深度学习梯度与反向传播
在深度学习中,多元函数通常是 复合(composite)的,所以我们可能没法应⽤上述任何规则来微分这些函数。幸运的是,链式法则使我们能够微分复合函数。
梯度与反向传播
1、梯度(方向向量)
1.1 什么是梯度
梯度:是一个向量,导数+变化最快的方向(学习的前进方向)
目标:通过梯度调整(学习)参数\(w\),尽可能的降低\(loss\)
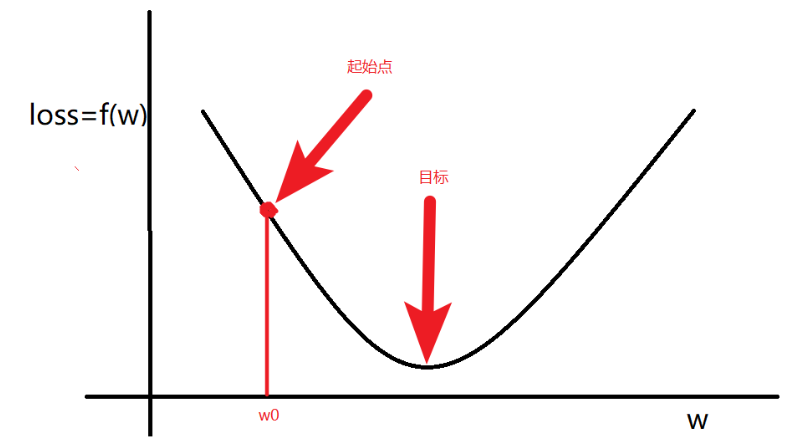
一般的,随机初始一个\(w0\),通过优化器在学习率和梯度的调整下,让\(loss\)函数取到最小值。
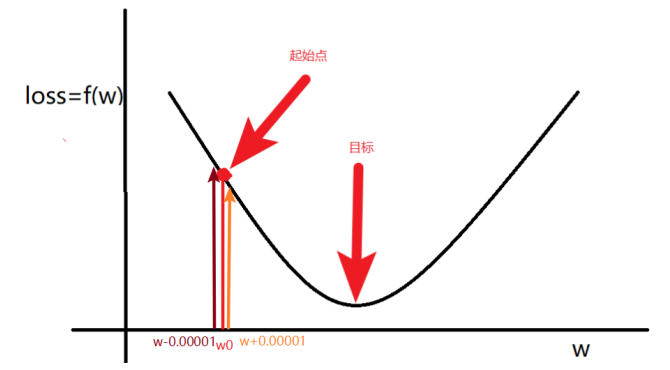
1.2 \(w\)的更新方法

总结:梯度就是多元函数参数的变化趋势(参数学习的方向),只有一个自变量时称为导数
1.3 偏导数与梯度计算

1.4、链式法则

2、反向传播算法
2.1 反向传播解释
假设有函数为:
J(a,b,c)= 3(a + bc),合u=a+u,v= bc
梯度计算图为:
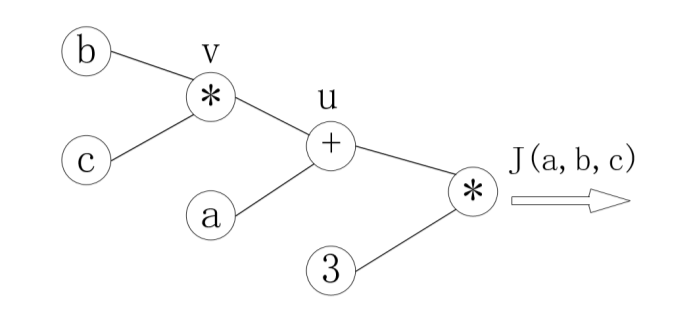
反向传播计算:
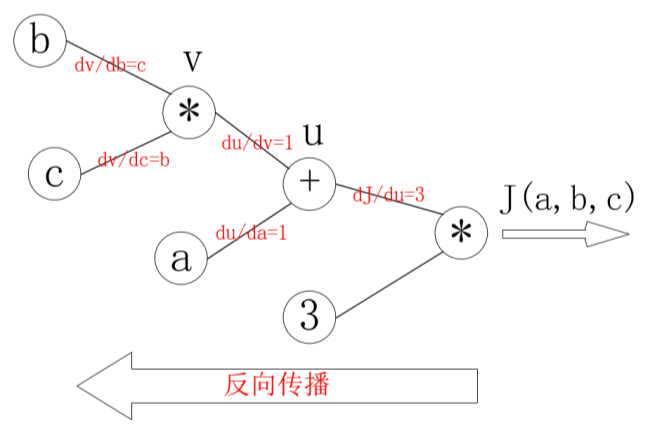
那么反向传播的过程就是一个上图的从右往左的过程,自变量\(a,b,c\)各自的偏导就是连线上的梯度的乘积。

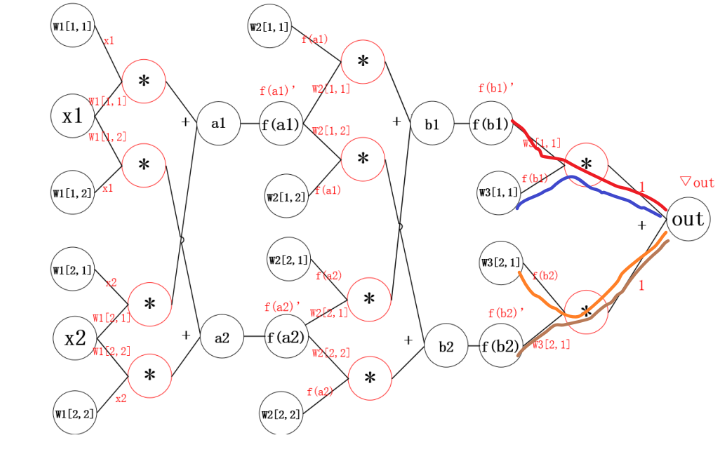
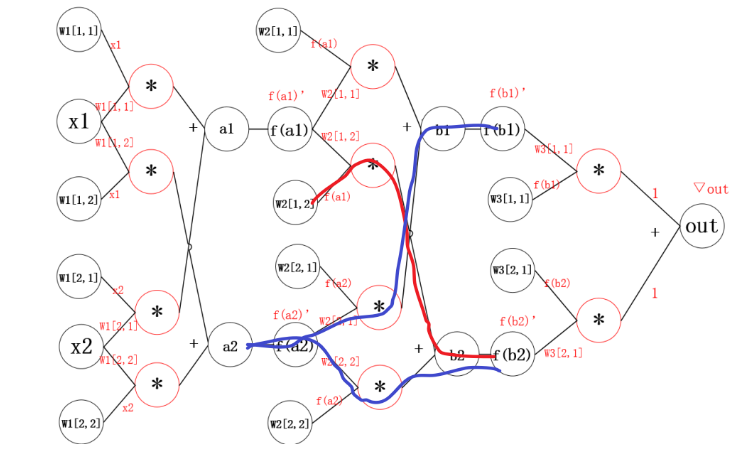
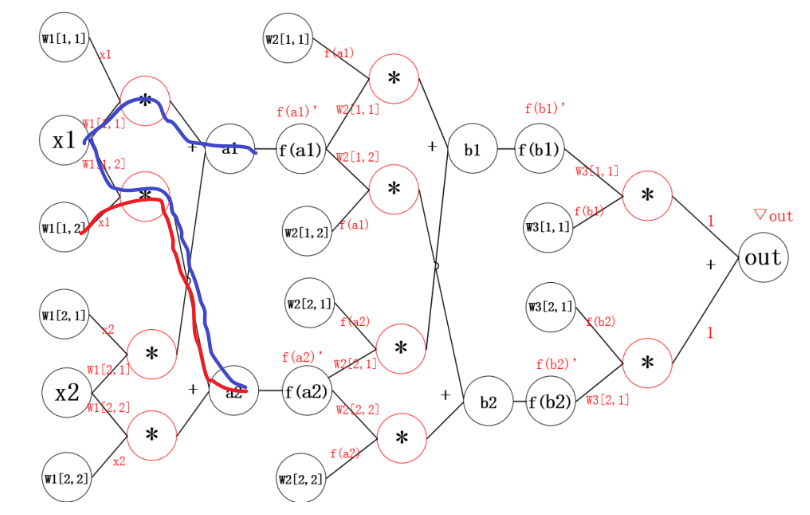
2.1 神经网络中的反向传播距举例
反向传播的思想就是对其中的某一个参数单独求梯度,之后更新。更新参数之后,继续反向传播。
3、线性回归举例
下面,我们使用一个自定义的数据,来使用torch实现一个简单的线性回归
假设我们的基础模型就是y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8来构造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8
- 准备数据
- 计算预测值
- 计算损失,把参数的梯度置为0,进行反向传播
- 更新参数
import torch
from matplotlib import pyplot as plt
#1. 准备数据 y = 3x+0.8,准备参数
x = torch.rand([50])
y = 3*x + 0.8
w = torch.rand(1,requires_grad=True)
b = torch.rand(1,requires_grad=True)
print('初始w={},b={}'.format(w,b))
def loss_fn(y,y_predict):
loss = (y_predict-y).pow(2).mean()
# 下述同等写法:[i.grad.data.zero_() for i in [w,b] if i.grad is not None]
for i in [w,b]:
# 每次反向传播前把梯度置为0
# 在默认情况下, PyTorch会累积梯度,我们需要清除之前的值
if i.grad is not None:
i.grad.data.zero_()
# 根据损失,反向传播计算梯度
loss.backward()
return loss.data
def optimize(learning_rate):
# print(w.grad.data,w.data,b.data)
# 由梯度与学习率,优化参数w,b的值
w.data -= learning_rate* w.grad.data
b.data -= learning_rate* b.grad.data
# 3000次epoch训练
for epoch in range(3000):
#2. 计算预测值
y_predict = x*w + b
#3.计算损失,把参数的梯度置为0,进行反向传播
loss = loss_fn(y,y_predict)
if epoch%500 == 0:
print(epoch,loss)
#4. 更新参数w和b
optimize(0.01)
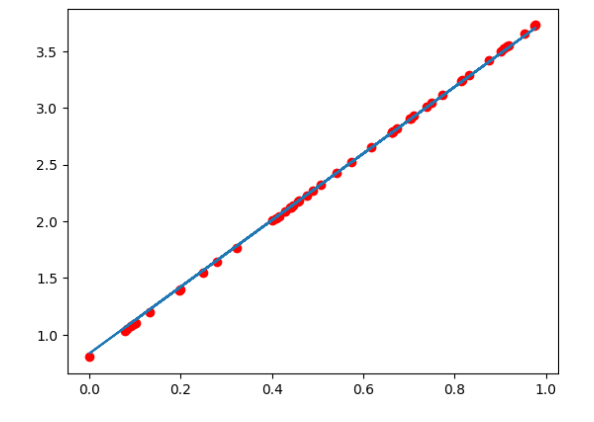
# 绘制图形,观察训练结束的预测值和真实值
predict = x*w + b
#使用训练后的w和b计算预测值
plt.scatter(x.data.numpy(), y.data.numpy(),c = "r")
plt.plot(x.data.numpy(), predict.data.numpy())
plt.show()
print("w",w)
print("b",b)
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 13
13 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)