机器学习面试:交叉特征
1.困惑之源半年前第一次做推荐算法,无意中碰到了一个问题,我使用LR模型对用户和商品进行联合打分,其中使用了所谓的交叉特征,这个问题思考了大半年终于有了一些思路。问题是这样的,我统计了不同用户在不同类目上的点击率,以此作为所谓的交叉特征,并且将点击率做了一个线上表,当用户请求时,直接查询用户历史所有的类目偏好。其中ucucuc表示用户(user)和类目(cate)的交叉特征,这里为点击率,下标表示
1.困惑之源
半年前第一次做推荐算法,无意中碰到了一个问题,我使用LR模型对用户和商品进行联合打分,其中使用了所谓的交叉特征,这个问题思考了大半年终于有了一些思路。
问题是这样的,我统计了不同用户在不同类目上的点击率,以此作为所谓的交叉特征,并且将点击率做了一个线上表,当用户请求时,直接查询用户历史所有的类目偏好。其中ucucuc表示用户(user)和类目(cate)的交叉特征,这里为点击率,下标表示用户id和类目id
| 用户 | 数码 | 女装 | 美妆 |
|---|---|---|---|
| u1u_1u1 | uc11uc_{11}uc11 | uc12uc_{12}uc12 | uc13uc_{13}uc13 |
| u2u_2u2 | uc21uc_{21}uc21 | uc22uc_{22}uc22 | uc23uc_{23}uc23 |
| u3u_3u3 | uc31uc_{31}uc31 | uc32uc_{32}uc32 | uc33uc_{33}uc33 |
| u4u_4u4 | uc41uc_{41}uc41 | uc42uc_{42}uc42 | uc43uc_{43}uc43 |
但是受到了其他同事的质疑,他说交叉特征是确定某个用户和某个类目之后,再去确定的某一个特征,例如在我们针对用户u1u_1u1推送了类目c3c_3c3,此时可以确定一个交叉特征uc13uc_{13}uc13,这一个特征才是交叉特征。我觉得非常奇怪,为什么不可以把用户所有类目的偏好放到LR模型中呢?
2.特征处理
我将特征分层了三个部分
- 用户特征,包括用户性别,登陆次数,RFM等
- 商品特征,包括商品是否包邮,商品价格,商品类目等
- 交叉特征,这里主要用户和类目的交叉
为了简单,假设这里用户特征只有性别,商品特征只有类目,交叉特征就是性别和类目,由于都是离散特征,需要做onehot编码
| 类目 | c1c_1c1 | c2c_2c2 | c3c_3c3 |
|---|---|---|---|
| 数码 | 1 | 0 | 0 |
| 女装 | 0 | 1 | 0 |
| 美妆 | 0 | 0 | 1 |
| 性别 | s1s_1s1 | s2s_2s2 |
|---|---|---|
| 男 | 1 | 0 |
| 女 | 0 | 1 |
| 性别x类目 | s1c1s_1c_1s1c1 | s1c2s_1c_2s1c2 | s1c3s_1c_3s1c3 | s2c1s_2c_1s2c1 | s2c2s_2c_2s2c2 | s2c3s_2c_3s2c3 |
|---|---|---|---|---|---|---|
| 男x数码 | 1 | 0 | 0 | 0 | 0 | 0 |
| 男x女装 | 0 | 1 | 0 | 0 | 0 | 0 |
| 男x美妆 | 0 | 0 | 1 | 0 | 0 | 0 |
| 女x数码 | 0 | 0 | 0 | 1 | 0 | 0 |
| 女x女装 | 0 | 0 | 0 | 0 | 1 | 0 |
| 女x美妆 | 0 | 0 | 0 | 0 | 0 | 1 |
3. LR模型
我之前最熟悉的是LR模型,可解释性强,有大规模训练库,并且可以快速上线。特征处理好之后就可以直接输入到LR模型之中了
y=σ(x)=11+e−∑wixiy=\sigma(x)=\frac{1}{1+e^{-\sum w_ix_i}}y=σ(x)=1+e−∑wixi1
做一个非常有趣的变换
f(y)=ln(y1−y)=∑wixif(y)=ln(\frac{y}{1-y})=\sum w_ix_if(y)=ln(1−yy)=∑wixi
为什么做这个变换呢?我们知道推荐系统的目标是排序,预测概率是为排序服务的,例如我们有两个物品i1,i2i_1,i_2i1,i2,如果有y1>y2y_1>y_2y1>y2,那么给用户推荐商品的时候就是先推i1i_1i1,然后再推i2i_2i2,这个没有任何问题。有趣的地方来了,如果y1>y2y_1>y_2y1>y2,f(y1)f(y_1)f(y1)和f(y2)f(y_2)f(y2)的大小关系是什么呢?
f(y1)−f(y2)=ln(y11−y1)−ln(y21−y2)=ln(y1−y1y2y2−y1y2)>0\begin{aligned} f(y_1)-f(y_2)&=ln(\frac{y_1}{1-y_1})-ln(\frac{y_2}{1-y_2})\\ &=ln(\frac{y_1-y_1y_2}{y_2-y_1y_2})>0 \end{aligned}f(y1)−f(y2)=ln(1−y1y1)−ln(1−y2y2)=ln(y2−y1y2y1−y1y2)>0
所以当y1>y2y_1>y_2y1>y2时,有f(y1)>f(y2)f(y_1)>f(y_2)f(y1)>f(y2),函数变换之后并不会影响大小顺序。这样做有什么好处呢?原本我们需要去计算σ(x)\sigma(x)σ(x),然后去比较概率大小,现在我们直接计算∑wx\sum wx∑wx后排序就可以了,最重要的是线性函数有更强的可解释性。
之后可以将特征进行分组,例如分为用户特征,商品特征,交叉特征等等,可以写成
∑wixi=∑wjxj+∑wkxk+...\sum w_ix_i=\sum w_jx_j+\sum w_kx_k +...∑wixi=∑wjxj+∑wkxk+...
3.无交叉特征
特征现在有性别和类目,我们先不使用交叉特征直接训练一个LR模型试试。
fu(i)=ws1∗s1+ws2∗s2‾+wc1∗c1+wc2∗c2+wc3∗c3‾=ctruser+ctritem\begin{aligned} f_u(i)&=\underline{w_{s1}*s_1+w_{s2}*s_2} +\underline{{w_{c1}*c_1+w_{c2}*c_2}+w_{c3}*c_3}\\ &= ctr_{user} + ctr_{item} \end{aligned}fu(i)=ws1∗s1+ws2∗s2+wc1∗c1+wc2∗c2+wc3∗c3=ctruser+ctritem
当模型训练完成之后,各个维度的权重就固定下来了。针对不同的用户,相同类目的权重是一样的,没有任何差异性
假如有一个用户u1u_1u1,有三个待推荐的商品,分别属于三个类目i1:c1=1,i2:c2=1,i3:c3=1i_1:c_1=1,i_2:c_2=1,i_3:c_3=1i1:c1=1,i2:c2=1,i3:c3=1。我们首先对用户u1u_1u1推荐商品,
i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ctru1+ctri1,ctru1+ctri2,ctru1+ctri3)=argmax(ws1+wc1,ws1+wc2,ws1+wc3)=argmax(wc1,wc2,wc3)\begin{aligned} i^*&=argmax(f(u_1,i_1),f(u_1,i_2),f(u_1,i_3))\\ &=argmax(ctr_{u_1}+ctr_{i1},ctr_{u_1}+ctr_{i2},ctr_{u_1}+ctr_{i3})\\ &=argmax(w_{s1}+w_{c1},w_{s1}+w_{c2},w_{s1}+w_{c3})\\ &=argmax(w_{c1},w_{c2},w_{c3}) \end{aligned}i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ctru1+ctri1,ctru1+ctri2,ctru1+ctri3)=argmax(ws1+wc1,ws1+wc2,ws1+wc3)=argmax(wc1,wc2,wc3)
因为是同一个用户,所以ctru1=wsxctr_{u1}=w_{sx}ctru1=wsx的值都是相同的,可以都去掉,最后发现排序的结果竟然只与商品的权重有关。这就会有一个非常严重的问题,我们的模型没有个性化的能力,什么意思呢?假如现在我们要对用户u2u_2u2推荐商品,
i∗=argmax(f(u2,i1),f(u2,i2),f(u2,i3))=argmax(ctru2+ctri1,ctru2+ctri2,ctru2+ctri3)=argmax(ws2+wc1,ws2+wc2,ws2+wc3)=argmax(wc1,wc2,wc3)\begin{aligned} i^*&=argmax(f(u_2,i_1),f(u_2,i_2),f(u_2,i_3))\\ &=argmax(ctr_{u2}+ctr_{i1},ctr_{u2}+ctr_{i2},ctr_{u2}+ctr_{i3})\\ &=argmax(w_{s2}+w_{c1},w_{s2}+w_{c2},w_{s2}+w_{c3})\\ &=argmax(w_{c1},w_{c2},w_{c3}) \end{aligned}i∗=argmax(f(u2,i1),f(u2,i2),f(u2,i3))=argmax(ctru2+ctri1,ctru2+ctri2,ctru2+ctri3)=argmax(ws2+wc1,ws2+wc2,ws2+wc3)=argmax(wc1,wc2,wc3)
换了一个用户,竟然排序结果没有发生任何变化,依然只与商品的特征相关。推荐系统最重要的就是个性化,根据用户信息给出推荐,而这里得到的结论却是与用户特征无关,本质就是没有使用交叉特征的原因。
4. 全类目统计特征
回到最开始的问题,我将用户所有类目的偏好都作为输入,到底是不是交叉特征,同样看一下简单的推导
fu(i)=ws1∗s1+ws2∗s2‾+wp1∗pu(1)+wp2∗pu(2)+wp3∗pu(3)‾+wc1∗c1+wc2∗c2+wc3∗c3‾=ctruser+ctrprefer+ctritem\begin{aligned} f_u(i)&=\underline{w_{s1}*s_1+w_{s2}*s_2} +\underline{w_{p_1}*p_u(1)+w_{p_2}*p_u(2)+w_{p_3}*p_u(3)}+\underline{w_{c1}*c_1+w_{c2}*c_2+w_{c3}*c_3}\\ &=ctr_{user}+ctr_{prefer}+ctr_{item} \end{aligned}fu(i)=ws1∗s1+ws2∗s2+wp1∗pu(1)+wp2∗pu(2)+wp3∗pu(3)+wc1∗c1+wc2∗c2+wc3∗c3=ctruser+ctrprefer+ctritem
其中pu(i)p_u(i)pu(i)是用户在每个类目上的点击率。我们可以统计用户近一年内在不同类目上的点击率,然后存储成一个表,
| 统计值T | c1c_1c1 | c2c_2c2 | c3c_3c3 |
|---|---|---|---|
| u1u_1u1 | p1(1)p_1(1)p1(1) | p1(2)p_1(2)p1(2) | p1(3)p_1(3)p1(3) |
| u2u_2u2 | p2(1)p_2(1)p2(1) | pu(i)p_u(i)pu(i) | … |
对每个用户来说,这三个值都是固定的。
i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ctruser+ctrp+ctri1,ctruser+ctrp+ctri2,ctruser+ctrp+ctri3)=ctruser+ctrprefer+argmax(ctri1,ctri2,ctri3)=argmax(ctri1,ctri2,ctri3)=argmax(wc1,wc2,wc3)\begin{aligned} i^*&=argmax(f(u_1,i_1),f(u_1,i_2),f(u_1,i_3))\\ &=argmax(ctr_{user}+ctr_{p}+ctr_{i_1},ctr_{user}+ctr_{p}+ctr_{i_2},ctr_{user}+ctr_{p}+ctr_{i_3})\\ &=ctr_{user}+ctr_{prefer}+argmax(ctr_{i_1},ctr_{i_2},ctr_{i_3})\\ &=argmax(ctr_{i_1},ctr_{i_2},ctr_{i_3})\\ &=argmax(w_{c1},w_{c2},w_{c3}) \end{aligned}i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ctruser+ctrp+ctri1,ctruser+ctrp+ctri2,ctruser+ctrp+ctri3)=ctruser+ctrprefer+argmax(ctri1,ctri2,ctri3)=argmax(ctri1,ctri2,ctri3)=argmax(wc1,wc2,wc3)
其中ctrp=∑wp∗pu(c)ctr_{p}=\sum w_{p}*p_u(c)ctrp=∑wp∗pu(c),针对同一个用户pu(c)p_u(c)pu(c)是相同的,同一个模型权重偏好是相同的
即使增加了用户在不同类目上的统计特征,依然只与商品特征有关系,与用户特征没有任何关系,并没有得到我们期望的交叉特征的效果。其实当时我列出这个式子的时候,就大致发现问题所在了,我希望的是当给用户推荐商品i=1i=1i=1的时候,只有p(1)p(1)p(1)是激活的,其他的值都应该是0,但是这里不管输入什么商品,所有类目偏好都是激活的,这就会导致ctrpreferctr_{prefer}ctrprefer不会改变。
5.单类目统计特征
回想之前师兄给我讲的是,交叉特征是确定用户和商品之后唯一确定的,需要单独将每个每个类目的统计值取出来,例如针对用户u1,我们给商品i1i_1i1打分的时候,只将与i1i_1i1有关的偏好特征筛选出来即可,其他的偏好值为0,这个很简单,直接修改ctrpreferctr_{prefer}ctrprefer为
ctrprefer=wp∗pu(i)ctr_{prefer}=w_{p}*p_u(i)ctrprefer=wp∗pu(i)
原来的式子变成
fu(i)=ws1∗s1+ws2∗s2‾+wp∗pu(i)‾+wc1∗c1+wc2∗c2+wc3∗c3‾\begin{aligned} f_u(i)&=\underline{w_{s1}*s_1+w_{s2}*s_2} +\underline{w_{p}*p_u(i)}+\underline{w_{c1}*c_1+w_{c2}*c_2+w_{c3}*c_3}\\ \end{aligned}fu(i)=ws1∗s1+ws2∗s2+wp∗pu(i)+wc1∗c1+wc2∗c2+wc3∗c3
同样针对用户u1u_1u1,分别对商品进行打分
f(u1,i1)=ws1‾+wp∗p1(1)‾+wc1‾f(u1,i2)=ws1‾+wp∗p1(2)‾+wc2‾f(u1,i3)=ws1‾+wp∗p1(3)‾+wc3‾ f(u_1,i_1)=\underline{w_{s1}} +\underline{w_{p}*p_1(1)}+\underline{w_{c1}}\\ f(u_1,i_2)=\underline{w_{s1}} +\underline{w_{p}*p_1(2)}+\underline{w_{c2}}\\ f(u_1,i_3)=\underline{w_{s1}} +\underline{w_{p}*p_1(3)}+\underline{w_{c3}} f(u1,i1)=ws1+wp∗p1(1)+wc1f(u1,i2)=ws1+wp∗p1(2)+wc2f(u1,i3)=ws1+wp∗p1(3)+wc3
然后我们进行排序筛选
i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ws1+wp∗p1(1)+wc1,ws1+wp∗p1(2)+wc2,ws1+wp∗p1(3)+wc3)=ws1+argmax(wp∗p1(1)+wc1,wp∗p1(2)+wc2,wp∗p1(3)+wc3)=argmax(wp∗p1(1)+wc1,wp∗p1(2)+wc2,wp∗p1(3)+wc3)\begin{aligned} i^*&=argmax(f(u_1,i_1),f(u_1,i_2),f(u_1,i_3))\\ &=argmax(w_{s1}+w_{p}*p_1(1)+w_{c1},w_{s1}+w_{p}*p_1(2)+w_{c2},w_{s1}+w_{p}*p_1(3)+w_{c3})\\ &=w_{s1}+argmax(w_{p}*p_1(1)+w_{c1},w_{p}*p_1(2)+w_{c2},w_{p}*p_1(3)+w_{c3})\\ &=argmax(w_{p}*p_1(1)+w_{c1},w_{p}*p_1(2)+w_{c2},w_{p}*p_1(3)+w_{c3}) \end{aligned}i∗=argmax(f(u1,i1),f(u1,i2),f(u1,i3))=argmax(ws1+wp∗p1(1)+wc1,ws1+wp∗p1(2)+wc2,ws1+wp∗p1(3)+wc3)=ws1+argmax(wp∗p1(1)+wc1,wp∗p1(2)+wc2,wp∗p1(3)+wc3)=argmax(wp∗p1(1)+wc1,wp∗p1(2)+wc2,wp∗p1(3)+wc3)
如果针对用户u2u_2u2打分的话
i∗=argmax(wp∗p2(1)+wc1,wp∗p2(2)+wc2,wp∗p2(3)+wc3)i^*=argmax(w_{p}*p_2(1)+w_{c1},w_{p}*p_2(2)+w_{c2},w_{p}*p_2(3)+w_{c3})i∗=argmax(wp∗p2(1)+wc1,wp∗p2(2)+wc2,wp∗p2(3)+wc3)
这回好像就是我们想要的结果了,每个商品中,除了商品自身特征贡献的ctr之外,还包含了用户在每个类目上的点击率,并且不同用户的点击率是不同的,也体现出了个性化。
对上式再次进行一次变换,都除以wpw_pwp,不会改变排序
i∗=argmax(pu(1)+wc1wp,pu(2)+wc1wp,pu(3)+wc1wp)=argmax(pu(1)+wc1∗,pu(2)+wc2∗,pu(3)+wc3∗)\begin{aligned} i^*&=argmax(p_u(1)+\frac{w_{c1}}{w_p} ,p_u(2)+\frac{w_{c1}}{w_p} ,p_u(3)+\frac{w_{c1}}{w_p} )\\ &=argmax(p_u(1)+w_{c1}^{*},p_u(2)+w_{c2}^{*},p_u(3)+w_{c3}^{*}) \end{aligned}i∗=argmax(pu(1)+wpwc1,pu(2)+wpwc1,pu(3)+wpwc1)=argmax(pu(1)+wc1∗,pu(2)+wc2∗,pu(3)+wc3∗)
这个式子可以说明一个问题,我们直接引入的统计值(最好归一化,否则系数wpw_pwp会很大),对商品排序有极大的影响,当我们直接使用ctrctrctr作为统计值的时候,有很强的可解释性。pu(i)p_u(i)pu(i)可以认为是用户在这个类目上点击率的基准值,通过模型的学习,得到一个校准值wci∗w_{ci}^{*}wci∗,两者之间的加和即位整体的ctr预估值。
这种人工构建的交叉特征,一般情况下主要也是用来加权。
6.交叉特征
上面研究了人工构建的交叉特征,现在考虑一下模型构建交叉特征,也就是最为常规的交叉特征。回去看2的特征处理,里面有一个【性别x类目】的交叉特征,也是一个onehot编码,我们只看交叉特征对ctr的贡献
ctrprefer=w11∗s1c1+w12∗s1c2+w13∗s1c3+w21∗s2c1+w22∗s2c2+w23∗s2c3\begin{aligned} ctr_{prefer}=w_{11}*s_1c_1+w_{12}*s_1c_2+w_{13}*s_1c_3+w_{21}*s_2c_1+w_{22}*s_2c_2+w_{23}*s_2c_3 \end{aligned}ctrprefer=w11∗s1c1+w12∗s1c2+w13∗s1c3+w21∗s2c1+w22∗s2c2+w23∗s2c3
当我们对用户u1u_1u1推送商品i1i_1i1时,有s1=1,s1c1=1s_1=1,s_1c_1=1s1=1,s1c1=1,f1(1)=w11f_1(1)=w_{11}f1(1)=w11
同理,推送商品i2,i3i_2,i_3i2,i3时,有f1(2)=w12f_1(2)=w_{12}f1(2)=w12,f1(3)=w13f_1(3)=w_{13}f1(3)=w13
对商品进行排序后有i∗=argmax(w11+wc1,w12+wc2,w13+wc3)i^*=argmax(w_{11}+w_{c1},w_{12}+w_{c2},w_{13}+w_{c3})i∗=argmax(w11+wc1,w12+wc2,w13+wc3)
当我们对用户u2u_2u2推送商品时有i∗=argmax(w21+wc1,wc2+w22,w23+wc3)i^*=argmax(w_{21}+w_{c1},w_{c2}+w_{22},w_{23}+w_{c3})i∗=argmax(w21+wc1,wc2+w22,w23+wc3)
我们将手动构建的交叉特征进行比对
i∗=argmax(wu(1)+wc1,wu(2)+wc2,wu(3)+wc3)i∗=argmax(pu(1)+wc1,pu(2)+wc2,pu(3)+wc3)\begin{aligned} i^*&=argmax(w_u(1)+w_{c1},w_u(2)+w_{c2},w_u(3)+w_{c3})\\ i^*&=argmax(p_u(1)+w_{c1},p_u(2)+w_{c2},p_u(3)+w_{c3}) \end{aligned}i∗i∗=argmax(wu(1)+wc1,wu(2)+wc2,wu(3)+wc3)=argmax(pu(1)+wc1,pu(2)+wc2,pu(3)+wc3)
其中wu(i)w_u(i)wu(i)是模型学习到的交叉特征的权重,pu(i)p_u(i)pu(i)是人工构建的交叉特征统计值,他们两个在LR模型中的形式一模一样,只是值是不同的,也就是说模型可以学习到手工构建的特征值。
7.隐式特征交叉
模型可以自动训练出人工构建的交叉特征权重值,但是依然有两个问题
- 交叉特征需要用户手动指定
- 特征维度膨胀,M维特征和N维特征交叉之后会得到MxN维新特征
- 交叉特征稀疏,交叉特征本身就是onehot编码,只有一个值为1,其他都是0
这世界上真的有天才,FM可以自动完成所有的特征交叉,无需用户指定,并且不会产生维度膨胀。不可思议,真的不可思议。我们本身要得到的不是交叉特征,而是交叉特征前的权重,如果想要得到权重,需要单独生成一列特征,模型训练之后会得到这个特征的权重。首先看一下一个样本是如何变化的
样本1:用户u1u_1u1,推送商品i1i_1i1,用户特征有性别【男】,商品特征有类目【数码】
| 性别 | 类目 |
|---|---|
| 男 | 数码 |
然后我们将这条朴实无华的样本进行onehot编码得到正常的样本格式
| s1s_1s1 | s2s_2s2 | c1c_1c1 | c2c_2c2 | c3c_3c3 |
|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 |
然后增加性别和类目的交叉特征
| s1s_1s1 | s2s_2s2 | c1c_1c1 | c2c_2c2 | c3c_3c3 | s1c1s_1c_1s1c1 | s1c2s_1c_2s1c2 | s1c3s_1c_3s1c3 | s2c1s_2c_1s2c1 | s2c2s_2c_2s2c2 | s2c3s_2c_3s2c3 |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
然后将这样一条条样本输入到LR模型中,最终得到一组权重
| s1s_1s1 | s2s_2s2 | c1c_1c1 | c2c_2c2 | c3c_3c3 | s1c1s_1c_1s1c1 | s1c2s_1c_2s1c2 | s1c3s_1c_3s1c3 | s2c1s_2c_1s2c1 | s2c2s_2c_2s2c2 | s2c3s_2c_3s2c3 |
|---|---|---|---|---|---|---|---|---|---|---|
| ws1w_{s_1}ws1 | ws2w_{s_2}ws2 | wc1w_{c_1}wc1 | wc2w_{c_2}wc2 | wc3w_{c_3}wc3 | ws1c1w_{s_1c_1}ws1c1 | ws1c2w_{s_1c_2}ws1c2 | ws1c3w_{s_1c_3}ws1c3 | ws2c1w_{s_2c_1}ws2c1 | ws2c2w_{s_2c_2}ws2c2 | ws2c3w_{s_2c_3}ws2c3 |
FM是将所有的特征进行交叉,写成公式为
y=w0+∑i=1nwixi+∑i=1j=n∑j=1nviTvjxixjy=w_0+\sum_{i=1}^{n}w_ix_i+\sum_{i=1}^{j=n}\sum_{j=1}^{n}v^{T}_{i}v_{j}x_ix_jy=w0+i=1∑nwixi+i=1∑j=nj=1∑nviTvjxixj
但从这个式子看好像也是需要将xixjx_ix_jxixj进行交叉,并且生成n∗nn*nn∗n维的交叉特征,但其实FM在求解交叉特征前的系数是并不是将样本变换输入的。
一开始理解为,用户和商品进行特征扩充,然后丢到lr模型学习各个特征(包括扩展后的交叉特征)的权重。fm则是根据数学形式做了优化。
8.用户特征
如果仔细看上面的各个公式的话会发现一个问题,单纯的用户特征在商品排序中根本没有任何用处,这是因为我们每次都是针对同一个用户推送物品的
ctruser=wu1u1+wu2u2+wu3u3....=wuTxctritem=wi1i1+wi2i2+wi3i3....=wiTictrcross=wui1ui1+wui2ui2+wui3ui3....wuiTuictr=ctruser+ctritem+ctrcross\begin{aligned} ctr_{user}&=w_{u1}u_1+w_{u2}u_2+w_{u3}u_3....= \boldsymbol{w_u^T} \boldsymbol{x}\\ ctr_{item}&=w_{i1}i_1+w_{i2}i_2+w_{i3}i_3....= \boldsymbol{w_i^T} \boldsymbol{i}\\ ctr_{cross}&=w_{ui1}ui_1+w_{ui2}ui_2+w_{ui3}ui_3.... \boldsymbol{w_{ui}^T} \boldsymbol{ui}\\ ctr&=ctr_{user}+ctr_{item}+ctr_{cross} \end{aligned}ctruserctritemctrcrossctr=wu1u1+wu2u2+wu3u3....=wuTx=wi1i1+wi2i2+wi3i3....=wiTi=wui1ui1+wui2ui2+wui3ui3....wuiTui=ctruser+ctritem+ctrcross
同一个用户,不管推送了什么商品,这个用户的特征都是不会发生任何变化的,权重训练之后也是固定不变的,所以ctruserctr_{user}ctruser也不会改变,更换推荐商品的时候,商品特征是发生变化的,所以ctritemctr_{item}ctritem也是不断变化的,交叉特征中虽然用户没有发生变化,但是用户交叉的商品在变化,导致交叉特征也是在不断变化的,因此ctrcrossctr_{cross}ctrcross的值也是在不断变化。
这就很有意思了,用户特征没有任何用处,唯一使用到用户特征的地方是在交叉特征里面了。我第一次做推荐的时候使用了非常多的用户特征,用户近1/3/7/30/60/180天内的gmv,登陆次数,点击次数,下单次数等等,但其实这些特征单独使用是根本没有任何效果的,必须要跟商品进行交叉才可以。而且可以遇见,用户自身特征的交叉也是没有任何作用的。
后面反应过来,统计用户的gmv其实是想要得到用户的价格区间,这样可以跟商品价格进行交互。可以手动进行交叉【用户价格区间】x【商品价格区间】,也可以使用fm自动进行交叉FM(用户价格区间,商品价格区间)
如果我们使用了神经网络来作为预估模型,纯粹的用户特征依然是非常非常重要的。因为神经网络会自动将用户和商品特征进行交叉,用户特征越多,交叉特征越多,模型会学习到更佳丰富的信息。
9. 用户分群
这是在思考交叉特征的时候想到的一个问题,在训练模型的时候是将所有的用户全都放到一起训练的,为什么不针对每个用户训练一个LR模型呢?例如针对用户u1u_1u1
y1=(w1(1)+wc1)∗c1+(w1(2)+wc2)∗c2+(w1(3)+wc3)∗c3y_1=(w_1(1)+w_{c1})*c_1+(w_1(2)+w_{c2})*c_2+(w_1(3)+w_{c3})*c_3y1=(w1(1)+wc1)∗c1+(w1(2)+wc2)∗c2+(w1(3)+wc3)∗c3
因为是同一个用户,所以单纯的用户特征都是一模一样的,依然不会对商品排序有任何影响。只有交叉特征和商品特征会影响商品的排序,针对用户u2u_2u2
y2=(w2(1)+wc1)∗c1+(w2(2)+wc2)∗c2+(w2(3)+wc3)∗c3y_2=(w_2(1)+w_{c1})*c_1+(w_2(2)+w_{c2})*c_2+(w_2(3)+w_{c3})*c_3y2=(w2(1)+wc1)∗c1+(w2(2)+wc2)∗c2+(w2(3)+wc3)∗c3
针对用户u3u_3u3
y3=(w3(1)+wc1)∗c1+(w3(2)+wc2)∗c2+(w3(3)+wc3)∗c3y_3=(w_3(1)+w_{c1})*c_1+(w_3(2)+w_{c2})*c_2+(w_3(3)+w_{c3})*c_3y3=(w3(1)+wc1)∗c1+(w3(2)+wc2)∗c2+(w3(3)+wc3)∗c3
其实可以看到,针对每个用户其实我们都学习了一个权重向量
| 用户 | f1f_1f1 | f2f_2f2 | f3f_3f3 | … | fjf_jfj |
|---|---|---|---|---|---|
| u1u_1u1 | w11w_{11}w11 | w12w_{12}w12 | w13w_{13}w13 | … | w1jw_{1j}w1j |
| u2u_2u2 | w21w_{21}w21 | w22w_{22}w22 | w23w_{23}w23 | … | w2jw_{2j}w2j |
| u3u_3u3 | w31w_{31}w31 | w32w_{32}w32 | w33w_{33}w33 | … | w3jw_{3j}w3j |
| uiu_iui | wi1w_{i1}wi1 | wi2w_{i2}wi2 | wi3w_{i3}wi3 | … | wijw_{ij}wij |
一个非常直接的问题是,有些用户的行为轨迹非常的少,交互的商品也非常的少,如果直接训练一个模型的话效果会非常的差。那是否可以将用户进行聚类之后再训练呢?根据用户的某些特征进行聚类,例如都喜欢浏览数码产品的用户分到一起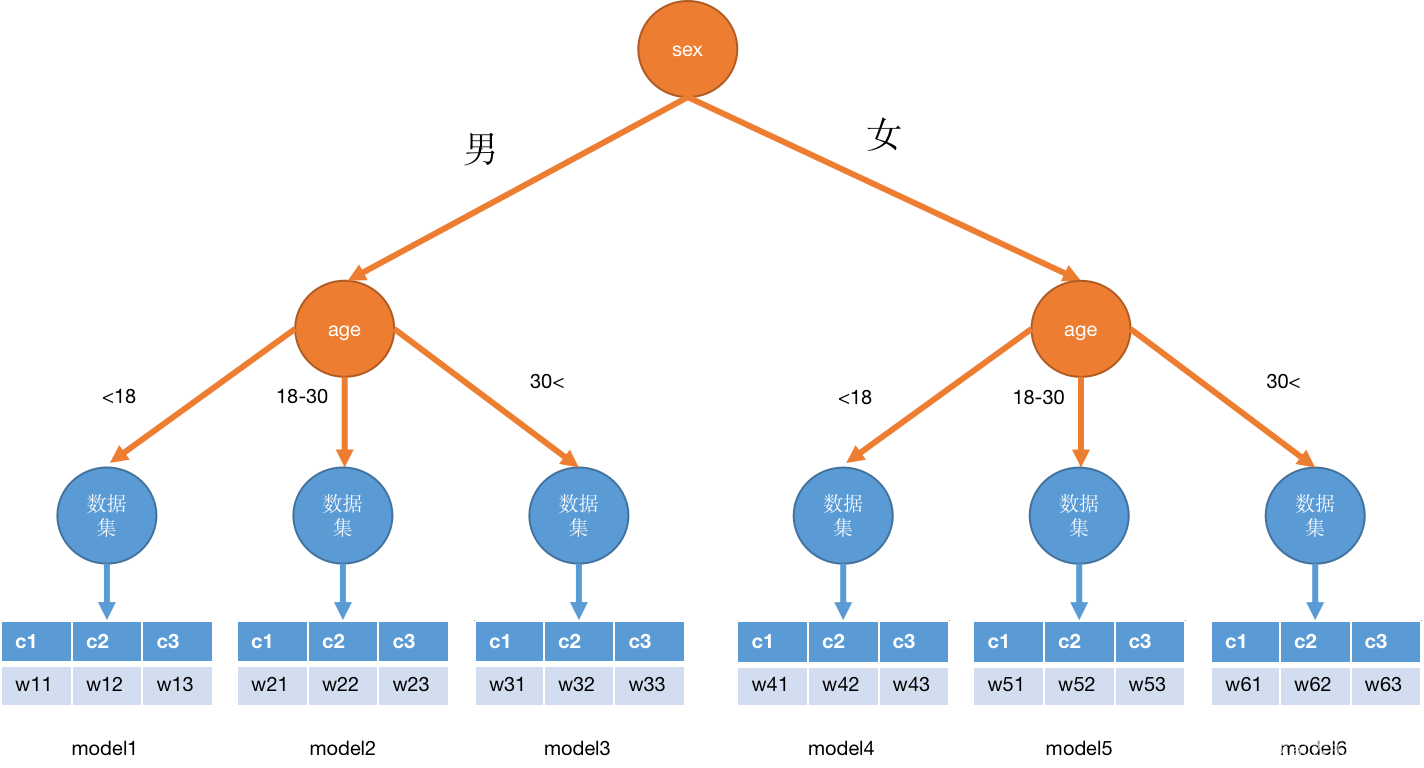
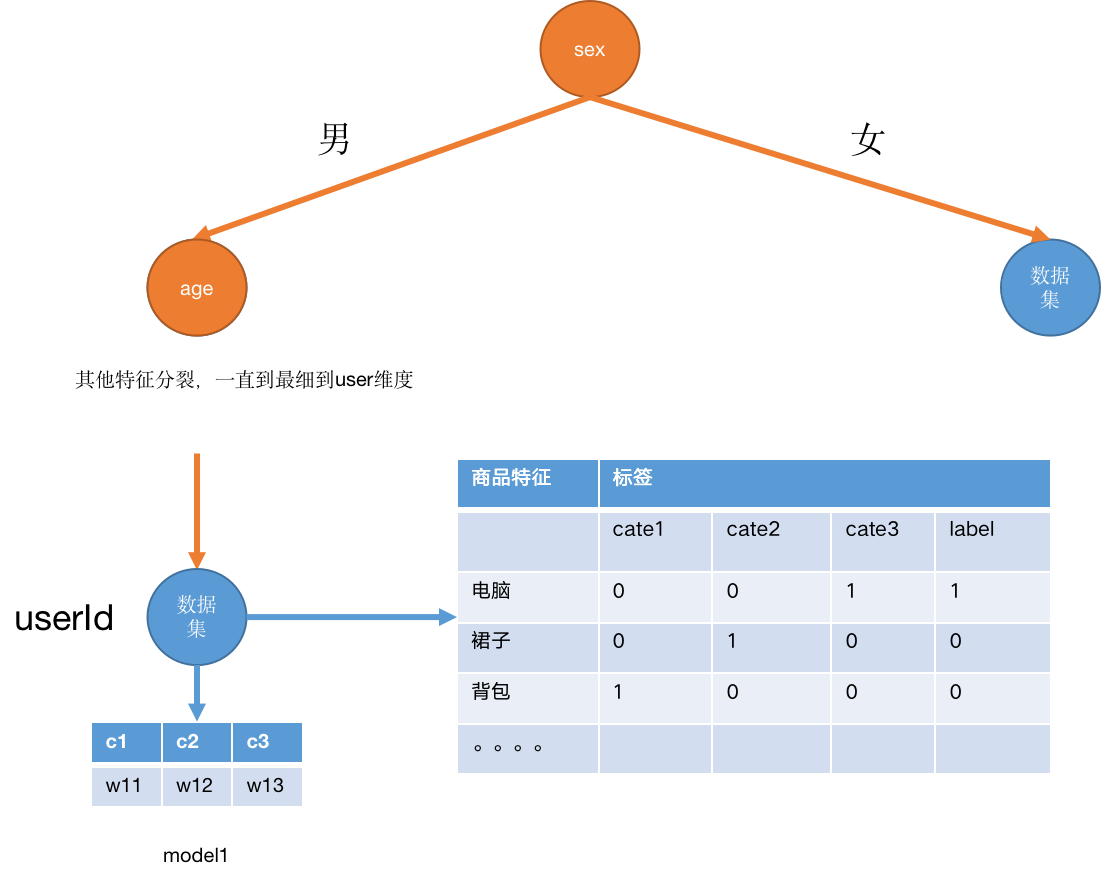
我并没有试过这样的模型,但是这样的思想确实有缘由的。
10. 交叉特征的由来
通过观察大量的样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高。例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征,对用户的点击有着正向的影响。换句话说,来自“China”的用户很可能会在“Chinese New Year”有大量的浏览、购买行为,而在“Thanksgiving”却不会有特别的消费行为。这种关联特征与label的正向相关性在实际问题中是普遍存在的,如“化妆品”类商品与“女”性,“球类运动配件”的商品与“男”性,“电影票”的商品与“电影”品类偏好等。因此,引入两个特征的组合是非常有意义的。
说是交叉特征,感觉本质就是【共现性】。例如word2vec中,词之间的上下文本质就是词之间的共现性来统计

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)