深度学习第20天_项目1_fasttext原理
fastText原理剖析
-
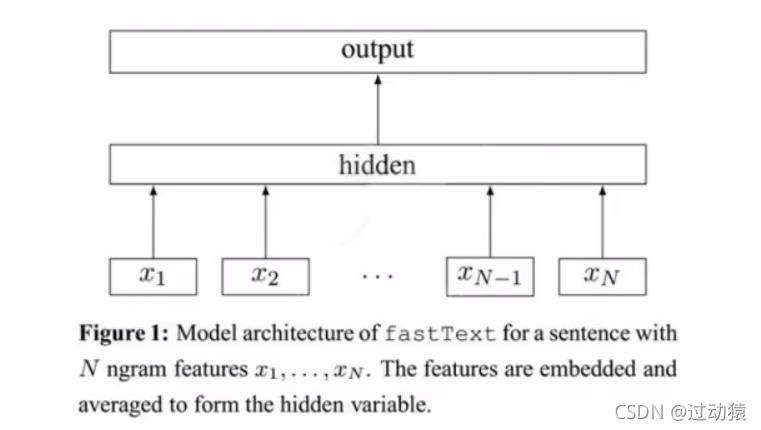
fastText的模型架构
fastText的架构有三层:输入层,隐含层,输出层
输入层:是对文档embedding之后的向量,包含又N-gram特征
隐藏层:是对输入数据的求和平均
输出层:是文档对应标签如下图所示:
(1)N-gram的理解a. bag of word(词袋)
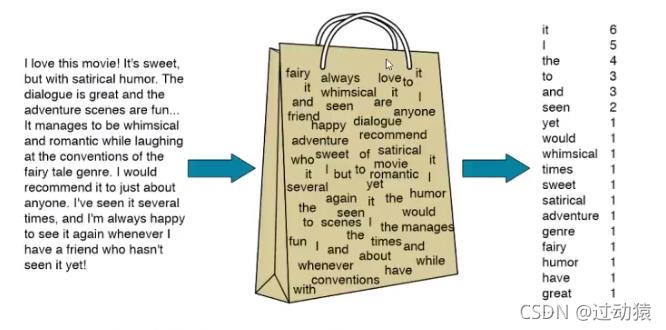
bag of word 又称为bow,称为词袋。是一种只统计词频的手段。b. N-gram模型
但在很多情况下,词袋模型是不满足我们的需求的
例如:我爱她 和 她爱我 在词袋模型下,概率完全相同,但其含义差别很大为了解决这个问题,就有了N-gram模型,它不仅考虑词频,还考虑当前词前面的词语,比如我爱 她爱。
N-gram模型的描述是:第n个词出现与前n-1个词相关。而与其他任何词不相关
例如:I love deep learning这个句子,在n=2的情况下,可以表示为{i love},{love deep},{deep learning},在n=3的情况下,可以表示为{I love deep},{love deep learning}。在n=2的情况下,这个模型被称为Bi-gram(二元n-gram模型)
在n=3的情况下,这个模型被称为Tri-gram(三元n-gram模型)所以在fasttext的输入层,不仅有分词之后的词语,还包含有N-gram的组合词语一起作为输入
(2)fastText模型中的层次化softmax
为了提高效率,在fastText中计算分类标签的概率的时候,不再是使用传统的softmax来进行多分类的计算,而是使用哈夫曼树,使用层次化的softmax来进行概率的计算
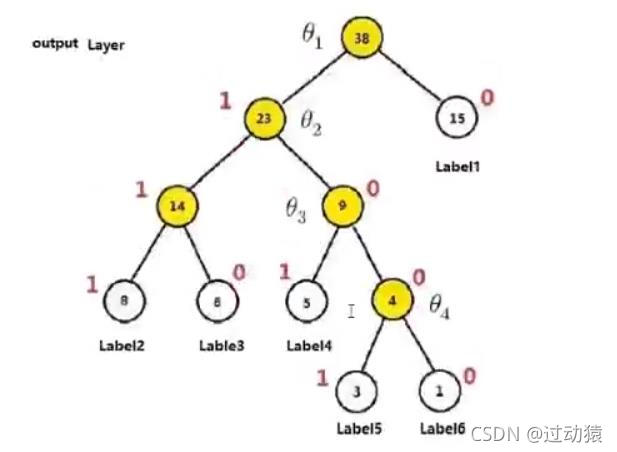


层次化softmax的好处:传统的softmax的时间复杂度为L(labels的数量),但是使用层次化softmax之后的时间复杂度为log(L),从而在多分类的场景提高了效率(3)负采样(negative sampling)
negative sampling,即每次从除当前label外的其他label中选择几个作为负样本,作为出现负样本的概率加到损失函数中
好处:1.提高训练速度 2.改进效果,增加部分负样本,能够模拟真实场景下的噪声情况,能够让模型的稳健性更强例如:
假设句子1对应的类别有label1,label2,label3,label4,label5这5个类别,假设句子1属于label2,如果按照之前的方法,在反向传播时需要对5个类别的所有参数进行求导更新,这样计算量很大。而使用负采样的话,就可以只更新将句子1判定为label2的参数和不判定为label2的参数,这样计算量不仅小了,而且也可以真实情况下不仅仅只有5种label的情况

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)