《自然语言处理-基于预训练模型的方法》第7章 预训练语言模型
第7章 预训练语言模型7.1 概述微调: 让模型从海量数据中充分学习如何从数据中提取特征。然后,会根据具体的目标任务,使用相应的领域数据精调,使模型进一步“靠近”目标任务的应用场景,起到领域适配和任务适配的作用。预训练语言模型具有“三大”特点——大数据、大模型和大算力。7.2 GPTGPT提出了“生成式预训练+判别式任务精调”的自然语言处理新范式,生成式预训练:在大规模文本数据上训练一个高容量的语
第7章 预训练语言模型
7.1 概述
微调: 让模型从海量数据中充分学习如何从数据中提取特征。然后,会根据具体的目标任务,使用相应的领域数据精调,使模型进一步“靠近”目标任务的应用场景,起到领域适配和任务适配的作用。
预训练语言模型具有 三大 特点
- 大数据 数据处理投入和数据质量之间做出权衡。
- 大模型 较高的并行程度,能够捕获构建上下文信息。
- 大算力 GPU TPU
7.2 GPT
GPT提出了 “生成式预训练+判别式任务精调” 的自然语言处理新范式,
- 生成式预训练:在大规模文本数据上训练一个高容量的语言模型,从而学习更加丰富的上下文信息;
- 判别式任务精调:将预训练好的模型适配到下游任务中,并使用有标注数据学习判别式任务。
7.2.1 无监督预训练
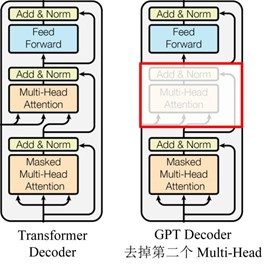
GPT的整体结构是一个基于Transformer的单向语言模型(只有Decoder层,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention),即从左至右对输入文本建模,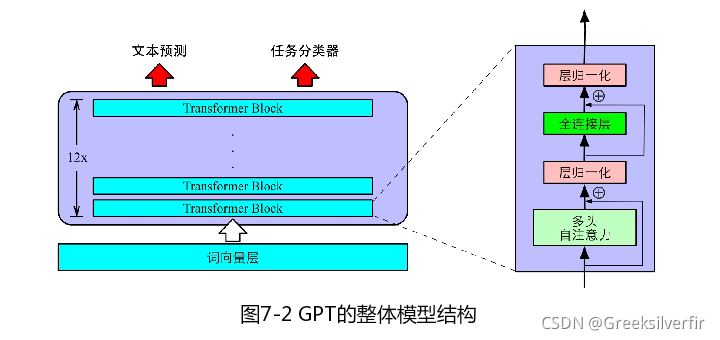
- 训练任务:文本序列x=x1...xnx=x_1...x_nx=x1...xn的最大似然估计LPTL^PTLPT
LPT(x)=∑ilogP(xi∣xx−k...xi−1;θ)L^{PT}(x)=\sum_{i}logP(x_i|x_{x-k}...x_{i-1};\theta)LPT(x)=i∑logP(xi∣xx−k...xi−1;θ)
k表示窗口大小,基于K个历史次xi−k...xi−1x_{i-k}...x_{i-1}xi−k...xi−1预测当前时刻的词xix_ixi。
h[0]=ex′We+Wph^{[0]}=e_{x'}W^e+W^ph[0]=ex′We+Wp
h[l]=Transformer−Block(h[l−1])任意l∈1,2,...,Lh^{[l]}=Transformer-Block(h^{[l-1]}) 任意 l\in{1,2,...,L}h[l]=Transformer−Block(h[l−1])任意l∈1,2,...,L
P(x)=Sofrmax(h[l]WEt)P(x)=Sofrmax(h^{[l]}W^{E^t})P(x)=Sofrmax(h[l]WEt)
其中ex′∈Rk×∣V∣e_{x'}\in R^{k \times |V|}ex′∈Rk×∣V∣ 表示 x′x'x′ 的独热向量表示,We∈R∣V∣×dW^e\in R^{|V| \times d}We∈R∣V∣×d表示词向量矩阵;Wp∈Rn×dW^p\in R^{n \times d}Wp∈Rn×d 表示位置向量矩阵;L表示Transformer的总层数。
与ELMO的区别:
- 特征抽取器不是用的 RNN,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN,这个选择很明显是很明智的;
- ELMO使用上下文对单词进行预测,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
7.2.2 有监督下游任务精调
- 精调(Fine-tuning) 的目的是在通用语义表示的基础上,根据 下游任务(Downstream task) 的特性进行领域适配。
- 如下游带标注的数据,输入预训练GPT中,获取最后一层的最后一个词对应的隐含层输出hn[L]h^{[L]}_nhn[L]
P(y∣x1...xn)=Softmax(h[L]Wy)P(y|x_1...x_n)=Softmax(h^{[L]}W^y)P(y∣x1...xn)=Softmax(h[L]Wy)
最终优化损失函数:
LPT(C)=∑(x,y)logP(y∣x1...xn)L^{PT}(C)=\sum_{(x,y)}logP(y|x_1...x_n)LPT(C)=(x,y)∑logP(y∣x1...xn)
其中Wy∈Rd×kW^y\in R^{d \times k}Wy∈Rd×k表示全连接权重,k表示标签个数。
- 灾难性遗忘。 下游任务精调回到预训练学习的部分知识覆盖或擦除,丢失一定通用性,在实际中采用:
L(C)=LFT(C)+λLPT(C)L(C)=L^{FT}(C)+\lambda L^{PT}(C)L(C)=LFT(C)+λLPT(C)
其中LFTL^{FT}LFT表示精调任务损失,LPTL^{PT}LPT表示预训练任务损失 (自回归交叉熵损失值),λ\lambdaλ表示权重,在实际应用中λ=0.5\lambda =0.5λ=0.5
7.2.3 适配不同的下游任务
自然语言处理中几种典型的任务在GPT中的输入输出形式.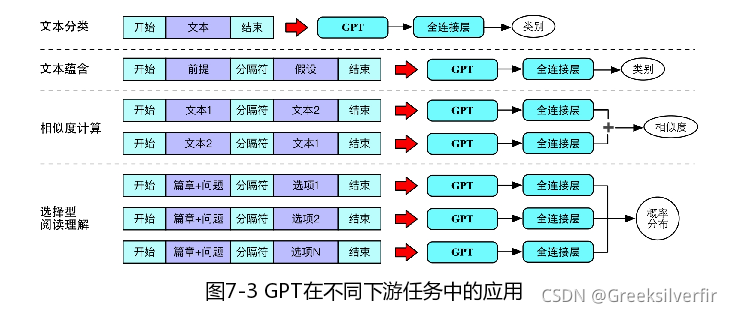
(1)单据文本分类
其输入是单个文本构成,输出由对应的分裂标签构成,假定输入为x=x1...xnx=x_1...x_nx=x1...xn,则喂给GPT的输入为:
<s>x1x2..xn<e><s>x_1x_2..x_n<e><s>x1x2..xn<e>
其中<s><s><s>为开始标记,<e><e><e>为结束标记
(2)文本蕴含(是否下一句)
输入是两段文本构建,输入为分类标签构成(0,1),即输入给GPT形式为
<s>x1(1)x2(1)..xn(1)$x1(2)x2(2)..xm(2)<e><s>x^{(1)}_1x^{(1)}_2..x^{(1)}_n \$ x^{(2)}_1x^{(2)}_2..x^{(2)}_m<e><s>x1(1)x2(1)..xn(1)$x1(2)x2(2)..xm(2)<e>
使用 $ 符号进行分割标记。n和m分别表示x(1)x^{(1)}x(1)和x(2)x^{(2)}x(2)的长度。
(3)相似度计算
相似度即判断两个文本之间的相似程度,是一个概率值:
<s>x1(1)x2(1)..xn(1)$x1(2)x2(2)..xm(2)<e><s>x^{(1)}_1x^{(1)}_2..x^{(1)}_n\$x^{(2)}_1x^{(2)}_2..x^{(2)}_m<e><s>x1(1)x2(1)..xn(1)$x1(2)x2(2)..xm(2)<e>
<s>x1(2)x2(2)..xm(2)$x1(1)x2(1)..xn(1)<e><s>x^{(2)}_1x^{(2)}_2..x^{(2)}_m\$x^{(1)}_1x^{(1)}_2..x^{(1)}_n<e><s>x1(2)x2(2)..xm(2)$x1(1)x2(1)..xn(1)<e>
(4)选择性阅读理解
即让机器阅读一篇文章,并从多个选项中选择出正确的正确选项。即需要将<篇章,问题,选项>作为输入,以正确的选项编号作为标签。假设篇章为p=p1p2...pnp=p_1p_2...p_np=p1p2...pn,问题为q=q1q2...qmq=q_1q_2...q_mq=q1q2...qm,第i个选项为c(i)=c1(i)c2(i)...ck(i)c^{(i)}=c^{(i)}_1c^{(i)}_2...c^{(i)}_kc(i)=c1(i)c2(i)...ck(i),并假设N为选项个数,并通过如下输入GPT中。
<s>p=p1p2...pn$q1q2...qm$c1(1)c2(1)...ck(1)<e><s>p=p_1p_2...p_n\$q_1q_2...q_m \$ c^{(1)}_1c^{(1)}_2...c^{(1)}_k<e><s>p=p1p2...pn$q1q2...qm$c1(1)c2(1)...ck(1)<e>
<s>p=p1p2...pn$q1q2...qm$c1(2)c2(2)...ck(2)<e><s>p=p_1p_2...p_n\$q_1q_2...q_m \$ c^{(2)}_1c^{(2)}_2...c^{(2)}_k<e><s>p=p1p2...pn$q1q2...qm$c1(2)c2(2)...ck(2)<e>
‘’’
<s>p=p1p2...pn$q1q2...qm$c1(N)c2(N)...ck(N)<e><s>p=p_1p_2...p_n\$q_1q_2...q_m \$ c^{(N)}_1c^{(N)}_2...c^{(N)}_k<e><s>p=p1p2...pn$q1q2...qm$c1(N)c2(N)...ck(N)<e>
将〈篇章,问题,选项〉作为输入,通过GPT建模得到对应的隐含层表示,并通过全连接层得到每个选项的得分。最终,将N个选项的得分拼接,通过Softmax函数得到归一化的概率(单选题),并通过交叉熵损失函数学习。
7.3 BERT
7.3.1 整体结构
BERT的基本模型结构由多层Transformer构成,包含两个预训练任务:
- 掩码语言模型(Masked Language Model,MLM)
- 下一个句子预测(Next Sentence Prediction,NSP)
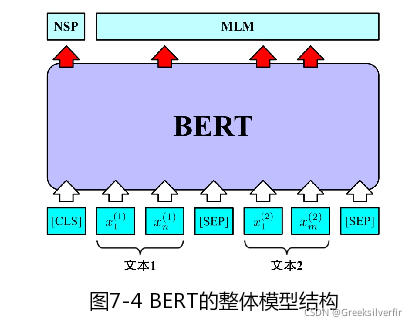
如上图所示,bert的输入是由两段文本构成,而实际上MLM任务不要求输入为两段文本,而下一句预测要求为2段文本,所以bert统一两段文本作为输入建模。
7.3.2 输入表示
Bert的输入由三个块组成
- 词向量(Token Embeddings)
- 块向量(Segment Embeddings)
- 位置向量(Position Embeddings)
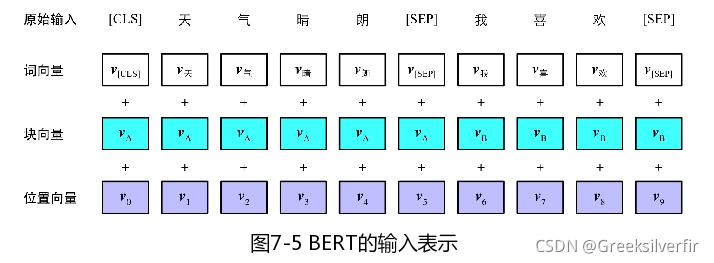
(1)词向量。与传统神经网络模型类似,都是通过词的独热编码乘以词向量矩阵。即
vt=etWtv^t=e^tW^tvt=etWt
式中,Wt∈R∣V∣×cW^t\in R^{|V| \times c}Wt∈R∣V∣×c表示可训练的词向量矩阵,|V|表示此表大小,e表示词向量维度
(2)块向量。块向量用来编码当前词属于那一块。
- 单句文本分类,所有词快编码都为0
- 句对文本相似度时,第一个句子块编码为0,第二个为1,(CLS 和一个句子结尾SEP 快编码也为0)
vs=esWsv^s=e^sW^svs=esWs
式中,Ws∈R∣S∣×cW^s\in R^{|S| \times c}Ws∈R∣S∣×c表示可训练的块向量矩阵,|S|表示块数量,e表示块向量维度
(3)位置向量,用来编码每个词的绝对位置,每个词按照下表顺序一次转换为位置独热编码。
vp=epWpv^p=e^pW^pvp=epWp
式中,Wp∈R∣N∣×cW^p\in R^{|N| \times c}Wp∈R∣N∣×c表示可训练的位置向量矩阵,|N|表示最大位置长度,e表示位置向量维度。
最后输入的形式为:
X=[CLS]x1(1)x2(1)...xn(1)[SEP]x1(2)x2(2)...xm(2)[SEP]X=[CLS]x^{(1)}_1x^{(1)}_2...x^{(1)}_n[SEP]x^{(2)}_1x^{(2)}_2...x^{(2)}_m[SEP]X=[CLS]x1(1)x2(1)...xn(1)[SEP]x1(2)x2(2)...xm(2)[SEP]
7.3.3 基本预训练任务
与GPT不同的是,BERT并没有采用传统的基于自回归的语言建模方法,而是引入了基于自编码(Auto-Encoding)的预训练任务进行训练。
- 自回归的语言建模方法: 根据上文内容预测下一个可能跟随的单词,比如GPT模型,就是通过上文的内容进行预测下一个出现词,ELMO也是,虽然看上了利用了上文、也利用了下文,最后将上下文输出拼接,所以其本质也是一个自回归模型。
缺点: 只能利用上文或者下文不能同时利用上下文,ELMO虽然是使用了上下文,但是通过拼接的方式,效果其实也一般。
优点: 对于生成式的NLP任务有优势,比如文本摘要,机器翻译等,都是从左往右的形式。 - 自编码的语言建模方法 : 将句子中随机一个单词用[mask]替换掉,是不是就能同时根据该单词的上下文来预测该单词。我们都知道Bert在预训练阶段使用[mask]标记对句子中15%的单词进行随机屏蔽,然后根据被mask单词的上下文来预测该单词,
缺点: 就是在Fine-tune阶段,模型是看不到[mask]标记的,所以这就会带来一定的误差。XLNet将二者的上述优缺点做了一个完美的结合,
优点: 自编码语言模型能很自然的把上下文信息融合到模型中(Bert中的每个Transformer都能看到整句话的所有单词,等价于双向语言模型)。
1.掩码语言模型
传统的建模(逆序)会造成数据泄露的问题。
MLM预训练任务直接将输入文本中的部分单词掩码(Mask),并通过深层Transformer模型还原为原单词,从而避免了双向语言模型带来的信息泄露问题,迫使模型使用被掩码词周围的上下文信息还原掩码位置的词。
在BERT中,采用了15%的掩码比例,实际上人为引入的[MASK]在下游中不会出现,所以,采用:
- 以80%的概率替换为 [MASK]标记;
- 以10%的概率替换为词表中的任意一个随机词;
- 以10%的概率保持原词不变,即不替换。

(1)输入层。 假设原始输入文本为x1x2..xnx_1x_2..x_nx1x2..xn,通过上述掩码后输入为x1′x2′...xn′x^{'}_1x^{'}_2...x^{'}_nx1′x2′...xn′,所以bert的输入为:
X=[CLS]x1′x2′...xn′[SEP]X=[CLS]x^{'}_1x^{'}_2...x^{'}_n[SEP]X=[CLS]x1′x2′...xn′[SEP]
当小于bert的最大序列长度N时,需要使用[PAD]进行填充,如果大于则需要进行裁剪。长度为5
X=[CLS]x1′x2′[SEP][PAD][PAD][PAD]X=[CLS]x^{'}_1x^{'}_2[SEP][PAD][PAD][PAD]X=[CLS]x1′x2′[SEP][PAD][PAD][PAD]
X=[CLS]x1′x2′x3′x4′x5′[SEP]X=[CLS]x^{'}_1x^{'}_2x^{'}_3x^{'}_4x^{'}_5[SEP]X=[CLS]x1′x2′x3′x4′x5′[SEP]
(2) BERT 编码层。
h[l]=Transformer−Block(h[l−1])任意l∈1,2,...,Lh^{[l]}=Transformer-Block(h^{[l-1]}) 任意 l\in{1,2,...,L}h[l]=Transformer−Block(h[l−1])任意l∈1,2,...,L
通过L层之后最后输出为h[L]h^{[L]}h[L],通过上述方法最终得到文本上下文语义表示h∈RN×dh\in R^{N \times d }h∈RN×d,d为embedding的维度
(3)输出层。
预测已经掩码的位置(不需要预测全部)。在BERT中,由于输入表示维度e和隐含层维度d相同。
M=m1,m2,...mkM={m_1,m_2,...m_k}M=m1,m2,...mk表示掩码位置的下表。从Bert编码层的输出中,获取,该掩码位置的上下文语义表示,并将其拼接得到掩码表示:
hm∈Rk×dh^m \in R^{k \times d}hm∈Rk×d
这里我们得到m个掩码的上下文语义(也就是词向量)。
最后在通过一个全连接层,将词向量映射到词典的维度,即词向量矩阵Wt∈R∣V∣×eW^t\in R^{|V| \times e}Wt∈R∣V∣×e,将掩码表示映射到此表空间,所以该掩码位置对应此表上的概率分布为PiP_iPi.
Pi=Softmax(himWtT+b0)P_i=Softmax(h^m_i W^{t^T}+b^0)Pi=Softmax(himWtT+b0)
其中b0∈R∣V∣b^0 \in R^{|V|}b0∈R∣V∣表示全连接层 的偏执。
得到概率PiP_iPi,与标签yiy_iyi(原单词xix_ixi的独热向量)计算交叉熵损失,学习模型参数、
(4)代码实现。此处给出BERT原版的生成MLM训练数据的方法,
def create_masked_lm_predictions(tokens,masked_lm_prob,
max_predictions_per_seq,vocab_words,rng):
"""
此函数用于创建MLM任务的训练数据
:param tokens: 输入文本(这里的文本指的是分词后的文本,bert是wordpiece)
:param masked_lm_prob: 掩码语言模型的掩码概率
:param max_predictions_per_seq: 每个序列的最大预测数目
:param vocab_words: 词表列表
:param rng: 随机数生成器
:return:
"""
cand_indexes=[] # 存储可以参与掩码的token下标
for (i,token) in enumerate(tokens):
# 掩码时跳过[CLS] 和[SEP]
if token=='[CLS]' or token=='[SEP]':
continue
cand_indexes.append([i])
rng.shuffle(cand_indexes) # 随机打乱所有下标
output_tokens=list(tokens) # 存储掩码后的输入序列,初始化为原始输入
num_to_predict=min(max_predictions_per_seq, # 计算掩码数量(预测数目)
max(1,int(round(len(tokens)*masked_lm_prob))))
masked_lms=[] # 存储掩码实例
covered_indexes=set() # 存储已经处理过的下标
for index in cand_indexes: # 对参与掩码的所有进行遍历
if len(masked_lms)>=num_to_predict:
break
if index in covered_indexes:
continue
covered_indexes.add(index)
masked_token=None
if rng.random()<0.8: # 以80% 的概率替换为[MASK]
masked_token='[MASK]'
else:
if rng.random()<0.5: # 以10%的概率不进行任务替换
masked_token=tokens[index]
else: # 以10%的概率替换此表的随机词
masked_token=vocab_words[rng.randint(0,len(vocab_words)-1)]
output_tokens[index]=masked_token # 设置为被掩码的token
masked_lms.append(MaskedLmInstance(index=index,label=tokens[index]))
masked_lms=sorted(masked_lms,key=lambda x:x.index)# 按下标升序排序
masked_lm_positions=[] # 存储需要掩码的下标
masked_lm_label=[] # 存储掩码前的原词,即还原目标
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_label.append(p.label)
return (output_tokens,masked_lm_positions,masked_lm_label)
2.下一个句子预测
MLM预训练任务,可以让模型根据上下文还原掩码部分的词,从而学习到上下文敏感的文本表示,但是,对于阅读理解、文本蕴含,无法表示句子的前后关系。
所以,bert引入了第二个预训练任务-------下一句预测(NSP)任务
(1) 输入层,
X=<CLS>x1(1)x2(1)..xn(1)[SEP]x1(2)x2(2)..xm(2)[SEP]X=<CLS>x^{(1)}_1x^{(1)}_2..x^{(1)}_n[SEP]x^{(2)}_1x^{(2)}_2..x^{(2)}_m[SEP]X=<CLS>x1(1)x2(1)..xn(1)[SEP]x1(2)x2(2)..xm(2)[SEP]
v=InputRepresentation(X)v=InputRepresentation(X)v=InputRepresentation(X)
(2) bert编码层。与MLM任务的编码层一致。
h=Transformer−Block(v)h=Transformer-Block(v)h=Transformer−Block(v)
式中,h∈RN×dh \in R^{N \times d}h∈RN×d,其中N表示最大序列长度,d表示bert隐含层维度。
(3) 输出层。与MLM任务不同,只要判断x2x_2x2是否是x1x_1x1的下一句。所以使用[CLS]的隐含层表示进行预测。所以可以得到概率为P∈R2P\in R^2P∈R2,。
P=softmax(h0Wp+b0)P=softmax(h_0 W^p+b^0)P=softmax(h0Wp+b0)
式中,Wp∈Rd×2W^p \in R^{d \times 2}Wp∈Rd×2 表示全连接层的权重,b0∈R2b^0 \in R^2b0∈R2表示全连接层 的偏置。
最后将分类概率p与真是分类标签y计算交叉熵损失,学习模型参数。
为什么用[CLS] ?
BERT在第一句前会加一个[CLS]标志,最后一层该位对应向量可以作为整句话的语义表示,从而用于下游的分类任务等。(实际上也可以选择其他词作为输出表示整句话含义,但是与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。)
bert 模型最后的损失,是有MLM和下一句预测进行相加
7.3.4 更多预训练任务
1.整词掩码
WordPiece字词,对于英语来说,是单词的(子词,可以减少词典的大小,以及避免oov词),而对于中文来说是字,中文很多次都是一个词,如果以字为掩码,则很容易造成子词(词) 泄露问题。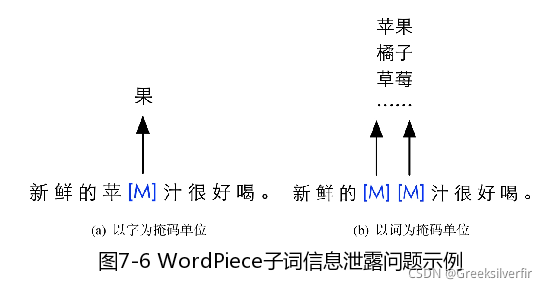
整词掩码(Whole Word Masking,WWM) 即最小掩码单位由WordPiece子词变为整词。构成单词“philammon”的所有子词“phil”“##am”和“##mon”都会被掩码(##为子词前缀标记)。
(1)正确理解整词掩码。
整词掩码中,当发生掩码操作时,
- 整词中的各个子词均会被掩码处理;
- 子词的掩码方式并不统一,并不是采用一样的掩码方式(三选一);
- 子词各自的掩码方式受概率控制。
如下图,tree,被分成tr ##ee 。
(2)中文整词掩码。
步骤,使用LTP工具对中文进行分词,掩码最小单位由字变为词。整词掩码。
2.N-gram掩码
N-gram掩码(N-gram Masking,NM)语言模型,顾名思义就是将连续的N-gram文本进行掩码,并要求模型还原缺失内容。需要注意的是,与整词掩码类似,N-gram掩码语言模型仅对掩码过程有影响(即只会影响选择掩码位置的过程),但仍然使用经过WordPiece分词后的序列作为模型输入。
- 根据掩码概率确定当前标记(token)是否应该被掩码
- 选定为掩码后,由于连续的N-gram必定会导致长文本丢失,最大短语长度为4-gram,所以对,unigram采用40%的概率,对于4-gram采用10%的概率。
- 对该标记及其之后N-1个标记进行掩码,不足N-1个标记时,以词边界截断。
- 掩码完毕后,跳过该N-gram,并对下一个候选标记进行掩码判断。
3.三种掩码策略的区别
掩码语言模型(MLM)、整词掩码(WWM)和N-gram掩码(NM)的联系和区别。
三种掩码策略仅影响模型的预训练阶段,而对于下游任务精调是透明的。
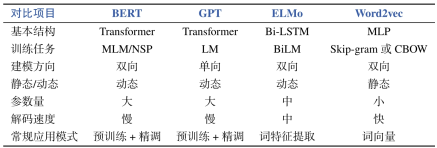
7.3.5 模型对比
7.4 预训练语言模型的应用
7.4.1 概述
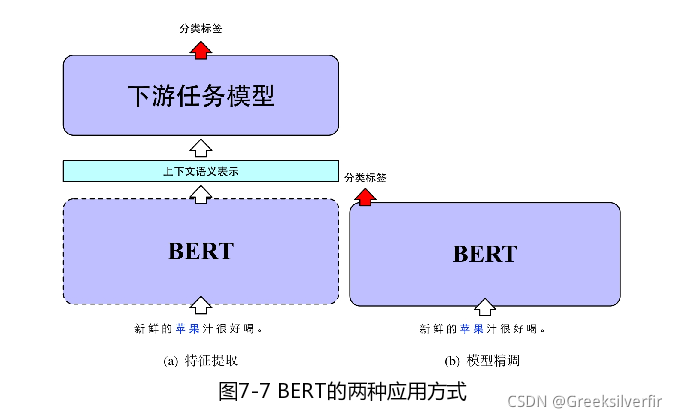
通常,预训练语言模型的应用方式分为以下两种。
- 特征提取: 仅利用BERT提取输入文本特征,生成对应的上下文语义表示,而BERT本身不参与目标任务的训练,即BERT部分只进行解码(无梯度回传);
- 模型精调: 利用BERT作为下游任务模型基底,生成文本对应的上下文语义表示,并参与下游任务的训练。即在下游任务学习过程中,BERT对自身参数进行更新。
7.4.2 单句文本分类
1.建模方法
单句文本分类(Single Sentence Classification,SSC) 任务是最常见的自然语言处理任务,需要将输入文本分成不同类别。
7.4.4 阅读理解
1.建模方法
抽取式阅读理解(Span-extraction Reading Comprehension)主要由篇章(Passage)、问题(Question)和答案(Answer)构成,

**(1)输入层。**在输入层中,对问题Q=q1q2⋅⋅⋅qnQ= q_1q_2··· q_nQ=q1q2⋅⋅⋅qn和篇章P=p1p2⋅⋅⋅pmP= p_1p_2··· p_mP=p1p2⋅⋅⋅pm(P和Q均经过WordPiece分词后得到)拼接得到BERT的原始输入序列X。(先问,后篇章,原因:bert最大长度)
X=[CLS]q1q2...qn[SEP]p1p2...pm[SEP]X=[CLS] q_1q_2...q_n[SEP]p_1p_2...p_m[SEP]X=[CLS]q1q2...qn[SEP]p1p2...pm[SEP]
v=InputRecpresentation(X)v=InputRecpresentation(X)v=InputRecpresentation(X)
其中,n表示问题序列长度,m表示篇章序列长度,[CLS]表示文本序列开始特殊标记,[SEP]文本序列之间的分割标记。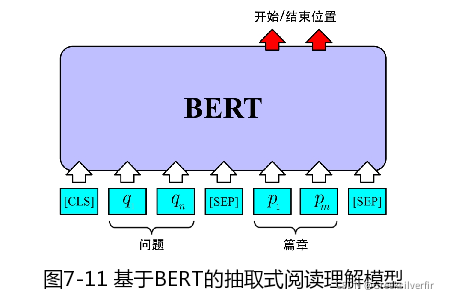
(2) BERT编码层。
输入表示经过多层Trnasformer的编码,借助自注意力机制充分学习篇章和问题之间的语义关联。并最终得到上下文语义h∈RN×dh\in R^{N \times d}h∈RN×d,d为Bert的隐含层维度。
h=BERT(v)h=BERT(v)h=BERT(v)
(3)答案输出层, 上下文语义表示h,通过全连接层,将每个分量(对应输入序列的每个位置)压缩为一个标量(其实就是通过全连接层,将上下文语义映射到词表)。并通过softmax函数预测每个时刻成为答案起始位置的概率(psp^sps)和终止位置的概率(pep^epe).
ps=Softmax(hWs+bs)p^s=Softmax(hW^s+b^s)ps=Softmax(hWs+bs)
其中WS∈RdW^S \in R^dWS∈Rd表示全连接层的权重,
pe=Softmax(hWe+be)p^e=Softmax(hW^e+b^e)pe=Softmax(hWe+be)
其中We∈RdW^e \in R^dWe∈Rd表示全连接层的权重,
最终通过交叉熵损失函数学习模型参数,起始位置和终止位置交叉熵取平均。
L=1/2(ls+le)L=1/2(l^s+l^e)L=1/2(ls+le)
(4)解码方法。 就很容易了,取top-k个起始位置的概率,再去top-k个终止位置的概率,二元组〈位置,概率〉。对于任意的进行两两相乘(起始位置<=终止位置),则可以形成文本片段概率:
公式:KaTeX parse error: Can't use function '$' in math mode at position 28: …i \times p^e_j$̲ 任意的$i,j …
7.4.5 序列标注
1.建模方法
序列标注中的典型任务——命名实体识别(Named Entity Recogni-tion,NER)介绍BERT在序列标注任务中的典型应用方法。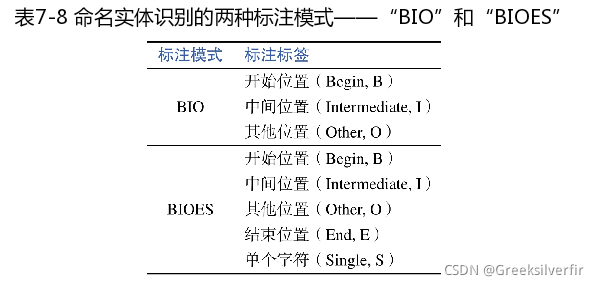
使用(WordPiece)处理输入文本,而这将破坏词与序列标签的一一对应关系(主要是英文上需要将词进行切分成粒度更小的字词,中文没有这情况)。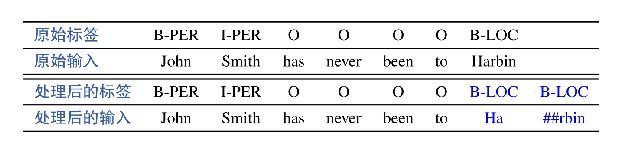
应用BERT处理命名实体识别任务的模型,由输入层、BERT编码层和序列标注层构成,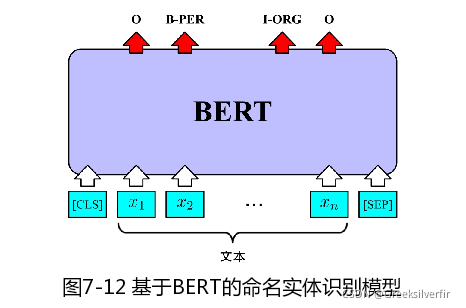
输入层与编码层,类似
(3) 序列标注层。和阅读理解任务一样,利用全连接层变换Bert隐含层表示,输出神经元个数为K,对应"BIO"标注模型下K个类别的概率值.
得到输入序列的上下文语义表示h后,针对输入序列中每一时刻t,预测在“BIO“模型标注模型下的概率分布ptp_tpt。即:
pt=Softmax(htWo+bo)p_t=Softmax(h_tW^o+b^o)pt=Softmax(htWo+bo)
其中W0∈dkW^0 \in d^kW0∈dk表示全连接层的权重,b0∈RKb^0 \in R^Kb0∈RK 表示全连接层的偏置。ht∈Rdh_t \in R^dht∈Rd表示h在时刻t的分量。
得到每个位置对应概率分布后,通过交叉熵损失函数对模型参数学习。
为了进一步提升序列标注的准确性,也可以在概率输出之上增加传统命名实体识别模型中使用的**条件随机场(Conditional Random Field,CRF)**预测。
2.代码实现
7.5 深入理解BERT
7.5.1 概述
7.5.2 自注意力可视化分析
BERT 模型依赖 Transformer 结构,其主要由多层自注意力网络层堆叠而成(含残差连接)。而 自注意力 的本质事实上是对 词(或标记)与词之间关系的刻画 。
如上图所示:有些注意力头分布较为均匀,具有较大的感受野,即编码了较“分散”的上下文信息;而有些注意力头的注意力分布较为集中,且显示出一定的模式,如集中在当前词的下一个词,或者[SEP]、句号等标记上。可以看出,不同的注意力头具有比较多样化的行为,因而能够编码不同类型的上下文和关系特征。
通过上图我们可以发现浅层的注意力层,具有较大的熵值(不确定因素)(其表示接近于词袋表示)。中间层的熵值较小(目标的明确),靠近输出层,其熵值会增大(主要与目标预训练任务直接相关)。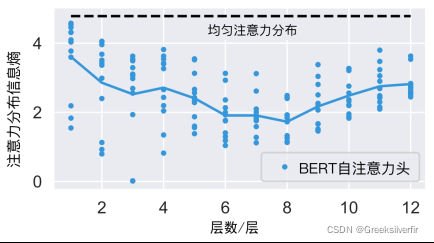
7.5.3 探针实验
定量分析方法是探针实验.。探针通常是一个非参或者非常轻量的参数模型(如线性分类器),它接受待分析对象作为输入,并对特定行为预测.自注意力反映了预训练模型内部信息的聚合过程,而模型的各层隐含层表示是聚合的结果。
问题:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)