书生大模型实战营第四期L0G2000(Python 基础知识)
共两个必做任务分别是“Leetcode 383”和“Vscode连接InternStudio debug笔记”
·
共两个必做任务分别是“Leetcode 383”和“Vscode连接InternStudio debug笔记”
任务一
完成Leetcode 383, 笔记中提交代码与leetcode提交通过截图
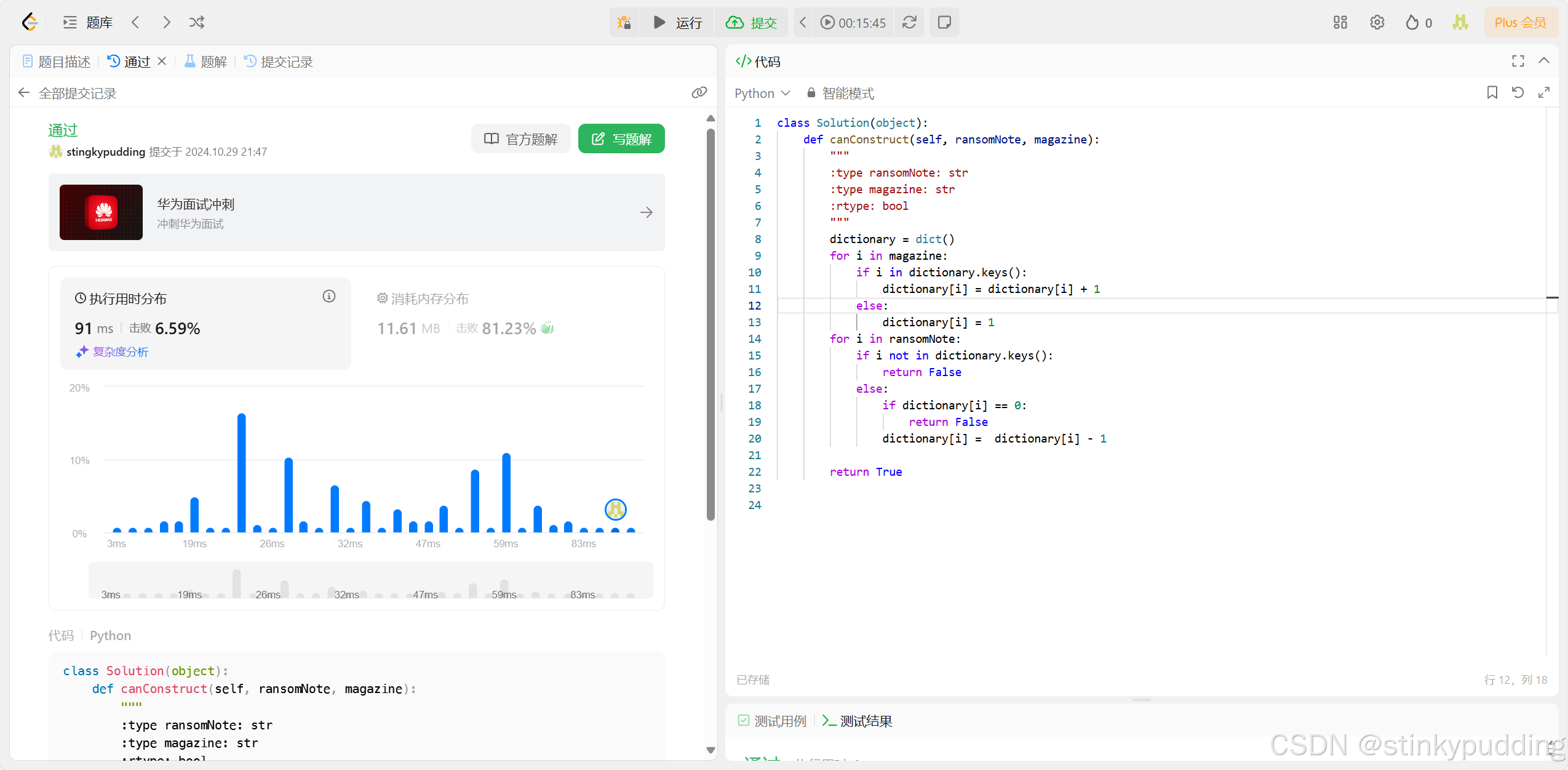
看题解没绷住,python的特性还是不熟
我的代码:
class Solution(object):
def canConstruct(self, ransomNote, magazine):
"""
:type ransomNote: str
:type magazine: str
:rtype: bool
"""
dictionary = dict()
for i in magazine:
if i in dictionary.keys():
dictionary[i] = dictionary[i] + 1
else:
dictionary[i] = 1
for i in ransomNote:
if i not in dictionary.keys():
return False
else:
if dictionary[i] == 0:
return False
dictionary[i] = dictionary[i] - 1
return True
官方题解:
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
if len(ransomNote) > len(magazine):
return False
return not collections.Counter(ransomNote) - collections.Counter(magazine)
任务二
对下面这段调用书生浦语API实现将非结构化文本转化成结构化json的代码进行Debug
from openai import OpenAI
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_json = json.loads(res)
print(res_json)直接运行此段代码,报错如下:
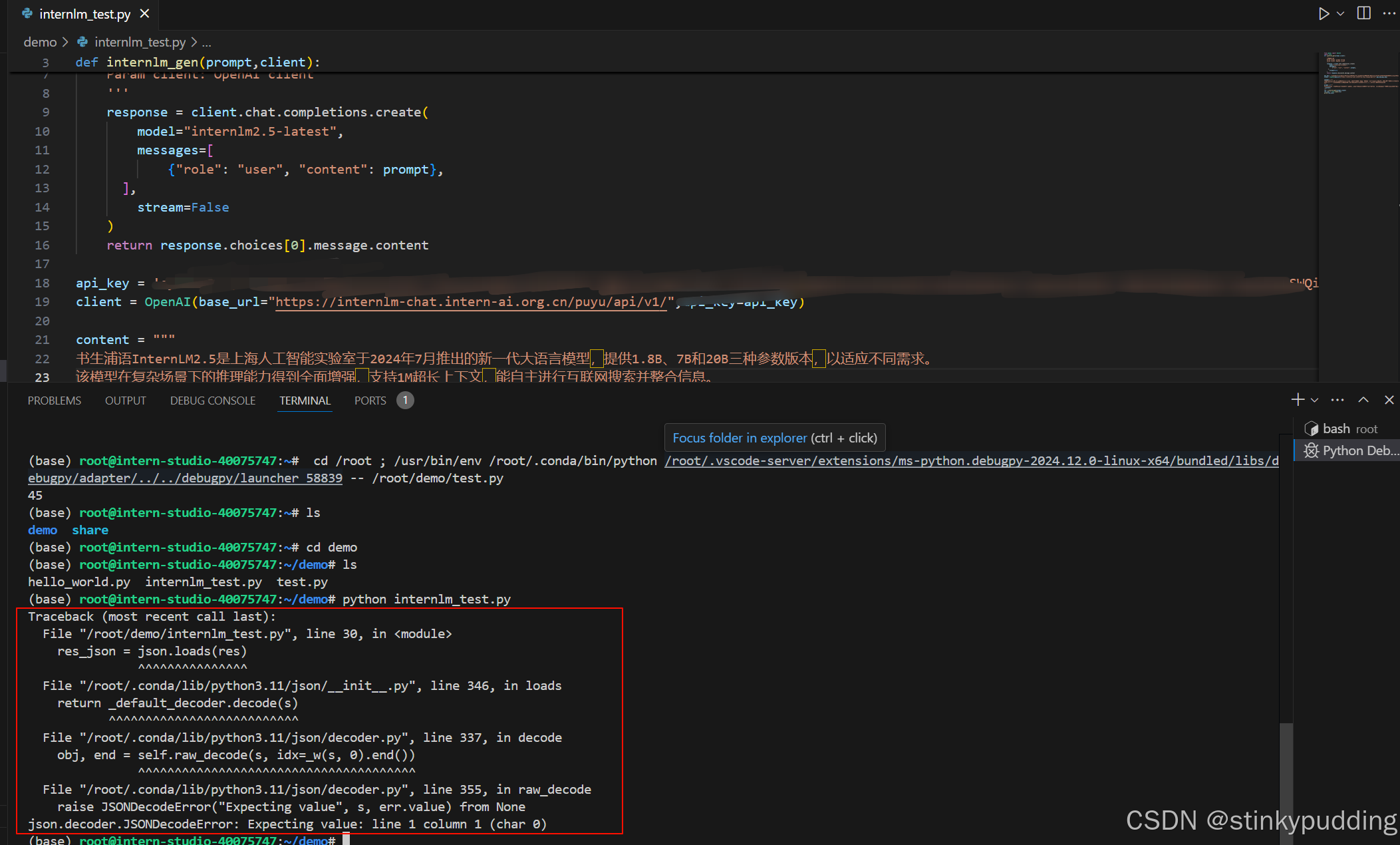
`JSONDecodeError`说明是在调用json.load这个函数把res解析成json的时候出问题了,所以我们看看res返回的是个啥。
res赋值这里打个断点,watch栏加入res,执行到这一步的时候看到了大模型返回的值。
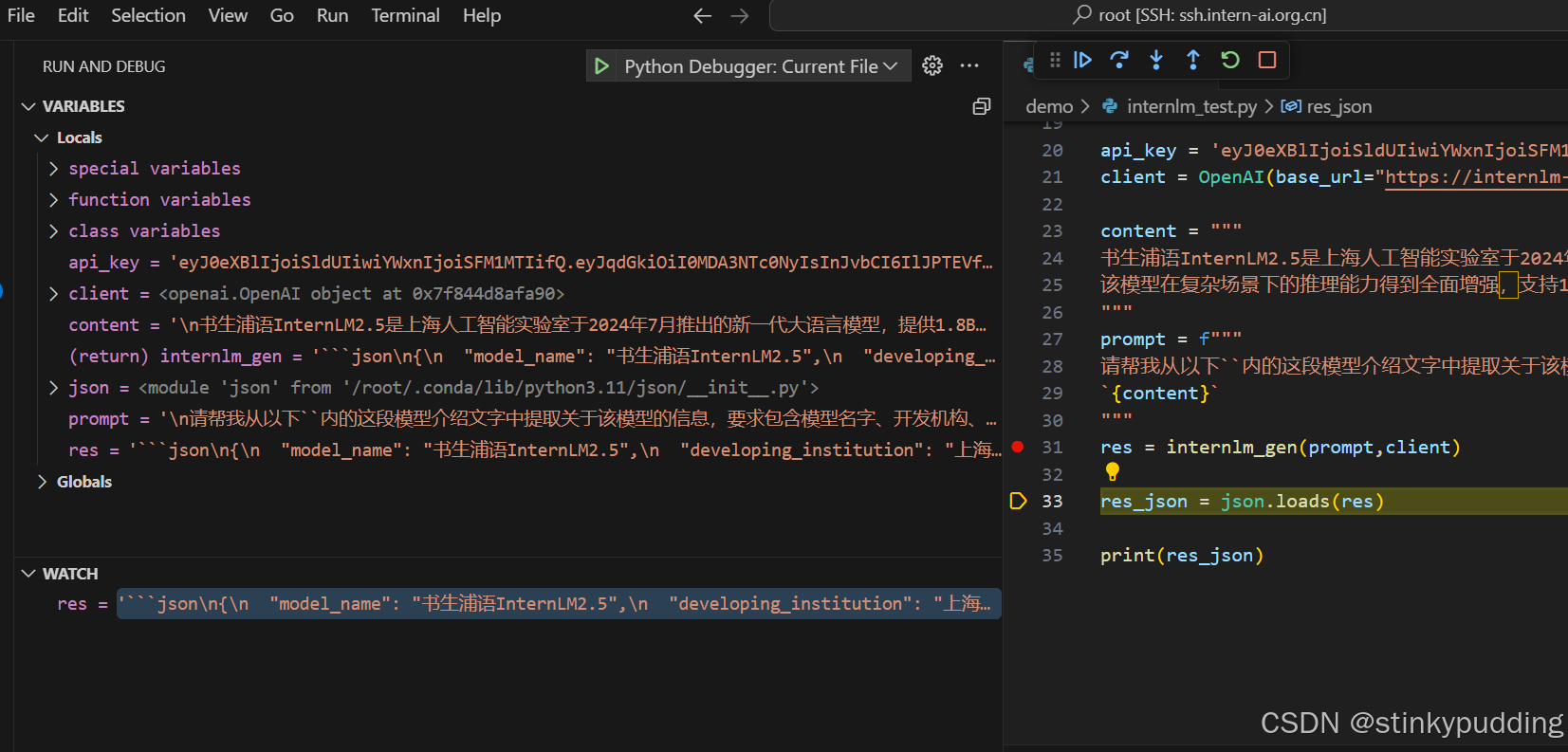
'```json\n{\n "model_name": "书生浦语InternLM2.5",\n "developer": "上海人工智能实验室",\n "parameter_versions": ["1.8B", "7B", "20B"],\n "maximum_context_length": 1000000\n}\n```'这个格式无法被解析,这里我直接简单粗暴地把这个字符串里面的json,\n和```都删除
res_cleaned = res.strip('\n').strip('```').strip('json')修改后的代码如下:
from openai import OpenAI
import json
def internlm_gen(prompt,client):
'''
LLM生成函数
Param prompt: prompt string
Param client: OpenAI client
'''
response = client.chat.completions.create(
model="internlm2.5-latest",
messages=[
{"role": "user", "content": prompt},
],
stream=False
)
return response.choices[0].message.content
api_key = ''
client = OpenAI(base_url="https://internlm-chat.intern-ai.org.cn/puyu/api/v1/",api_key=api_key)
content = """
书生浦语InternLM2.5是上海人工智能实验室于2024年7月推出的新一代大语言模型,提供1.8B、7B和20B三种参数版本,以适应不同需求。
该模型在复杂场景下的推理能力得到全面增强,支持1M超长上下文,能自主进行互联网搜索并整合信息。
"""
prompt = f"""
请帮我从以下``内的这段模型介绍文字中提取关于该模型的信息,要求包含模型名字、开发机构、提供参数版本、上下文长度四个内容,以json格式返回。
`{content}`
"""
res = internlm_gen(prompt,client)
res_cleaned = res.strip('\n').strip('```').strip('json')
res_json = json.loads(res_cleaned)
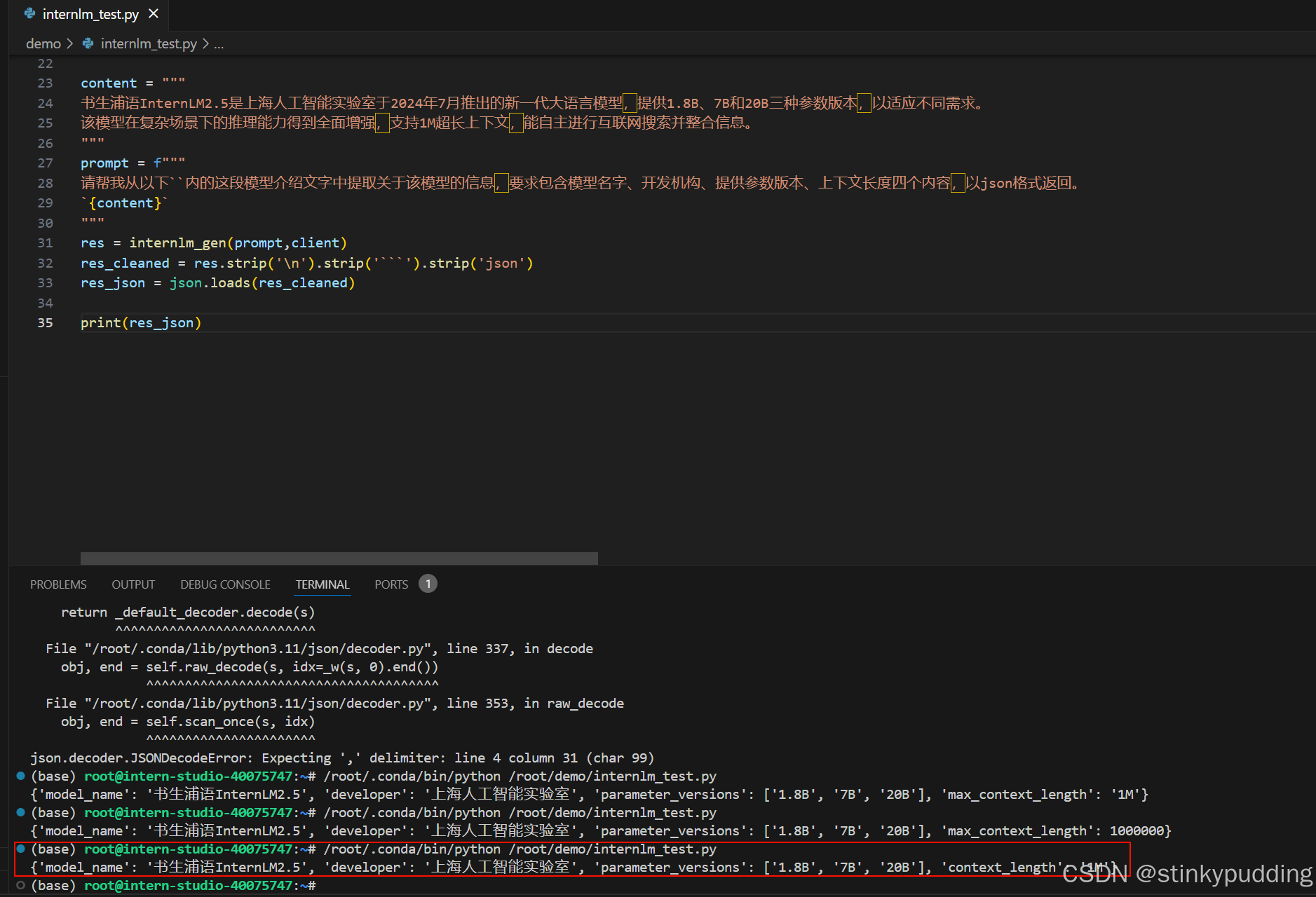
print(res_json)成功获得json

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)