大模型微调数据集怎么搞?基于easydataset实现文档转换问答对json数据集!
·
微调的难点之一在与数据集。本文介绍一种将文档转换为问答数据集的方法,超级快!
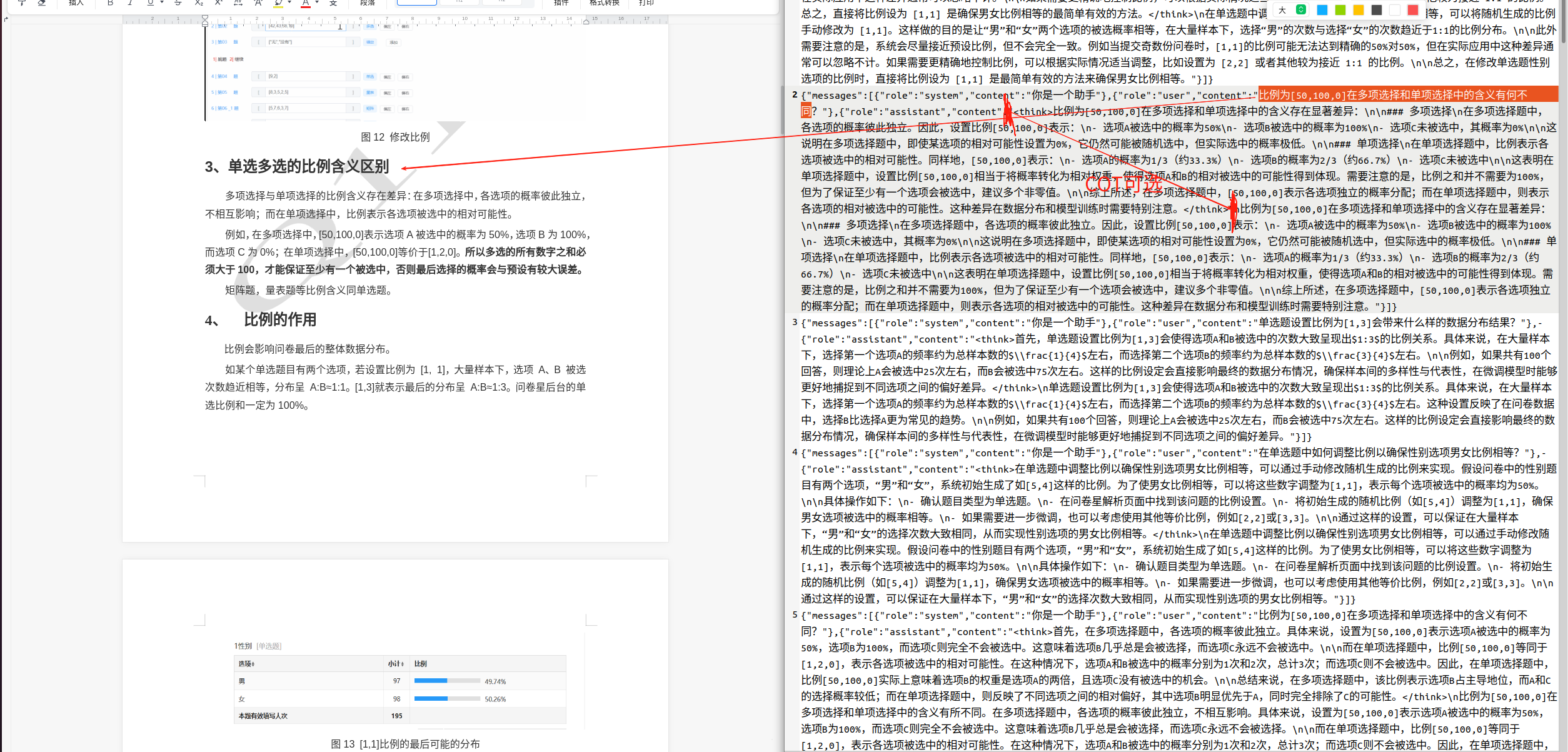
上图左侧是我的原文档,右侧是我基于文档生成的数据集。
原理是通过将文档片段发送给ollama本地模型,然后本地模型生成有关问题,并基于文档片段回答问题。需要用到的工具有ollama,easy-dataset: https://github.com/ConardLi/easy-dataset
ollama安装就不赘述了,easy-dataset是一个前端项目,只需要有nodejs就能运行起来了。
进入easydataset的运行界面,新建项目,会被要求添加模型。如果ollama在运行,easydataset能检测到已安装的模型。

首先需要将文档拆分成md格式,MinerU 可以很好做到这一点。
然后将md文件上传到easydataset,easydataset会将其拆分成若干个片段,并针对每个片段生成若干个问题,最后再对每个问题进行回答,问答对就完成了。
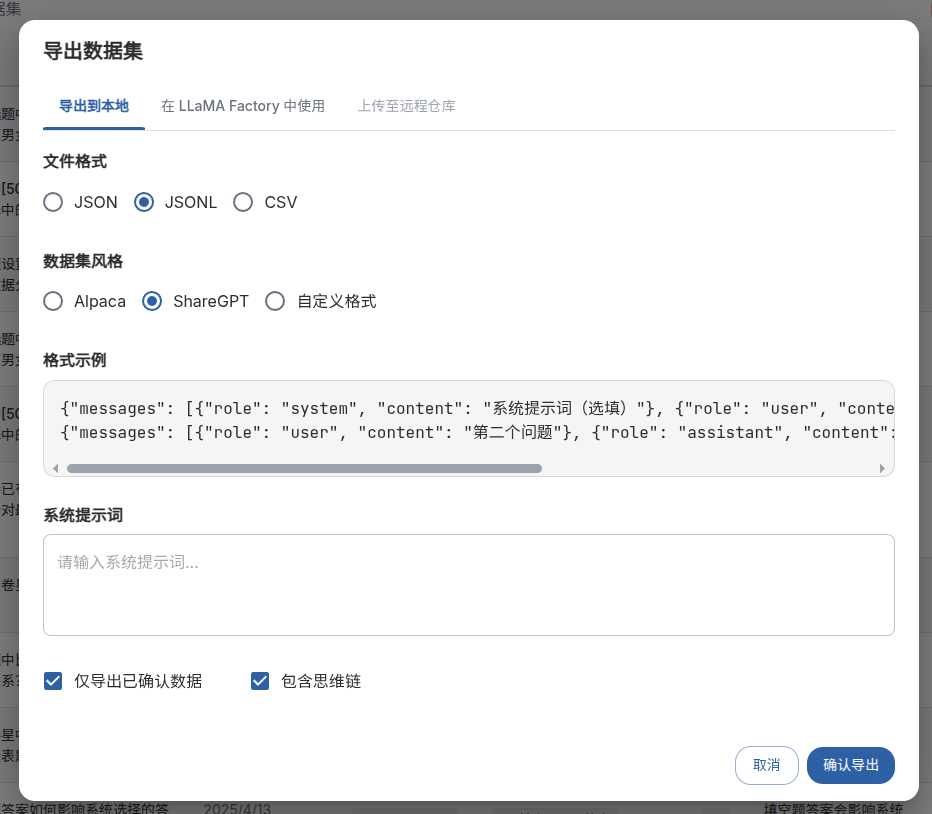
按照需要的格式导出,就能直接作为数据集文件了。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)