计算机视觉CV+数字图像处理
计算机视觉:图像形成;图像处理;模型拟合与优化;深度学习;深度估计;特征检测与匹配;分割;基于特征的对齐;运动估计;由运动到结构与 SLAM;图像拼接;计算摄影学;立体匹配;3D 重建;基于图像的渲染数字图像处理:图像感知与获取、图像取样和量化、灰度变换与空间滤波、频率域滤波原理、图像复原与重构、彩色图像处理、小波变换和其他图像变换、图像压缩和水印、形态学图像处理、图像分割、图像特征提取、图像模式
计算机视觉包括三个领域(R3):Recognition,Reconstruction ,Reorganization。
识别和检测只能是第一个R,SLAM算第二个R。图像处理属于计算机视觉的底层处理。增强现实AR、IBR、计算摄影是计算机视觉和其他领域如图形学、VR、成像学的交集。
计算机视觉目录:图像形成;图像处理;模型拟合与优化;深度学习;深度估计;特征检测与匹配;分割;基于特征的对齐;运动估计;由运动到结构与SLAM;图像拼接;计算摄影学;立体匹配;3D 重建;基于图像的渲染
数字图像处理目录: 图像感知与获取、 图像取样和量化、灰度变换与空间滤波、频率域滤波原理、图像复原与重构、彩色图像处理、小波变换和其他图像变换、图像压缩和水印、形态学图像处理、图像分割、图像特征提取、图像模式分类
1、立体匹配 Stereo correspondence
应用于,立体匹配是从图像生成三维点云的常规手段。
人根据左眼和右眼的外观差异来感知深度。简单的实验,将手指垂直地放在眼睛前面,交替地闭上每只眼睛,能看到手指相对于场景背景左右跳跃。1张图片无法测量物体深度,2张可以。
下图,两个相机拍摄同一场景,两个场景中相同的点就是一个同名点对,立体匹配就是寻找两幅图中所有的同名点对。

下图,一个概念“极线”约束。在这条极线上找同名点对。大大缩短了寻找同名点对的复杂程度。

下图,极线来源于极平面和相机平面的交线。极平面由两个相机和物体P三个点组成。

一个相机无法测距。下图,两个相机O1、Or,通过公式可以求出深度,就是物体P与相机的距离。视差和深度成反比。

2、SLAM
经典的运动重建(SFM,Structure From Motion),也叫做同步定位和制图(simultaneous localization and mapping,SLAM)。是假设场景静态情况下,通过摄像机的运动来获取图像序列,并得到场景3-D结构的估计。是计算机视觉的重要任务;在机器人领域,这个任务还会估计现场摄像头的姿态和位置,即定位任务。
基础知识
分辨率
分辨率的单位:PPI、DPI、LPI和PPD。
- PPI(Pixels Per Inch)。
每英寸像素数,用于描述屏幕或数字图像的分辨率,是衡量像素密度的标准单位。例如,手机屏幕的清晰度常用PPI表示。 - DPI(Dots Per Inch)。
每英寸点数,主要用于印刷领域,表示打印机输出的墨点密度。尽管常与PPI混用,但DPI更强调物理输出精度。 - LPI(Lines Per Inch)。
每英寸线数,用于印刷中的网线数,控制半色调图像的细节疏密,与专业印刷分辨率相关。 - PPD(Pixels Per Degree)。
像素每度,用于头戴显示设备如VR,衡量视场角内像素填充密度,直接影响视觉清晰度。
其他相关概念
- 像素(px):基础单位,表示图像或屏幕的最小显示单元。例如,1920×1080分辨率指水平1920像素、垂直1080像素。
- 位分辨率(BPP):每个像素的位数,决定色彩深度(如24位真彩色),但属于色彩信息单位,与分辨率无直接关联。
色彩模型
计算机常用的色彩模型主要包括以下几种,这些模型在不同应用场景中发挥着关键作用:
一、RGB模型
基于红(R)、绿(G)、蓝(B)三原色的加法混合原理,适用于屏幕显示和数字图像处理。每个通道取值范围为0-255,可组合生成1677万种颜色,是显示器、相机等数字设备的核心模型。
二、CMYK模型
基于青(C)、品红(M)、黄(Y)、黑(K)四色油墨的减法混合原理,专为印刷行业设计。通过油墨对光线的吸收实现色彩还原,确保纸质材料上的颜色准确性。
三、HSV/HSL模型
以人类视觉感知为设计基础:
- HSV:包含色相(H,0-360°)、饱和度(S,0-100%)、明度(V,0-100%)三个维度,便于直观调整颜色。
- HSL:类似HSV,但用亮度(L)替代明度(V),更符合设计师的调色习惯。
四、Lab模型
由国际照明委员会(CIE)制定的设备无关色彩空间,包含明度(L)和两个色度分量(a、b)。能覆盖最广的色域,常用于跨媒介色彩转换和高端印刷校对。
五、其他辅助模型
- YUV/YCrCb:主要用于视频编码,分离亮度(Y)与色度(UV)信号,减少传输数据量。
- 灰度模式:仅用单一通道表示明度,适用于黑白图像处理。
这些模型通过不同的数学表达方式,分别服务于显示技术、印刷工艺、设计调色及科学计算等领域,共同构成了数字色彩管理的核心框架

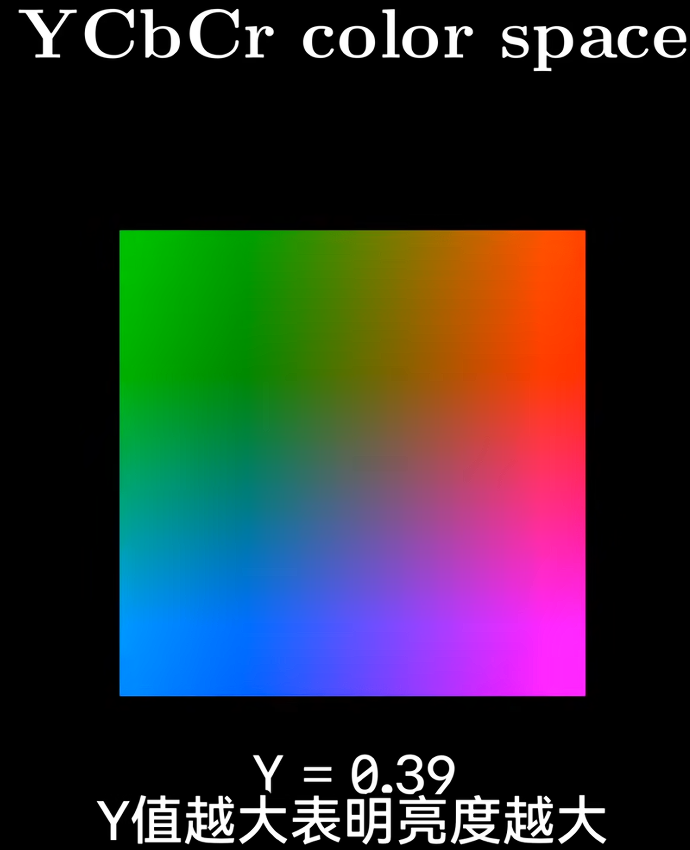

颜色几何学
颜色的“几何学” - ScienceClic English_哔哩哔哩_
视频内容:色彩空间的发展历史。
引子问题:在色彩相关的软件中,拾色器有很多种形式,它们是如何工作的?
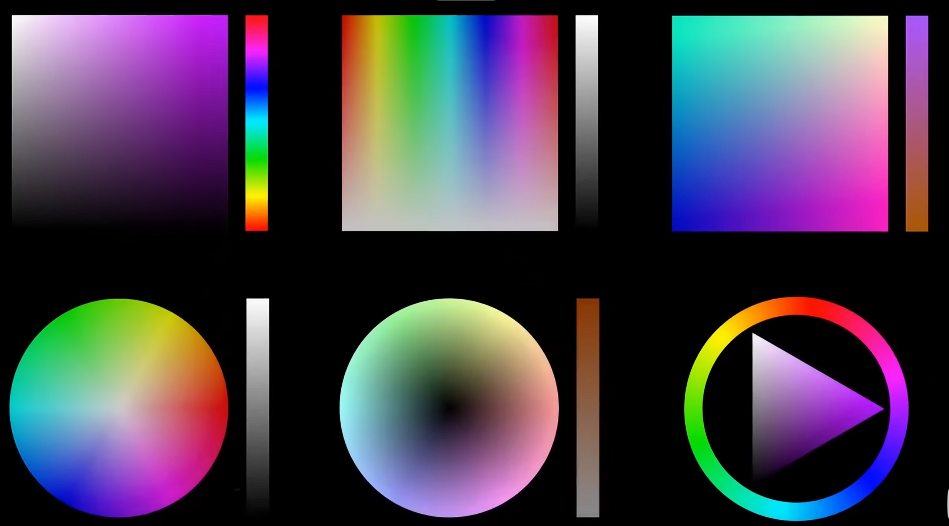
颜色是一个跨学科问题,包括:物理学、生物学、数学、心理学。颜色科学依然是一个活跃的研究领域,比如薛定谔认为色彩空间是非欧几何,像广义相对论里的时空。
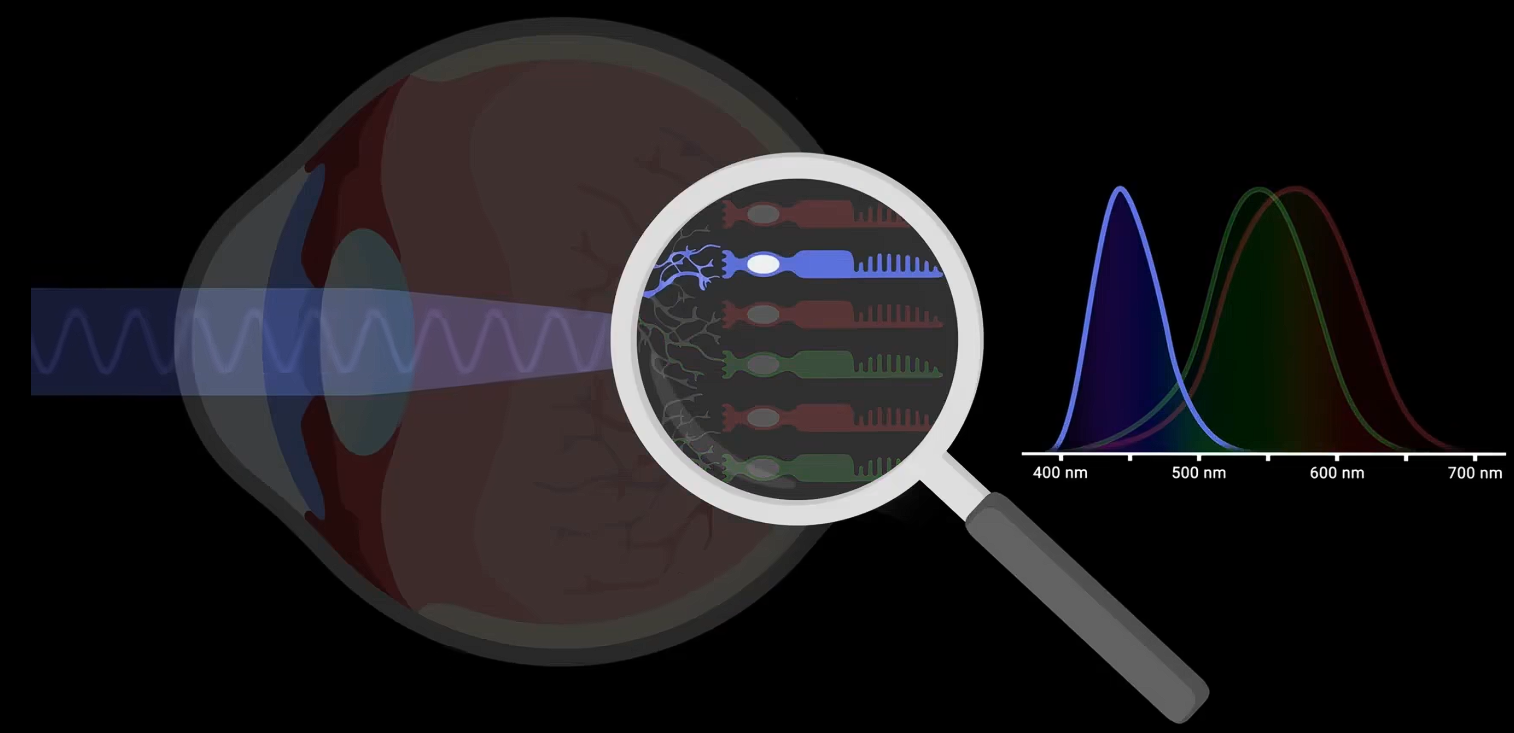
什么是颜色?物体本身是没有“颜色”的,颜色是人类的一种感觉。当眼睛接收到光线时,比如太阳光,太阳光由多种波长/颜色的光组合,物体吸收一部分光,再反射一部分光。
- 比如,植物表皮色素(尤其是花青素)吸收短波光(如蓝紫光400-500纳米)并反射长波光(如红光600-700纳米),这正是花朵呈现红色、紫色等鲜艳色彩的关键。
- 人类的眼睛对不同波长光敏感,将信号传递给大脑,大脑将其解读为颜色。
1637年法国数学家笛卡尔的著作《方法论》。在附录中,他探讨了折光学、流星学、几何学等多个领域。《流星学》中说虹的现象是阳光通过水滴的折射而产生的自然现象,牛顿受到他的启示。1666年牛顿在剑桥大学进行了一系列光学实验,最著名的是光的色散实验。
- 在暗室中,让一束细小的太阳光穿过三棱镜,投射到对面的墙上。这束白光被分解成了连续的、绚丽的彩色光带,即光谱(spectrum)——这个词正是牛顿创造的。原理在于不同颜色的光波长不同,在棱镜中折射率不同,导致它们偏折的角度有差异。
- 他再用第二个棱镜去投射光谱中的某一种单色光(例如红色光),发现这束红光穿过第二个棱镜后,仅仅是发生了折射,颜色和性质并未改变。
- 这证明了,白光是由这些具有不同折射率的单色光组成的混合物,而棱镜的作用仅仅是将它们分离开来,而非创造出颜色。这一发现奠定了现代物理光学的基础。
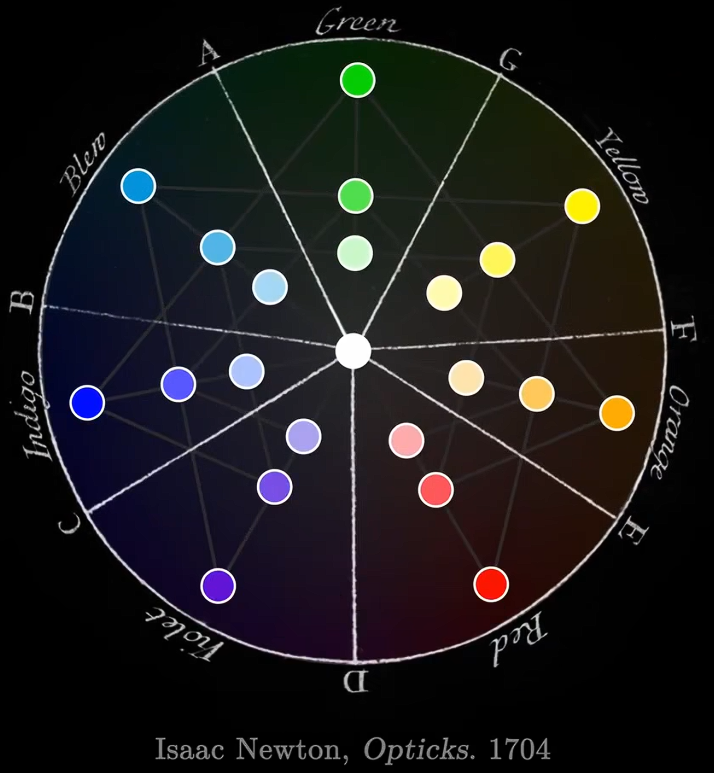
牛顿在1704年出版的划时代著作《光学》(Opticks)中,明确提出了光谱由七种基本颜色组成:红Red、橙Orange、黄Yellow、绿Green、蓝Blue、靛Indigo、紫Violet。光谱划分为七种颜色,这一决策深受牛顿个人世界观和当时文化背景的局限。牛顿对宇宙和谐有序的信念,他发现光谱中七种颜色的宽度比例与西方音乐中的七个自然音阶的音程间隔存在着惊人的相似性???他试图构建一个包含声音、颜色和行星轨道的宏大和谐宇宙模型。在西方文化传统中,数字“七”长期以来被赋予特殊的、甚至是神秘的意义。例如,一周有七天,天上有七个(当时已知的)行星,古代世界有七大奇迹等等。这种文化上的偏好可能潜移默化地影响了牛顿的分类决策。

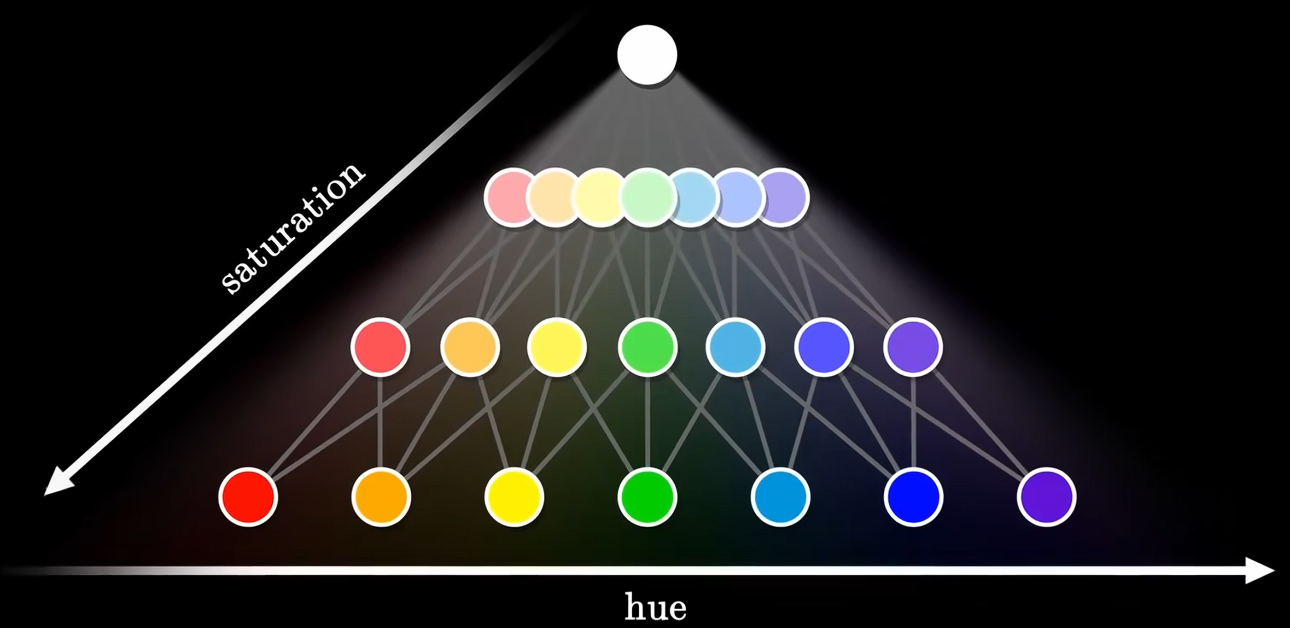
下一步,尝试将纯色混合。红色和黄色混合得到橙色,蓝色和绿色得到青色...它们与光谱上的纯色略有不同,纯度较低,更接近白色。通过将光谱中的颜色相互混合,我们构建了一个全新的维度:饱和度saturation,也称作纯度。它衡量的是接近光谱纯色的程度,越大越纯色彩越鲜艳。
注意区分:光的混合VS颜料混合
- 光的混合。本节讨论对象,各种波长的光的叠加。称为“加色合成”。加色法(如RGB)将色光“叠加”,适用于主动发光源。
- 颜料的混合。正好和光混合相反!遵循“减色原理”,减色法从白光中“减”去色光,适用于被动发光物体。颜料选择性吸收白光中的某些色光,反射剩余部分形成颜色。常见应用:印刷(CMYK四色模式)。

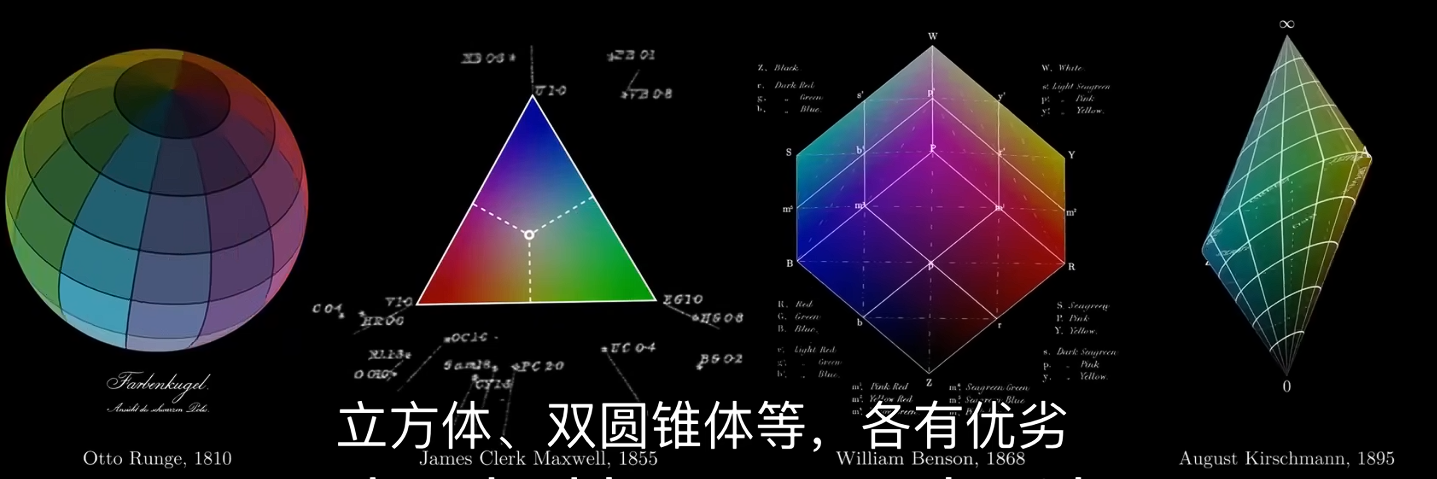
牛顿并未采用这种金字塔状的方式来组织颜色,而是提出了一种新的几何模型:
- 他将光谱首尾相连形成一个圆环,并将白色置于中心。
- 两种色光混合时,其混合色光会位于两点之间的中点。因此可以通过几何方式预测色光混合。
- 互补色位于中心点的两侧,它们相加会得到白色。
- 通过色光混合,能得到光谱中没有的颜色???
- 再加入第三条轴——光强,就能得到从白色到黑色所有中间色光。形成了完整的色彩空间,形状是一个圆锥体。在这个抽象空间里,颜色的属性便转化为几何关系。
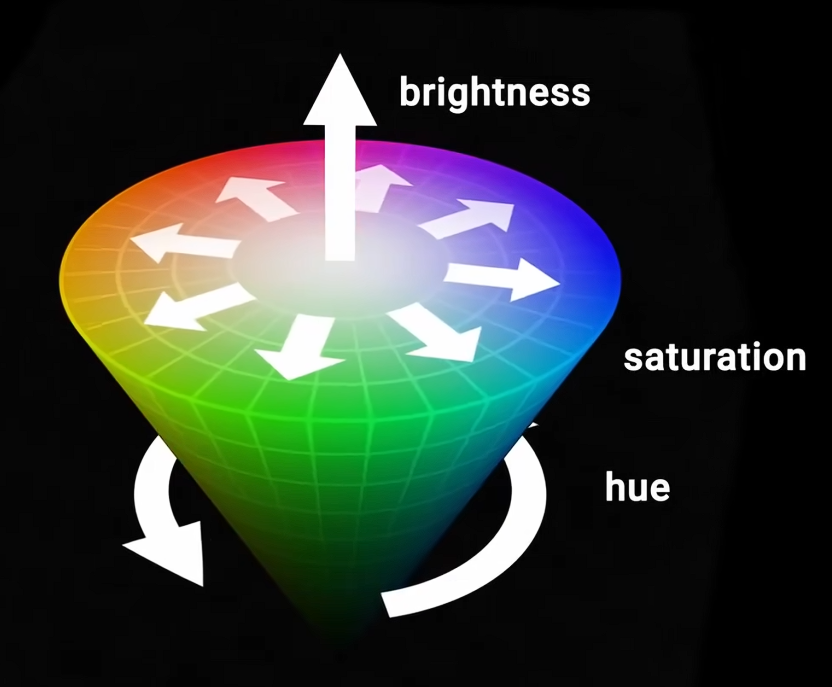
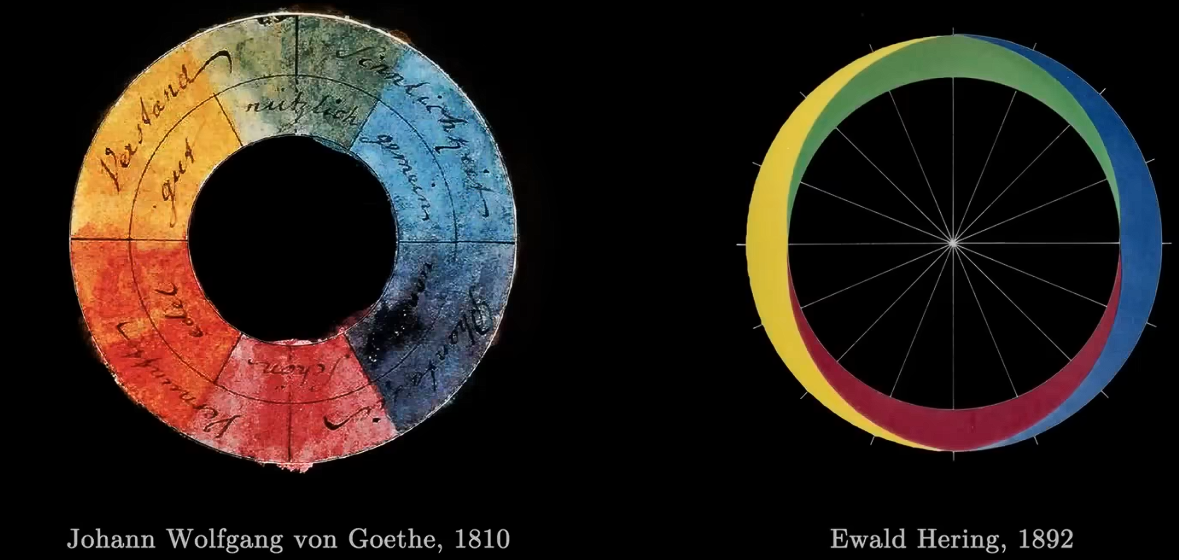
其他几何形式的色彩模型包括,如图,注意时间。
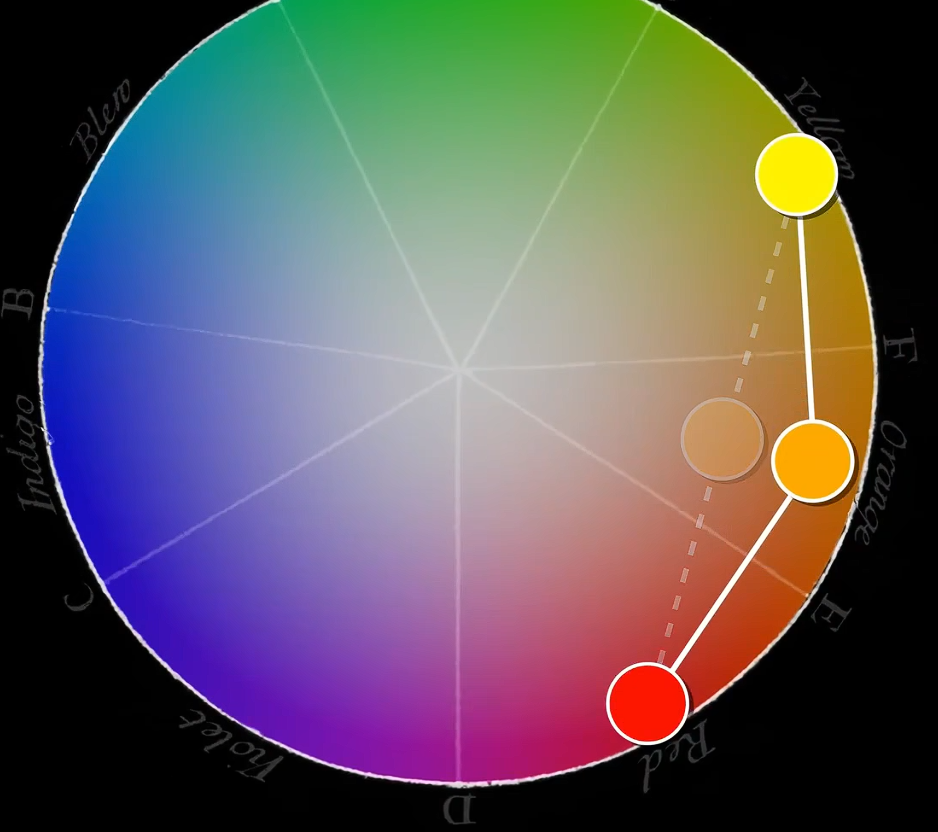
牛顿色环的错误:
- 两种色光的混合色光位于中点❌比如,如图,红色和黄色的混合色不在直线中点。
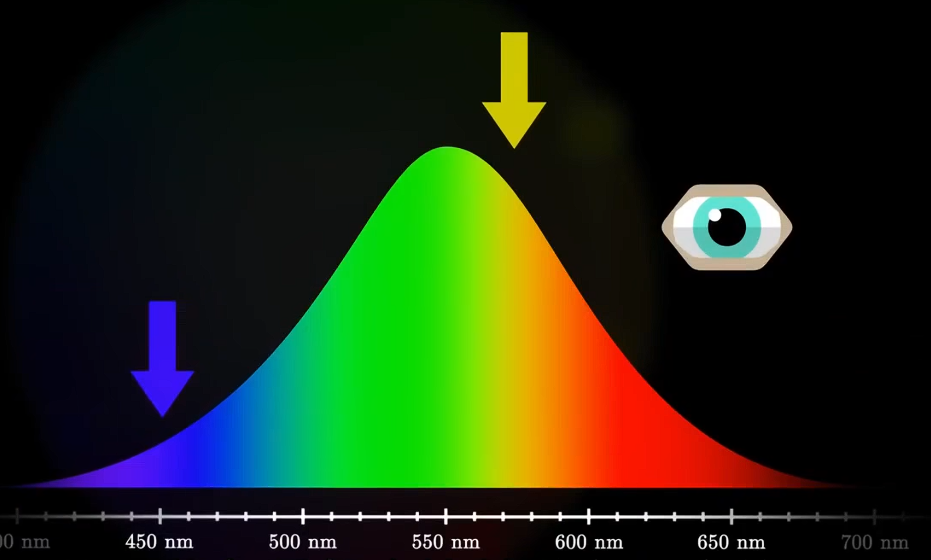
- 人眼对中波长的光更为敏感。如图。这就是黄色看起来比靛蓝色更亮的原因。
- 根据人眼的敏感性调整色环后,互补色位相加也不再是中间的白色,而是偏移一边。
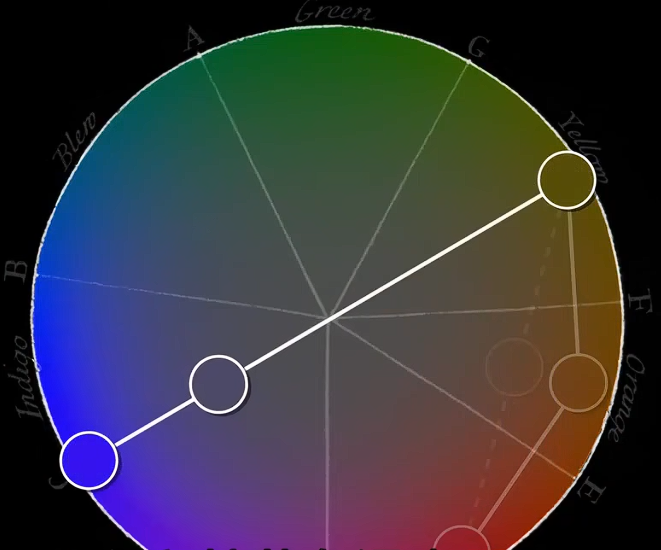
赫尔姆霍兹(1821-1894)解决了牛顿色环部分问题。他通过扭曲色环来实现。
- 比如,连接红色和黄色的部分应该几乎是平的,因为它们的混合色接近光谱纯色。
- 靛蓝色应该比黄色离白色更远,因为混合得到白色需要更多的黄色而非靛蓝色。
- 最后,紫色应该位于一条直线上而非曲线上,因为它们对应的是光谱两端之间的渐进混合色。
- 这样,赫尔姆霍兹得到了一个马蹄形的示意图。

区别violet和purple。Violet(紫罗兰色)是光谱中颜色,波长较短(380-450nm),偏蓝调;Purple(紫色)是红蓝混合的二次色,偏红调,非光谱色。 Violet 用于自然物(如紫罗兰花朵)。Purple用于人工物(如三角梅或染料)。
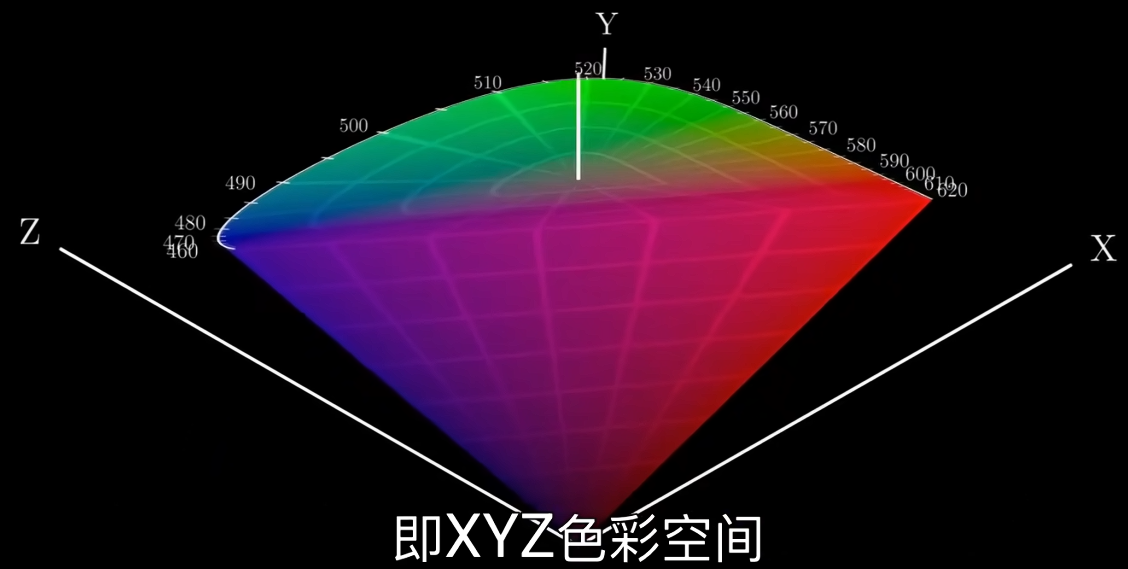
1931年,国际照明委员会CIE,改进赫尔姆兹的版本,形成标准XYZ色彩空间。
- 这是一个数学空间,马蹄形截面的圆锥,颜色可以像矢量一样被相加以计算混合色。
- 这个圆锥可以无限延伸,以表示任意强度的光。但如果限定每个波长的最大能量,就会得到一个有限的体积,即最优色立体Optimal solid。是人眼观能察到的颜色。
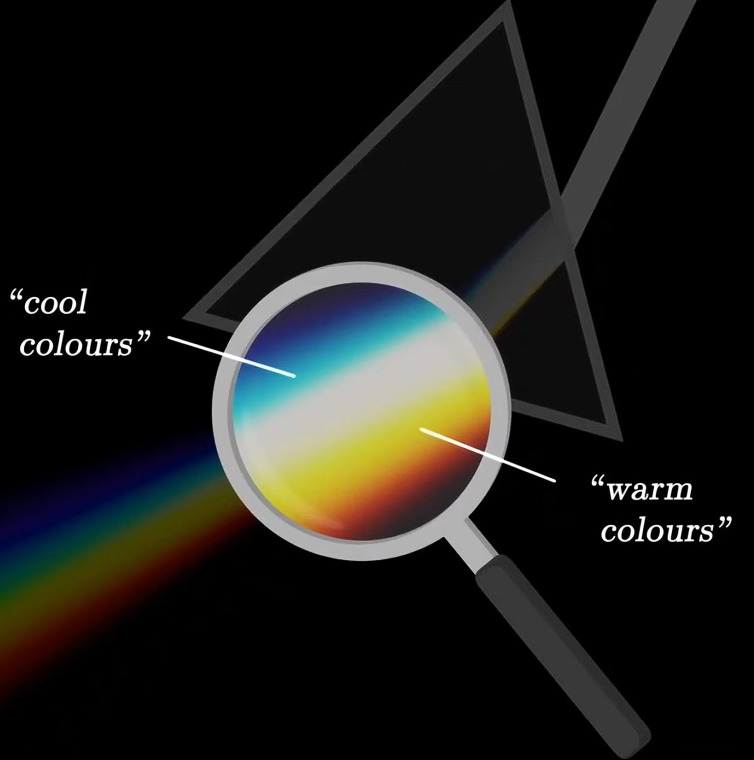
- 最优色立体的边界是每种色调能达到的最鲜艳的色度。黑色与白色相连的棱边为:黑-红-黄-白以及白-青-蓝-黑,这种渐变我们可以在棱镜附近观察到,在那里波长并未被完全分离,艺术家们称之为暖色和冷色。


目前的电子设备显示的颜色并不准确。通过为每个像素混合三种原色光:通常是红、绿、蓝。根据这三种光的强度,屏幕可以在一个立方体内合成颜色。这就是sRGB色彩空间。缺点是
- 对于大多数图像来说,这些颜色够用,但会错过一些非常鲜艳的色彩。
- 色盲占5%。大多是男人。遗传因素。人的眼睛依靠3种受体,即视锥细胞,它们分布在视网膜上,分别对三种特定波长范围的光产生反应,大概对应红、绿、蓝。大脑根据这3种信号构建感知到的颜色。所以色彩空间是3维的。色盲者的视网膜或视觉系统存在缺陷,因此他们所能感知的色彩空间便缩小了,具体取决于哪些受体受损。色盲有多种类型,每种都有其对应的色彩空间,有时仅跨越两个维度,甚至只有一维度。
- 克里斯汀·拉德·富兰克林提出色觉进化:最初眼睛只能区分一个维度,即明与暗;第二个维度区别长波与短波,即黄与蓝;第三维度则能区分长波与中波,即红与绿。远古祖先还能感知第四维度,即紫外线波段,许多动物至今仍保留着这种能力。但许多哺乳动物只能感知二维色彩,因此老虎的花纹依然是完美伪装。

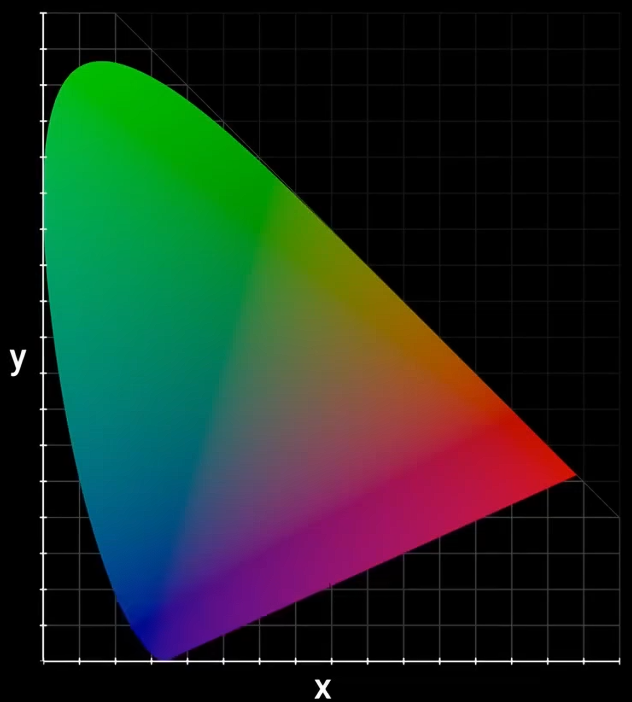
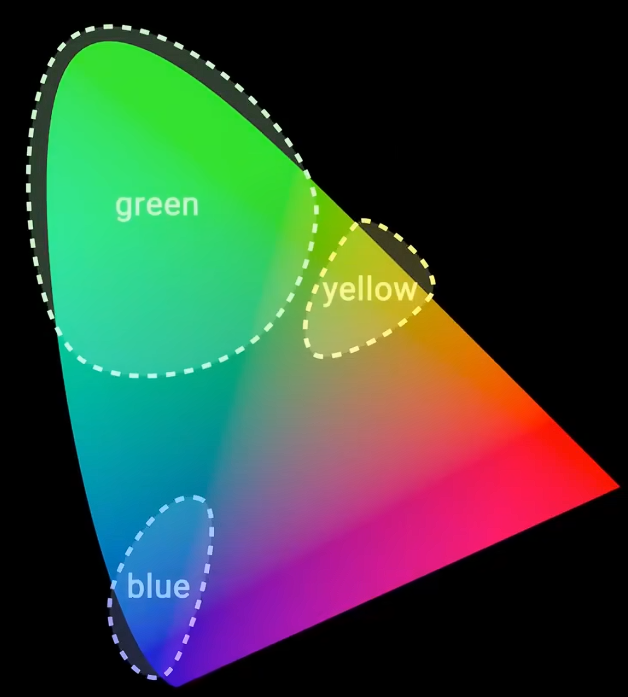
尽管这些图表在数学上很有用,但它们并未反映出人类从感官上对颜色的实际感知。比如,
- 绿色区域明显比黄色和蓝色区域大得多。
- 颜色之间的距离与我们的感知毫无关系。有些颜色在图中的距离很远,看起来却很相似。
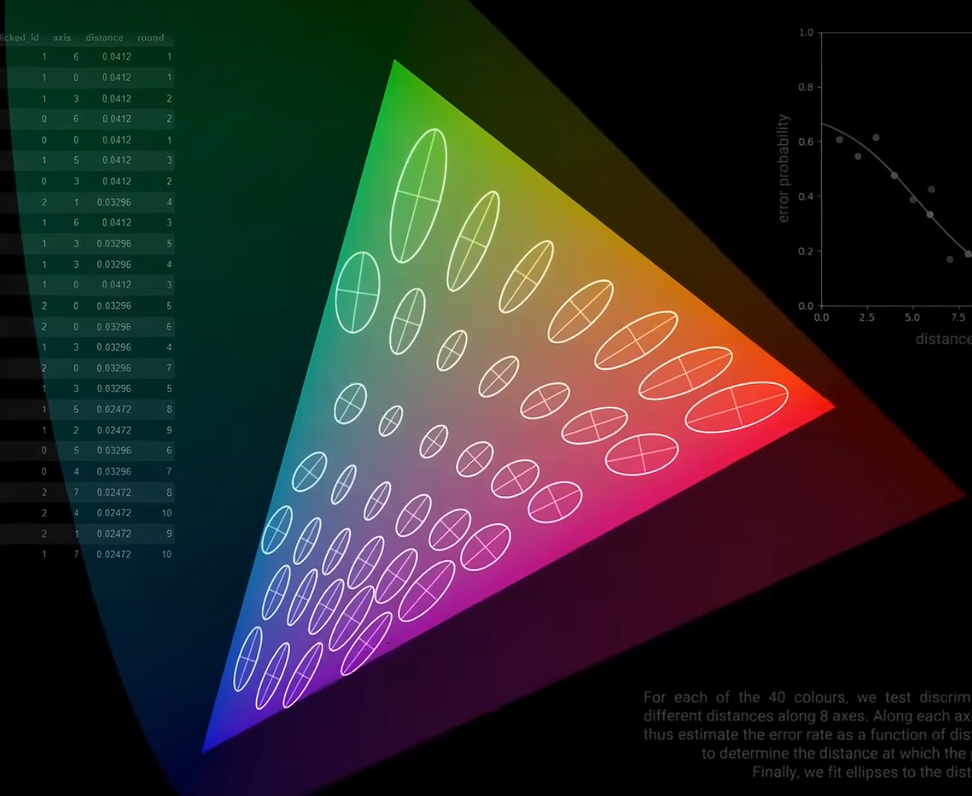
- 经过大量测试,绘制出一组椭圆,每个椭圆内的颜色是人眼无法区分的。这些椭圆在大小和方向上各不相同,比如蓝色区域的椭圆在纵向比横向更难区分。
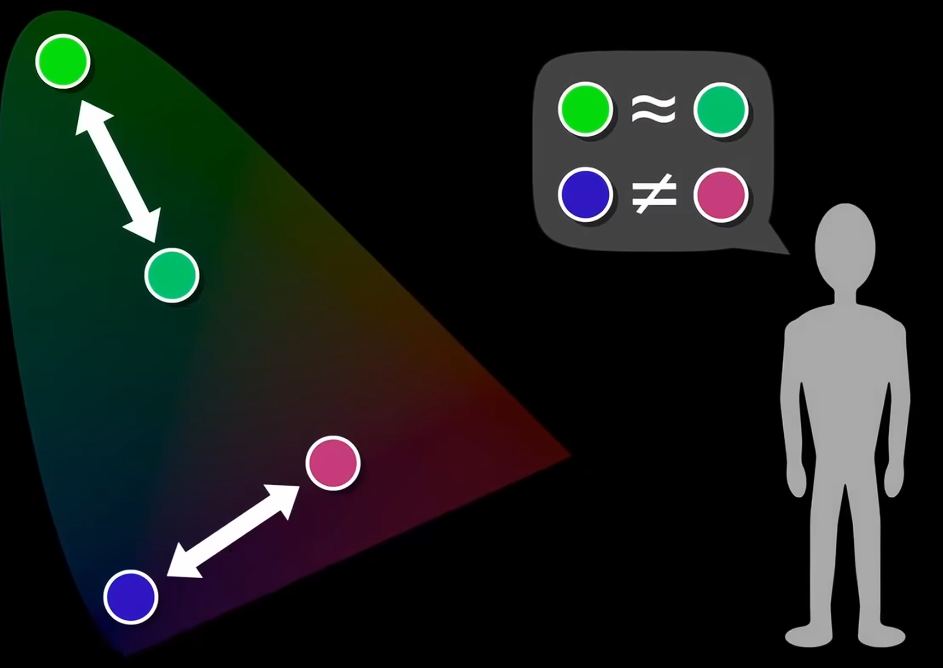
因此,又出现了色彩的心理学方法。试图直接依据感觉来组织颜色。
- 他们认为我们的感知基于几组根本的对立关系,黑白、红绿、黄蓝。这种理论目前认为有效,因为和视网膜功能对应。
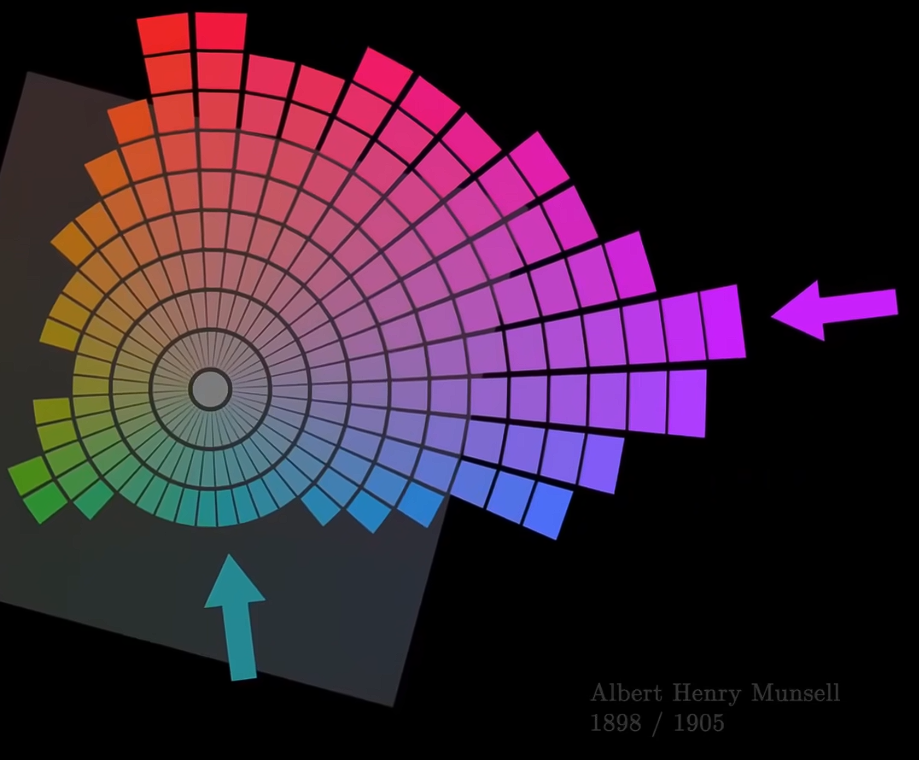
- 经过精确的测量得到著名的孟塞尔系统,它不规则的几何形状贴切地模拟了我们对不同色调的感知。不同色调在不同亮度下达到的饱和度不同,如黄和蓝。某些色调也往往比其他色调看起来更鲜艳,比如洋红色比青绿色鲜艳。
- 随之出现了“心理物理学”,试图用函数描述人类感知。比如,线性变化的黑白条,然而暗部区域的变化比亮部更明显。


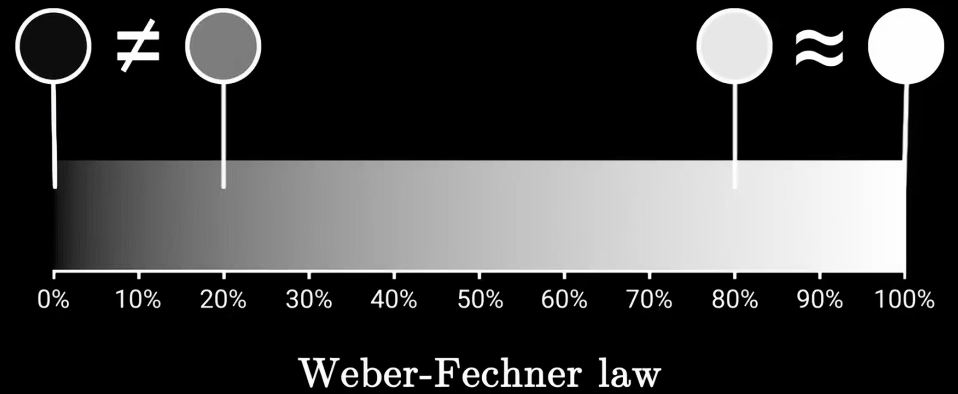

考虑到以上的这种韦伯-费歇尔效应,创建出在感知上更均匀的渐变。对色彩空间的3个维度都这样渐变处理,就能得到更均匀的颜色分布,比在基础空间中更平滑、更规律,这就是LAB色彩空间创立的原则。对立轴设置了:黑白、黄蓝、红绿。
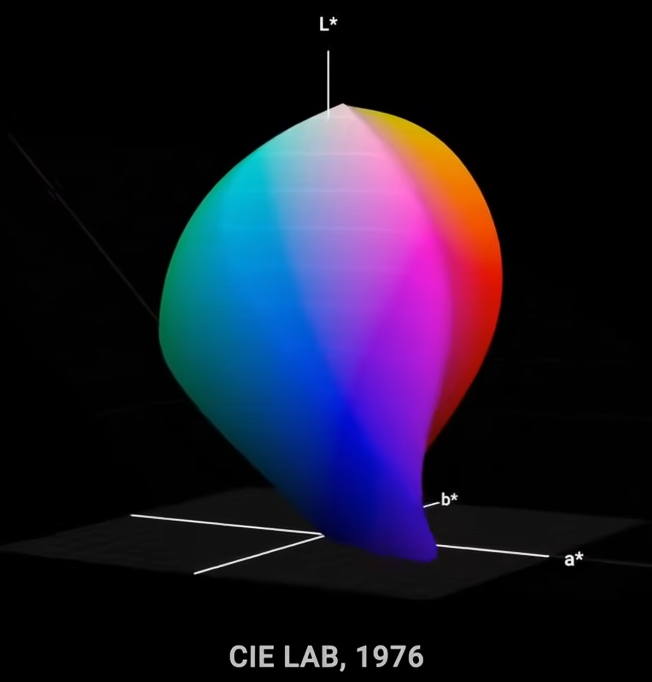
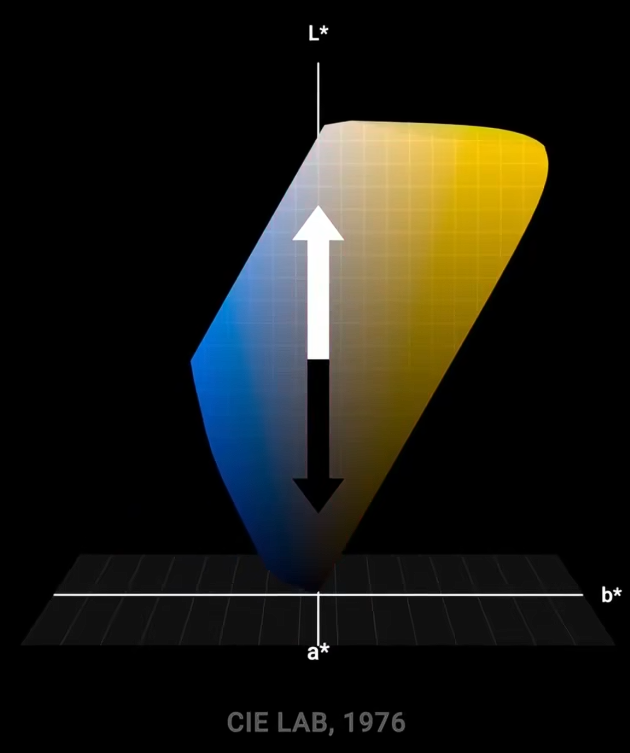
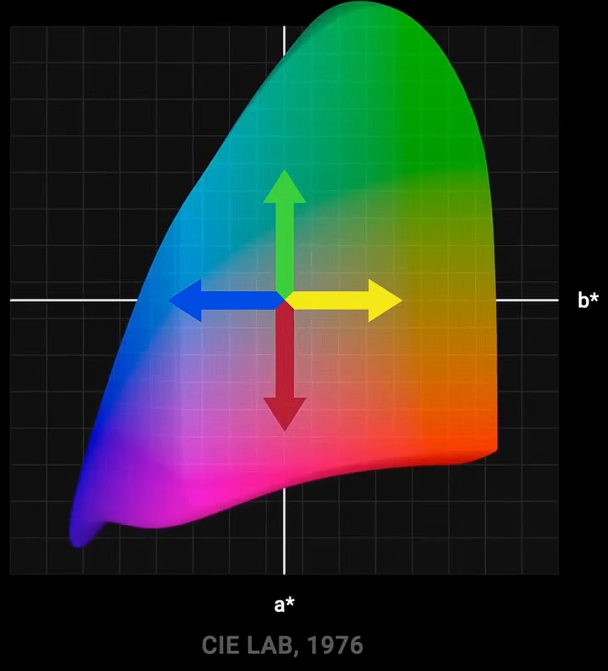
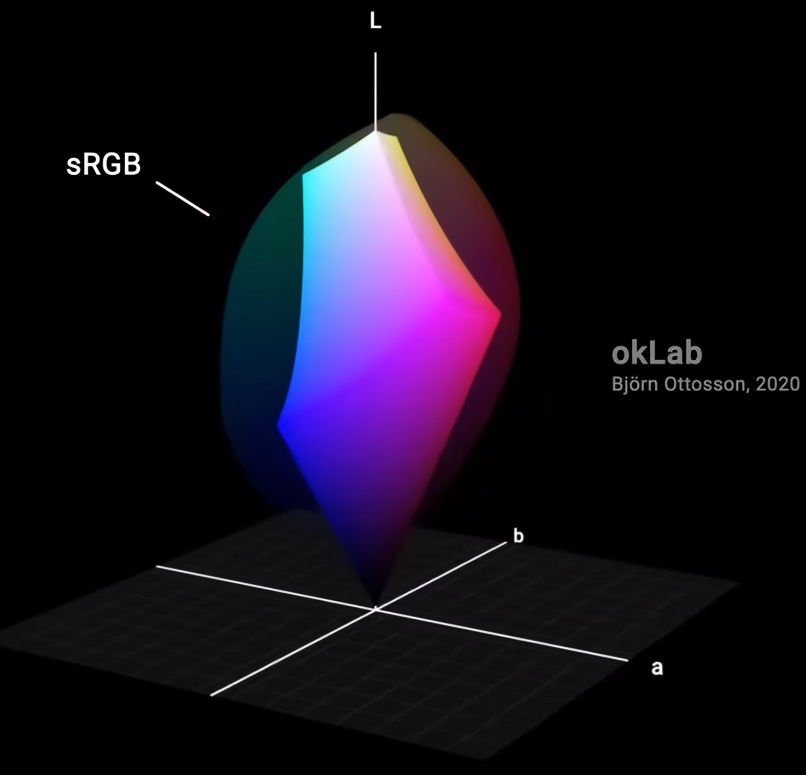
2020年,比约恩·奥特森提出了更精确的okLab。其几何形状类似于变形的水滴,或是一个倾斜的双圆锥体。对应的拾色器如图。

为了克服牛顿分类的模糊性和主观性,并满足工业、艺术和科研的精确需求,现代色彩科学发展出了多种更为先进的色彩分类和测量系统。这些系统可以分为两大类:
- 基于感知的颜色顺序系统:根据人类对颜色的主观感知(而非物理测量)来组织颜色。孟塞尔颜色系统(Munsell Color System)20世纪初创建,它根据颜色的三个基本属性——色相(Hue)、明度(Value)和彩度(Chroma)——来定义颜色,并将它们排列在一个三维的颜色空间中。自然色彩系统NCS(Natural Color System)人类感知的六种基本色(白黑红黄绿蓝),通过描述任何颜色与这六种基本色的相似度来定义颜色。
- 基于物理测量的量化色彩系统(色度学):科学和工业界主流方法,为颜色提供唯一的数字坐标。CIE色彩空间,由国际照明委员会CIE制定的国际标准。其中最基础的是CIE 1931 XYZ色彩空间。它将人眼能看到的所有颜色都映射到二维的色度图(Chromaticity Diagram)上。光谱色(即单色光)在色度图上形成一条马蹄形的边界曲线。
《几何学》共分为三卷:第一卷讨论尺规作图;第二卷深入研究曲线的性质;而第三卷则探讨了立体和“超立体”的作图问题,实质上是在探讨方程的根的性质。中心思想是建立一种能够统一算术、代数和几何的“普遍”数学。通过代数方法研究曲线的性质,将任何数学问题都转化为代数问题来解决。因此,《几何学》被视为解析几何的起点。
16世纪以后,随着生产和科学技术的迅猛发展,涌现出一系列重大事件。例如,德国天文学家开普勒揭示了行星沿椭圆轨道绕太阳运行的规律,太阳位于其中一个焦点上;而意大利科学家伽利略则发现了投掷物体遵循抛物线运动的原理。这些发现均与圆锥曲线紧密相关。
公开图片数据集

matlab计算机视觉和图像处理
图像处理
在matlab里有很多app可以直接使用,实现图像处理。比如,image labler图像标注,image segment图像分割。matlab官方视频中介绍了几种app的用法。
完整的例子:摄像机实时检测糖果数量。关键软硬件:图像分割app软件;webcam硬件支持包。

计算机视觉
使用人工智能、机器学习的算法处理图像。
例1:ocr文字识别。
可以使用OCR trainer app,,可以自定义识别的字符,但是我的matlab没有这个app????;还可以使用trainOCR函数,并有例子,用下面语句打开。
openExample('vision/TrainAnOCRModelExample')
例2:实现“你画我猜”。
不用现成的app,而是通过机器学习和已有数据训练一个模型,选择一个最佳模型实现。
模型训练使用机器学习的分类学习器app。
JPEG格式
joint Photographic Experts Group。1986年由国际电话与电报咨询委员会CCITT与ISO联合成立。连续色调、多级灰度、静止图像的数字图像压缩编码方法,即JPEG算法。扩展名.jpg.jpe.jpeg。
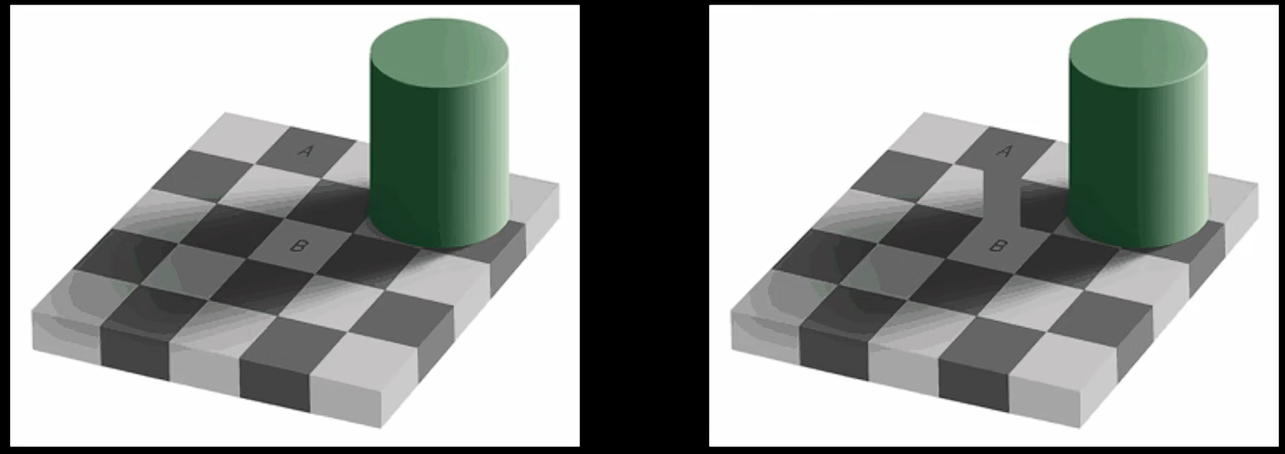
利用人眼特点,对亮度敏感、对色差不敏感。大小是普通图片十分之一程度。网络中86%静态图片是jpeg格式。 但是现在存储能力提高后无损压缩PNG也不少。人眼对色差不敏感的例子,如图。A、B是同色的。
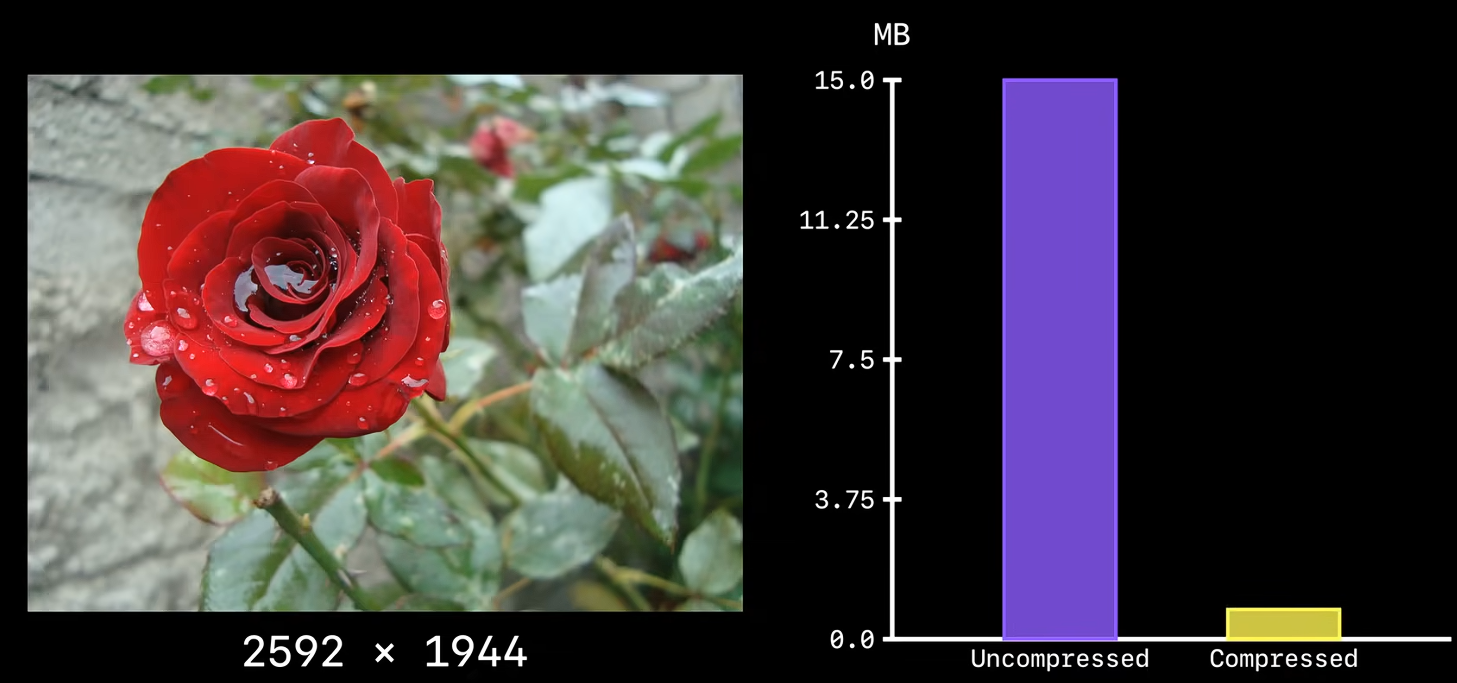
例,4032 X 3024分辨率为12M,1200万像素,46MB(BMP格式)压缩到4MB。需1.2亿次运算,手机soc如骁龙snapdragon 8 gen3耗时10ms。
计算机使用的RGB色彩模型,每种颜色取值0-255占8bit,那么每个像素24bit即3byte。如图,2592 × 1944 = 5,038,848 ≈ 5M,5M×3=15M。不压缩的图片15M像素,压缩后0.8M像素。
主要技术:色彩空间转换、色差下采样、离散余弦变换DCT、量化与编码。
压缩遵循原则:亮度优先;黑白图像保留细节;色差图像模糊可接受。

JPEG压缩过程是一种有损压缩标准,主要用于减少连续色调静态图像的文件大小,平衡视觉质量与存储效率。整个流程中,可调整压缩参数(如量化级别)以控制输出文件大小和质量。
第一步:color treatment
- 颜色空间转换:因为人眼对亮度分量(Y)更敏感,而对色度分量(Cb和Cr)不敏感,色度数据可以被压缩。首先将RGB颜色模型转换为YCbCr模型(或称YUV/YPbPr),转换公式:Y = 0.299R + 0.587G + 0.114B,Cb = −0.1687R − 0.3313G + 0.5B,Cr = 0.5R − 0.4600G − 0.0402B。
- 将转换后的图像划分为8×8像素块,便于后续处理。
- 对像素块色度下采样/色度抽样,chroma subsampling,保留所有Y,减少采样Cb和Cr。chroma色度。hue色调。Cb(蓝色色度分量)chroma Blue。Cr(红色)。
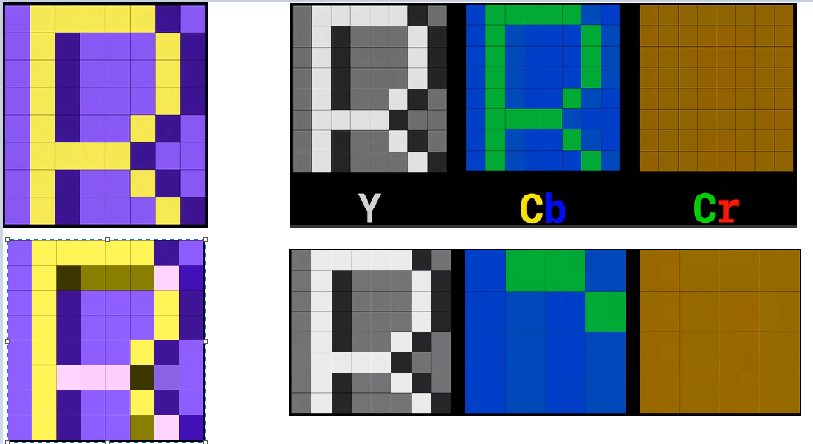
原始图像转换YUV后,对图像按采样格式进行采样,常见格式有4:4:4,4:2:2和4:2:0。
色度抽样方法如图,采样格式4:2:0。第一行是8×8像素原图和它的三个分量图:亮度分量Y,色度分量Cb和Cr。Y图不做处理,把Cb图和Cr图划分为2×2的小块,块的颜色由左上角像素颜色决定。第二行是处理后的图。处理后数据减少50%。
第二步:JPEG encoder
- 量化:使用预设的量化表压缩DCT系数,通过除法操作减少数据精度(特别是高频系数),这是有损压缩的关键,损失部分视觉细节但显著减小文件大小。
- 熵编码:最后对量化后的数据进行无损压缩,如哈夫曼编码,移除统计冗余进一步优化存储。
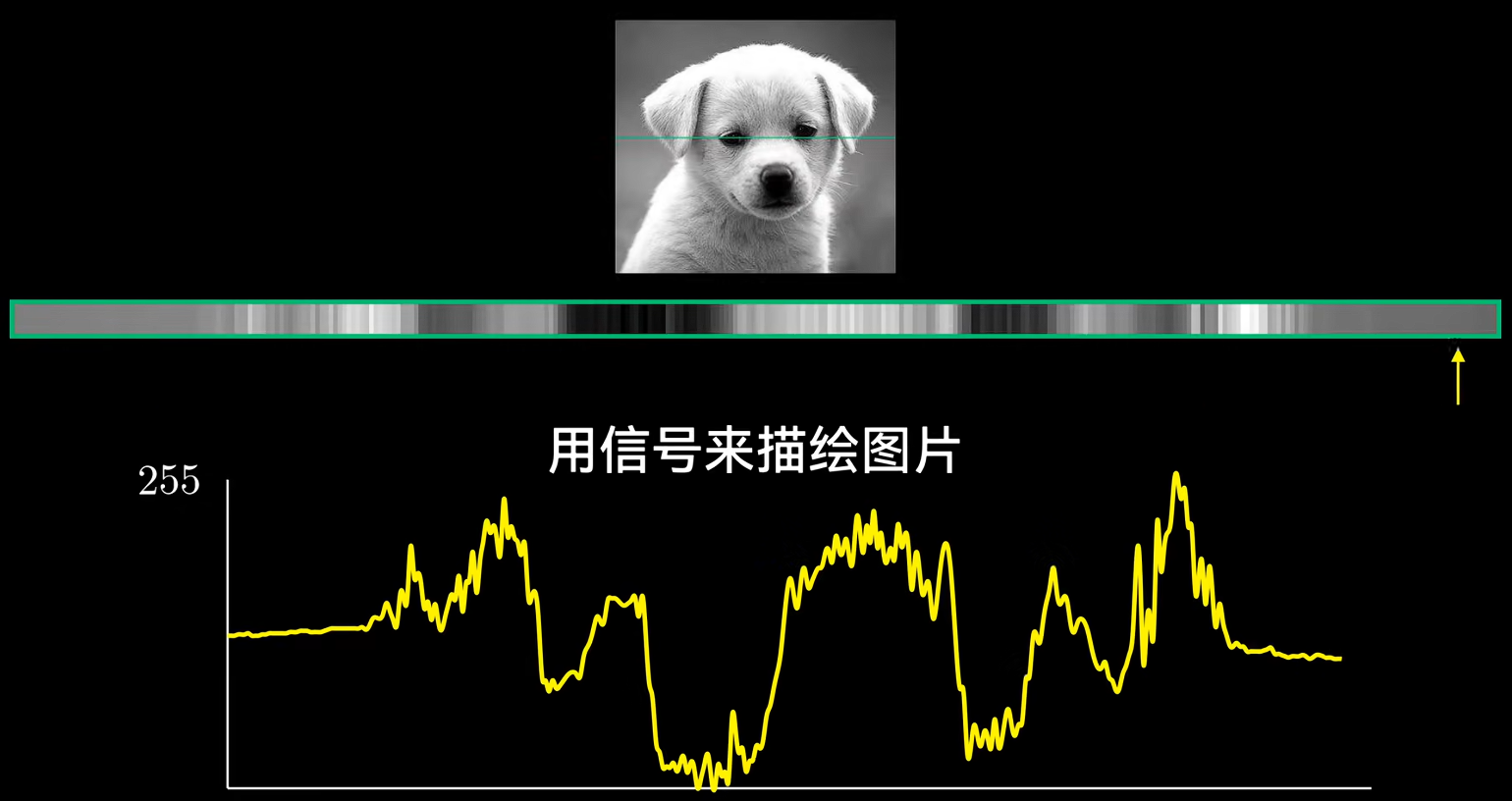
取图像中的一行像素,每个像素值0-255,绘制像素值曲线,如图。可以看成一个信号,因此可以讨论信号的频率分量。如图,像素值变化剧烈的图片是高频分量,变化缓慢的是低频。
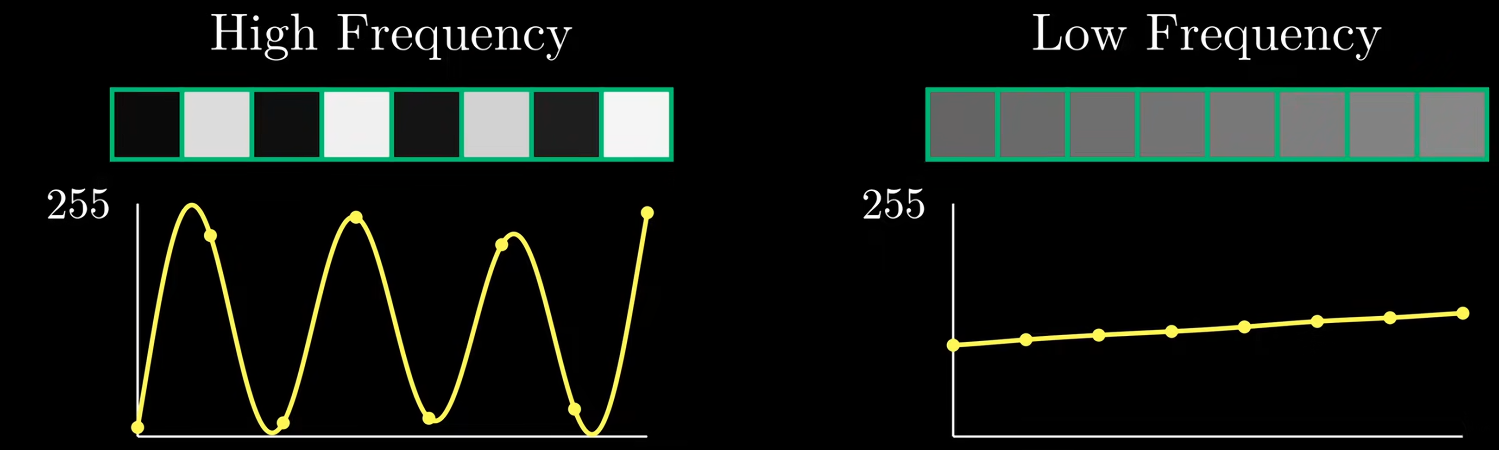
对图像信号处理有2个前提:
- 图片大部分都是低频信号。原因是无论是一行像素还是一小块像素,值不会剧烈变化。
- 人类对图像的高频分量不敏感。
接下来的问题,如何从图片中提取/分离高频分量,并去掉以压缩数据。答案是,离散余弦变换。对每个像素块应用DCT,将空间域图像数据转换为频域系数。
离散余弦变换(Discrete Cosine Transform,DCT)是一种在数字信号处理和图像处理中重要的变换方式。核心源于傅里叶变换的实数化改进,它能够将信号从时域(或空间域)转化到以余弦基函数为核心的频域表达形式。
《数字信号处理-理论 算法与实现_胡广书》第四章
从DFT到DCT
- 连续傅里叶变换(CFT):对连续函数,无穷多的三角函数的线性组合表示。
- 离散傅里叶变换(DFT):对离散采样,有限个复数频率分量。常用FFT实现。
- 离散余弦变换(DCT):DFT得到的结果是复数,而在实际应用如图像处理中,信号本身通常是实值,需要的数据在余弦分量上。DCT是对特定边界条件下的DFT进行简化得出的,且只取余弦(实数)部分。DCT用“余弦基函数”对信号正交分解,且结果均为实数。
DCT的优点
- 平滑性:许多自然信号(图像中的连续区域、音频中的平滑片段)在用余弦函数来进行逼近时展现出“能量集中在低频”这一特征。
- 对称边界条件:DCT可以等效地看作原信号在边界处做了对称延拓,因此在边界过渡方面相对更“平滑”,不会像离散傅里叶变换那样在信号区间首尾可能出现明显的不连续跳变。
具体解释以上结论。分为5点。
第一点,解释DCT是DFT的实部。把指数型DFT公式,利用欧拉公式,改写成三角函数型。
- 指数型DFT:
- 三角函数型DFT:
看出三角函数型DFT分为2部分:实部和虚部,其中实部是余弦基函数组成,对比后文中的DCT-II公式,就是DFT的实部。
第二点,解释三角函数的正交性。正交性表明不同频率的三角函数在积分意义下“相互垂直”,类似于向量正交。这种性质使得三角函数系成为傅里叶级数的理想基函数,任何周期函数可表示为这些正交基的线性组合。具体来说,以下两对三角函数族具有正交性:
1. 三角函数的正交性。对于整数n,m>0,有
2. 指数形式的正交性。欧拉公式改写以上公式。复指数函数的正交性,是傅里叶级数的基础。
第三点,解释信号的能量。帕斯瓦尔定理(Parseval's Theorem)是信号处理的核心定理:一个信号的总能量(即平方的积分或求和)在时域和频域的表达形式是相等的。
一、定理定义。对于平方可积的连续信号 x(t),时域能量为,其傅里叶变换为 X(Ω),频域能量为
,时域与频域能量相等。离散信号同样守恒。频域能量为什么要除以周期?当信号被采样后,频谱会周期性扩展,导致单个周期内的能量值放大。若不除以采样点数(即周期),则计算出的能量会与原信号的能量不一致。
二、物理意义
- 能量守恒:信号的总能量在时域与频域相等。
- 正交基关联:该定理本质上是希尔伯特空间中正交基的性质体现,表明信号在正交基(如傅里叶基)下的投影能量与原信号能量一致。信号可以分解为多个频率分量的叠加(如傅里叶级数或傅里叶变换),而各频率分量的能量之和等于信号的总能量。这类似于勾股定理在多维空间中的推广,即不同方向的分量的平方和等于总能量的平方。
三、应用场景
- 信号处理:用于验证信号完整性(如滤波器设计前后能量是否守恒)。
- 通信工程:分析信号在传输中的能量损耗与频域特性。
- 功率谱分析:在随机信号处理中,帕斯瓦尔定理表明信号的功率谱密度(频域能量分布)与时域自相关函数对应,可用于噪声分析和信号检测。
- 数值计算:通过程序验证离散傅里叶变换的能量守恒性(如MATLAB实现)。
四、数学证明要点
- 傅里叶逆变换:通过将信号表示为频域分量的线性组合,利用正交性简化三重积分。
- Delta函数性质:借助狄拉克函数的抽样特性消去中间变量积分。
----------希尔伯特空间?----------------------------
在数学中,希尔伯特空间是欧几里德空间的一个推广,其不再局限于有限维的情形。与欧几里德空间相仿,希尔伯特空间也是一个内积空间,其上有距离和角的概念(及由此引申而来的正交性与垂直性的概念)。此外,希尔伯特空间还是一个完备的空间,其上所有的柯西序列等价于收敛序列,从而微积分中的大部分概念都可以无障碍地推广到希尔伯特空间中。希尔伯特空间为基于任意正交系上的多项式表示的傅立叶级数和傅立叶变换提供了一种有效的表述方式,而这也是泛函分析的核心概念之一。希尔伯特空间是公式化数学和量子力学的关键性概念之一。
---------分界线结束------------------------------------------------
第四点,解释DFT在信号区间首尾出现不连续跳变的现象,主要源于其隐含的周期性假设和信号截断操作。以下是具体原因及解决方案的详细分析:
1. 不连续跳变的成因
- 周期性假设:DFT本质上假设信号是无限周期重复的离散序列。当采样窗口内的信号未满足整周期截断时,周期延拓后会在首尾边界处产生突变,导致频域能量扩散(频谱泄漏)。
- 截断效应:实际信号被有限长度窗口截断后,若首尾值不等(如非整周期截断),会引入高频分量,表现为频域旁瓣(Gibbs现象)。
2. 解决方案
- 加窗处理:通过窗函数平滑信号首尾过渡,降低截断突变的影响。如:
- 汉宁窗:
w(n)=0.5-0.5cos(2πn/N),可有效减少旁瓣幅度; - 汉明窗:
w(n)=0.54-0.46cos(2πn/N),在抑制泄漏与主瓣宽度间取得平衡
- 汉宁窗:
- 补零与采样调整:增加采样点数或补零可缓解栅栏效应,但注意补零不改变频谱泄漏的本质。理想情况下,采样长度应为信号周期的整数倍。
- 信号预处理:确保信号在截断前首尾值接近(如零相位延拓),或使用DCT替代DFT,因其基于对称延拓边界条件,天然减少边界突变。
第五点,解释DCT能量集中在低频。
- 基函数特性。DCT的基函数由余弦函数构成,低频分量对应变化平缓的余弦函数(如周期为2π的余弦函数),而高频分量对应变化剧烈的余弦函数(如周期小于2π的余弦函数)。由于自然图像中相邻像素具有高相关性,低频区域(如平滑区域)能量集中,高频区域(如边缘或纹理区域)能量分散。
- 能量紧致性。DCT变换后,约70%-90%的能量集中在左上角(低频区域),而绝大多数高频系数幅值接近0。这种特性使得数据压缩时只需保留少量低频系数即可恢复主要视觉信息,符合人类视觉系统对低频信息更敏感的特性。
JPEG编码使用二维DCT变换,一维DCT是二维的基础。一维DCT变换共有8种形式,其中前4种DCT I-IV常见,后4种是前4种的扩展。这些形式的主要区别在于边界条件的选择和采样点的偏移。
8种DCT形式
1. DCT-I。最基本的形式,适用于对称边界条件。其变换公式为:
![]()
2. DCT-II 。最常用的形式,JPEG压缩标准采用。其公式为:
其中,
3. DCT-III。DCT-II的逆变换(IDCT),公式为:
![]()
4. DCT-IV。在改进的离散余弦变换(MDCT)中有应用,公式为:![]()
5. DCT-V。是DCT-I的变体,公式为:![]()
6. DCT-VI。是DCT-II的变体,公式为:![]()
7. DCT-VII。是DCT-III的变体,公式为:![]()
8. DCT-VIII。是DCT-IV的变体,公式为:![]()
| DCT类型 | 主要特点 | 典型应用 |
|---|---|---|
| DCT-I | 适用于对称边界条件 | 信号处理中的对称问题 |
| DCT-II | 能量集中性好,计算简单 | JPEG图像压缩、MPEG视频编码 |
| DCT-III | DCT-II的逆变换 | IDCT(逆离散余弦变换) |
| DCT-IV | 适用于重叠变换 | MDCT(改进的离散余弦变换) |
| DCT-V-VIII | 前四种的扩展形式 | 特殊边界条件的信号处理 |
一维DCT-II公式和逆变换详解
对于长度为N的离散序列 { x[n] } ,其DCT-II系数 { X[k] } 定义为:
,
其中,是缩放因子(归一化因子),使DCT和它的逆单位正交;
表示第k个余弦基函数在第n个点的值。
一维DCT-II的逆变换是DCT-III,其公式如下:
,
只要用逆变换系数β(k) 和同样的余弦基函数,就能从频域系数{ X[k] } 复原出原始信号{ x[n] }。
二维DCT
DCT是先将整体图像分成N*N像素块,然后对N*N像素块逐一进行DCT变换。由于大多数图像的高频分量较小,相应的图像高频分量的系数为零,所以可用更粗的量化。转换后的系数数据远远小于图像像素数据。接收端通过反离散余弦变换回到样值。
余弦函数和图像信息是怎么联系在一起的?自己定义的。如图,是一维图片的变换,波峰亮波谷暗,频率越高明暗变化越多,组合不同频率的余弦函数并加权,得到复杂的明暗图像。
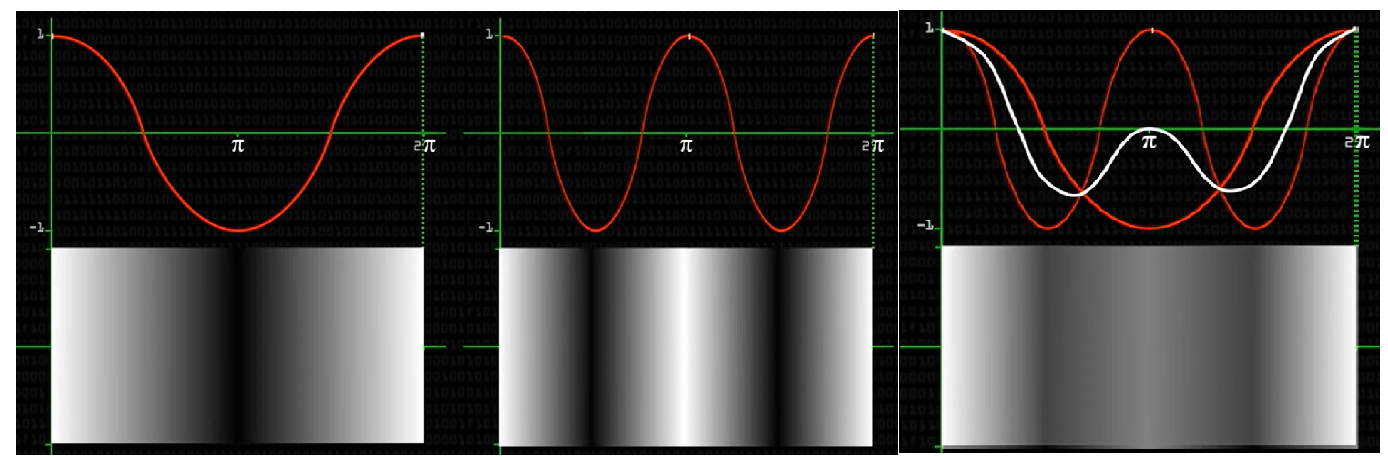
对于二维图片,同样分别定义,横像素和竖像素。如图,基本DCT图,是64个余弦波代表的像素,他们可以生成任何8×8像素图像。DCT的作用就是计算64个格子的系数,得到64个系数后乘以每个余弦波,得到复杂的余弦波,再对应8×8像素图像。

举例:如图是一个任意的8×8像素图像,只有亮度Y分量,可以由基本DCT的64种图案组合而成。
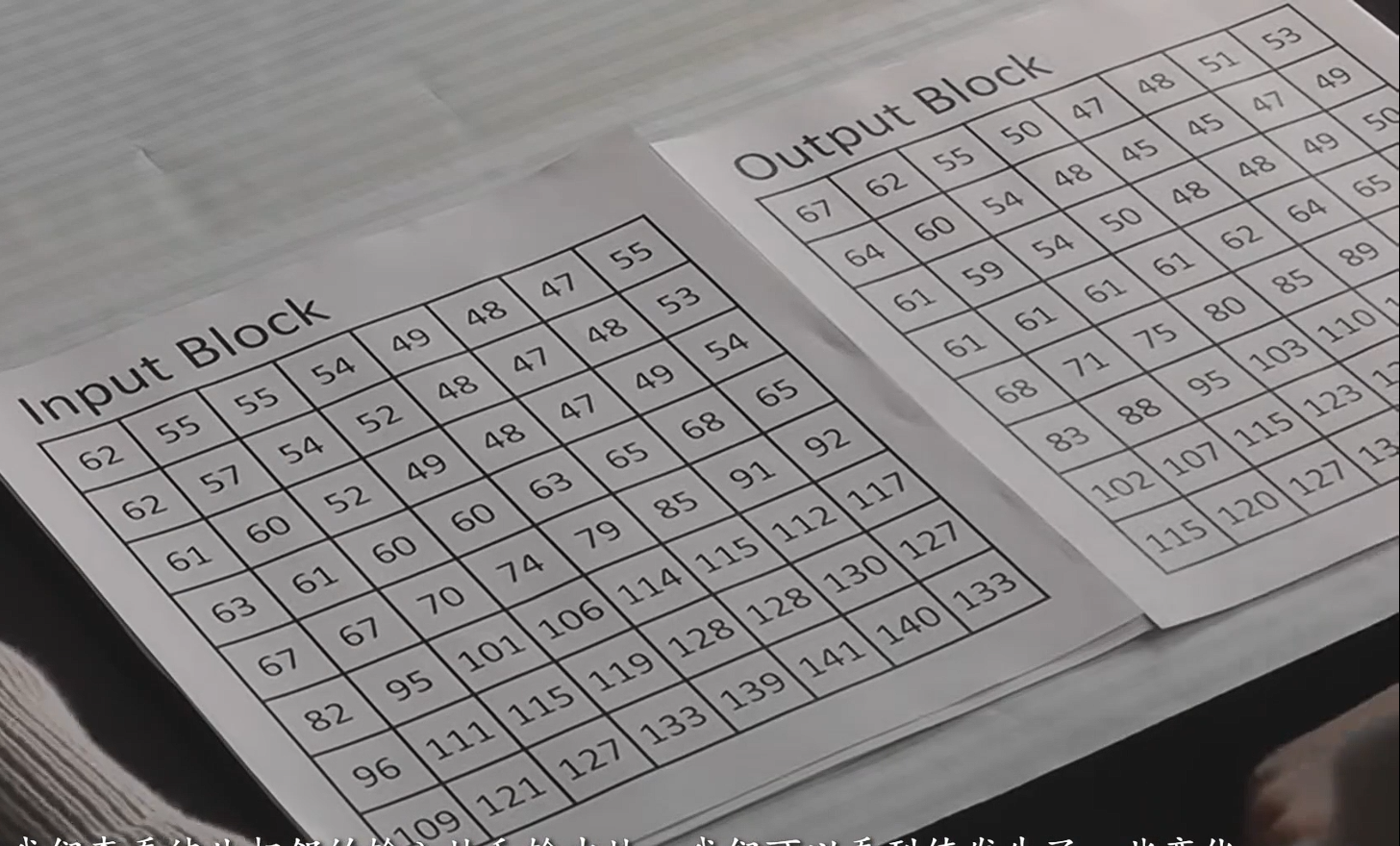
- 把每个像素用它的亮度值表示,取值0-255,如图input block;
- 由于余弦函数取值范围-1~1,所以需要改动像素取值范围到-127~128,如图shifted block;
- 将shifted block矩阵输入二维DCT-II公式,得到DCT系数表,系数取值-1024~1024,每个系数代表了这一格的基本图像对源图像的影响权重,绝对值越大代表影响越大。1行1列是直流DC系数(单独存储),其他是交流AC系数。特点:DC系数最大,左上角系数偏大(低频余弦),右下角系数约为0(高频余弦)。如图DCT-II coefficients;
- 量化,去除高频数据的过程称为量化。将DCT-II coefficients矩阵和quantization table(采用50%质量JPEG量化表)计算,计算方式:每个系数除以对应的量化值后取整。得到量化后的系数表,如图quantized,quantized的特点:除了左上角其他系数都为0。quantization table的特点:左上角值小,右下角值大。不同的压缩器采用不同的量化表。
- 编码,JPEG 选用差分编码(DPCM)对DC系数的差值DIFF进行编码,对AC系数之字形扫描和游程编码,再对DC系数进行差分编码后的结果和AC系数进行游程编码后的结果进行Huffman编码。编码缩短了序列,实际传输的就是这个简短的序列。霍夫曼编码(熵编码中的变长编码),游程编码RLE;
- 还原解码。收到序列后,先还原成quantized,接收方用quantized乘以quantization table(收发双方都知晓该表),得到DCT-Ⅲ系数表,如图DCT-Ⅲ coefficients。再用二维DCT-Ⅲ公式还原,得到output shifted block,再+128得到output block。


结果分析。如图,对比发送图片和接受图片,很接近但不完全一样,差异是50%,差异大小源于第4步量化时选择的quantization table。通过操作quantization table的值控制图片质量,表中数值变大,会降低图片质量,数值变小提高图片质量。
二维DCT-II公式解析。其思路与一维的完全一致,只不过我们需要分别在行和列两个维度上做变换。对于大小为 M × N 的图像块 { f ( m , n ) } ,其二维DCT-II可表示为:
,
计算二维DCT最常见的做法是先对每行做一维DCT,再对变换后的结果按列再做一维DCT。
DCT的快速算法。就像DFT可以通过FFT得到快速实现一样,DCT也有相应的快速算法,其复杂度常可以降到 O(NlogN) 级别。思路:将余弦基的矩阵分解为若干子块,可以使用类似“蝴蝶操作”来节省计算量。实际实现:在很多编程库(如FFTW、Intel MKL、OpenCV、scipy)中,都已经提供了高效的DCT实现,直接调用即可。
代码实现
JPEG原理分析及JPEG解码器的调试_dct量化表-CSDN博客
参考文献
1、《Computer Vision_ Algorithms and Applications-Richard Szeliski 》
2、《Digital Image Processing_3ed_Gonzalez_冈萨雷斯》
3、【3D视觉工坊】第八期公开课:立体视觉之立体匹配理论与实战_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1Uv411q7GU
4、单目视觉深度估计测距的前生今世 - 知乎 https://zhuanlan.zhihu.com/p/56263560
5、使用MATLAB进行计算机视觉和图像处理 -MATLAB&Simulink_哔哩哔哩_bilibili
6、MATLAB深度学习之手写数字识别_哔哩哔哩_bilibili
7、MATLAB利用OCR Trainer识别数字&字母_matlab ocr-CSDN博客
8、一个案例学会用Matlab App Designer设计文字识别工具_matlab 读取文本框-CSDN博客
10、JPEG不可思议的压缩率——归功于信号处理理论 @圆桌字幕组_哔哩哔哩_bilibili
12、JPEG原理分析及JPEG解码器的调试_dct量化表-CSDN博客
13、
14、
15、
16、

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)