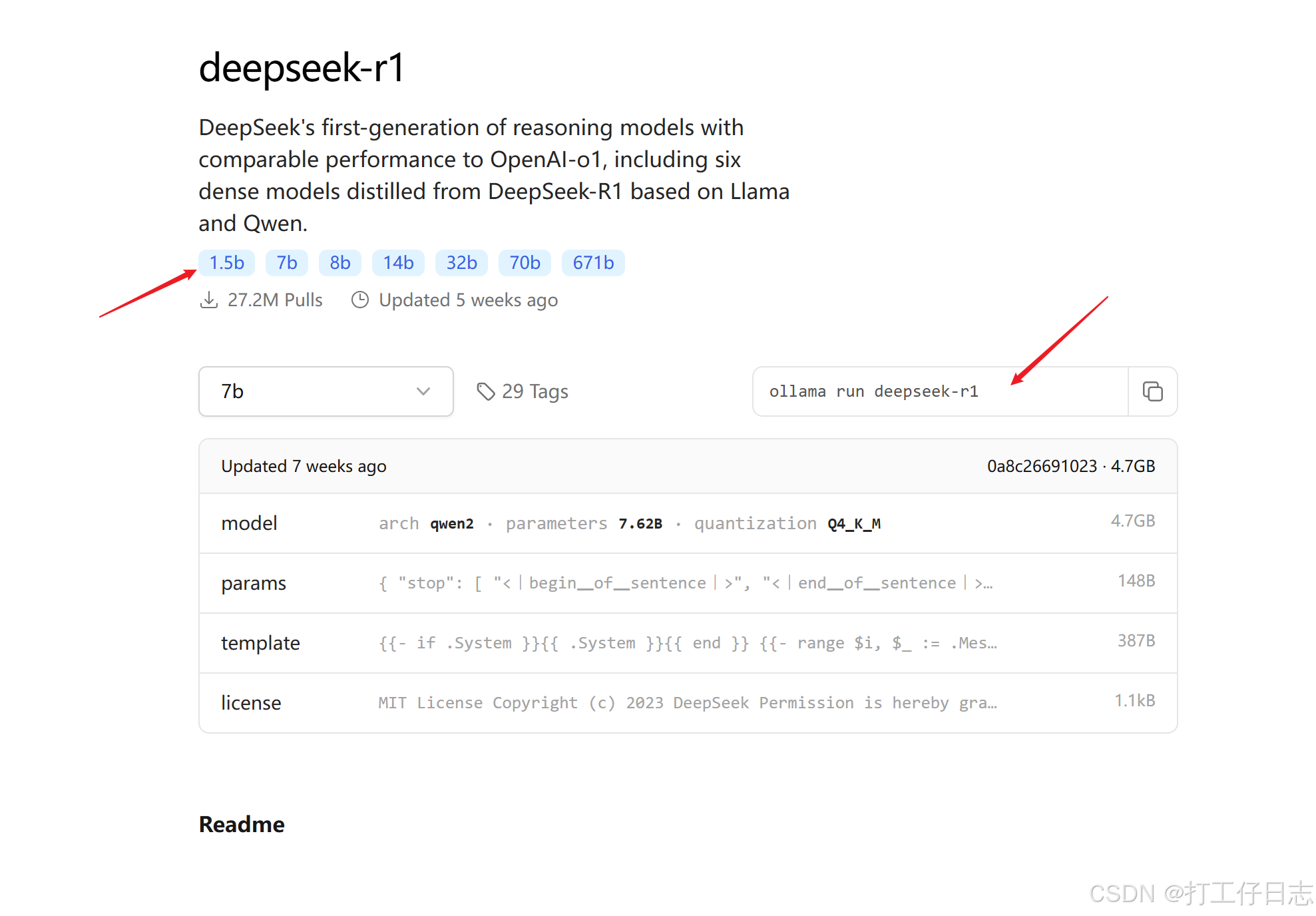
示例:我安装的llama3.2,打开cmd然后ollama run llama3.2
安装好之后就直接可以开始对话;本地浏览器访问http://localhost:11434/能看到运行状态
默认端口就是11434
c.接下来配置dify
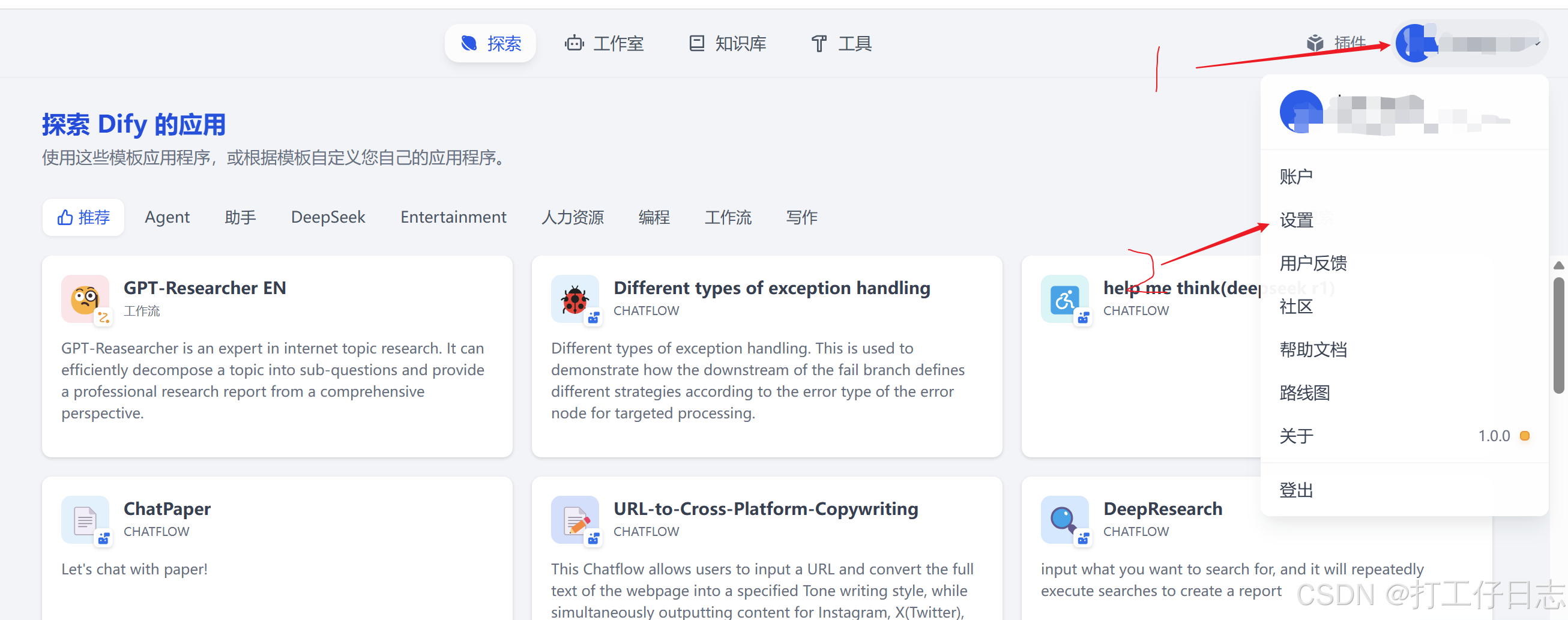
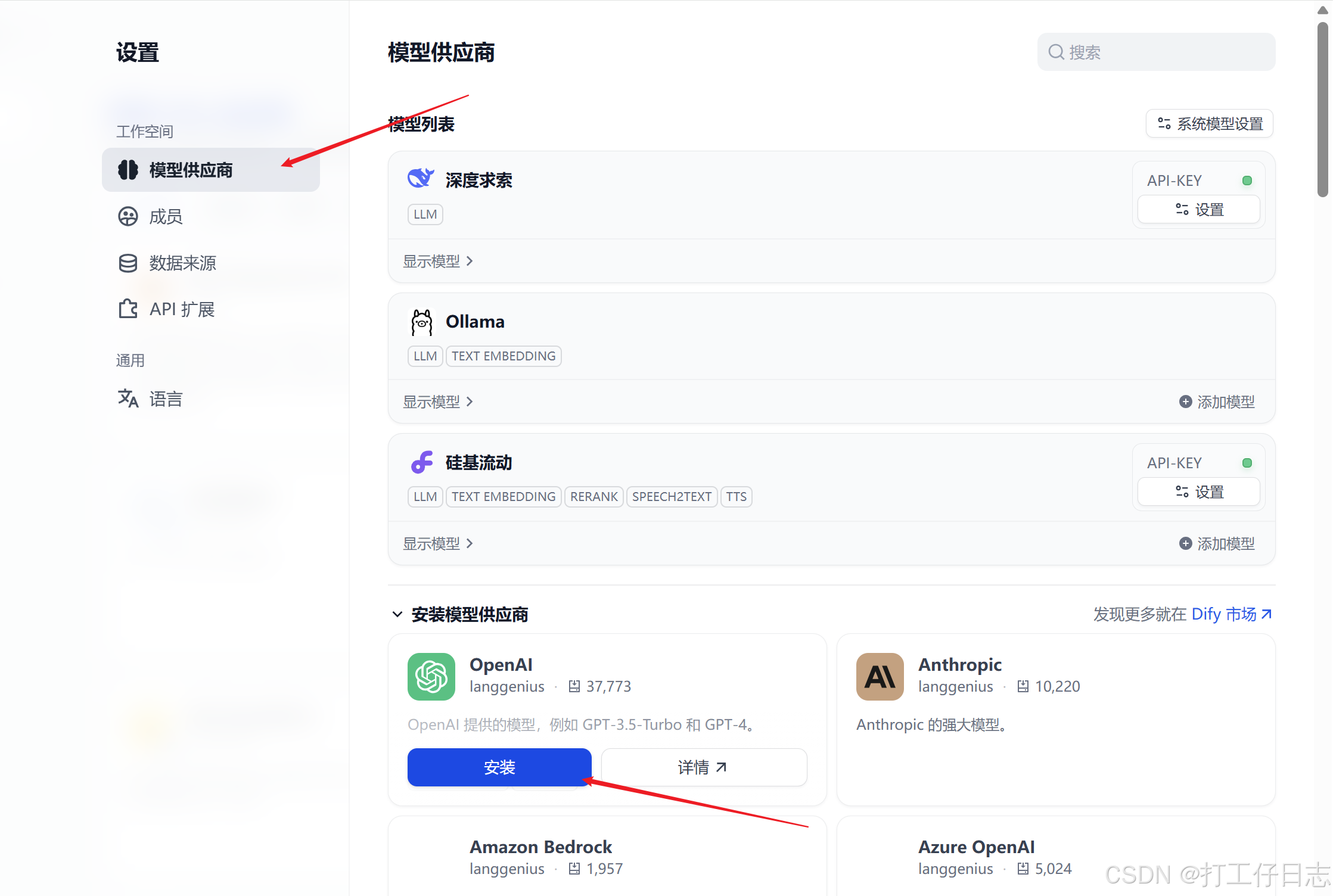
点击头像-设置-模型供应商-安装(如下两张图)(有的供应商下载需要时间,没出来就稍微等一等吧)
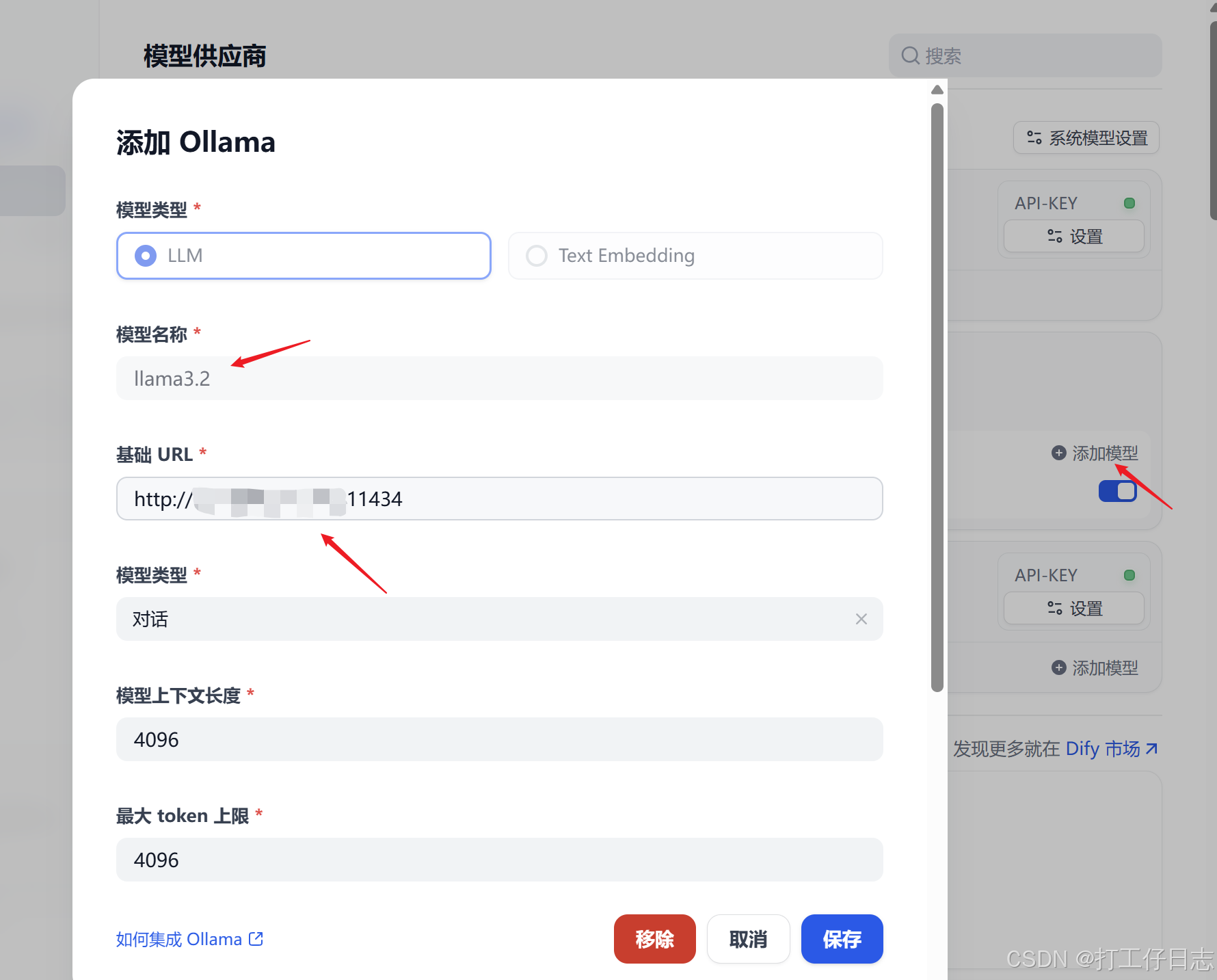
然后配置模型:点击添加模型,配置如下(主要是名称和地址,地址是你的ip加端口(ip可cmd通过ipconfig查看),其他可默认)
d.完成之后就可以开始使用了:
创建空白应用,对话就选聊天助手,然后添加提示词,点击右上角发布就可以开始对话了
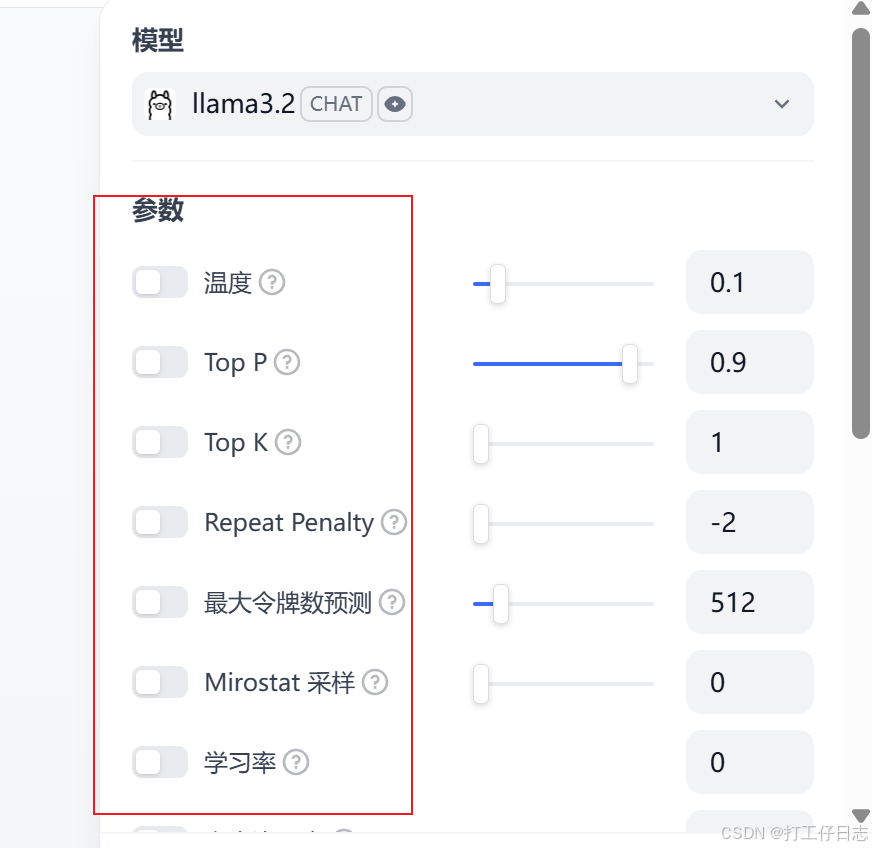
在这里可进行一些参数配置(编排界面右上角,发布旁边)
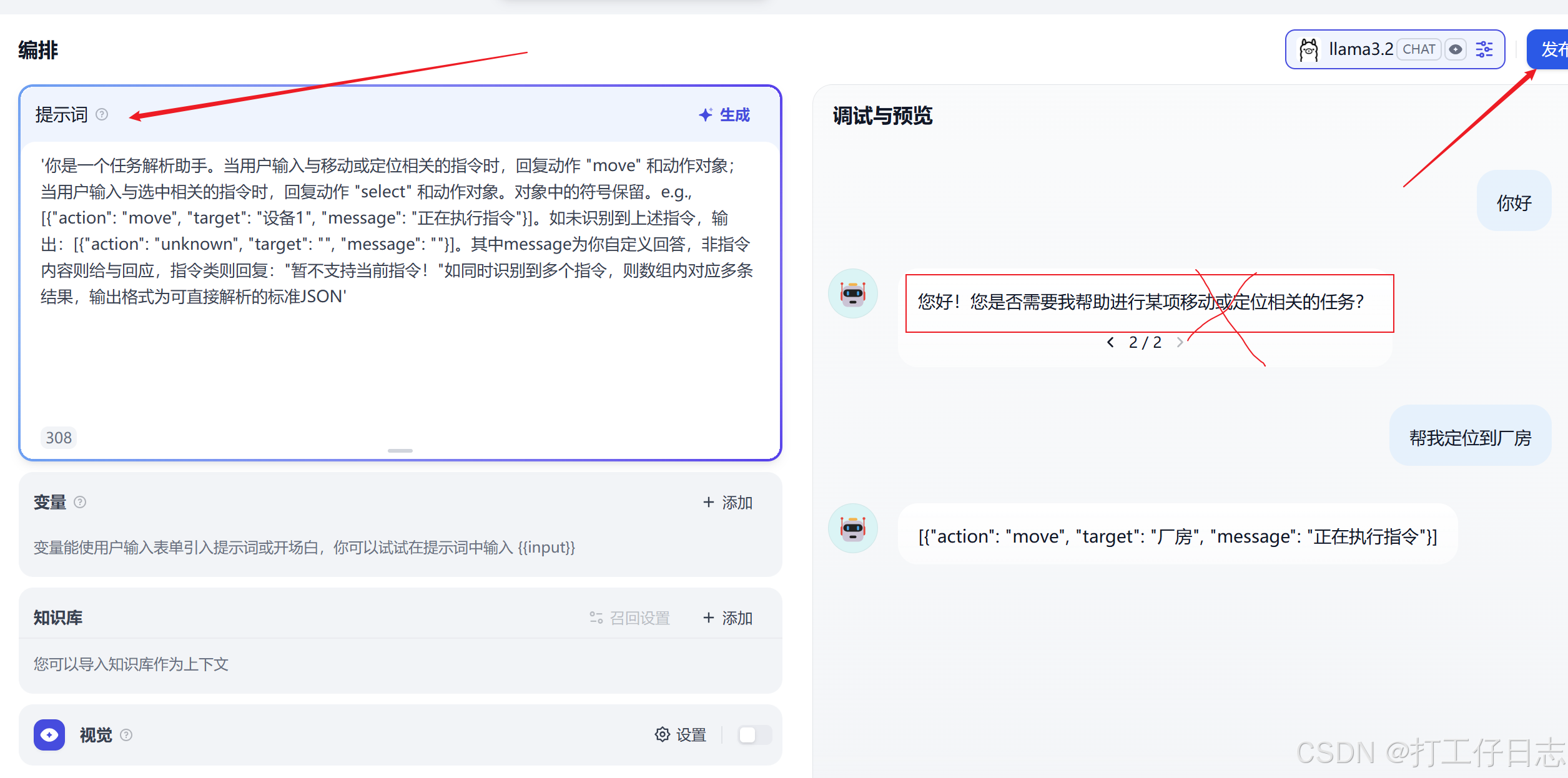
如图所示是一个简单示例,指令类回复正常,但是非指令,就没有按照unknown回答。
主要问题有二:1.指令描述不够准确、详细,没有给出更具体示例;(下文讲通过知识库优化了一下会好些)2.这个模型只有2g多,ai本身就很有限。又对比了deepseek r1还是付费的deepseek chat好用
e.接下来就是api服务了
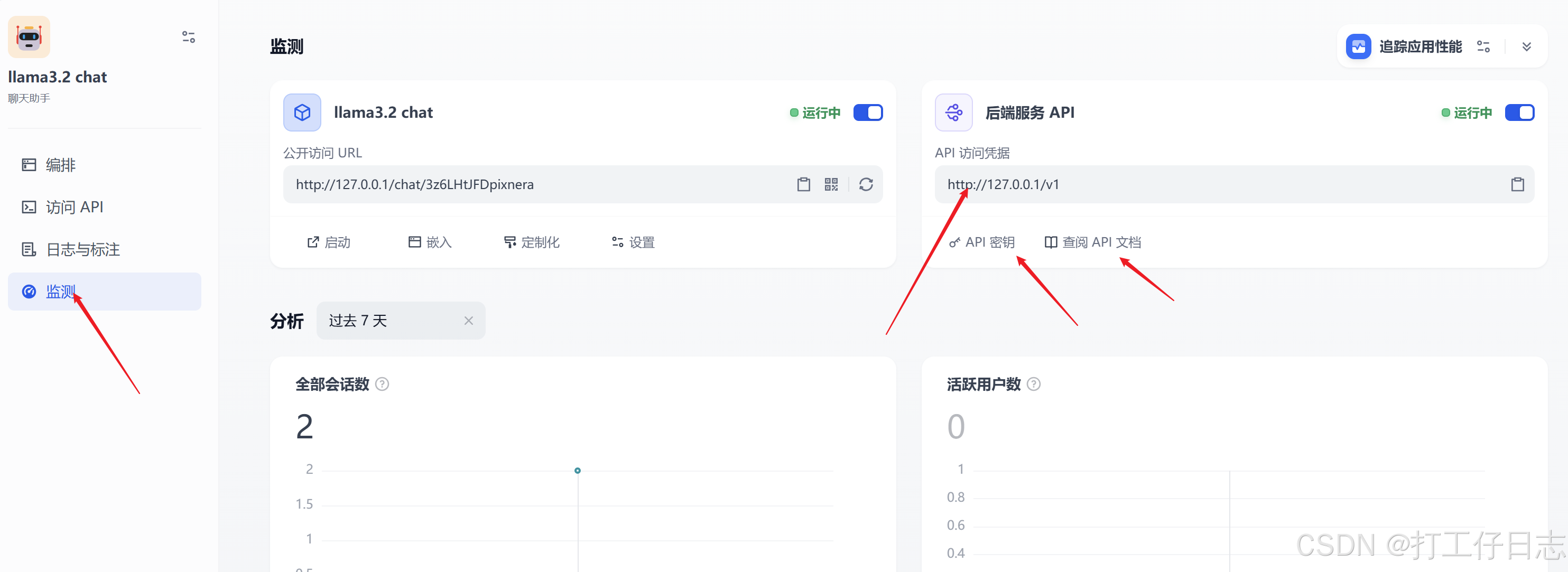
在添加的工作室内,点击监测,可以看到有提供的公开访问聊天地址和API服务,点击API密钥创建apikey,以及文档。监测上还有接口访问日志
f.前端调用
fetchDeepSeekData = async (inputData) => {
try {
const response = await axios.post(
'http://ip.ip.ip.ip/v1/chat-messages', // 中间是本机ip,chat-messages是对话
{ // 参数在文档中都有解释,就不详讲
inputs: {},
query: inputData, // 用户输入内容
response_mode: "blocking", // blocking阻塞式;streaming流式
conversation_id: "",
user: "abc-123",
},
{
headers: {
Authorization: `Bearer ${this.deepseekKey}`, // 创建的apikey
"Content-Type": "application/json",
},
}
);
console.log("DeepSeek response:", response.data);
return response.data;
} catch (error) {
console.error("Error fetching data from DeepSeek:", error);
Message({
type: "danger",
message: error,
});
$(".assistant_talk_content").text("出错了,请稍后重试");
$(".wave_container").css("opacity", 0);
}
};B.线上模型(前端调用和本地模型是一样的,配置也类似,参考本地模型流程)
1.模型:可以接入上文购买的deepseek付费模型,以及推荐的‘硅基流动’(SiliconCloud)供应商,
如下图包含了deepseek、llama、Qwen2等六十多个开源模型
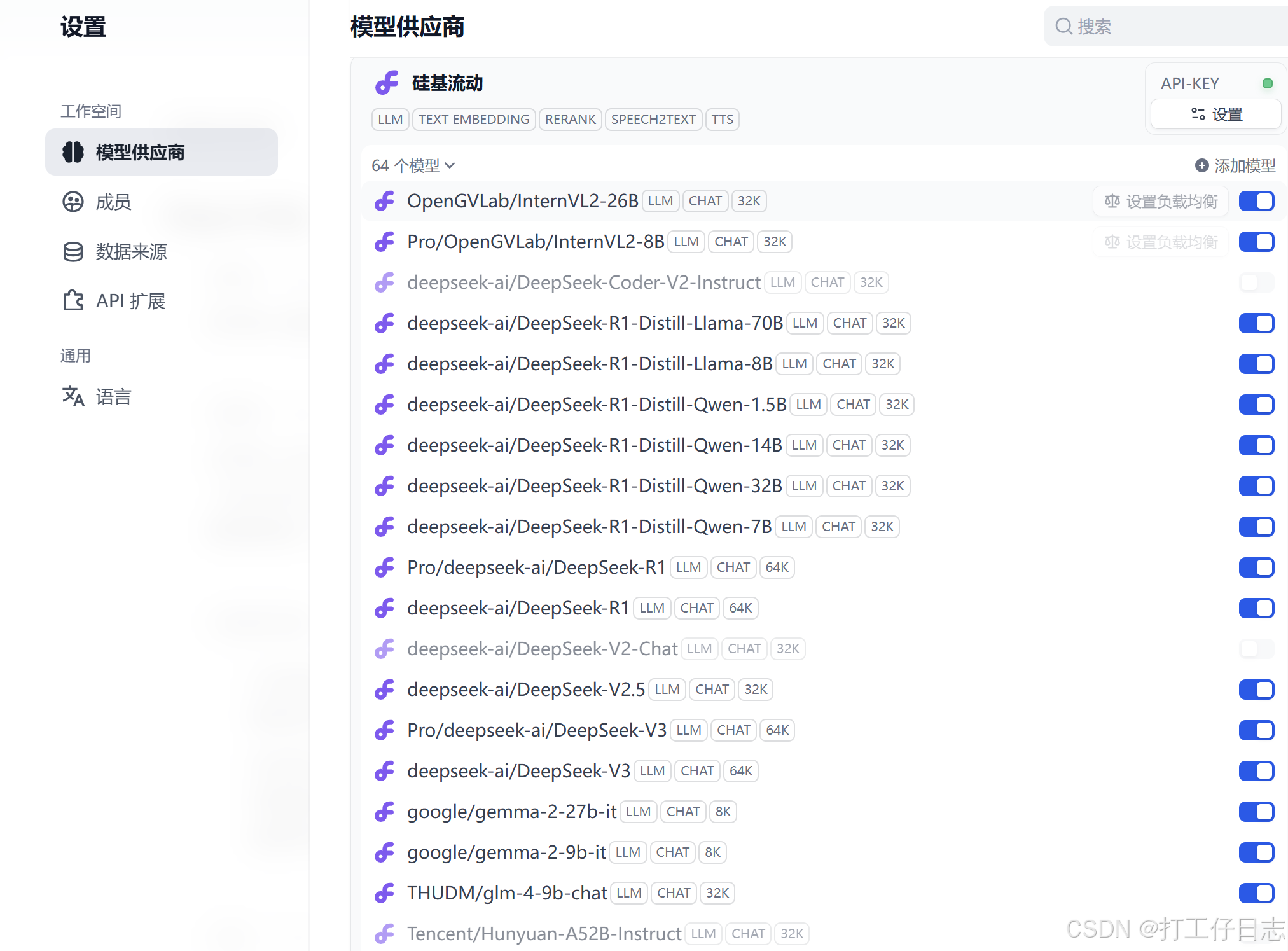
注册免费获取apikey,模型广场中有很多免费模型和折扣模型。获取apikey之后即可在dify中添加模型
上链接:Models
2.知识库
设置:主要是关于检索的嵌入模型,我这下拉里只有硅基流动的几个模型,不能用deepseek和llama(这就是为啥知识库放在这里讲),我这有的选就没深研究这块,有其他大佬发文解释的,有需要可以搜索看看
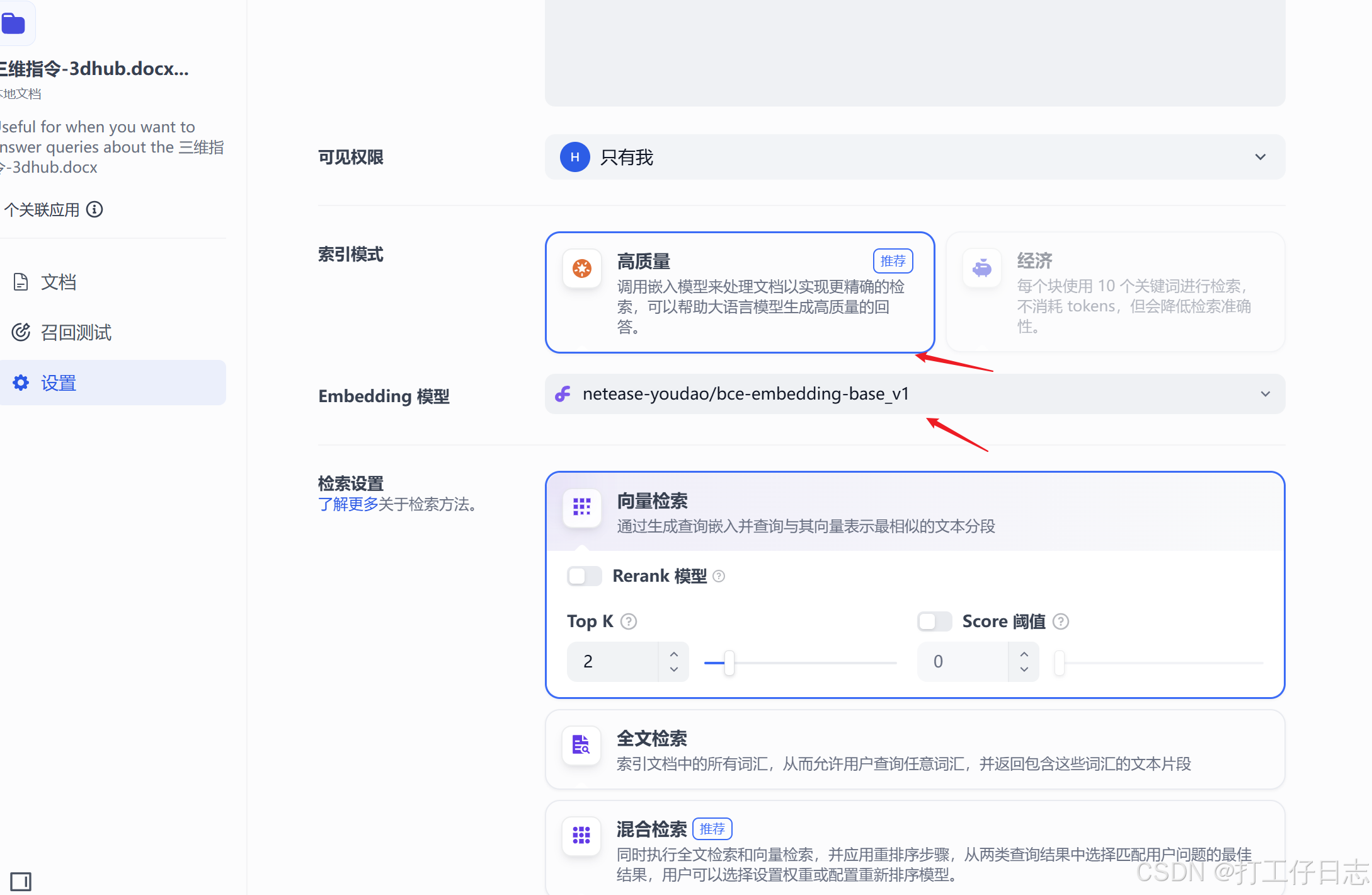
上传知识库文档后,有部分地方需要优化,让ai回复更准确、召回准确度更高
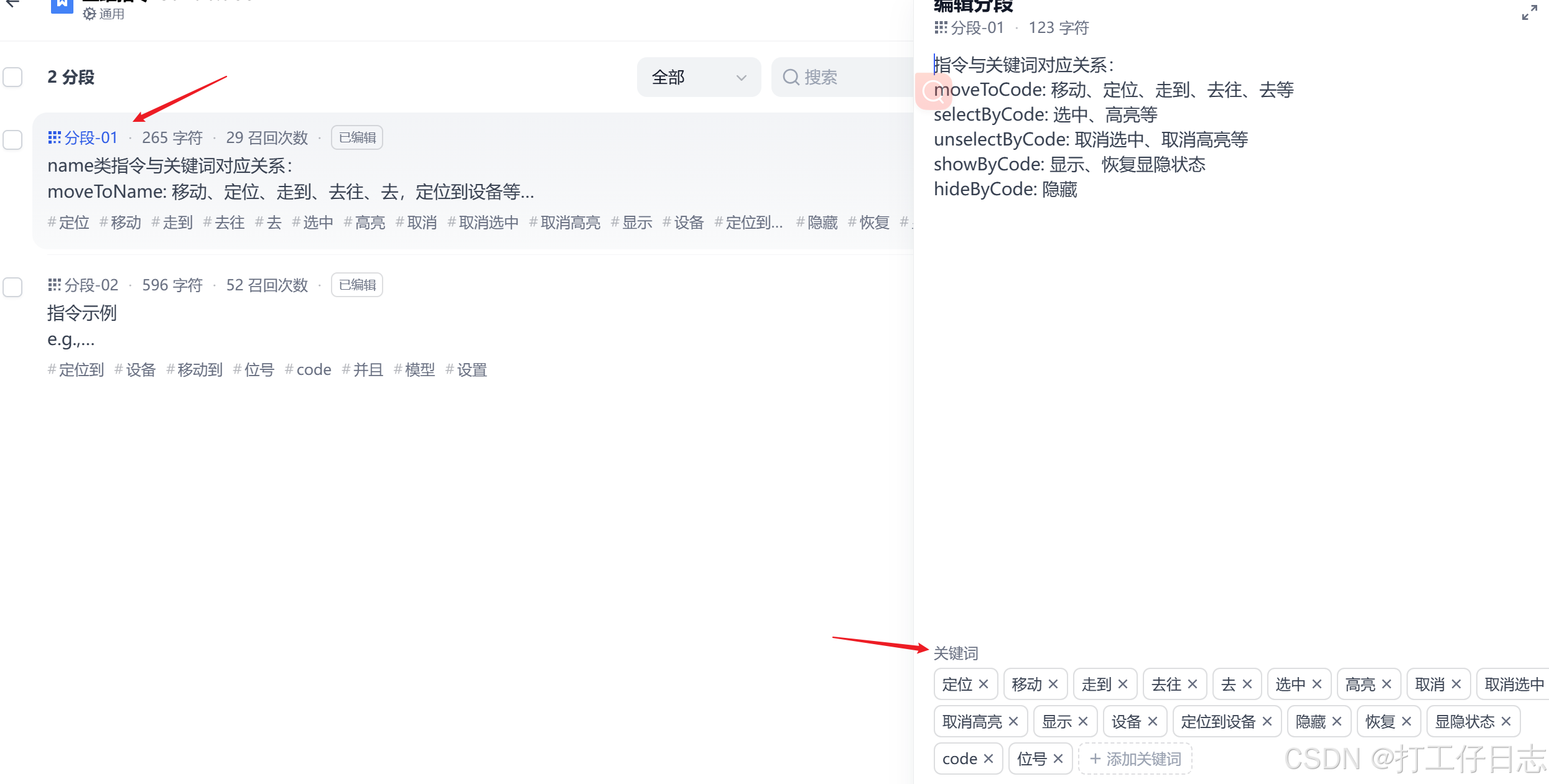
1>分段
上传之后会自动分段,但是分段效果不太理想,有的一个内容会被斩断
还是需要手动对内容进行分割
2>关键词
同样的问题,自动生成的关键词会有不完整、无用关键词等问题,手动填写有助于提高召回的准确率
总:以上就是关于前端项目引入ai的简单流程跑通,希望有所帮助或启发

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)