[中英字幕]吴恩达机器学习系列课程 笔记
[中英字幕]吴恩达机器学习系列课程 笔记
- 教程与代码地址
- P1 1-1.欢迎参加《机器学习》课程
- P2 1-2.什么是机器学习?
- P3 1-3.监督学习
- P4 1-4.无监督学习
- P5 2-1.模型描述
- P6 2-2.代价函数
- P7 2-3.代价函数(一)
- P8 2-4.代价函数(二)
- P9 2-5.梯度下降
- P10 2-6.梯度下降知识点总结
- P11 2-7.线性回归的梯度下降
- P12 3-1.矩阵和向量
- P13 3-2.加法和标量乘法
- P14 3-3.矩阵向量乘法
- P15 3-4.矩阵乘法
- P16 3-5.矩阵乘法特征
- P17 3-6.逆和转置
- P18 4-1.多功能
- P19 4-2.多元梯度下降法
- P20 4-3.多元梯度下降法演练.I.–.特征缩放
- P21 4-4.多元梯度下降法II.–.学习率
- P22 4-5.特征和多项式回归
- P23 4-6.正规方程(区别于迭代方法的直接解法)
- P24 4-7.正规方程在矩阵不可逆情况下的解决方法
- P25 4-8.导师的编程小技巧
- P26 5-1.基本操作
- P27 5-2.移动数据
- P28 5-3.计算数据
- P29 5-4.数据绘制
- P30 5-5.控制语句:for,while,if.语句
- P31 5-6.矢量
- P32 6-1.分类
- P33 6-2.假设陈述
- P34 6-3.决策界限
- P35 6-4.代价函数
- P36 6-5.简化代价函数与梯度下降
- P37 6-6.高级优化
- P38 6-7.多元分类:一对多
- P39 7-1.过拟合问题
- P40 7-2.代价函数
- P41 7-3.线性回归的正则化
- P42 7-4.Logistic.回归的正则化
- P43 8-1.非线性假设
- P44 8-2.神经元与大脑
- P45 8-3.模型展示Ⅰ
- P46 8-4.模型展示Ⅱ
- P47 8-5.例子与直觉理解Ⅰ
- P48 8-6.例子与直觉理解Ⅱ
- P49 8-7.多元分类
- P50 9-1.代价函数
- P51 9-2.反向传播算法
- P52 9-3.理解反向传播
- P53 9-4.使用注意:展开参数
- P54 9-5.梯度检测
- P55 9-6.随机初始化
- P56 9-7.组合到一起
- P57 9-8.无人驾驶
- P58 10-1.决定下一步做什么
- P59 10-2.评估假设
- P60 10-3.模型选择和训练、验证、测试集
- P61 10-4.诊断偏差与方差
- P62 10-5.正则化和偏差、方差
- P63 10-6.学习曲线
- P64 10-7.决定接下来做什么
- P65 11-1.确定执行的优先级
- P66 11-2.误差分析
- P67 11-3.不对称性分类的误差评估
- P68 11-4.精确度和召回率的权衡
- P69 11-5.机器学习数据
- P70 12-1.优化目标
- P71 12-2.直观上对大间隔的理解
- P72 12-3.大间隔分类器的数学原理
- P73 12-4.核函数1
- P74 12-5.核函数2
- P75 12-6.使用SVM
- P76 13-1.无监督学习
- P77 13-2.K-Means算法
- P78 13-3.优化目标
- P79 13-4.随机初始化
- P80 13-5.选取聚类数量
- P81 14-1.目标.I:数据压缩
- P82 14-2.目标.II:可视化
- P83 14-3.主成分分析问题规划1
- P84 14-4.主成分分析问题规划2
- P85 14-5.主成分数量选择
- P86 14-6.压缩重现
- P87 14-7.应用.PCA.的建议
- P88 15-1.问题动机
- P89 15-2.高斯分布
- P90 15-3.算法
- P91 15-4.开发和评估异常检测系统
- P92 15-5.异常检测.VS.监督学习
- P93 15-6.选择要使用的功能
- P94 15-7.多变量高斯分布
- P95 15-8.使用多变量高斯分布的异常检测
- P96 16-1.问题规划
- P97 16-2.基于内容的推荐算法
- P98 16-3.协同过滤
- P99 16-4.协同过滤算法
- P100 16-5.矢量化:低轶矩阵分解
- P101 16-6.实施细节:均值规范化
- P102 17-1.学习大数据集
- P103 17-2.随机梯度下降
- P104 17-3.Mini-Batch.梯度下降
- P105 17-4.随机梯度下降收敛
- P106 17-5.在线学习
- P107 17-6.减少映射与数据并行
- P108 18-1.问题描述与.OCR.pipeline
- P109 18-2.滑动窗口
- P110 18-3.获取大量数据和人工数据
- P111 18-4.天花板分析:下一步工作的.pipeline
- P112 19-1.总结与感谢
教程与代码地址
笔记中,图片和代码基本源自up主的视频和代码
视频地址:[中英字幕]吴恩达机器学习系列课程
代码地址:matlab 代码
讲义地址:https://github.com/TheisTrue/MLofAndrew-Ng
如果想要爬虫视频网站一样的csdn目录,可以去这里下载代码:https://github.com/JeffreyLeal/MyUtils/tree/%E7%88%AC%E8%99%AB%E5%B7%A5%E5%85%B71
P1 1-1.欢迎参加《机器学习》课程
P2 1-2.什么是机器学习?
P3 1-3.监督学习
P4 1-4.无监督学习
P5 2-1.模型描述
P6 2-2.代价函数
P7 2-3.代价函数(一)
P8 2-4.代价函数(二)

P9 2-5.梯度下降

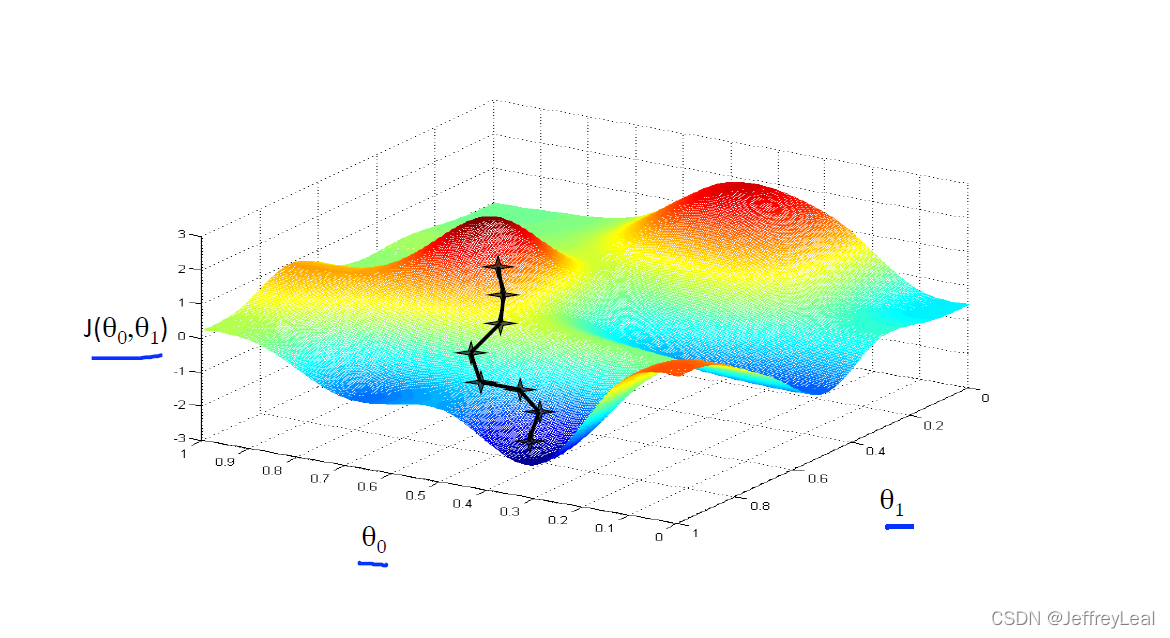
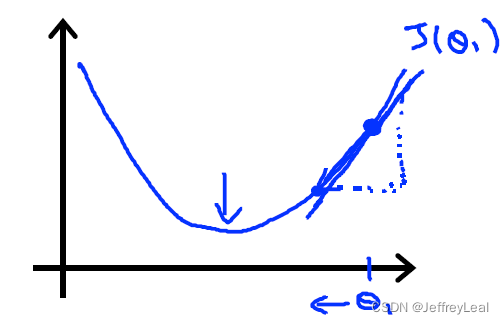
Θ n e w = Θ − α ∂ J ( Θ ) ∂ Θ \Theta_{new} = \Theta - \alpha\frac{\partial J(\Theta)}{\partial \Theta} Θnew=Θ−α∂Θ∂J(Θ)
∂ J ( Θ ) ∂ Θ \frac{\partial J(\Theta)}{\partial \Theta} ∂Θ∂J(Θ) 其实是上山最快的方向, α \alpha α 是学习率,走一步的距离,当前位置-上山最快的方向*走一步的距离=下山最快的路径。
P10 2-6.梯度下降知识点总结
P11 2-7.线性回归的梯度下降
P12 3-1.矩阵和向量
P13 3-2.加法和标量乘法
P14 3-3.矩阵向量乘法
P15 3-4.矩阵乘法
P16 3-5.矩阵乘法特征
P17 3-6.逆和转置
P18 4-1.多功能
P19 4-2.多元梯度下降法
P20 4-3.多元梯度下降法演练.I.–.特征缩放
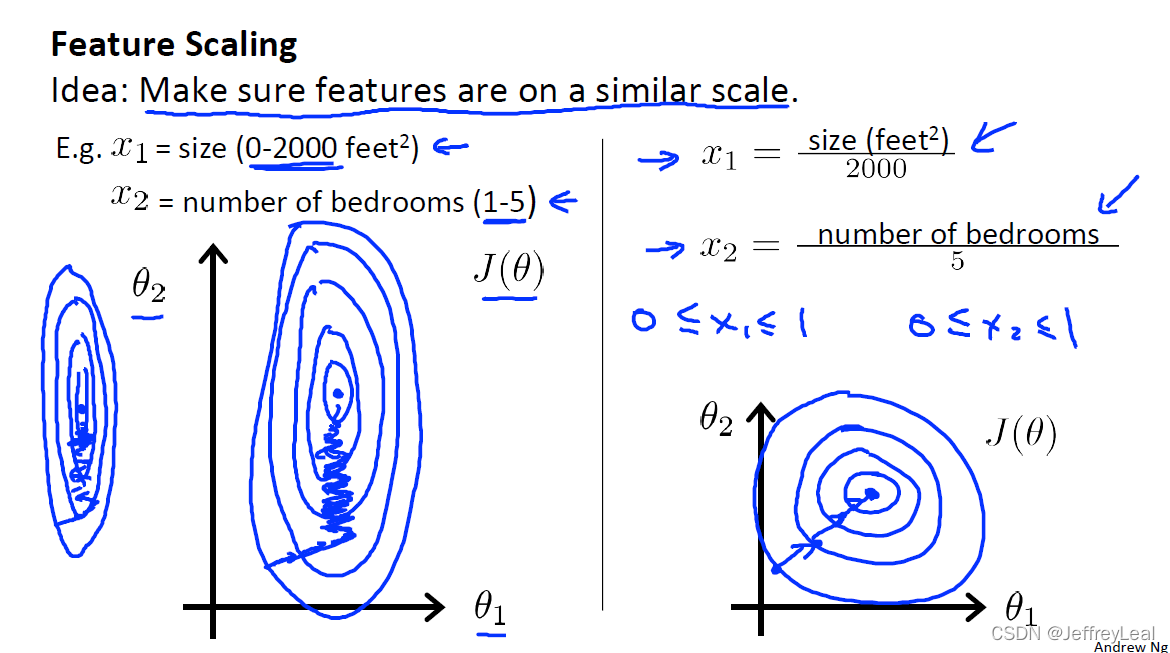
normalize 之后,训练收敛要更快,椭圆收敛慢,收敛到中心的距离更远。
P21 4-4.多元梯度下降法II.–.学习率
学习率要用不同数量级去尝试,看哪个收敛比较快
P22 4-5.特征和多项式回归
P23 4-6.正规方程(区别于迭代方法的直接解法)
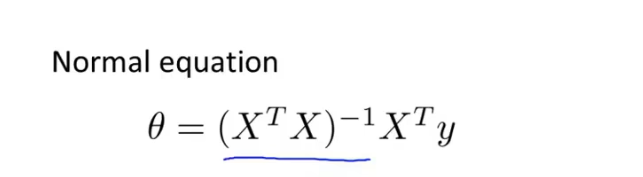
对于数据集很大的训练,即使参数求解有闭式解,我们扔使用梯度下降法,因为矩阵的复杂度为 O ( n 3 ) O(n^3) O(n3)。
P24 4-7.正规方程在矩阵不可逆情况下的解决方法
P25 4-8.导师的编程小技巧
P26 5-1.基本操作
P27 5-2.移动数据
P28 5-3.计算数据
P29 5-4.数据绘制
P30 5-5.控制语句:for,while,if.语句
P31 5-6.矢量
P32 6-1.分类
P33 6-2.假设陈述

P34 6-3.决策界限
P35 6-4.代价函数
P36 6-5.简化代价函数与梯度下降

下面三种无需手动设置学习率。
P37 6-6.高级优化
P38 6-7.多元分类:一对多
P39 7-1.过拟合问题
P40 7-2.代价函数
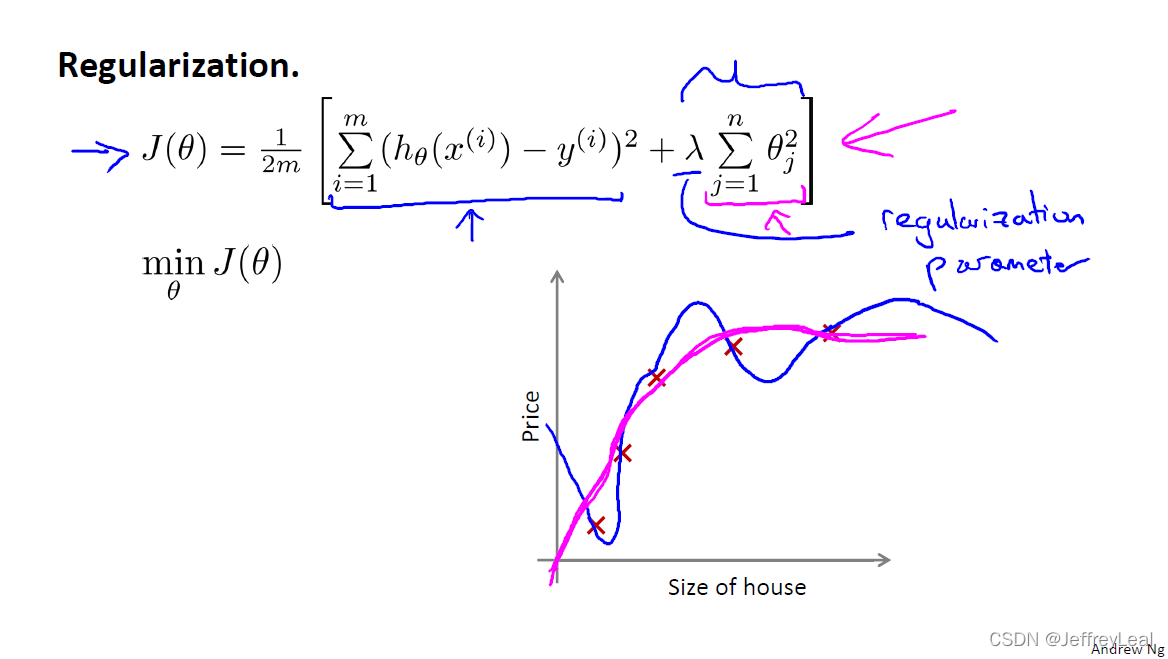
此 loss 函数的后项,就是一个惩罚函数,就是 regularization。 λ \lambda λ 很大, θ \theta θ 就会很小,偏置 θ 0 \theta_0 θ0 会很大,相当于直线,减小过拟合。
P41 7-3.线性回归的正则化
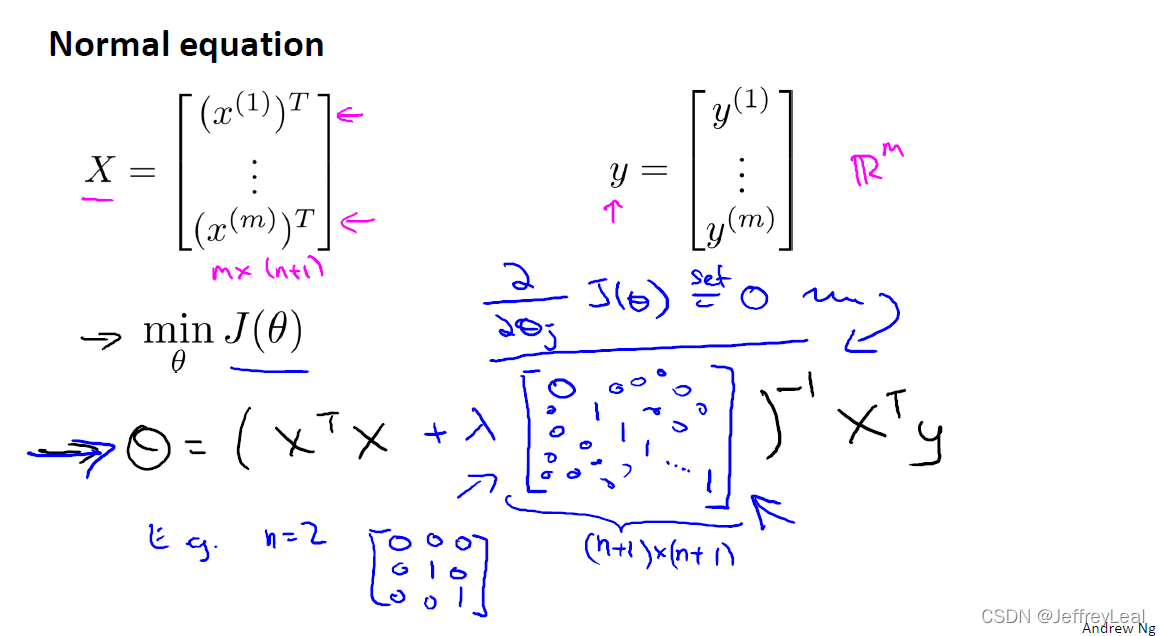
正则化后求解参数时,蓝色部分是较之前多出来的项。加上此项,奇异矩阵也会变非奇异矩阵。
P42 7-4.Logistic.回归的正则化
P43 8-1.非线性假设
P44 8-2.神经元与大脑
P45 8-3.模型展示Ⅰ
P46 8-4.模型展示Ⅱ
P47 8-5.例子与直觉理解Ⅰ
P48 8-6.例子与直觉理解Ⅱ
P49 8-7.多元分类
P50 9-1.代价函数
P51 9-2.反向传播算法
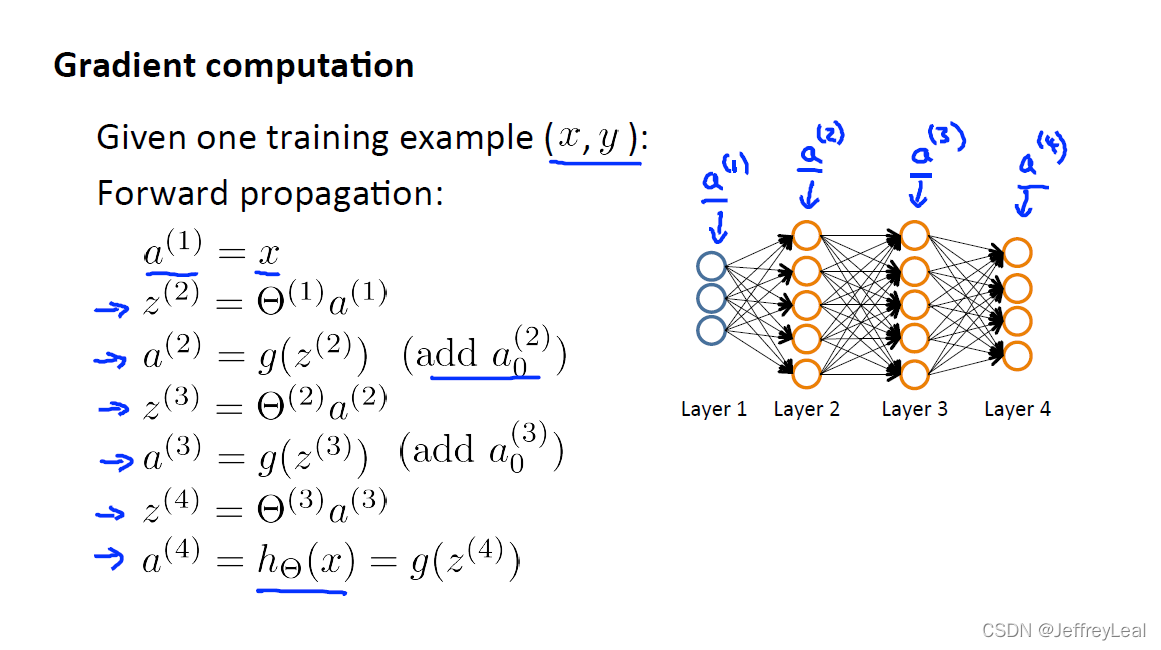

δ \delta δ 是偏导
P52 9-3.理解反向传播
P53 9-4.使用注意:展开参数
P54 9-5.梯度检测
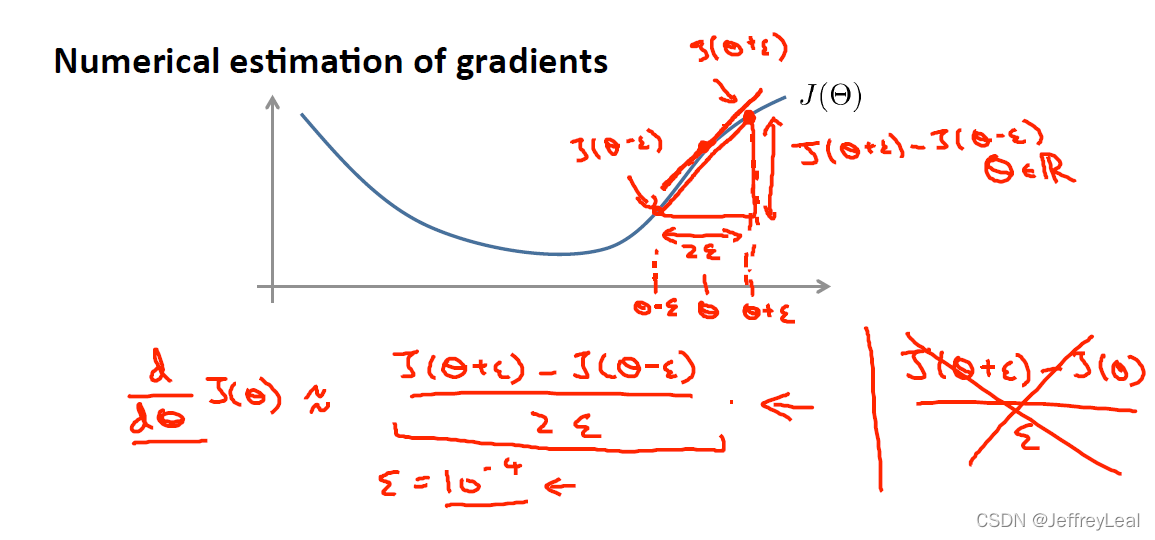
ϵ \epsilon ϵ 通常是 1 0 − 4 10^{-4} 10−4
P55 9-6.随机初始化
权重初始化如果相等,更新也会相等,就学不到东西了
P56 9-7.组合到一起
P57 9-8.无人驾驶
P58 10-1.决定下一步做什么
P59 10-2.评估假设
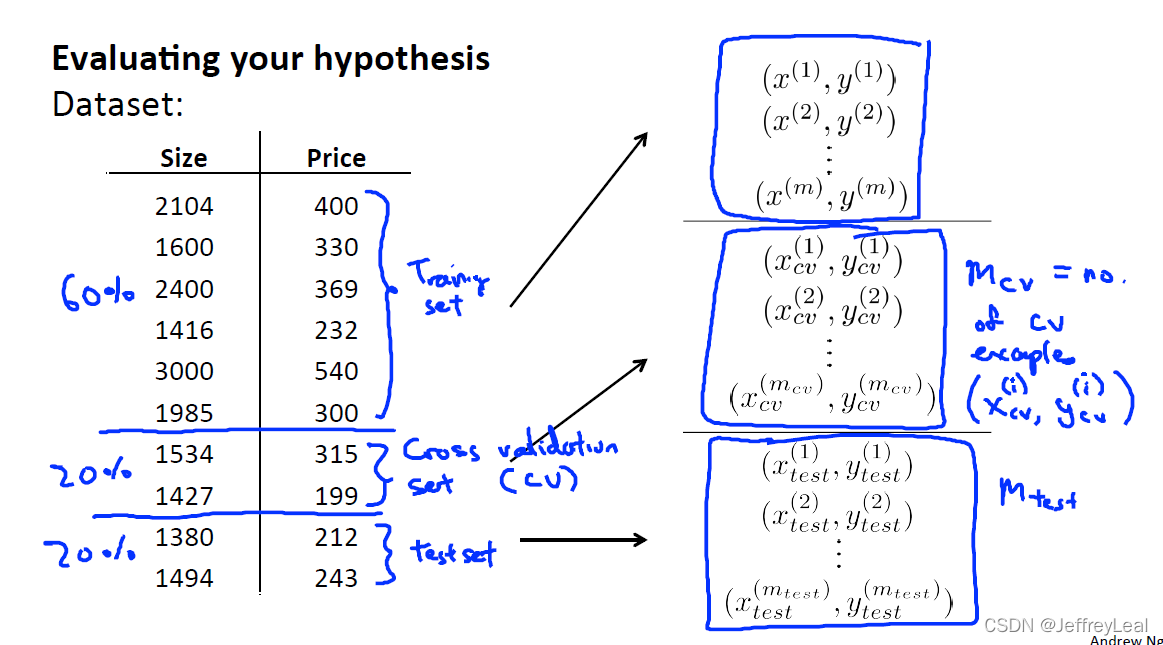
P60 10-3.模型选择和训练、验证、测试集
P61 10-4.诊断偏差与方差
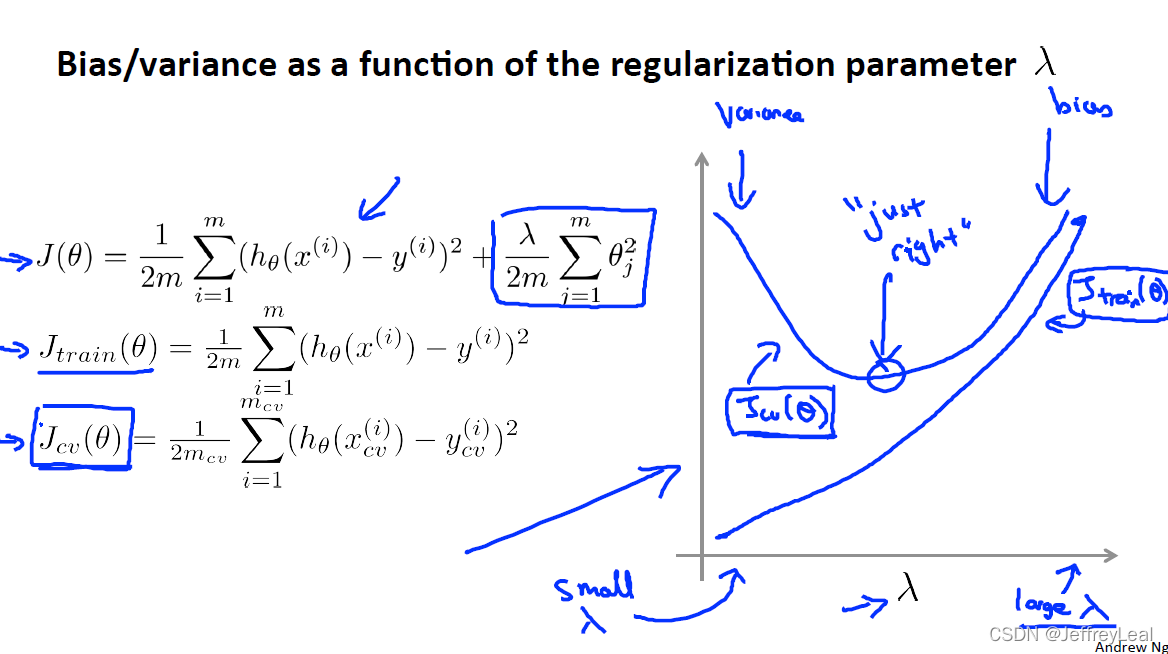
P62 10-5.正则化和偏差、方差

使用验证集调整超参数。
P63 10-6.学习曲线
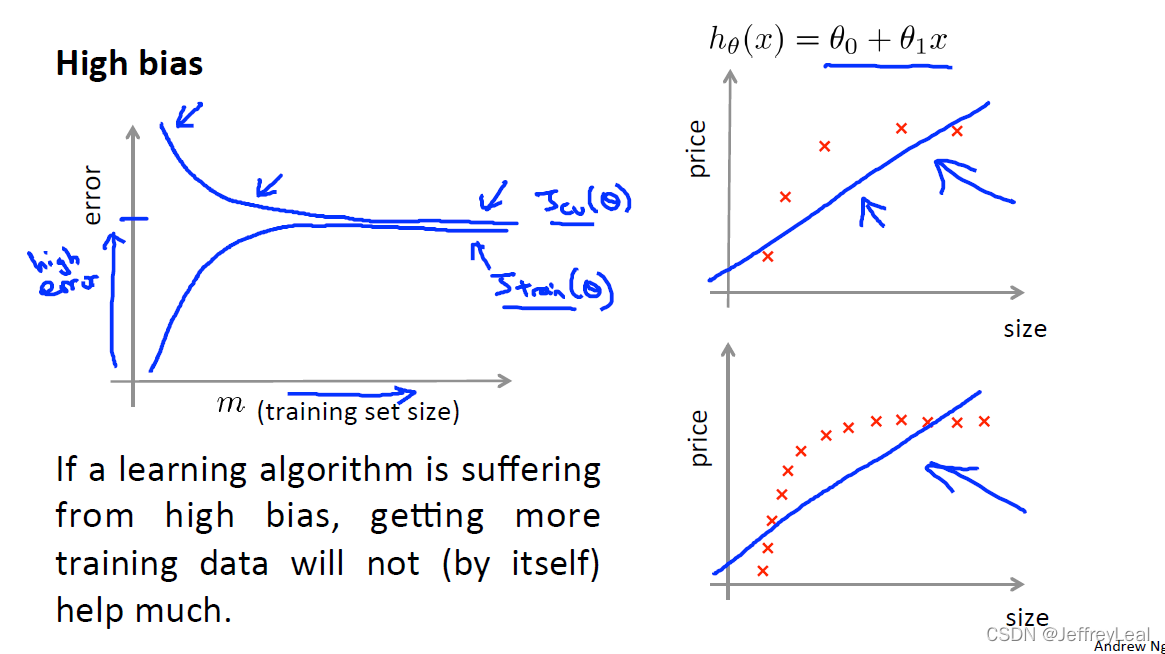
高偏差说明模型有问题,增大数据集是没有用的。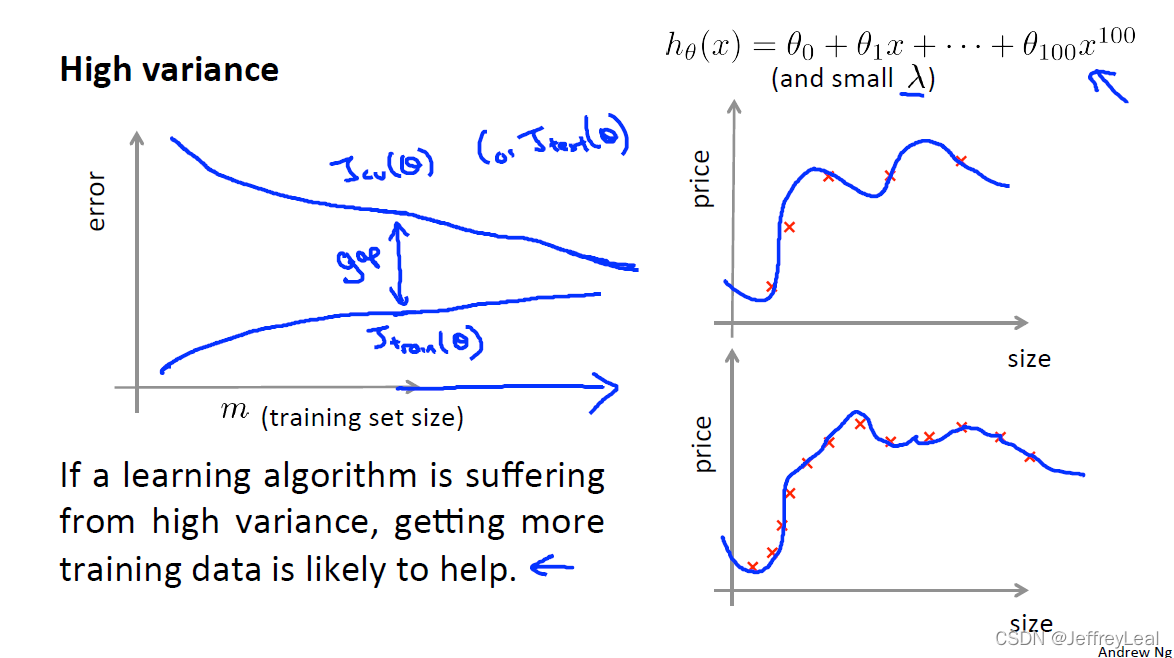
高方差,增大数据集是有用的。
P64 10-7.决定接下来做什么

P65 11-1.确定执行的优先级
P66 11-2.误差分析
使用简单的算法,分析分类错误的样本,使用更好的分类特征。
P67 11-3.不对称性分类的误差评估
P68 11-4.精确度和召回率的权衡
P69 11-5.机器学习数据
P70 12-1.优化目标
P71 12-2.直观上对大间隔的理解
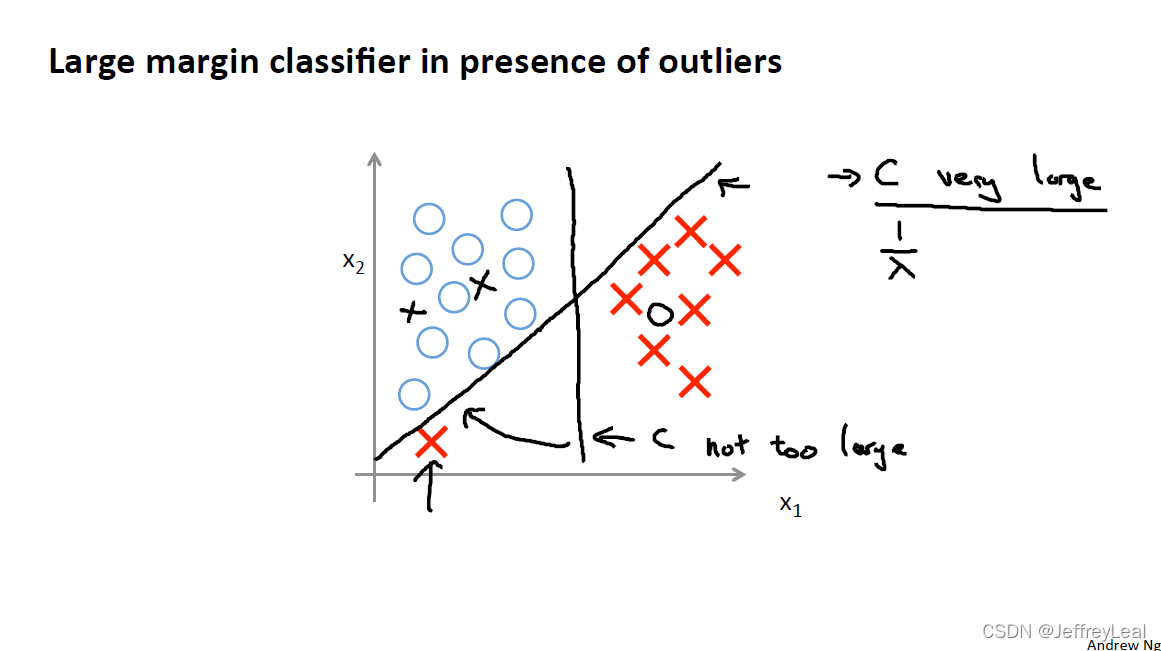
P72 12-3.大间隔分类器的数学原理
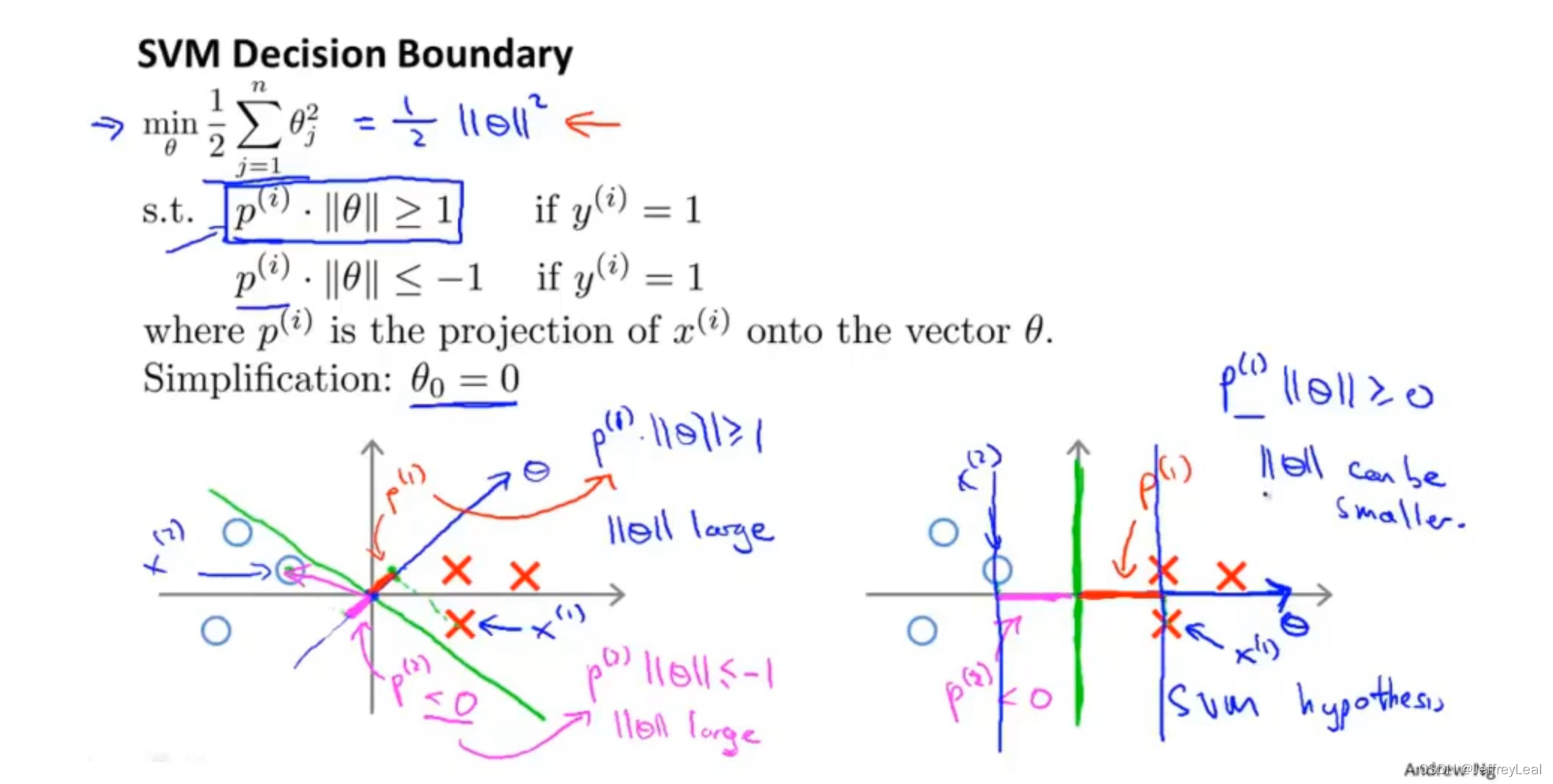
已知 p ( i ) ⋅ ∥ θ ∥ ≥ 1 p^{(i)}\cdot \lVert \theta \lVert \geq 1 p(i)⋅∥θ∥≥1,想要 p ( i ) p^{(i)} p(i) 大,即右边那样, ∥ θ ∥ \lVert \theta \lVert ∥θ∥ 就要小,这就是SVM。
P73 12-4.核函数1
核函数,用于产生新的特征,是特征映射。
P74 12-5.核函数2

给予m个样本,输入x是一个n维的向量,使用此核函数后,每个核函数对应一个样本。

C大, 1 λ \frac{1}{\lambda} λ1 小,趋于unfitting;
C小, 1 λ \frac{1}{\lambda} λ1 大,趋于overfitting;
P75 12-6.使用SVM
使用normalization技巧。
P76 13-1.无监督学习
P77 13-2.K-Means算法

第一个子循环,将样本分类;
第二个子循环,寻找每个类别的新中心。
P78 13-3.优化目标
P79 13-4.随机初始化
k在2-4左右,比较小的时候,随机初始化才会有比较大的影响。
P80 13-5.选取聚类数量
P81 14-1.目标.I:数据压缩
P82 14-2.目标.II:可视化
P83 14-3.主成分分析问题规划1
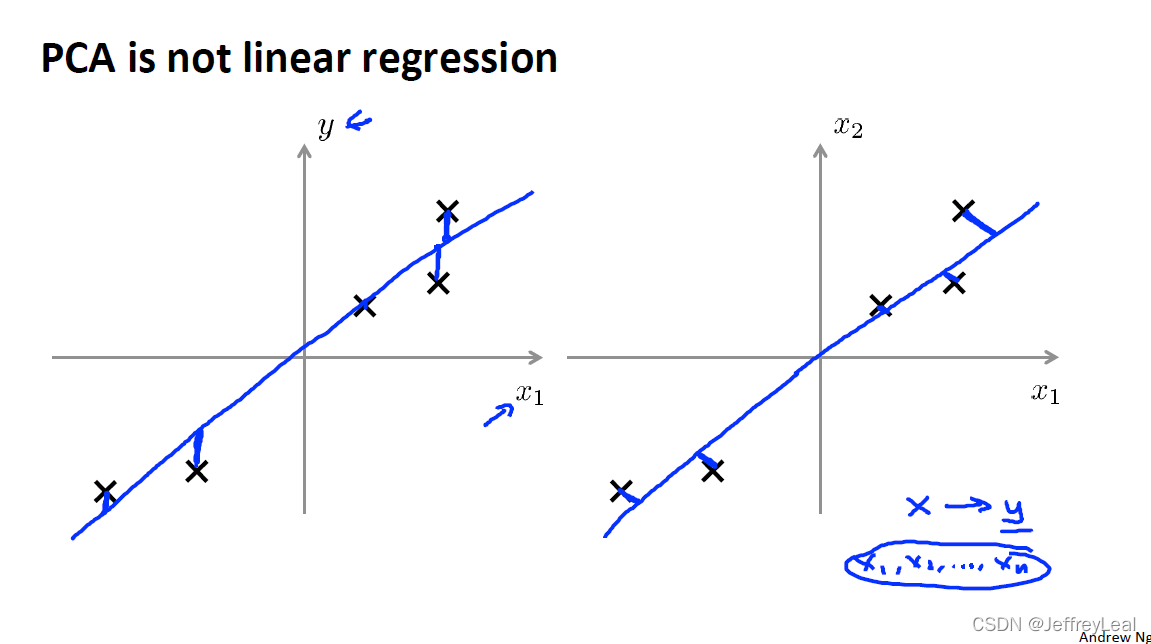
左边是 linear regression,右边是 PCA。
P84 14-4.主成分分析问题规划2
P85 14-5.主成分数量选择

保留90%的能量、信息。
计算S矩阵的能量即可。
P86 14-6.压缩重现
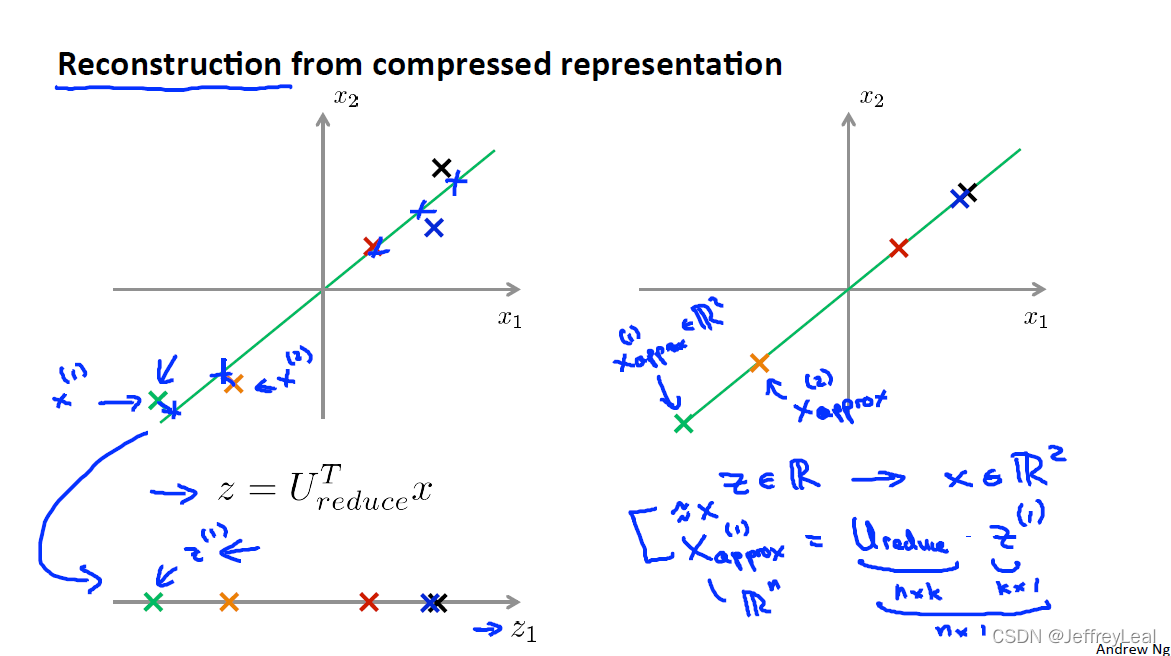
左边是压缩,右边是解压。
P87 14-7.应用.PCA.的建议
- 先用PCA降维,再输入到其他算法。
- 特征数远大于样本数时,很容易过拟合,PCA可降维,减少过拟合,但这不是推荐的减少过拟合的方法。正则化才比较推荐。
P88 15-1.问题动机
P89 15-2.高斯分布
P90 15-3.算法

异常数据监测算法。
P91 15-4.开发和评估异常检测系统
P92 15-5.异常检测.VS.监督学习

正负样例极度不平均
P93 15-6.选择要使用的功能
变成高斯去检测。
P94 15-7.多变量高斯分布
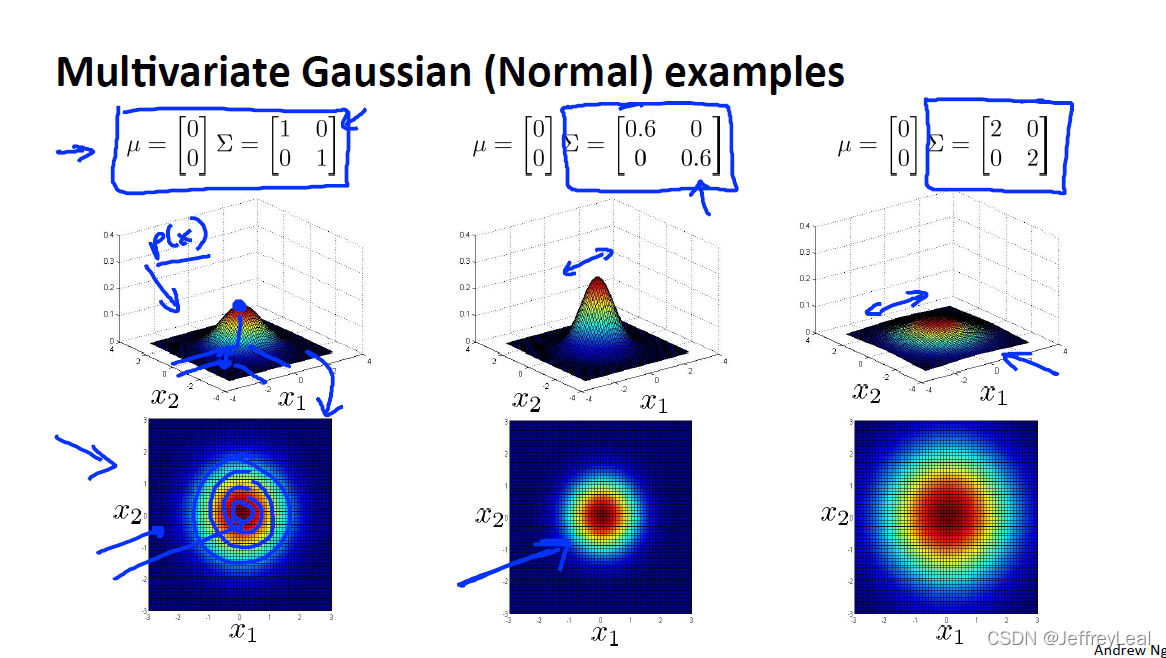
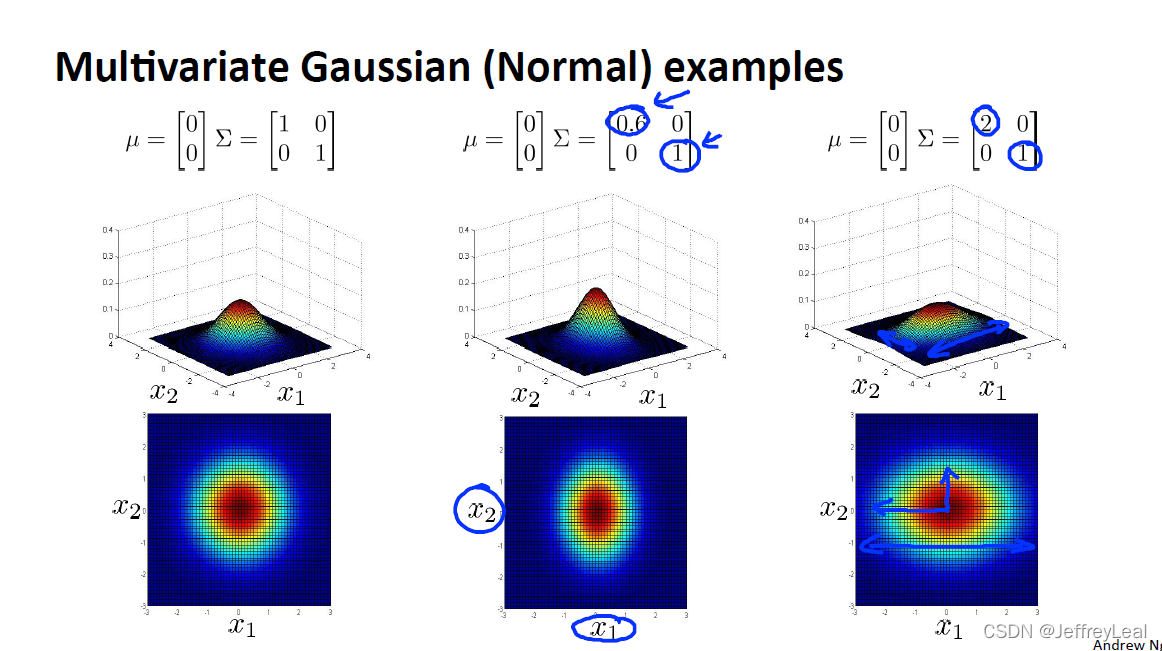
不同方差的高斯形状。
P95 15-8.使用多变量高斯分布的异常检测


左边是圆,右边是椭圆。
左边自己设计,右边自动捕捉特征。
右边 Σ \Sigma Σ矩阵要是奇异的,说明有冗余特征。
P96 16-1.问题规划
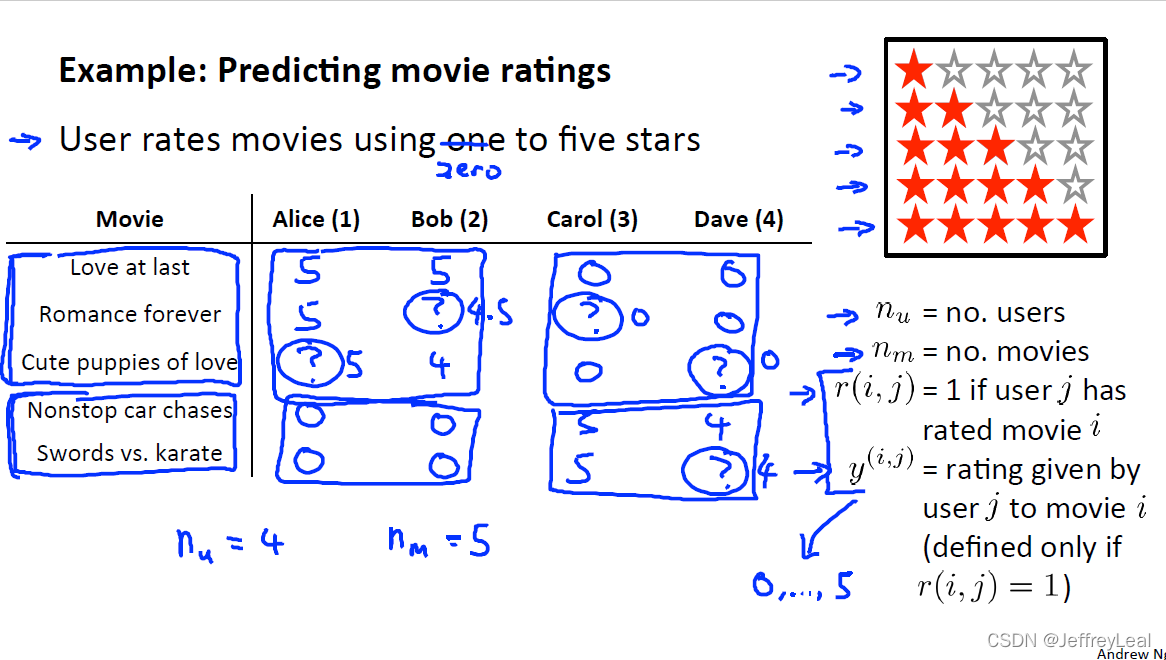
用户可能只对部分电影有评分,造成难以推荐的问题。
P97 16-2.基于内容的推荐算法
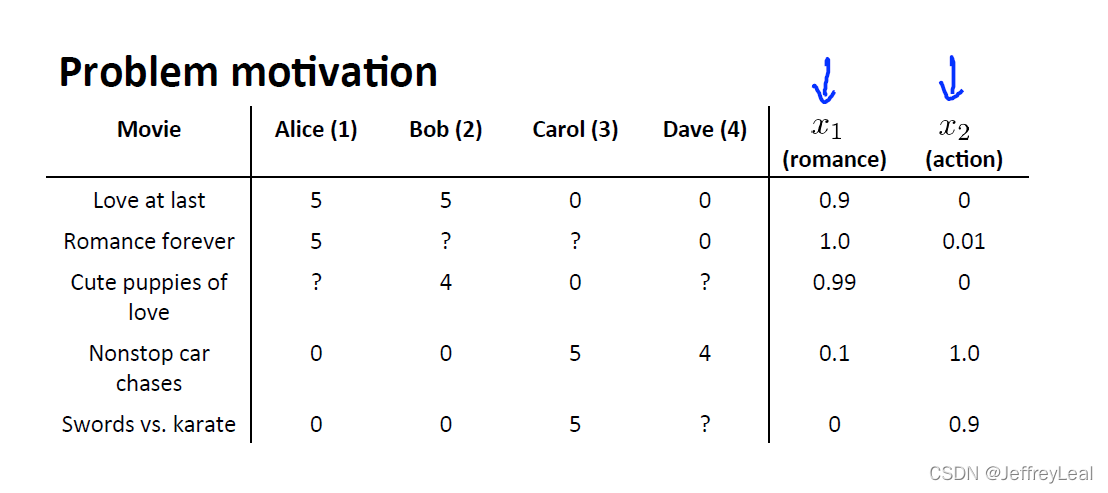
以一部电影的爱情部分,动作部分等作为特征,用户就不用所有电影都看了。
P98 16-3.协同过滤
如果没有人告诉我们每部电影的各种成分占比是多少,使用上面算法就很困难。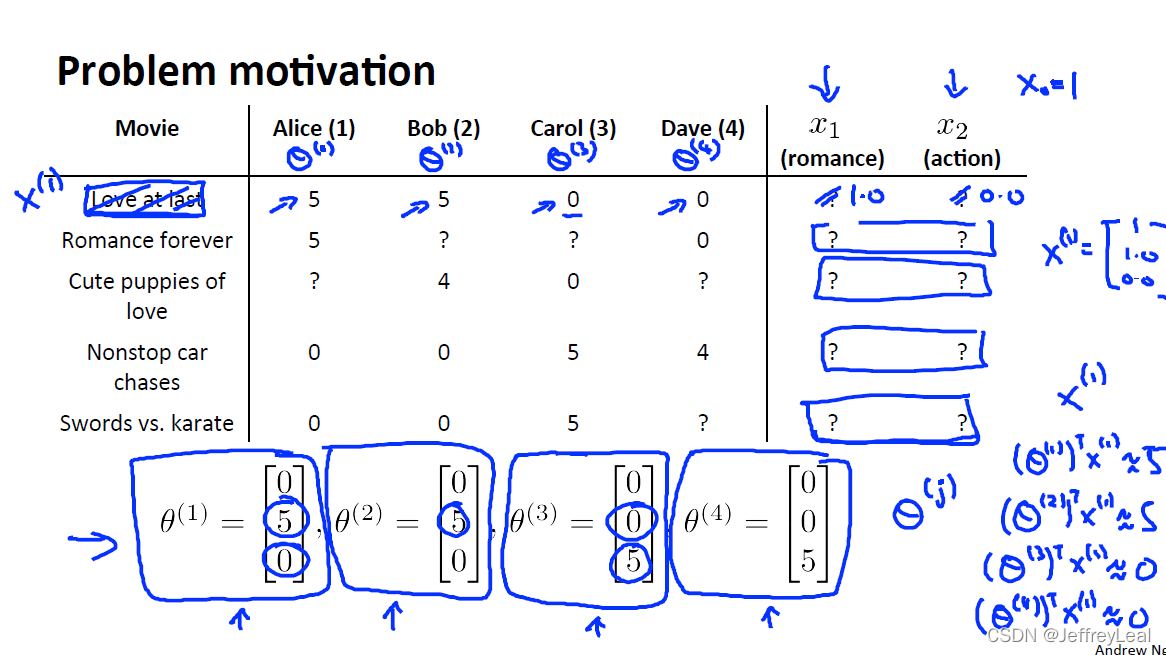
根据用户的喜好 θ \theta θ与他们看共同看过的电影,预测电影的特征。

用户喜好预测电影特征,电影特征预测用户喜好,不断迭代就会收敛。
P99 16-4.协同过滤算法
P100 16-5.矢量化:低轶矩阵分解
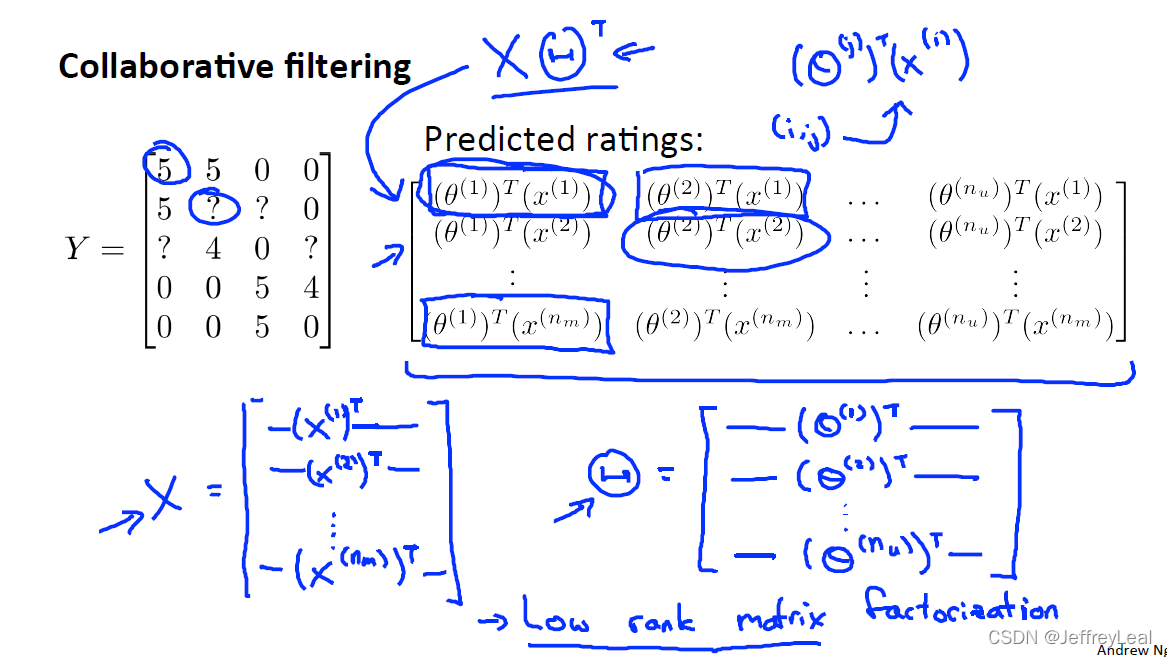
协同过滤算法,用到低轶矩阵分解。
P101 16-6.实施细节:均值规范化
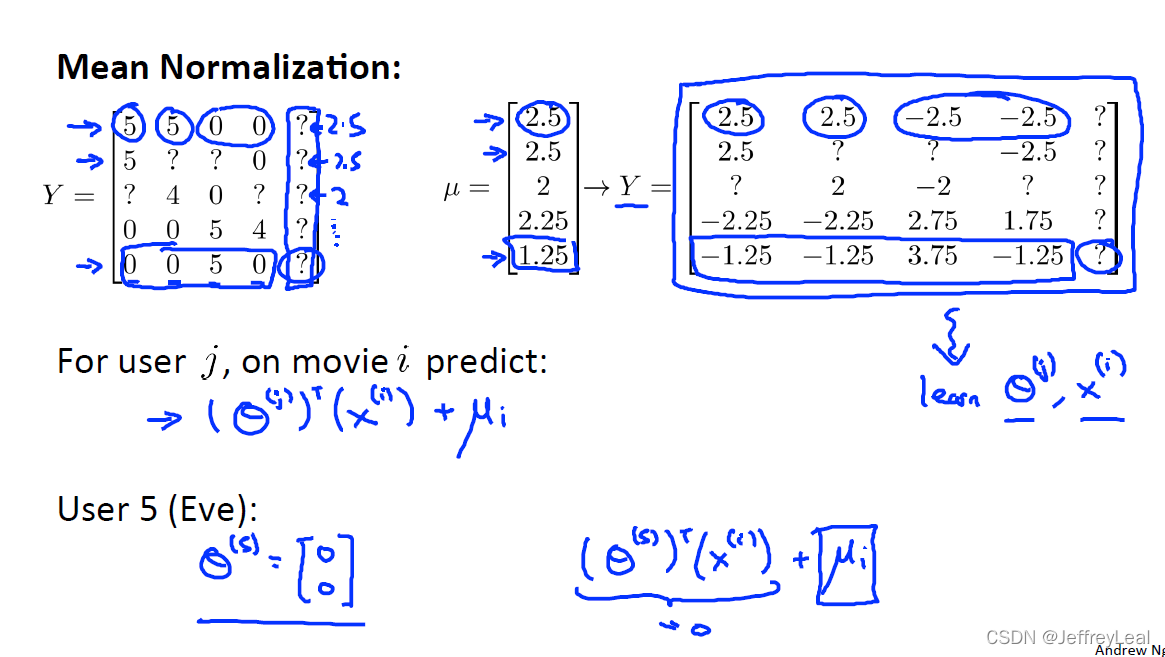
没有评分的,最后会给他推荐大众喜欢的,平均值。
P102 17-1.学习大数据集
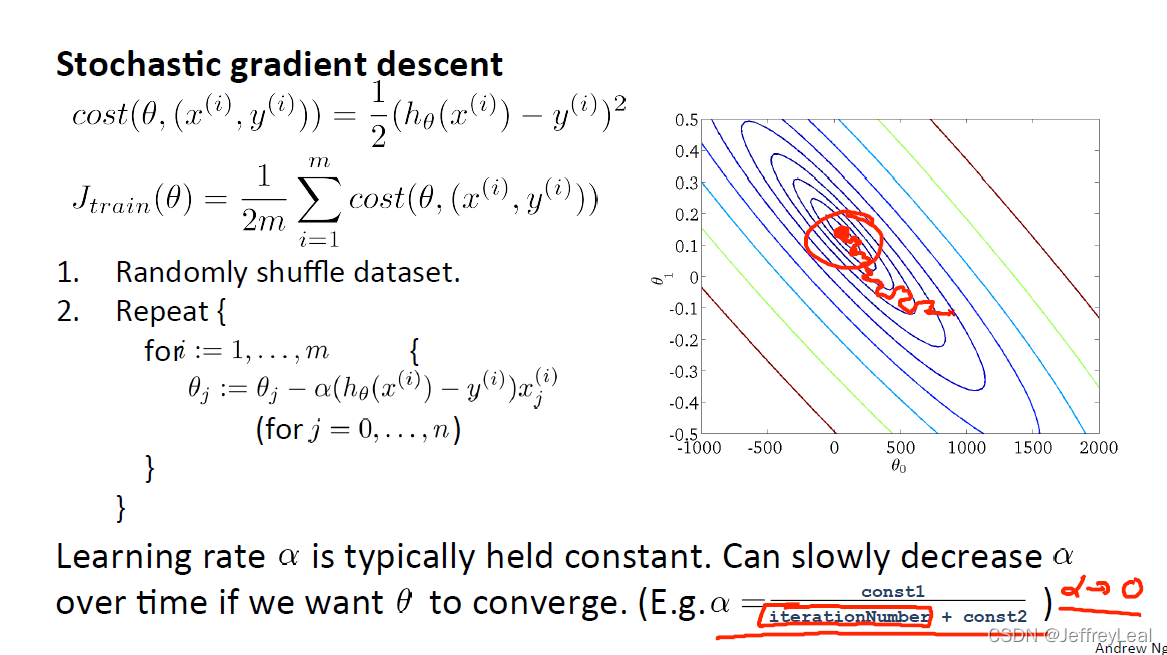
P103 17-2.随机梯度下降
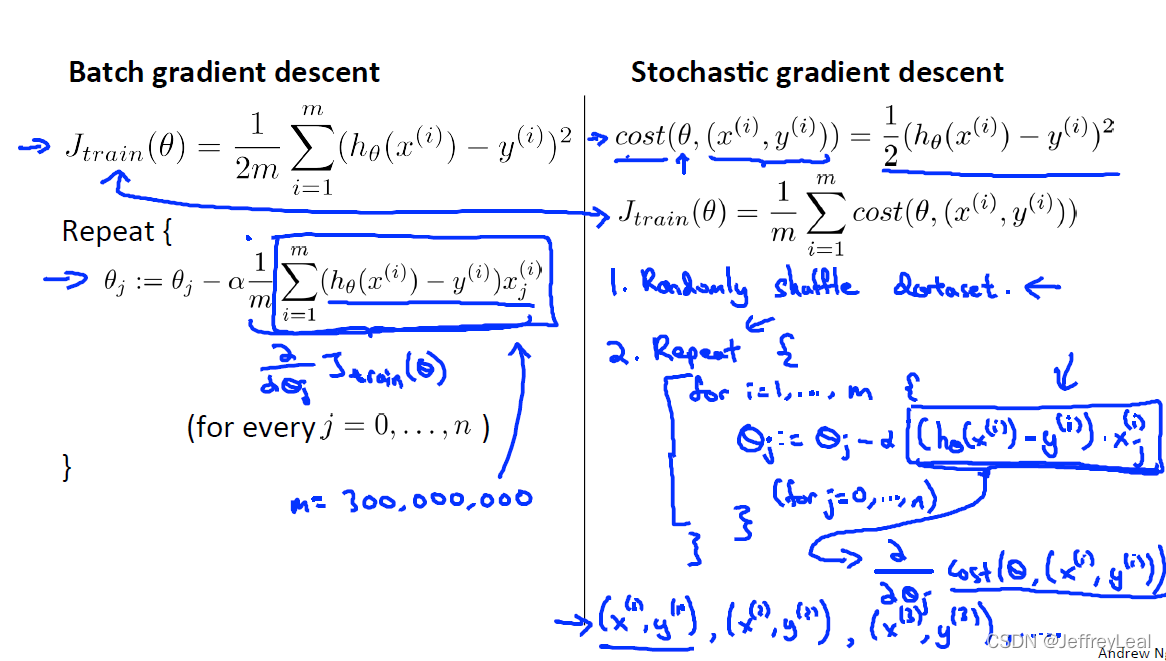
左边是计算全部数据集的梯度,右边是计算单个数据的梯度。
P104 17-3.Mini-Batch.梯度下降

batch:全部数据;
stochastic:单个数据;
mini-batch:一小批数据。
P105 17-4.随机梯度下降收敛
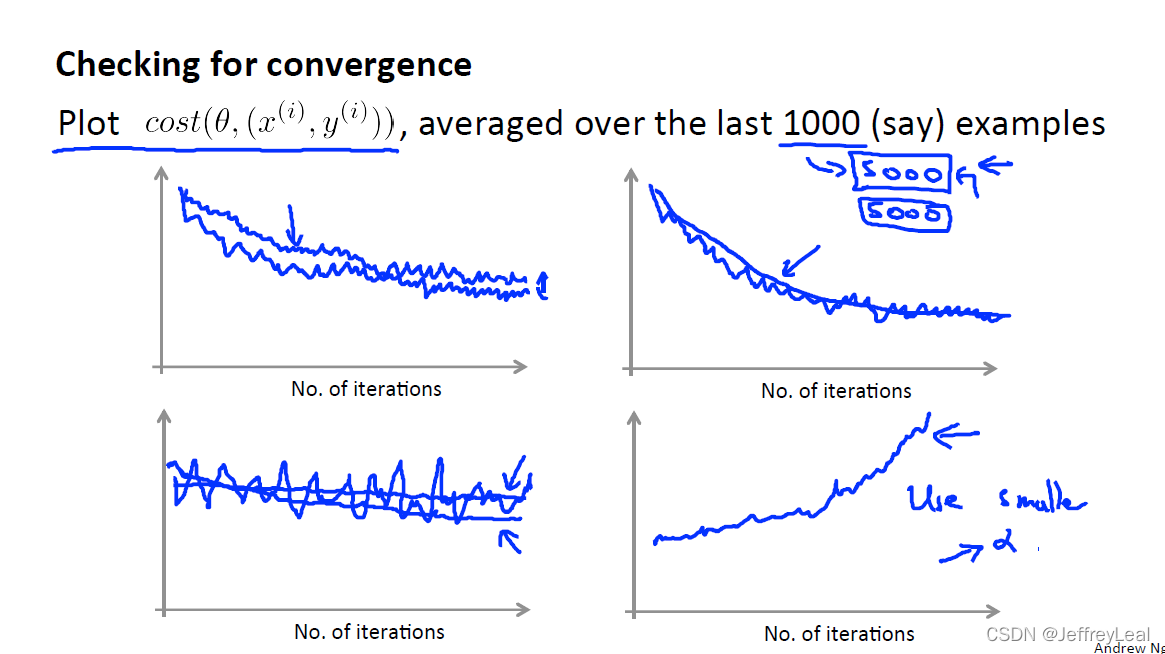
纵轴是一堆样例的平均损失:
图(1,1)波动小的线使用更小的学习率;
图(1,2)更平滑的线使用更大的mini-batch;
图(2,1)波动大的线使用很少的样例;
图(2,2)发散,应该使用更小的学习率;
学习率也衰减。
P106 17-5.在线学习
不断使用在线用户的数据来学习,而不是使用固定的数据集。
P107 17-6.减少映射与数据并行
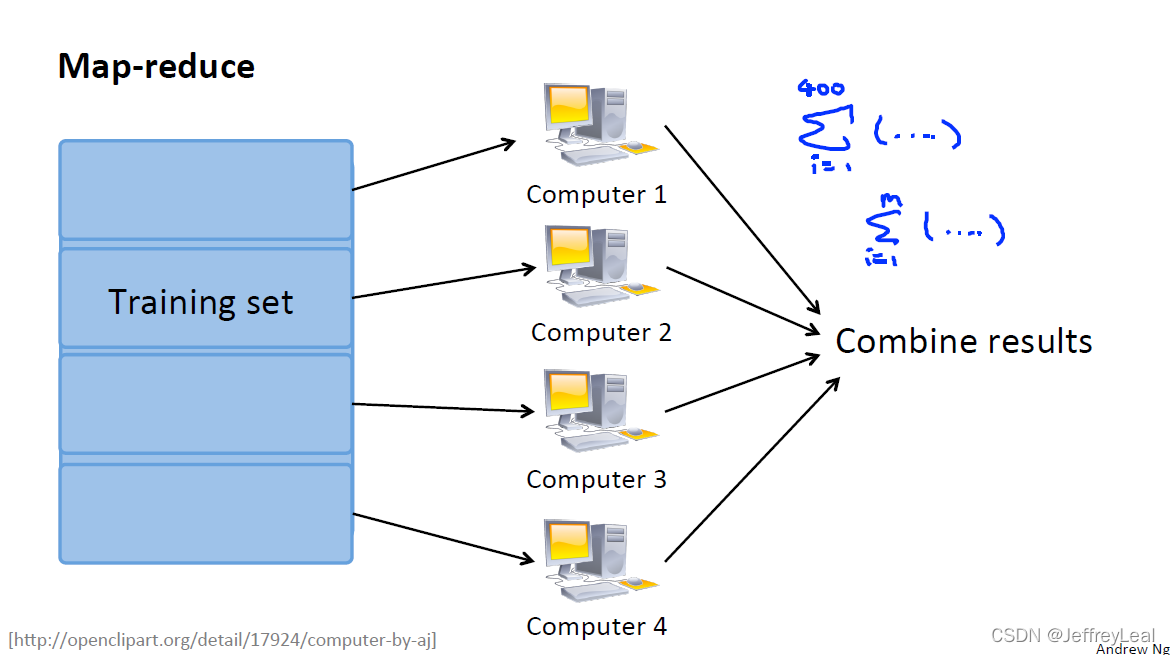
把数据集分成多个,计算后结果汇总,再更新参数。
P108 18-1.问题描述与.OCR.pipeline

P109 18-2.滑动窗口

使用滑动窗口去检测。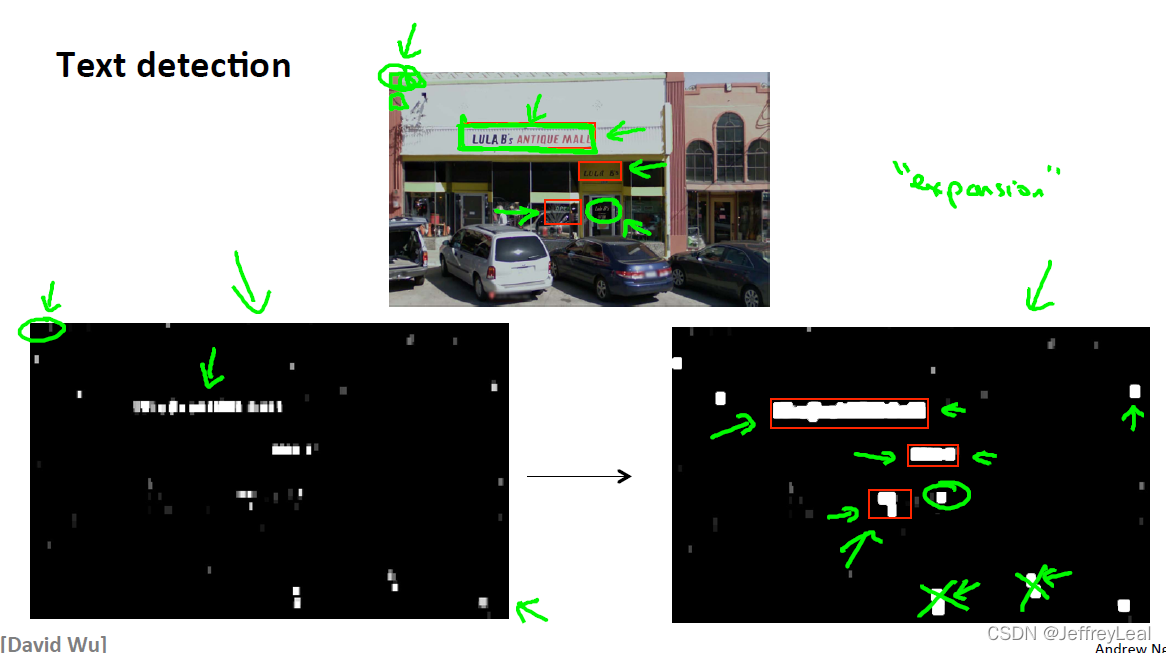
分割字符: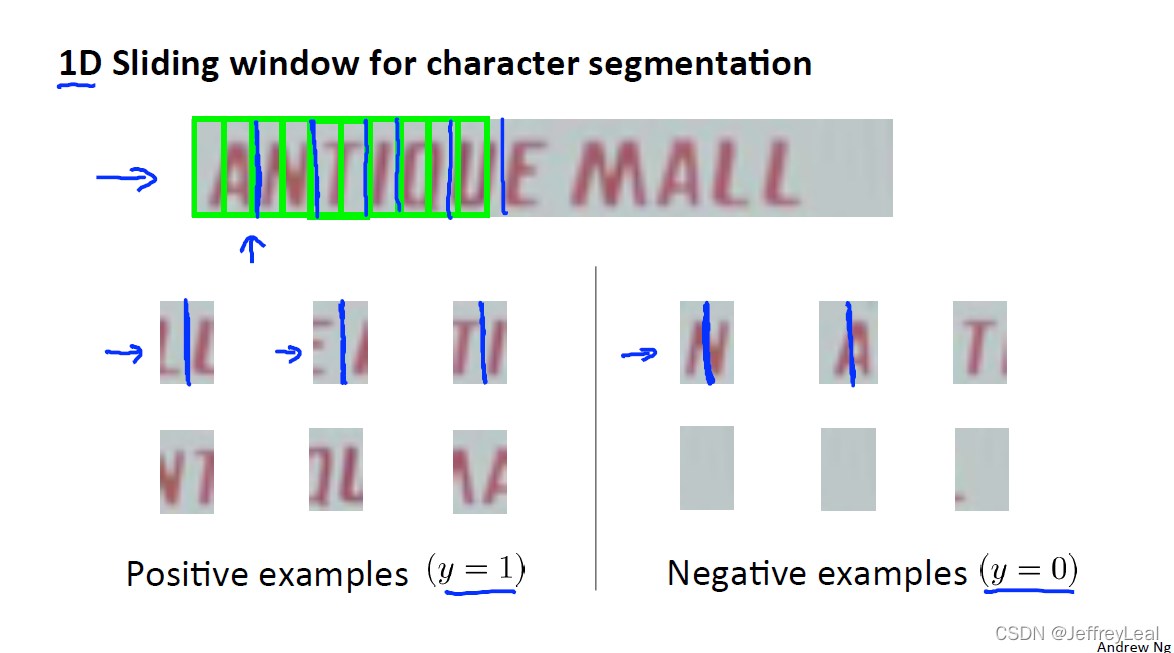
P110 18-3.获取大量数据和人工数据
对原始图片进行仿射,即旋转和拉伸。
对原始音频添加不同的失真与背景声音。
P111 18-4.天花板分析:下一步工作的.pipeline
把资源集中在对整个系统提升最大的那个部分。即使是吴恩达,也不能靠直接分析把精力投入到哪个模块,而是要做上限分析。
P112 19-1.总结与感谢

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)