【自然语言处理|Transformer框架-05】:前馈全连接层、规范化层和子层连接结构
介绍Transformer架构中的前馈全连接层、规范化层和子层连接结构的原理及实现
·
1 前馈全连接层
前馈全连接层 (Multi-Head Attention) 概念:Transformer中前馈全连接层就是具有两层线性层的全连接网络
为什么需要前馈全连接层?
考虑注意力机制可能对复杂过程的拟合程度不够, 通过增加两层网络来增强模型的能力
class PositionwiseFeedForward(nn.Module):
# 传入输入的特征维度,输出的特征维度
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
# 定义线性层1
self.w1 = nn.Linear(d_model, d_ff)
# 定义线性层2
self.w2 = nn.Linear(d_ff, d_model)
# dropout层
self.dropout = nn.Dropout(p=dropout)
def foward(self,x):
x = self.w2(self.dropout(F.relu(self.w1(x1))))
return x
def dm04_test_PositionwiseFeedForward():
# 1 实例化PositionwiseFeedForward
d_model, d_ff = 512, 1024
my_positionwisefeedforward = PositionwiseFeedForward(d_model, d_ff)
print('my_positionwisefeedforward-->', my_positionwisefeedforward)
# 2 给模型喂数据
pe_result = torch.randn(2, 4, 512)
ff_result = my_positionwisefeedforward(pe_result)
print('ff_result--->', ff_result.shape, ff_result)

2 规范化层
规范化层(Normalization Layer)概念
- 是一种用于对输入数据进行归一化的重要组件。它通常紧随着每个子层的输出,以确保网络在处理数据时保持稳定的分布
- 规范化层实际上是一种归一化的操作,旨在使输入的均值保持接近0,标准差保持接近1
规范化层的作用:
- 防止梯度消失和梯度爆炸:在深度神经网络中,随着层数的增加,梯度很容易变得非常小(梯度消失)或非常大(梯度爆炸)。
- 规范化层通过将输入数据归一化,可以缓解这一问题,使得梯度的传播更加稳定。
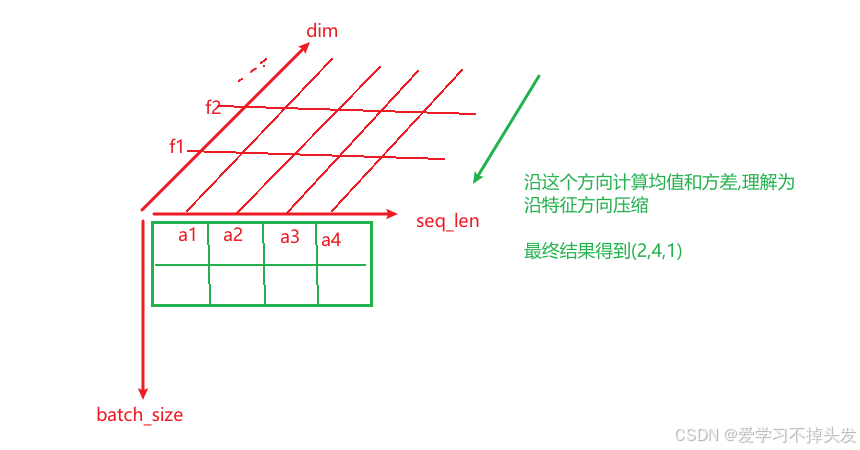
计算方式:
- 计算每个位置的所有特征维度上的均值和方差
- 然后对该位置的所有特征维度进行线性变换,以保证均值为0,方差为1
- 最后再进行缩放和平移操作,引入了可学习的参数(缩放因子和平移因子)。
# 规范化层 LayerNorm 实现思路分析
# 1 init函数 (self, features, eps=1e-6):
# 定义线性层self.a2 self.b2, nn.Parameter(torch.ones(features))
# 2 forward(self, x) 返回标准化后的结果
# 对数据求均值 保持形状不变 x.mean(-1, keepdims=True)
# 对数据求方差 保持形状不变 x.std(-1, keepdims=True)
# 对数据进行标准化变换 反向传播可学习参数a2 b2
# eg self.a2 * (x-mean)/(std + self.eps) + self.b2
# 1 按照批次,学习所有批次数据的均值和方差, 最终训练出来一个均值和方差,来更好的适应数据
# 2 到预测阶段,就要让这个值不要再变化,设置模型为:
# 2-1 model.eval()模式,在评估阶段 不让a2 b2这样的数据不发生变化
# 2-2 with torch.no_grad(): 在评估阶段,不进行梯度更新
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# features指的是特征数,每个指都需要进行变换
# 定义线性层参数 a2 相当于y = k x + b 中的k
self.a2 = nn.Parameter(torch.ones(features))
# 定义线性层参数 b2 相当于y = k x + b 中的b
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
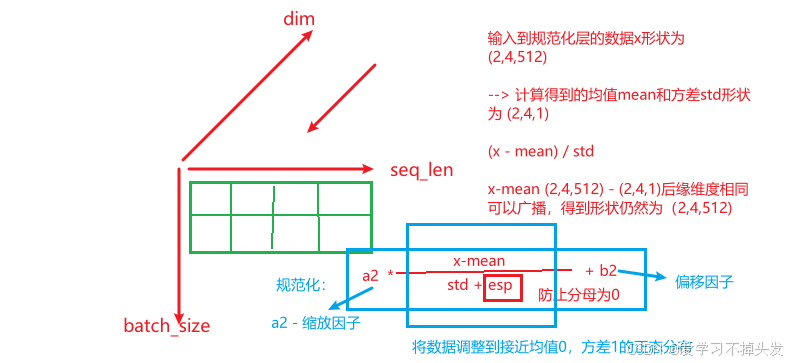
# 对数据求均值 保持形状不变 x.mean(-1, keepdims=True) # [2,4,512] --->[2,4,1]
mean = x.mean(-1, keepdims = True)
# 对数据求方差 保持形状不变 x.std(-1, keepdims=True) # [2,4,512] --->[2,4,1]
std = x.std(-1, keepdims = True)
# 对数据进行标准化变换后,在不同批次之间学习参数a2 b2 让模型对所有数据有更好的适应性
# 反向传播可学习参数a2 b2
y = self.a2 * (x-mean)/(std+self.eps) + self.b2
return y
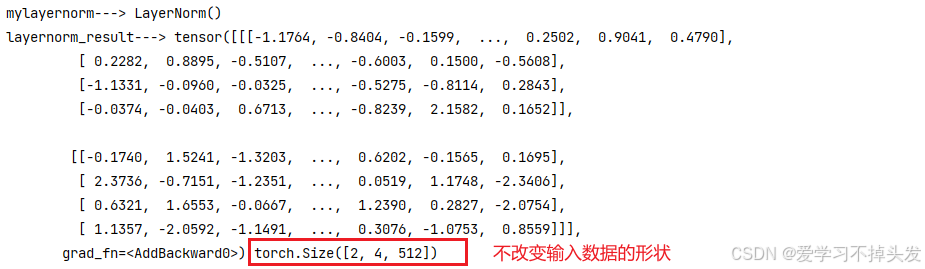
def dm05_test_LayerNorm():
# 实例化标准化层
mylayernorm = LayerNorm(512)
print('mylayernorm--->', mylayernorm)
# 给模型喂数据
pe_result = torch.randn(2, 4, 512)
layernorm_result = mylayernorm(pe_result)
print('layernorm_result--->', layernorm_result, layernorm_result.shape)
- a2 和 b2 是额外增加的权重参数,为了让模型更好适配不同批次的数据,学习不同批次之间的数据特征,能让模型有更好的泛化能力
- 原始数据调整为均值为0,方差为1的数据之后,再次经过线性变换
y = a2*x + b2 更好的适配不同批次的数据- a2 和 b2是模型参数,会随着反向传播,进行更新
- 按照批次,学习所有数据的均值和方差, 最终训练出来一个均值和方差,来更好的适应数据
- 到预测阶段,就要让这个值不要再变化,设置模型为:
- model.eval()模式,在评估阶段 不让a2 b2这样的数据不发生变
- with torch.no_grad(): 在评估阶段,不进行梯度更新
LayerNorm和BatchNorm的区别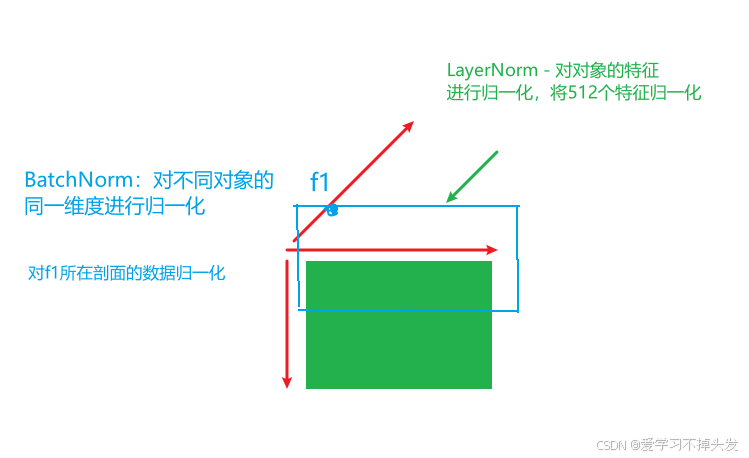
3 子层连接结构
子层连接结构组成
- 子层(多头注意力子层或者 前馈全连接层)
- 规范化层
- 残差连接
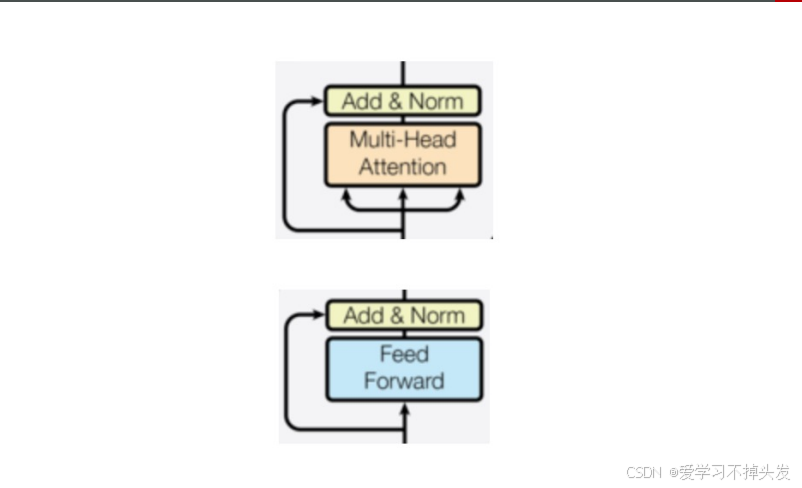
子层连接结构的设计思想:
- 功能上实现x+x2
- 设计思想:函数的入口地址做函数参
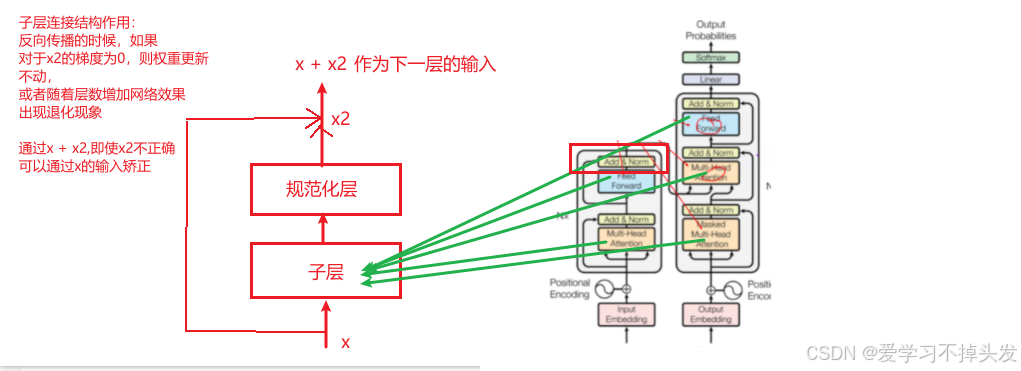
# 子层连接结构 子层(前馈全连接层 或者 注意力机制层)+ norm层 + 残差连接
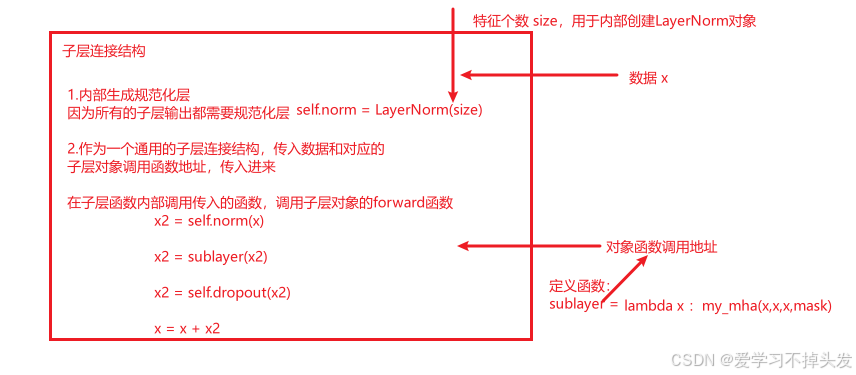
# SublayerConnection实现思路分析
# 1 init函数 (self, size, dropout=0.1):
# 定义self.norm层 self.dropout层, 其中LayerNorm(size)
# 2 forward(self, x, sublayer) 返回+以后的结果
# 数据self.norm() -> sublayer()->self.dropout() + x
class SublayerConnection(nn.Module):
def __init__(self, size, dropput=0.1):
super(SublayerConnection, self).__init__()
# 实例化规范化层对象
self.norm = LayerNorm(size)
# 定义dropout层
self.dropput = nn.Dropout(p = dropput)
# self.feed_forward
def forward(self, x, sublayer):
'''x -数据 sublayer回调函数的入口地址'''
# ====》self.feed_forward(x)
# self.self_attn(x) , self.self_attn(x,x,x,mask)
# 问题是:为什么 回调函数的入口地址为什么 self.feed_forward可以这样写
# 而 注意力机制的回调函数入口不能这样写self.self_attn(x)
# 答:注意力机制的回调函数入口这样写,掉不起来 。因为注意力机制的forward需要有4个参数
# x2 = self.norm(x)
# x2 = sublayer(x2)
# x2 = self.dropput(x2)
# x = x + x2
# 参数 x代表数据
# sublayer 函数入口地址 子层函数(前馈全连接层 或者 注意力机制层函数的入口地址)
# 方式1 如果采用前norm,编码部分最后要保证 再多加一个norm运行
x = x + self.dropput(sublayer(self.norm(x)))
# # 方式2
# x = x + self.dropput(self.norm(sublayer(x)) )
# # 方式3
# x = self.norm (x + self.dropput(sublayer(x)))
return x
def dm06_test_SublayerConnection():
size = 512
# 实例化子层连接结构对象
my_sublayerconnection = SublayerConnection(size)
print('my_sublayerconnection--->', my_sublayerconnection)
# 给模型喂数据
# 1-1 准备数据
x = torch.randn(2, 4, 512)
# 1-2 准备函数的入口地址
# 实例化多头注意力机制对象
mask = Variable(torch.zeros(8, 4, 4))
my_mha = MultiHeadedAttention(8, 512, 0.1)
# 构建多头注意力机制对象的forward函数的 入口地址
sublayer = lambda x:my_mha(x, x, x, mask)
# my_sublayerconnection为数据
sublayerconnection_result = my_sublayerconnection(x, sublayer)
print('sublayerconnection_result--->', sublayerconnection_result.shape, sublayerconnection_result)


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)