机器学习——多模型选择和融合的方法2(AdaBoost)
Adaptive Boost(AdaBoost)是一种融合模型,而与Blending不同的是,Blending是在得到gtg_tgt之后再进行融合,而AdaBoost是一边学习gtg_tgt,一边融合。那么在介绍AdaBoost之前,首先要看的一个算法模型——前向分步算法。那么,什么是前向分步算法?首先,考虑如下形式的加法模型,f(x)=∑m=1Mβmb(x;γm){\rm{f}}(x...
Adaptive Boost(AdaBoost)是一种融合模型,而与Blending不同的是,Blending是在得到gtg_tgt之后再进行融合,而AdaBoost是一边学习gtg_tgt,一边融合。那么在介绍AdaBoost之前,首先要看的一个算法模型——前向分步算法。
那么,什么是前向分步算法?
首先,考虑如下形式的加法模型,
f(x)=∑m=1Mβmb(x;γm){\rm{f}}(x) = \sum\limits_{m = 1}^M {{\beta _m}b(x;{\gamma _m})}f(x)=m=1∑Mβmb(x;γm)
其中b(x;γm)b(x;{\gamma _m})b(x;γm)是基函数,γm{\gamma _m}γm是基函数的参数,βm{\beta _m}βm是基函数的系数。
显然,函数f(x)是基函数的线性组合,是一个加法模型。
那么,在给定数据集D和损失函数L(y,f(x))L(y,f(x))L(y,f(x))的条件下,学习加法模型就变成了极小化损失函数的问题,
minβm,γm∑i=1NL(yi,∑m=1Mβmb(xi;γm))\mathop {\min }\limits_{{\beta _m},{\gamma _m}} \sum\limits_{i = 1}^N {L({y_i},\sum\limits_{m = 1}^M {{\beta _m}b({x_i};\gamma {}_m)} )}βm,γmmini=1∑NL(yi,m=1∑Mβmb(xi;γm))
解决上述问题的一个思路就是前向分步算法,其具体的想法为:因为学习算法为加法模型,如果能从前往后,每一步只学习一个基函数及其系数,逐步逼近优化目标函数式(上式),那么就可以简化优化的复杂度。
具体的,每一步只需要优化如下的损失函数,
minβ,γ∑i=1NL(yi,b(xi;γ))\mathop {\min }\limits_{\beta ,\gamma } \sum\limits_{i = 1}^N {L({y_i},b({x_i};\gamma ))}β,γmini=1∑NL(yi,b(xi;γ))
具体的前向分布算法如下:
| 前向分步算法 |
|---|
| 输入:训练数据集T={(x1,y1),(x2,y2),⋯ ,(xN,yN)}T = \{ ({x_1},{y_1}),({x_2},{y_2}), \cdots ,({x_N},{y_N})\}T={(x1,y1),(x2,y2),⋯,(xN,yN)};损失函数为L(y,f(x))L(y,f(x))L(y,f(x));基函数集为{b(x;γ)}\{ b(x;\gamma )\}{b(x;γ)}; 输出:加法模型f(x) 1.初始化f0(x)=0{f_0}(x) = 0f0(x)=0 2.对m=1,2,⋯ ,Mm = 1,2, \cdots ,Mm=1,2,⋯,M 2.1 极小化损失函数(βm,γm)=argminβ,γ∑i=1NL(yi,fm−1(xi)+βb(x;γ))({\beta _m},{\gamma _m}) = \arg \mathop {\min }\limits_{\beta ,\gamma } \sum\limits_{i = 1}^N {L({y_i},{f_{m - 1}}({x_i}) + \beta b(x;\gamma ))}(βm,γm)=argβ,γmini=1∑NL(yi,fm−1(xi)+βb(x;γ)) 2.2 更新fm(x)=fm−1(x)+βmb(x;γm){f_m}(x) = {f_{m - 1}}(x) + {\beta _m}b(x;{\gamma _m})fm(x)=fm−1(x)+βmb(x;γm) 3.得到加法模型f(x)=fM(x)=∑m=0Mβmb(x;γm)f(x) = {f_M}(x) = \sum\limits_{m = 0}^M {{\beta _m}b(x;{\gamma _m})}f(x)=fM(x)=m=0∑Mβmb(x;γm) |
前向分步算法将同时求解从m=1到M的所有参数βm,γm{\beta _m},{\gamma _m}βm,γm的优化问题简化为逐步求解各个βm,γm{\beta _m},{\gamma _m}βm,γm的优化问题。
上述就是前向分步算法的主要思想,而AdaBoost就是前向分布算法的一个特例,因为在AdaBoost里,基函数为基本分类器,损失函数为指数损失函数。下面,就基于前向分步算法来推导AdaBoost。
当基函数为基本分类器时,前向分布算法中的加法模型等价于AdaBoost的最终分类器,
f(x)=∑m=1MαmGm(x)f(x) = \sum\limits_{m = 1}^M {{\alpha _m}{G_m}(x)}f(x)=m=1∑MαmGm(x)
其中,Gm(x){G_m}(x)Gm(x)为基本分类器,αm{\alpha _m}αm为基本分类器的系数。
当前向分布算法的损失函数为指数损失函数时,
L(y,f(x))=exp(−yf(x))L(y,f(x)) = \exp ( - yf(x))L(y,f(x))=exp(−yf(x))
由前向分步算法,在经过了m轮迭代后,有,
fm(x)=fm−1(x)+αmGm(x){f_m}(x) = {f_{m - 1}}(x) + {\alpha _m}{G_m}(x)fm(x)=fm−1(x)+αmGm(x)
求解目标是让求得的αm{\alpha _m}αm和Gm(x){G_m}(x)Gm(x)使fm(x){f_m}(x)fm(x)在训练数据集T上的指数损失最小,即,
(αm,Gm(x))=argminα,G∑i=1Nexp(−yi(fm−1(xi)+αG(xi)))                                      =argminα,G∑i=1Nexp(−yifm−1(xi))⎵wˉmiexp(−yiαG(xi)))                                      =argminα,G∑i=1Nwˉmiexp(−yiαG(xi)))\begin{array}{l} ({\alpha _m},{G_m}(x)) = \arg \mathop {\min }\limits_{\alpha ,G} \sum\limits_{i = 1}^N {\exp ( - {y_i}({f_{m - 1}}({x_i}) + \alpha G({x_i})))} \\\\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;{\kern 1pt} {\kern 1pt} = \arg \mathop {\min }\limits_{\alpha ,G} \sum\limits_{i = 1}^N {\underbrace {\exp ( - {y_i}{f_{m - 1}}({x_i}))}_{{{\bar w}_{mi}}}\exp ( - {y_i}\alpha G({x_i})))} \\\\ \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;{\kern 1pt} {\kern 1pt} = \arg \mathop {\min }\limits_{\alpha ,G} \sum\limits_{i = 1}^N {{{\bar w}_{mi}}\exp ( - {y_i}\alpha G({x_i})))} \end{array}(αm,Gm(x))=argα,Gmini=1∑Nexp(−yi(fm−1(xi)+αG(xi)))=argα,Gmini=1∑Nwˉmi
exp(−yifm−1(xi))exp(−yiαG(xi)))=argα,Gmini=1∑Nwˉmiexp(−yiαG(xi)))
其中,wˉmi=exp(−yifm−1(xi)){\bar w_{mi}} = \exp ( - {y_i}{f_{m - 1}}({x_i}))wˉmi=exp(−yifm−1(xi)),之所以把该项单独分出来,是因为该项既不依赖于α\alphaα,也不依赖于GGG,与最小化无关,但其依赖于fm−1(x){f_{m - 1}}(x)fm−1(x),随着每一轮的迭代而改变。
上式中优化的参数有两个α\alphaα和GGG,所以求解也分为两步,先求解GGG,再求解α\alphaα。
首先,求解G,G的含义为基本分类器,所以可由在训练集上最小化损失得到,
Gm(x)=argminG∑i=1Nwˉmi[[yi≠G(xi)]]{G_m}(x) = \arg \mathop {\min }\limits_G \sum\limits_{i = 1}^N {{{\bar w}_{mi}}\left[\kern-0.15em\left[ {{y_i} \ne G({x_i})} \right]\kern-0.15em\right]}Gm(x)=argGmini=1∑Nwˉmi[[yi̸=G(xi)]]
之后,求解αm{\alpha _m}αm,对式(αm,Gm(x))({\alpha _m},{G_m}(x))(αm,Gm(x))进行简化,
          ∑i=1Nwˉmiexp(−yiαG(xi)))=∑i=1Nwˉmiexp(−yiαG(xi)))=∑yi≠Gm(xi)wˉmie−α+∑yi=Gm(xi)wˉmieα=(eα+e−α)∑i=1Nwˉmi[[yi≠G(xi)]]+eα∑i=1Nwˉmi\begin{array}{l} \;\;\;\;\;\sum\limits_{i = 1}^N {{{\bar w}_{mi}}\exp ( - {y_i}\alpha G({x_i})))} \\\\ {\kern 1pt} = \sum\limits_{i = 1}^N {{{\bar w}_{mi}}\exp ( - {y_i}\alpha G({x_i})))} \\\\ = \sum\limits_{{y_i} \ne {G_m}({x_i})} {{{\bar w}_{mi}}{e^{ - \alpha }}} + \sum\limits_{{y_i} = {G_m}({x_i})} {{{\bar w}_{mi}}{e^\alpha }} \\\\ = ({e^\alpha } + {e^{ - \alpha }})\sum\limits_{i = 1}^N {{{\bar w}_{mi}}\left[\kern-0.15em\left[ {{y_i} \ne G({x_i})} \right]\kern-0.15em\right]} + {e^\alpha }\sum\limits_{i = 1}^N {{{\bar w}_{mi}}} \end{array}i=1∑Nwˉmiexp(−yiαG(xi)))=i=1∑Nwˉmiexp(−yiαG(xi)))=yi̸=Gm(xi)∑wˉmie−α+yi=Gm(xi)∑wˉmieα=(eα+e−α)i=1∑Nwˉmi[[yi̸=G(xi)]]+eαi=1∑Nwˉmi
对α\alphaα求导并等于0,得到最优解α\alphaα,其中目标函数H(α)=(eα+e−α)∑i=1Nwˉmi[[yi≠G(xi)]]+eα∑i=1NwˉmiH(\alpha ) = ({e^\alpha } + {e^{ - \alpha }})\sum\limits_{i = 1}^N {{{\bar w}_{mi}}\left[\kern-0.15em\left[ {{y_i} \ne G({x_i})} \right]\kern-0.15em\right]} + {e^\alpha }\sum\limits_{i = 1}^N {{{\bar w}_{mi}}}H(α)=(eα+e−α)i=1∑Nwˉmi[[yi̸=G(xi)]]+eαi=1∑Nwˉmi ,为了方便书写,这里的[[yi≠G(xi)]]\left[\kern-0.15em\left[ {{y_i} \ne G({x_i})} \right]\kern-0.15em\right][[yi̸=G(xi)]]用III代替,
∂H∂α=eα∑wˉmiI+e−α∑wˉmiI−e−α∑wˉmi=0eα∑wˉmiI=e−α(∑wˉmi−∑wˉmiI)α+ln∑wˉmiI=−α+ln(∑wˉmi−∑wˉmiI)2α=ln(∑wˉmi−∑wˉmiI∑wˉmiI)α=12ln(∑wˉmi∑wˉmiI−1)\begin{array}{l} \frac{{\partial H}}{{\partial \alpha }} = {e^\alpha }\sum {{{\bar w}_{mi}}I} + {e^{ - \alpha }}\sum {{{\bar w}_{mi}}I} - {e^{ - \alpha }}\sum {{{\bar w}_{mi}}} = 0\\\\ {e^\alpha }\sum {{{\bar w}_{mi}}I} = {e^{ - \alpha }}(\sum {{{\bar w}_{mi}}} - \sum {{{\bar w}_{mi}}I} )\\\\ \alpha + \ln \sum {{{\bar w}_{mi}}I} = - \alpha + \ln (\sum {{{\bar w}_{mi}}} - \sum {{{\bar w}_{mi}}I} )\\\\ 2\alpha = \ln (\frac{{\sum {{{\bar w}_{mi}}} - \sum {{{\bar w}_{mi}}I} }}{{\sum {{{\bar w}_{mi}}I} }})\\\\ \alpha = \frac{1}{2}\ln (\frac{{\sum {{{\bar w}_{mi}}} }}{{\sum {{{\bar w}_{mi}}I} }} - 1) \end{array}∂α∂H=eα∑wˉmiI+e−α∑wˉmiI−e−α∑wˉmi=0eα∑wˉmiI=e−α(∑wˉmi−∑wˉmiI)α+ln∑wˉmiI=−α+ln(∑wˉmi−∑wˉmiI)2α=ln(∑wˉmiI∑wˉmi−∑wˉmiI)α=21ln(∑wˉmiI∑wˉmi−1)
一般,令em=∑i=1NwˉmiI∑i=1Nwˉmi=∑i=1Nwˉmi[[yi≠Gm(xi)]]∑i=1Nwˉmi{e_m} = \frac{{\sum\limits_{i = 1}^N {{{\bar w}_{mi}}I} }}{{\sum\limits_{i = 1}^N {{{\bar w}_{mi}}} }} = \frac{{\sum\limits_{i = 1}^N {{{\bar w}_{mi}}\left[\kern-0.15em\left[ {{y_i} \ne {G_m}({x_i})} \right]\kern-0.15em\right]} }}{{\sum\limits_{i = 1}^N {{{\bar w}_{mi}}} }}em=i=1∑Nwˉmii=1∑NwˉmiI=i=1∑Nwˉmii=1∑Nwˉmi[[yi̸=Gm(xi)]],则α\alphaα为,
αm=12ln(1−emem){\alpha _m} = \frac{1}{2}\ln (\frac{{1 - {e_m}}}{{{e_m}}})αm=21ln(em1−em)
最后,再来看一下每一轮样本权值的更新,因为wˉmi=exp(−yifm−1(xi)){\bar w_{mi}} = \exp ( - {y_i}{f_{m - 1}}({x_i}))wˉmi=exp(−yifm−1(xi)),所以在第m+1轮有,
wˉm+1,i=exp(−yifm(xi))                =exp(−yi(fm−1(xi)+αmGm(xi)))                  =wˉmiexp(−yiαmGm(xi))\begin{array}{l} {{\bar w}_{m + 1,i}} = \exp ( - {y_i}{f_m}({x_i}))\\\\ \;\;\;\;\;\;\;\;{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} = \exp ( - {y_i}({f_{m - 1}}({x_i}) + {\alpha _m}{G_m}({x_i})))\\\\ {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \;\;\;\;\;\;\;\;\; = {\kern 1pt} {{\bar w}_{mi}}\exp ( - {y_i}{\alpha _m}{G_m}({x_i})) \end{array}wˉm+1,i=exp(−yifm(xi))=exp(−yi(fm−1(xi)+αmGm(xi)))=wˉmiexp(−yiαmGm(xi))
这里如果对wˉmi{\bar w_{mi}}wˉmi规范化,即,使得∑i=1Nwmi=1\sum\limits_{i = 1}^N {{w_{mi}} = 1}i=1∑Nwmi=1 ,则有,
wmi=wˉmi∑i=1Nwˉmi{w_{mi}} = \frac{{{{\bar w}_{mi}}}}{{\sum\limits_{i = 1}^N {{{\bar w}_{mi}}} }}wmi=i=1∑Nwˉmiwˉmi
那么,第m+1轮规范化后的样本权值为,
wm+1,i=wmiZmexp(−yiαmGm(xi)){w_{m + 1,i}} = \frac{{{w_{mi}}}}{{{Z_m}}}\exp ( - {y_i}{\alpha _m}{G_m}({x_i}))wm+1,i=Zmwmiexp(−yiαmGm(xi))
其中 Zm=∑i=1Nwmiexp(−yiαmGm(xi)){Z_m} = \sum\limits_{i = 1}^N {{w_{mi}}\exp ( - {y_i}{\alpha _m}{G_m}({x_i}))}Zm=i=1∑Nwmiexp(−yiαmGm(xi))。
以上就是,AdaBoost算法的推导,那么写成算法形式为,
| AdaBoost |
|---|
| 输入:训练数据集T={(x1,y1),(x2,y2),⋯ ,(xN,yN)}T = \{ ({x_1},{y_1}),({x_2},{y_2}), \cdots ,({x_N},{y_N})\}T={(x1,y1),(x2,y2),⋯,(xN,yN)};其中xi∈χ⊆Rn,yi∈Y={−1,+1}{x_i} \in \chi \subseteq {R^n},{y_i} \in Y = \{ - 1, + 1\}xi∈χ⊆Rn,yi∈Y={−1,+1};弱学习算法Gm(x){G_m}(x)Gm(x) 输出:最终分类器G(x) 1.初始化训练数据的权值分布D1=(w11,w12,⋯ ,w1i,⋯ ,w1N),          w1i=1N,i=1,2,⋯ ,N{D_1} = ({w_{11}},{w_{12}}, \cdots ,{w_{1i}}, \cdots ,{w_{1N}}),\;\;\;\;\;{w_{1i}} = \frac{1}{N},i = 1,2, \cdots ,ND1=(w11,w12,⋯,w1i,⋯,w1N),w1i=N1,i=1,2,⋯,N 2.对m=1,2,⋯ ,Mm = 1,2, \cdots ,Mm=1,2,⋯,M 2.1 使用具有权值分布Dm{D_m}Dm的训练数据集学习,得到基分类器Gm(x):χ→{−1,+1}{G_m}(x):\chi \to \{ - 1, + 1\} Gm(x):χ→{−1,+1} 2.2 计算Gm(x){G_m}(x)Gm(x)在训练集上的分类误差率em=∑i=1Nwmi[[Gm(xi)≠yi]]{e_m} = \sum\limits_{i = 1}^N {{w_{mi}}\left[\kern-0.15em\left[ {{G_m}({x_i}) \ne {y_i}} \right]\kern-0.15em\right]}em=i=1∑Nwmi[[Gm(xi)̸=yi]] 2.3 计算Gm(x){G_m}(x)Gm(x)的系数αm=12ln(1−emem){\alpha _m} = \frac{1}{2}\ln (\frac{{1 - {e_m}}}{{{e_m}}})αm=21ln(em1−em) 2.4 更新数据集的权值分布Dm+1=(wm+1,1,⋯ ,wm+1,i,⋯ ,wm+1,N)wm+1,i=wmiZmexp(−αmyiGm(xi)),i=1,2,⋯ ,N\begin{array}{l}{D_{m + 1}} = ({w_{m + 1,1}}, \cdots ,{w_{m + 1,i}}, \cdots ,{w_{m + 1,N}})\\\\{w_{m + 1,i}} = \frac{{{w_{mi}}}}{{{Z_m}}}\exp ( - {\alpha _m}{y_i}{G_m}({x_i})),i = 1,2, \cdots ,N\end{array}Dm+1=(wm+1,1,⋯,wm+1,i,⋯,wm+1,N)wm+1,i=Zmwmiexp(−αmyiGm(xi)),i=1,2,⋯,N其中,Zm{Z_m}Zm是规范化因子,Zm=∑i=1Nwmiexp(−αmyiGm(xi)){Z_m} = \sum\limits_{i = 1}^N {{w_{mi}}\exp ( - {\alpha _m}{y_i}{G_m}({x_i}))}Zm=i=1∑Nwmiexp(−αmyiGm(xi))它使Dm+1{D_{m + 1}}Dm+1成为了一个概率分布,即,∑i=1Nwmi=1\sum\limits_{i = 1}^N {{w_{mi}} = 1}i=1∑Nwmi=1。 3.得到最终的分类器G(x)=sign(f(x))=sign(∑m=1MαmGm(x))G(x) = sign(f(x)) = sign(\sum\limits_{m = 1}^M {{\alpha _m}{G_m}(x)} )G(x)=sign(f(x))=sign(m=1∑MαmGm(x)) |
最后,来看一下有关AdaBoost算法的一些含义解释。
首先,在刚开始的时候,假设训练集具有均匀的权值分布,即,训练集里的每条样本数据都具有相同的权值,为1N\frac{1}{N}N1。这能保证在原始数据上学习得到基本分类器G1(x){G_1}(x)G1(x)。
而后的每一轮迭代,改变的其实只有两个量,一个是样本权重wmi{w_{mi}}wmi,另一个是基本学习器的系数(权重) αm{\alpha _m}αm。在每一轮m=1,2,⋯ ,Mm = 1,2, \cdots ,Mm=1,2,⋯,M顺次地执行下列操作:
1.使用当前加权的训练集Dm{D_m}Dm,学习基本分类器Gm(x){G_m}(x)Gm(x)。其实该步骤更新了Gm(x){G_m}(x)Gm(x)里的参数γm{\gamma _m}γm。
2.计算Gm(x){G_m}(x)Gm(x)在加权数据集Dm{D_m}Dm上的分类误差率,
em=∑i=1Nwmi[[Gm(xi)≠yi]]=∑Gm(xi)≠yiwmi{e_m} = \sum\limits_{i = 1}^N {{w_{mi}}\left[\kern-0.15em\left[ {{G_m}({x_i}) \ne {y_i}} \right]\kern-0.15em\right]} = \sum\limits_{{G_m}({x_i}) \ne {y_i}} {{w_{mi}}}em=i=1∑Nwmi[[Gm(xi)̸=yi]]=Gm(xi)̸=yi∑wmi
wmi{w_{mi}}wmi表示第m轮中第i个样本的权值,因为是规范化之后的,所以∑i=1Nwmi=1\sum\limits_{i = 1}^N {{w_{mi}} = 1}i=1∑Nwmi=1。则这里的分类误差率表示的是被Gm(x){G_m}(x)Gm(x)误分类的样本权值之和。
3.计算基本分类器Gm(x){G_m}(x)Gm(x)的系数αm{\alpha _m}αm,
αm=12ln(1−emem){\alpha _m} = \frac{1}{2}\ln (\frac{{1 - {e_m}}}{{{e_m}}})αm=21ln(em1−em)
图像如下图,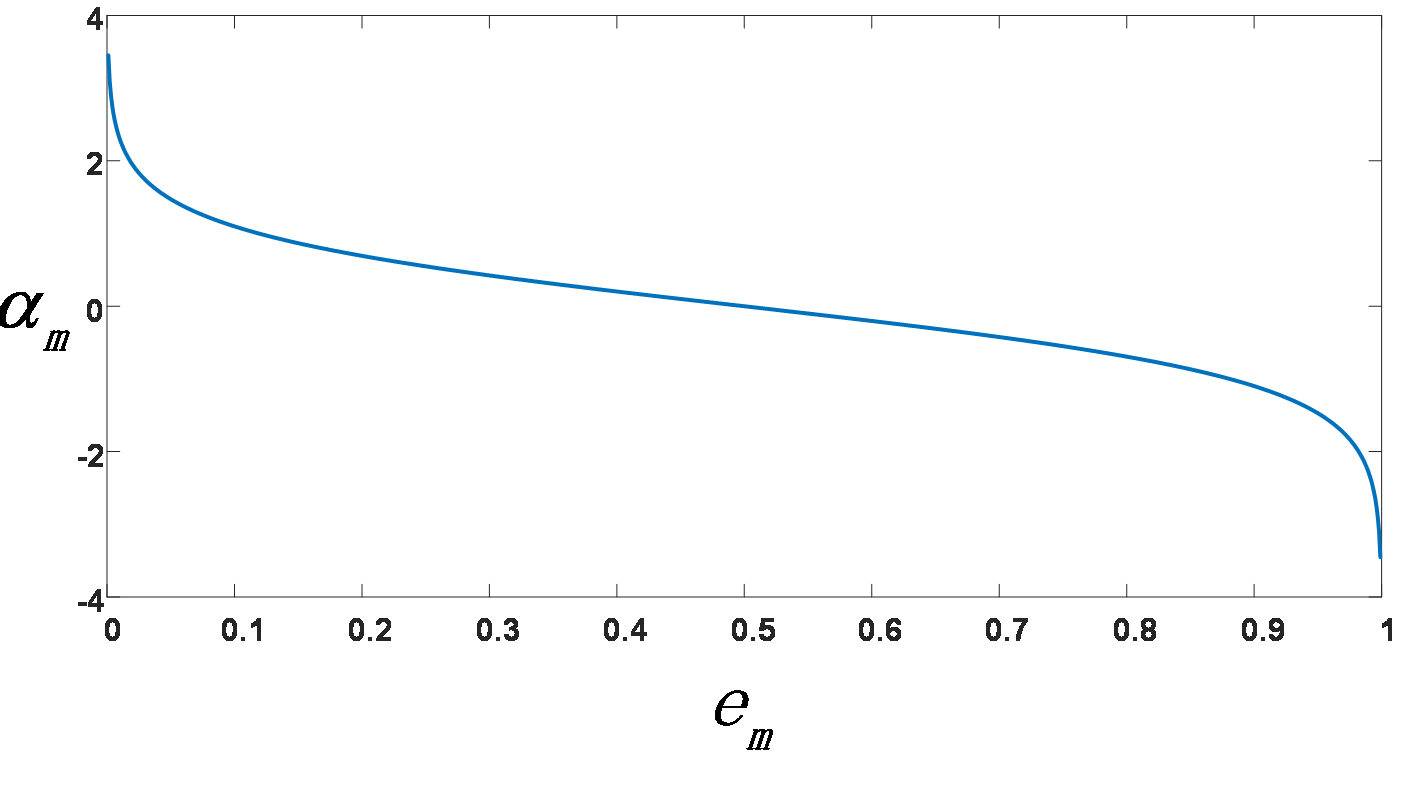
这里的αm{\alpha _m}αm表示的是 在最终分类器中的重要程度。由函数图像可知,当em≤12{e_m} \le \frac{1}{2}em≤21时,αm≥0{\alpha _m} \ge 0αm≥0,并且αm{\alpha _m}αm随em{e_m}em的减小而增大,所以分类误差率越小的基分类器在最终分类器中的作用就越大。
4.更新样本集的权值分布,为下一轮做准备,这里的权值更新式wm+1,i=wmiZmexp(−αmyiGm(xi)){w_{m + 1,i}} = \frac{{{w_{mi}}}}{{{Z_m}}}\exp ( - {\alpha _m}{y_i}{G_m}({x_i}))wm+1,i=Zmwmiexp(−αmyiGm(xi))可以改写成,
wm+1,i={wmiZme−αm,        Gm(xi)≠yiwmiZmeαm,        Gm(xi)=yi{w_{m + 1,i}} = \left\{ {\begin{array}{} {\frac{{{w_{mi}}}}{{{Z_m}}}{e^{ - {\alpha _m}}},\;\;\;\;{G_m}({x_i}) \ne {y_i}}\\\\ {\frac{{{w_{mi}}}}{{{Z_m}}}{e^{{\alpha _m}}},\;\;\;\;{G_m}({x_i}) = {y_i}} \end{array}} \right.wm+1,i=⎩⎨⎧Zmwmie−αm,Gm(xi)̸=yiZmwmieαm,Gm(xi)=yi
由上式可知,被基本分类器Gm(x){G_m}(x)Gm(x)误分类的样本的权值得以扩大,而被正确分类的样本的权值得以缩小。其中,误分类样本的权值被放大了e2α=1−emem{e^{2\alpha }} = \frac{{1 - {e_m}}}{{{e_m}}}e2α=em1−em倍。这就说明,误分类的样本在下一轮学习中起到了更大的作用。不改变所给的训练集,而不断改变样本的权值分布,使得训练集在基本分类器中的学习起到了不同的作用,这其实就是统计学里的boostrapping操作,即,在一个样本集里进行N次有放回的抽样,这也是AdaBoost的一个特点。
最终分类器是由M个基本分类器线性组合而成,这是AdaBoost的另一个特点。系数αm{\alpha _m}αm表示了基本分类器Gm(x){G_m}(x)Gm(x)的重要性,所有的αm{\alpha _m}αm之和并不为1。最终的分类器f(x)的符号决定了实例所属的类别,而绝对值表示了分类的确信度。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)