pytorch深度学习bug集合
1、出现下面错误说明网络中有多个线程,线程间出现问题解决办法,在main入口处代码第一行 加入以下代码:if __name__=='__main__':torch.multiprocessing.set_start_method('spawn') # 在main第一行加入这行代码即可....................
1、出现下面错误说明网络中有多个线程,线程间出现问题
解决办法,在main入口处代码第一行 加入以下代码:
if __name__=='__main__':
torch.multiprocessing.set_start_method('spawn') # 在main第一行加入这行代码即可
.....
再次出现以下错误:

说明有些数据在cpu上,而有些在gpu上 ,发现有一个变量经过torch.Tensor变换后,没有转移到cuda上,所以加上to(device),代码运行成功!!
rank_score_norm = torch.Tensor(rank_score_norm).to(device)2、梯度出现问题,在优化器梯度回传时候,出现以下错误,就是
即在代码第17行:param.grad.data.即param.grad=None
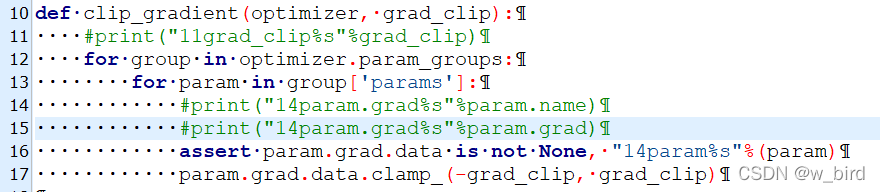
那么我们就打印参数,看看哪些参数梯度为None:
在loss.backward()之后加入以下代码,打印参数名称以及对应的grad,并且将grad is None的参数名称打印出来:
for name, param in model.named_parameters():
print(name, ' ', param.grad)
if param.grad is None :
print(name,' ',param.grad)果不其然,打印出一堆None:
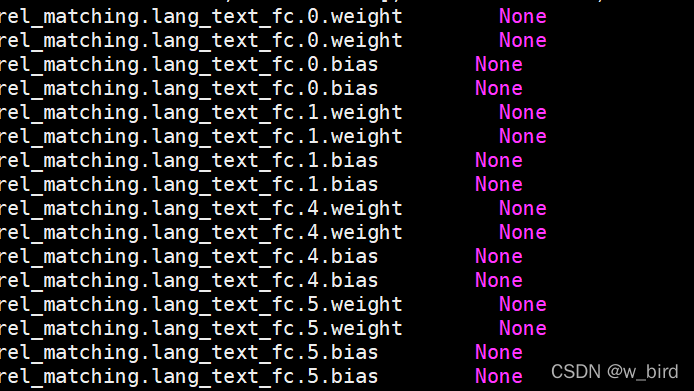
然后去找relationmatch对应部分的参数的问题,其实都是rel_matching这个模块对应的lang_text_fc层出现了问题,就是定义了fc层,也进行了前向传播,但是最后因为疏忽没有使用这个网络层!
3、加载model_pth时候出现以下问题,原因是模型原来在cuda3上(在服务器A上训练的),但是现在的服务器上(服务器B)只有2个cuda,因此运行代码提示:用map_location将cuda映射到当前的显卡上面
更改如下:
device=torch.device('cuda',gpu_id)
#predictor.load_state_dict(torch.load(model_path))错误代码
predictor.load_state_dict(torch.load(model_path,map_location=device))#正确4、在pytorch里面计算两个变量的加法时候,出现以下错误,说明两个变量类型不统一
去debug,发现一个是float32 一个是64
print("dtype1%s"%(rpn_score1.dtype))
# rpn_score1 is numpy ndarray的类型, .dtype看其数据类型,打印出来是float64
print("dtype2%s"%(rpn_score2.dtype))
# rpn_score2 is torch.Tensor .dtype看其数据类型,打印出来是float32将float64转为float32,再转为cuda(Tensor)
rpn_score1=torch.from_numpy(rpn_score1.astype(np.float32)).to(device)git提交或克隆报错fatal: unable to access ‘https://github.com/tata20191003/autowrite.git/‘: Failed to connec
复制一个大佬的评论解决了问题:产生原因:一般是这是因为服务器的SSL证书没有经过第三方机构的签署,所以才报错
解决方法:
git config --global http.sslVerify "false"
GIT推送错误error: RPC failed; curl 92 HTTP/2 stream 0 was not closed cleanly: CANCEL (err 8)
解决方法:
方法一:将git 远程地址改为自己的ssh地址
git remote set-url origin git@github.com:github用户名/仓库名.git
方法二:增加git缓冲区大小(我用了这个)
git config --global http.postBuffer 524288000
torch.load函数加载预训练参数时出现以下错误:NotImplementedError()。定位错误的code
File "/home/wangjing/code/InternVideo/Downstream/Video-Text-Retrieval/modules/clip_evl/clip.py", line 153, in load
init_state_dict = torch.load(model_path, map_location='cpu')['state_dict']
File "/home/wangjing/anaconda3/envs/TVP/lib/python3.9/site-packages/torch/jit/_script.py", line 810, in __getitem__
return self.forward_magic_method("__getitem__", idx)
File "/home/wangjing/anaconda3/envs/TVP/lib/python3.9/site-packages/torch/jit/_script.py", line 803, in forward_magic_method
raise NotImplementedError()
发现不取[state_dict]时不报错
init_state_dict = torch.load(model_path, map_location='cpu')['state_dict']将上述代码换为下面的,可以正确运行,猜测是python版本问题。
init_state_dict = torch.load(model_path, map_location='cpu').state_dict()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)