广义典型相关分析算法原理_机器学习算法之聚类分析原理和实操
2020-6-05免费线上沙龙《大数据时代下不良资产处置新模式》报名咨询Vivian:wmyd80回复沙龙欢迎加入全国风控微信群组:免费加入,详情可添加管理Vivian:wmyd80回复微信群组文章来源于风控汪的数据分析之路,作者RideWind前言:聚类分析是一种非监督的机器学习算法,可以建立在无给定划分类别的情况下,根据数据相似程度进行样本分组的方法。它的入参是一组未被标记的样本,根...
·
 2020-6-05免费线上沙龙《大数据时代下不良资产处置新模式》报名咨询Vivian:wmyd80回复沙龙欢迎加入全国风控微信群组:免费加入,详情可添加管理Vivian:wmyd80回复微信群组
2020-6-05免费线上沙龙《大数据时代下不良资产处置新模式》报名咨询Vivian:wmyd80回复沙龙欢迎加入全国风控微信群组:免费加入,详情可添加管理Vivian:wmyd80回复微信群组
文章来源于风控汪的数据分析之路,作者RideWind
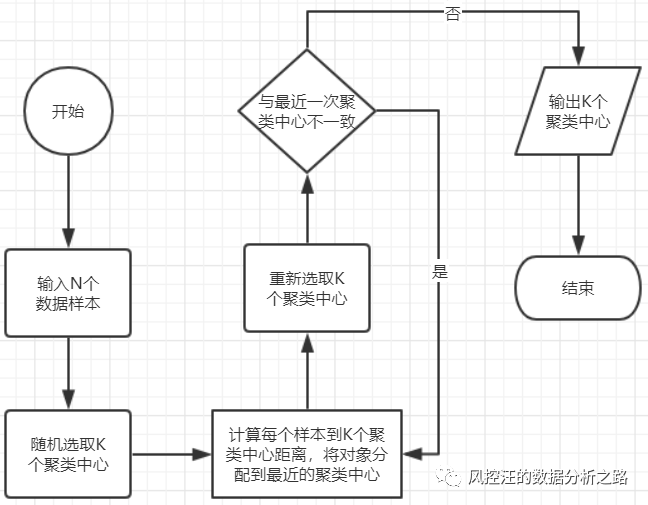
前言:聚类分析是一种非监督的机器学习算法,可以建立在无给定划分类别的情况下,根据数据相似程度进行样本分组的方法。它的入参是一组未被标记的样本,根据样本数据的距离或相似度划分为若干组,划分的原则是组内距离最小化,组外间距最大化。聚类分析的算法有多种,本文只为大家介绍K-Means 算法的应用和简单的原理。下文将分4个模块为大家介绍聚类分析:- 聚类分析的应用场景
- 聚类分析的K-Means 算法原理
- 聚类分析代码-输出聚类中心
- 聚类分析代码-可视化
- 如何得到一个好的聚类分析结果
- 客户画像:可以基于众多数据,给客户进行分层分类,以便对目前运营的产品有完善的了解,如客户的性别、年龄、地区、职业、收入等;
- 精准营销:利用贷前、贷中数据,挖掘真正有价值的客户,并找到其需求所在,精准推送,一网打尽;
- 反欺诈:清洗欺诈特征(如首逾)进行数据挖掘,找到明细有欺诈倾向客户和正常客户的差异。
 Scikit-learn 中的 K-Means算法使用欧式距离去度量样本到聚类中心的距离,并把误差平方和SSE作为度量聚类效果的目标函数,选取误差平方和最小的分类结果作为最终的聚类结果。欧式距离函数:
Scikit-learn 中的 K-Means算法使用欧式距离去度量样本到聚类中心的距离,并把误差平方和SSE作为度量聚类效果的目标函数,选取误差平方和最小的分类结果作为最终的聚类结果。欧式距离函数: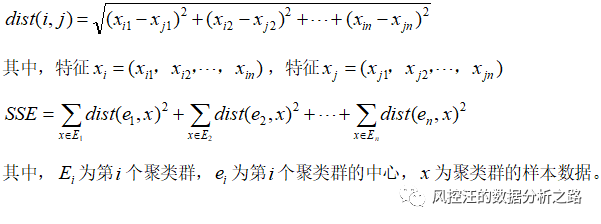 三、聚类分析代码-输出聚类中心3.1. 定义聚类分析所需要的包
三、聚类分析代码-输出聚类中心3.1. 定义聚类分析所需要的包
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport mglearnfrom sklearn.preprocessing import LabelEncoderimport warningswarnings.filterwarnings('ignore')import seaborn as snsfrom sklearn.datasets import make_blobsfrom matplotlib import pyplotplt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签plt.rcParams['axes.unicode_minus']=False #用来正常显示负号# 生成随机数data,target=make_blobs(n_samples=100000,n_features=10,centers=10)# 给随机数定义列名a = []for i in range(10): a.append('X'+str(i))data = pd.DataFrame(data)data.columns = a# 在二维图中绘制样本,每个样本颜色不同# 每次只能选取2个特征绘图(二维图像)pyplot.scatter(data[:,1],data[:,0],c=target);pyplot.show()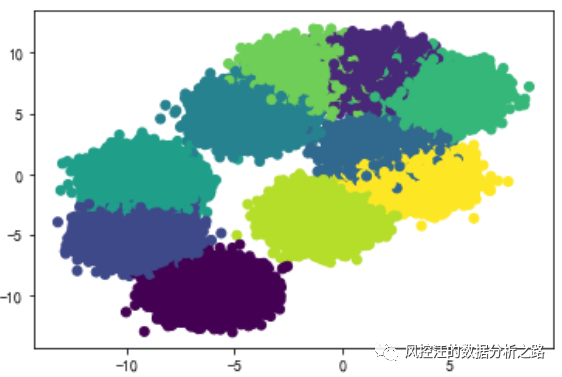 3.3. 输出聚类中心
3.3. 输出聚类中心
from sklearn.cluster import KMeansk = 4 # 定义聚类的类别中心个数,即聚成4类iteration = 500 # 计算聚类中心的最大循环次数model = KMeans(n_clusters = k,n_jobs = 4,max_iter = iteration)model.fit(data)r1 = pd.Series(model.labels_).value_counts()r2 = pd.DataFrame(model.cluster_centers_)r = pd.concat([r2,r1],axis=1)r.columns = list(data.columns)+[u'所属类别数目']r 3.4. 给每行数据标记所属类别
3.4. 给每行数据标记所属类别
r = pd.concat([data,pd.Series(model.labels_,index=data.index)],axis=1)r.columns = list(data.columns)+[u'所属类别数目']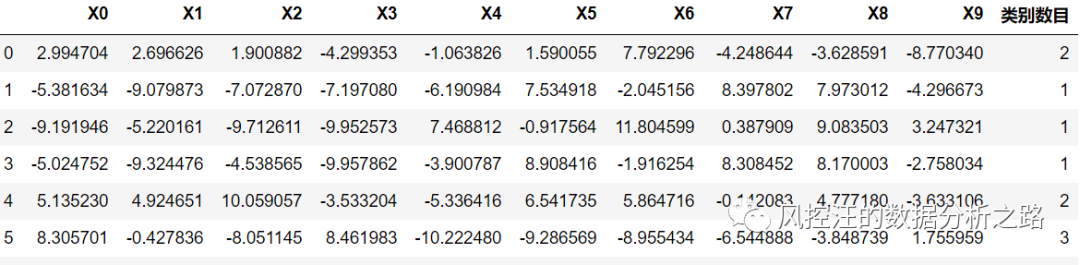 四、聚类分析代码-可视化上述已经输出了聚类中心并给每个客户都打好聚类标签了,接下来就需要使用2种可视化工具进行聚类结果的观测:
四、聚类分析代码-可视化上述已经输出了聚类中心并给每个客户都打好聚类标签了,接下来就需要使用2种可视化工具进行聚类结果的观测:
- 聚类分析可视化工具-TSNE(观测聚类效果)
- 特征间的二维分布散点图(观测聚类效果)
- 单个特征的概率密度函数(观测聚类结果是否具有业务意义)
from sklearn.manifold import TSNEtsne = TSNE()tsne.fit_transform(data)tsne = pd.DataFrame(tsne.embedding_,index=data.index)c = ['go','r.','b*','y.'] # 定义每个分类的颜色for i in range(k): # k为分类的个数 v = tsne[r[u'类别数目'] == i] plt.plot(v[0],v[1],c[i])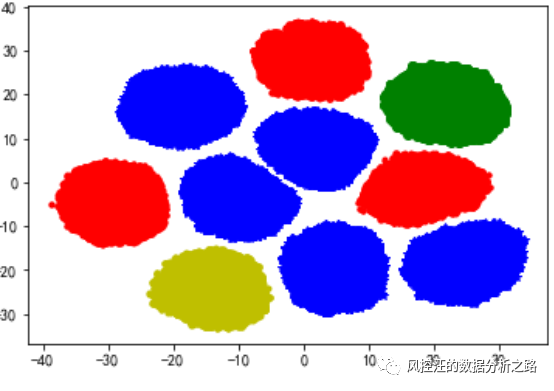 4.2. 特征间的二维分布散点图TSNE有个缺点,处理大量数据(10万+),会非常慢,考验工程师的耐心,这时也可以使用两两特征的散点图。我们可以根据业务经验选取散点图的特征,比如高学历伴随高收入,我们可以选取学历和收入来看其散点图是否有明显的聚类效果,如果觉得1-2组不够有代表性,可以多选几组。
4.2. 特征间的二维分布散点图TSNE有个缺点,处理大量数据(10万+),会非常慢,考验工程师的耐心,这时也可以使用两两特征的散点图。我们可以根据业务经验选取散点图的特征,比如高学历伴随高收入,我们可以选取学历和收入来看其散点图是否有明显的聚类效果,如果觉得1-2组不够有代表性,可以多选几组。
# 查看两两特征的二维分布fig,axes = plt.subplots(1,2,figsize=(10,5))mglearn.discrete_scatter(data['X0'],data['X1'],model.labels_,ax=axes[0])mglearn.discrete_scatter(data['X1'],data['X2'],model.labels_,ax=axes[1])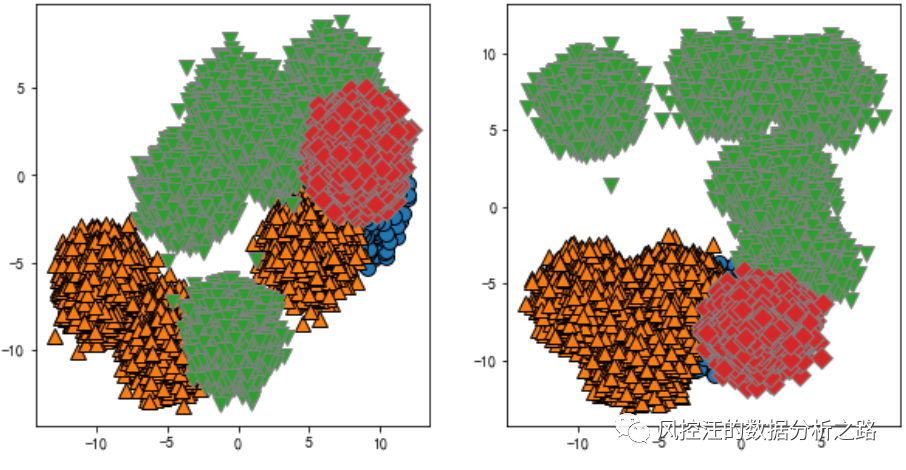 4.3. 单个特征的概率密度函数在聚类完成后,我们可以通过查看每个聚类的分布情况,判断聚类出来的结果是否具有业务意义。通过下面的代码,我们将对每个聚类标签下的特征都画出一张概率密度函数图像(即如果有4个聚类中心,将有4张特征为X1的分布图)。
4.3. 单个特征的概率密度函数在聚类完成后,我们可以通过查看每个聚类的分布情况,判断聚类出来的结果是否具有业务意义。通过下面的代码,我们将对每个聚类标签下的特征都画出一张概率密度函数图像(即如果有4个聚类中心,将有4张特征为X1的分布图)。
def density_plot(data,col):# data: 数据集# col: 作图的特征名称 plt.figure(dpi=80) p = data[col].plot(kind='kde',linewidth=2,subplots=True,sharex=False,figsize=(5,5)) plt.legend() return plt for i in range(k): # k为聚类个数 density_plot(data[r[u'类别数目']==i],'X1')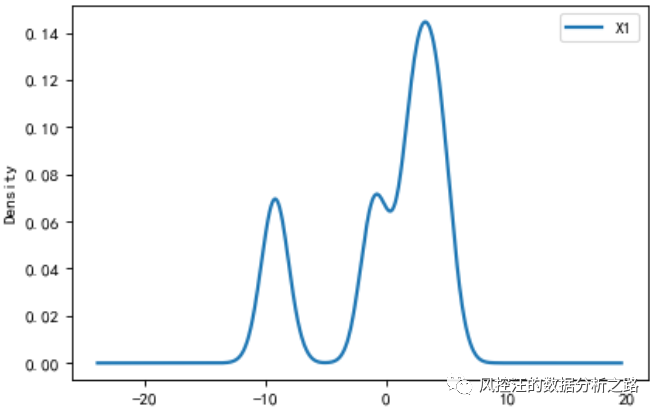 这时候,就需要多个特征辅助判断聚类结果是否有业务意义。如下例:
这时候,就需要多个特征辅助判断聚类结果是否有业务意义。如下例: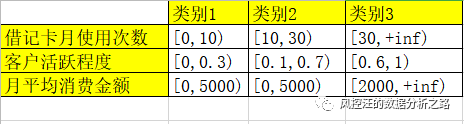 从上表中可以明显观察到月使用次数越多,客户活跃程度越高,说明此结果在业务层面的解释下非常好。五、如何得到一个好的聚类分析结果在做聚类分析的时候,我们通常会遇到以下几个问题:
从上表中可以明显观察到月使用次数越多,客户活跃程度越高,说明此结果在业务层面的解释下非常好。五、如何得到一个好的聚类分析结果在做聚类分析的时候,我们通常会遇到以下几个问题:
- 到底该聚成几类?
- 样本特征过多,怎么降维?
- 怎样才是一个好的聚类结果?

欢迎添加:
公众号:消费金融风控联盟,ID:xiaojinfengkong
公众号:天天学风控,ID:xuefengkong
Vivian:微信号:wmyd80
抖音号:xuefengkong
商务合作:安然:13911850028
欢迎加入社群圈子:免费加入+免费发布信息,详情可添加管理Vivian:wmyd80回复社群圈子
欢迎加入风控干货知识星球:详情可添加管理Vivian:wmyd80回复知识星球
欢迎加入全国风控微信群组:免费加入,详情可添加管理Vivian:wmyd80回复微信群组

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)