Ai学习之本地部署Ollama
1.什么是Ollama
Ollama是一个开源工具,旨在简化大型语言模型的本地部署和操作。它由活跃的社区维护并定期更新,提供了一个轻量且易于扩展的框架,使开发人员能够轻松地在本地机器上构建和管理LLMs。这消除了复杂的配置或依赖外部服务器的需要,使其成为各种应用的理想选择。
github网址:ollama/ollama: Get up and running with Llama 3.3, Mistral, Gemma 2, and other large language models.
2.Ollama的主要功能特点
-
模型运行和管理:Ollama 允许用户在本地机器上运行大型语言模型,提供了简单的 API 来创建、运行和管理模型 。
-
模型库:Ollama 拥有一个丰富的预构建模型库,这些模型可以轻松地集成到各种应用程序中 。
-
多模态模型支持:Ollama 支持多模态模型,能够理解和生成与图像相关的描述 。
-
REST API:Ollama 提供了一个 REST API,用于运行和管理模型,包括生成响应和与模型进行聊天 。
-
跨平台支持:Ollama 支持 macOS、Linux 和 Windows 操作系统,并且可以通过 Docker 容器进行部署 。
-
硬件加速:Ollama 能够识别正在运行的硬件,并在可能的情况下调用 GPU 加速模型的运行 。
-
易用性:Ollama 提供了多种安装方式,简化了安装和配置过程,使得用户即使没有专业背景也能轻松使用 。
-
社区集成:Ollama 拥有丰富的社区生态,提供了多种交互界面和插件,如网页、桌面、终端等,以及 Raycast 插件等 。
-
模型自定义:用户可以通过 Modelfile 自定义模型参数,包括系统提示词、对话模板、模型推理温度等 。
-
开源:作为一个开源项目,Ollama 允许用户查看、修改和贡献代码,促进了社区的协作和发展 。
总结一下:借助Ollama,开发人员可以访问和运行一系列预构建的模型,如Llama 3、Gemma和Mistral,或导入和定制自己的模型,而无需担心底层实现的复杂细节。该工具通过定义包含模型权重、配置和必要数据组件的模型文件,简化了设置过程,免去了复杂的配置文件或部署程序的需求。
3.平台优势
Ollama 平台在性能、稳定性和灵活性等方面相比其他 AI 平台具有一些显著的优势:
-
性能:Ollama 支持 GPU 加速,这使得它在处理大型语言模型(LLMs)时能够提供更快的推理速度。此外,Ollama 允许并发请求,更好地利用 GPU 资源,从而提高吞吐量。
-
稳定性:Ollama 提供了强大的模型管理功能,包括多版本控制和自动更新,这有助于确保平台的稳定性和模型的持续改进。
-
灵活性:Ollama 设计上考虑了未来模型的扩展性,易于添加新模型或更新现有模型。它还提供了灵活的安装方式,支持 macOS、Windows 和 Linux 操作系统,并且可以通过 Docker 容器进行部署。
-
易用性:Ollama 提供了简单的安装和配置过程,使得用户即使没有专业背景也能轻松使用。它还提供了多种交互界面和插件,如网页、桌面、终端等,以及 Raycast 插件等,增加了使用的灵活性。
-
本地化部署:Ollama 允许在本地机器上运行复杂的 AI 模型,降低了对网络的依赖,提高了数据处理的隐私性。
-
社区支持:Ollama 拥有活跃的社区和丰富的文档,便于用户学习和交流。
-
跨平台应用:Ollama 不仅限于 Linux,还提供了跨平台支持,无论使用 Windows、macOS 还是 Linux,都能满足用户的需求。
-
与 Python 的集成:Ollama 与 Python 的无缝集成,只需几行代码,就可以运行本地语言模型并将其集成到 Python 项目中。
-
隐私保护:OLLAMA 使所有数据处理在本地设备上完成,这对于用户隐私来说是一大胜利。
-
多功能性:OLLAMA 不仅适用于 Python 爱好者,其灵活性还使其适用于各种应用,包括 Web 开发。
本地化部署的优势:Ollama使您能够本地使用开源模型。它会自动从最佳的可用存储库中获取模型,并在您的计算机拥有专用GPU时无缝地使用GPU加速,而无需手动配置。它甚至可以利用您计算机上的多个GPU,从而加快推理速度并增强资源密集型任务的性能。此外,本地运行LLMs确保您的数据永远不会离开您的计算机,这对敏感信息来说至关重要。
4.Ollama的下载和安装
Ollama的安装过程非常简单,支持多个操作系统,包括macOS、Windows和Linux,以及Docker环境,确保广泛的可用性和灵活性。以下是Windows和macOS平台的安装指南。
-
Ollama GitHub Releases:Releases · ollama/ollama
Ollama下载页截图:
Ollama GitHub Releases截图:
4.1、在Windows上安装Ollama
-
首先从Ollama 官方网站下载安装程序
-
运行安装程序并点击Install
-
安装程序回自动执行安装任务,请耐心等待,安装完成后,安装程序窗口回自动关闭,此时Ollama在后台运行,可以在任务栏右侧的系统托盘中找到它
-
4.2、在Linux上安装Ollama
curl -fsSL https://ollama.com/install.sh | sh可以从官方手册了解更多的详细信息:ollama/docs/linux.md at main · ollama/ollama
5.如何使用Ollama
本文将以Windows平台为例介绍如何使用Ollama。在macOS和其他平台上的使用方式非常相似。
5.1、自定义模型存储位置和环境变量(可选)
本节不是强制性的,跳过它不会影响您使用Ollama。
在开始使用Ollama之前,如果您的系统驱动器或分区(C:)可用空间有限,或者您更喜欢将文件存储在其他驱动器或分区上,您需要更改Ollama模型的默认存储位置。默认情况下,Ollama将下载的模型存储在C:\Users\%username%\.ollama\models,由于模型可能有几个GB大小,这可能会迅速减少系统驱动器的可用空间,可能影响系统性能。故需要设置环境变量,主要的环境变量有3个(系统属性-->环境变量-->用户变量)
| 变量名 | 变量值 | 描述 |
|---|---|---|
| OLLAMA_ORIGINS | * | 跨域访问,HTTP客户端请求来源的逗号分隔列表。如果在本地使用且没有严格要求,可以将其设置为星号(*)表示没有限制。 |
| OLLAMA_HOST | 0.0.0.0:11434 | 端口配置,Ollama服务监听的网络地址,默认为127.0.0.1。如果您希望允许其他计算机(如本地网络中的计算机)访问Ollama,可以将其设置为0.0.0.0以允许来自其他网络的访问。 |
| OLLAMA_MODELS | D:\ollama_models | 更改模型存储位置 |
| OLLAMA_PORT | 11434 | Ollama服务监听的默认端口,默认为11434。如果存在端口冲突,可以将其更改为其他端口(如8080)。 |
| OLLAMA_KEEP_ALIVE | 300 | 大模型在内存中的保留时间,默认为5分钟(5m)。例如,纯数字如300表示300秒,0表示在处理请求后立即卸载模型,任何负数表示无限期保留模型在内存中。您可以将其设置为24h以在内存中保留模型24小时,从而提高访问速度。 |
| OLLAMA_NUM_PARALLEL | 1 | 并发请求处理程序的数量,默认为1,即请求按顺序处理。根据实际需要进行调整。 |
| OLLAMA_MAX_QUEUE | 512 | 请求队列的长度,默认为512。超出此长度的请求将被丢弃。根据情况调整此设置。 |
| OLLAMA_DEBUG | 1 | 输出调试日志的标志。将其设置为1以输出详细的日志信息,有助于排查问题。 |
| OLLAMA_MAX_LOADED_MODELS | 1 | 可以同时加载到内存中的模型最大数量,默认为1,即一次只能有一个模型在内存中。 |
以上变量更改后,重启Ollama即可生效
5.2、快速开始:试用Qwen2.5
我们可以使用ollama run qwen:14b 命令来快速体验千问的最新开源14b模型,首先,打开一个命令行窗口(您可以使用cmd、PowerShell或Windows Terminal运行本文中提到的命令),并输入ollama run qwen:14b以开始拉取模型。(如果您想体验其他模型,请参阅本文后面的“模型库”部分了解模型及其对应命令,或按照“从GGUF导入”部分加载自定义GGUF模型。)
模型拉取完成后,我们可以开始使用qwen:14b模型。您可以在命令行中直接向模型发送对话内容。
5.3、Ollama模型库
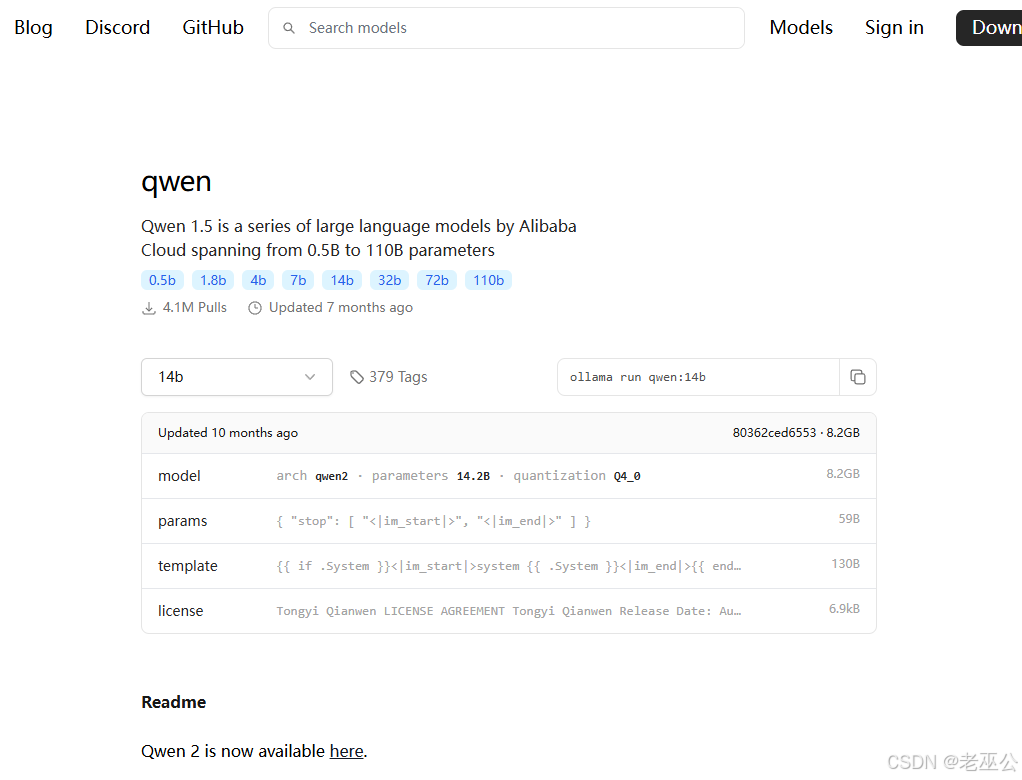
Ollama模型列表:library 如下图
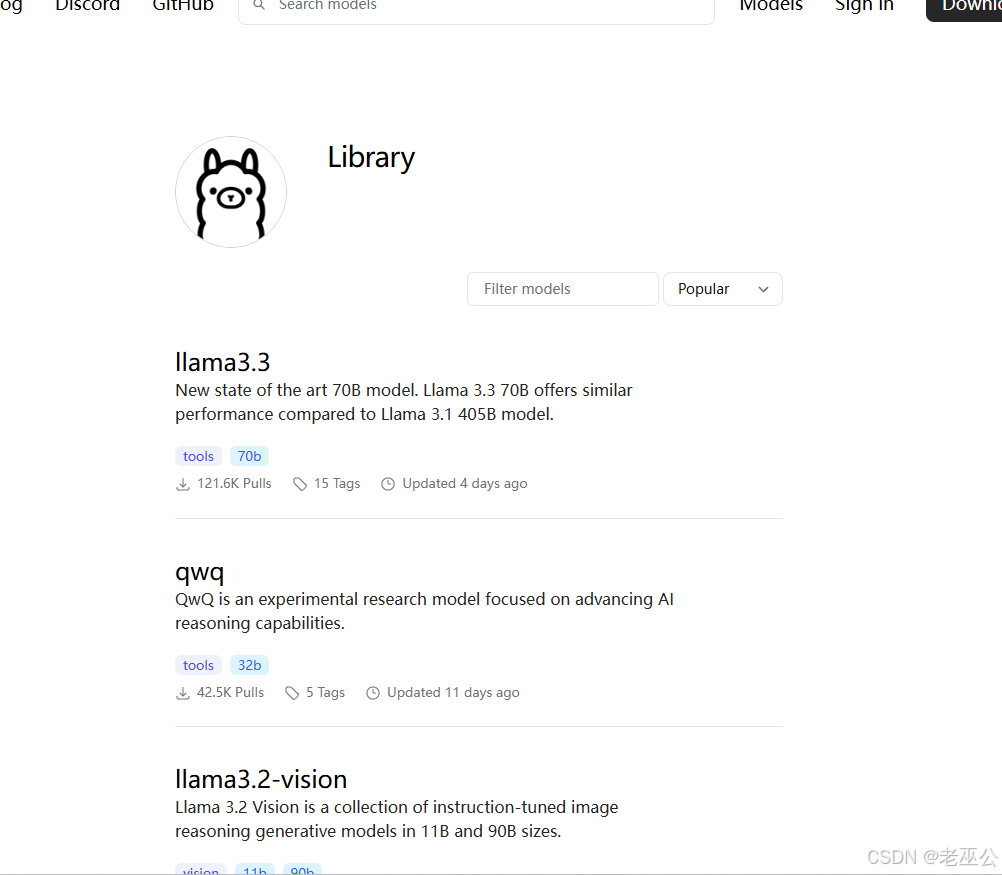
可以在模型库中看到可以下载的示例模型以及相关信息(模型、参数、大小)点进去可以看到相关详细介绍和下载命令
5.4、操作指令
可以在命令行中运行这些命令以利用Ollama的各种功能:
| 命令 | 描述 | 示例 |
|---|---|---|
| serve | 启动ollama | |
| create | 从模型文件创建模型 | ollama create mymodel -f ./Modelfile |
| show | 显示模型信息 | |
| run | 运行模型 | |
| pull | 从注册表拉取模型 | ollama pull llama3 |
| push | 将模型推送到注册表 | |
| list | 列出模型 | |
| ps | 列出运行中的模型,显示硬件使用情况 | |
| cp | 复制模型 | ollama cp llama3 my-model |
| rm | 删除模型 | ollama rm llama3 |
| help | 获取命令帮助 |
pull 命令也可用于更新本地模型,只会拉取差异部分。如果您想获取特定命令(如run)的帮助内容,可以输入ollama [command] --help以获取该命令的详细使用信息。例如,输入ollama run --help,
在模型运行时,可执行以下操作:
| 命令 | 描述 |
|---|---|
| /set | 设置会话变量 |
| /show | 显示模型信息 |
| /load | 加载会话或模型 |
| /save | 保存当前会话 |
| /clear | 清除会话上下文 |
| /bye | 退出 |
| /?, /help | 获取命令帮助 |
| /? shortcuts | 获取快捷键帮助 |
5.5、查看日志
有时,Ollama可能不会按预期运行。查明问题的最佳方法之一是检查日志。
在Windows上运行Ollama时,可以检查几个不同的位置。通过按Win+R打开文件资源管理器并输入以下命令:
explorer %LOCALAPPDATA%\\Ollama # View logs
explorer %LOCALAPPDATA%\\Programs\\Ollama # Browse binaries (the installer adds this to the user's PATH)
explorer %HOMEPATH%\\.ollama # Browse model and configuration storage location
explorer %TEMP% # Temporary executable files are stored in one or more ollama* direc6.高级用法
6.1、从GGUF导入
Ollama 支持在模型文件中导入GGUF模型,可以从Hugging Face官网Hugging Face – The AI community building the future.(国内镜像:hf-mirror.com/models)等平台下载微调的GGUF模型,并通过Ollama 运行他们,流程如下
-
在Hugging Face 平台下载微调过后的GGUF模型
-
创建一个名为Modelfile的文件,使用FROM指令指定要导入的模型的本地文件路径
FROM ./llama3.1_8b_chinese_chat_q4_k_m.gguf -
在Ollama中创建模型
ollama create llama3.18bq4km -f Modelfile.txt -
运行模型
ollama run llama3.18bq4km
6.2、使用Ollama像GPT一样,在Docker中打开WebUI
Docker环境配置有问题,未实现
6.3、Web UI使用
使用前提是Ollama 已经部署完毕,Node.js / npm已经安装
-
克隆存储库或下载:
git clone https://github.com/ollama-webui/ollama-webui-lite.git cd ollama-webui-lite -
安装依赖项
npm ci -
在开发者模式下运行应用程序
npm run dev注意:为了其他电脑能够访问,修改源码文件
src/lib/constants.ts将localhost改为本机ip

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)