使用cursor 完成大模型微调SFT,conda创建环境到最后运行,一招搞定。详细版。
都说cursor挺火的,我也来试试。由于实验室服务器最近链接不了网,我拿我电脑4060找一个小的试试。做一个简单的SFT。
·
都说cursor挺火的,我也来试试。 由于实验室服务器最近链接不了网,我拿我电脑4060找一个小的试试。做一个简单的SFT
1.首先打开一个空文件夹,为test.
你先用conda 创建一个环境,然后激活
现在cursor 上输入 > 选择python解释器
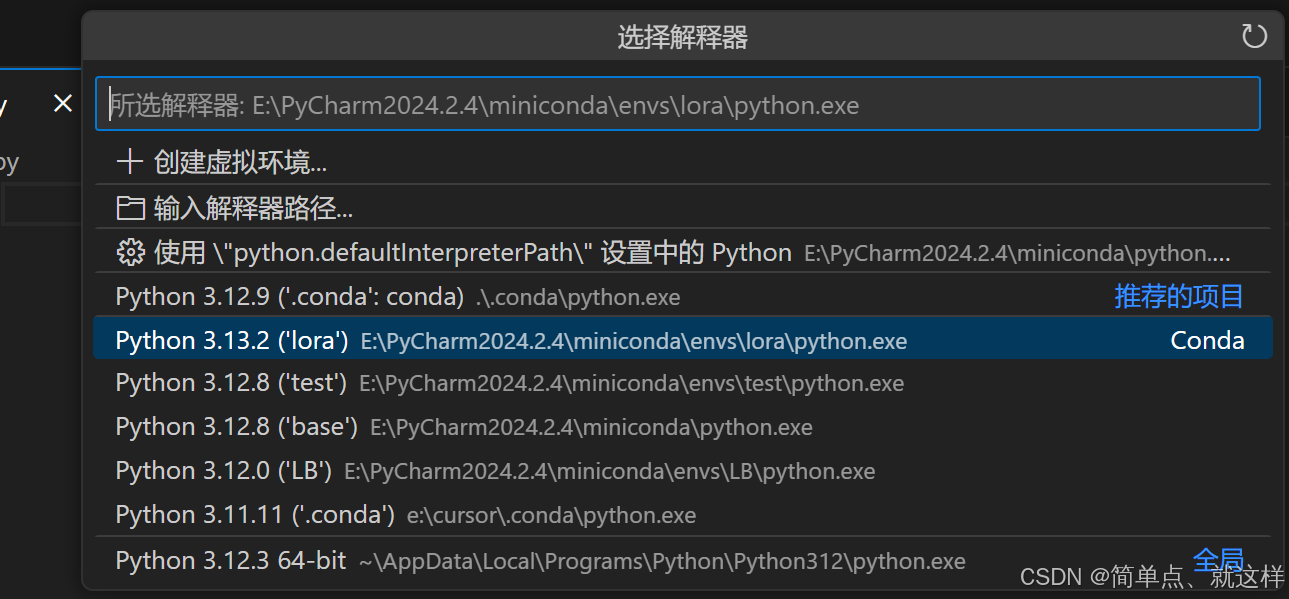
即使上面是黄色感叹号也没啥,继续选择,然后它会自动激活环境,
2.检查环境是否正确激活,在终端 输入conda env list.
# conda environments:
#
base * /opt/anaconda3
myenv /opt/anaconda3/envs/myenv前面带 ✳ 代表当前使用的环境是那个。
3. 创建一个空的main.py文件。
4.那接下来,就可以编写代码了。我们使用yelp_review_full 这个数据集。
# 首先在终端运行以下命令安装 datasets 库:
# pip install datasets
from datasets import load_dataset
dataset = load_dataset("yelp_review_full")
# 查看数据集的训练集
print(dataset["train"])
# 查看数据集的测试集
print(dataset["test"])

哈哈哈,让deepseek给你们介绍一下这个数据集。那print一下,就是下面这个样子

5、由于我们是做文本分类,那么需要分类器,将这些长短不一文本转换成token,才能被模型理解。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
6、接下来 准备加载预训练模型。我们使用bert模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=5, torch_dtype="auto")7、剩下的就tab tab tab 哈哈哈 真舒坦,这个太好用了
这里说明一下 ,在微调中直接调用Hugging face中的trainer这个类 进行微调,默认是 全参数微调
完整代码如下
# 首先在终端运行以下命令安装必要的库(如果使用 GPU 请确保安装 CUDA 版本的 PyTorch):
# pip install datasets transformers torch accelerate tensorboard --index-url https://download.pytorch.org/whl/cu118
from datasets import load_dataset
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
#加载数据集
dataset = load_dataset("yelp_review_full")
# 对数据集进行分词
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
#加载预训练模型
model = AutoModelForSequenceClassification.from_pretrained(
"google-bert/bert-base-cased",
num_labels=5,
)
# 设置训练参数
training_args = TrainingArguments(
output_dir="test_trainer",
per_device_train_batch_size=8, # 增加batch size
per_device_eval_batch_size=8,
num_train_epochs=10, # 训练轮数
)
# 创建 Trainer 对象
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
)
# 训练模型
trainer.train()
# 保存模型
model.save_pretrained("test_trainer")
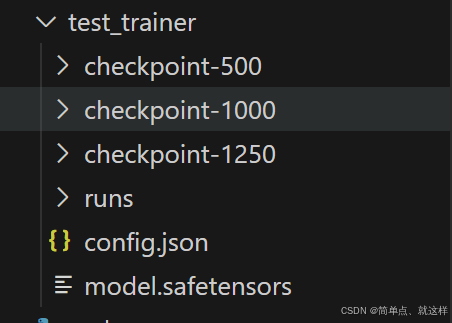
接下来,运行结束后,输出的结果都保存到这个test_trainer中去了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)