机器学习复盘(4):监督学习完整总结
监督学习的应用主要为分类问题和回归问题。分类问题分类问题是监督学习的核心问题,在监督学习中,当输出变量 f(x) 取有限个离散值时,预测问题就成为了分类问题。这事,输入变量 x 可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器,分类器对新的输入进行输出的预测,称为分类。可能的输出称为类别。分类的类别为两个时,称为二类分类问题,分类的类别为多个时,称为多类分类
监督学习是最常见的一种机器学习,他的训练数据是有标签的。通过已有的一部分输入数据与输出数据之间的相应关系。生成一个函数,将输入映射到合适的输出,训练目标是能够对新数据(或测试数据)预测标签。
监督学习的流程
简单来说,主要可分为以下几步:
- 选择适合目标任务的有监督算法或数学模型
- 把已知的“问题和答案”(训练数据)输入给机器去学习
- 机器通过自己的学习,从训练数据中寻找规律,总结出自己的“方法论”
- 使用者把“新的问题”(测试数据或者新数据)输入给机器,机器根据自己总结出的“方法论”给出答案
具体来讲,监督学习的应用主要为分类问题和回归问题。
分类问题
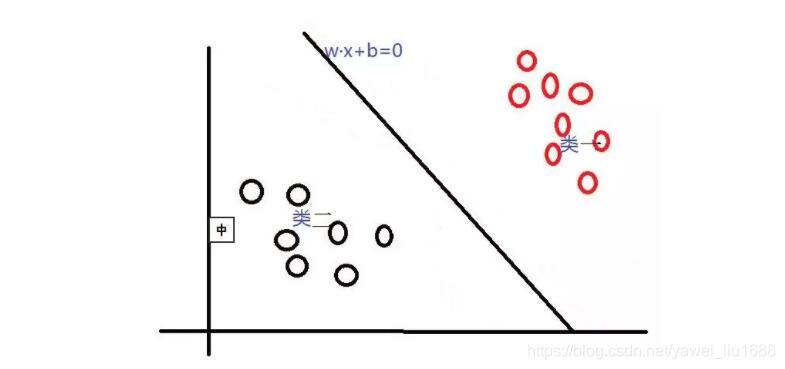
分类问题是监督学习的核心问题,在监督学习中,当输出变量 f(x) 取有限个离散值时,预测问题就成为了分类问题。这事,输入变量 x 可以是离散的,也可以是连续的。监督学习从数据中学习一个分类模型或分类决策函数,称为分类器,分类器对新的输入进行输出的预测,称为分类。可能的输出称为类别。分类的类别为两个时,称为二类分类问题,分类的类别为多个时,称为多类分类问题。
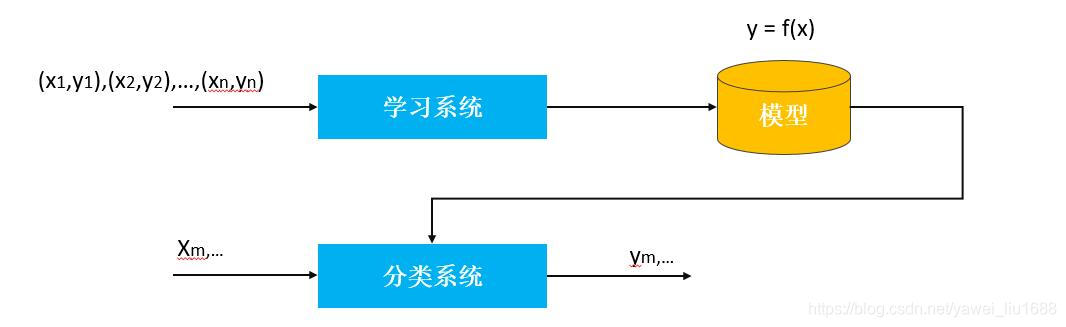
分类问题包括学习(训练)和分类(预测)两个过程。在学习过程中,根据已知的训练数据利用有效的学习方法学习一个分类器;在分类过程中,利用学习的分类器对新的输入数据进行预测分类。如下如,图中(x1,y1),(x2,y2),…,(xn,yn)是训练数据,学习系统有训练数据学习一个分类器 y = f(x) ;分类系统通过学到的分类器对于新输入的数据进行分类预测。
许多算法可以用于分类,包括K近邻法、感知机、朴素贝叶斯、决策树、逻辑回归、支持向量机、集成方法、神经网络等。
| 监督学习算法 | 算法简介 |
| K近邻 | 通过测量不同特征值之间的距离分类。当输入没有标签的新数据时,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)数据的标签作为预测标签。 |
| 感知机 | 假设训练数据集是线性可分的,感知机学习的目标就是求得一个能够将训练集正实例点和负实例点完成正确分开的分离超平面。为此导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。感知机是神经网络与支持向量机的基础。 |
| 朴素贝叶斯(Naive Bayes) | 朴素贝叶斯(Naive Bayes)中的“朴素”,表示所有特征变量间相互独立,不会影响彼此。主要思想就是:如果有一个需要分类的数据,它有一些特征,我们看看这些特征最多地出现在哪些类别中,哪个类别相应特征出现得最多,就把它放到哪个类别里。基本原理还是来自贝叶斯定理。是一种基于概率论的算法,在做决策时要求分类器给出一个最优的类别猜测结果,同时给出这个猜测的概率估计值。 |
| 逻辑回归(Logistic) | Logistic回归虽然名字叫”回归”,但却是一种分类学习方法。使用场景大概有两个:第一用来预测,第二寻找因变量的影响因素。逻辑回归是分类和预测算法中的一种。通过历史数据的表现对未来结果发生的概率进行预测。例如,我们可以将购买的概率设置为因变量,将用户的特征属性,例如性别,年龄,注册时间等设置为自变量。根据特征属性预测购买的概率。 |
| 支持向量机(SVM) | 支持向量机也称为支持向量网络。在给定一组训练样本后,每个训练样本被标记为属于两个类别中的一个或另一个。支持向量机的训练算法会创建一个将新的样本分配给两个类别之一的模型,使其成为非概率二元线性分类器。支持向量机模型将样本表示为在空间中的映射的点,这样具有单一类别的样本能尽可能明显的间隔分开出来。所有这样新的样本映射到同一空间,就可以基于它们落在间隔的哪一侧来预测属于哪一类别。 |
| 决策树 | 决策树是基于特征对实例进行分类的树形结构。根据一些特征进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上 |
| 集成方法 | 主要有bagging、boosting两种集成多个分类器的方法 其中bagging思想是把训练集进行随机放回抽样,抽取出与原训练集数量相同的新数据集,总共生成多个样本数量相同的新训练集。利用同一个学习算法对这几个训练集训练,形成多个分类器。之后预测新实例时用多个分类器同时进行预测,选择最多的分类类别作为结果。最常用的方法是随机森林;boosting思想只用原始数据集,但对里面每个样本赋予权重,先后用同种弱分类器训练数据集,每个弱分类器训练结束得到由分类正确率计算出来的alpha值,再通过这个值更新样本权重。预测新实例时是将每个弱分类器预测结果乘alpha值线性相加得到。最常用的方法是Adaboost。 |
| 神经网络 | 神经网络是一种模拟人脑结构的算法模型。其原理就在于将信息分布式存储和并行协同处理。虽然每个单元的功能非常简单,但大量单元构成的网络系统就能实现非常复杂的数据计算,并且还是一个高度复杂的非线性动力学习系统。神经网络的结构更接近于人脑,具有大规模并行、分布式存储和处理、自组织、自适应和自学能力。 |
分类在于根据其特性将数据“分门别类”,所以在许多领域都有广泛的应用,例如,在银行业务中,可以构建一个客户分类模型,对客户按照贷款风险的大小进行分类;在邮箱的收取上,可以利用相关数据的分类对广告邮件进行屏蔽;在电信行业,可以根据用户的语音使用和流量使用行为,训练分类模型对用户开展诈骗用户识别等等。
回归问题
Y=f(X)+ ε, X=(x1,x2,....xn)
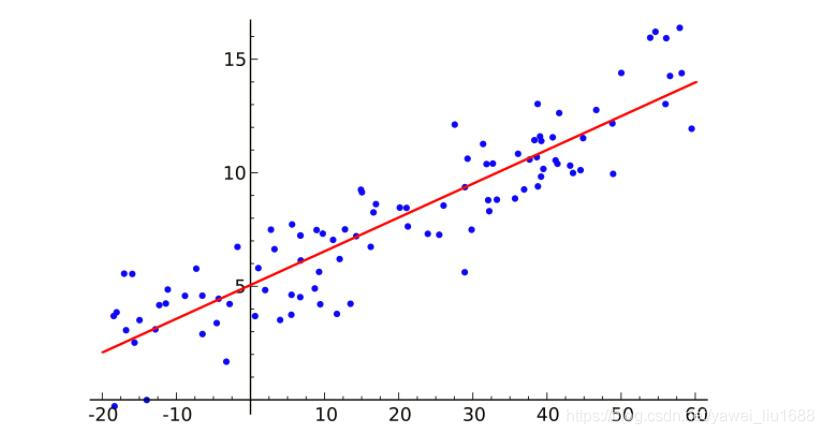
回归是监督学习的另一个重要问题,假设输入变量(x)和单个输出变量(y)之间存在线性关系的模型。 更具体地,y可以从输入变量(x)的线性组合计算,当输入变量的值发生变化时,输出变量的值随之发生变化。回归模型正是表示从输入变量到输出变量之间映射的函数。回归问题的学习等价于函数拟合:选择一条函数曲线使其很好的拟合已知数据且很好的预测未知数据。我们初高中非常熟悉的 y=ax+b 就是一种线性回归模型。
回归问题分为学习和预测两个过程:
- 学习:机器从带有标签的训练数据中学习得f
- 预测:机器从无标签的测试数据中预测Y
具体的,首先给定一个训练数据集:T = {(x1,y1),(x2,y2),…,(xn,yn) } ,学习系统基于训练数据构建一个模型,即函数 y = f(x) ;对新的输入数据。预测系统根据学习到的模型确定相应的输出。见下图:
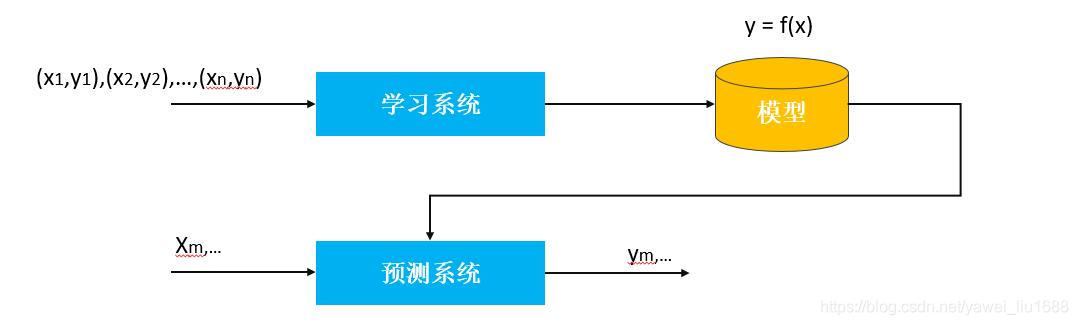
回归问题按照输入变量的个数,可以进一步细分为一元回归和多元回归;按照输入变量和输出变量之间关系的类型即模型的类型,分为线性回归和非线性回归。
一元回归模型
线性回归(linear regression)是一种线性模型,它假设输入变量x 和单个输出变量y之间存在线性关系。具体来说,利用线性回归模型,可以从一组输入变量X的线性组合中, 计算输出变量y。
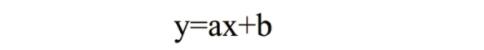
多元线性回归
如果有两个或两个以上的自变量,这样的线性回归分析就称为多元线性回归。实际问题中,一个现象往往是受多个因素影响的,所以多元线性回归 比一元线性回归的实际应用更广。
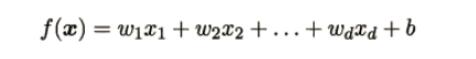
回归学习最常用的损失函数是平方损失函数,在此情况下,回归问题可以由著名的最小二乘法求解。
许多领域的任务都可以形式化为回归问题,比如股价预测、市场销量预测、趋势分析等。
分类与回归对比
- 分类问题的核心是如何利用模型来判别一个数据样本的类别。这个类别一般是离散的,比如两类或者多类。
- 回归问题的核心则是利用模型来输出一个预测的数值。这个数值一般是一个实数,是连续的。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)