计算机视觉:Vision Transformers
Vision Transformers是应用于视觉任务的Transformers模型。它们来源于ViT的工作,ViT直接将Transformer架构应用于不重叠的中型图像块上进行图像分类。1、Vision Transformer (ViT)Vision Transformer(简称ViT)是一种用于图像分类的模型,它在图像的补丁上采用了类似Transformer的结构进行图像分类任务。输入图像被分
Vision Transformers是应用于视觉任务的Transformers模型。它们来源于ViT的工作,ViT直接将Transformer架构应用于不重叠的中型图像块上进行图像分类。
1、Vision Transformer (ViT)
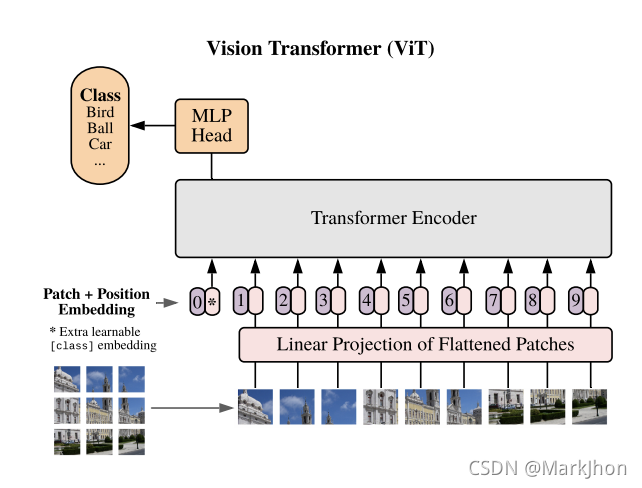
Vision Transformer(简称ViT)是一种用于图像分类的模型,它在图像的补丁上采用了类似Transformer的结构进行图像分类任务。输入图像被分割成固定大小的块,然后线性嵌入每个块,添加位置嵌入(Position Embeding),并将得到的向量序列送到标准的 Transformer 编码器进行学习。为了进行分类,在序列中添加一个额外可学习的“分类令牌”(classification token)。
Source:https://arxiv.org/abs/2010.11929v2
2、Swin Transformer
Swin Transformer 是Vision Transformer的类型。 它通过在网络结构中合并图像块(以灰色显示)来构建分层特征图,并且由于仅在每个局部窗口(以红色显示)内计算自注意力,因此对输入图像大小具有线性计算复杂度。 所以,它可以作为图像分类和密集识别任务的主干网络。 相比之前的Vision Transformer,以前的Vision Transformer只能产生单个低分辨率的特征图,并且因为要计算全局自注意力,对输入图像大小具有二次的计算复杂度。
 https://arxiv.org/abs/2103.14030v2
https://arxiv.org/abs/2103.14030v2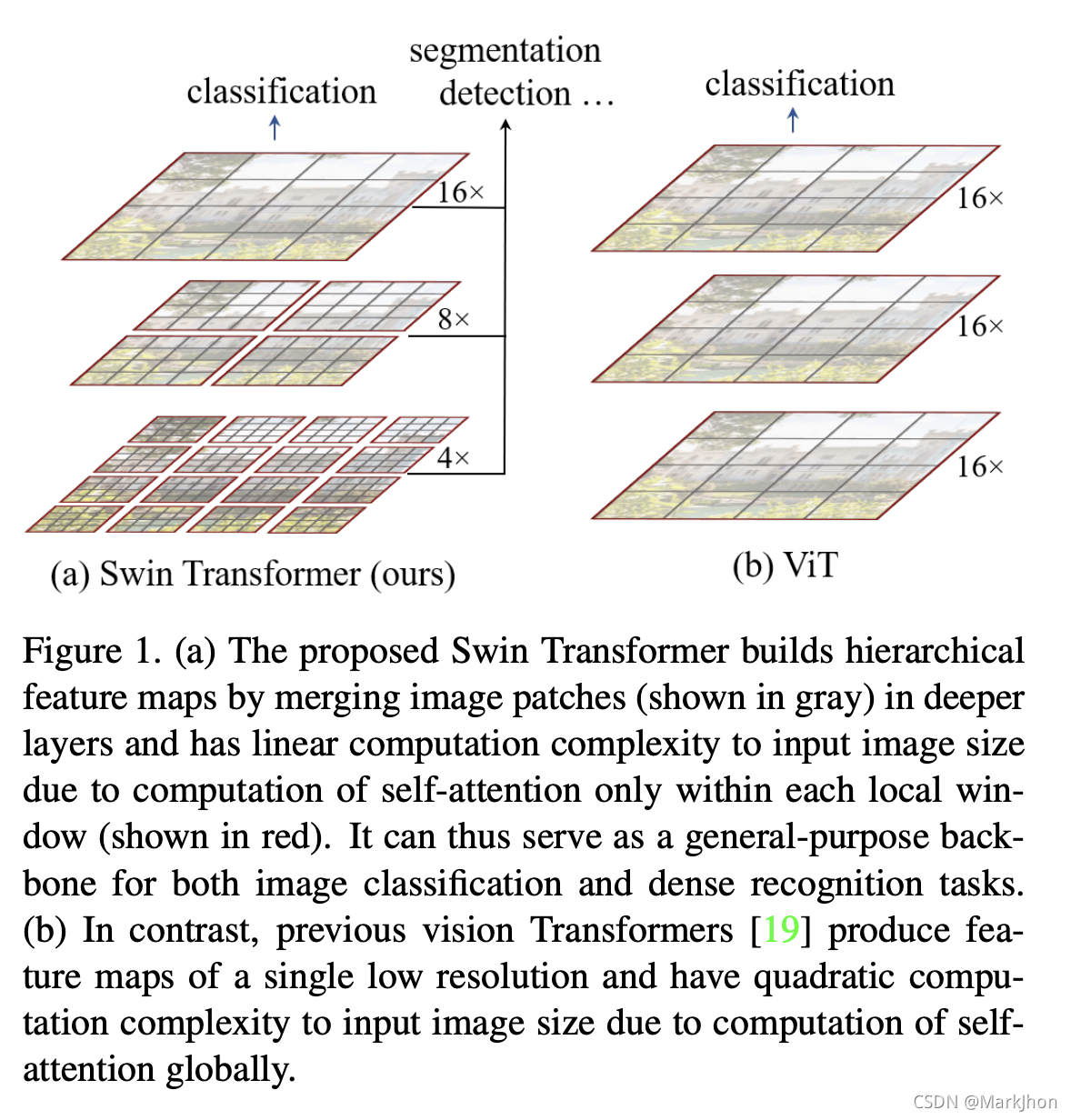
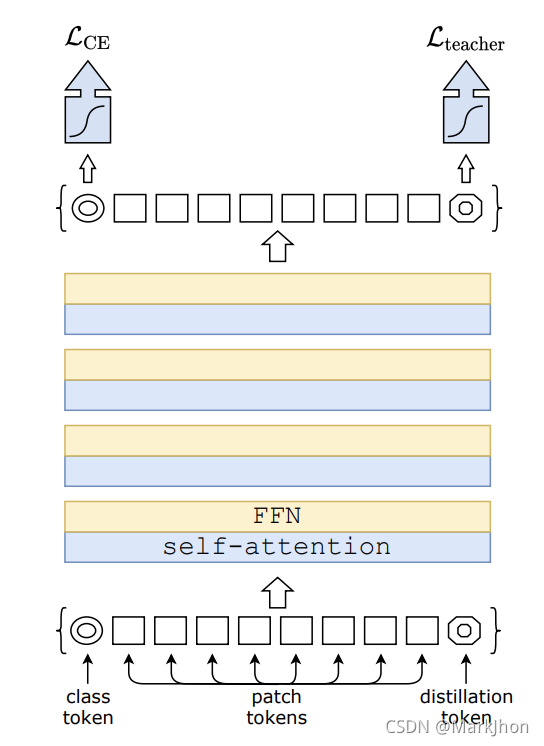
3、Data-efficient Image Transformer
Data-Efficient Image Transformer 是一种用于图像分类任务的视觉转换器。 该模型使用特定针对Transformer 的teacher-student策略进行训练。 它依赖于蒸馏令牌(distillation token),确保学生网络通过注意力向老师网络学习。
Source: Training data-efficient image transformers & distillation through attention

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)