python散点图形状_Python 机器学习散点图
随机数据分布在机器学习中,数据集可以包含成千上万甚至数百万个值。测试算法时,您可能没有真实的数据,您可能必须使用随机生成的值。正如我们在上一章中学到的那样,NumPy模块可以帮助我们!让我们创建两个数组,它们都填充有正常数据分布中的1000个随机数。第一个数组的平均值设置为5.0,标准差为1.0。第二个数组的平均值设置为10.0,标准差为2.0:有1000个点的散点图:import numpyim
·
随机数据分布
在机器学习中,数据集可以包含成千上万甚至数百万个值。测试算法时,您可能没有真实的数据,您可能必须使用随机生成的值。正如我们在上一章中学到的那样,NumPy模块可以帮助我们!让我们创建两个数组,它们都填充有正常数据分布中的1000个随机数。第一个数组的平均值设置为5.0,标准差为1.0。第二个数组的平均值设置为10.0,标准差为2.0:
有1000个点的散点图:
import numpy
import matplotlib.pyplot as plt
x = numpy.random.normal(5.0, 1.0, 1000)
y = numpy.random.normal(10.0, 2.0, 1000)
plt.scatter(x, y)
plt.show()
输出如下所示:
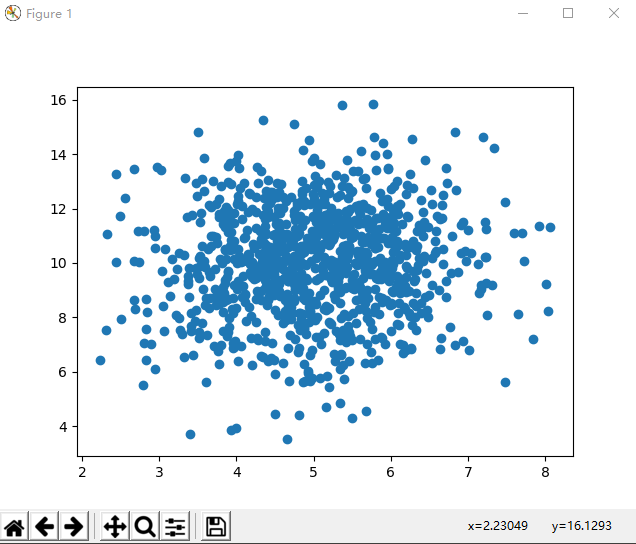
散点图解释::
我们可以看到,点集中在x轴上的值5和y轴上的10周围。我们还可以看到,在y轴上的扩散比在x轴上的扩散大。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)