机器学习实践——Bank
文章目录
一、实践流程
- 问题识别
- 数据准备
- 数据分析处理
- 数据分析可视化
- 数据特征提取
- 模型选择及训练
- 模型测试评价
- 模型应用
二、问题识别
- 观察问题属于哪一类,回归、分类、聚类
三、数据准备
3.1数据文件(csv文件)
数据集连接:这个是此文章用到的数据集连接,请点击我
- bank-additional-full.csv
包含所有的样例(41188个)和所有的特征输入(20个),根据时间排序(从2008年5月到2010年9月) - bank-additional.csv
从上述文件中随机选出10%的样例(4119个)
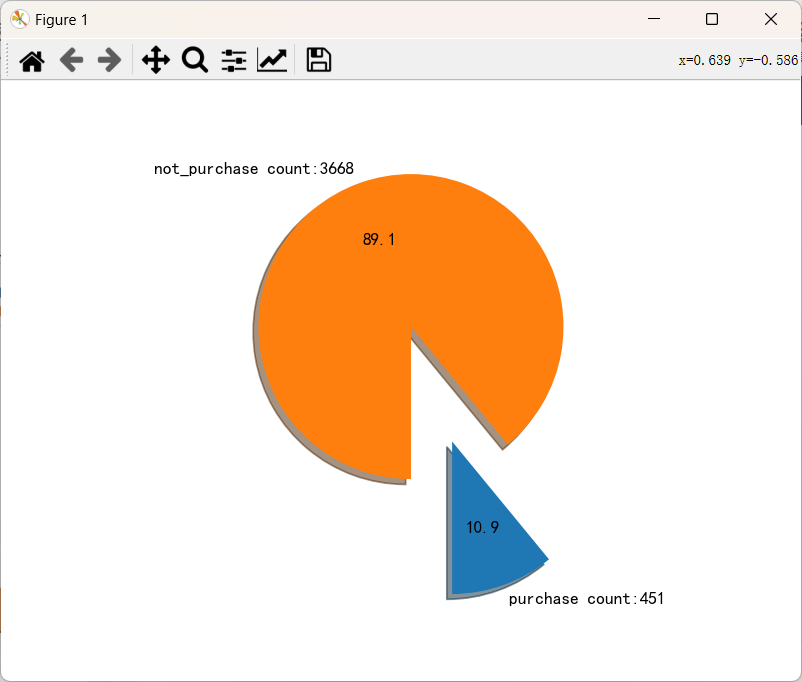
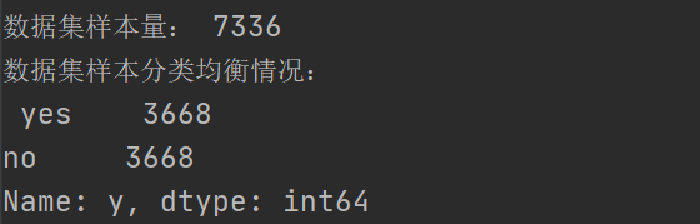
客户认购定期存款(yes)有451个样本
未认购定期存款(no)有3668个样本
发现:正样本(y=‘yes’)的数量远小于负样本(y=‘no’)的数量,近似等于负样本数量的1/8,数据存在正负样本不平衡问题
3.2数据特征
客户属性数据
客户信用行为数据
银行营销业务数据
市场指标数据
预测目标数据(目标值)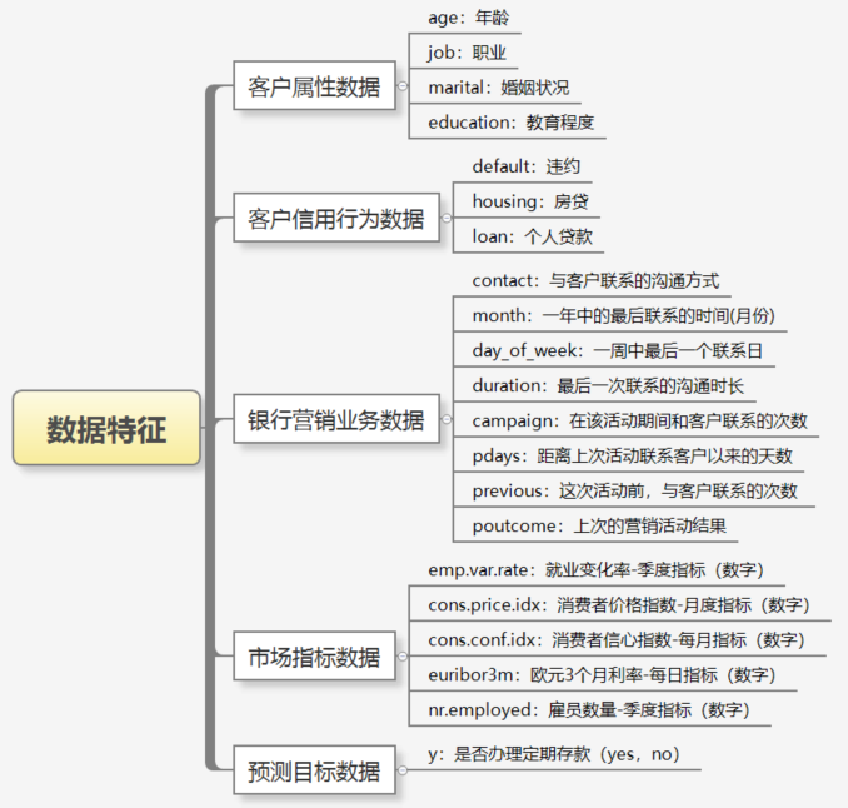
属性
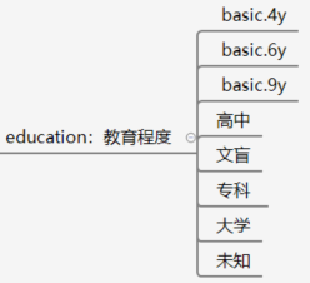

3.3数据样本示例

- 数据文件包含“特征名称”(表头)
- 第1条样本解读
客户未认购定期存款
特征如下:年龄30,蓝领,已婚,9年基础教育,无信用违约,有住房贷款,无个人贷款,…
四、数据分析处理
4.1数据分析前的准备
- 环境准备
paycharm - 文件的创建
创建bank_marketing_classification.py (名称尽量规范,体现含义)
- 实践库的导入
如:import numpy as np - 数据集的导入
依据:根据数据文件格式使用不同方法导入
实践中数据文件是CSV格式
使用pandas中 read_csv 读取
数据格式:DataFrame
针对read_csv 和DataFrame进行简单介绍:
pandas.read_csv(
filepath_or_buffer, # 设置需要访问的文件的有效路径
sep, # 指定读取文件的分隔符,支持自定义分隔符
delimiter, # 定界符,备选分隔符(如果指定该参数,则sep参数失效)
header, # 指定作为整个数据集列名的行,如果数据集中没有列名,则需要设置header=None,对有表头的数据识别第一行作为header
names, #用于结果的列名列表
…,
encoding, # 指定字符集类型,通常指定为’utf-8’,支持切换其它格式
… )
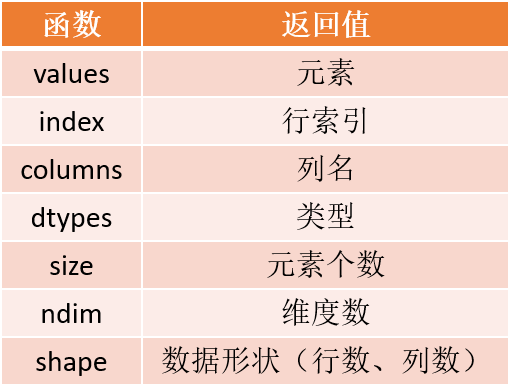
DataFrame
一种表格型数据类型,每列值类型可以不同
既有行索引,也有列索引
常用于表达二维主句也可以用于表达多维数据
4.2基础流程
4.3正式进行数据处理
4.3.1导入数据集,进行数据读取
需要考虑数据的内容:
- 是否包含特征名称(列名)?
- 分割符号(逗号、分号、空格等)?
- 是否含有中文?需要考虑编码
df=pd.read_csv('./data/bank-additional-1686527941639.csv', delimiter=";")
df.columns=["age","job","marital","education","default","housing","loan","contact","month","day_of_week","duration","campaign","pdays","previous","poutcome","emp.var.rate","cons.price.idx","cons.conf.idx","euribor3m","nr.employed","y"]
print(df.head(5)) #打印前5行
df示例: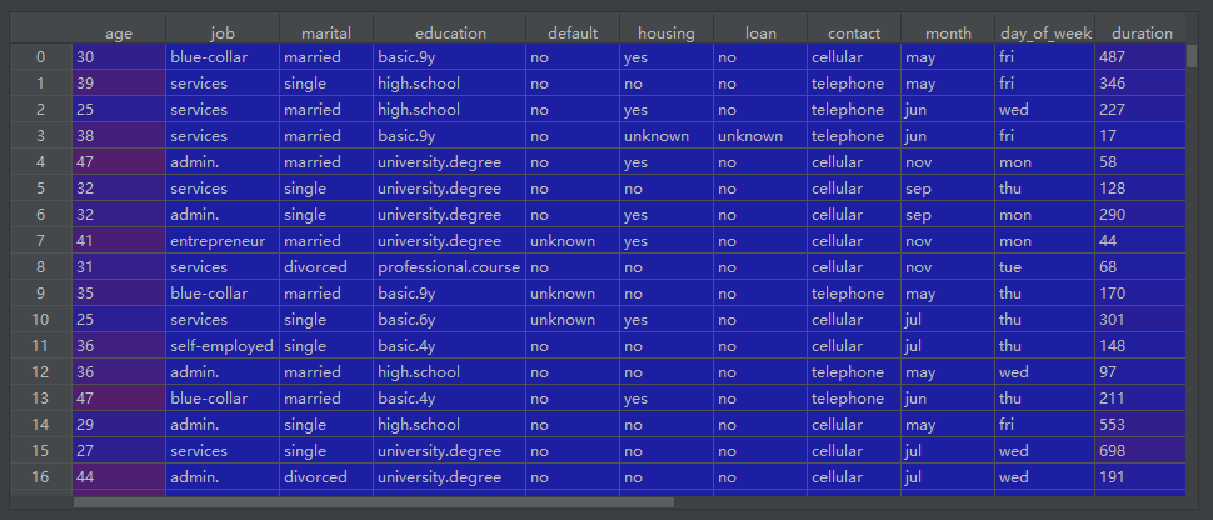
4.3.2数据分析处理考虑的维度
#数据示例,展示的是21列前五行的数据
pd.set_option("display.max_columns",21)#让所有的列都能加载出来
print("数据示例:\n",df.head(5))
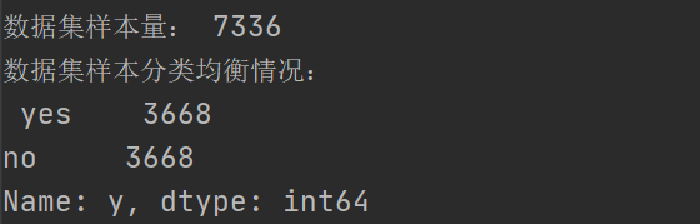
- 数据样本量
print("数据集样本量:",df.shape[0])
- 数据分布情况
print("数据集样本分类均衡情况:\n",df.y.value_counts())
#y是表头object的一个属性
- 查看数据基本统计信息
print("基本信息:\n",df.describe())
#可以判断数据是否都存在异常值(某些数据不可以存在负值)
- 数据类型及缺失情况
print(df.info())
- 数据有无重复情况
print("数据是否存在重复值",df.duplicated().all())
4.3.3数据深入分析
- 数据中字符型特征中存在unkwown值,一般认为unknown值是缺失值,需要处理
- 对数据缺失情况进行深入分析(缺失值占比)
- 依据80%原则,即非缺失部分低于总样本量的80%,需要对该数据特征进行删除
for col in df.columns:#循环的是表头
#print(col)#查看数据集的表头
if type(df[col][0]) is str:#如果表头的类型是字符串
total_col=df[col].isin(['unknown']).sum()
total=df[col].count()
print(col+'中unknown值的个数有:',total_col,'\t占比为:%3.f'%(total_col/total))
数据分析:
- 对缺失值需要进行填补
- 不同数值型的特征,数据量纲差异较大,需要标准化处理
- String格式的特征,无法放到模型训练,需要离散型特征编码处理
数据处理:
- 针对数据缺失处理
利用sklearn.impute 模块中单变量填充 SimpleImputer
sklearn.impute.SimpleImputer (missing_values=np.nan, strategy=‘mean’,…)
missing_values:空值类型,默认np.nan
strategy:采取什么策略去填充空值,总共有4种选择,分别是mean(均值),median(中位数),most_frequent (众数)以及 constant(常数)
空值为 “unknown”
使用该缺失值对应的特征的非缺失值,统计most_frequent (众数)来填充该缺失值
# 数据填补:对于出现的unknown变量,可将变量取众数,赋值给unknown值
imp_most_frequest=SimpleImputer(missing_values='unknown',strategy='most_frequent')
for col in df.columns:
if type(df[col][0]) is str:
print(type(df[col]))
df[col]=imp_most_frequest.fit_transform(np.array(df[col]).reshape(-1,1))
- 针对数据量纲差异大标准化处理
利用sklearn.preprocessing 模块中的 StandardScaler
sklearn.preprocessing.StandardScaler(*, copy=True, with_mean=True, with_std=True)
标准化方法:z = (x − u)/S ,计算均值u与标准差S ,再进行转化
stand=StandardScaler()#标准化,先计算均值u与标准差s,再进行转化
for col in df.columns:
if df[col].dtypes != 'object':
df[col]=stand.fit_transform(np.arry(df[col]).reshape(-1,1))#先fir再transform
print(df.head(5))
- 针对字符串格式特征,离散编码处理
标准化标签,将标签值统一转换成range(标签值个数-1)范围内
le=LabelEncoder()#将数据特征统一转换成range(类别个数-1)范围内
for col in df.columns:
if type(df[col][0]) is str:
df[col] = le.fit_transform(df[col])
print(df.head(5))
五、数据可视化
- 使用matplotlib和seaborn绘制数据分布条形图
- seaborn.countplot(x=None, y=None ,hue= None, data=None,…)
x : x轴上的条形图,以x标签划分统计个数
y : y轴上的条形图,以y标签划分统计个数
hue :在x或y标签划分的同时,再以hue标签划分统计个数
data:用于绘图的数据集
使用条形图显示每个分箱器中的观察计数
5.1 绘制条形图
plt.figure()
plt.title("客户是否认购定期存款情况")
sns.countplot(x="y",hue="y",data=df)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
plt.show()
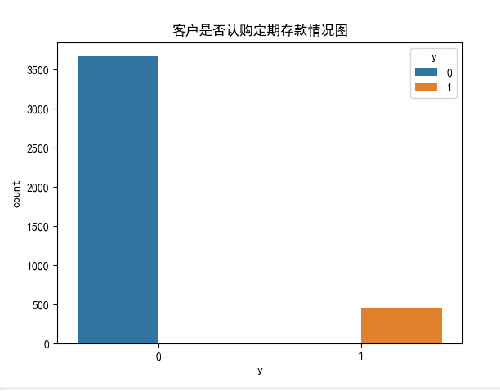
发现:
客户认购定期存款不高,样本数据分布不均衡
需要采用方法解决样本不均衡问题
5.2 绘制饼状图
- pie(x, explode=None, labels=None, colors=None, autopct=None, shadow=False, startangle=None, …)
x:(每一块)的比例,如果sum(x) > 1,会使用sum(x)归一化
labels :(每一块)饼图外侧显示的说明文字
explode :(每一块)离开中心距离
shadow :在饼图下面画阴影,默认值:False,即不画阴影
autopct :控制饼图内百分比设置,
startangle :起始绘制角度,默认图是从x轴正方向逆时针画起
client_purchase=df[df.loc[:,'y']==1].copy()
print(client_purchase)
client_not_purchase=df[df.loc[:,'y']==0].copy()
print(client_not_purchase)
pie_data={"purchase count": client_purchase.shape[0],
"not_purchase count":df.shape[0]-client_purchase.shape[0]}
print(pie_data)
fig,ax=plt.subplots()
print(fig,ax)
sizes=pie_data.values()
print(sizes)
labels=['{}:{}'.format(key,value) for key,value in pie_data.items()]
# a=[1,2,3,4] w**2("结果对象") for w("目标对象") in a
ax.pie(sizes,explode=(0.2,0),labels=labels,autopct='%1.1f',shadow=True,startangle=-90)
ax.axis('equal')#使饼图宽度相等
plt.show()
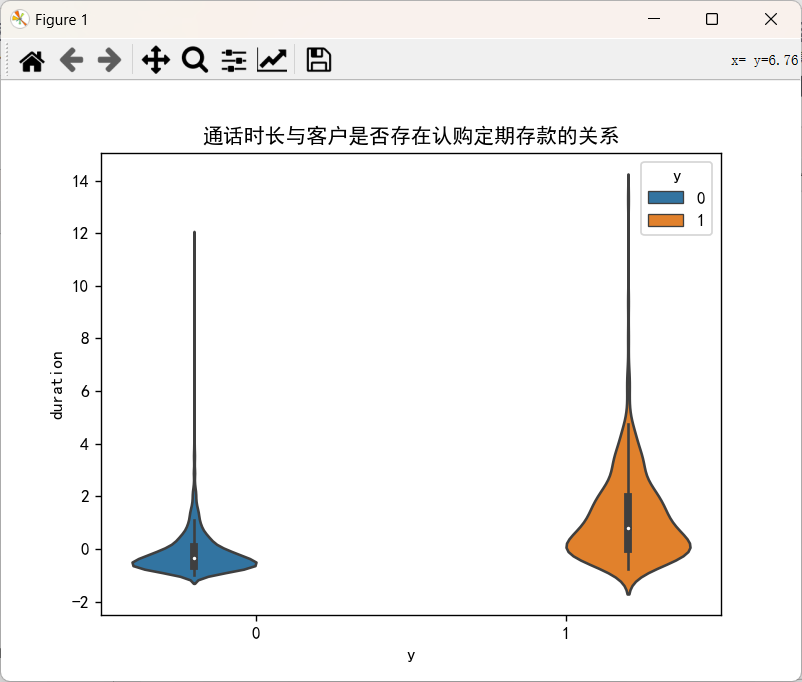
5.3 绘制关系图
- seaborn.violinplot(x=None, y=None, hue=None, data=None,…)
x : x轴上的条形图,以x标签划分统计个数
y : y轴上的条形图,以y标签划分统计个数
hue :在x或y标签划分的同时,再以hue标签划分统计个数
data:用于绘图的数据集
plt.figure()
plt.title("通话时长与客户是否存在认购定期存款的关系")
sns.violinplot(x="y",y="duration",hue="y",data=df)
plt.show()
六、模型选择及训练
6.1数据集的划分
- 利用sklearn 中 train_test_split进行数据集的划分+sklearn.model_selection.train_test_split(train_data, train_target, test_size, train_size, random_state,…)
train_data:待划分的样本数据
train_target:待划分的对应样本数据的样本标签
test_size:测试集样本占比/样本数
train_size:训练集样本占比/样本数
random_state:随机数种子,种子不同,每次采的样本不一样;种子相同,采的样本不变,random_state不取,采样数据不同,但random_state等于某个值,采样数据相同
X=df.drop(["y"],axis=1)#删掉df最后一列,其余为特征
y=df['y'] #目标变量
train_size=0.67 #设置训练集的比例
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=train_size,random_state=1)
6.2模型的选择
模型选择方法:
- 选择单个分类模型进行训练
- 选择多个分类模型同时训练,进行效果评价
选择5个已学过的模型:
- 朴素贝叶斯分类
- KNN分类
- 决策树分类
- 支持向量机分类
- 随机森林分类
model_list=[GaussianNB(),#朴素贝叶斯
KNeighborsClassifier(n_neighbors=9),#KNN
DecisionTreeClassifier(criterion='entropy',max_depth=5,class_weight='balanced'),#决策树
SVC(probability=True,kernel='rbf',class_weight='balanced'),#支持向量机
RandomForestClassifier(n_estimators=100,max_depth=3)#随机森林
]
model_name=['Naive_Bayes','KNN','Decision_Tree','SVC','RandomForest']
6.3模型训练
for name,model in zip(model_name,model_list):
#根据选择的模型进行训练
model.fit(X_train,y_train)
6.4模型预测及评价
- 利用predict对测试集进行模型预测
- 对测试集进行评价
准确率(accuracy):正确预测的正反例数/总数 (分母为定数)
召回率(recall):也称查全率,正确预测的正例数/实际正例总数(分母为定数)
精确率(precision):也称查准率,正确预测的正例数/预测正例总数
F_1综合值(F1score):是精确率与召回率的调和平均值
模型预测与评价:
#进行预测
y_test_predict=model.predict(X_test)
#进行评价
acc_test=accuracy_score(y_test,y_test_predict) #和模型自带的moedl.score一致
precosopn_test=precision_score(y_test,y_test_predict)
recall_test=recall_score(y_test,y_test_predict)
f1score_test=f1_score(y_test,y_test_predict)
print("{}分类模型在测试集上的评价结果为:".format(name))
print("准确率:%.3f\t 精确率:%.4f\t 召回率:%.4f\t F1值:%.4f\t"
%(acc_test,precosopn_test,recall_test,f1score_test))
七、模型优化(参数调整)
7.1优化方向
- 数据处理方法的优化 —— 数据不平衡化处理
- 数据特征优化(特征重合、相关)——特征工程
- 选取新模型(例如LightGBM、XGBoost等)
7.2减弱数据不平衡
7.2.1 正例样本抽样
数据集bank-additional.csv中正样本(y=‘yes’)的数量:451,负样本(y=‘no’)的数量:3668,为平衡正负样本数量,将正样本进行重复抽样
数据是DataFrame格式
使用pandas.DataFrame.sample 随机选取若干行
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n:要抽取的行数
frac:抽取行的比例
replace:是否为有放回抽样,True:有放回抽样,False:未放回抽样
random_state:随机数发生器种子,random_state=None,取得数据不重复,random_state=1,可以取得重复数据
axis:选择抽取数据的行还是列,axis=0:抽取行,axis=1:抽取列
具体方法的实现
将数据集中正负样本分开,分别为正样本集和负样本集,对正样本集使用sample方法,随机重复抽取3668行
- 使用pandas中concat将抽取的正样本集和原负样本集进行组合
pandas.concat(object,axis=0,…, ignore_index=False,…)
object:series,dataframe或则是panel构成的序列list
axis:需要合并连接的轴,0是行,1是列
#方法1:正例样本重复抽样
#方法1:正例样本重复抽样
df_no=df[df.y=='no']#原有数据集负样本3668
df_yes=df[df.y=='yes']#原有数据集正样本 451
df_yes1=df_yes.sample(len(df_no),replace=True,random_state=1)
# 组合成正负样本平衡的数据集
if (len(df_no) == 0) or (len(df_yes1) == 0):
df = pd.DataFrame()
else:
df = pd.concat([df_yes1, df_no], ignore_index=True)
数据平衡化方法1的评价指标结果: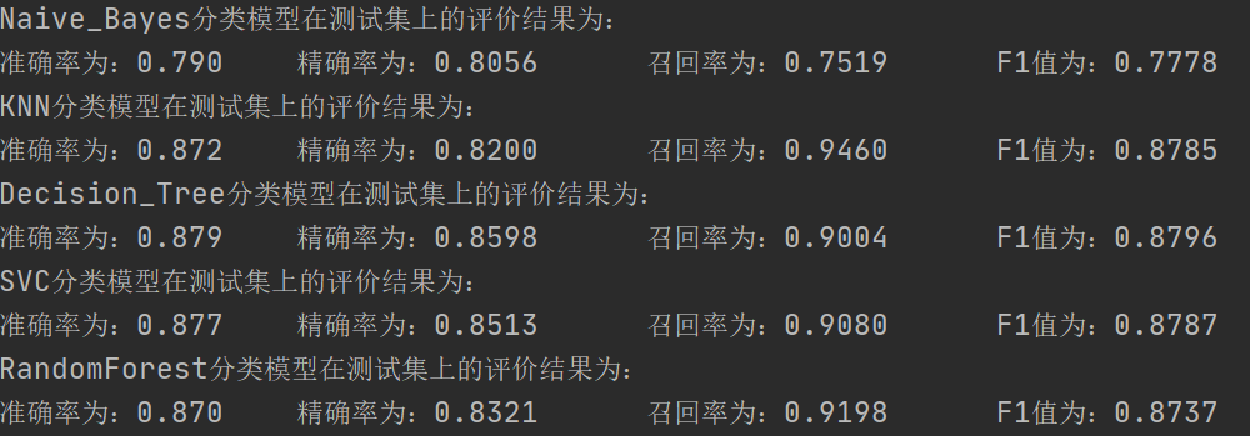
7.2.2 增加新的正例样本
- 新的正例样本来源于数据集bank-additional-full.csv
正例样本4640,负例样本36548个
从正例样本中随机选取3217个,和原正例样本集组合成新的正例样本集与负例样本集数量一致
和原有负例样本集组成一个新的数据集
#方法2:增加新的正例样本
df_full=pd.read_csv('./data/bank-additional-full-1686527941688.csv',delimiter=';')
df_yes_full=df_full[df_full.y=="yes"]#数据全集中的样例
df_yes11=df_yes_full.sample(3217,replace=False,random_state=1)
df=pd.concat([df,df_yes11],ignore_index=True)
数据平衡化方法1的评价指标结果: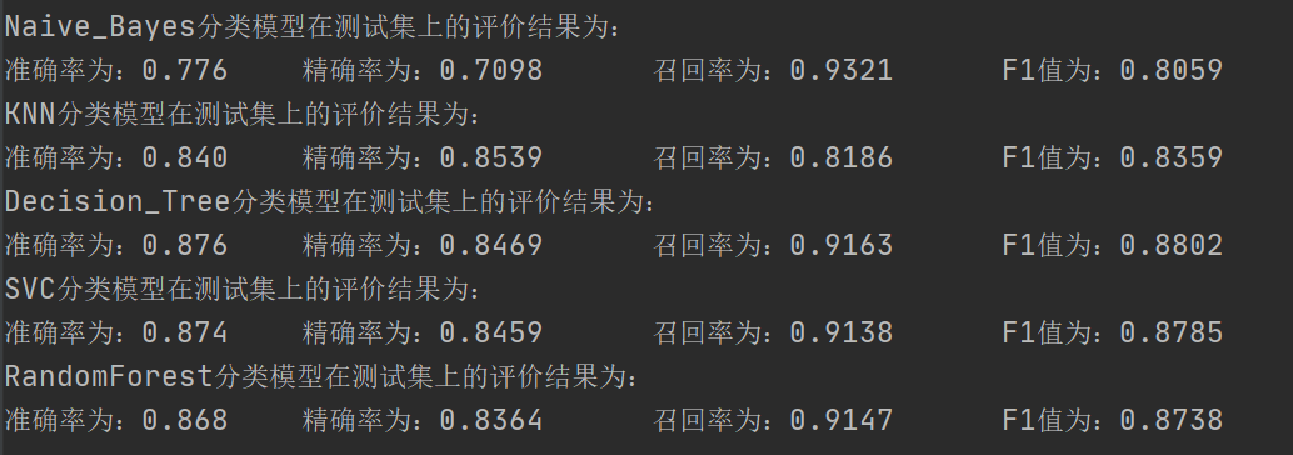
7.2特征优化
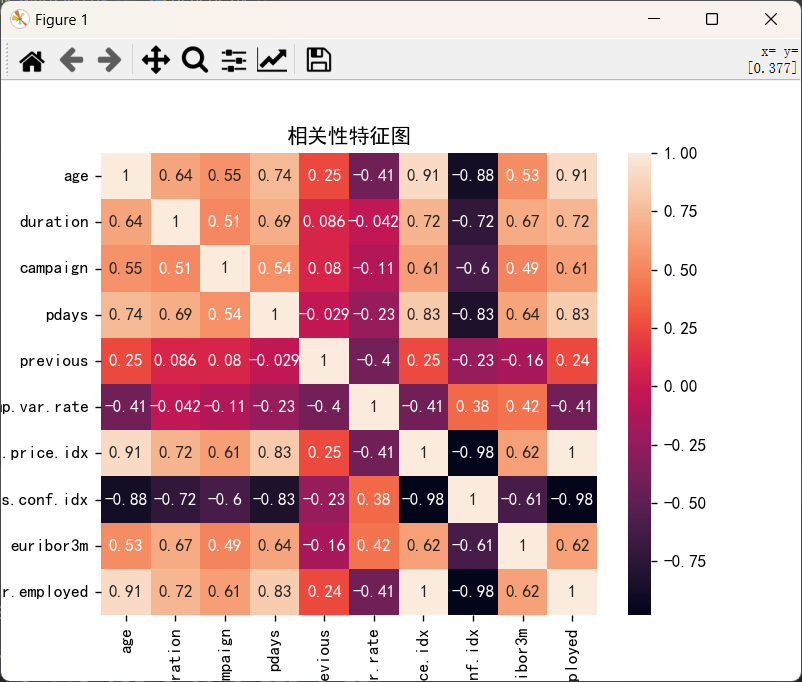
使用seaborn绘制特征相关性图(热力图)
- seaborn.heatmap(data,…,cmap=None,…, annot=None,…)
data:矩阵数据集
cmap:热力图颜色
annot:当annot为True时,在heatmap中每个方格写入数据
df.corr(method=‘pearson’, …):计算df的pearson相关系数
plt.figure()
plt.title("相关性特征图")
sns.heatmap(data=df.corr(method='pearson'),annot=True)
plt.show()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)